En esta guía aprenderás:
- Qué es un Scraper de Alibaba y cómo funciona
- Los tipos de datos que puede recuperar automáticamente de Alibaba
- Cómo crear un script de scraping de Alibaba utilizando Python
¡Empecemos!
¿Qué es un Scraper de Alibaba?
Un scraper de Alibaba es unbot de Scraping webdiseñado para extraer automáticamente datos de las páginas de Alibaba. Funciona simulando el comportamiento de navegación de un usuario para navegar por las páginas de Alibaba. Gestiona interacciones como la paginación y recupera información estructurada, como detalles de productos, precios y datos de empresas.
Datos que se pueden extraer de Alibaba
Alibaba es un tesoro de información valiosa, como por ejemplo:
- Detalles del producto: nombres, descripciones, imágenes, rangos de precios, información del vendedor y más.
- Información de la empresa: nombres de empresas, detalles del fabricante, información de contacto y valoraciones.
- Comentarios de los clientes: valoraciones, reseñas de productos y mucho más.
- Logística y disponibilidad: estado de las existencias, cantidades mínimas de pedido, opciones de envío y mucho más.
- Categorías y etiquetas: categorías de productos, etiquetas relevantes o rótulos.
¡Descubre cómo extraerlos!
Extracción de datos de Alibaba en Python: guía paso a paso
En esta sección, aprenderá a crear un Scraper de Alibaba en un tutorial guiado.
El objetivo es guiarte en la creación de un script de Python que extraiga automáticamente datos de la página «laptop» de Alibaba:
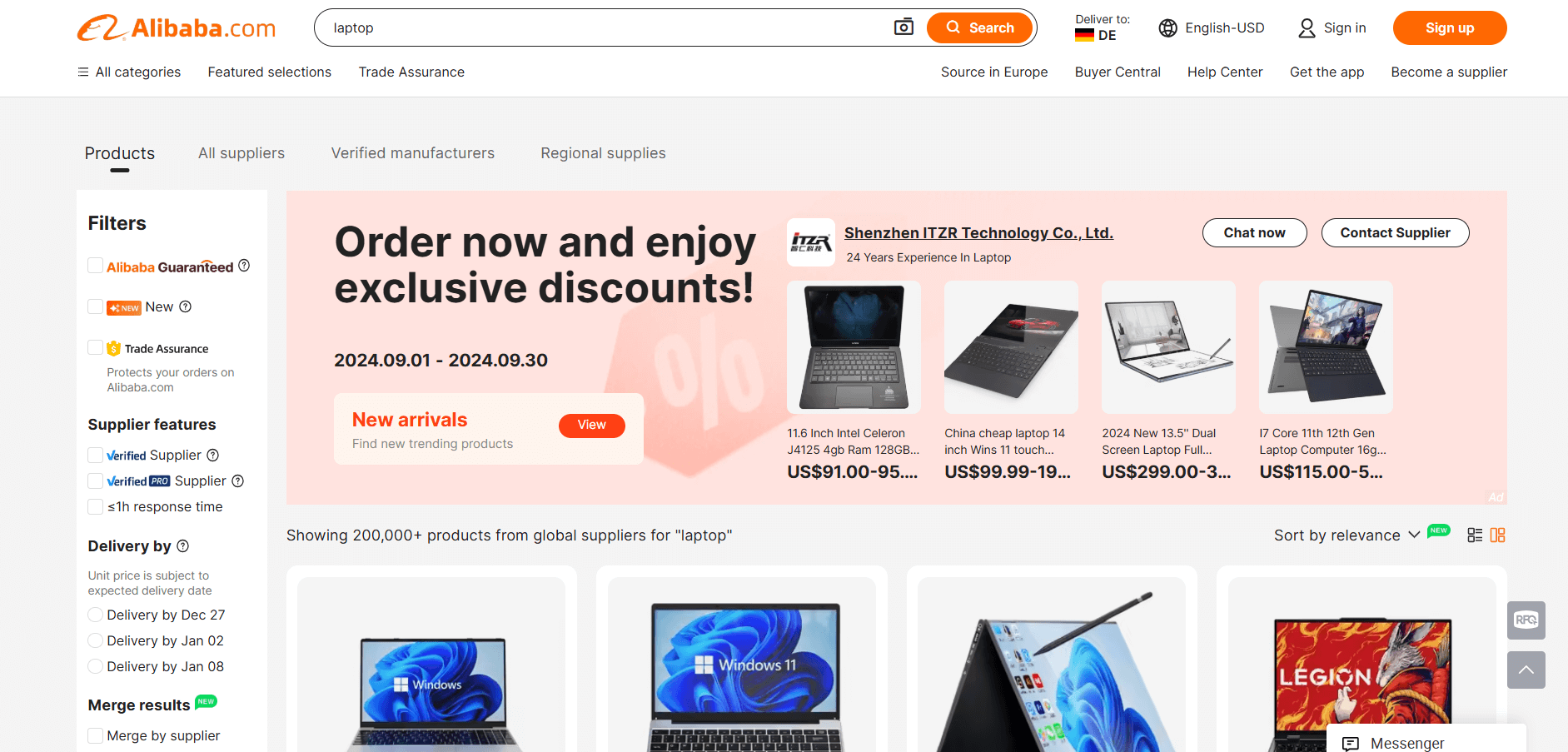
¿Listo? ¡Siga los pasos que se indican a continuación!
