

En este tutorial aprenderás:
- Qué es AWS Glue y qué ofrece.
- Por qué Bright Data es compatible con los procesos ETL gracias a sus servicios de recuperación de datos web.
- Cómo integrar Bright Data en un trabajo ETL en AWS Glue.
¡Empecemos!
¿Qué es AWS Glue?
AWS Glue es un servicio de integración de datos sin servidor creado para simplificar el proceso de descubrimiento, preparación y combinación de datos de múltiples fuentes a cualquier escala.
Te permite crear flujos de trabajo ETL (extraer, transformar, cargar) para análisis, aprendizaje automático y desarrollo de aplicaciones sin tener que gestionar la infraestructura. AWS Glue acelera el desarrollo de canalizaciones de datos y facilita el acceso a los datos para su análisis. Esto se consigue centralizando tu catálogo de datos y proporcionando herramientas de creación de trabajos visuales y basadas en código.
Las tres características más relevantes que ofrece son:
- Descubrir y organizar datos: inferir automáticamente esquemas, catalogar metadatos y conectarse a fuentes de datos en AWS, locales y otras nubes.
- Transformar y limpiar datos: editor visual de trabajos, cuadernos interactivos, compatibilidad con ETL en streaming y deduplicación integrada basada en ML.
- Crear y supervisar canalizaciones: programar, automatizar y escalar trabajos, con la capacidad de supervisar canalizaciones con información detallada y desencadenantes.
Más información en la documentación oficial.
Por qué integrar Bright Data en su flujo de trabajo ETL de AWS Glue
La integración de Bright Data en un flujo de trabajo ETL de AWS puede ampliar drásticamente el alcance y la calidad de sus canalizaciones de datos.
Mientras que el ETL se centra tradicionalmente en extraer datos estructurados de fuentes conocidas, Bright Data permite acceder a datos web estructurados en tiempo real. Esto desbloquea información que, de otro modo, requeriría una recopilación manual o una compleja infraestructura de scraping.
Más allá de la extracción de datos web enriquecidos (E), Bright Data también puede mejorar su fase de transformación (T). Durante la transformación, puede enriquecer los Conjuntos de datos añadiendo información en tiempo real sobre el mercado, los productos o las redes sociales a sus registros. Por ejemplo, podría añadir métricas de rendimiento bursátil, precios de la competencia o metadatos de la empresa a sus Conjuntos de datos internos.
Esa información ayuda a los equipos a tomar decisiones más informadas. La verificación de datos es otra ventaja clave, ya que los datos extraídos pueden cotejarse con fuentes fidedignas. Eso le ayuda a garantizar la precisión antes de cargarlos en su almacén de datos de destino.
Cómo utilizar Bright Data para recuperar datos web para un trabajo ETL de AWS Glue
En esta sección guiada se muestra una posible integración de Bright Data en un trabajo ETL de AWS Glue. En concreto, verá cómo crear este ejemplo de canalización ETL:
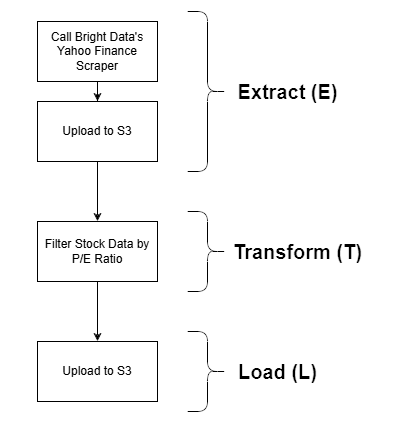
Bright Data entra en juego en la fase de extracción (E), gracias a sus potentes opciones de recuperación de datos web. Se utiliza Yahoo Finance Scraper para recuperar datos bursátiles, que luego se filtran por ratio P/E y finalmente se almacenan en un bucket S3. Se trata de un ejemplo sencillo, pero que constituye una demostración realista de un flujo de trabajo ETL completo.
Nota: Después de este tutorial, se pueden explorar y considerar otros enfoques de integración de Bright Data en AWS Glue.
Siga las instrucciones que se indican a continuación para empezar.
Requisitos
Antes de seguir este tutorial, asegúrese de tener lo siguiente configurado:
- Una cuenta de AWS (incluso una cuenta de prueba gratuita servirá).
- Una cuenta de Bright Data con una clave API configurada. Siga las instrucciones oficiales para generar su clave API.
- Un bucket S3 definido en su cuenta de AWS.
- Conocimientos básicos de Python para escribir un script que se integre con las API de scraping de Bright Data y suba los datos recopilados a su bucket S3.
- Conocimientos básicos de SQL para escribir una consulta sencilla en la fase Transform (T) del proceso ETL.
Para este tutorial, supondremos que su bucket S3 se llama bright-data-etl-bucket: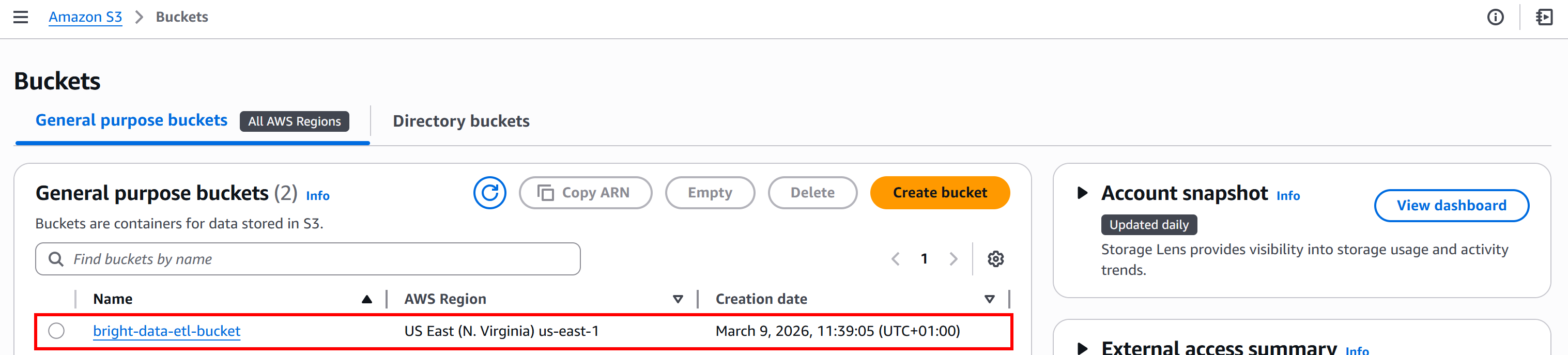
También es útil estar familiarizado con el funcionamiento de las API de Scraping web de Bright Data.
Paso n.º 1: Empieza a utilizar las API de scraping de Bright Data
Al desarrollar un proceso ETL, obviamente debe comenzar con la fase de extracción (E). El primer paso es recuperar los datos utilizando el Scraper de Yahoo Finance de Bright Data, por lo que es importante familiarizarse con él.
