En este tutorial, explorarás:
- La definición de un raspador de noticias y por qué resulta útil
- Los tipos de datos que puedes extraer con él
- Los dos enfoques más comunes para crear un raspador de noticias web
- Cómo crear un proceso de extracción de noticias con IA
- Cómo crear un script de raspado de noticias con Python
- Los retos del raspado de artículos de prensa
¡Vamos allá!
¿Qué es un raspador de noticias?
Un raspador de noticias es una herramienta automatizada para extraer datos de sitios de noticias. Recopila información como los titulares, las fechas de publicación, los autores, las etiquetas y el contenido de los artículos.
Los raspadores de noticias se pueden crear con IA y varios lenguajes de programación para el raspado web. Se utilizan ampliamente para la investigación, el análisis de tendencias o la creación de agregadores de noticias, lo que ahorra tiempo en comparación con la recopilación manual de datos.
Datos para raspar de los artículos de prensa
Los datos que puedes extraer de los artículos de prensa incluyen:
- Titulares: el título principal y los subtítulos del artículo.
- Fecha de publicación: la fecha en que se publicó el artículo.
- Autor: el nombre de los escritores o periodistas que escribieron el contenido.
- Contenido: el cuerpo del texto del artículo.
- Etiquetas/Temas: palabras clave o categorías relacionadas con el artículo.
- Archivos adjuntos multimedia: elementos visuales que acompañan al artículo.
- URL: enlaces a artículos o referencias relacionados.
- Artículos relacionados: otras noticias relacionadas o similares al artículo actual.
Cómo crear un raspador de noticias
Al crear una solución para extraer automáticamente datos de artículos de prensa, hay dos enfoques principales:
- Uso de la IA para la extracción de datos
- Creación de scripts de raspado personalizados
Vamos a presentar ambos métodos y explorar sus ventajas y desventajas. Encontrarás los pasos de implementación detallados más adelante en esta guía.
Uso de la IA
La idea detrás de este enfoque es proporcionar el contenido HTML de un artículo de noticias a un modelo de IA para extraer datos. También puedes proporcionar la URL de un artículo de noticias a un proveedor de LLM (Large Language Model) y pedirle que extraiga información esencial, como el título y el contenido principal.
👍 Ventajas:
- Funciona en casi cualquier sitio de noticias
- Automatiza todo el proceso de extracción de datos
- Puede mantener el formato, como la sangría original, la estructura de los encabezados, las negritas y otros elementos estilísticos
👎 Desventajas:
- Los modelos avanzados de IA están patentados y pueden ser caros
- No tienes pleno control sobre el proceso de raspado
- Los resultados pueden incluir alucinaciones (información inexacta o inventada)
Uso de un script de raspado personalizado
El objetivo aquí consiste en codificar manualmente un bot de raspado que se dirija a sitios de fuentes de noticias específicos. Estos scripts se conectan al sitio de destino, analizan el HTML de las páginas de noticias y extraen datos de ellas.
👍 Ventajas:
- Tienes el pleno control sobre el proceso de extracción de datos
- Se puede adaptar para cumplir con requisitos específicos
- Es rentable, ya que no depende de proveedores externos
👎 Desventajas:
- Requiere conocimientos técnicos para diseñar y mantener
- Cada sitio de noticias necesita su propio script de raspado específico
- Gestionar casos extremos (p. ej., artículos en directo) puede ser difícil
Enfoque 1: usar la IA para raspar noticias
La idea es usar la IA para que se encargue del trabajo duro por ti. Se puede hacer utilizando directamente herramientas de LLM de primera calidad, como las últimas versiones de ChatGPT con capacidades de rastreo, o integrando modelos de IA en tu script. En este último caso, también necesitarás conocimientos técnicos y la capacidad de escribir un script básico.
Estos son los pasos que normalmente implica el proceso de raspado de noticias basado en la IA:
- Recopilar datos: recupera el HTML de la página de destino mediante un cliente HTTP. Si utilizas una herramienta como ChatGPT con funciones de rastreo, este paso es automático y solo necesitas introducir la URL de la noticia.
- Preprocesar los datos: si trabajas con HTML, depura el contenido antes de enviarlo a la IA. Esto puede requerir la eliminación de guiones, anuncios o estilos innecesarios. Céntrate en las partes más relevantes de la página, como el título, el nombre del autor y el cuerpo del artículo.
