
En este artículo, aprenderás:
- Qué son Apache Airflow y Apache Spark y qué ofrecen.
- Por qué la integración de la API Web Unlocker de Bright Data con Airflow y Spark es una estrategia eficaz para la generación de clientes potenciales.
- Cómo crear un proceso integral que recopile, procese y almacene datos empresariales estructurados a gran escala.
Antes de profundizar en las herramientas específicas y la implementación, establezcamos los conceptos fundamentales y veamos cómo se conectan dentro de un flujo de trabajo de generación de clientes potenciales.
¿Qué es Apache Airflow?
Apache Airflow es una plataforma de código abierto para la orquestación de flujos de trabajo que permite crear, programar y supervisar pipelines de datos mediante programación. Desarrollada originalmente en Airbnb, permite a los ingenieros de datos definir flujos de trabajo como grafos acíclicos dirigidos (DAG) utilizando Python sin sintaxis especial, lo que proporciona un control total sobre las dependencias de las tareas, los reintentos, la programación y las alertas.
Su objetivo principal es ayudarte a ejecutar de forma fiable flujos de datos complejos y de varios pasos. Esto se consigue proporcionando un amplio ecosistema de operadores (para Bash, Python, HTTP, Spark, SQL y más), una interfaz de usuario web visual para supervisar las ejecuciones, lógica integrada de reintentos y alertas, e integraciones nativas con plataformas en la nube como AWS, GCP y Azure.
Ahora que ya comprendemos la orquestación de flujos de trabajo, veamos el lado del procesamiento de datos del pipeline.
Apache Spark es un motor de análisis unificado para el procesamiento de datos a gran escala. Proporciona un marco de computación distribuida capaz de procesar conjuntos de datos masivos en memoria a través de un clúster de máquinas, lo que lo hace considerablemente más rápido que los sistemas de procesamiento tradicionales basados en disco.
Spark admite el procesamiento por lotes, el streaming, las consultas SQL, el aprendizaje automático y el cálculo de grafos a través de una API unificada disponible en Python (PySpark), Scala, Java y R. Para cargas de trabajo con un uso intensivo de datos, como la limpieza, la deduplicación, el enriquecimiento y la transformación de grandes volúmenes de datos empresariales extraídos, Spark es la herramienta estándar del sector.
Apache Airflow frente a Apache Spark: ¿cuál es la diferencia?
Si eres nuevo en esta pila, es fácil confundir ambos, ya que suelen aparecer juntos. Pero tienen fines muy diferentes:
- Apache Airflow es un orquestador. Decide cuándo ejecutar las tareas, en qué orden, cómo gestionar los fallos y cómo supervisar el flujo de trabajo general. No procesa los datos por sí mismo.
- Apache Spark es un procesador de datos. Toma datos sin procesar o semiestructurados y los transforma a gran escala utilizando el cálculo distribuido entre muchos núcleos o máquinas.
Se complementan muy bien. Airflow programa y activa tus trabajos de Spark en el momento adecuado y en la secuencia correcta, mientras que Spark se encarga del trabajo pesado de la transformación de datos. En este tutorial, verás cómo Airflow orquesta todo el proceso de principio a fin: activando Bright Data para recopilar listados de empresas, pasando los resultados sin procesar a Spark para su limpieza y enriquecimiento, y escribiendo los clientes potenciales finales en una base de datos.
¿Por qué integrar Bright Data en un proceso de Airflow + Spark?
Airflow proporciona un SimpleHttpOperator y un PythonOperator que te permiten llamar a cualquier API REST como tarea del proceso. Esto significa que puedes activar la recopilación de datos web como un paso de primer orden en tu DAG junto con tus trabajos de transformación y carga.
Sin embargo, para inyectar datos empresariales fiables y estructurados en su proceso a gran escala, necesita una fuente que pueda gestionar medidas anti-bot, segmentación geográfica y salida estructurada sin necesidad de mantener un Scraper personalizado. Aquí es donde entra en juego la API Web Unlocker de Bright Data.
