

En esta entrada del blog, verás:
- Qué son los datos X, en qué consisten, por qué obtenerlos a través de la API oficial puede no ser lo ideal y los principales obstáculos para extraerlos.
- Cómo el uso de un proveedor de datos de Twitter/X proporciona una solución sólida para la recopilación de datos.
- Los principales factores a evaluar a la hora de seleccionar dichos proveedores.
- Una comparación detallada de los 5 principales proveedores de datos X.
¡Empecemos!
TL;DR: Tabla comparativa de proveedores de datos de Twitter/X
Compare los principales proveedores de datos de Twitter/X de un vistazo en la siguiente tabla:
| Proveedor | Infraestructura | Datos en tiempo real | Datos históricos | Informes/Conjuntos de datos | Integración de IA | Cumplimiento GDPR | Muestra/prueba gratuita | Opción de pago por uso | Precios |
|---|---|---|---|---|---|---|---|---|---|
| Bright Data | De nivel empresarial, basado en la nube, altamente escalable, más de 150 millones de direcciones Proxy, medidas antibots, compatible con MCP, múltiples formatos de entrega | ✅ | ✅ | ✅ | Servidor MCP para flujos de trabajo de IA/LLM, con soporte de integración para más de 70 tecnologías de IA. | ✅ | ❌ | ✅ | 2,50 $/1000 registros (Conjuntos de datos), 1,50 $/1000 registros (Scraper) |
| Tweet Binder | Plataforma de análisis gestionada + infraestructura API gestionada | ✅ | ✅ | ✅ | Compatibilidad con IA Claude | ❌ | ✅ | ✅ | Plataforma: 62,99 $/mes – 564,99 $/mes; API: 0,00305 € – 0,00550 € por tuit/publicación |
| TwitterAPI.io | Infraestructura API basada en la nube | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ✅ | 0,15 $/1000 tuits, 0,18 $/1000 perfiles |
| Apify | Plataforma sin servidor basada en la nube | ✅ | ❌ | ❌ | Integración de actores para procesos de IA | ✅ | ✅ | Depende del actor elegido | Depende del actor elegido |
| Datos impresionantes de Twitter | — (Sin infraestructura) | ❌ | ✅ | ✅ | ❌ | Varía según la licencia del conjunto de datos | — | — | Gratis |
Descripción general de los datos de Twitter/X
Para apreciar plenamente las ventajas de los proveedores de datos X, es útil conocer primero algunos antecedentes sobre los datos de Twitter/X.
Por qué son importantes los datos de X
X.com es el sexto sitio web más visitado del mundo, y X se encuentra entre las 15 plataformas sociales más grandes por número de usuarios. Las estimaciones indican que X recibe alrededor de 3600 millones de visitas al mes. Cabe destacar que el 59,7 % de los usuarios visitan X para leer noticias, lo que la convierte en una de las principales plataformas para seguir la actualidad.
Estas estadísticas ponen de relieve que los datos de Twitter/X son extremadamente valiosos para la investigación, el análisis y la obtención de información empresarial. El acceso a esos datos proporciona información fundamental sobre el comportamiento de los usuarios, su opinión, los temas de actualidad y los patrones de participación.
Como resultado, las empresas y los profesionales confían en los datos de X para respaldar una amplia gama de tareas estratégicas, tales como:
- Identificar temas de tendencia, hashtags populares y contenido de alta participación para informar las campañas de marketing y aumentar el alcance de la audiencia.
- Supervisar la actividad de la competencia, las campañas y las estrategias de interacción de los usuarios para comparar el rendimiento y perfeccionar sus propias tácticas en las redes sociales.
- Analizar el comportamiento, las preferencias y la opinión de la audiencia para crear contenidos más relevantes y mejorar la orientación a los clientes.
- Optimizar el rendimiento de las redes sociales y el alcance del contenido para maximizar la participación, las conversiones y la visibilidad de la marca.
- Prever tendencias y demanda del mercado basándose en la actividad social para tomar decisiones empresariales y de estrategia de producto basadas en datos.
Tipos de datos X
Los datos de Twitter/X se pueden agrupar en estas categorías:
- Tweets/publicaciones: contenido básico compartido por los usuarios, incluyendo texto, medios incrustados, enlaces, marcas de tiempo precisas, códigos de idioma e identificadores para el seguimiento y análisis histórico.
- Perfiles de usuario: metadatos públicos como biografía, ubicación, número de seguidores y seguidos, estado de verificación y fecha de creación de la cuenta, útiles para la puntuación de credibilidad y la segmentación de la audiencia.