Empiece por crear una cuenta de Bright Data, si aún no tiene una. De lo contrario, inicie sesión en su cuenta existente. En el panel de control, vaya a la sección«Web Scrapers»:
A continuación, vaya a la pestaña «Web Scrapers Library» (Biblioteca de Scrapers). Busque «finance» (finanzas) y seleccione la opción «Yahoo Finance Scraper» (Rastreador de Yahoo Finance). Acceda al Scraper disponible:
En la página del Scraper de Yahoo Finance, puede explorar los requisitos de entrada y el esquema de salida de este Scraper: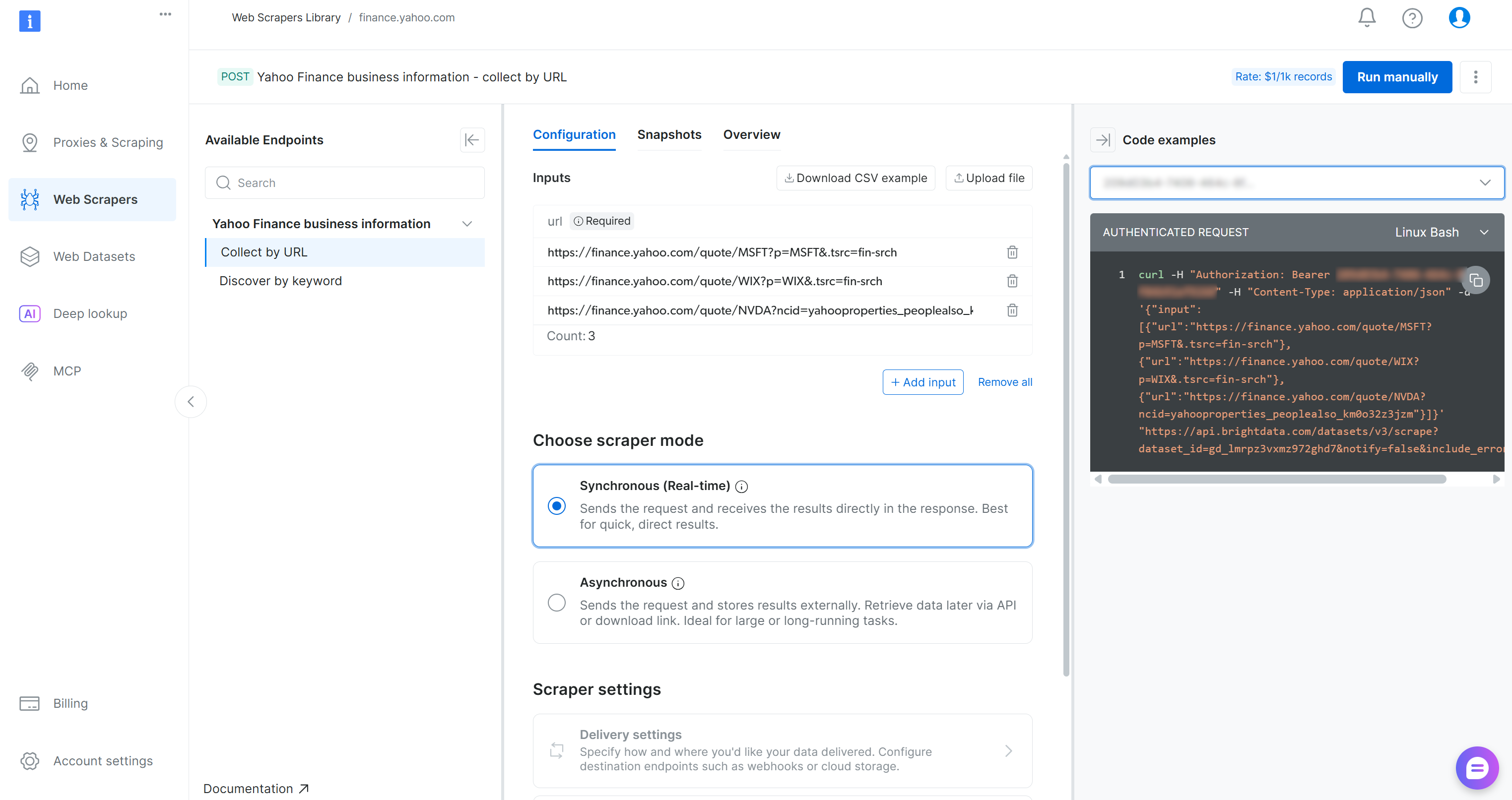
El panel de control también proporciona fragmentos de código en varios lenguajes de programación para una configuración rápida. La clave es que el Scraper acepta una o más páginas de acciones de Yahoo Finance como entrada y devuelve datos bursátiles estructurados en tiempo real. ¡Perfecto!
Paso n.º 2: Configurar la entrega S3
Las API de Scraping web de Bright Data admiten la entrega automática de los datos extraídos a Amazon S3. Por lo tanto, tiene sentido aprovechar esta útil función para acelerar el paso de recopilación de datos. Para configurar la entrega de Amazon S3, primero debe habilitar el modo asíncrono.
En la pestaña «Configuración», seleccione la opción «Asíncrono». A continuación, haga clic en el botón «Configuración de entrega»:
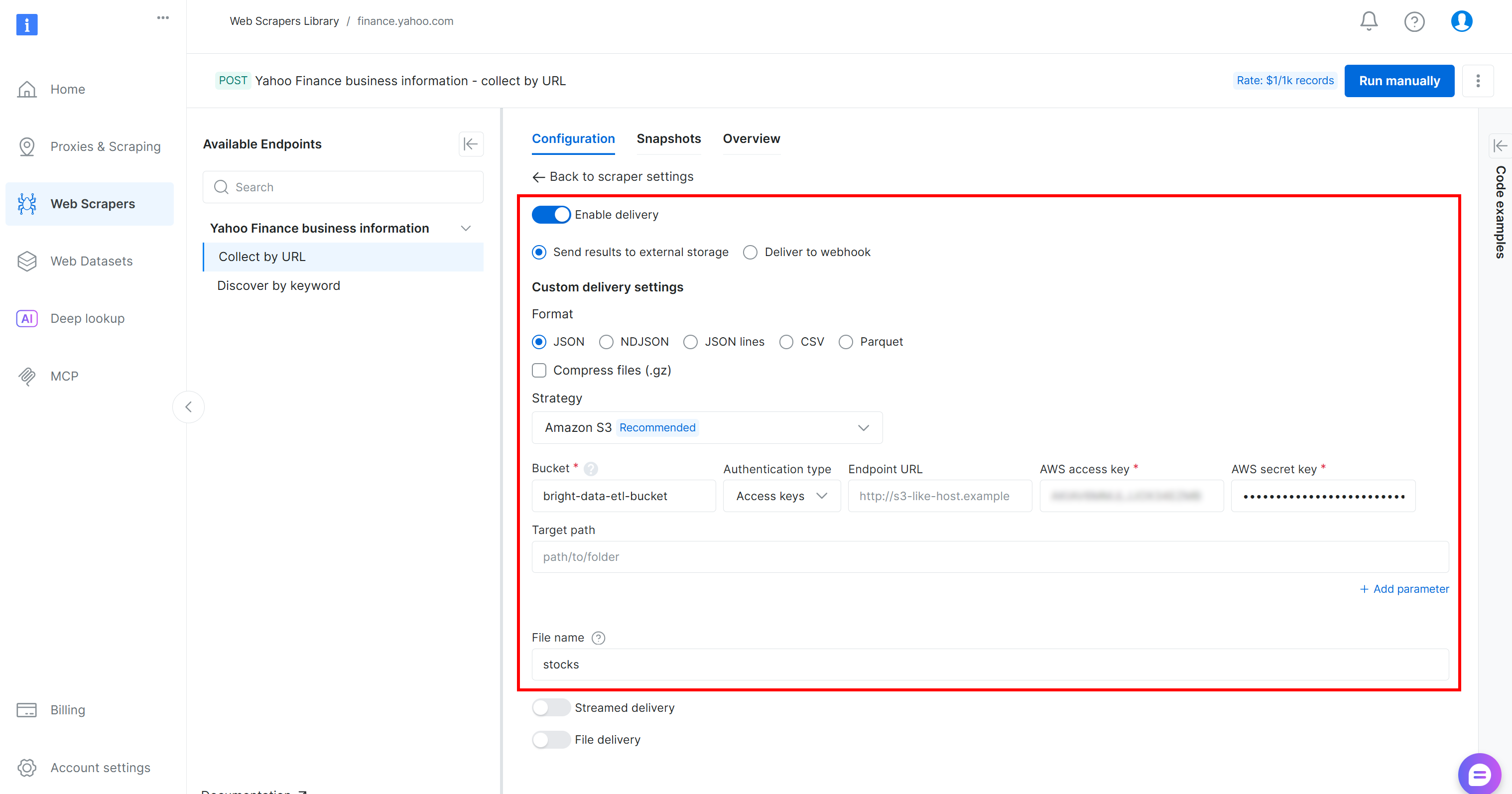
Configure la entrega de datos a su bucket de Amazon S3 rellenando el formulario de la siguiente manera:
- Active la opción «Habilitar entrega».
- Establezca el formato en
JSON. - Seleccione «Amazon S3» como destino de almacenamiento.
- Introduzca el nombre de su bucket S3 (en este ejemplo,
bright-data-etl-bucket). (El campo URL del punto final puede dejarse vacío). - Deje el campo «Ruta de destino» vacío para cargar el archivo en la carpeta raíz del bucket.
- Establezca la opción «Tipo de autenticación» en el valor «Claves de acceso».
- Pegue su ID de clave de acceso de AWS y su clave de acceso secreta de AWS.
- Establezca el nombre del archivo como
stocks.
Con esta configuración, la API de Scraping web se ejecutará en modo asíncrono. Esto significa que Bright Data creará una tarea de scraping que se ejecutará en su infraestructura. Una vez completada la tarea, los datos extraídos se cargarán automáticamente en su bucket de Amazon S3, donde podrá acceder a ellos su trabajo ETL de AWS Glue. ¡Increíble!
