En este artículo aprenderá:
- Qué es Azure Synapse Analytics y qué ofrece.
- Por qué la integración con la API SERP de Bright Data en Azure Synapse Analytics es una estrategia ganadora.
- Cómo crear un canal de Azure Synapse que recopile, transforme y analice datos de búsqueda web utilizando la API SERP de Bright Data.
¡Empecemos!
¿Qué es Azure Synapse Analytics?
Azure Synapse Analytics es una plataforma de análisis basada en la nube que reúne la integración de datos, el almacenamiento de datos empresariales y el procesamiento de big data en un único espacio de trabajo. Proporciona orquestación de canalizaciones, grupos Apache Spark y grupos SQL dedicados y sin servidor, lo que le permite ingestar, transformar y consultar datos a escala desde un único entorno unificado.
Su objetivo principal es ayudarle a pasar de los datos sin procesar a la información empresarial. Esto se consigue combinando un motor de canalización (creado en Azure Data Factory) para la ingesta de datos, cuadernos Apache Spark para transformaciones basadas en código y grupos SQL para consultar y servir Conjuntos de datos listos para el análisis a paneles de control, modelos de aprendizaje automático y aplicaciones posteriores.
Azure Synapse Analytics frente a Azure IA Foundry: ¿cuál es la diferencia?
Si ya ha leído nuestra guía sobre la integración de la API SERP con Azure AI Foundry, es posible que se pregunte en qué se diferencia Synapse Analytics. Ambos tienen fines fundamentalmente diferentes:
- Azure AI Foundry es una plataforma de desarrollo de IA unificada centrada en la creación, implementación y gestión de aplicaciones, agentes y flujos de prompts de IA. Proporciona acceso a un catálogo de LLM (de Azure OpenAI, Meta, Mistral, etc.) y está diseñada para el desarrollo basado en IA que implica ingeniería de prompts, ajuste de modelos y flujos de trabajo RAG.
- Azure Synapse Analytics es una plataforma de análisis y almacenamiento de datos centrada en la ingesta de grandes volúmenes de datos, la ejecución de transformaciones complejas y la prestación de análisis estructurados a escala. Destaca en canalizaciones ETL/ELT, procesamiento de big data con Spark e inteligencia empresarial basada en SQL.
En resumen, Azure AI Foundry es donde se crean aplicaciones basadas en IA y flujos de prompts, mientras que Azure Synapse Analytics es donde se crean canalizaciones de datos que recopilan, transforman y almacenan datos para su análisis y generación de informes.
En realidad, se complementan a la perfección. Puede utilizar Synapse para crear la base de datos, recopilando y almacenando datos web a gran escala, y luego introducir esos datos seleccionados en AI Foundry para realizar análisis basados en LLM. En este tutorial, verá cómo Synapse Analytics puede integrarse con la API SERP de Bright Data para crear un canal de datos web completo que recopila resultados de búsqueda, los transforma con Spark y ofrece análisis a través de SQL.
Por qué integrar la API SERP de Bright Data en Azure Synapse Analytics
Azure Synapse Analytics proporciona un potente conector REST en su motor de canalización que le permite llamar a cualquier API REST y enviar los resultados directamente a Azure Data Lake Storage. Esto abre la puerta a la incorporación de fuentes de datos externas en sus flujos de trabajo de análisis. Sin embargo, para inyectar datos de búsqueda web en tiempo real en su almacén de datos, necesita una fuente de datos fiable, escalable y estructurada.
Aquí es donde entra en juego la API SERP de Bright Data. La API SERP le permite buscar consultas de forma programada en motores de búsqueda, incluidos Google, Bing, DuckDuckGo, Yandex y muchos más, y recuperar todo el contenido SERP. Devuelve datos en múltiples formatos, incluidos JSON analizado, HTML sin procesar y Markdown listo para IA, lo que le proporciona una fuente fiable de datos actualizados y verificables.
Este enfoque es especialmente útil para:
- Canales de seguimiento de palabras clave SEO para supervisar diariamente su posicionamiento en miles de palabras clave e identificar tendencias a lo largo del tiempo.
- Almacenes de inteligencia competitiva para recopilar datos de visibilidad de la competencia y combinarlos con métricas internas para realizar análisis estratégicos.
- Conjuntos de datos de estudios de mercado para agregar tendencias de resultados de búsqueda en todos los sectores, regiones y períodos de tiempo para la elaboración de informes a gran escala.
- Análisis del rendimiento del contenido para realizar un seguimiento de la clasificación de su contenido para las palabras clave objetivo y medir el impacto de los esfuerzos de SEO.
Al combinar las capacidades de orquestación de procesos y almacenamiento de datos de Azure Synapse con la API SERP de Bright Data, puede crear procesos de datos que recopilen, transformen y analicen continuamente datos de búsqueda web a gran escala, sin necesidad de mantener ninguna infraestructura de scraping.
Cómo crear un canal de datos SERP en Azure Synapse con Bright Data
En esta sección guiada, verá cómo integrar la API SERP de Bright Data en un canal de Azure Synapse como parte de un rastreador diario de posicionamiento de palabras clave. Este canal consta de cinco pasos principales:
- Configuración del espacio de trabajo: se crea un espacio de trabajo de Azure Synapse con una cuenta de Data Lake Storage vinculada.
- Configuración de la fuente de datos: se crea un servicio vinculado REST que apunta a la API SERP de Bright Data, con almacenamiento seguro de credenciales.
- Canalización de ingestión: una canalización de Synapse llama a la API SERP para un conjunto de palabras clave rastreadas y envía los resultados JSON sin procesar a su lago de datos.
- Transformación Spark: un cuaderno Apache Spark aplana y normaliza los datos SERP sin procesar en tablas Delta listas para su análisis.
- Análisis SQL: las consultas SQL sin servidor analizan las tendencias de clasificación y se crean vistas para los paneles de Power BI.
Nota: Esto es solo un ejemplo, y puede aprovechar la API SERP en muchos otros escenarios y casos de uso. Por ejemplo, también podría crear canalizaciones para el Monitoreo de precios competitivos o introducir datos SERP en modelos de aprendizaje automático.
Siga las instrucciones que se indican a continuación para crear un canal de datos web impulsado por la API SERP de Bright Data dentro de Azure Synapse Analytics.
Requisitos
Para seguir esta sección del tutorial, asegúrese de que dispone de:
- Una cuenta de Microsoft.
- Una suscripción a Azure (incluso la versión de prueba gratuita es suficiente).
- Una cuenta de Bright Data con una zona API SERP activa y una clave API (con permisos de administrador).
Siga la documentación oficial de Bright Data para configurar su zona API SERP y obtener su clave API. Guarde tanto su clave API como el nombre de la zona en un lugar seguro, ya que los necesitará en breve.
Paso 1: Crear un espacio de trabajo de Azure Synapse
Las canalizaciones de Azure Synapse solo están disponibles dentro de un espacio de trabajo de Synapse, por lo que el primer paso es crear uno.
Inicie sesión en su cuenta de Azure y busque Azure Synapse Analytics en la barra de búsqueda situada en la parte superior del portal de Azure:
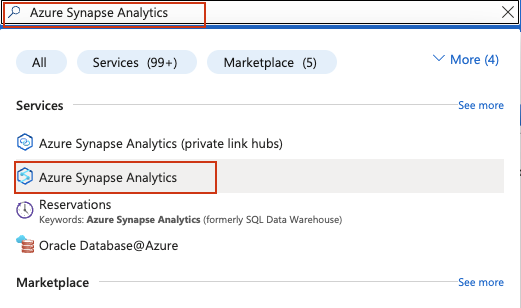
En la página de administración de Synapse Analytics, haga clic en Crear. Rellene el formulario de creación:
- Seleccione su suscripción a Azure.