- Métricas de interacción: recuento de «me gusta», retuits, respuestas, citas de tuits y visualizaciones que miden la interacción pública, la resonancia social y la opinión sobre el contenido.
- Medios y enlaces: imágenes, vídeos, GIF y URL externas incluidas en las publicaciones, que proporcionan contexto, mejoran el contenido y respaldan el análisis de tendencias entre plataformas.
- Hashtags y temas de tendencia: hashtags y palabras clave regionales o globales con volumen y rango asociados, que ayudan a identificar temas emergentes, contenido viral y tendencias del mercado.
- Hilos de conversación: respuestas públicas y citas de tuits/publicaciones que mapean la estructura de la discusión, lo que permite el seguimiento del sentimiento, el análisis del discurso y la obtención de información sobre la comunidad.
- Menciones y etiquetas: referencias a usuarios en tuits/publicaciones o respuestas, que muestran las interacciones públicas y las conexiones entre cuentas.
- Gráficos de seguidores: listas públicas de las cuentas que siguen y a las que siguen, útiles para trazar redes de influencia y grupos de comunidades.
- Datos geoespaciales: ubicaciones etiquetadas por los usuarios o información regional de los perfiles, que permiten obtener información hiperlocal y supervisar las tendencias basadas en la ubicación.
¿Por qué no utilizar directamente la API de X?
X incluye API oficiales que proporcionan acceso programático a publicaciones, usuarios, espacios, listas, tendencias, medios y mucho más. Estas API son útiles para obtener datos de Twitter/X, pero implican estrictas limitaciones que dependen del plan de precios seleccionado:
- Gratis: lee hasta 100 publicaciones/tuits al mes, con un límite de 1 solicitud cada 15 minutos.
- Básico (200 $ al mes): lectura de hasta 15 000 publicaciones/tuits al mes, con un límite de 15 solicitudes cada 15 minutos.