Paso n.º 1: Configuración del proyecto
En primer lugar, comprueba que tienes Python 3 instalado en tu equipo. Si no es así, descárgalo y sigue el asistente de instalación.
Ahora, utiliza el siguiente comando para crear un directorio para tu proyecto:
mkdir alibaba-scraper
La carpeta alibaba-scraper es donde colocarás el Scraper Python Alibaba.
Introdúzcalo en el terminal y cree un entorno virtual dentro de él:
cd alibaba-Scraper
python -m venv env
Cargue la carpeta del proyecto en su IDE de Python favorito, como Visual Studio Code con la extensión Python o PyCharm Community Edition.
Crea un archivo scraper.py en el directorio del proyecto, que ahora debería contener esta estructura de archivos:

scraper.py es actualmente un script Python en blanco, pero pronto contendrá la lógica de scraping deseada.
En la terminal del IDE, activa el entorno virtual. En Linux o macOS, ejecuta este comando:
./env/bin/activate
De forma equivalente, en Windows, ejecute:
env/Scripts/activate
¡Genial, tu entorno Python para el Scraping web de Alibaba ya está listo!
Paso n.º 2: selecciona la biblioteca de scraping
El objetivo ahora es determinar si Alibaba utiliza páginas dinámicas o estáticas. Para ello, abra la página de destino de Alibaba en su navegador en modo incógnito. A continuación, haga clic con el botón derecho del ratón en el fondo, seleccione «Inspeccionar», vaya a la pestaña «Red», filtre por «Fetch/XHR» y vuelva a cargar la página:
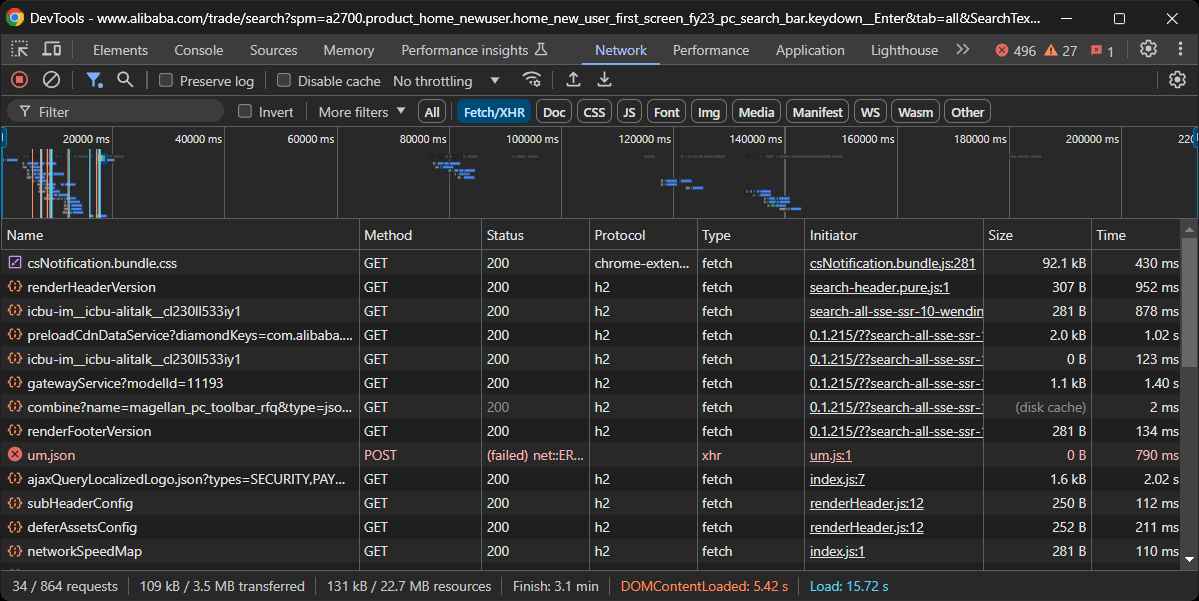
En esta sección de DevTools, observe si la página realiza alguna solicitud dinámica significativa. En este caso, sí lo hace, lo que indica que la página es dinámica. Un análisis más detallado revela que la página utiliza JavaScript para la renderización.
