Apify es una plataforma completa basada en la nube que proporciona herramientas para crear, implementar y ejecutar sus propios programas de automatización o Scrapers. Por el contrario, Bright Data ofrece API listas para usar, servicios de datos gestionados, Conjuntos de datos preparados para IA y Proxy para admitir innumerables integraciones y aplicaciones, lo que proporciona un ecosistema completo de datos web.
¿Cuál es mejor, Bright Data o Apify? ¡Vamos a averiguarlo!
TL;DR: Bright Data vs Apify: tabla comparativa rápida
| Criterios | Bright Data | Apify |
|---|---|---|
| Tipo de solución | Plataforma completa de datos web con API, servicios gestionados, Conjuntos de datos y Proxy | Plataforma completa de automatización y Scraping web |
| Público objetivo | Desarrolladores, analistas, especialistas en marketing, equipos de IA y empresas | Desarrolladores, analistas y empresas |
| Productos | Proxies, Conjuntos de datos, API de Scraping web, API de navegador, Web Unlocker, API SERP, archivo web, MCP, Scraper Studio y mucho más | Miles de actores en múltiples dominios, con la capacidad de crear, implementar y monetizar programas sin servidor |
| Integraciones de API | ✅ | ✅ |
| Experiencia sin código | ✅ | ✅ |
| Herramientas de scraping preintegradas | API listas para usar creadas y mantenidas por un equipo profesional | Actores listos para usar creados y mantenidos principalmente por la comunidad |
| Compatibilidad con proxies | Más de 150 millones de IP en más de 195 países | Proxies residenciales y de centros de datos |
| Gestión antibots | Integrado | Compatible |
| Facilidad de uso | Alta | Alta para los usuarios, pero requiere conocimientos sobre la plataforma para crear e implementar actores. |
| Integraciones | Más de 70 plataformas compatibles, marcos de IA, herramientas de automatización y mucho más | Se integra con n8n, Zapier, Slack, Google Drive y Make |
| Infraestructura | Infraestructura de nivel empresarial con un tiempo de actividad del 99,99 % y fiabilidad gestionada. | Infraestructura basada en la nube |
| Cumplimiento | Cumple con el RGPD y la CPPA | Cumple con el RGPD y la CPPA |
| Modelo de precios | Planes de pago por uso o por suscripción | Suscripción con uso prepagado, luego pago por uso más allá de los créditos |
| Soporte para monetización | ❌ (No diseñado para revender Scrapers) | ✅ (Monetiza actores personalizados a través de la tienda Apify) |
| Soporte MCP | ✅ | ✅ |
| Disponibilidad de conjuntos de datos | ✅ (Miles de millones de registros de más de 200 dominios) | ❌ |
Introducción a Bright Data
Comience esta guía comparativa entre Apify y Bright Data explorando qué es Bright Data y qué ofrece.
¿Qué es Bright Data?
Bright Data comenzó como proveedor de Proxies y se ha convertido en la plataforma de datos web líder del mercado. Te permite recopilar datos web públicos a gran escala, lo que admite una lista muy larga de casos de uso y escenarios.
Bright Data proporciona un conjunto completo de herramientas, que incluye Proxies residenciales, móviles y de centro de datos, API de Scraping web, conjuntos de datos recopilados previamente y una API SERP. La empresa presta servicio a más de 20 000 clientes, ayudándoles a acceder y estructurar datos web para obtener información útil.
Su tecnología simplifica la recopilación de datos al gestionar CAPTCHAs, restricciones geográficas, renderización de JavaScript, límites de velocidad y otras medidas anti-bot. El objetivo final de Bright Data es ayudarle a crear canales de datos web sin complicaciones.
Servicios, productos y características
Bright Data tiene una oferta muy amplia, que abarca numerosos servicios y productos. Los más relevantes son:
- API Web Unlocker: gestiona automáticamente los bloqueos, los CAPTCHA y la rotación de proxies, lo que garantiza una extracción de datos fiable con costes predecibles para los canales de Scraping web.