La API Web Unlocker le da acceso a cualquier página web pública, independientemente de la protección contra bots, los requisitos de renderización de JavaScript o las restricciones geográficas. Usted envía una solicitud POST con una URL de destino y Bright Data devuelve el contenido de la página. Sin código de automatización del navegador, sin gestión de Proxy, sin gestión de CAPTCHA.
Este enfoque resulta especialmente útil para:
- Canales de generación de clientes potenciales que recopilan periódicamente listados de empresas actualizados de directorios y los introducen en un CRM o una herramienta de captación.
- Flujos de trabajo de estudio de mercado que agregan datos empresariales de distintas regiones o sectores para realizar análisis de la competencia.
- Sistemas de enriquecimiento de datos que añaden datos de contacto, el tamaño de la empresa o la clasificación sectorial a una base de datos de clientes potenciales existente.
- Plataformas de inteligencia de ventas que supervisan los cambios en los listados de empresas y activan alertas cuando las empresas objetivo actualizan sus perfiles.
Al combinar la programación y la orquestación de Airflow con el procesamiento de datos distribuido de Spark y la infraestructura de datos web de Bright Data, puedes crear un motor de generación de clientes potenciales de nivel de producción que funcione de forma automática.
Cómo crear un proceso de generación de clientes potenciales con Airflow, Spark y Bright Data
En esta sección guiada, creará un proceso integral que consta de tres etapas principales:
- Recupera listados de empresas: una tarea de Airflow llama a la API Web Unlocker de Bright Data para recopilar los resultados de búsqueda de las Páginas Amarillas en tres ciudades.
- Valida los datos recopilados: una segunda tarea lee los resultados guardados y confirma que los datos se han recopilado correctamente.
- Procesa con Spark: un trabajo de PySpark limpia, deduplica y puntúa los registros sin procesar.
Nota: Esta es una de las muchas arquitecturas posibles. Podrías escribir la salida de Spark en un almacén de datos como BigQuery o Snowflake, enviarla directamente a un CRM a través de su API o introducirla en un paso de enriquecimiento basado en LLM para la puntuación automatizada de clientes potenciales.
Siga las instrucciones que se indican a continuación para crear un proceso automatizado de generación de clientes potenciales impulsado por la API Web Unlocker de Bright Data dentro de Apache Airflow y Spark.
Requisitos previos
Para seguir este tutorial, necesitas:
- Una cuenta de Bright Data con una zona de Web Unlocker activa. Inicie sesión en su panel de control de Bright Data, vaya a «Configuración de la cuenta» y copie su token de API. Estará en formato UUID. Anote también el nombre de su zona.
- Docker Desktop (macOS o Windows) O un entorno nativo de Python (Ubuntu/Linux). Consulta el paso 1 para ambas opciones.
Paso 1: Configuración del proyecto
Instala Docker Desktop y asegúrate de que está en ejecución antes de continuar. En la configuración de Docker Desktop, ve a Recursos y asigna al menos 5 GB de memoria. La pila multicontainer de Airflow lo necesita.
Paso 2: Crear la estructura del proyecto
Crea un directorio de trabajo y las carpetas que necesita Airflow:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins configLa estructura de tu proyecto tendrá este aspecto:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yamlPaso 3: Configurar Docker Compose
Descarga el archivo oficial de Airflow Docker Compose:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'Crea un archivo Dockerfile en el mismo directorio. Esto amplía la imagen base de Airflow para añadir la biblioteca requests:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkAbre docker-compose.yaml. Busca el bloque x-airflow-common cerca de la parte superior y añade build: . justo debajo de la línea image:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .Además, asegúrate de que la línea _PIP_ADDITIONAL_REQUIREMENTS esté vacía. El Dockerfile es el lugar correcto para las dependencias, no esta variable de entorno:
_PIP_ADDITIONAL_REQUIREMENTS: ""Por último, añade un montaje de volumen para spark_jobs/ en la lista volumes: del mismo bloque. El archivo predeterminado solo monta dags/, logs/, plugins/ y config/, por lo que el contenedor de trabajo no podrá encontrar tu archivo de trabajo de Spark sin esta adición:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobsEl resto del archivo permanece exactamente como se descargó. De forma predeterminada, te proporciona CeleryExecutor con Redis como intermediario de mensajes y PostgreSQL como base de datos de metadatos, las carpetas dags/, logs/, config/ y plugins/ montadas como volúmenes desde la carpeta de tu proyecto, credenciales predeterminadas con el nombre de usuario airflow y la contraseña airflow, y un servicio airflow-init que se ejecuta una vez al iniciar por primera vez para migrar la base de datos y crear el usuario de administrador.
