Guía paso a paso para crear un canal de scraping sin servidor en Google Cloud utilizando Cloud Run, Firestore, BigQuery, Workflows y Cloud Scheduler.
En este artículo aprenderás:
- Por qué una arquitectura sin servidor funciona bien para los procesos de Scraping web.
- Cómo configurar la infraestructura necesaria de Google Cloud desde cero.
- Cómo implementar un servicio de scraping privado y un servicio API público en Cloud Run.
- Cómo organizar las ejecuciones de scraping con Cloud Workflows y automatizarlas con Cloud Scheduler.
- Cómo almacenar y consultar los datos extraídos utilizando Firestore y BigQuery.
- Cómo verificar que todo el proceso funciona de principio a fin.
¡Empecemos!
¿Por qué crear un proceso de scraping sin servidor?
La mayoría de los tutoriales sobre scraping se limitan al script. Obtienes algo de HTML, tal vez realizas el Parseo de algunos campos, y eso es todo. Pero cuando se trata de ejecutar Scrapers en producción, necesitas respuestas a preguntas más difíciles: ¿A dónde van los datos? ¿Cómo se ejecuta según un calendario? ¿Cómo se consultan los resultados más tarde? ¿Cómo se mantienen bajos los costes cuando el Scraper no está en funcionamiento?