- API SERP: obtiene resultados en tiempo real de múltiples motores de búsqueda, incluidos Google, Bing, Yandex, DuckDuckGo y otros. Gestiona Proxies, desbloqueos y Parseo para proporcionar datos estructurados para SEO, supervisión o investigación.
- Browser API: ejecuta y escala scripts de Puppeteer, Selenium o Playwright en navegadores alojados. Admite scraping dinámico, proxies automatizados y Resolución de CAPTCHA para sitios complejos.
- API de rastreo: extrae el contenido completo de cualquier sitio web especificando una URL raíz. Los resultados incluyen Markdown, HTML, texto o JSON para facilitar la integración.
- API de Scraping web: recupere datos estructurados de más de 120 dominios con rotación automática de Proxies, evasión de bots y renderización de JavaScript.
- Servicios de proxy: acceda a más de 150 millones de IPs residenciales, móviles, de ISP y de centros de datos en más de 195 países, lo que permite operaciones de scraping web fiables y escalables.
- Scraper Studio: inicie rápidamente scrapers basados en IA, mantenga la estabilidad con funciones de autorreparación y gestione Proxies y navegadores sin intervención manual.
- Conjuntos de datos: acceda a datos estructurados y validados de más de 200 sitios web que abarcan miles de millones de registros. Compatible con el RGPD y disponible sin necesidad de mantener Scrapers.
- API de archivo web: recupere contenido HTML histórico y actual del vasto archivo de Bright Data, que se actualiza continuamente con más de 1 PB añadido cada semana.
- Servicios de adquisición de datos gestionados: servicio totalmente gestionado que ofrece información estructurada sin esfuerzo de desarrollo, mantenimiento ni gestión de infraestructura.
- Deep Lookup: motor de búsqueda basado en IA para empresas, profesionales y entidades. Admite consultas complejas y devuelve resultados estructurados de alta calidad para su uso inmediato.
- Inteligencia minorista: obtenga información armonizada sobre el comercio electrónico en tiempo real, incluidos datos de productos, precios y recomendaciones impulsadas por IA en múltiples sitios web.
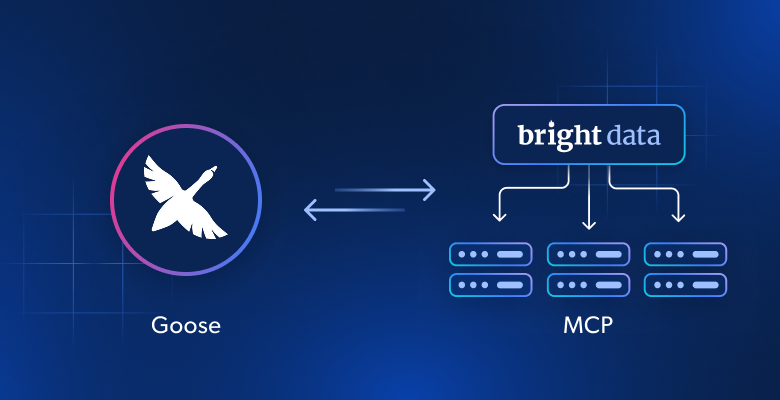
- Web MCP: proporciona modelos de IA, agentes y aplicaciones con acceso web a través de MCP (Model Context Protocol). Admite la búsqueda, extracción, navegación e interacción automatizadas a gran escala.
Como puede imaginar, este amplio conjunto de soluciones abre la puerta a innumerables posibilidades. La lista de funciones compatibles es extensa, pero algunas de las más importantes son:
- Experiencia de scraping sin código: recopilación de datos simplificada y bajo demanda para usuarios de todos los niveles. Mantenga la flexibilidad y la escala sin tener que gestionar la infraestructura ni los Proxies.
- Panel de control web: interfaz centralizada para la gestión de productos, la configuración, la supervisión y el control del flujo de trabajo.
