
El filtrado de datos solía ser un simple truco de base de datos. Hoy en día, es una capacidad empresarial básica que potencia la IA, le permite cumplir las normativas y le ayuda a superar a sus competidores.
En esta guía, aprenderá:
- Qué es el filtrado de datos.
- Por qué es importante el filtrado de datos.
- Por qué debe utilizar el filtrado de datos automatizado.
- Cómo Deep Lookup facilita el filtrado de datos.
¡Entremos en materia!
¿Qué es el filtrado de datos?
El filtrado de datos es simplemente mostrarte sólo los datos que realmente te interesan. Es como usar un filtro de café que te muestra sólo lo que quieres, no los posos. La mecánica es sencilla: se establecen reglas (por ejemplo, mostrarme los clientes de California) y el sistema excluye todo lo que no coincide con las reglas.
Todos utilizamos el filtrado de datos en nuestra vida cotidiana. Cuando buscas “auriculares inalámbricos de menos de 100 dólares” en Amazon, estás filtrando. Cuando tu equipo de marketing saca una lista de clientes que no han comprado en 6 meses, están filtrando. Cuando ordenas tu bandeja de entrada por remitente, estás filtrando.
Aunque el concepto es sencillo, el uso del filtrado de datos a escala en una organización requiere un conocimiento sólido de los datos y las herramientas adecuadas. Hoy en día, el filtrado de datos es importante para el éxito de cualquier organización, y le diremos exactamente por qué.
Por qué es importante el filtrado de datos
El filtrado es necesario para dar sentido a los macrodatos.
Hoy en día, la mayoría de las empresas están sentadas sobre minas de oro de datos que nunca utilizarán. No porque los datos no sean valiosos, sino porque no pueden escarbar eficazmente en ellos para encontrar lo que importa.
Piénselo de este modo. Es probable que su empresa recopile cientos de datos sobre cada cliente. Pero cuando llega la hora de la verdad y necesita identificar sus segmentos más valiosos, ¿realmente va a clasificar manualmente 50.000 registros de clientes? Por supuesto que no. Tomará una muestra, hará algunas conjeturas y esperará lo mejor.
Ese es exactamente el problema que resuelve el filtrado. He aquí por qué es esencial un filtrado de datos eficaz:
- Elimineel ruido: sus analistas dejarán de perder el tiempo con datos irrelevantes y se centrarán en los patrones que realmente mueven la aguja.
- Aceleretodo:conjuntos de datosmás pequeñossignifican consultas más rápidas, perspectivas más rápidas y decisiones que se toman en días en lugar de semanas.
- Descubra patrones ocultos: Al eliminar el desorden, las tendencias que eran invisibles de repente se hacen evidentes.
- Ahorre dinero: Menos datos que almacenar y procesar significa menores costes de infraestructura. Además, el tiempo de su equipo será infinitamente más valioso.
- Cumpla la normativa: Filtre automáticamente la información confidencial y dormirá mejor sabiendo que no está exponiendo accidentalmente los datos de sus clientes.
En resumen, el filtrado de datos es el puente entre los datos brutos y la toma de decisiones informada. A continuación, veremos cómo abordar el filtrado en la práctica y algunas técnicas estándar para un filtrado eficaz.
Recorrido manual de filtrado de datos con datos del mercado de Amazon
Permítanme explicarles lo que hacen la mayoría de los equipos cuando necesitan filtrar datos. Utilizaremos un conjunto de datos real de productos de Amazon (cortesía de Bright Data datasets) para mostrarle cómo funciona exactamente. Este conjunto de datos incluye varios campos como títulos de productos, marcas, precios, valoraciones, etc. de diferentes categorías y regiones.