- Enviar datos al modelo de IA: en el caso de herramientas como ChatGPT con funciones de navegación, basta con proporcionar la URL del artículo junto con una indicación bien elaborada. La IA analizará la página y devolverá datos estructurados. Otra posibilidad es introducir el contenido HTML depurado en el modelo de IA y darle instrucciones específicas sobre lo que debe extraer.
- Gestiona el resultado de la IA: la respuesta de la IA suele ser desestructurada o semiestructurada. Usa tu script para procesar y formatear la salida en el formato deseado.
- Exporta los datos extraídos: guarda los datos estructurados en el formato que prefieras, ya sea una base de datos, un archivo CSV u otra solución de almacenamiento.
Para obtener más información, lee nuestro artículo sobre cómo usar la IA para el raspado web.
Enfoque 2: crear un script de raspado de noticias
Para crear manualmente un raspador de noticias, primero debes familiarizarte con el sitio de destino. Inspecciona la página de noticias para entender su estructura, los datos que puedes extraer y las herramientas de raspado que debes utilizar.
En el caso de sitios de noticias sencillos, este dúo debería ser suficiente:
- Requests: una biblioteca de Python para enviar solicitudes HTTP. Permite recuperar el contenido HTML en bruto de una página web.
- Beautiful Soup: una biblioteca de Python que permite analizar documentos HTML y XML. Ayuda a navegar y extraer datos de la estructura HTML de la página. Obtén más información en nuestra guía sobre raspado con Beautiful Soup.
Puedes instalarlas en Python con:
pip install requests beautifulsoup4
Para los sitios de noticias que utilizan tecnologías antibots o que requieren la ejecución de JavaScript, debes usar herramientas de automatización del navegador como Selenium. Para obtener más información, consulta nuestra guía sobre el raspado de selenio.
Puedes instalar Selenium en Python con:
pip install selenium
En este caso, debes seguir estos pasos:
- Conectar con el sitio de destino: recupera el HTML de la página y analízalo.
- Seleccionar los elementos de interés: identifica los elementos específicos (por ejemplo, título o contenido) de la página.
- Extraer datos: extrae la información deseada de estos elementos.
- Depurar los datos extraídos: procesa los datos para eliminar cualquier contenido innecesario, si es necesario.
- Exportar los datos extraídos del artículo de noticias: guarda los datos en el formato que prefieras, como JSON o CSV.
En los siguientes capítulos, ¡verás ejemplos de scripts de raspado de noticias en Python para extraer datos de CNN, Reuters y BBC!
Raspado de CNN
Artículo de prensa objetivo:: «El frío nordeste se ve asolado por condiciones húmedas y desordenadas mientras una ráfaga ártica apunta al fin de semana de Acción de Gracias».
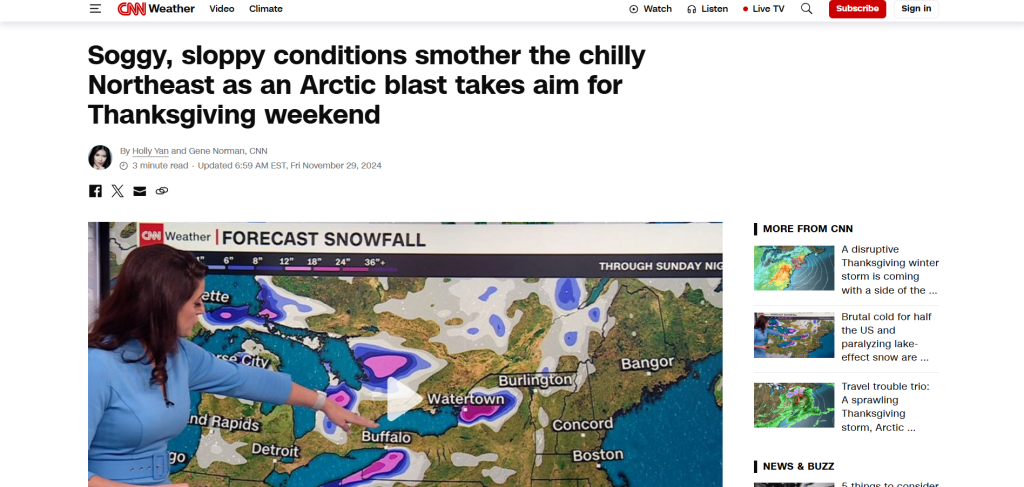
CNN no cuenta con medidas específicas contra el raspado. Así que nos bastará con un sencillo script que utilice Requests y Beautiful Soup:
import requests
from bs4 import BeautifulSoup
import json
# URL of the CNN article
url = "https://www.cnn.com/2024/11/28/weather/thanksgiving-weekend-weather-arctic-storm/index.html"
# Send an HTTP GET request to the article page
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title
title_element = soup.select_one("h1")
title = title_element.get_text(strip=True)
# Extract the article content
article_content = soup.select_one(".article__content")
content = article_content.get_text(strip=True)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
Ejecuta el script y generará un archivo JSON que contiene:
{
"title": "Soggy, sloppy conditions smother the chilly Northeast as an Arctic blast takes aim for Thanksgiving weekend",
"content": "CNN—After the Northeast was hammered by frigid rain or snow on Thanksgiving, a bitter blast of Arctic air is set to envelop much of the country by the time travelers head home this weekend. ... (omitted for brevity)"
}
¡Genial! Acabas de raspar CNN.