- CAPTCHA Solver: resuelve reCAPTCHA, hCaptcha, px_captcha, SimpleCaptcha, GeeTest CAPTCHA y otros retos por usted. Permite el Scraping web desbloqueado y la automatización.
- Recursos y aprendizaje: seminarios web, documentación, tutoriales y vídeos para incorporarse rápidamente y empezar a trabajar.
- Administrador de proxies: interfaz personalizable para gestionar, rotar y optimizar el tráfico de proxies con total visibilidad y control.
- Cumplimiento y seguridad: cumple con el RGPD, la CPPA y otras normativas de privacidad, al tiempo que sigue las mejores prácticas éticas y los estándares de seguridad de máximo nivel.
Precios
Independientemente de la solución de scraping o Proxy de Bright Data que elija, los planes de precios siguen una estructura coherente.
Existe una opción de pago por uso, en la que la unidad de cobro es el número de resultados (por ejemplo, API Web Unlocker y API Scraping web) o los GB de Tráfico (por ejemplo, API Browser y Proxy). Además, hay planes basados en suscripción para usuarios con necesidades continuas o predecibles. Esto significa que puede elegir una suscripción o empezar inmediatamente con el pago por uso, sin comprometerse con un plan recurrente.
En concreto, los precios de Bright Data para sus principales soluciones son los siguientes:
| Pago por uso | Equipo pequeño | Equipo grande | Empresa | |
|---|---|---|---|---|
| Proxies residenciales | 4 $/GB | 141 GB – 3,50 $/GB (499 $/mes) | 332 GB – 3,00 $/GB (999 $/mes) | 798 GB – 2,50 $/GB (1999 $/mes) |
| API del navegador | 8 $/GB | 71 GB – 7 $/GB (499 $/mes) | 166 GB – 6 $/GB (999 $/mes) | 399 GB – 5 $/GB (1999 $/mes) |
| API SERP | 1,50 $/1000 resultados | 380 000 resultados: 1,30 $/1000 (499 $/mes) | 900 000 resultados: 1,10 $/1000 (999 $/mes) | 2 millones de resultados: 1,00 $/1000 (1999 $/mes) |
| API de rastreo | 1,50 $/1000 resultados | 380 000 resultados: 1,30 $/1000 (499 $/mes) | 900 000 resultados: 1,10 $/1000 (999 $/mes) | 2 millones de resultados: 1,00 $/1000 (1999 $/mes) |
| API Web Unlocker | 1,50 $/1000 resultados | 380 000 resultados: 1,30 $/1000 (499 $/mes) | 900 000 resultados: 1,10 $/1000 (999 $/mes) | 2 millones de resultados: 1,00 $/1000 (1999 $/mes) |
| API de Scraping web | 1,50 $/1000 registros | 510 000 registros: 0,98 $/1000 (499 $/mes) | 1 millón de registros: 0,83 $/1000 (999 $/mes) | 2,5 millones de registros: 0,75 $/1000 (1999 $/mes) |
Tenga en cuenta que solo se le cobrarán las solicitudes que se hayan completado con éxito y que hay una prueba gratuita disponible para todos los productos.
Nota: los Conjuntos de datos tienen un precio basado en los registros, mientras que los servicios gestionados siguen un coste mensual fijo.
Descripción general de Apify
Continuemos con este artículo comparativo entre Bright Data y Apify profundizando en Apify.
¿Qué es Apify?
Apify es una plataforma basada en la nube para el Scraping web y la automatización. Permite a los desarrolladores crear e implementar programas sin servidor llamados Actors. En el ecosistema de Apify, un Actor es un programa en la nube sin servidor que automatiza tareas, principalmente para la extracción de datos web, el rastreo web o los flujos de trabajo de IA.
Los desarrolladores pueden integrar estos Actors a través de API u otros métodos. De manera similar, los usuarios sin conocimientos técnicos pueden seleccionar Actors del mercado público (conocido como Apify Store), probarlos y gestionarlos directamente en la plataforma a través de una experiencia visual sin código.