Paso n.º 3: Ejecutar la lógica de extracción de datos web
Para verificar que la lógica de extracción de datos web funciona, añada algunas URL de acciones de Yahoo Finance (por ejemplo, NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, BRK.B, LLY) y pulse el botón «Ejecutar manualmente»: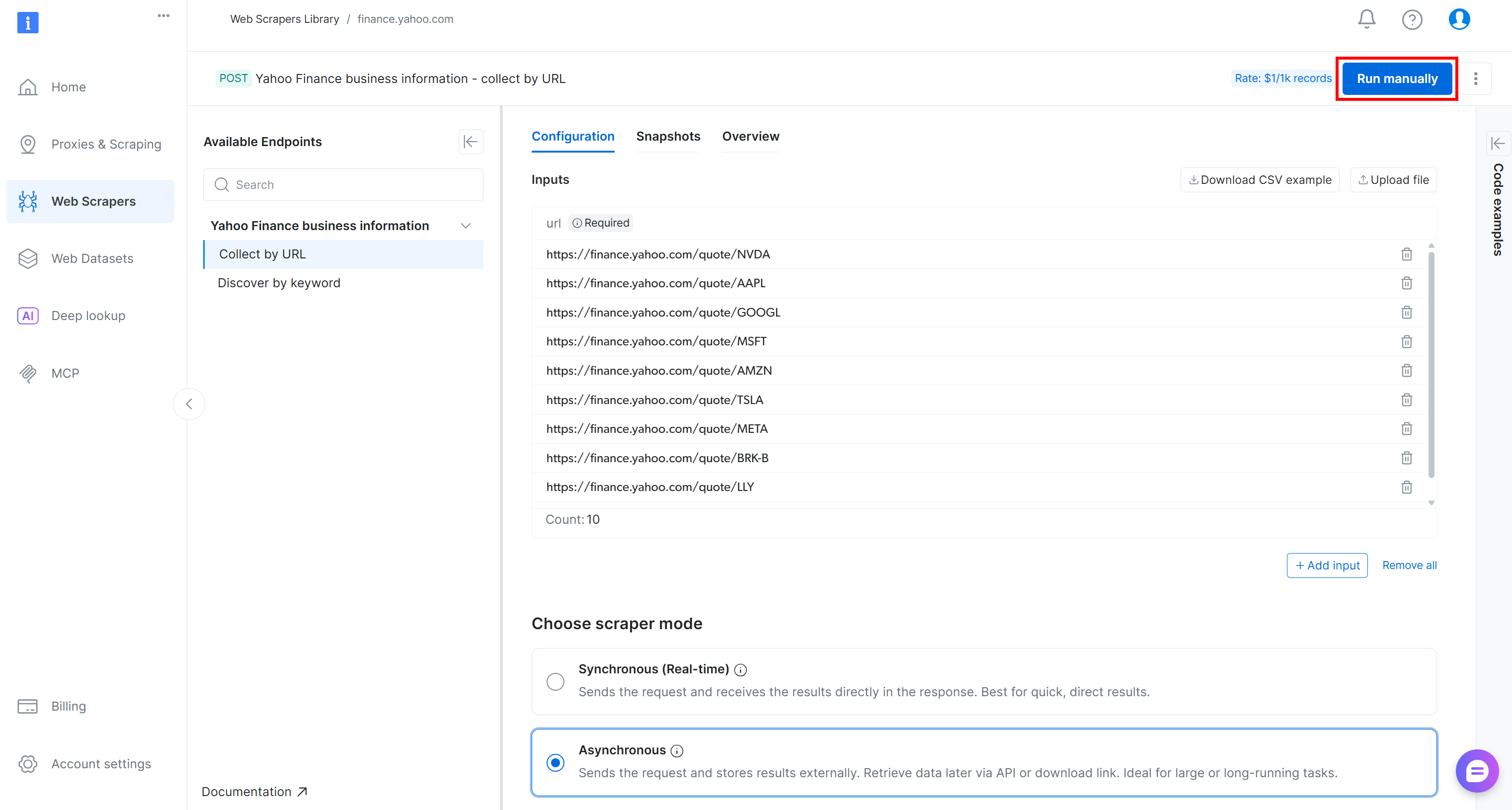
Se enviará la solicitud de la API de scraping y la tarea de scraping se iniciará en la nube. Puede supervisar el estado de la tarea en tiempo real desde el panel de control de Bright Data: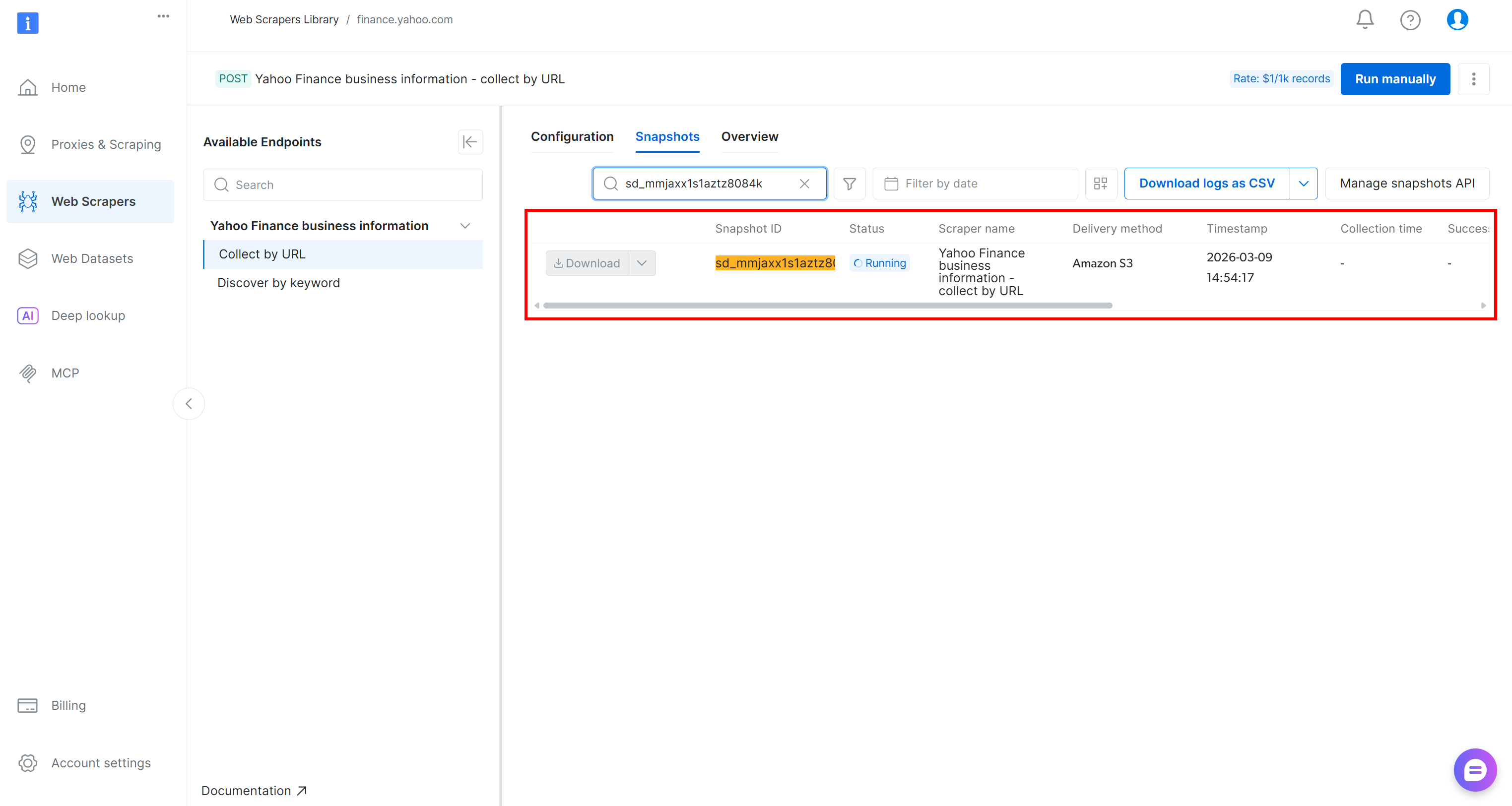
También puede obtener el mismo resultado mediante programación ejecutando uno de los fragmentos de código disponibles en la consola de Bright Data (que se muestra en la columna de la derecha), utilizando su lenguaje de programación preferido:
Cuando el estado de la tarea cambie a «Listo», compruebe su bucket de AWS S3. Debería ver un nuevo archivo llamado stocks.json:
Si abre el archivo stocks.json en su navegador, verá algo como esto: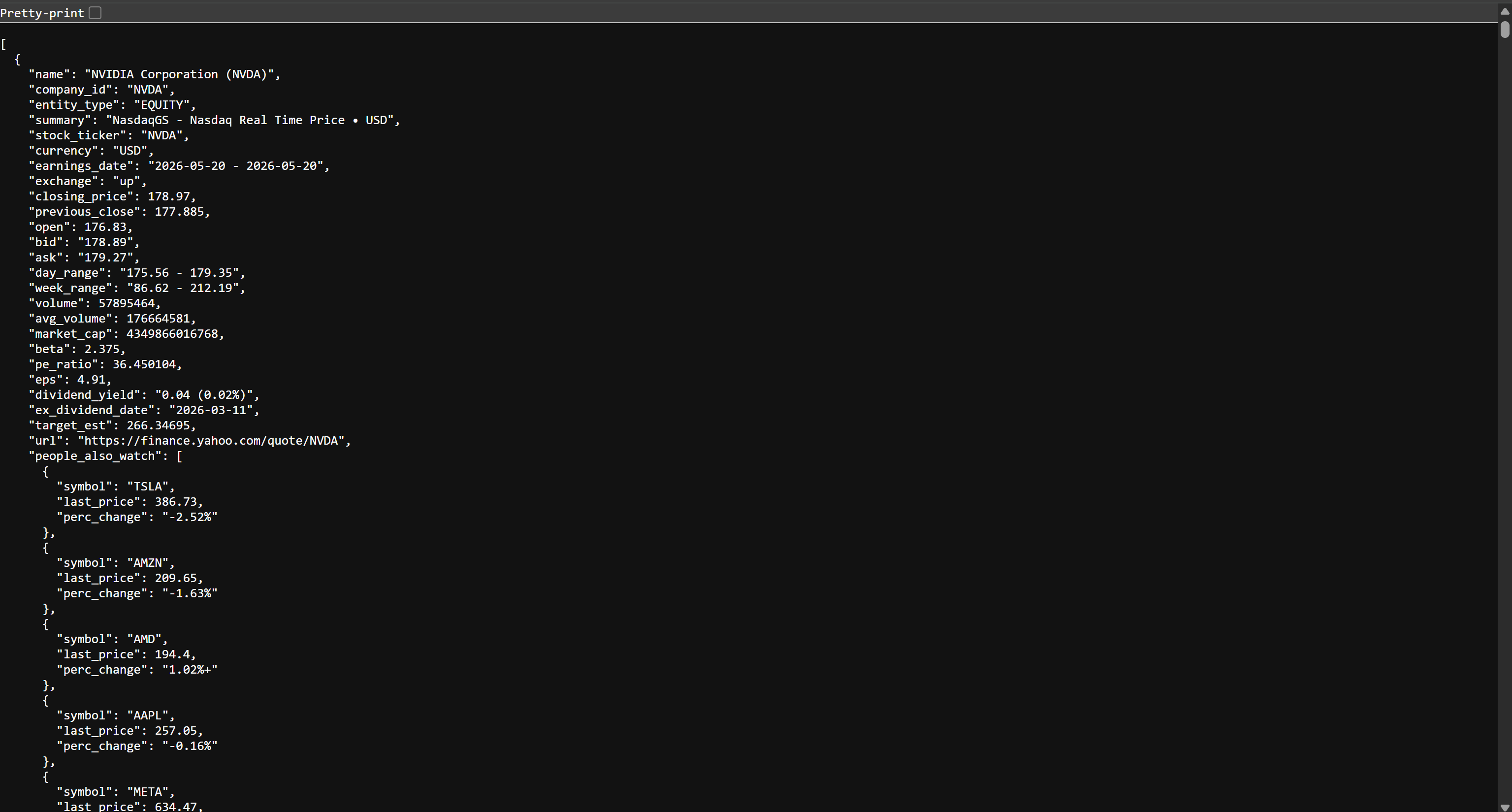
Se trata de los mismos datos bursátiles disponibles en Yahoo Finance, pero estructurados en formato JSON. Esos datos fueron extraídos por la API de Scraping web de Bright Data. ¡Misión cumplida! Ahora dispone de los datos necesarios para crear su canalización ETL de AWS Glue.