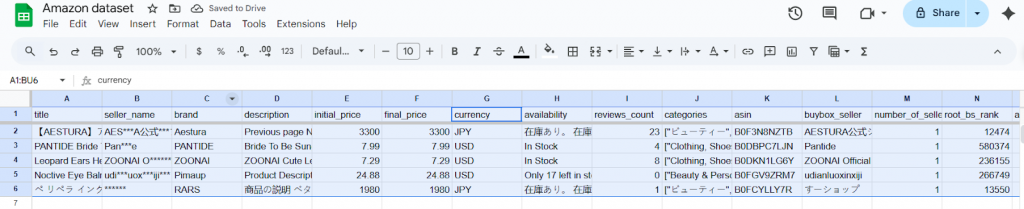
Ante una lista tan amplia, un profesional de los datos necesitaría aislar sólo los productos relevantes para un análisis concreto con el fin de centrarse en la información útil. Para ello, tendría que seguir los siguientes pasos:
- Empezar filtrando los artículos que no cumplan los criterios de interés iniciales. En la práctica, esto suele significar excluir los productos que no pertenecen a su categoría o ámbito de interés. Por ejemplo, si sólo nos interesan los productos de belleza, eliminaríamos las entradas que pertenezcan a otras categorías.
- Utilizando una herramienta como Google sheets o Excel, navegue hasta la pestaña Datos y haga clic en crear un filtro.

- Aparecerá entonces un filtro en cada columna, y podrás utilizarlo para personalizar el conjunto de datos tanto como quieras.
- Por ejemplo, si quieres filtrar los productos por divisa, y tener sólo los productos que tienen precios en USD, irías a la columna de precios y aplicarías ese filtro.

- Una vez desmarcado el JPY, el conjunto de datos sólo mostrará productos con precios en USD.
La primera vez que se hace esto, la sensación es muy buena. Tienes el control, puedes ver exactamente lo que ocurre y detectas patrones interesantes sobre la marcha. “¡Oh, mira, los productos ecológicos parecen tener valoraciones más altas!”.
Pero esto es lo que ocurre en la práctica:
- Semana 1: ¡Esto es genial! Me encanta tener este control.
- Semana 4: Vale, esto se está volviendo repetitivo, pero sigo encontrando buenas ideas.
- Semana 12: Me he pasado toda la mañana aplicando los mismos filtros que utilicé ayer.
- Semana 24: Creo que olvidé borrar el filtro anterior… ¿Estos números son correctos?
Muchos analistas brillantes se queman haciendo exactamente esto. No porque el trabajo no sea valioso, sino porque dedican el 80% de su tiempo a tareas mecánicas en lugar de al análisis real.
Ahora que ya sabe cómo filtrar datos manualmente, veamos los pros y los contras de utilizar este método.
Ventajas del filtrado manual
- El filtrado manual le proporciona información visual inmediata, lo que le permite ver los resultados al instante y ajustar los filtros de forma iterativa. Puede detectar patrones inesperados o problemas de calidad de los datos mientras trabaja.
- También se obtiene una integración del contexto empresarial que permite tomar decisiones matizadas. Al filtrar los campos “customers_say” o “top_review”, el juicio humano identifica sentimientos y preocupaciones que los sistemas automatizados podrían pasar por alto.
- Permite una exploración flexible que respalda el análisis basado en descubrimientos. Es posible que observe que los productos con “climate_pledge_friendly” = TRUE tienen valoraciones más altas, lo que conduce a nuevas perspectivas estratégicas.
- La barrera de entrada es baja, lo que significa que cualquier miembro del equipo familiarizado con las hojas de cálculo puede realizar análisis sin formación técnica ni herramientas especializadas.
- Además, los criterios documentados garantizan la reproducibilidad de los análisis y la colaboración en equipo.
Desventajas del filtrado manual
- Las limitaciones de escala se hacen evidentes rápidamente. El filtrado de más de 10.000 filas en Google Sheets provoca una notable degradación del rendimiento. Con millones de productos de Amazon, sólo verás una pequeña muestra.