Servicios, productos y características
Los dos servicios principales de Apify son:
- Crear, compartir y monetizar Actors: crear tareas de automatización (centradas en el Scraping web), ejecutarlas en la plataforma en la nube de Apify y, opcionalmente, publicarlas en la Apify Store para ganar dinero.
- Apify Store: acceda a un mercado con miles de Actors listos para usar en diversos escenarios de recopilación de datos y automatización. Gestione estos Actors directamente desde la consola de Apify, la plataforma web disponible tras iniciar sesión.
Para dar soporte a estas dos soluciones, Apify ofrece varias características:
- Integración completa de la API: controle programáticamente la plataforma y gestione las ejecuciones de los actores a través de la API de Apify.
- SDK y bibliotecas de código abierto: simplifique la creación de actores utilizando SDK y bibliotecas oficiales como Crawlee.
- Almacenamiento de datos en la nube integrado: almacene y exporte los resultados del scraping y los archivos en formatos como JSON, CSV, XML, Excel, HTML y RSS.
- Integración de proxy integrada: rote automáticamente las solicitudes entre IPs residenciales y de centros de datos para evitar bloqueos y limitaciones de velocidad.
- Programación personalizada: automatice la ejecución de los actores en momentos específicos o a intervalos recurrentes.
- Integraciones de terceros: conecta los flujos de trabajo de Apify a aplicaciones como Slack, Zapier o Google Drive para crear canales de datos automatizados y productivos.
- CLI de Apify: inicialice, gestione y ejecute Actors directamente desde su terminal.
- Servidor MCP: permite a los LLM descubrir y ejecutar actores de Apify en flujos de trabajo y agentes de IA.
Precios
Los precios de Apify dependen de si utiliza Actors preconstruidos o si crea los suyos propios.
Para los desarrolladores de la comunidad que utilizan la plataforma Apify para crear y publicar Actors, existe un plan especial para creadores. Cuesta 1 $ al mes y te da acceso a 500 $ de uso de la plataforma durante los primeros seis meses.
Para los usuarios que deseen aprovechar los Actors, hay varios planes de suscripción. Cada plan ofrece un conjunto específico de funciones y una cantidad de uso prepagada, que se puede gastar en la tienda Apify o en ejecutar sus propios Actors. Cualquier uso que supere esa cantidad se cobra mediante un modelo de pago por uso, lo que garantiza que sus tareas continúen ejecutándose sin interrupciones.
A continuación se resume el precio de Apify:
| Plan | Precio mensual (facturado mensualmente/anualmente) | Uso prepagado para la tienda Apify / Ejecuciones de Actors | Precio CU / 1 GB de RAM por hora | Nivel de asistencia |
|---|---|---|---|---|
| Gratis | 0 $ / 0 | 5 | 0,30 | Soporte de la comunidad |
| Starter | 29 $ / 26 | 29 | 0,30 | Asistencia por chat |
| Escala | 199 $ / 179 | 199 | 0,25 | Asistencia prioritaria por chat |
| Negocios | 999 $ / 899 | 999 | 0,20 | Gerente de cuenta |
La idea es que primero consumas tu uso prepagado según uno de los posibles modelos de precios de Actor:
- Pago por evento: cargos basados en acciones específicas activadas por el Actor (por ejemplo, inicio, recuperación de resultados).
- Pago por resultado: cargos basados en el número de resultados producidos.
- Alquiler: cuota mensual fija por el acceso continuo a un Actor después de un periodo de prueba.
Una vez agotado el uso prepagado, el consumo adicional se factura según el uso real utilizando el precio por unidad de cómputo de su plan.