Ahí es donde entra en juego la tecnología sin servidor. Google Cloud Run solo te cobra cuando tus servicios gestionan solicitudes. No hay servidores que gestionar, ni computación inactiva que consuma dinero durante la noche. Combina eso con Firestore para el seguimiento de tareas, BigQuery para el análisis y Cloud Workflows para la orquestación, y obtendrás una arquitectura de canalización de datos que se escala a cero cuando está inactiva y se activa bajo demanda.
Al final de esta guía, tendrás:
- Un
servicio de Scraperprivado en Cloud Run que realiza el rastreo real. - Un
servicio APIpúblico en Cloud Run que expone tus datos. - Colecciones de Firestore que realizan el seguimiento del estado y los resultados de los trabajos.
- Una tabla de BigQuery que puede consultar para realizar análisis.
- Un flujo de trabajo de Cloud que coordina toda la ejecución del rastreo.
- Un trabajo de Cloud Scheduler que lo activa en un cron.
Comprender la arquitectura
Antes de empezar a ejecutar comandos, es útil ver cómo se conectan todas las piezas. Dedicamos mucho tiempo a determinar la arquitectura adecuada cuando lo creamos por primera vez, así que vamos a explicártela.
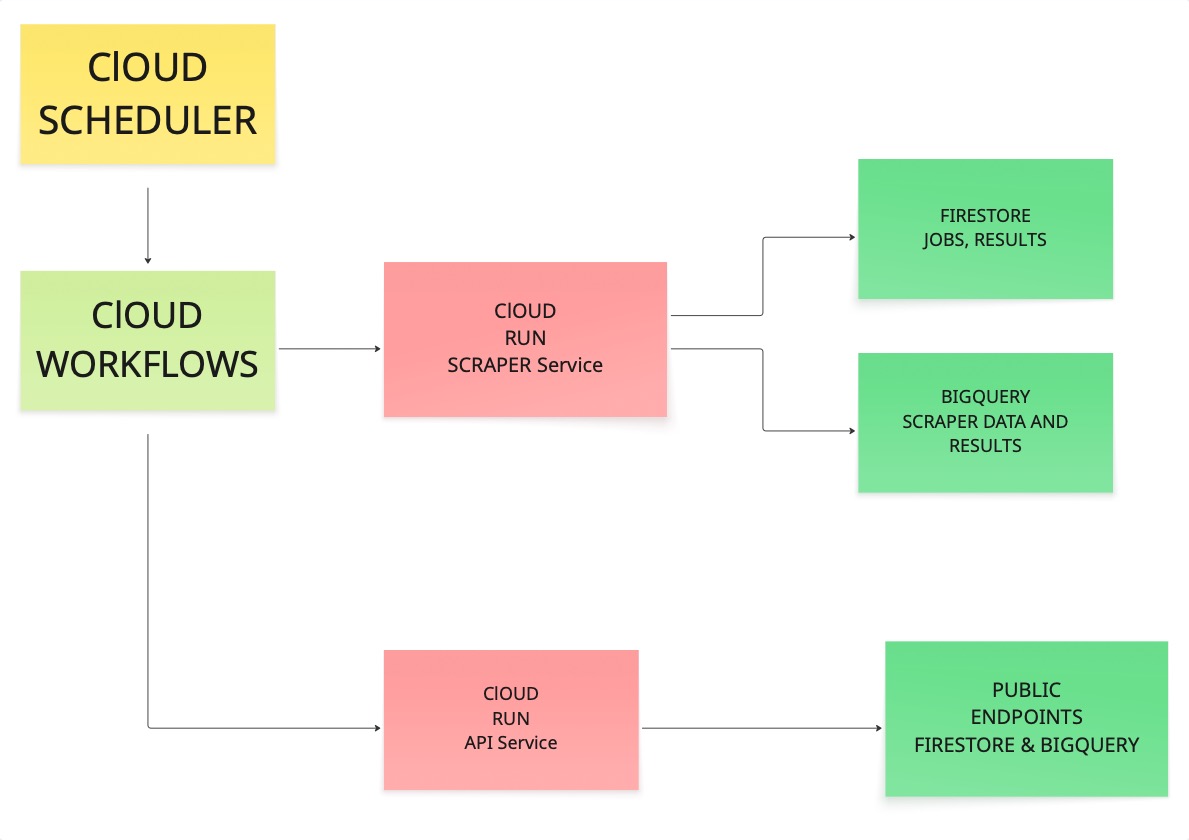