Compila la imagen personalizada e inicia todos los servicios:
docker compose build
docker compose up -dEspera unos 60 segundos y, a continuación, comprueba que los seis contenedores funcionan correctamente:
docker compose psResultado esperado:

Abre http://localhost:8080 en tu navegador e inicia sesión con el nombre de usuario airflow y la contraseña airflow.
Paso 4: Escribe el DAG de Airflow
Crea el archivo dags/lead_generation_dag.py:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "tu-token-API-de-brightdata-aquí"
ZONA = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Recuperando: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zona": "Zona",
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"Se han obtenido {len(response.text)} caracteres de {url}")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"Se han guardado {len(results)} páginas en {RAW_DATA_PATH}")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"Validación superada: {count} páginas recopiladas")
for item in data:
print(f" URL: {item['url']} | Estado: {item['status']} | Tamaño: {len(item['content'])} caracteres")
con DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Recopilar clientes potenciales empresariales utilizando Bright Data Web Unlocker",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_dataSustituye your-brightdata-api-token-here por tu token de API real y actualiza ZONA para que coincida con el nombre de tu zona de Web Unlocker.
Analicemos qué hace cada parte:
API_KEYyZONA: Tus credenciales de Bright Data. El token de API es el token en formato UUID de la configuración de tu cuenta, no una contraseña de zona.TARGETS: Tres URL de búsqueda de Yellow Pages que abarcan empresas de software en San Francisco, agencias de marketing en Nueva York y startups de tecnología financiera en Austin.fetch_business_listings: Recorre cada URL de destino y envía una solicitud POST a la API de Web Unlocker. Bright Data se encarga de las medidas anti-bot, la rotación de Proxies y la renderización de JavaScript, devolviendo el contenido de la página como Markdown. Los resultados se guardan en disco y el recuento de registros se envía al almacén XCom de Airflow para que lo lea la siguiente tarea.validate_output: Lee el archivo guardado y registra cada URL, el estado HTTP y el tamaño del contenido. Esto actúa como una comprobación ligera de la calidad de los datos antes del procesamiento posterior.fetch_listings >> validate_data: El operador>>define la dependencia de la tarea. La validación solo se ejecuta después de que la recuperación se haya realizado con éxito.
Importante: Establezca siempre
start_dateen la fecha de hoy ycatchup=Falseal implementar por primera vez un DAG con una programación recurrente. Si establecestart_dateen una fecha pasada concatchup=True, Airflow pone en cola una ejecución de retroalimentación para cada intervalo perdido desde esa fecha. Para una programación semanal que comenzó hace diez semanas, eso supone diez ejecuciones simultáneas compitiendo por los slots de los trabajadores en el momento en que se reanuda el DAG.
Paso 5: Escribir el trabajo de transformación de PySpark
Crea el archivo spark_jobs/process_leads.py:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
)
.filter(col("company_name").isNotNull())
.filter(col("phone").isNotNull())
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"Se han procesado {enriched_df.count()} clientes potenciales. Salida escrita en {output_path}")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])Este trabajo realiza cuatro tareas. Carga el JSON sin procesar escrito por fetch_listings desde el disco. Limpia los datos normalizando los espacios en blanco, convirtiendo los campos numéricos y eliminando los registros a los que les falte el nombre o el número de teléfono. Desduplica los registros por nombre de empresa y número de teléfono para eliminar los listados duplicados entre ciudades. Por último, puntúa cada registro con una etiqueta lead_score: las empresas con una valoración de 4,0 o superior y al menos 50 reseñas se marcan como «calientes», las que tienen una valoración de 3,0 o superior y al menos 10 reseñas se marcan como «templadas», y el resto se marcan como «frías».