Raspado de Reuters
Artículo de prensa objetivo: «Macron elogia a los artesanos por la restauración de la Catedral de Notre-Dame de París».
Ten en cuenta que Reuters tiene una solución antibots especial que bloquea todas las solicitudes que no provienen de un navegador. Si intentas realizar una solicitud automática con Requests o cualquier otro cliente HTTP de Python, aparecerá la siguiente página de error:
<html><head><title>reuters.com</title><style>#cmsg{animation: A 1.5s;}@keyframes A{0%{opacity:0;}99%{opacity:0;}100%{opacity:1;}}</style></head><body style="margin:0"><p id="cmsg">Please enable JS and disable any ad blocker</p><script data-cfasync="false">var dd={'rt':'c','cid':'AHrlqAAAAAMAjfxsASop65YALVAczg==','hsh':'2013457ADA70C67D6A4123E0A76873','t':'fe','s':46743,'e':'da7ef98f4db57c2e85c7ae9df5bf374e4b214a77c73ee80d700757e60962367f','host':'geo.captcha-delivery.com','cookie':'lperXjdnamczWV5K~_ghwm4FDVstzxj76zglHEWJSBJjos3qpM2P8Ir0eNn5g9yh159oMTwy9UaWuWgflgV51uAJZKzO7JJuLN~xg2wken37VUTvL6GvZyl89SNuHrSF'}</script><script data-cfasync="false" src="https://ct.captcha-delivery.com/c.js"></script></body></html>
Por tanto, debes usar una herramienta de automatización del navegador como Selenium para extraer artículos de prensa de Reuters. He aquí cómo hacerlo:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import json
# Initialize the WebDriver
driver = webdriver.Chrome(service=Service())
# URL of the Reuters article
url = "https://www.reuters.com/world/europe/excitement-relief-paris-notre-dame-cathedral-prepares-reopen-2024-11-29/"
# Open the URL in the browser
driver.get(url)
# Extract the title from the <h1> tag
title_element = driver.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
# Select all text elements
paragraph_elements = driver.find_elements(By.CSS_SELECTOR, "[data-testid^="paragraph-"]")
# Aggregate their text
content = " ".join(p.text for p in paragraph_elements)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
Si ejecutas el script anterior y no te bloquean, el resultado será el siguiente archivo article.json:
{
"title": "Macron lauds artisans for restoring Notre-Dame Cathedral in Paris",
"content": "PARIS, Nov 29 (Reuters) - French President Emmanuel Macron praised on Friday the more than 1,000 craftspeople who helped rebuild Paris' Notre-Dame Cathedral in what he called "the project of the century", ... (omitted for brevity)"
}
¡Genial! Acabas de realizar un raspado de Reuters.
Raspado de BBC
Artículo de prensa objetivo: «Black Friday: cómo encontrar una oferta sin dejarse estafar».