Además del uso básico, Apify vende complementos flexibles para ampliar las capacidades y adaptar la plataforma a sus necesidades:
| Complemento | Precio | Descripción |
|---|---|---|
| Ejecuciones simultáneas | 5 $/ejecución | Ejecute varias instancias de Actor simultáneamente. |
| RAM del actor | 2 $/GB | Asigne más memoria para tareas más pesadas. |
| Proxy de centro de datos | Desde 0,6 $/IP | Accede a proxies adicionales para el scraping web. |
| Soporte prioritario | 100 | Tiempos de respuesta más rápidos y asistencia dedicada. |
| Formación personalizada | 150 $/hora | Orientación para optimizar Actors y flujos de trabajo. |
Bright Data vs Apify: principales diferencias
Ahora que ya sabes qué son Bright Data y Apify, estás listo para profundizar en sus aspectos diferenciadores.
Enfoque del scraping y la automatización
Bright Data y Apify comparten algunos puntos en común, ya que ambos admiten el Scraping web y los flujos de trabajo de automatización. Estos se ofrecen a través de herramientas de autoservicio o servicios gestionados. Dicho esto, las dos plataformas difieren significativamente en la forma en que se ofrecen estas experiencias.
Apify se estructura en torno a proporcionar a los usuarios las herramientas para crear, implementar y ejecutar sus propios programas de automatización en la nube. Bright Data ofrece capacidades similares, pero con un enfoque diferente. Sus herramientas están diseñadas para integrarse en scripts personalizados, pipelines, flujos de trabajo y sistemas existentes. En cambio, la implementación y la orquestación se dejan en tus manos para una mayor flexibilidad.
Además, la oferta de Bright Data es considerablemente más amplia. Esto se debe al acceso directo a servidores Proxy, Conjuntos de datos pre-recogidos, una API de archivo web y productos especializados de datos e IA, como se ha presentado anteriormente.
Al comparar las dos soluciones, tiene sentido empezar por lo que tienen en común. En este caso, se trata del acceso a una amplia gama de soluciones de scraping ya preparadas para muchos dominios de destino.
En Apify, esas opciones de scraping se ofrecen como Actors y se pueden utilizar a través de una interfaz sin código directamente en la plataforma o mediante llamadas a la API. Del mismo modo, Bright Data proporciona una gran colección de API de Scraping web, que se pueden utilizar en integraciones, código personalizado o directamente desde el panel de control a través de una interfaz basada en código.
La diferencia fundamental radica en la propiedad y la fiabilidad. La mayoría de los Actores de Apify son creados y mantenidos por la comunidad, lo que significa que la calidad del soporte, el mantenimiento y la confianza a largo plazo pueden variar. Por el contrario, todas las soluciones de Bright Data son desarrolladas y mantenidas por un equipo de expertos, se ejecutan en una infraestructura de nivel empresarial y están respaldadas por una de las redes de proxies más grandes del mundo, lo que garantiza un mayor rendimiento, estabilidad y soporte.
Ecosistema e integraciones
Apify está disponible como nodo en plataformas de automatización populares como n8n, Zapier y Make, y también se puede integrar directamente a través de API. Además, la plataforma incluye un sistema de integración incorporado que le permite conectar Actors con herramientas como Google Drive, Slack, Gmail y otras para crear flujos de trabajo de automatización sencillos y listos para usar.
Todas las soluciones de Bright Data son API-first y están disponibles en una amplia gama de plataformas de automatización e IA, incluyendo n8n, Zapier, Make y muchas otras. Además, Bright Data admite oficialmente más de 70 integraciones, incluidos los principales marcos de IA y agentes, como LangChain, LlamaIndex, CrewAI, Dify, Haystack, IBM Watsonx, Microsoft Copilot, AWS Bedrock AI Agents, Cursor, RooCode y cualquier otra solución que admita integraciones de clientes MCP.
La infraestructura de Proxy de Bright Data también se puede integrar en una amplia variedad de herramientas, como Phantombuster, GoLogin y Kameleo. Por ejemplo, los Proxies y la API del navegador de Bright Data se pueden utilizar directamente en el propio Apify. Por lo tanto, las dos soluciones son complementarias.