- La intensidad del tiempo aumenta con la complejidad. Aplicar el proceso de filtrado de 8 pasos anterior lleva entre 15 y 20 minutos para un análisis. Repetir este proceso a diario o en varias categorías resulta insostenible.
- La probabilidad de error humano aumenta con la repetición. La selección accidental de operadores erróneos (mayor que frente a menor que) o el olvido de borrar los filtros anteriores conducen a análisis incorrectos.
- La incoherencia entre los usuarios crea ideas contradictorias. Dos analistas pueden interpretar “vendedor de alta calidad” de forma distinta, filtrando ‘nombre_vendedor’ o ‘valoración’ con umbrales diferentes.
- La reproducibilidad limitada hace imposible la automatización. Cada sesión de filtrado manual requiere la intervención humana, lo que impide elaborar informes programados o cuadros de mando en tiempo real.
- El coste de oportunidad es significativo. Mientras los analistas pasan horas filtrando datos, los competidores que utilizan soluciones automatizadas ya actúan sobre las percepciones. El tiempo dedicado al filtrado mecánico podría invertirse en el análisis estratégico y la toma de decisiones.
En general, el filtrado manual de datos proporciona un alto grado de control y claridad para el analista, por lo que es muy adecuado para el análisis exploratorio o conjuntos de datos a pequeña escala donde la comprensión de los matices es importante. Sin embargo, su ineficacia y los riesgos de error en datos a gran escala lo hacen menos adecuado para big data o flujos de trabajo rutinarios.
En esos casos, es mejor pasar a métodos o herramientas de filtrado automatizado, y vamos a explicarle exactamente por qué.
Por qué el filtrado automatizado de datos es más inteligente, rápido y escalable
Cuando hablamos de filtrado automatizado, no sólo nos referimos a la velocidad. La automatización no sólo hace más rápido lo que usted hacía antes, sino que hace cosas que literalmente no podría hacer manualmente.
¿Recuerda ese conjunto de datos de Amazon con 73 campos diferentes? Manualmente, podría explorar entre 5 y 10 combinaciones de esos campos. Con la automatización, puede probar miles de combinaciones en paralelo. Puede descubrir que los productos con distintivos respetuosos con el clima tienen en realidad un 23% más de retención de clientes, pero sólo en determinados rangos de precios y sólo cuando los venden determinados tipos de vendedores.
No se trata de descubrimientos por casualidad. Son conocimientos que surgen cuando se pueden explorar sistemáticamente todos los ángulos, y sólo se pueden encontrar mediante el filtrado automatizado de datos.
El filtrado automatizado cambia radicalmente las posibilidades de un analista o una empresa al procesar millones de registros en segundos y aplicar cientos de combinaciones de filtros simultáneamente. Para ello, codifica sus criterios como reglas ejecutables por máquina y las ejecuta a escala de forma continua.
En lugar de hacer clic en las columnas, puede definir filtros declarativos, aplicarlos lo más cerca posible de la fuente y obtener datos rápidos y reutilizables. Con el filtrado automatizado de datos, puede explorar exhaustivamente miles de interacciones de campo en paralelo, sacando a la luz patrones que nunca cabrían dentro del limitado presupuesto de exploración de un humano, y luego reproducirlos tanto como desee.
| Dimensión | Manual | Automatizada |
|---|---|---|
| Velocidad/Latencia | A ritmo humano; de minutos a horas por ejecución | A ritmo de máquina; de segundos a minutos a escala |
| Escalabilidad | Limitada por la interfaz de usuario y la memoria | Escalado horizontal (computación distribuida, pushdown) |
| Fiabilidad | Susceptible al error humano | Determinista, comprobable, idempotente |
| Frescura | Por lotes, ad hoc | Programado o en flujo continuo; posible casi en tiempo real |
| Coherencia | Varía según el operador | Lógica controlada por versiones; resultados reproducibles |
| Coste | Coste de mano de obra oculto; repetición del trabajo | Optimización informática; caché y predicado pushdown |
| Gobernanza | Difícil de auditar | Linaje, registro, aprobaciones, controles de acceso |
Una de las mejores herramientas que puede utilizar para el filtrado automático de datos es Deep Lookup de Brightdata, de la que hablaremos a continuación.