- Seleccione un grupo de recursos existente o cree uno nuevo.
- Asigne un nombre a su área de trabajo, como
bright-data-serp-pipeline. - Elija una región cercana a usted.
- Para Data Lake Storage Gen2, seleccione Crear nuevo y proporcione un nombre de cuenta de almacenamiento (debe estar todo en minúsculas, tener entre 3 y 24 caracteres y ser único a nivel mundial, por ejemplo,
serppipelinelake). Cree un nuevo sistema de archivos llamadoraw.
Haga clic en Revisar + Crear y, a continuación, en Crear para iniciar la implementación.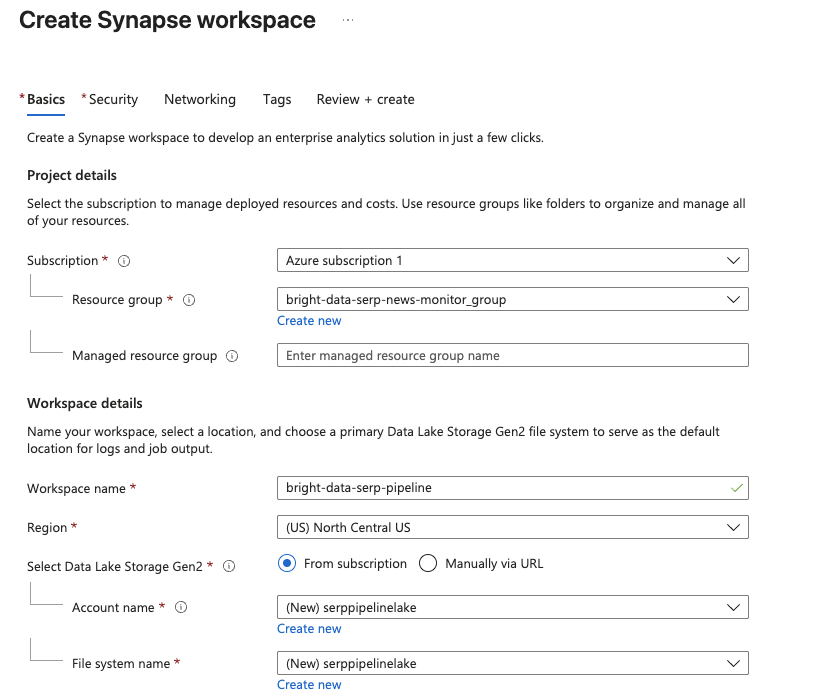
El proceso de inicialización puede tardar unos minutos. Una vez completado, debería ver una página de confirmación. Haga clic en Ir al recurso y, a continuación, en Abrir Synapse Studio para iniciar el entorno de desarrollo basado en web.
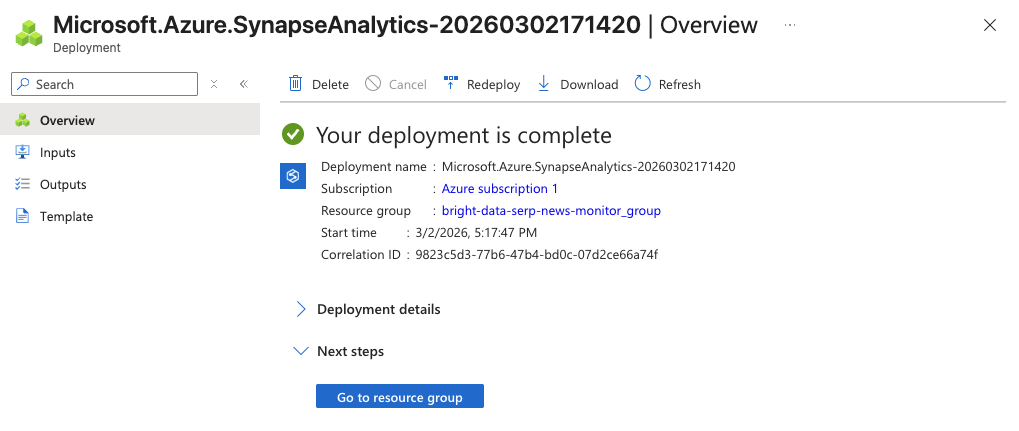
Ahora dispone de un espacio de trabajo de Synapse en el que puede crear canalizaciones, escribir cuadernos de Spark y ejecutar consultas SQL.
Paso 2: Crear un grupo Apache Spark
Para ejecutar los cuadernos de transformación más adelante en este tutorial, necesita un grupo Apache Spark en su espacio de trabajo.
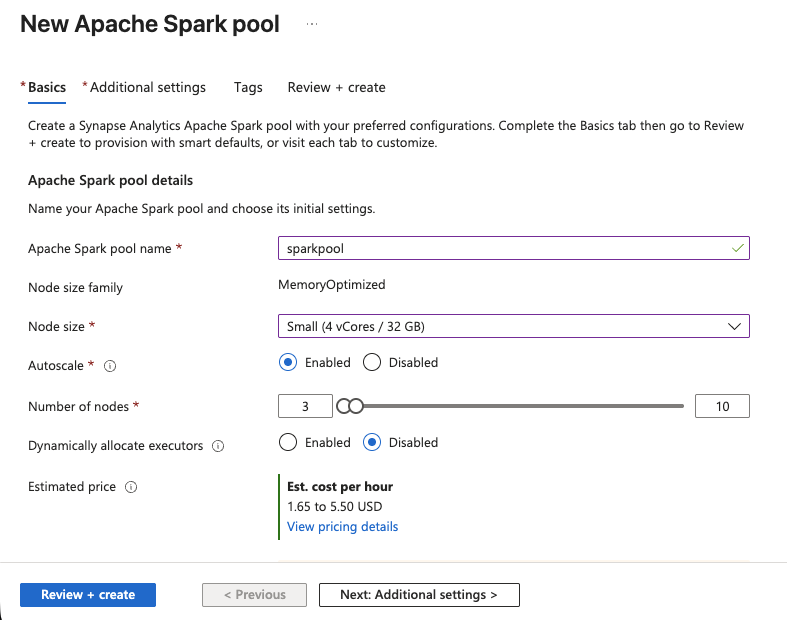
- En Synapse Studio, vaya a Administrar > Pools de Apache Spark > Nuevo.
- Asigne un nombre al grupo, por ejemplo,
sparkpool. - Establezca el tamaño del nodo en Pequeño (4 vCores / 32 GB), lo cual es suficiente para las transformaciones de datos SERP.
- Habilite Autoscale y establezca el rango en 3-5 nodos.
- Haga clic en Revisar + Crear y, a continuación, en Crear.
El grupo Spark estará listo en unos momentos. Ahora dispone de potencia de cálculo para ejecutar cuadernos PySpark.
Paso 3: Crear el canal de ingestión
Ahora creará un canal de Synapse que llama a la API SERP de Bright Data para un conjunto de palabras clave rastreadas y envía los resultados a su lago de datos.