Tanto Apify como Bright Data son compatibles con un servidor MCP local/remoto. El servidor MCP de Apify tiene más de 700 estrellas en GitHub y permite a los usuarios buscar e integrar Apify Actors para realizar tareas específicas. El Web MCP de Bright Data tiene más de 1900 estrellas en GitHub y es compatible con más de 60 herramientas para la búsqueda web, el Scraping web, la interacción web y mucho más.
Infraestructura y escalabilidad
Bright Data se basa en una infraestructura de nivel empresarial que le permite escalar sin problemas a medida que crecen sus necesidades. Puede empezar con requisitos pequeños como desarrollador individual y luego escalar para satisfacer las demandas de proyectos de grandes empresas.
El tiempo de actividad y la tasa de éxito de las soluciones de scraping de Bright Data son del 99,99 %. El respaldo de una de las redes de proxies más grandes del mundo proporciona a la plataforma una escalabilidad prácticamente ilimitada. Esto es válido tanto para la recopilación de datos a nivel mundial como para tareas más específicas en países o regiones concretos.
Todos los usuarios cuentan con el respaldo de un SLA estándar, y los clientes empresariales pueden solicitar SLA personalizados. Además, las alertas y notificaciones integradas le ayudan a supervisar los cambios, como las actualizaciones del esquema de salida de una API de Scraping web, para reducir el riesgo de problemas inesperados.
Por el contrario, Apify está diseñado principalmente para desarrolladores que desean implementar sus programas de automatización en la nube y permitir que otros los ejecuten. Esto se evidencia en su modelo de pago por uso, que cobra en función de las unidades de cómputo y el uso de RAM a lo largo del tiempo. Después de todo, ese enfoque es común en la mayoría de las soluciones de alojamiento y despliegue en la nube.
Como resultado, Apify es una plataforma de nivel inferior centrada en los desarrolladores, mientras que Bright Data abstrae los detalles de la infraestructura, lo que permite a los usuarios centrarse por completo en la ejecución de tareas de scraping y recopilación de datos.
Experiencia de incorporación y curva de aprendizaje
Bright Data ofrece una experiencia de incorporación muy sencilla. Te registras, generas tu clave API, seleccionas los productos a los que deseas acceder con solo unos clics desde el panel de control y ya estás listo para integrarlos a través de la API.
Las integraciones se explican detalladamente en la documentación, con el apoyo de ejemplos de código claros en cURL, Node.js, Python, Java, Ruby y muchos otros lenguajes, junto con miles de guías y tutoriales disponibles en el blog oficial.
También puede probar las integraciones de la API directamente desde el panel de control, supervisar el uso, ver los registros, realizar un seguimiento de los costes, explorar resultados anteriores, gestionar permisos y mucho más. Alternativamente, las soluciones de Scraping web se pueden probar y utilizar directamente dentro de la plataforma a través de una experiencia sin código.
Apify también ofrece una configuración inicial sencilla. Te registras, buscas el actor que deseas utilizar y lo ejecutas directamente desde el panel de control para obtener resultados, o lo integras a través de la API. Sin embargo, las funciones más avanzadas, como la programación y las integraciones, requieren un mayor conocimiento de la plataforma y un cierto tiempo de adaptación.
A continuación, implementar su propio programa automatizado en la nube de Apify es una experiencia completamente diferente. Esto se debe a que los Actores de Apify deben seguir las directrices y los requisitos estructurales específicos de la plataforma. La experiencia de desarrollo general puede ser muy diferente a la de simplemente crear un bot de Scraping web ligero que se conecte a API o Proxies de Scraping, como se suele hacer con Bright Data.
Precios
Tanto Bright Data como Apify ofrecen planes de suscripción y precios de pago por uso. La principal diferencia es la estructura de la opción de pago por uso.
Con Apify, el uso de pago por uso solo está disponible como complemento de uno de los planes de suscripción. Por el contrario, Bright Data también ofrece el pago por uso como opción independiente, lo que le permite acceder a servicios premium sin comprometerse a una suscripción mensual. Esto es ideal para desarrolladores individuales y pequeñas empresas que no quieren comprometerse con un plan de pago recurrente.
Es cierto que Apify ofrece un plan gratuito, pero Bright Data ofrece una generosa prueba gratuita. Además, algunas de sus herramientas más útiles se pueden utilizar de forma totalmente gratuita a través del nivel gratuito de Web MCP, lo que abre la puerta a integraciones de IA totalmente gratuitas.
En lo que respecta a los costes, es difícil hacer una comparación directa, ya que los precios de Apify dependen en gran medida del actor específico que se utilice. Algunos actores pueden ser más baratos que Bright Data, mientras que otros pueden ser más caros. En comparación, los precios de Bright Data son transparentes y muy predecibles, lo que facilita la estimación y el control del gasto a lo largo del tiempo.
Casos de uso
Tanto Bright Data como Apify admiten un conjunto de casos de uso muy similar. Estos se centran principalmente en el Scraping web general, los flujos de trabajo automatizados y las integraciones de IA en múltiples sectores.
En concreto, los casos de uso más interesantes de Bright Data y Apify son:
- Scraping web: desbloquee sitios web protegidos por CAPTCHAs, sistemas antibots, límites de velocidad y prohibiciones de IP para extraer datos de forma fiable e interactuar con cualquier sitio web público.
- Flujos de trabajo automatizados e integraciones de IA: integrar con herramientas de automatización como n8n, Make, Zapier o marcos y plataformas de IA para dar soporte a los procesos de automatización.
- Seguimiento SERP: realice un seguimiento de los resultados de los motores de búsqueda en múltiples motores para la supervisión del SEO, la investigación de palabras clave, el análisis de la competencia y el seguimiento de anuncios.
- Inteligencia de comercio electrónico y minorista: realice un seguimiento de la competencia a nivel mundial utilizando datos de comercio electrónico en tiempo real para analizar productos, precios, disponibilidad y opinión de los consumidores.
- Supervisión de datos de viajes: recopile datos sobre precios, disponibilidad y competidores para vuelos, hoteles y servicios de viaje en diferentes regiones.
- Estudio de mercado: comprenda a su público objetivo, supervise las tendencias y respalde las decisiones sobre productos y estrategias utilizando datos web a gran escala.
- Análisis inmobiliario: supervise los anuncios, las tendencias de precios y los movimientos del mercado para optimizar las inversiones y anticiparse a los cambios antes que la competencia.
- Protección de marca: busque vendedores no autorizados, detecte productos falsificados, elimine cuentas falsas y haga cumplir el cumplimiento de la marca y la marca comercial en toda la web.
- Supervisión de las redes sociales para marketing: realizar un seguimiento de las tendencias, analizar la participación y supervisar la presencia de la marca en las plataformas sociales para optimizar las campañas de marketing.
- Recopilación de datos sanitarios: comparar los precios de los medicamentos y los dispositivos médicos, supervisar la disponibilidad y respaldar los casos de uso en el ámbito de la asistencia sanitaria y la salud pública.
- Seguridad de los datos y supervisión de amenazas: supervise los activos expuestos, el malware, las señales de fraude y las actividades sospechosas en la web pública.
- Pruebas y supervisión de sitios web: identifique problemas de experiencia de usuario, problemas de rendimiento y errores funcionales mediante capturas de pantalla e interacciones web automatizadas.
- Generación de clientes potenciales: recopile, valide y enriquezca los datos de clientes potenciales y empresas para mejorar la precisión del CRM y el rendimiento de las ventas.
- Inteligencia en materia de seguros: comparar las pólizas de la competencia, realizar el monitoreo de precios, mejorar los modelos de suscripción y detectar posibles fraudes.
- Aplicaciones y agentes de IA: proporcionar a los agentes de IA datos web estructurados y actualizados para la búsqueda, la extracción, la navegación y los flujos de trabajo basados en RAG.
- Investigación financiera y de inversiones: agregar datos financieros, realizar un seguimiento de empresas y carteras, y obtener información útil para la toma de decisiones de inversión.