Paso 6: Activar y supervisar el pipeline
Con tu archivo DAG en la carpeta dags/, Airflow lo recoge automáticamente en 30 segundos.
Usuarios de Docker, reanuden y activen el DAG:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation
Observa los registros del trabajador:
docker compose logs airflow-worker -f --tail=20Verás un resultado como este una vez que se ejecuten las tareas:
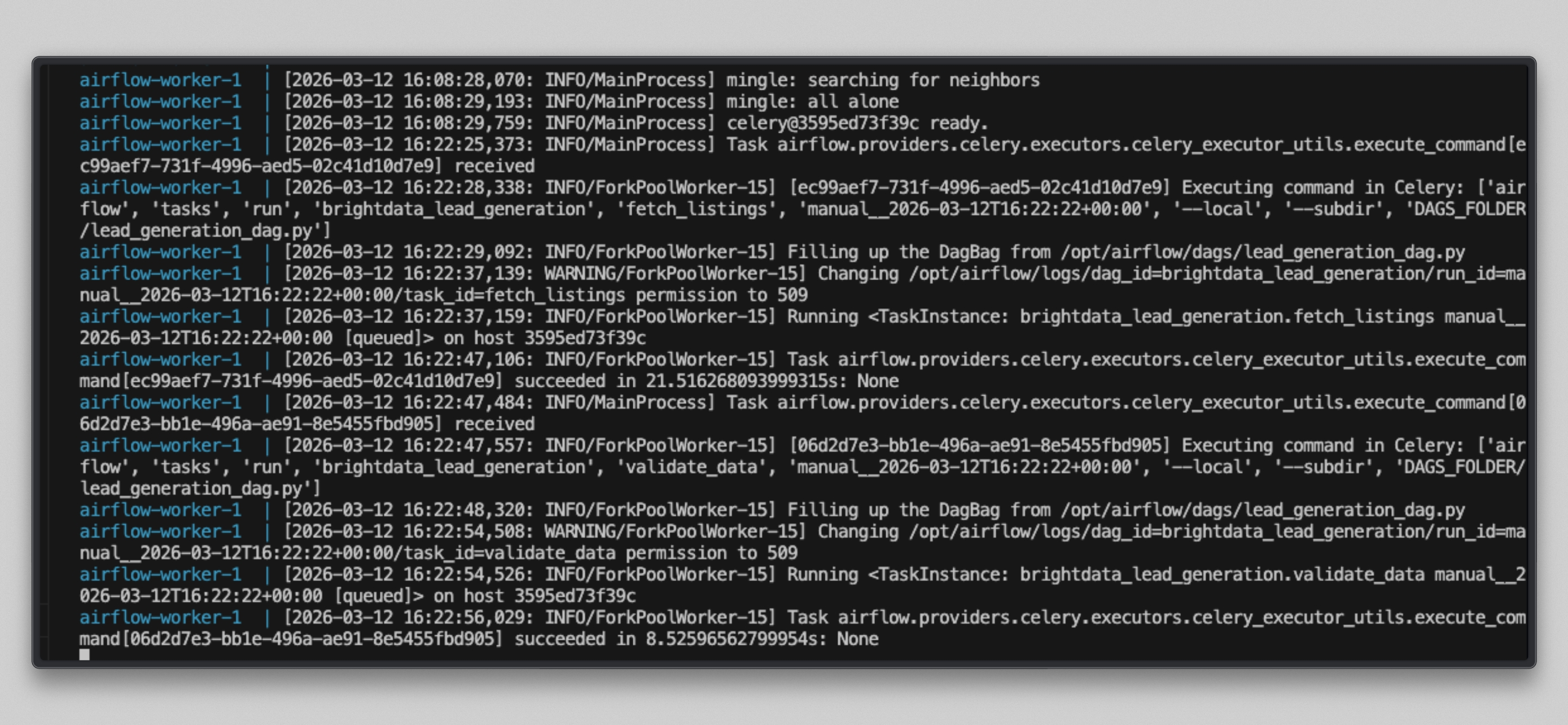
Abre http://localhost:8080, haz clic en el DAG brightdata_lead_generation y cambia a la vista Grid. Cada mosaico de tarea se vuelve verde a medida que se completa. Haz clic en cualquier mosaico de tarea y selecciona Log para ver la salida en tiempo real, incluyendo cada URL obtenida y el recuento de caracteres devuelto por Bright Data.