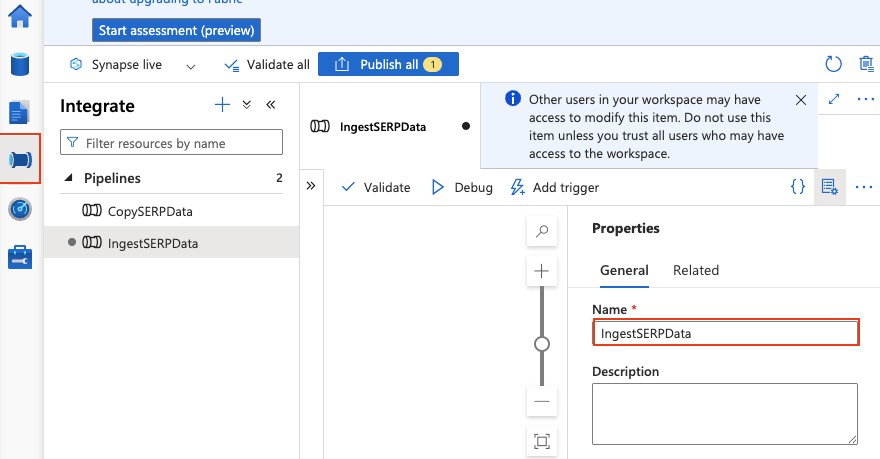
Crear una nueva canalización
- Vaya a Integrar > + > Canalización.
- Asigne el nombre
IngestSERPData.
Añada los parámetros del canal
Haga clic en el fondo del lienzo del pipeline para abrir las propiedades del pipeline. Vaya a la pestaña Parámetros y añada:
| Nombre | Tipo | Valor predeterminado |
|---|---|---|
Palabras clave |
Matriz | ["herramientas de Scraping web", "Proxy", "API de extracción de datos"] |
Estas son las palabras clave para las que desea realizar un seguimiento de las clasificaciones. Puede modificar esta lista en cualquier momento.
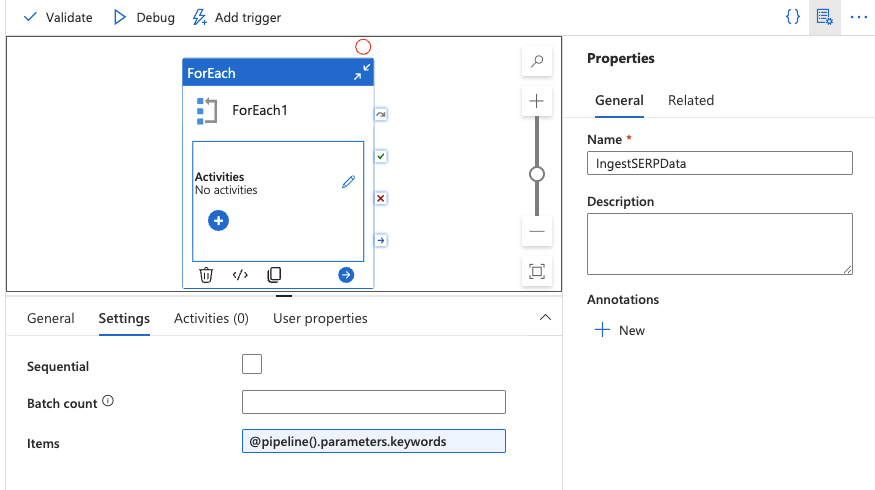
Añadir una actividad ForEach
- Arrastre una actividad ForEach al lienzo desde el panel Actividades.
- En la pestaña Configuración, establezca el campo Elementos en:
@pipeline().parameters.keywords
Esto iterará sobre cada palabra clave de su matriz.
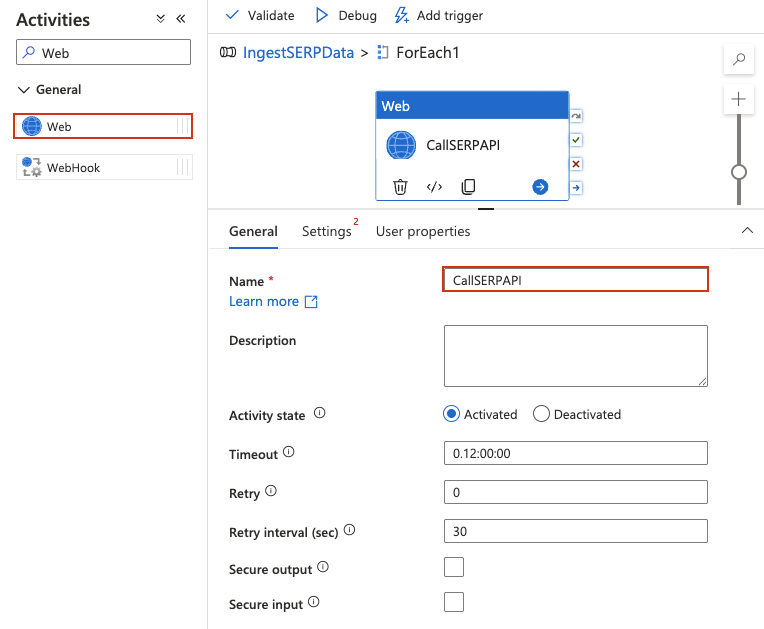
Añada una actividad Web dentro de ForEach
Una actividad Web llama directamente a una API REST, sin necesidad de Conjuntos de datos ni servicios vinculados para la solicitud en sí.
- Haga doble clic en la actividad ForEach para abrir su lienzo interno. Debería ver que el encabezado del diseñador cambia para indicar que se encuentra dentro del ámbito ForEach (similar a una ruta de navegación:
IngestSERPData > ForEach1). - En el panel Actividades de la izquierda, expanda General y arrastre una actividad web al lienzo interno.
- Asigne un nombre, como
CallSERPAPI.
Configurar la actividad web
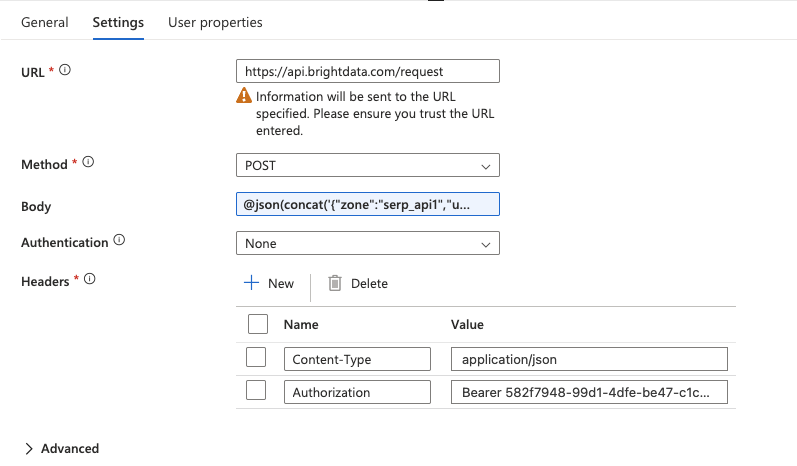
Haga clic en la actividad Web para seleccionarla, luego vaya a la pestaña Configuración y configure:
- URL: escriba el punto final completo de la API directamente en el campo:
https://api.brightdata.com/request- Método: Seleccione
POSTen el menú desplegable. - Encabezados: haga clic dos veces en + Añadir encabezado para añadir: Nombre Valor
Tipo de contenidoapplication/jsonAutorizaciónPortador SU_CLAVE_DE_API_DE_BRIGHT_DATA - Cuerpo: aquí es donde se pasa la solicitud de la API SERP con la palabra clave actual del bucle ForEach. Escriba la siguiente expresión directamente en el campo Cuerpo (no utilice la ventana emergente «Añadir contenido dinámico»):
@concat('{"zona":"YOUR_SERP_API_ZONA","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')Reemplace YOUR_SERP_API_ZONE por el nombre real de su zona en el panel de control de Bright Data.