- Pro (5000 $ al mes): lectura de hasta 1 000 000 de publicaciones/tuits al mes, con un límite de 900 solicitudes cada 15 minutos.
Como se puede ver, estos planes son caros y tienen cuotas y límites de velocidad restrictivos. Esto limita significativamente la escalabilidad y la capacidad de utilizarlos en proyectos a gran escala.
Además, cuando se depende de las API oficiales, nunca se tiene el control total. X puede restringir el acceso a los puntos finales, modificarlos o cambiar la estructura y el contenido de los datos devueltos (a menudo eliminando campos de datos).
Al comparar las API oficiales con el Scraping web, este último tiende a ofrecer más control, mejor escalabilidad, menores costes y mayor flexibilidad a largo plazo. Por esta razón, el Scraping web es la forma más eficaz de acceder a los datos de X a gran escala.
Los retos del Scraping web de datos X
El scraping de datos X de sus páginas web tampoco es sencillo. La plataforma está protegida por sistemas que requieren una gran capacidad de renderización de JavaScript.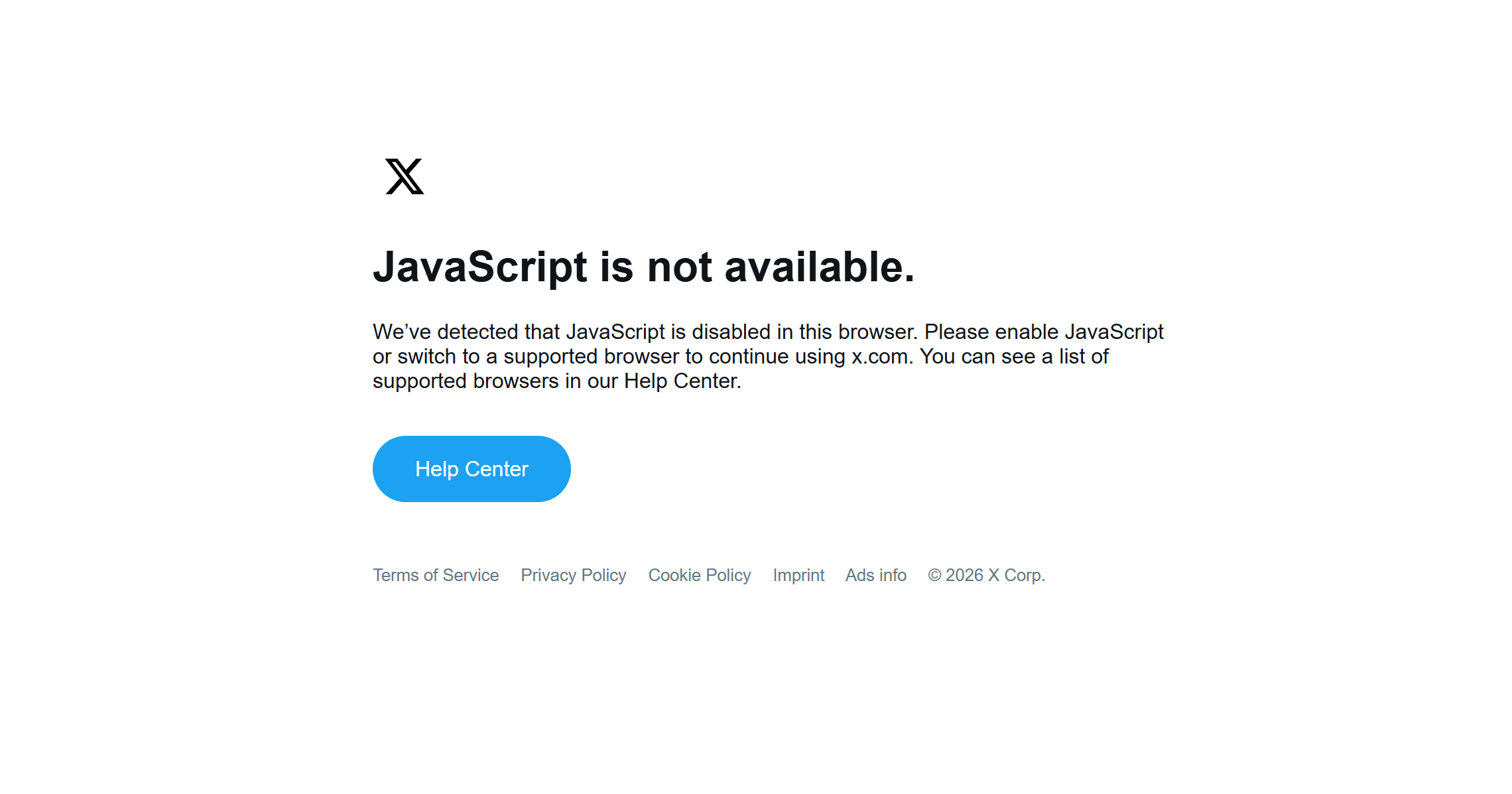
Esto significa que debe utilizar una solución de automatización del navegador e indicarle que visite las páginas X y extraiga los datos. El problema es que el navegador de scraping es difícil de gestionar, difícil de escalar y caro (¡ya que los navegadores consumen mucha RAM!).
Además, si se sigue reutilizando la misma dirección IP, X puede rastrear la sesión y activar barreras de inicio de sesión: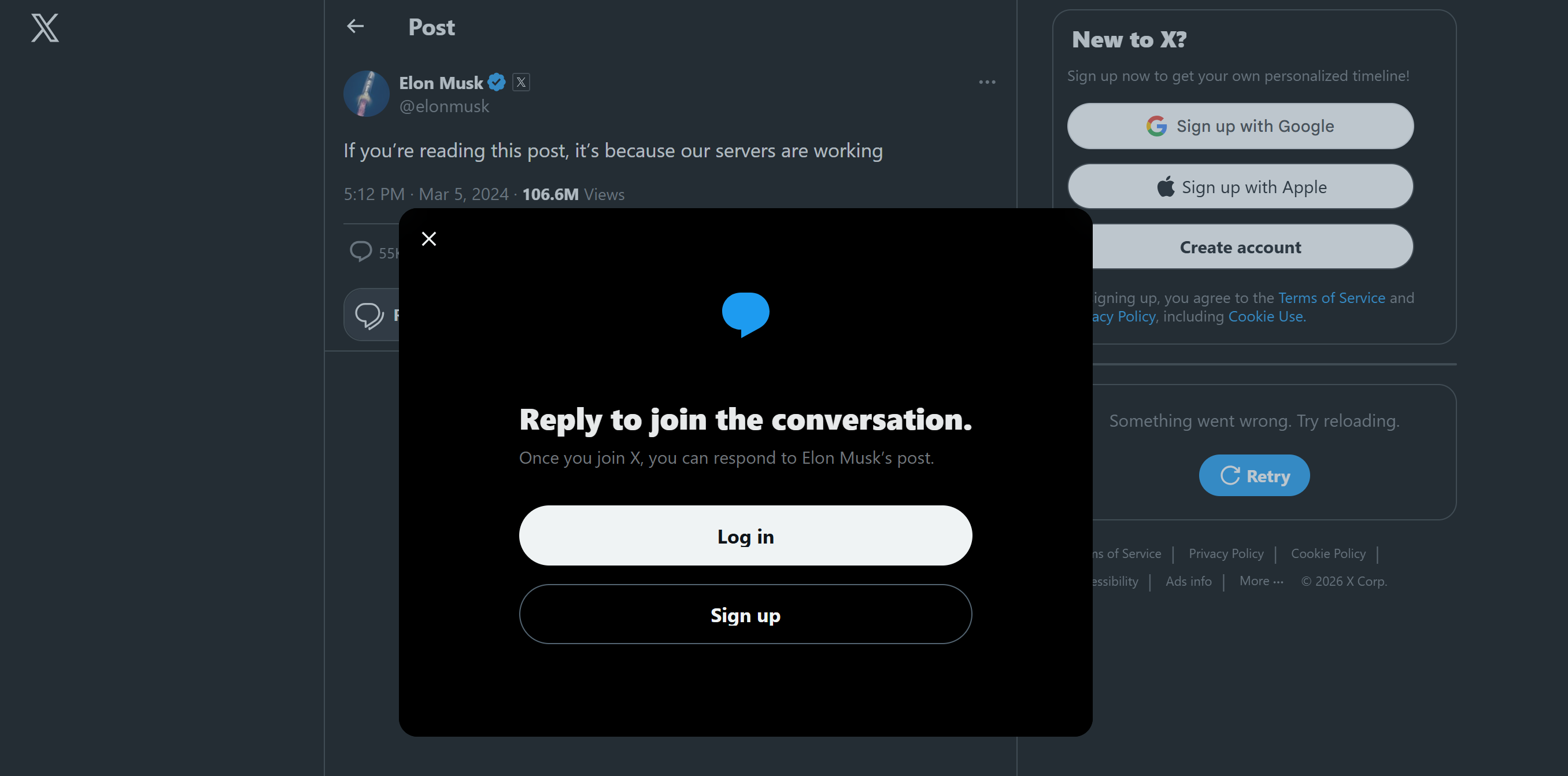
Extraer datos que no son de acceso público, como el contenido protegido por muros de inicio de sesión, puede plantear problemas legales. Para mitigar este riesgo, necesitas un gran grupo de proxies para rotar tu identidad pública con regularidad y evitar el rastreo.