El programador activa un flujo de trabajo. El flujo de trabajo llama al Scraper. El Scraper visita las URL, extrae el contenido y escribe los resultados tanto en Firestore como en BigQuery. A continuación, el servicio API lee esos almacenes y expone los datos a través de puntos finales públicos.
Si cada eslabón de esa cadena funciona, tendrá algo en lo que puede confiar en producción.
Requisitos previos
Antes de empezar, asegúrate de que tienes lo siguiente:
- Una cuenta de Google.
- Un proyecto de GCP con la facturación habilitada (los costes serán mínimos, pero la facturación debe estar activa).
- Node.js 18 o superior.
- La CLI de
gcloudinstalada en su máquina.
Realice una comprobación rápida:
node --version
npm --version
gcloud --versionSi los tres muestran los números de versión, todo está listo.
Configuración de tu proyecto de Google Cloud
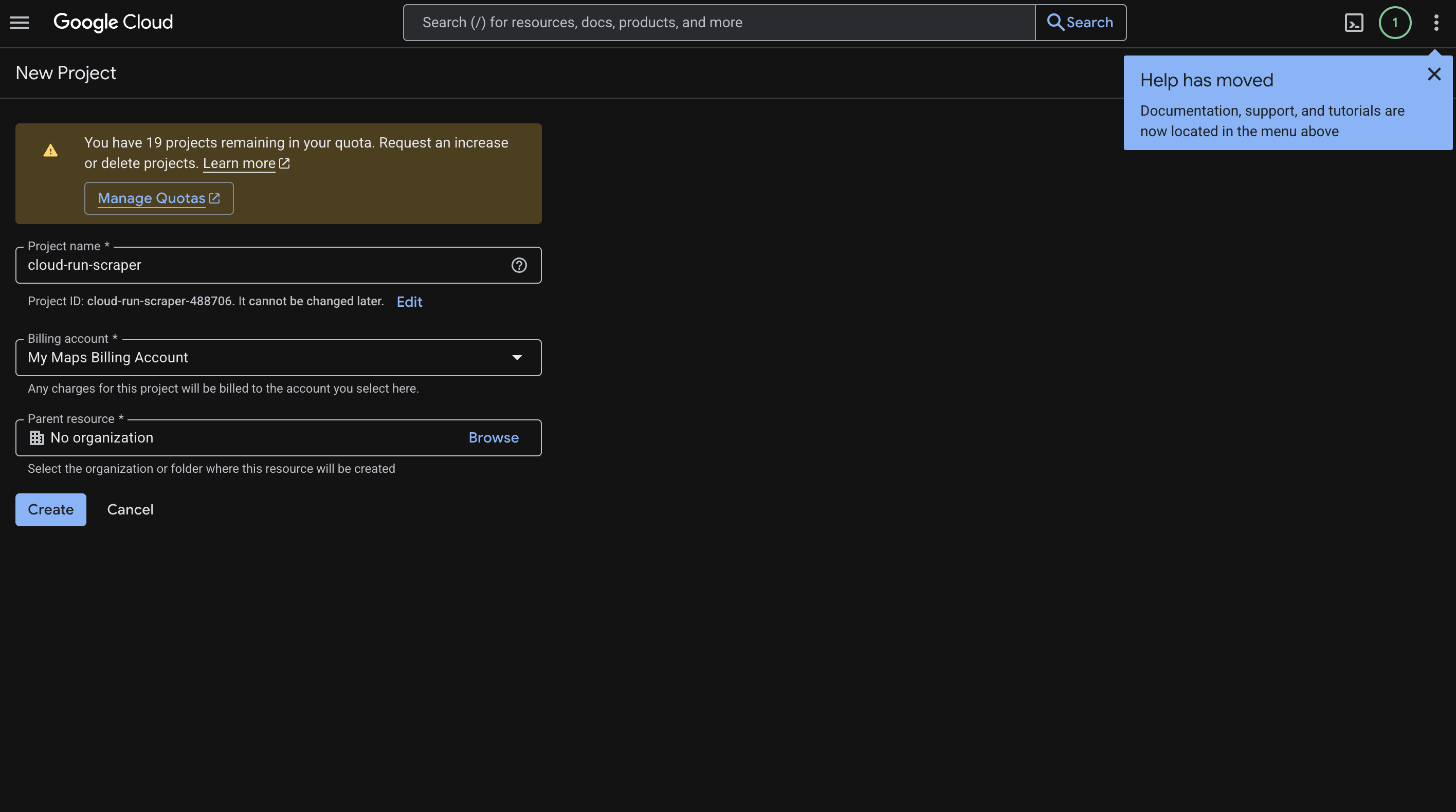
Dirígete a Cloud Console y crea un nuevo proyecto. Nosotros lo hemos llamado cloud-run-scraper, pero puedes ponerle el nombre que más te convenga según tu caso de uso.
Esto es lo que debe hacer:
- Introduce el nombre de tu proyecto.
- Haga clic en Crear.
- Copie el ID del proyecto que se genera (algo así como
cloud-run-scraper-123456). Lo necesitará a lo largo de toda la guía. - Vaya a Facturación y vincule una cuenta de facturación al proyecto.