Importante: La
@debe ser el primer carácter del campo, sin espacios al principio. Esto le indica a Synapse que evalúe el texto como una expresión. Si se ingresa correctamente, el campo resaltará la expresión. Si aparece como texto sin formato, elimínelo y vuelva a escribirlo, asegurándose de que@esté en la posición cero.Qué hace: La función
item()devuelve la palabra clave actual del bucle ForEach (por ejemplo,«herramientas de Scraping web»). La funciónreplace()sustituye los espacios por caracteres+para formar un parámetro de consulta URL válido. La funciónconcat()construye el cuerpo completo de la solicitud JSON como una sola cadena.
- Autenticación: Establecida en
Ninguna(la autenticación ya se gestiona a través del encabezado Authorization).
Añadir un desencadenador de programación
- De vuelta en el lienzo principal de la canalización, haga clic en Añadir desencadenador > Nuevo/Editar.
- Seleccione Nuevo y establezca una recurrencia diaria (por ejemplo, 6:00 a. m. UTC).
- Haga clic en Aceptar y, a continuación, en Publicar todo para guardar e implementar el canal.
Para probarlo inmediatamente, haga clic en Activar ahora > Aceptar. Vaya a Monitor > Ejecuciones de canalización para ver la ejecución. Debería ver que la canalización se ejecuta correctamente y encontrar archivos JSON en su lago de datos en la ruta raw/serp/.
Vuelva al lienzo principal del canal
Haga clic en el nombre del canal (IngestSERPData) en la ruta de navegación situada en la parte superior del diseñador para volver al lienzo principal. Debería ver la actividad ForEach con un indicador que muestra que contiene actividades secundarias.
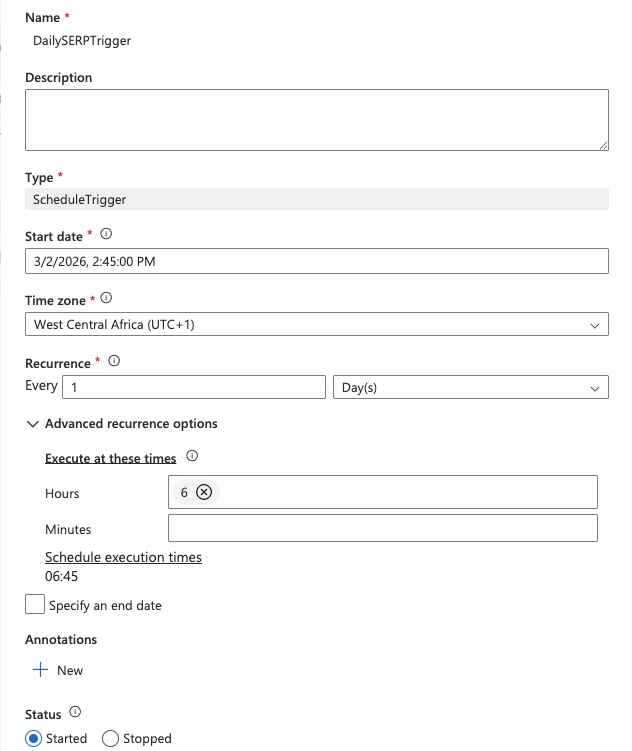
Añada un desencadenador de programación
- Haga clic en Añadir desencadenador > Nuevo/Editar en la parte superior del diseñador de canalizaciones.
- En el menú desplegable, seleccione Nuevo.
- Asigne un nombre al desencadenador (por ejemplo,
DailySERPTrigger), establezca el Tipo en Programación y configure:
- Fecha de inicio: Fecha de hoy
- Recurrencia: Cada
1día - A estas horas:
6(para las 6:00 a. m. UTC)
- Haga clic en Aceptar y, a continuación, confirme los parámetros del desencadenador.
- Haga clic en Publicar todo en la parte superior de Synapse Studio para guardar e implementar todo.
Pruebe el canal
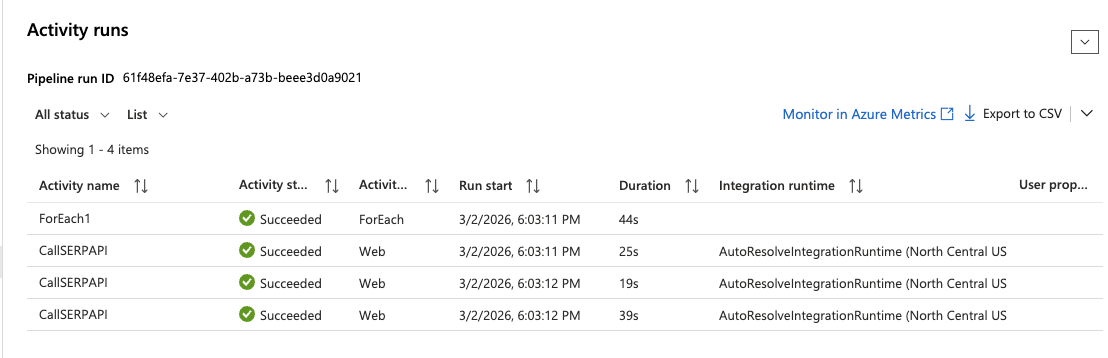
Para ejecutar el proceso inmediatamente sin esperar al desencadenador programado:
- Haga clic en Activar ahora > Aceptar en la parte superior del diseñador de canalizaciones.
- Vaya a Monitor > Ejecuciones de canalización en el menú de la izquierda.
- Espere a que finalice la ejecución; debería ver un estado verde de Éxito.
- Haga clic en la ejecución y expanda la actividad ForEach para inspeccionar cada ejecución de la actividad web. Haga clic en cualquier iteración
de CallSERPAPIpara ver la respuesta completa de la API en la sección Salida.
Paso 4: Recopilar y transformar datos con Apache Spark
La actividad web del paso 3 validó que la integración de la API SERP funciona y demostró la orquestación de la canalización con programación. Para el paso de recopilación y transformación de datos, utilizará un cuaderno de Apache Spark que llama a la API SERP directamente utilizando Python, guarda las respuestas sin procesar en su lago de datos y las transforma en tablas Delta listas para el análisis.
Este enfoque es estándar en la ingeniería de datos: las canalizaciones se encargan de la orquestación y la programación, mientras que los cuadernos se encargan de la lógica real del procesamiento de datos.
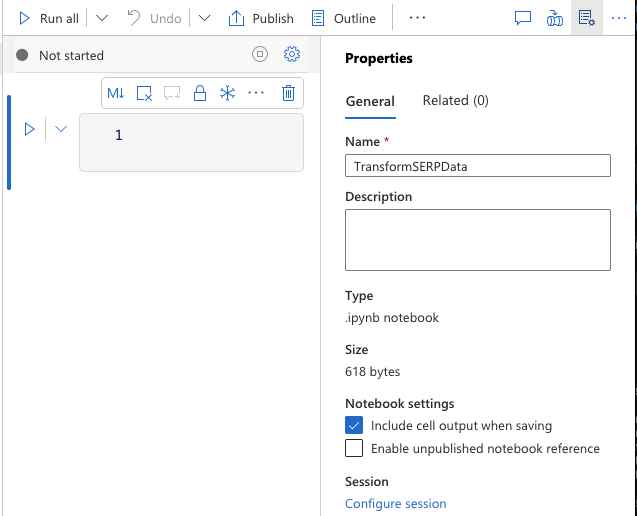
Crear un cuaderno de Spark
- Vaya a Develop > + > Notebook.
- Asigne el nombre
TransformSERPData. - Añádalo a su grupo Apache Spark
sparkpool. - Asegúrese de que PySpark (Python) está seleccionado como lenguaje.
Celda 1: Recopilar datos SERP y guardarlos en el lago de datos
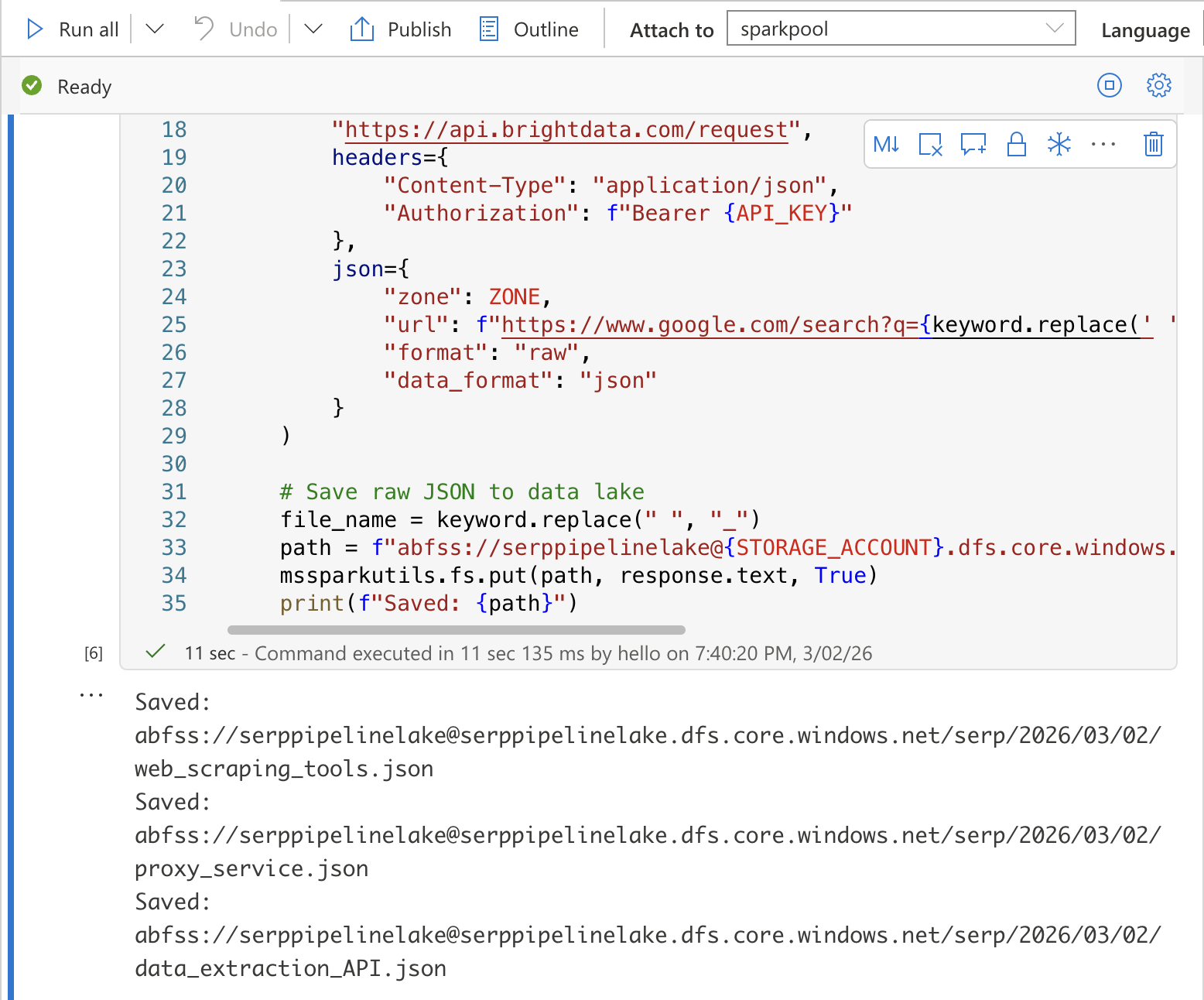
En la primera celda, añada el siguiente código. Esto llama a la API SERP de Bright Data para cada palabra clave y guarda las respuestas JSON sin procesar en su lago de datos:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Configuración
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
Zona = "YOUR_SERP_API_ZONA"
STORAGE_ACCOUNT = "YOUR_STORAGE_ACCOUNT"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Recopilar datos SERP para cada palabra clave
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Llamar a la API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zona": ZONA,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# Guardar JSON sin procesar en el lago de datos
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"Saved: {path}")Reemplace YOUR_BRIGHT_DATA_API_KEY, YOUR_SERP_API_ZONE y YOUR_STORAGE_ACCOUNT con sus valores reales.
Consejo de seguridad: en producción, almacene su clave API en Azure Key Vault y recupérela utilizando
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")en lugar de codificarla de forma rígida.
Ejecute la celda pulsando Mayús + Intro. Debería ver un resultado que confirme que cada archivo se ha guardado en el lago de datos.
Celda 2: Transformar y aplanar los datos SERP
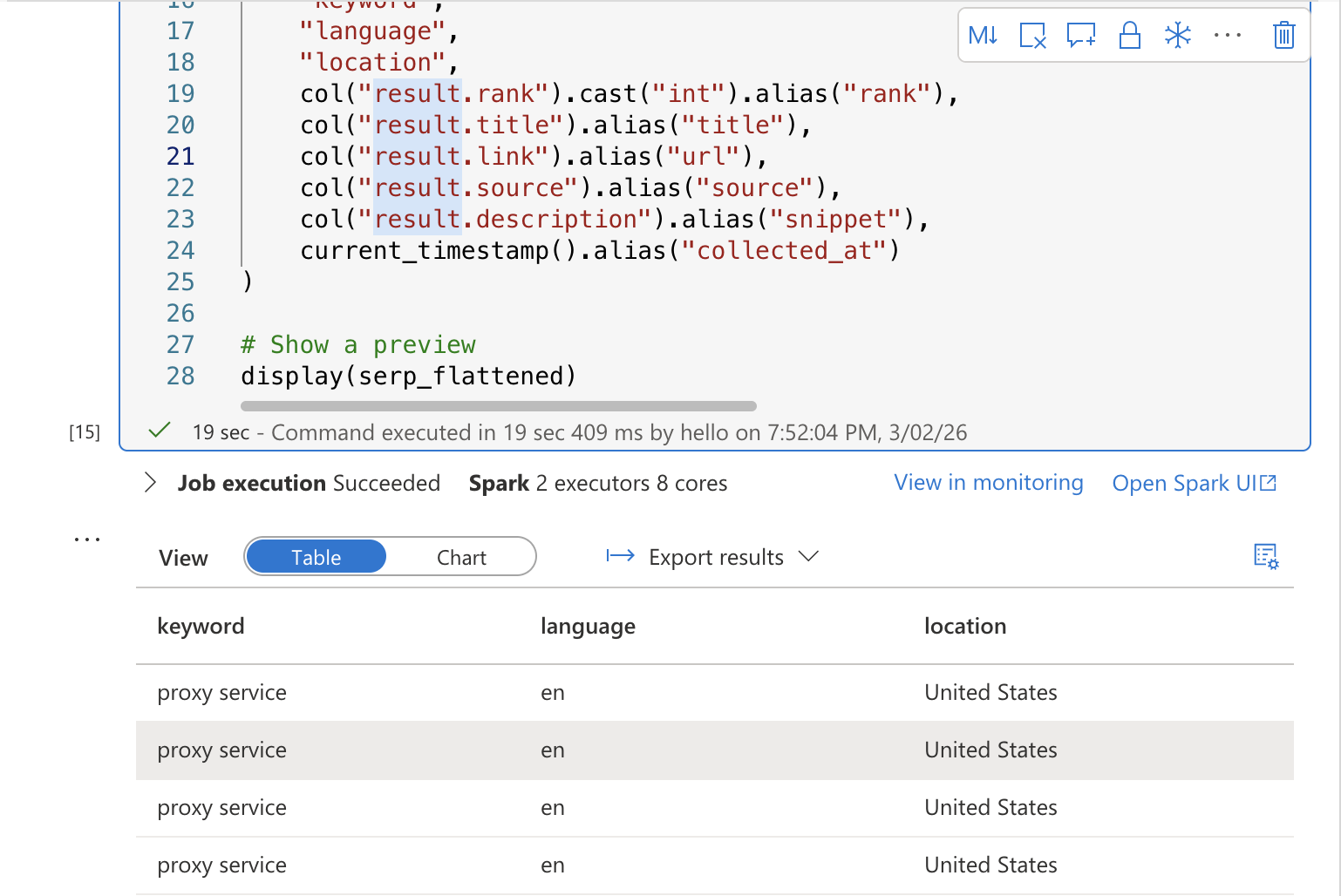
En una nueva celda, añada el código de transformación que lee el JSON sin procesar y lo aplana en una tabla estructurada:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# Leer los datos SERP sin procesar del lago de datos
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# Aplanar: extraer la palabra clave de general.query y desglosar los resultados orgánicos
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
# Mostrar una vista previa
display(serp_flattened)Ejecute la celda. Debería ver una tabla de vista previa que muestra los resultados SERP aplanados con columnas para la palabra clave, la clasificación, el título, la URL, el fragmento y la marca de tiempo de la recopilación.
Celda 3: Guardar en una tabla Delta
En una tercera celda, escriba los datos transformados en una tabla Delta para el análisis SQL:
# Escriba los datos transformados como una tabla Delta en su lago de datos
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("Datos escritos en curated/serp_rankings") 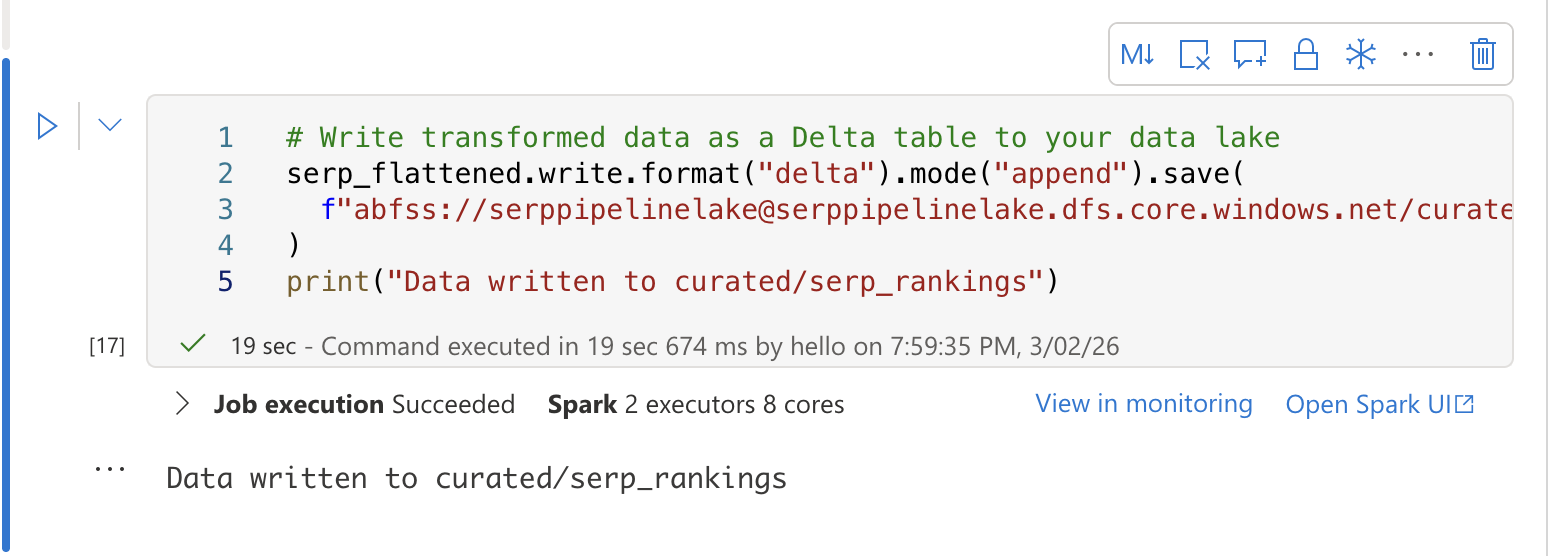
Añada el cuaderno a su canalización
- Vuelva a su canalización
IngestSERPDataen el centro Integrate. - Arrastra una actividad Notebook al lienzo, fuera y después de la actividad ForEach.
- En la pestaña Configuración, seleccione su cuaderno
TransformSERPDatay adjúntelo asparkpool. - Conecte la actividad ForEach a la actividad Notebook con una dependencia Success (arrastre la flecha verde).
- Haga clic en Publicar todo para guardar.
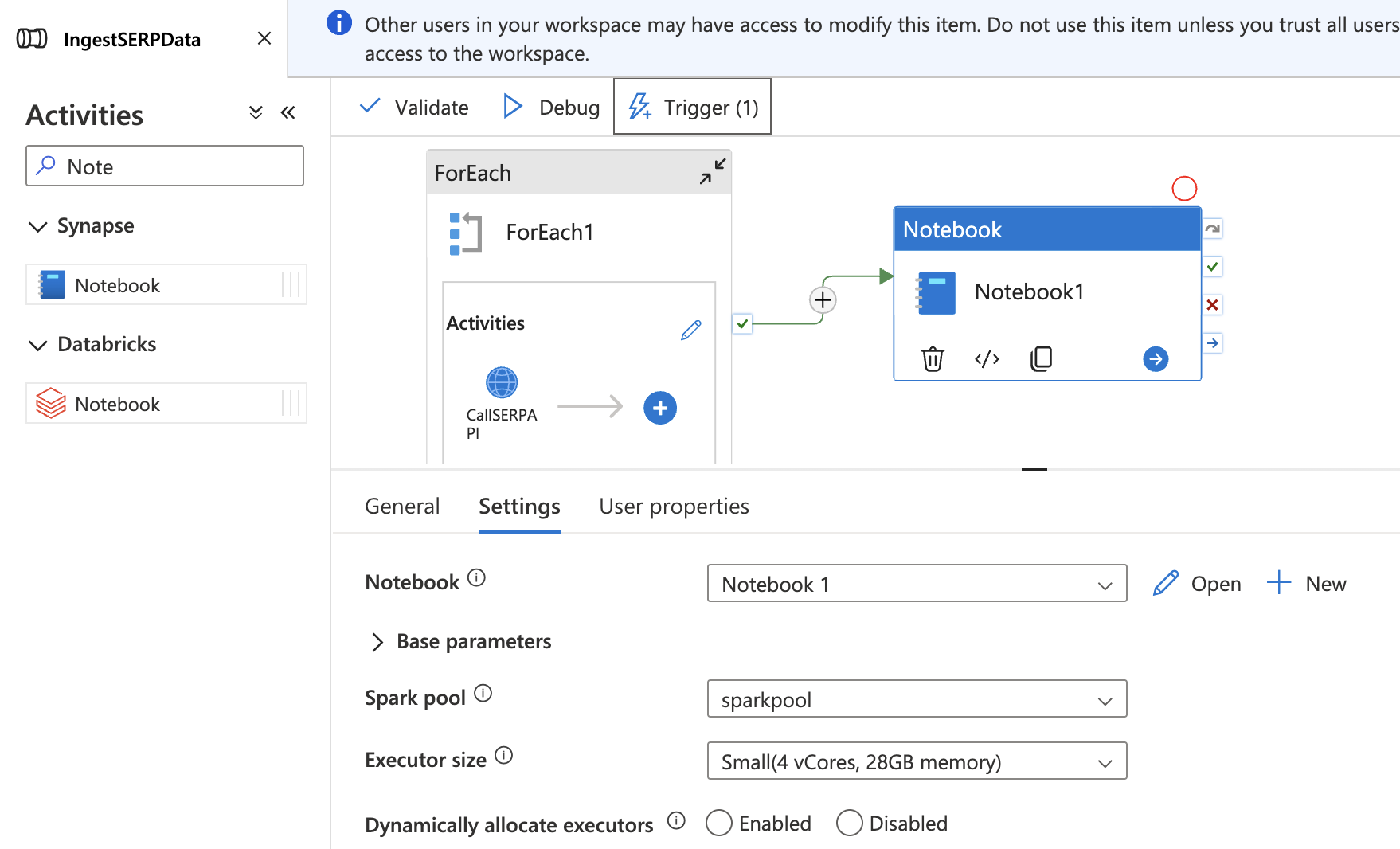
Ahora la canalización completa se ejecuta de principio a fin: recopilar datos SERP → aterrizar en el lago de datos → transformar en una tabla Delta.
Paso 5: Analizar clasificaciones con SQL
Una vez que los datos estén en una tabla Delta, puede consultarlos directamente utilizando el grupo SQL sin servidor de Synapse, sin necesidad de aprovisionamiento adicional. El grupo SQL sin servidor lee los archivos Delta directamente desde el lago de datos utilizando la función OPENROWSET.
Crear una base de datos
Vaya a Desarrollar > + > Script SQL. Asegúrese de que Integrado (sin servidor) esté seleccionado como grupo SQL en la parte superior del editor de scripts. Ejecute lo siguiente para crear una base de datos dedicada para sus análisis SERP:
CREATE DATABASE serp_analytics;Una vez creada la base de datos, cambie a ella seleccionando serp_analytics en el menú desplegable de bases de datos en la parte superior del editor de scripts.
Realice un seguimiento de los cambios en la clasificación a lo largo del tiempo
Cree un nuevo script SQL (o borre el anterior) y ejecute la siguiente consulta. Esto lee la tabla Delta directamente desde su lago de datos utilizando OPENROWSET:
-- Vea cómo cambian las clasificaciones día a día para cada palabra clave y URL
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = 'Scraping web tools'
ORDER BY collected_at DESC, rank ASC;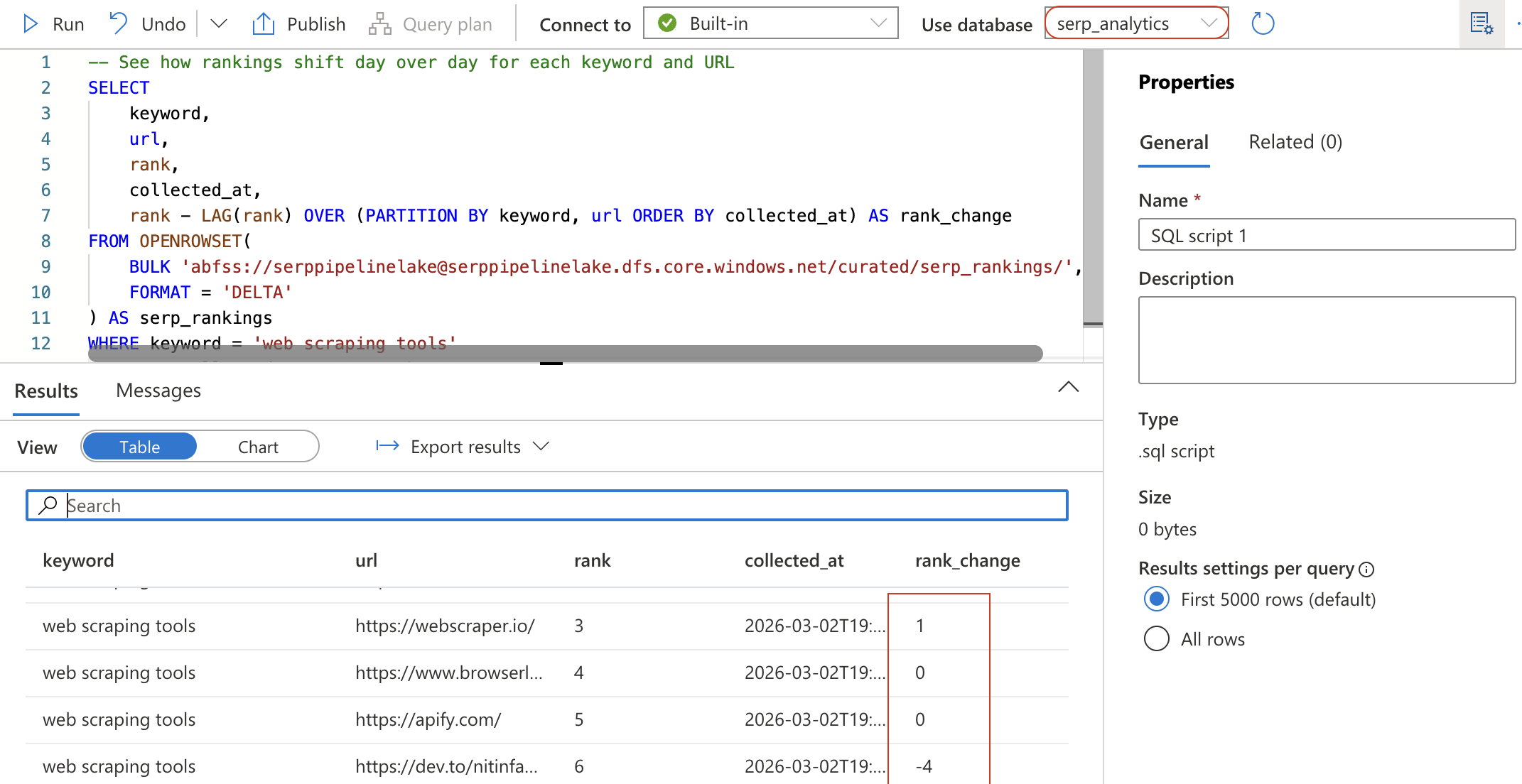
Esta consulta utiliza la función de ventana LAG para calcular cómo ha cambiado la posición de cada URL desde la recopilación anterior. Un rank_change negativo significa que la URL ha subido en la clasificación.
Crear una vista resumida para Power BI
Para que Power BI pueda utilizar fácilmente los datos, cree una vista que resuma las clasificaciones diarias por palabra clave:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
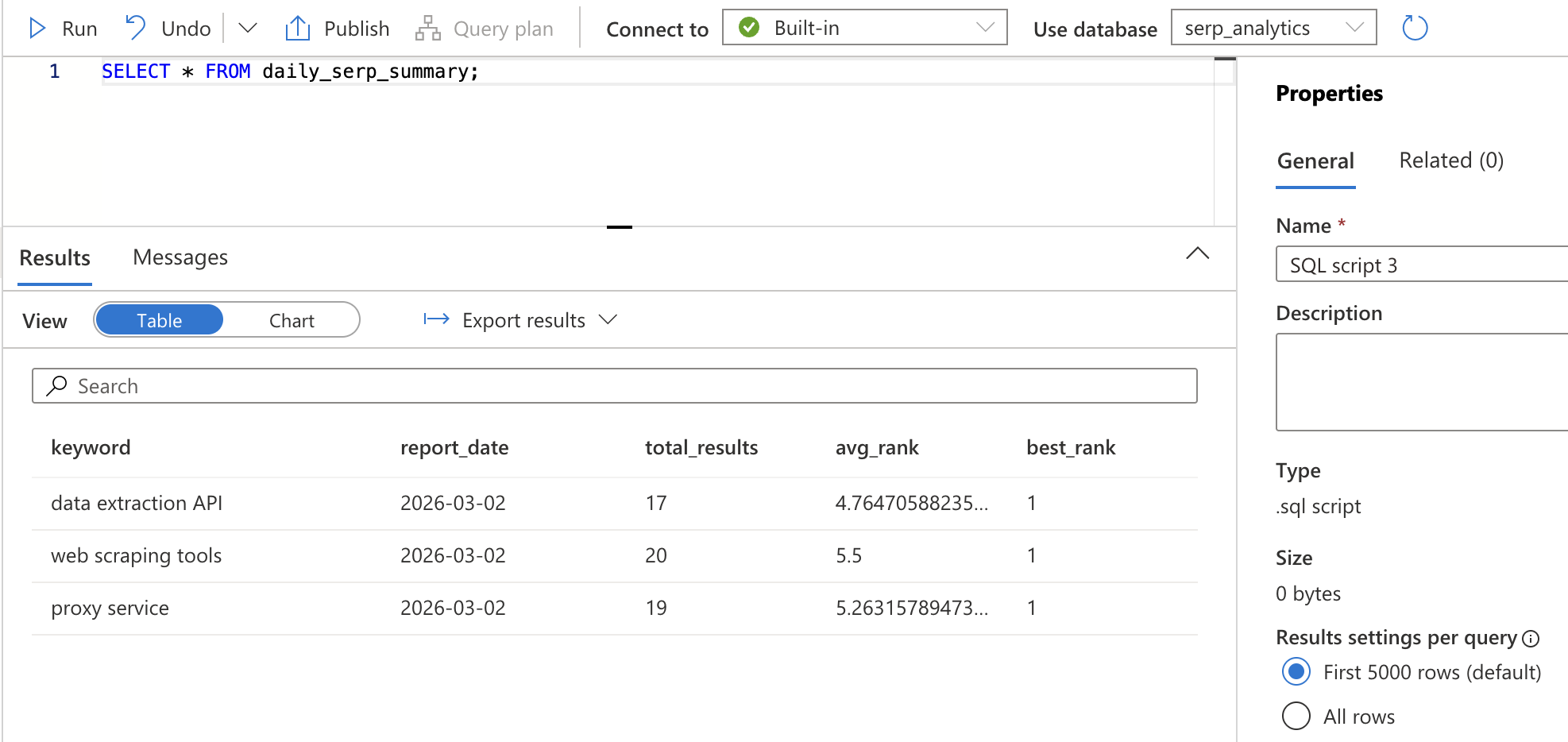
GROUP BY keyword, CAST(collected_at AS DATE);Haga clic en Ejecutar. Esto crea una vista, una consulta guardada a la que se puede hacer referencia por su nombre. Compruebe que funciona ejecutando:
SELECT * FROM daily_serp_summary;Debería ver una fila por palabra clave por día, con el número total de resultados, la clasificación media y la mejor clasificación.
Paso 6: Inspeccione los resultados
Una vez que se haya ejecutado todo el proceso, puede inspeccionar cada etapa desde Synapse Studio.
Vaya a Monitor > Ejecuciones del proceso y haga clic en la ejecución más reciente para inspeccionarla. Verá una representación visual de cada paso, que muestra:
- La actividad ForEach con cada iteración de palabra clave y los resultados de la actividad Web.
- La actividad Notebook con los detalles de ejecución del trabajo Spark.
Expanda la actividad ForEach para verificar que los datos SERP se recuperaron correctamente para cada palabra clave. Haga clic en cualquier ejecución de la actividad web CallSERPAPI para ver los detalles de la solicitud/respuesta en las secciones Entrada y Salida.
Vaya a Data > Linked > su cuenta de almacenamiento para explorar los archivos JSON sin procesar en la carpeta raw/serp/. Debería ver carpetas divididas por fecha con un archivo JSON por palabra clave.
Por último, abra el centro de desarrollo, vaya a su cuaderno TransformSERPData y compruebe la tabla Delta ejecutando:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;Debería ver filas estructuradas con la palabra clave, la clasificación, el título, la URL, el fragmento y la marca de tiempo de la recopilación, datos limpios y listos para el análisis, creados a partir de resultados SERP sin procesar. La API SERP de Bright Data se encargó de la parte difícil: obtener de forma fiable los resultados de búsqueda de Google a gran escala, eludiendo las medidas antibots y los limitadores de velocidad, y devolviendo datos estructurados listos para su canalización.
Yendo más allá
Este ejemplo muestra un rastreador de clasificación de palabras clave, pero puede ampliar su canalización de Synapse en muchas direcciones:
- Reemplaza la llamada a la API SERP por la API Web Scraper de Bright Data para recopilar precios de productos, reseñas o listados de empleos, y crea paneles de inteligencia competitiva de precios.
- Añada un segundo cuaderno Spark para ejecutar análisis de opiniones en fragmentos SERP, puntuando cada resultado según su framing positivo o negativo.
- Conecte las tablas Delta seleccionadas a Azure Machine Learning para realizar análisis predictivos, como pronosticar cambios en el posicionamiento o identificar tendencias de búsqueda emergentes.
- Cree una arquitectura de nube híbrida en la que los datos SERP se almacenen en Azure Data Lake, mientras que los datos internos confidenciales permanezcan en las instalaciones, con Synapse consultando ambos a través de consultas federadas.
- Reenvíe los datos transformados a un flujo de comandos de Azure AI Foundry para realizar análisis basados en LLM, combinando la ingeniería de datos de Synapse con las capacidades de IA de AI Foundry.
- Integre herramientas como LangChain o CrewAI para crear flujos de trabajo agenticos que consuman sus datos SERP seleccionados.
¡Las posibilidades son prácticamente infinitas!
Conclusión
En esta entrada del blog, ha aprendido a utilizar la API SERP de Bright Data para obtener resultados de búsqueda actualizados de Google e integrarlos en un canal de datos completo en Azure Synapse Analytics.
El canal que se muestra aquí es ideal para cualquiera que desee crear un rastreador de clasificación de palabras clave automatizado que recopile continuamente datos SERP, los transforme en tablas listas para el análisis y ofrezca información a través de consultas SQL y paneles de Power BI. A diferencia del enfoque de Azure AI Foundry, que es ideal para la ingeniería de prompts basada en IA y los flujos de trabajo RAG, Azure Synapse Analytics destaca en la ingesta, transformación y almacenamiento de datos a gran escala para la inteligencia empresarial y el análisis.
Para crear canalizaciones de datos más avanzadas, explore el conjunto completo de herramientas de Scraping web de Bright Data para recuperar, validar y transformar datos web en tiempo real. Para profundizar en los patrones de arquitectura de canalizaciones de datos, el blog de Bright Data cubre los fundamentos.
¡Regístrese hoy mismo para obtener una cuenta gratuita de Bright Data y comience a experimentar con nuestras soluciones de datos web preparadas para la IA!