Además, X implementa medidas adicionales contra el scraping, como CAPTCHAs, huellas digitales del navegador, huellas digitales TLS y otras protecciones avanzadas. En conjunto, la extracción programática de datos de X mediante el Scraping web es sin duda un reto.
La solución: adoptar un proveedor de datos de Twitter/X
Los retos y obstáculos descritos anteriormente hacen que la recopilación automatizada de datos de Twitter/X sea bastante compleja. Por esta razón, muchas empresas confían en proveedores de datos especializados para acceder a información fiable sin esfuerzo.
Un proveedor de datos de Twitter/X recopila, limpia, organiza y entrega datos de X. Estos proveedores dan acceso directo a los datos que necesitas, eliminando las preocupaciones sobre las restricciones de la plataforma, los límites de velocidad u otros obstáculos técnicos.
Los datos de Twitter/X se ofrecen normalmente de dos formas principales:
- Conjuntos de datos de Twitter/X: conjuntos de datos recopilados previamente que contienen datos históricos de Twitter, así como datos actualizados periódicamente desde que la plataforma cambió su nombre a X. Son ideales para el análisis de tendencias, la investigación de audiencias o el entrenamiento de modelos de aprendizaje automático que requieren grandes volúmenes de datos históricos.
- Soluciones de scraping de Twitter/X: herramientas que extraen datos actuales directamente de tweets/publicaciones, perfiles de usuario, hashtags, resultados de búsqueda y otras páginas públicas. El Scraping web es ideal para casos de uso que requieren información actualizada, como el seguimiento de temas de tendencia, la supervisión de la competencia o el seguimiento de la interacción en directo.
Para obtener una visión precisa del panorama de X, la mayoría de las organizaciones combinan Conjuntos de datos históricos con soluciones de scraping para obtener tanto información a largo plazo como actualizaciones en tiempo real.