Presentación de Deep Lookup: Filtre datos con un lenguaje sencillo
Deep Lookup es la herramienta de investigación de Bright Data impulsada por IA que convierte las preguntas en inglés sencillo en conjuntos de datos estructurados y precisos. Con Deep Lookup, puede pedir exactamente lo que necesita y obtenerlo como una tabla que puede utilizar.
En lugar de unir fuentes o escribir consultas complejas, usted describe las entidades que desea (empresas, productos, personas, noticias, propiedades), los filtros que deben cumplir y las columnas que desea ver. Deep Lookup se encarga del filtrado, el enriquecimiento y la estructuración entre bastidores para ofrecer resultados listos para el análisis.
Cómo funciona Deep Lookup
Deep Lookup fomenta un formato de consulta de dos líneas, como éste:
- Buscar todo. .. <entidades y condiciones>
- Mostrar: <columnas que desee>
Por ejemplo, un ejemplo de búsqueda profunda sería el siguiente:
***Encuentra todos los productos de belleza y cuidado personal de Amazon con un precio ≤ $25 con una valoración ≥ 4 y en stock.***
***Mostrar: nombre del producto, marca, precio actual, valoración, número de opiniones, URL del producto***
Deep Lookup toma esa descripción y:
- Identifica las fuentes de datos que necesita
- Aplica sus filtros a nivel de base de datos (no después de descargarlo todo)
- Enriquece los resultados con contexto adicional
- Devuelve un conjunto de datos limpio y estructurado que puede utilizar inmediatamente
Para consultas más complejas, puede utilizar un enfoque más estructurado:
BUSCAR TODO: [tipos de entidad]
FILTROS:
- Condición #1
- Condición #2
MOSTRAR:
- Columna #1 [Enriquecimiento o Restricción]
- Columna #2 [Enriquecimiento o restricción]
La diferencia clave es que está describiendo la lógica empresarial, no la implementación técnica. No necesita saber a qué puntos finales de la API debe acceder, cómo gestionar la paginación o dónde encontrar los datos de precios de la competencia.
Los conjuntos de datos que recibe de Deep Lookup se seleccionan, estructuran y entregan como Websets. Los Websets se verifican y citan por completo, son personalizables (se eligen los campos exactos) y están diseñados para mantenerse actualizados a medida que Deep Lookup explora nuevas fuentes.
En la práctica, el flujo es el siguiente
- Formule su pregunta
- Rastrear y razonar
- Obtener resultados procesables.
Puedes personalizar Websets por entidad, sector, geografía y campos de datos para adaptarlo a tu caso de uso.
Para terminar
A estas alturas, ya has visto que el filtrado de datos es la forma de convertir información desordenada y abrumadora en decisiones claras. El filtrado manual crea intuición, pero la automatización ofrece velocidad, coherencia y la capacidad de sacar a la luz patrones que nadie puede encontrar columna por columna.
Aquí es exactamente donde Bright Data ayuda. Con Deep Lookup, usted establece sus criterios en un lenguaje sencillo y recibe un conjunto de datos limpios, estructurados y siempre actualizados que puede incluir en cuadros de mando, cuadernos o modelos. En combinación con los conjuntos de datos de Bright Data (como el conjunto de datos de Amazon de esta guía), puede pasar de la idea al conocimiento y a la producción sin necesidad de mantener canalizaciones frágiles.
¿Está listo para ver lo que el filtrado automatizado puede hacer por sus datos? Pruebe Deep Lookup con una cuenta gratuita de Bright Data. Tome esas reglas de filtrado que ha estado aplicando manualmente y vea qué información se ha estado perdiendo.