Al igual que la CNN, la BBC no cuenta con soluciones antibots específicas. Por tanto, valdrá con usar un sencillo script de raspado que utilice el dúo de cliente HTTP y analizador HTML:
import requests
from bs4 import BeautifulSoup
import json
# URL of the BBC article
url = "https://www.bbc.com/news/articles/cvg70jr949po"
# Send an HTTP GET request to the article page
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title
title_element = soup.select_one("h1")
title = title_element.get_text(strip=True)
# Extract the article content
article_content_elements = soup.select("[data-component="text-block"], [data-component="subheadline-block"]")
# Aggregate their text
content = "n".join(ace.text for ace in article_content_elements)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
Ejecútalo y producirá este archivo article.json:
{
"title": "Black Friday: How to spot a deal and not get ripped off",
"content": "The Black Friday sales are already in full swing and it can be easy to get swept up in the shopping frenzy and end up out of pocket - instead of bagging a bargain... (omitted for brevity)"
}
¡Increíble! Acabas de hacer un raspado de la BBC.
Dificultades en el raspado de noticias y cómo superarlas
En los ejemplos anteriores, nos dirigimos a unos pocos sitios de noticias y extrajimos únicamente el título y el contenido principal de sus artículos. Esta simplicidad hizo que el raspado de noticias pareciera fácil. En realidad, es mucho más complejo, ya que la mayoría de los sitios web de noticias detectan y bloquean activamente los bots:
Algunas de las dificultades que debe tener en cuenta son:
- Asegúrate de que los artículos raspados conserven su estructura de encabezados adecuada
- No te limites a los títulos y el contenido principal para extraer metadatos como etiquetas, autores y fechas de publicación
- Automatiza el proceso de raspado para gestionar varios artículos en varios sitios web de manera eficiente
Para afrontar estos retos, puedes:
- Aprender técnicas avanzadas: consulta nuestras guías sobre cómo eludir los CAPTCHA con Python y explora los tutoriales de raspado para obtener consejos prácticos.
- Usar herramientas de automatización avanzadas: emplea herramientas sólidas como Playwright Stealth para raspar sitios con mecanismos antibots.
Aun así, la mejor solución es aprovechar una API de raspado de noticias específica.
La API de raspado de noticias de Bright Data ofrece una solución eficaz e integral para raspar las principales fuentes de noticias como BBC, CNN, Reuters y Google News. Con esta API, puedes:
- Extraee datos estructurados como identificadores, URL, titulares, autores, temas y mucho más
- Ampliar tus proyectos de raspado sin preocuparte por la infraestructura, los servidores proxy o los bloques de sitios web
- Olvidarte de los bloqueos y las interrupciones
Optimizar tu proceso de raspado de noticias y centrarte en lo que importa: ¡analizar los datos!
Conclusión
En este artículo, has aprendido qué es un raspador de noticias y el tipo de datos que permite recuperar de los artículos de prensa. También has visto cómo crear uno usando una solución basada en IA o scripts manuales.
Por muy sofisticado que sea tu script de raspado de noticias, la mayoría de los sitios pueden detectar actividades automatizadas y bloquear tu acceso. La solución a este problema es usar una API de raspado de noticias específica, diseñada expresamente para extraer datos de noticias de manera fiable de varias plataformas.
Estas API ofrecen datos estructurados y completos, adaptados a cada fuente de noticias:
- API de raspado de CNN: extrae datos como titulares, autores, temas, fechas de publicación, contenido, imágenes, artículos relacionados y mucho más.
- API de raspado de Google News: recopila información como titulares, temas, categorías, autores, fechas de publicación, fuentes y mucho más.
- API de raspado de Reuters: recupera datos que incluyen ID, URL, autores, titulares, temas, fechas de publicación y mucho más.
- API de raspado de BBC: recopila detalles como titulares, autores, temas, fechas de publicación, contenido, imágenes, artículos relacionados y mucho más.
Si no te interesa crear un raspador, puedes usar nuestros conjuntos de datos de noticias listos para usar. Estos conjuntos de datos están precompilados e incluyen registros completos:
- BBC News: un conjunto de datos que abarca todos los puntos principales, con decenas de miles de registros.
- CNN News: un conjunto de datos que incluye todos los puntos de datos críticos, con cientos de miles de registros.
- Google News: un conjunto de datos que abarca todos los puntos de datos fundamentales, con decenas de miles de registros.
- Reuters News: un conjunto de datos que abarca todos los puntos principales, con cientos de miles de registros.
Explora todos nuestros conjuntos de datos para periodistas.
Crea hoy mismo una cuenta gratuita de Bright Data para probar nuestras API de raspado o explora nuestros conjuntos de datos.