Criterios para seleccionar y comparar los mejores proveedores de datos X
En Internet se pueden encontrar diversos proveedores de datos que cubren los datos de Twitter/X. Algunos se centran únicamente en Conjuntos de datos históricos, otros proporcionan Scrapers web para la recuperación de datos en tiempo real y otros están más orientados a las plataformas de análisis.
Con todas estas opciones (¡y la confusión resultante!), no es fácil identificar los mejores proveedores de datos X. Por eso, debes compararlos utilizando un conjunto de criterios coherentes, como por ejemplo:
- Amplitud de los datos: los tipos de datos de Twitter/X disponibles, como tuits/publicaciones, perfiles de usuario, métricas de interacción, hashtags, tendencias y mucho más.
- Actualidad de los datos: si el proveedor ofrece Conjuntos de datos históricos, datos en tiempo real a través de soluciones de scraping o una combinación de ambos.
- Infraestructura: la escalabilidad, el tiempo de actividad, la fiabilidad y las tasas de éxito generales del proveedor para entregar datos de forma coherente.
- Requisitos técnicos: las habilidades, herramientas y opciones de integración necesarias para acceder a los datos y trabajar con ellos.
- Cumplimiento GDPR: Adhesión al RGPD, la CCPA y otras normativas pertinentes en materia de privacidad y seguridad de los datos.
- Precios: el modelo de precios del proveedor, los planes de suscripción y la disponibilidad de pruebas gratuitas o Conjuntos de datos de muestra para evaluar la calidad antes de comprometerse.
Los 5 mejores proveedores de datos de Twitter/X
Descubramos los 5 mejores proveedores de datos de Twitter/X, cuidadosamente seleccionados, clasificados y evaluados en función de los criterios presentados anteriormente.
1. Bright Data
Bright Data comenzó como proveedor de Proxies y ha evolucionado hasta convertirse en una empresa líder en soluciones de Scraping web y datos. Entre los principales proveedores de datos de Twitter/X, destaca por su infraestructura de nivel empresarial, altamente escalable y preparada para la IA.
En lo que respecta a los datos de Twitter, Bright Data ofrece tres soluciones complementarias:
- Conjuntos de datos de Twitter: datos de Twitter precargados y seleccionados, disponibles en múltiples formatos, incluidos JSON, CSV y Parquet. Los conjuntos de datos se limpian, validan y actualizan continuamente, con precios flexibles basados en registros. Abarcan tuits, retuits, respuestas, me gusta, hashtags, fechas de publicación, enlaces a medios y perfiles completos de usuarios, junto con muchos otros campos de datos. Con más de 22,8 millones de registros disponibles, estos conjuntos de datos son ideales para plataformas de análisis, herramientas de BI y ingestión de LLM.
- Twitter Scraper: una solución para la extracción de datos a gran escala bajo demanda. Le ayuda a recopilar datos públicos actuales de Twitter/X, incluyendo tweets, retweets, hilos de conversación, hashtags, imágenes, vídeos, listas de seguidores/seguidos, ubicaciones y mucho más. El Scraper gestiona automáticamente las medidas anti-bot y es accesible a través de una API para la automatización y la integración, o a través de una interfaz sin código para usuarios sin conocimientos técnicos.
- Herramienta Twitter MCP Server: una herramienta especializada que expone los datos de Twitter/X directamente a los agentes de IA y a los flujos de trabajo impulsados por LLM a través del Web MCP de Bright Data. Esto permite consultar, analizar y consumir los datos de Twitter en aplicaciones de IA, procesos de automatización y flujos de trabajo de ML.
Estos productos están diseñados para respaldar tanto la investigación histórica como la inteligencia en tiempo real.
Nota: Todas las soluciones de datos de Twitter/X se basan en la sólida infraestructura de Bright Data, que ofrece un tiempo de actividad del 99,99 % y una tasa de éxito del 99,99 %. La fiabilidad está respaldada por una red global de Proxies de más de 150 millones de IP y tecnologías avanzadas antibots.
En conjunto, estas ofertas posicionan a Bright Data como el proveedor de datos X más amplio, escalable y preparado para la IA del mercado.
🥇 Ideal para: análisis X de nivel empresarial e integraciones de agentes de IA.
Amplitud de datos:
- Acceso a tweets y perfiles de usuario.
- Analice el contenido, los hashtags, las menciones, los «me gusta», los retuits, las respuestas y las fechas de publicación para descubrir las tendencias de interacción y los temas populares.
- Explora los perfiles de los usuarios con información sobre biografías, estado de verificación, imágenes de perfil, enlaces, fechas de incorporación, tamaño de la red, ubicaciones y métricas de actividad.
Actualización de los datos:
- Extracción de datos en tiempo real a través de Twitter Scraper (API + sin código).
- Datos históricos disponibles bajo demanda.
- Conjuntos de datos con opciones de actualización y programación totalmente automatizadas (mensuales, trimestrales o semestrales).
Infraestructura:
- Admite scraping masivo (hasta 5000 URL por solicitud).
- Resolución de CAPTCHA, rotación de IP, rotación de agentes de usuario, encabezados personalizados y otros mecanismos para evitar el bloqueo.
- Herramienta de scraping de Twitter/X disponible a través de MCP, que permite que los agentes de IA y los flujos de trabajo basados en LLM utilicen directamente los tweets y perfiles extraídos.
- Alta fiabilidad y escalabilidad con más de 150 millones de IP Proxy que cubren 195 países.
- Entrega flexible de conjuntos de datos en múltiples formatos (JSON, NDJSON, CSV, etc.) con compresión Gzip opcional.
- Los métodos de validación integrados garantizan datos precisos, estructurados y fiables.
- Compatible con aplicaciones de IA y flujos de trabajo de enriquecimiento de CRM.
- Capacidad para buscar en terabytes de datos históricos, incluido el contenido de Twitter, a través de la API de Archive.
- 99,99 % de tiempo de actividad y 99,99 % de tasa de éxito.
- Asistencia global 24/7 con un equipo dedicado de profesionales de datos.
Requisitos técnicos:
- Scraper sin código para acceso plug-and-play directamente a través de la plataforma web de Bright Data.
- El Scraper basado en API permite la automatización, la programación y la integración en los canales de datos existentes.
- Los datos se pueden entregar directamente al almacenamiento preferido (Amazon S3, Google Cloud, Snowflake, Azure, SFTP y otros).
- Se requieren conocimientos técnicos mínimos para el rastreo estándar.
- Se necesitan conocimientos de integración de API para flujos de trabajo avanzados.
Cumplimiento normativo:
- Totalmente conforme con el RGPD, la CCPA y otras normativas de privacidad.
- Los datos se obtienen de forma ética únicamente de fuentes disponibles públicamente.
- Certificado para ISO 27001, SOC 2 Tipo II, CSA STAR Nivel 1 y otras prácticas de seguridad.
Precios:
- Se ofrece una prueba gratuita de las herramientas de scraping + Conjuntos de datos de muestra disponibles sin coste alguno.
- A partir de 2,50 $ por cada 1000 registros para Conjuntos de datos de Twitter.
- A partir de 1,50 $ por cada 1000 registros para datos recién extraídos a través del Twitter Scraper.
2. Tweet Binder
Tweet Binder es un servicio de análisis web centrado en X. En concreto, permite supervisar hashtags, palabras clave, menciones y actividad de los usuarios para campañas y eventos en Twitter/X. La plataforma proporciona datos tanto actuales como históricos. El acceso a la API permite la integración en paneles de control y canalizaciones personalizados para la recuperación, el análisis y la generación de informes de datos escalables.
🥇 Ideal para: análisis de hashtags y supervisión de eventos.
Amplitud de datos:
- Tweets/publicaciones públicos filtrados por hashtags, palabras clave, usuarios y cashtags.
- Métricas de interacción, como «me gusta», alcance, impresiones, evolución de seguidores y rendimiento de hashtags.
Actualización de los datos:
- Datos en tiempo real para el seguimiento de hashtags y eventos en directo.
- Datos históricos disponibles para intervalos de fechas personalizados a través de informes.
Infraestructura:
- Plataforma de análisis gestionada con paneles de control y generación de informes alojados.
- Acceso a la API para crear paneles de control personalizados y recuperar estadísticas agregadas de Twitter/X.
Requisitos técnicos:
- Baja barrera técnica para utilizar paneles de control, generar informes e integrarse con IA Claude.
- Se requieren conocimientos técnicos para conectarse a las API e integrarlas en los canales de datos de Twitter/X.
Cumplimiento:
- Plataforma de análisis compatible con Twitter/X.
Precios:
- Prueba gratuita con informes limitados (hasta 200 publicaciones de los últimos 7 días).
- Planes de suscripción a la plataforma:
- Starter: 62,99 $ al mes o 250,00 $ si se factura anualmente (50 000 publicaciones/tuits).
- Avanzado: 564,99 $ al mes o 2275,00 $ si se factura anualmente (saldo de 500 000 publicaciones/tuits).
- Ilimitado: precios personalizados para empresas.
- Precios de API basados en el volumen:
- Hasta 100 000 publicaciones: 0,00550 € por publicación.
- Hasta 500 000 publicaciones: 0,00540 € por publicación.
- Hasta 1 000 000 de publicaciones: 0,00528 € por publicación.
- Hasta 5 000 000 de publicaciones: 0,00429 € por publicación.
- Hasta 10 000 000 de publicaciones: 0,00305 € por publicación.
3. TwitterAPI.io
TwitterAPI.io es un proveedor de API externo para datos públicos de Twitter/X. En concreto, expone puntos finales REST y WebSocket para recuperar tuits/publicaciones y perfiles de usuario. Esa interfaz API te da acceso tanto a datos en tiempo real como históricos, con una infraestructura escalable capaz de gestionar grandes volúmenes de solicitudes.
🥇 Ideal para: Sustituir las integraciones oficiales de la API de X gracias a sus capacidades de lectura y escritura.
Amplitud de datos:
- Tweets/publicaciones y perfiles de usuario.
Actualización de los datos:
- Flujos de datos en tiempo real.
- Ofrece acceso a datos históricos.
Infraestructura:
- Infraestructura API con un acuerdo de nivel de servicio (SLA) del 99,99 % de tiempo de actividad para empresas.
- CDN global con servidores en más de 12 regiones para una baja latencia.
- Autoescalado para picos de tráfico.
- Admite más de 1000 solicitudes por segundo.
Requisitos técnicos:
- Se requieren conocimientos sobre el funcionamiento de los puntos finales de las API REST y WebSocket para la integración.
- Incluye documentación Swagger, una colección Postman y fragmentos de código listos para pegar que facilitan la integración.
Cumplimiento normativo:
- Cumple con la norma ISO 27001.
Precios:
- Prueba gratuita con 0,10 $ en créditos.
- Modelo de pago por uso: 0,15 $ por cada 1000 tuits, 0,18 $ por cada 1000 perfiles.
4. Apify
Apify es una plataforma de automatización y Scraping web basada en la nube, diseñada para la extracción y el procesamiento a gran escala de datos web. Su componente básico, un Actor, es un programa independiente que realiza una tarea específica (por ejemplo, extraer datos de un sitio web o automatizar un flujo de trabajo). Para Twitter/X, Apify proporciona más de 2000 Actors preconfigurados para recopilar una amplia gama de datos.
🥇 Ideal para: análisis y enriquecimiento de X utilizando datos de otros proveedores.
Amplitud de datos:
- Tweets/publicaciones, incluyendo texto, respuestas, citas y hilos.
- Perfiles de usuario, incluyendo seguidores, seguidos, estado de verificación, ubicación, imagen de perfil, biografía y más.
- Métricas de interacción, como «me gusta», retuits, respuestas, recuento de citas, marcadores y recuento de visitas.
- Hashtags, menciones, listas y resultados de búsqueda.
Actualización de los datos:
- Recopilación de datos actualizados de las páginas de Twitter/X.
Infraestructura:
- Plataforma sin servidor con cientos de Scrapers de Twitter/X listos para usar.
- Medidas antibloqueo integradas y Proxy rotativo.
Requisitos técnicos:
- La integración con Actors y los pipelines personalizados requiere algunos conocimientos técnicos (uso de API, procesamiento de datos, etc.).
- La interfaz de scraping sin código permite una configuración rápida con un mínimo esfuerzo en la aplicación web Apify.
Cumplimiento normativo:
- Totalmente compatible con el RGPD.
- Certificado SOC2 para la seguridad y privacidad de los datos.
Precios:
- Plan gratuito disponible.
- Los costes varían en función del actor de scraping de Twitter/X seleccionado y del uso.
5. Datos impresionantes de Twitter
shaypal5/awesome-twitter-data es un repositorio GitHub abierto con licencia CC0 que recopila Conjuntos de datos públicos de Twitter/X y recursos de investigación relacionados. Proporciona acceso a tweets históricos, datos de usuarios, gráficos sociales y Conjuntos de datos etiquetados a través de enlaces de descarga de terceros.
🥇 Ideal para: Investigación académica y experimentación con IA/ML.
Amplitud de datos:
- Tweets/publicaciones públicos, ID de tweets, perfiles de usuario, gráficos sociales, señales de interacción, datos de geolocalización, datos etiquetados según el sentimiento, anotaciones demográficas y mucho más.
- Incluye tanto conjuntos de datos sin procesar como enlaces seleccionados a recursos académicos, herramientas y artículos.
Actualización de los datos:
- Solo conjuntos de datos históricos, en su mayoría de hace varios años.
Infraestructura:
- Los datos se alojan en plataformas de terceros, por lo que la disponibilidad depende del host del conjunto de datos original, pero generalmente se basa en enlaces de descarga simples.
Requisitos técnicos:
- Se requieren conocimientos de ingeniería de datos e investigación para descargar, preprocesar, agregar, analizar y visualizar los datos.
Cumplimiento:
- Las licencias de los conjuntos de datos varían (por ejemplo, CC0, Apache 2.0, MIT, BSD y otras).
Precio:
- Gratuito y de código abierto.
Conclusión
En esta guía, ha aprendido por qué los datos X son valiosos, los principales tipos de datos disponibles y por qué acceder a ellos directamente a través de la API oficial puede no ser la mejor solución. También ha visto las complejidades que entraña la obtención de estos datos y cómo los proveedores de datos especializados pueden ayudar a superarlas.
Los proveedores de datos de Twitter/X dan acceso a los datos X a través de Conjuntos de datos listos para usar o soluciones de scraping que permiten recopilar datos actualizados bajo demanda. Entre los principales proveedores de datos X, Bright Data destaca gracias a su infraestructura de nivel empresarial.
En lo que respecta a Twitter/X, la amplia oferta de datos de Bright Data incluye:
- Conjuntos de datos de Twitter que contienen más de 22 millones de registros históricos, actualizados periódicamente.
- Un Scraper de Twitter para la recuperación bajo demanda de tweets/publicaciones, perfiles y otros contenidos públicos.
- Herramientas de scraping de Twitter MCP que se integran perfectamente con agentes de IA o flujos de trabajo personalizados.
¡Regístrese hoy mismo en Bright Data para explorar nuestras soluciones de datos de Twitter/X!
Preguntas frecuentes
¿Cómo obtener datos de Twitter/X?
Hay tres formas principales de obtener datos de Twitter/X:
- Conectándose a la API oficial de X: X proporciona API oficiales para acceder a publicaciones, usuarios, espacios, mensajes directos, listas, tendencias, medios y mucho más. Sin embargo, la API tiene límites de velocidad estrictos y restricciones en cuanto al tipo y volumen de datos que se pueden recuperar. Además, la estructura y el contenido que devuelve la API pueden cambiar con el tiempo.
- A través de un Scraper web de X: puede crear su propio Scraper o utilizar un servicio de Scraping web de X ya preparado (como el Scraper de Twitter de Bright Data). Este enfoque le permite recopilar datos actuales directamente de perfiles, tuits, resultados de búsqueda y páginas de hashtags. Algunos proveedores también permiten la integración en agentes de IA a través de MCP o herramientas personalizadas.
- Utilizando conjuntos de datos X recopilados previamente: se trata de conjuntos de datos seleccionados que contienen datos históricos de Twitter y datos X recientes disponibles para su compra a proveedores de datos específicos. Este método es útil para la investigación, el análisis y el aprendizaje automático, ya que evita las complejidades del rastreo y las limitaciones de las API oficiales.
¿Cómo extraer datos de X?
Para recuperar datos de X, siga esta hoja de ruta de scraping:
- El Scraper envía una solicitud a la página X de destino (por ejemplo, perfiles, publicaciones, resultados de búsqueda).
- La página se renderiza utilizando una herramienta de automatización del navegador.
- Aplica la lógica de parseo para recopilar los campos de datos necesarios (por ejemplo, texto, marcas de tiempo, comentarios, estadísticas, imágenes de perfil, etc.).
- Convierte los datos extraídos al formato de salida deseado (por ejemplo, CSV, JSON).
Esta es la teoría, pero en la práctica, el scraping de Twitter/X es mucho más complejo. Esto se debe a las agresivas barreras de inicio de sesión, los exigentes requisitos de renderización de JavaScript y otros mecanismos avanzados contra el scraping.
¿Qué es un conjunto de datos de Twitter/X?
Un conjunto de datos de X es un archivo que contiene una recopilación de datos extraídos de X en formatos estructurados como CSV, JSON o Excel. Los conjuntos de datos de Twitter/X suelen incluir tuits/publicaciones, información del perfil del usuario, métricas de interacción (me gusta, retuits, respuestas), marcas de tiempo, hashtags, archivos adjuntos multimedia y otras métricas relacionadas con la actividad en las redes sociales.