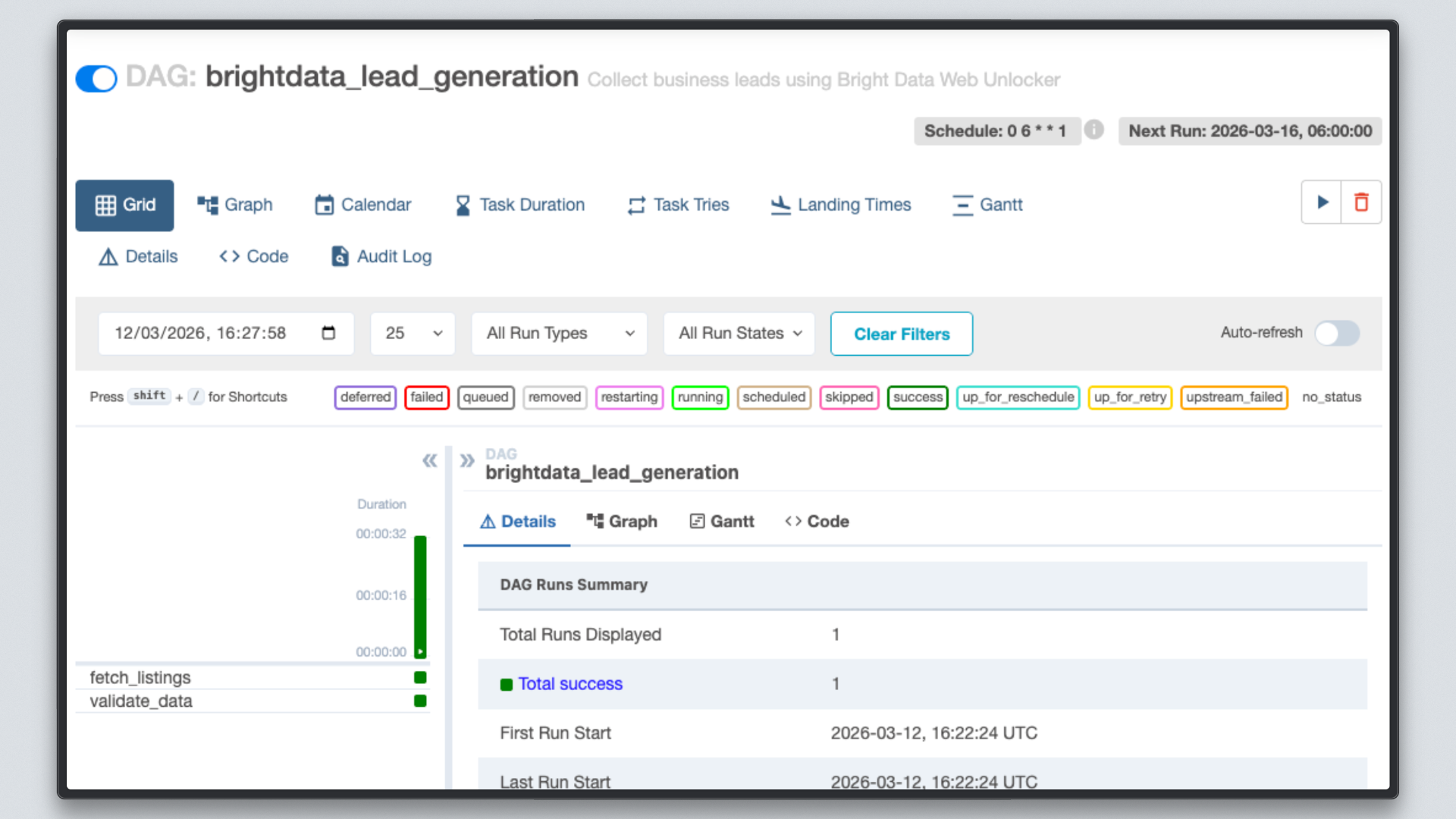
Paso 7: Revisa los resultados
Una vez que ambas tareas aparezcan en verde, comprueba el archivo de salida.