Así es como se ve esa pantalla:
Configuración de su shell
Le recomendamos que configure algunas variables de entorno por adelantado para no tener que copiar y pegar los ID de proyecto en todas partes. De este modo, sus comandos estarán limpios y serán reutilizables:
export PROJECT_ID="TU_ID_DE_PROYECTO"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"A continuación, dirija gcloud a su proyecto:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"Y autentifíquese (esto abrirá su navegador):
gcloud auth login
gcloud auth application-default loginHabilitar las API necesarias
Una cosa que confunde a la gente con Google Cloud es que nada funciona hasta que no se activan explícitamente las API que se necesitan. Piensa en ello como si se tratara de accionar unos interruptores. Ejecuta esto una vez y ya está:
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.comPuede verificar que todos estén habilitados con:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"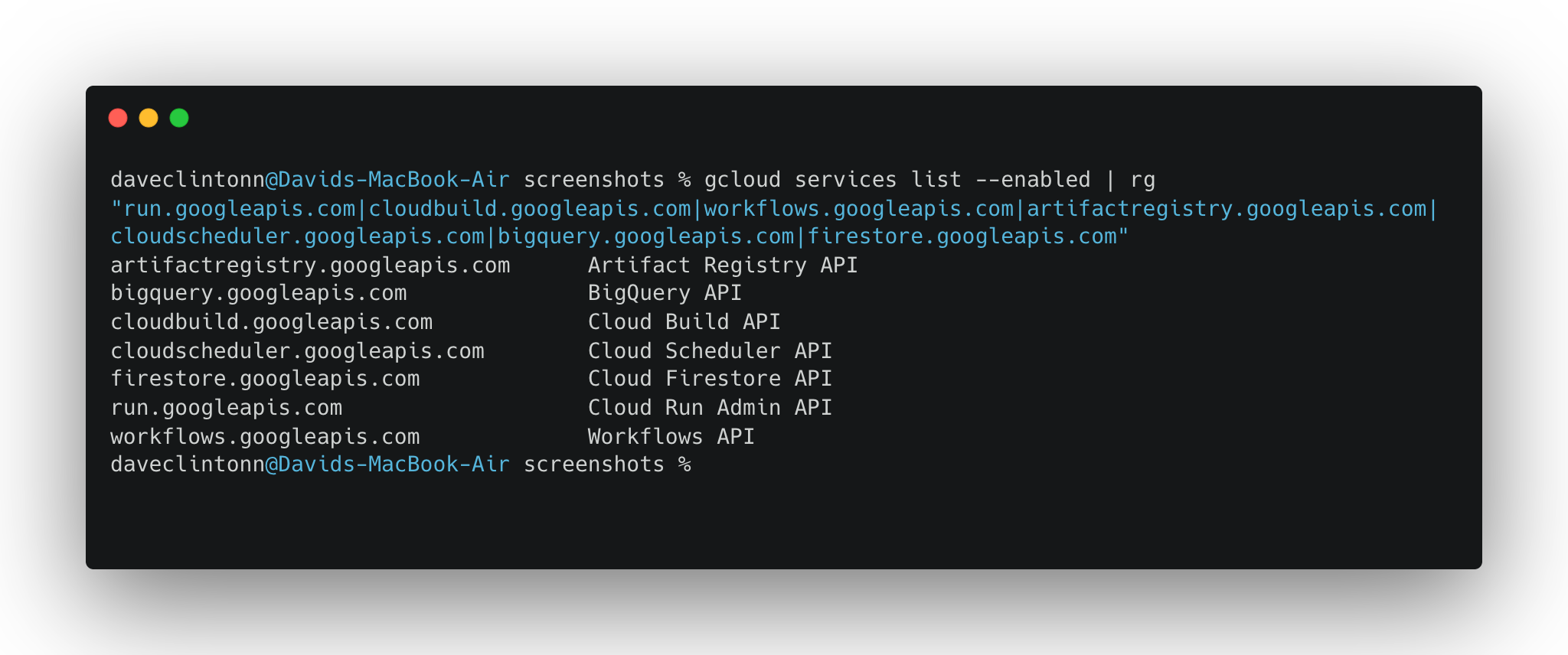
Configuración de Firestore
Necesitamos Firestore en modo nativo para almacenar los datos de seguimiento de trabajos y recopilar resultados:
gcloud firestore databases create --location="$REGION" --type=firestore-nativeSi ya tiene Firestore configurado en este proyecto, puede omitir este paso. Se mostrará un error indicando que la base de datos ya existe.