Paso n.º 4: Inicialice su trabajo de AWS Glue
Inicie sesión en la consola de AWS y busque la cadena «AWS Glue». Seleccione el servicio para abrir su página principal.
Desde allí, haz clic en el botón «Ir a trabajos ETL» para abrir AWS Glue Studio, la interfaz oficial para crear flujos de trabajo ETL:
Aquí puede inicializar un nuevo trabajo de AWS Glue. Para este tutorial, seleccione la opción «Visual ETL». Se recomienda para crear canalizaciones a través de una interfaz simplificada de arrastrar y soltar.
A continuación, se le dirigirá a un lienzo en blanco, donde podrá definir visualmente su flujo de trabajo ETL de AWS Glue conectando diferentes nodos:
Asigne un nombre descriptivo a su trabajo ETL, como «Trabajo ETL de Bright Data Glue». Una vez hecho esto, estará listo para empezar a crear su canalización ETL.
Paso n.º 5: Crear una función de IAM
Para ejecutar un trabajo de AWS Glue, debe proporcionar una función de IAM para acceder a recursos como Amazon S3 y gestionar AWS Glue. Estos permisos son necesarios para componentes de Glue como trabajos, rastreadores y puntos finales de desarrollo.
Para crear la función directamente desde Glue Studio, vaya al panel «Detalles del trabajo» y haga clic en el botón «Crear nueva función»: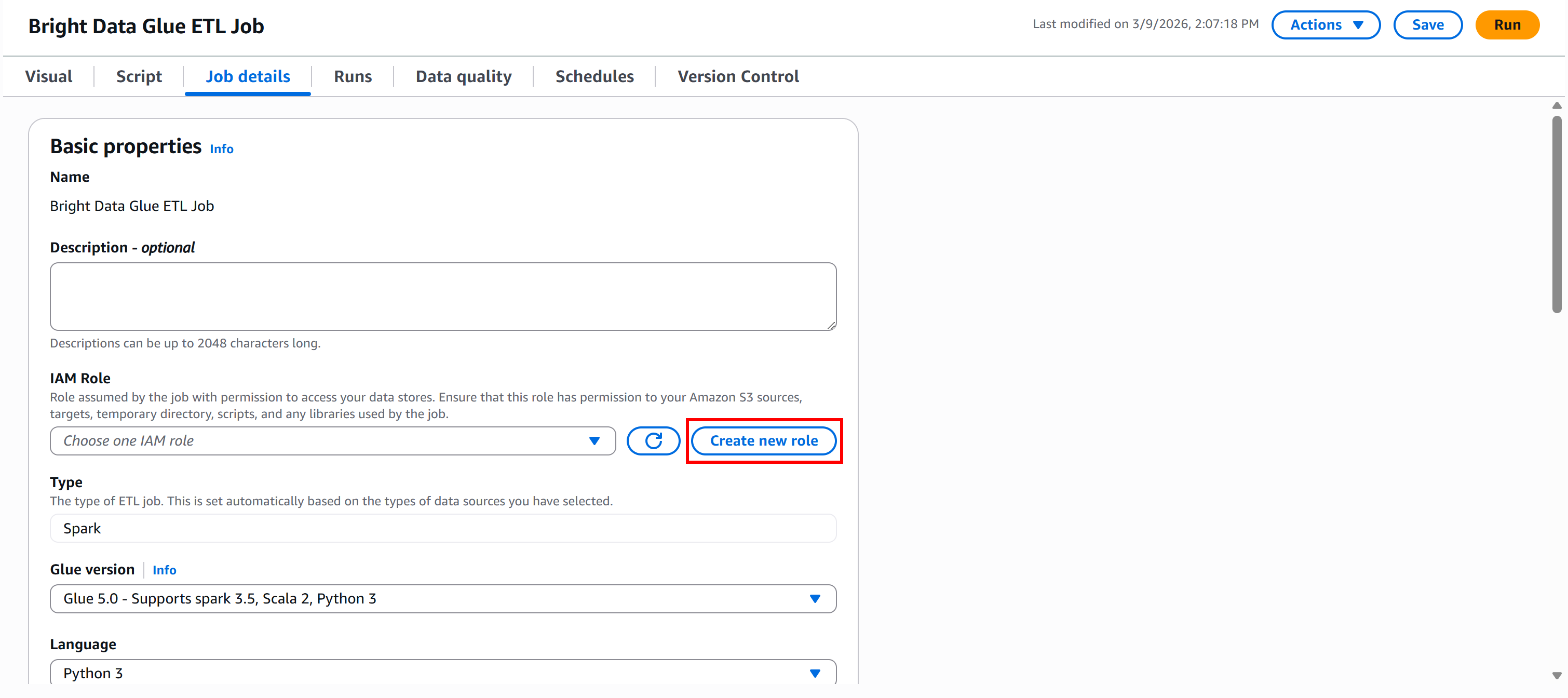
En la sección «Crear rol», asigne a su rol de IAM un nombre descriptivo, como «bd-glue-role»:
De forma predeterminada, AWS adjuntará las dos políticas necesarias:
AWSGlueConsoleFullAccess: proporciona acceso completo a AWS Glue a través de la consola de administración de AWS.AWSGlueServiceRole: política para la función de servicio de AWS Glue, que permite el acceso a servicios relacionados, incluidos EC2, S3 y Cloudwatch Logs.