Usuarios de Docker:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUsuarios nativos de Ubuntu:
cat /tmp/brightdata_raw/leads.jsonVerás una matriz JSON con tres entradas, una por cada URL de destino:
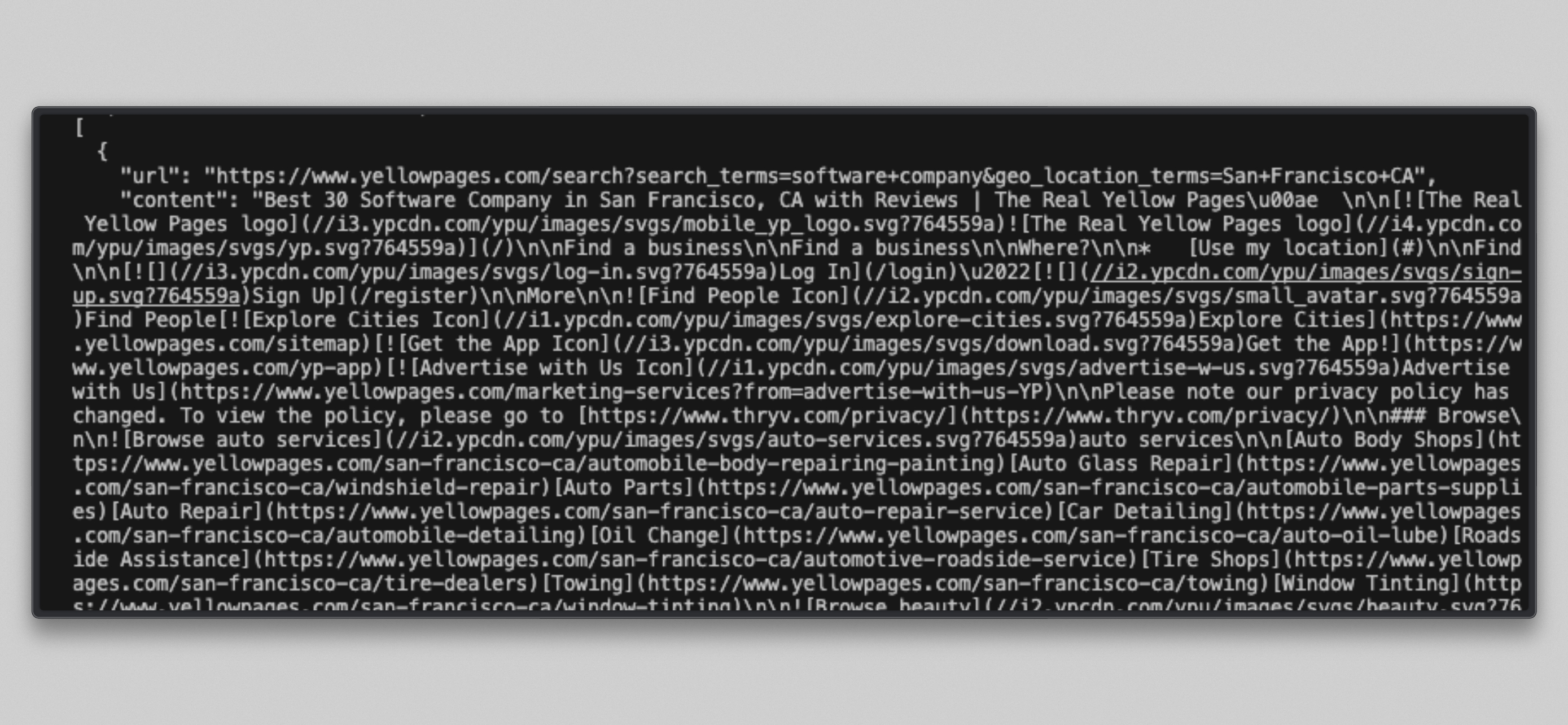
Nota: Algunas URL de Yellow Pages pueden devolver un mensaje
de «bad_endpoint»si el sitio está restringido en el modo de acceso inmediato de Bright Data. Esto es normal. Bright Data muestra el error en la respuesta en lugar de fallar de forma silenciosa. Ponte en contacto con tu Gerente de cuenta de Bright Data si necesitas acceso completo a un sitio restringido.