Creación del Registro de artefactos
El Registro de artefactos es donde se almacenarán tus imágenes de Docker. Piensa en él como un registro de contenedores privado en GCP:
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="Docker images for cloud-run-Scraper"A continuación, indique a Docker cómo autenticarse con él:
gcloud auth configure-docker "$REGION-docker.pkg.dev"Configuración de BigQuery
Ahora crearemos el conjunto de datos y la tabla de BigQuery donde se almacenarán los datos recopilados. Esto es lo que hace que todo el proceso sea útil: un flujo de proceso ETL bien estructurado le permite ejecutar consultas SQL en todos los datos recopilados para detectar tendencias, filtrar por fuente o crear paneles de control.
Cree el conjunto de datos:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"A continuación, cree la tabla con el esquema utilizado por el Scraper:
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRINGComprueba rápidamente que ha funcionado:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"Obtener los permisos IAM correctos
Esta parte no es la más emocionante, pero es fundamental. Sus servicios Cloud Run necesitan permiso para comunicarse con Firestore, BigQuery y entre sí. Sin estos enlaces IAM, obtendrá misteriosos errores 403 sin una explicación clara.
En primer lugar, obtenga su cuenta de servicio de computación:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"A continuación, conceda las funciones que necesita:
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"Son cinco enlaces de roles. Cada uno permite a la cuenta de servicio realizar una acción específica: leer/escribir en Firestore, insertar en BigQuery, invocar servicios de Cloud Run y activar flujos de trabajo.
Instalación de dependencias
Desde la raíz del repositorio, instala las dependencias para ambos servicios:
npm --prefix scraper-service install
npm --prefix api-service installImplementación del servicio Scraper
Este es el motor de todo el proceso. Es el servicio que visita las URL, extrae el contenido y escribe los resultados en Firestore y BigQuery. Si desea gestionar escenarios antibots más complejos en su Scraper, vale la pena explorar herramientas como el Navegador de scraping de Bright Data para la automatización de navegadores basados en la nube a gran escala.
Lo estamos implementando como un servicio privado. Fíjese en el indicador --no-allow-unauthenticated. Solo las solicitudes autenticadas, como las de nuestro flujo de trabajo, pueden llamarlo:
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=productionObtenga la URL una vez que se haya implementado:
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"Guarde esa URL. La necesitará para la configuración del flujo de trabajo.
Implementación del servicio API
El servicio API es la parte pública del canal. Lee desde Firestore y BigQuery y expone los puntos finales para que usted o su interfaz puedan acceder a los datos recopilados:
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionObtenga la URL:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"Prueba de los servicios implementados
Ahora viene la parte divertida: acceder a sus servicios en vivo y asegurarse de que todo funciona. Tenga en cuenta que los retos habituales del Scraping web, como el bloqueo de IP y la limitación de velocidad, pueden afectar a su Scraper incluso en una configuración sin servidor, por lo que vale la pena tener una estrategia para ellos desde el principio.
Pruebe lo siguiente con su servicio API:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"Para el Scraper, debe pasar un token de autenticación, ya que se trata de un servicio privado:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"También puede pasar selectores CSS personalizados si desea seleccionar elementos específicos de una página:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
"$SCRAPER_URL/scrape"Configuración del flujo de trabajo
El flujo de trabajo es lo que vincula el Scraper a una programación. Se trata de un archivo YAML que indica a Cloud Workflows que llame al Scraper para cada URL de la lista.
Abre workflows/scrape-pipeline.yaml y configura scraper_url con la URL que obtuviste en el paso de implementación del Scraper.
A continuación, impleméntelo:
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"Creación de la tarea del programador
Aquí es donde el canal se vuelve totalmente automático. Configuramos una tarea cron que ejecuta el flujo de trabajo todos los días a las 6:00 a. m. UTC:
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Si el trabajo ya existe y solo desea actualizarlo:
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Ejecutar su primera prueba completa
No espere al programador. Active el flujo de trabajo manualmente y observe cómo se ejecuta todo el proceso:
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'Puede supervisar la ejecución con:
gcloud workflows executions list scrape-pipeline --location "$REGION"Espere uno o dos minutos. Una vez que la ejecución muestre SUCCEEDED, sus datos deberían estar fluyendo hacia Firestore y BigQuery.
Verificación de los datos
Ahora confirmemos que los datos realmente llegaron a donde debían.
Compruebe el recuento de filas en BigQuery:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"Vea los últimos resultados recopilados:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"Comprueba Firestore en la consola. Deberías ver dos colecciones: jobs y results.
A continuación, acceda a la API para confirmar que puede leer todo:
curl -s "$API_URL/jobs?limit=1"Toma un jobId de la respuesta y profundiza:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"Si todo eso devuelve datos, tu canalización está funcionando de principio a fin.
CI/CD con Cloud Build
El repositorio incluye un archivo cloudbuild.yaml que se encarga de crear e implementar ambos servicios de una sola vez. Cuando quieras enviar cambios, solo tienes que ejecutar:
gcloud builds submit --config cloudbuild.yaml .Ese único comando creará ambas imágenes de Docker, las enviará a Artifact Registry e implementará ambos servicios de Cloud Run. Si desea ampliar más allá de una sola canalización, consulte esta descripción general de las principales herramientas de Scraping web para ver cómo diferentes soluciones pueden complementar una configuración basada en la nube como esta.
Lista de verificación final
Antes de darlo por terminado, siga estos pasos de verificación:
gcloud run services list --region us-central1debería mostrar ambos servicios.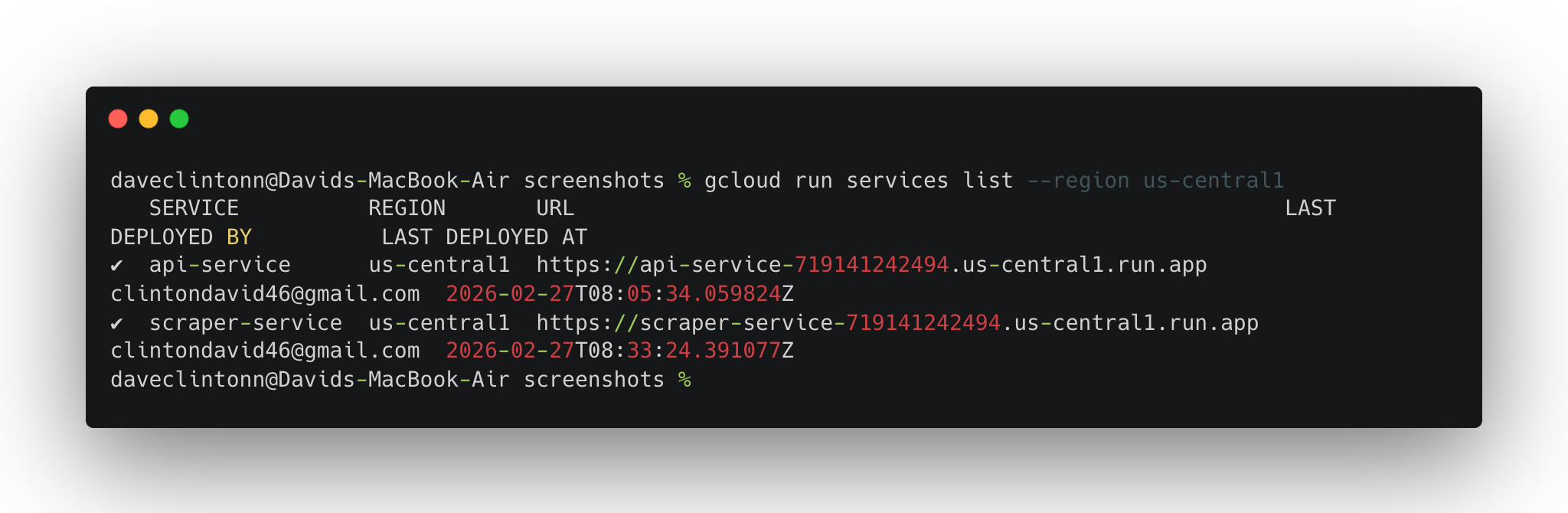
gcloud workflows describe scrape-pipeline --location us-central1debería devolver los detalles del flujo de trabajo.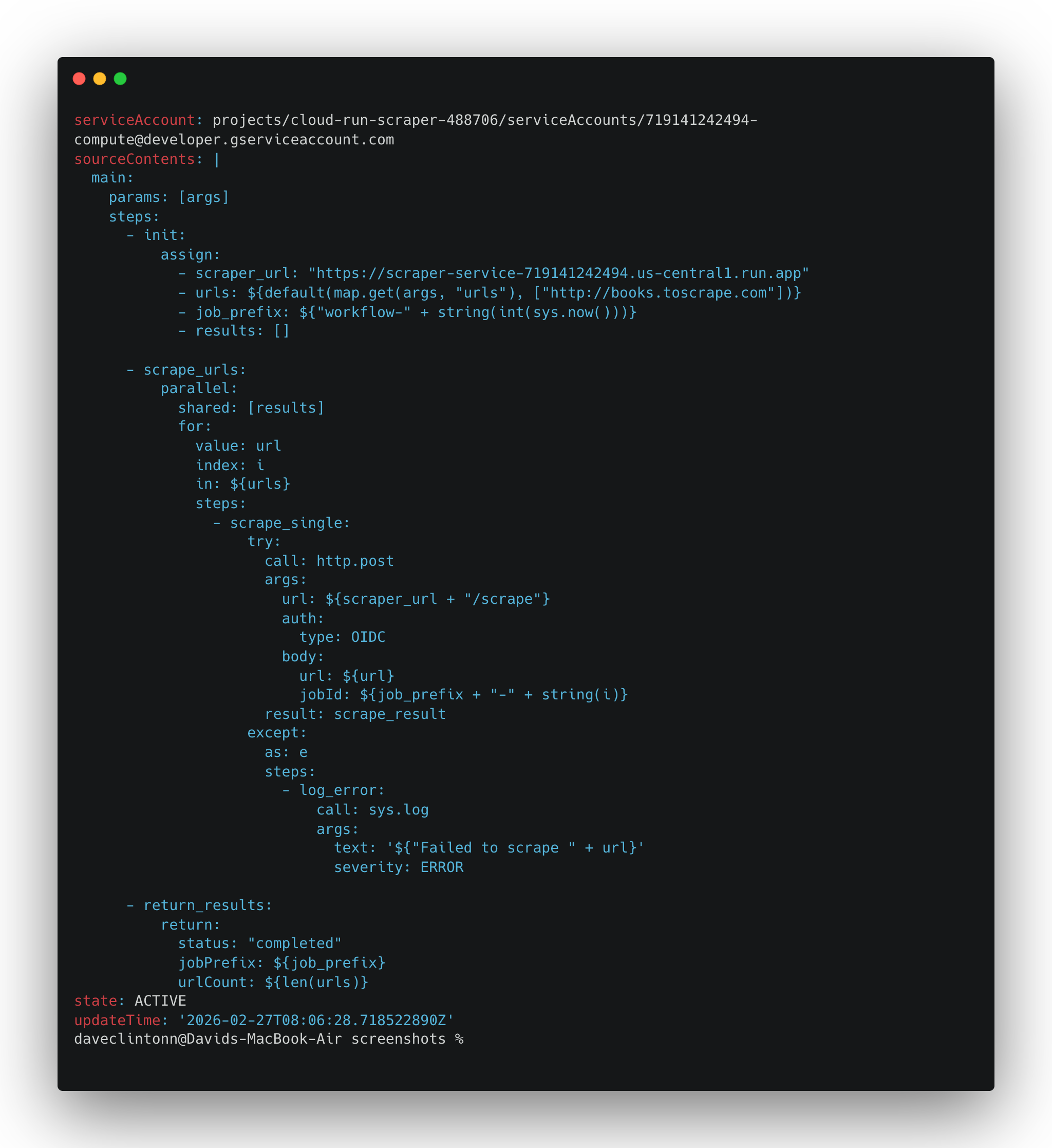
gcloud scheduler jobs list --location us-central1debería mostrar el trabajo del programador.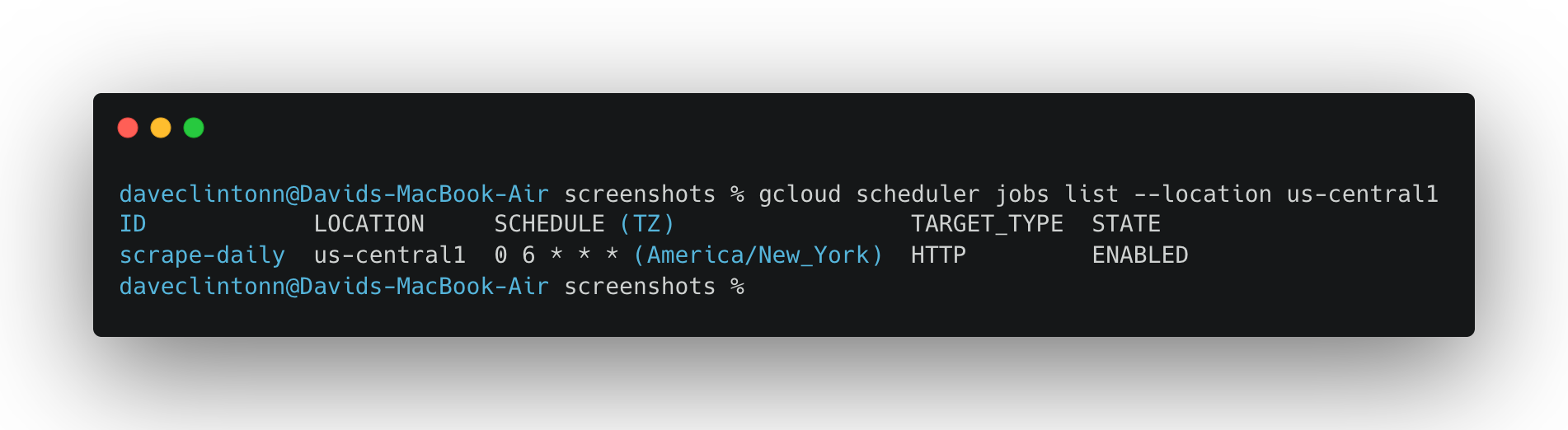
- Firestore debería tener colecciones de
trabajosyresultados. - La tabla de BigQuery debería tener filas.
- El punto final API
/jobsdebería devolver registros reales.
Si los seis pasos se completan correctamente, ya no estás ejecutando una demostración. Tienes un canal real que extrae datos según lo programado, los almacena en dos lugares y los sirve a través de una API pública.
Conclusión
En esta guía, hemos visto cómo crear un canal de Scraping web sin servidor completo en Google Cloud. Hemos tratado la configuración de la infraestructura, la implementación de dos servicios Cloud Run, la coordinación de las ejecuciones de scraping con Cloud Workflows y la automatización de todo con Cloud Scheduler.
Si prefiere un enfoque gestionado en lugar de mantener su propia infraestructura, puede explorar los Conjuntos de datos prerecopilados de Bright Data o Scraper Studio para convertir cualquier sitio web en un canal de datos listo para usar. También puede leer nuestra guía sobre scraping sin servidor con Scrapy y AWS para ver cómo se ve una arquitectura similar en un proveedor de nube diferente. Clone el proyecto, intercambie sus propias URL de destino y tendrá un canal de scraping en funcionamiento.