A continuación, recupere el ARN de su bucket de S3. Lo encontrará en la página «Propiedades» de su bucket en la consola de S3: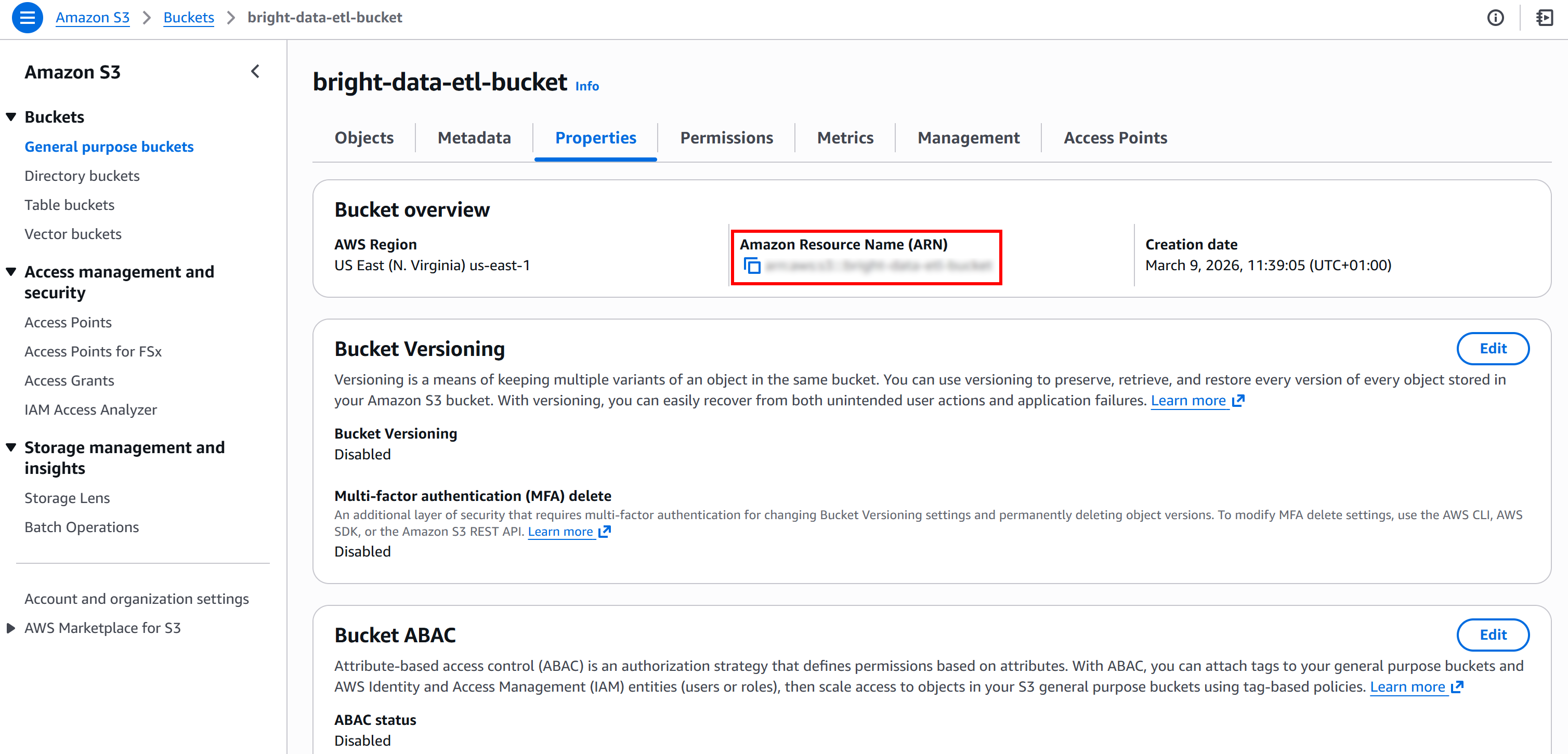
Esa información es la que necesita para anular la política predeterminada proporcionada por AWS Glue. En concreto, pegue el ARN del bucket de S3 en el campo «Recurso» del editor de texto «Política adicional» de la página «Crear función»:
«Recurso»: {
«<SU_ARN_DE_DOBLE_S3>/*»
} 
Por último, haga clic en el botón «Crear rol». Una vez creado el rol, aparecerá automáticamente en la configuración de su trabajo de AWS Glue: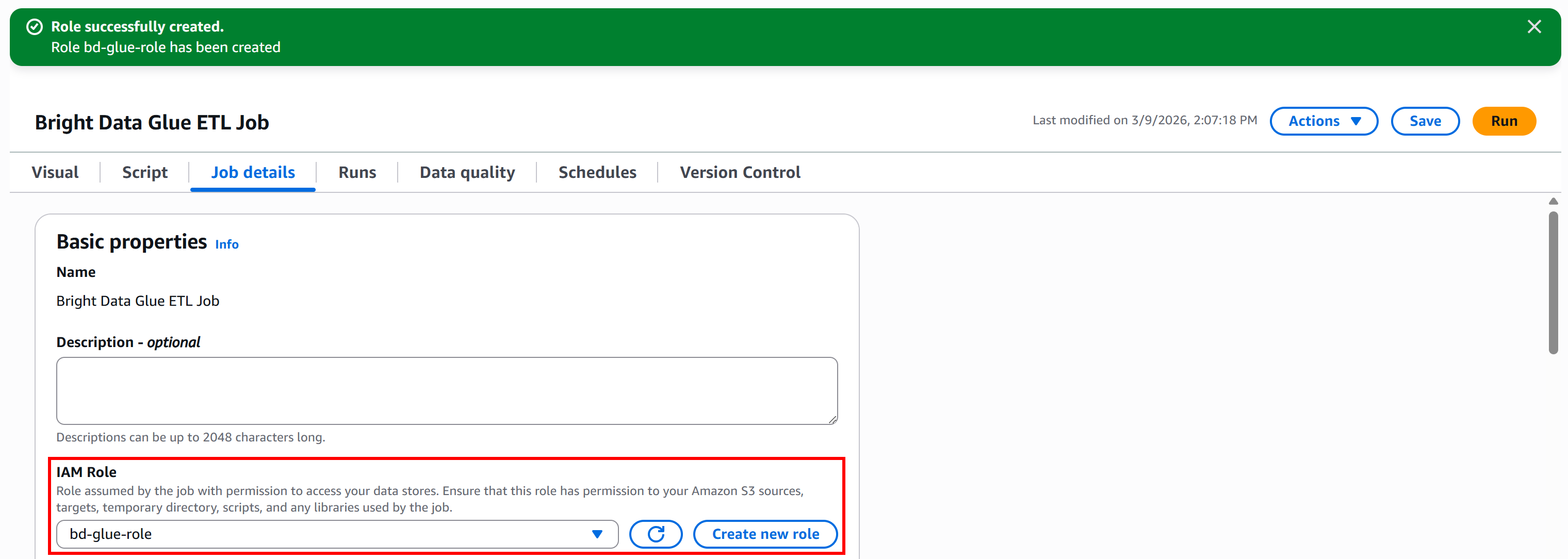
¡Genial! Su trabajo de AWS Glue ahora tiene una función de IAM con los permisos necesarios para acceder a S3 y ejecutar su canalización ETL.
Paso n.º 6: Añada el nodo Extraer (E) a su canalización
La fase de extracción (E) de la canalización comenzó cuando ejecutó el Scraper de Bright Data que recopiló los datos bursátiles y los subió a Amazon S3.
Ahora, el objetivo es conectar su canalización ETL de AWS Glue a esos datos para que puedan procesarse. Para ello, vaya a la pestaña «Fuentes» en el panel «Añadir nodos» y seleccione el nodo «Amazon S3».
Aparecerá un nodo «Fuente de datos – Depósito S3 – Amazon S3» en el lienzo. Haga clic en él y configure la fuente S3: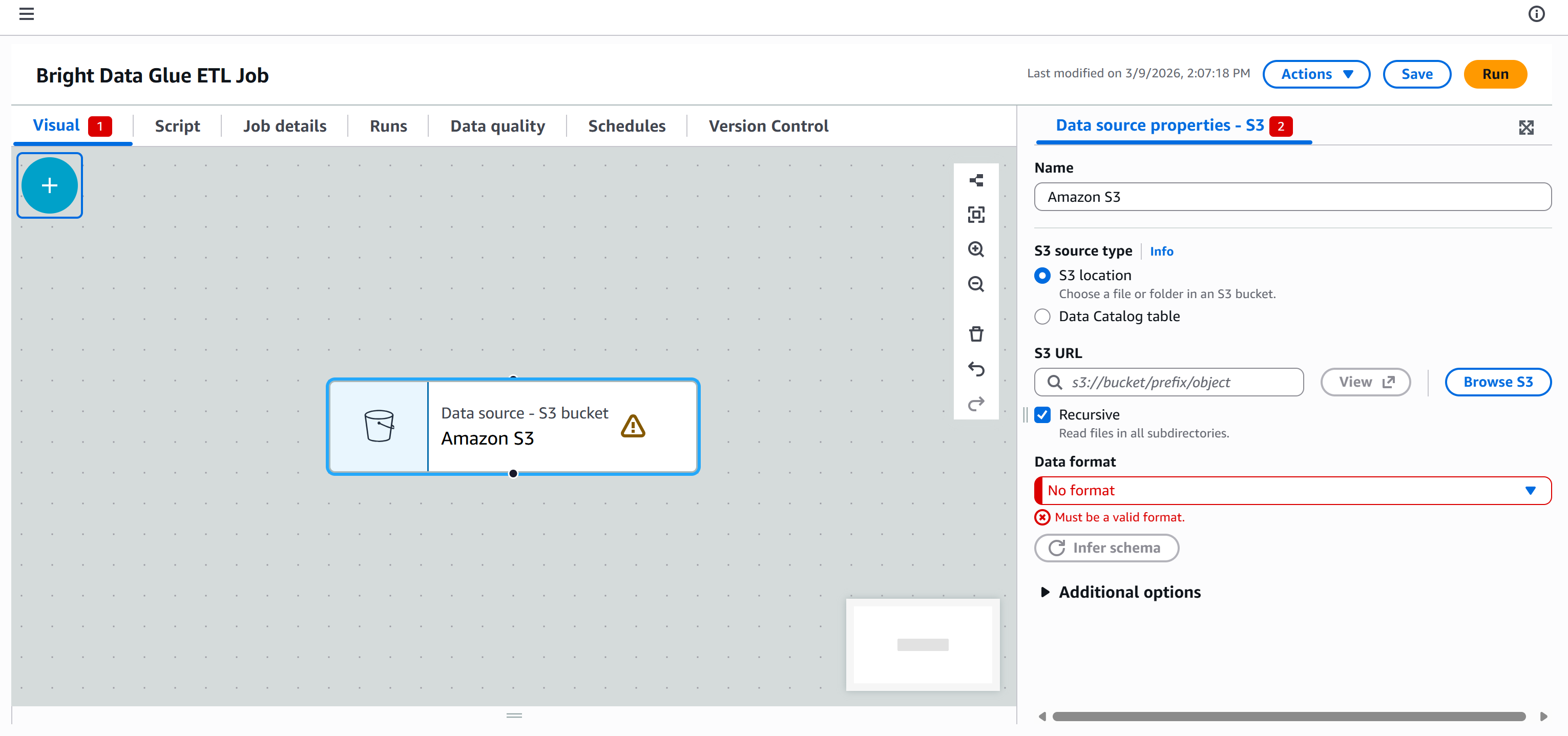
Pulse el botón «Examinar S3» y seleccione su bucket S3 (por ejemplo, bright-data-etl-bucket).