Por último, ejecute el trabajo de Spark con la salida:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leadsEsto escribe archivos Parquet limpios y puntuados en /tmp/brightdata_processed/leads, listos para cargarse en PostgreSQL o cualquier sistema posterior.
La API de Web Unlocker proporcionó contenido nuevo y en tiempo real de Yellow Pages, y su canalización lo limpió, puntuó y almacenó automáticamente sin escribir una sola línea de código de scraping o de gestión de proxies. Recopilar listados de empresas manualmente es notoriamente difícil debido a los sistemas de detección de bots y a la limitación de velocidad. Al utilizar Web Unlocker de Bright Data, puede obtener de forma fiable el contenido de las páginas de cualquier sitio público en cualquier región, sin necesidad de mantener infraestructura.
Llevándolo más allá
Este pipeline es una base funcional que puede ampliarse en muchas direcciones:
- Sustituya el sistema de archivos local por Amazon S3 o Google Cloud Storage para la capa de datos intermedia, de modo que el proceso funcione en trabajadores distribuidos.
- Añade un paso de enriquecimiento con LLM entre el procesamiento de Spark y la carga de la base de datos, utilizando la API de OpenAI o Anthropic para generar resúmenes de contacto personalizados para cada cliente potencial de interés.
- Cambia la salida local por un envío directo al CRM a Salesforce, HubSpot o Pipedrive utilizando los operadores de proveedores existentes de Airflow.
- Añade una tarea de comprobación de la calidad de los datos utilizando Great Expectations o el SQLCheckOperator de Airflow para validar el recuento de registros y la integridad de los campos antes de confirmar los datos.
Escale el trabajo de Spark a un clúster gestionado utilizando AWS EMR, - Google Dataproc o Databricks actualizando la URL de conexión de Spark en Airflow; el DAG y el código PySpark permanecen sin cambios.
- Utilice la API SERP de Bright Data como tarea de recopilación paralela para enriquecer cada lead con noticias recientes o datos de visibilidad en las búsquedas.
¡Las posibilidades son prácticamente infinitas!
Conclusión
En este artículo, ha creado un proceso de generación de clientes potenciales que funciona combinando la API Web Unlocker de Bright Data, Apache Airflow y Apache Spark.
Airflow se encarga de la programación, la lógica de reintentos, la gestión de dependencias y la observabilidad. Spark se encarga de la limpieza distribuida, la deduplicación y la puntuación de los datos empresariales sin procesar. Bright Data elimina la parte más difícil: recopilar contenido actualizado de páginas web sin tener que gestionar Proxies, escribir código de Scraper ni lidiar con sistemas antibots.
A diferencia de las herramientas de automatización sin código, esta pila te ofrece un control total sobre cada capa del proceso: parámetros de recopilación, lógica de transformación, esquema de salida y cadencia de programación. Se integra de forma natural en cualquier plataforma de datos moderna y se adapta al volumen de tus datos.
Para crear flujos de trabajo más completos, explore el conjunto completo de herramientas de recopilación de datos de Bright Data, que incluye la API SERP para datos de búsqueda, Web Unlocker para páginas con gran cantidad de JavaScript y Conjuntos de datos listos para usar para casos de uso comunes.
Regístrate hoy mismopara obtener una cuenta gratuita de Bright Data y empieza a recopilar los datos empresariales que necesita tu canalización.