En otras palabras, necesitas una herramienta de automatización del navegador como Selenium para extraer datos de Alibaba de forma eficaz. Obtén más información en nuestro tutorial sobre el Scraping web con Selenium.
Selenium le permite controlar mediante programación un navegador web, simulando las interacciones del usuario y permitiéndole extraer contenido renderizado por JavaScript. ¡Es hora de instalarlo y empezar a utilizarlo!
Paso n.º 3: Instalar y configurar Selenium
En un entorno virtual activado, instala Selenium con este comando:
pip install -U selenium
Importe Selenium en scraper.py y cree un objeto WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# inicializar una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
El código anterior inicializa una instancia de WebDriver para controlar una instancia de Chrome. Tenga en cuenta que Alibaba tiene algunas medidas antiscraping que pueden bloquear los navegadores sin interfaz gráfica.
Por lo tanto, no debe establecer el indicador --headless. Como solución alternativa, considere explorar Playwright Stealth.
Como última línea de su Scraper, recuerde cerrar el controlador web:
driver.quit()
¡Genial! Ya tiene todo configurado para empezar a scrapear Alibaba.
Paso n.º 4: Conéctese a la página de destino
Utilice el método get() expuesto por el objeto Selenium WebDriver para visitar la página deseada:
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
driver.get(url)
El archivo scraper.py ahora contendrá estas líneas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# inicializar una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# la url de la página de destino