Después de seleccionar el bucket, AWS Glue rellenará el campo «URL de S3» con algo similar a:
s3://bright-data-etl-bucketDe forma predeterminada, AWS Glue intenta leer todos los archivos dentro de la ruta S3 especificada. Como conocemos el nombre exacto del archivo de entrada, actualice el campo «URL de S3» para que apunte directamente a él:
s3://bright-data-etl-bucket/stocks.jsonEsto le indica a AWS Glue que utilice el archivo stocks.json cargado anteriormente, que contiene los datos extraídos con Yahoo Finance Scraper.
A continuación, configure el formato de datos. Dado que el conjunto de datos de entrada es un archivo JSON, seleccione «JSON» como formato de entrada.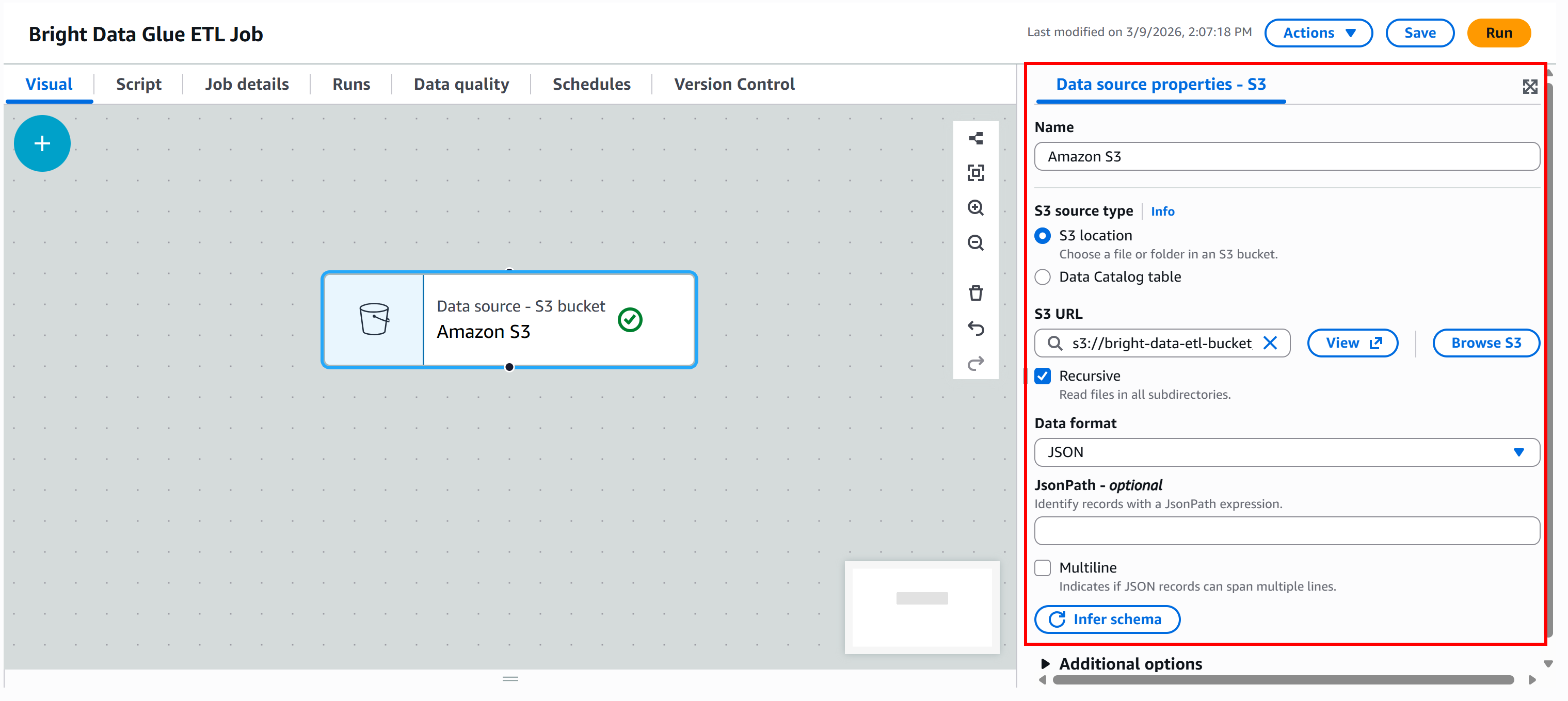
A continuación, haga clic en el botón «Inferir esquema». AWS Glue analizará automáticamente el archivo JSON de entrada y generará el esquema correspondiente.
En la sección «Esquema de salida» del nodo, verá la estructura inferida a partir de los datos JSON:
El esquema inferido coincide con el esquema de datos de salida devuelto por Bright Data Yahoo Finance Scraper. ¡Genial!
Paso n.º 7: definir la lógica de transformación (T)
Como se mencionó anteriormente, este es solo un ejemplo sencillo, por lo que el paso de transformación (T) se mantendrá al mínimo. El objetivo es filtrar los datos de origen mediante una consulta SQL y conservar solo las empresas cuya relación P/E sea inferior a 30.
Para ello, vaya a la pestaña «Transformaciones» y seleccione el nodo «Consulta SQL»:
El nodo se añadirá al lienzo. Haga clic en él y configúrelo de manera que el nodo principal sea «Amazon S3». Esto significa que la salida del nodo Amazon S3 se convierte en la entrada del nodo «SQL Query». En otras palabras, ejecutará una consulta SQL en los datos JSON extraídos.
A continuación, define el nombre de alias para el conjunto de datos de entrada como stocks y añade esta consulta SQL:
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;Esta consulta selecciona los campos stock_ticker y pe_ratio de cada acción extraída, conservando solo aquellas cuya relación P/E sea inferior a 30.
Si se pregunta de dónde provienen estos campos, stock_ticker y pe_ratio son dos de los atributos devueltos por el Scraper de Yahoo Finance de Bright Data (que AWS Glue inferió automáticamente en el paso anterior):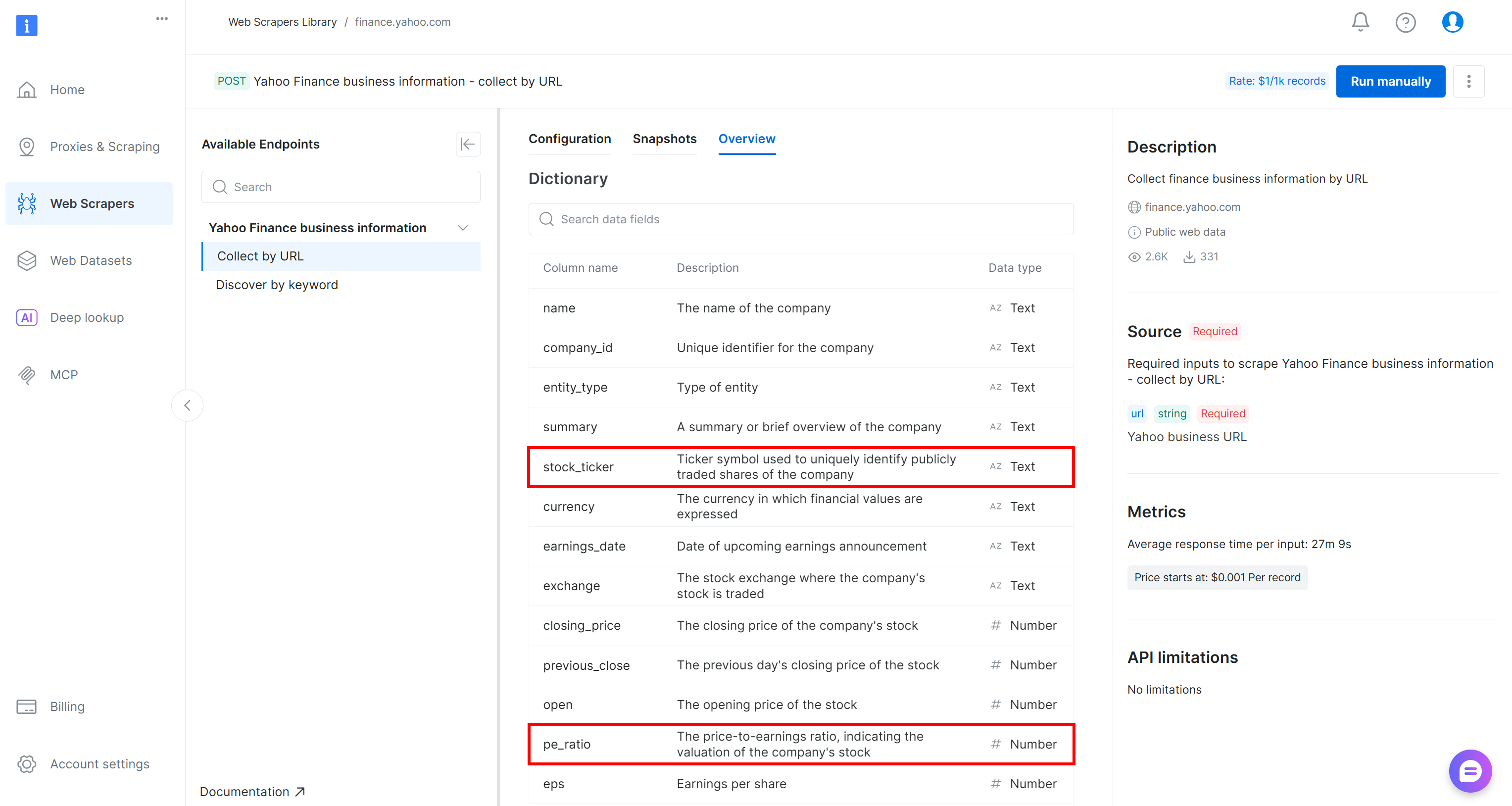
En este punto, su canalización ETL debería tener este aspecto: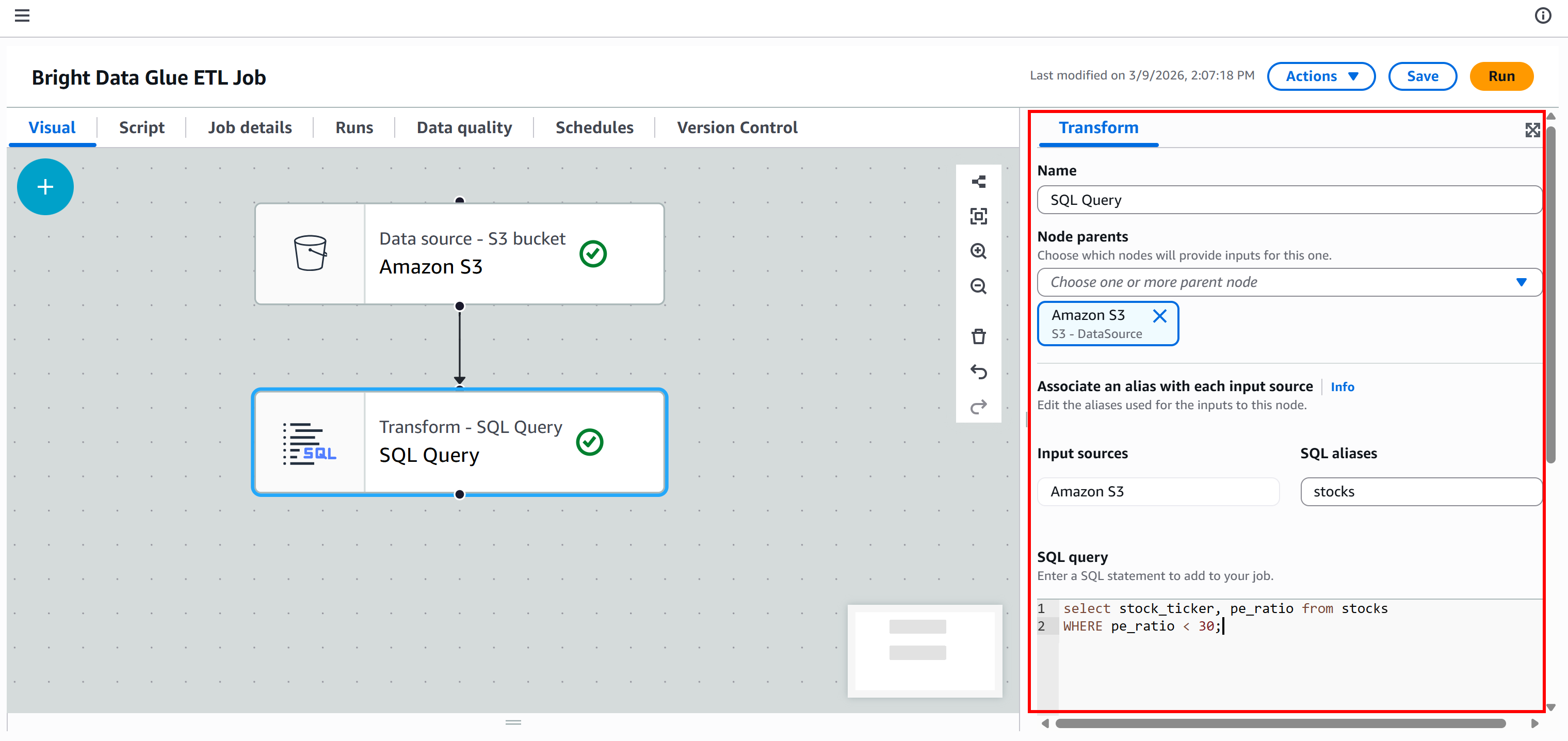
Nota: En los procesos reales, la fase de transformación (T) suele incluir varios pasos. Puede implementarlos añadiendo varios nodos de transformación y conectándolos secuencialmente, o creando varias ramificaciones en el flujo de trabajo.
Paso n.º 8: Conéctese a su bucket S3 en la fase de carga (L)
El resultado de su nodo «SQL Query» son los datos filtrados y transformados. El paso final consiste en almacenar estos datos en su bucket S3 para completar la fase Load (L) de su canalización ETL.
En la pestaña «Destinos», añada otro nodo Amazon S3:
Haga clic en el nuevo nodo para configurarlo. Establezca el nodo principal como su nodo «SQL Query». La salida del nodo «SQL Query» se enviará como entrada al nuevo nodo Amazon S3.
Defina el formato de salida como «JSON» sin compresión. A continuación, especifique la carpeta S3 de salida de destino, por ejemplo:
s3://bright-data-etl-bucket/output/Nota: Asegúrese de sustituir bright-data-etl-bucket por el nombre de su bucket S3 real.
De esta manera, los datos transformados se almacenarán dentro de la carpeta /output.
Mantenga todas las demás opciones como predeterminadas y, a continuación, pulse «Guardar» para actualizar su trabajo ETL de AWS Glue: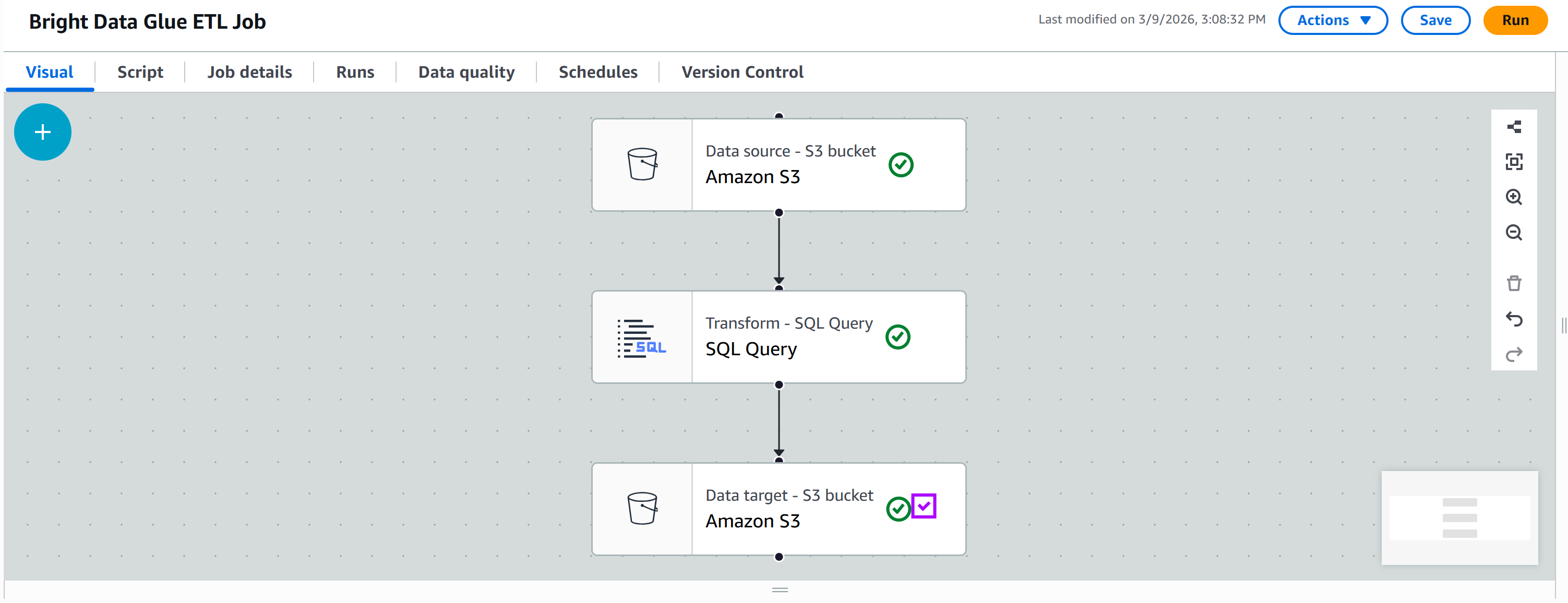
¡Genial! Su canalización ETL ya está completamente configurada y lista para ejecutarse.
Paso n.º 9: Ejecute el proceso y explore los resultados
Pulse el botón «Ejecutar» para iniciar su trabajo de AWS Glue. Debería ver una notificación como esta:
Vaya a la pestaña «Ejecuciones» para supervisar la ejecución de su canalización: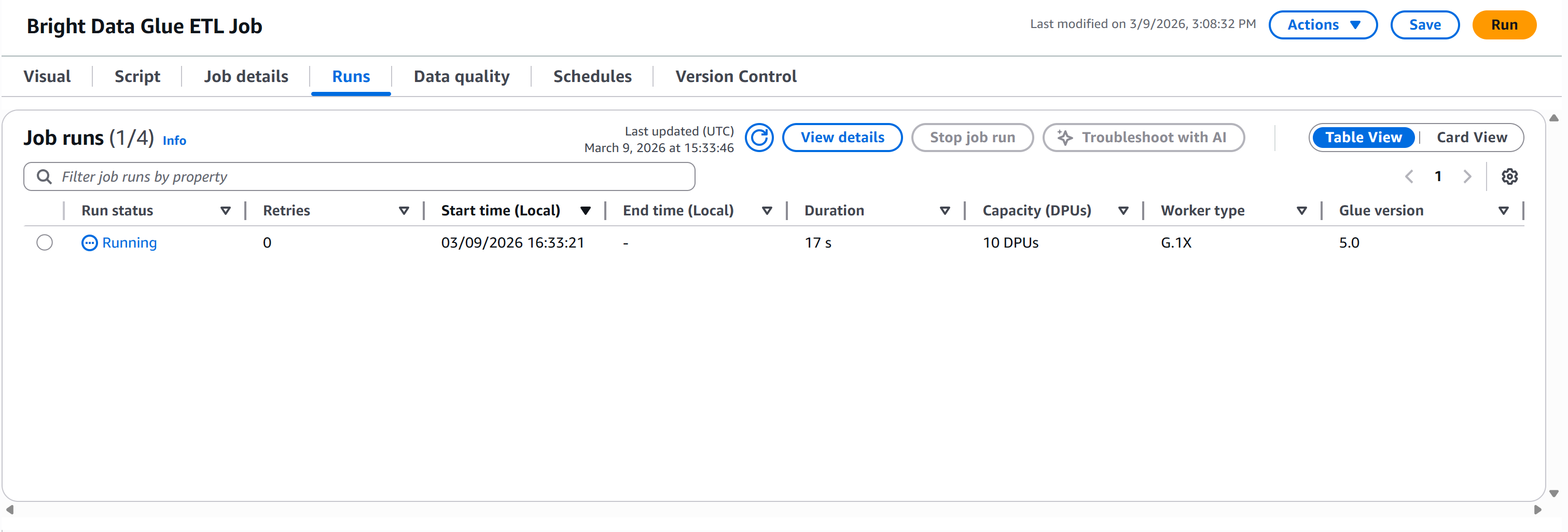
Espere a que el «Estado de ejecución» alcance el estado «Correcto». Esto puede tardar más de un minuto, así que tenga paciencia:
Una vez completado, el archivo de salida aparecerá en la carpeta /output de su bucket S3: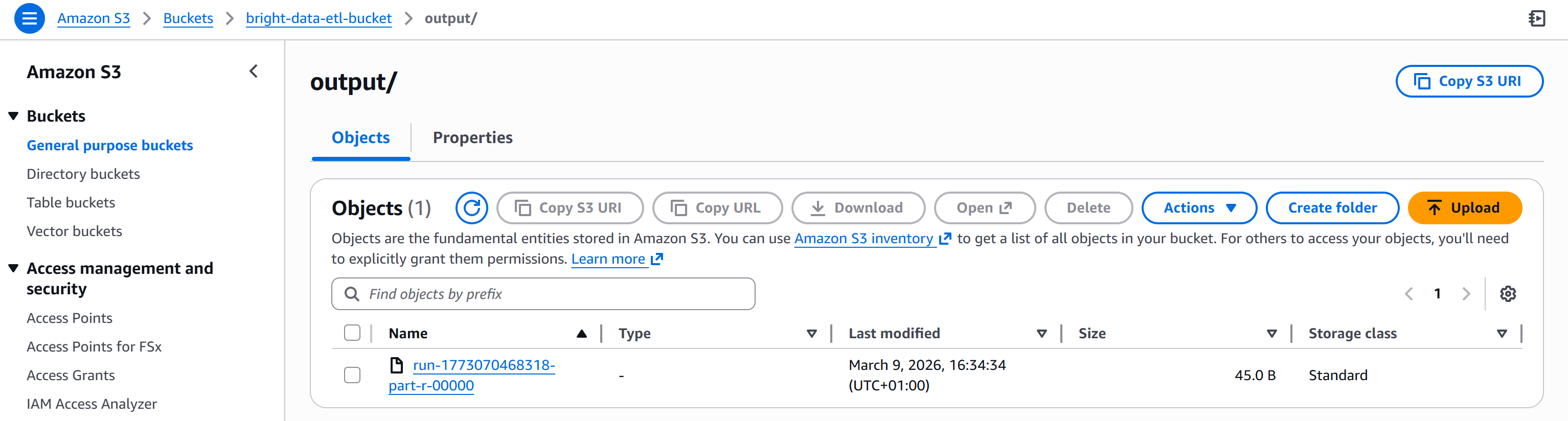
Abra el archivo generado. Verá la lista de acciones con una relación P/E inferior al umbral de su filtro (por ejemplo, menos de 30):
Como puede ver, las acciones resultantes incluyen AMZN, BRK.B, META, MSFT y GOOGL.
¡Et voilà! Acaba de crear un canal ETL de AWS Glue integrado con Bright Data. La fase de extracción aprovecha las API de Scraping web de Bright Data, la fase de transformación filtra los datos con SQL y la fase de carga almacena los resultados de nuevo en S3.
Otras ideas de integración de Bright Data en un trabajo ETL de AWS Glue
No hay duda de que Bright Data puede desempeñar un papel importante en la fase de extracción de un proceso ETL gracias a sus capacidades de recuperación de datos web.
Sin embargo, Bright Data también se puede aprovechar más allá de la extracción, incluso en la fase de transformación para el enriquecimiento, la validación o la verificación de datos. Por ejemplo, podrías:
- Mejorar los perfiles de las empresas: utilice ZoomInfo Scraper para añadir datos firmográficos a los registros extraídos de fuentes web.
- Validar la información de los empleados: integrar los perfiles de LinkedIn para verificar los cargos, los correos electrónicos o los perfiles sociales.
- Recuperar los precios de la competencia o los detalles de los productos: utilice Amazon Scraper o Amazon Reviews Scraper para enriquecer sus conjuntos de datos con información sobre el mercado.
- Añadir datos de SEO o de búsqueda: utilice la API SERP para incluir datos de posicionamiento en motores de búsqueda o información sobre palabras clave como parte de su conjunto de datos transformado, así como para la verificación de datos.
Si se pregunta cómo es posible esta integración, consulte la guía oficial sobre cómo definir transformaciones visuales personalizadas. Todo lo que tiene que hacer es incluir un archivo JSON con las descripciones y un archivo Python que contenga la lógica para la integración de la API de Bright Data.
Conclusión
En este tutorial, ha aprendido qué es AWS Glue y cómo Bright Data puede mejorar sus capacidades a través de una amplia gama de soluciones de Scraping web.
En concreto, ha visto cómo las API de Scraping web de Bright Data pueden dar soporte a las fases de extracción (E) y transformación (T) de un proceso ETL (ya sea recuperando datos sin procesar, enriqueciendo Conjuntos de datos o verificando información).
¡Crea hoy mismo una cuenta gratuita en Bright Data y empieza a explorar nuestras soluciones de datos web!