Gracias a su amplia cartera de servicios, Bright Data también ofrece un soporte más profundo o especializado para lo siguiente:
- Datos para IA y ML: acceda a conjuntos de datos específicos de cada dominio o cree canalizaciones personalizadas para el entrenamiento de modelos de IA/ML, el ajuste fino y la ingesta continua de datos a escala.
- Verificación de anuncios: verifique anuncios, supervise campañas, detecte fraudes y recopile información publicitaria para mejorar la segmentación y el retorno de la inversión.
- Datos e IA para el impacto social: proporcione a ONG, universidades e instituciones públicas acceso gratuito a la infraestructura de datos web para proyectos de investigación y de interés público.
Cuándo utilizar Bright Data frente a Apify
La forma más fácil de concluir la comparación entre Apify y Bright Data es ofrecerte información clara y práctica sobre cuándo elegir una solución en lugar de la otra.
Elija Bright Data cuando:
- Tenga necesidades de Scraping web o automatización.
- Busca un amplio conjunto de productos para la adquisición de datos web, incluyendo API de scraping, Conjuntos de datos y Proxy.
- Desea una configuración rápida e intuitiva y una fácil incorporación para la integración de API.
- Desea crear canalizaciones de IA, flujos de trabajo o entrenar modelos de ML/IA con datos web fiables y verificables.
- Necesita fiabilidad y asistencia de nivel empresarial.
- Desea acceso directo a Proxies.
- No quieres estar atado a un plan basado en suscripción.
Prefiera Apify cuando:
- Desea una plataforma en la nube para implementar sus programas de scraping/automatización sin tener que gestionar la infraestructura.
- Desea monetizar su solución de scraping o compartirla con otros.
- Confías en las plantillas de scraping basadas en la comunidad para configurar rápidamente tus proyectos.
- Prefieres un ecosistema centrado en los desarrolladores en el que puedas ampliar, personalizar y automatizar tareas mediante programación.
Comentario final
En esta comparación entre Bright Data y Apify, ha visto lo que ofrece cada solución, en qué se diferencian y cuál podría ser la mejor para usted. Si desea una plataforma para implementar y monetizar sus Scrapers, Apify es una opción sólida. Si busca integraciones intuitivas, sin código o basadas en API, de Scraping web e IA, ¡Bright Data es la plataforma ideal!
Cree hoy mismo una cuenta gratuita en Bright Data y explore nuestros productos de Scraping web y automatización.
Preguntas frecuentes
¿Para qué se utiliza Bright Data?
Bright Data es una plataforma de datos web que se utiliza para recopilar datos web públicos estructurados a gran escala a través de Proxies, Scrapers web y Conjuntos de datos preparados para IA. Te permite eludir las restricciones geográficas, supervisar a la competencia, verificar anuncios, entrenar modelos de IA, realizar estudios de mercado y mucho más.
¿Para qué se utiliza Apify?
Apify se utiliza para conectarse a actores preconstruidos o crear flujos de trabajo personalizados de Scraping web y automatización. Estos le permiten extraer, almacenar y procesar datos web a gran escala desde cientos de sitios web.
¿Qué es mejor para iniciarse en el Scraping web y las integraciones: Apify o Bright Data?
Bright Data suele ser mejor para empezar. Su incorporación es rápida e intuitiva, con un acceso fácil a la API, documentación clara, código de ejemplo en varios idiomas y opciones de panel de control sin código. ¡Crea una cuenta gratis hoy mismo!
¿Bright Data se encarga de los Proxies, las medidas anti-bot y los retos anti-scraping por ti?
Sí, Bright Data se encarga de los proxies, las medidas antibots y los retos antirraspado por usted. Su plataforma proporciona proxies residenciales, de centro de datos, ISP y móviles, junto con Resolución de CAPTCHA, rotación de IP y gestión de huellas digitales. Esto significa que le equipa con todo lo que necesita para rastrear sitios web a gran escala de forma fiable y ética, sin bloqueos ni dolores de cabeza operativos.