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# conectarse a la página de destino
driver.get(url)
# lógica de scraping...
# cerrar el navegador
driver.quit()
Coloca un punto de interrupción de depuración en la última línea e inicia el script con el depurador. Esto es lo que deberías ver:
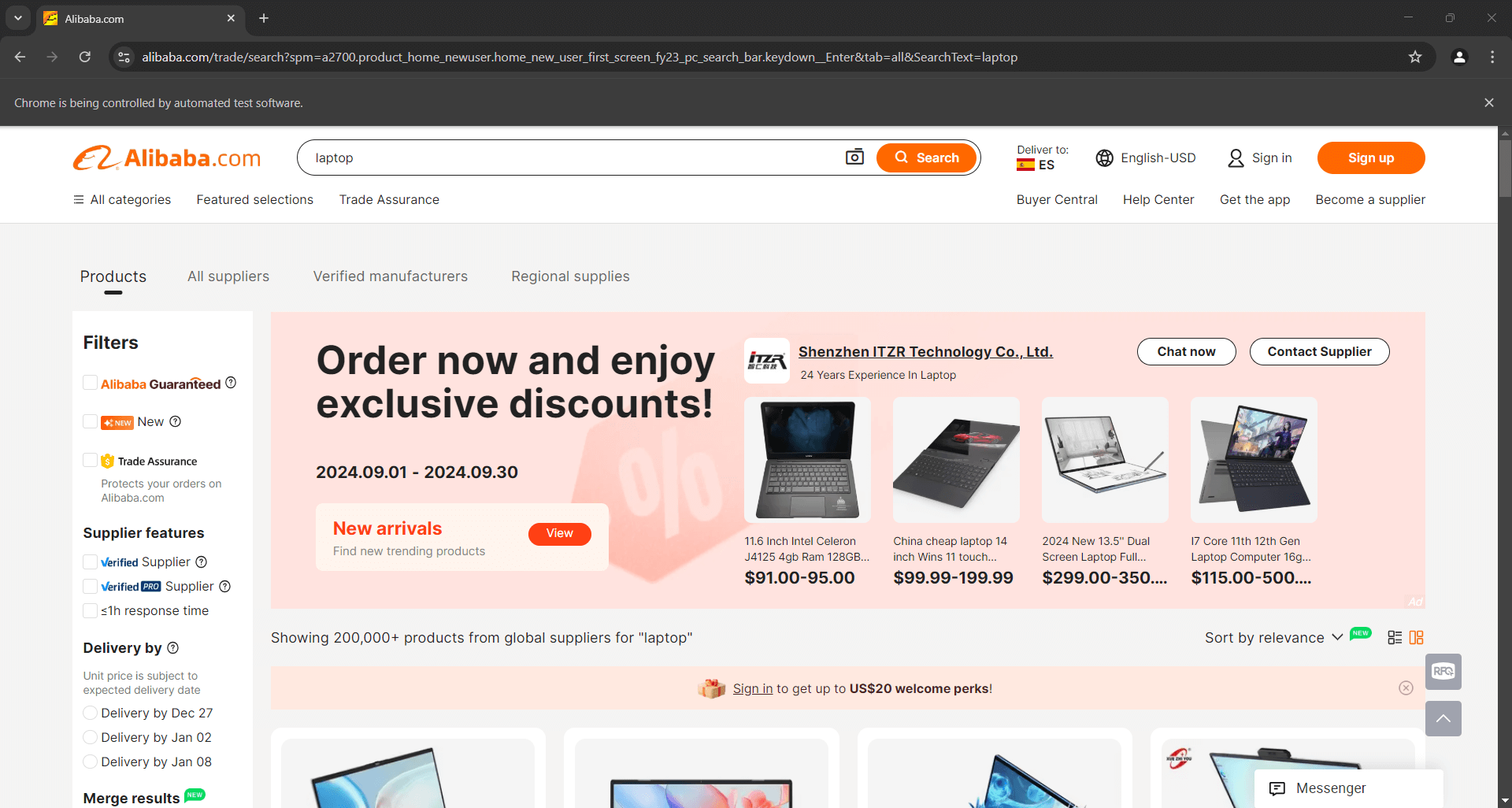
El mensaje «Chrome está siendo controlado por un software de pruebas automatizado» certifica que Selenium está controlando Chrome como se esperaba. ¡Bien hecho!
Paso n.º 5: Seleccionar los elementos del producto
Dado que la página de productos de Alibaba contiene varios productos, primero debe inicializar una estructura de datos para almacenar los datos extraídos. Una matriz funcionará perfectamente para este propósito:
productos = []
A continuación, inspeccione los elementos HTML de los productos de la página para comprender:
- Cómo seleccionarlos
- Qué datos contienen
- Cómo extraer esos datos
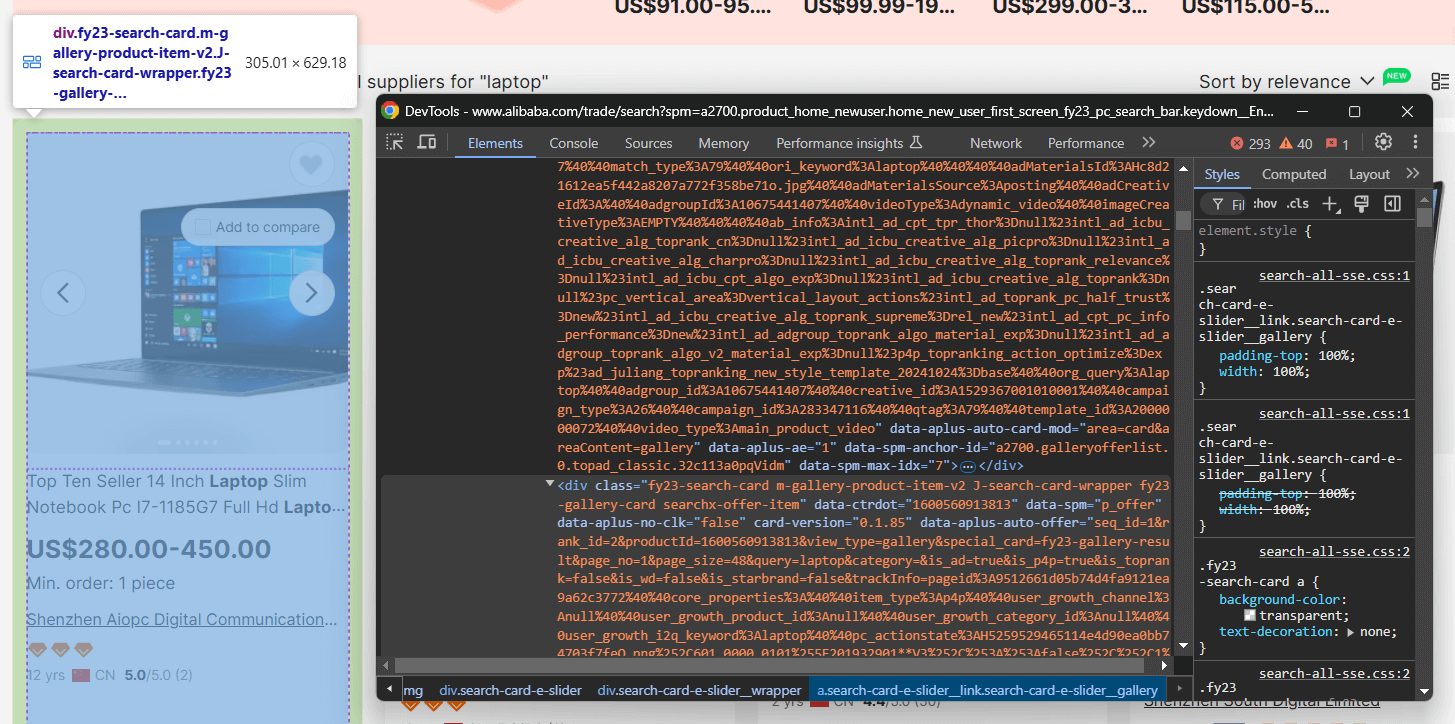
Aquí puede ver que cada elemento de producto es un nodo .m-gallery-product-item-v2.
Utilice Selenium para seleccionar todos los elementos de producto:
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
find_elements() aplica la estrategia de selección dada para recuperar elementos de la página. En el caso anterior, la estrategia de selección es un selector CSS.
No olvide importar By:
from selenium.webdriver.common.by import By
Itera sobre los elementos seleccionados y prepárate para extraer datos de cada uno de ellos:
for product_element in product_elements:
# extrae datos de cada elemento de producto
¡Genial! Estás un paso más cerca de extraer con éxito los datos de Alibaba.
Paso n.º 6: extraer los elementos del producto
Inspecciona un elemento del producto para comprender su estructura HTML:
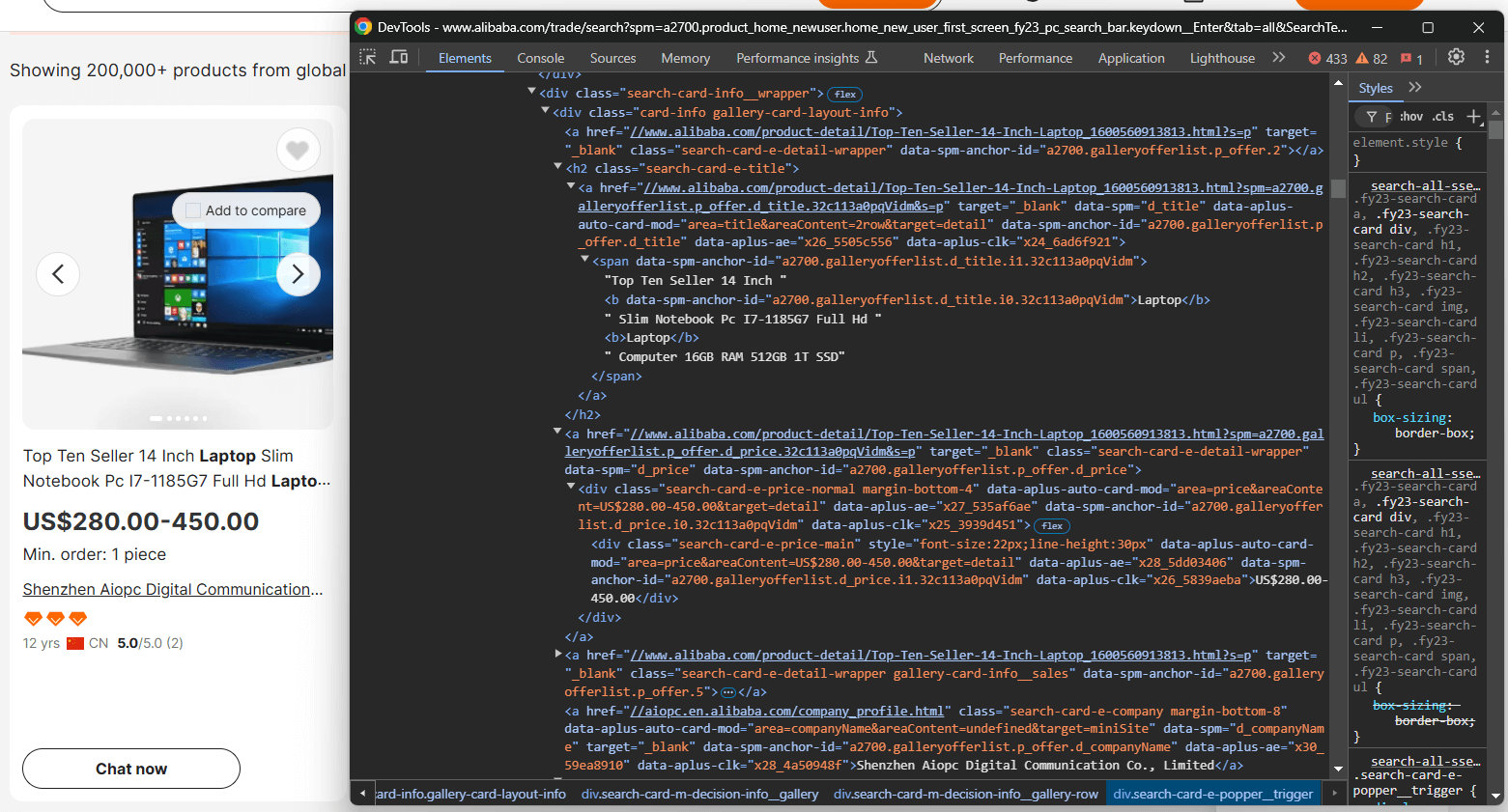
Aquí puede ver que puede extraer:
- La imagen del producto desde
.search-card-e-slider__img - La descripción del producto de
.search-card-e-title - El rango de precios del producto de
.search-card-e-price-main - La empresa/fabricante de
.search-card-e-company
En el bucle «for», traduce esa información a lógica de rastreo:
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
find_element() recupera el único elemento que coincide con el selector CSS dado. A continuación, puede acceder a su contenido de texto con el atributo text. Para obtener el valor del atributo HTML de un nodo, utilice el método get_attribute().
Utilice los datos extraídos para rellenar un diccionario de productos y añádalo a la matriz de productos:
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
products.append(product)
¡Fantástico! La lógica de extracción de datos de Alibaba está completa.
Paso n.º 7: Exportar los datos extraídos a CSV
Actualmente, los datos extraídos se almacenan en la matriz de productos. Para que sean accesibles y se puedan compartir con otras personas, es necesario exportarlos a un formato legible para los humanos, como un archivo CSV.
Utilice el siguiente código para crear y rellenar un archivo CSV con los datos extraídos:
csv_file_name = "products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image", "description", "price", "company"])
# escribir la fila del encabezado
writer.writeheader()
# escribir las filas de datos del producto
for product in products:
writer.writerow(product)
No olvides importar csv desde la biblioteca estándar de Python:
import csv
¡Vaya! Tu Scraper Aliaba está completo.
Paso n.º 8: Ponlo todo junto
A continuación se muestra el código final de tu script de scraping de Alibaba:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# inicializar una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# la URL de la página de destino
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# conectar a la página de destino
driver.get(url)
# dónde almacenar los datos extraídos
products = []
# seleccionar todos los elementos de producto de la página
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
# iterar sobre los nodos de producto y extraer datos de ellos
for product_element in product_elements:
# extraer los detalles del producto
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
# crear un diccionario de productos con los
# datos extraídos
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
# añadir los datos del producto a la matriz
products.append(product)
# definir el nombre del archivo CSV de salida
csv_file_name = "products.csv"
# abrir el archivo en modo escritura y crear un escritor CSV
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["img", "description", "price", "company"])
# escribe la fila del encabezado
writer.writeheader()
# escribe las filas de datos del producto
for product in products:
writer.writerow(product)
# cierra el navegador
driver.quit()
¡Con poco más de 60 líneas de código, acabas de crear un Scraper de Alibaba en Python!
Inicia el Scraper con el siguiente comando:
python3 script.py
O, en Windows:
python script.py
Aparecerá un archivo products.csv en la carpeta de tu proyecto. Ábrelo y verás:
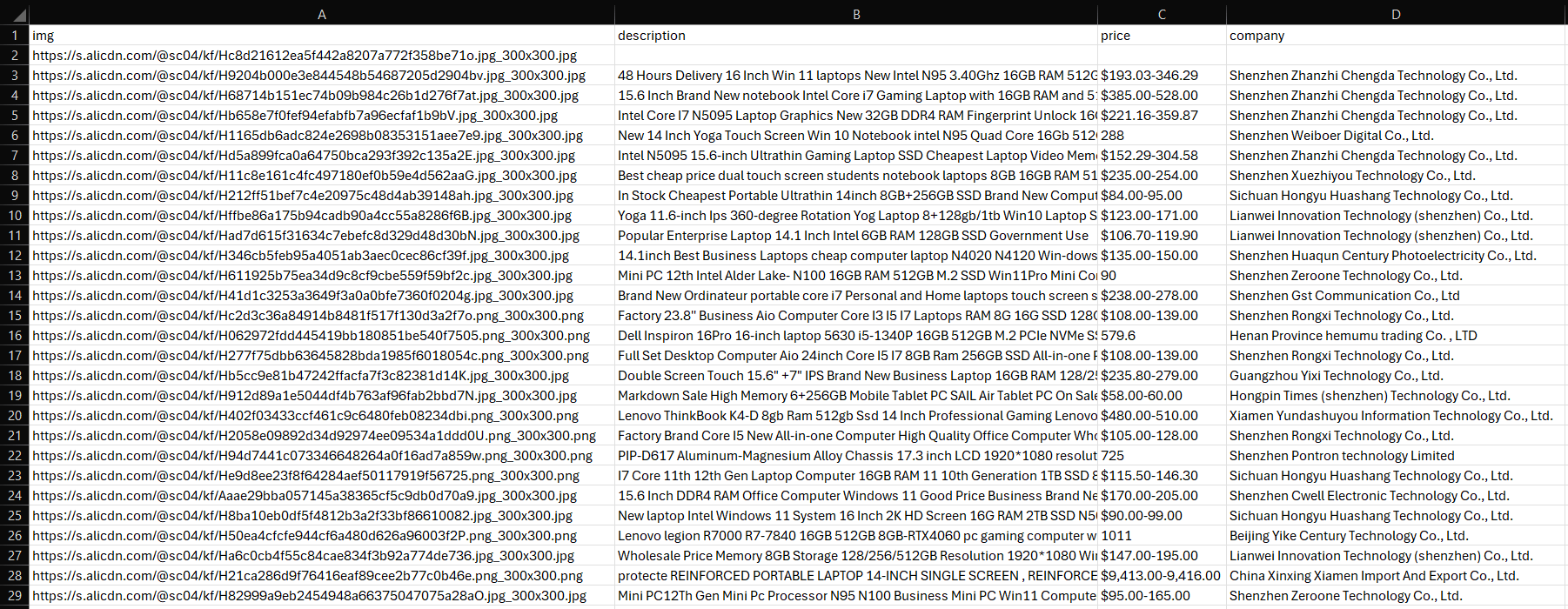
¡Et voilà! Misión completada. ¿Los siguientes pasos? Gestiona la paginación, implementa tu script, automatiza su ejecución y perfecciónalo aún más para obtener un rendimiento óptimo.
Conclusión
En este tutorial paso a paso, ha aprendido qué es un Scraper de Alibaba y los tipos de datos que puede recuperar. También ha visto cómo crear un script de Python para rastrear productos de Alibaba con menos de 100 líneas de código.
El problema es que el rastreo de Alibaba conlleva algunos retos. La plataforma emplea estrictas medidas anti-bot y adopta interacciones como la paginación que hacen que el proceso de rastreo sea más complejo. Crear una solución de rastreo de Alibaba escalable y eficaz puede ser bastante exigente.
¡Olvídate de esos retos con nuestra API Alibaba Scraper! Esta solución específica te permite recuperar datos del sitio de destino mediante simples llamadas a la API, sin riesgo de ser bloqueado.
Si el Scraping web no es su método preferido, pero sigue interesado en los datos de los productos, explore nuestros Conjuntos de datos de Alibaba listos para usar.
Cree hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos.