

Etsy es un sitio muy difícil de rastrear. Emplean diversas tácticas de bloqueo y cuentan con uno de los sistemas de bloqueo de bots más sofisticados de la web. Desde análisis detallados de encabezados hasta una interminable sucesión de CAPTCHAs, Etsy es la pesadilla de los Scrapers web de todo el mundo. Si logras superar estos obstáculos, Etsy se convierte en un sitio relativamente fácil de rastrear.
Si puedes extraer datos de Etsy, obtendrás acceso a una gran cantidad de datos de pequeñas empresas de uno de los mercados más grandes que ofrece Internet. Sigue leyendo y en poco tiempo estarás extrayendo datos de Etsy como un profesional. Aprenderemos a extraer datos de todos los siguientes tipos de páginas de Etsy.
- Resultados de búsqueda
- Páginas de productos
- Páginas de tiendas
Introducción
Python Requests y BeautifulSoup serán nuestras herramientas elegidas para este tutorial. Puedes instalarlas con los siguientes comandos. Requests nos permite realizar solicitudes HTTP y comunicarnos con los servidores de Etsy. BeautifulSoup nos da la posibilidad de realizar el Parseo de las páginas web utilizando Python. Te recomendamos que leas primero nuestra guía sobre cómo utilizar BeautifulSoup para el Scraping web.
Instalar Requests
pip install requests
Instalar BeautifulSoup
pip install beautifulsoup4
Qué extraer de Etsy
Si inspeccionas una página de Etsy, es posible que te encuentres con una complicada red de elementos anidados. Si sabes dónde buscar, es bastante fácil de solucionar. Las páginas de Etsy utilizan datos JSON para renderizar la página en el navegador. Si encuentras el JSON, podrás encontrar todos los datos que se utilizaron para crear la página… sin tener que profundizar demasiado en el HTML del documento.
Resultados de búsqueda
Las páginas de búsqueda de Etsy contienen una matriz de objetos JSON. Si observas la imagen siguiente, todos estos datos se encuentran dentro de un elemento de script con type="application/ld+json". Si miras con atención, estos datos JSON contienen una matriz llamada itemListElement. Si podemos extraer esta matriz, obtendremos todos los datos que se utilizaron para crear la página.
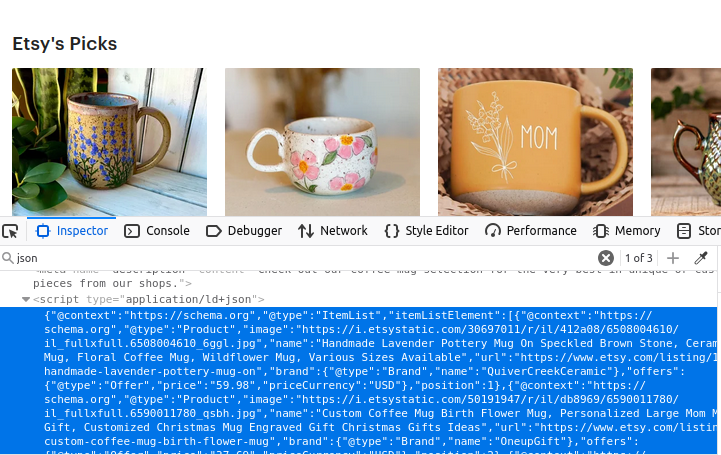
Información del producto
Sus páginas de productos no son muy diferentes. Fíjate en la imagen de abajo, una vez más, tenemos una etiqueta de script con type="application/ld+json". Esta etiqueta contiene toda la información que se utilizó para crear la página del producto.
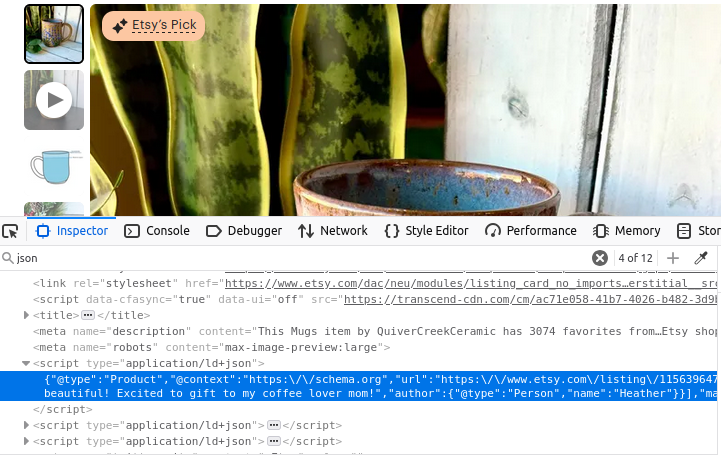
Tiendas
Probablemente lo hayas adivinado, nuestras páginas de tiendas también se crean de la misma manera. Busca el primer objeto script de la página con type="application/ld+json" y obtendrás tus datos.
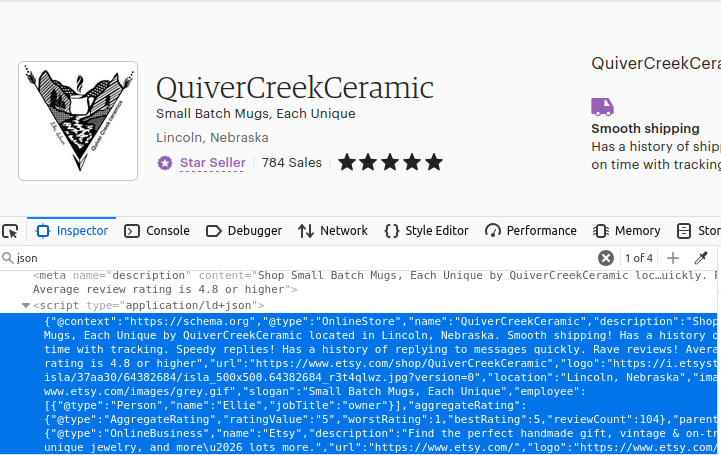
Cómo extraer datos de Etsy con Python
Ahora repasaremos todos los componentes necesarios que debemos crear. Como se ha mencionado anteriormente, Etsy emplea diversas tácticas para impedirnos acceder al sitio. Utilizamos Web Unlocker como navaja suiza para estos bloqueos. No solo gestiona las conexiones Proxy por nosotros, sino que también resuelve cualquier CAPTCHA que se nos presente. Puedes intentarlo sin un Proxy, pero en nuestras pruebas iniciales no pudimos superar los sistemas de bloqueo de Etsy sin Web Unlocker.
Una vez que tengas una instancia de Web Unlocker, puedes configurar tu conexión Proxy creando un simple dict. Utilizamos el certificado SSL de Bright Data para garantizar que nuestros datos permanezcan cifrados durante la transmisión. En el código siguiente, especificamos la ruta a nuestro certificado SSL y luego utilizamos nuestro nombre de usuario, nombre de zona y contraseña para crear la URL del Proxy. Nuestros proxies se crean mediante la construcción de una URL personalizada que reenvía todas nuestras solicitudes a través de uno de los servicios Proxy de Bright Data.
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<TU-NOMBRE-DE-USUARIO>-zone-<TU-NOMBRE-DE-ZONA>:<TU-CONTRASEÑA>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<TU-NOMBRE-DE-USUARIO>-zone-<TU-NOMBRE-DE-ZONA>:<TU-CONTRASEÑA>@brd.superproxy.io:33335'
}
Resultados de la búsqueda
Para extraer los resultados de la búsqueda, realizamos una solicitud utilizando nuestros Proxies. A continuación, utilizamos BeautifulSoup para realizar el parseo del documento HTML entrante. Buscamos los datos dentro de la etiqueta de script y los cargamos como un objeto JSON. A continuación, devolvemos el campo itemListElement del JSON.
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
Información del producto
La información de nuestros productos se extrae básicamente de la misma manera. La única diferencia real es la ausencia de itemListElement. En este caso, utilizamos nuestro listing_id para crear nuestra url y extraemos todo el objeto JSON.
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Tiendas
Al extraer tiendas, seguimos el mismo modelo que utilizamos con los productos. Utilizamos el nombre de la tienda (shop_name) para construir la URL. Una vez que obtenemos la respuesta, buscamos el JSON, lo cargamos como JSON y devolvemos los datos extraídos de la página.
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Almacenamiento de los datos
Nuestros datos están perfectamente estructurados en JSON tan pronto como los extraemos. Podemos escribir nuestra salida en un archivo utilizando el manejo básico de archivos de Python y json.dumps(). Lo escribimos con indent=4 para que sea limpio y legible cuando los humanos miren el archivo.
with open("products.json", "w") as file:
json.dump(products, file, indent=4)
Poniendo todo junto
Ahora que sabemos cómo construir nuestras piezas, lo pondremos todo junto. El código siguiente utiliza las funciones que acabamos de escribir y devuelve los datos deseados en formato JSON. A continuación, escribimos cada uno de estos objetos en sus propios archivos JSON individuales.
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Configuración del Proxy y del certificado (CREDENCIALES CODIFICADAS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<TU-NOMBRE-DE-USUARIO>-zone-<TU-NOMBRE-DE-ZONA>:<TU-CONTRASEÑA>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<TU-NOMBRE-DE-USUARIO>-zone-<TU-NOMBRE-DE-ZONA>:<TU-CONTRASEÑA>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""Recupera y analiza datos JSON-LD de una página de Etsy."""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Solicitud fallida: {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("No se ha encontrado el script JSON-LD en la página.")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"Error al realizar el parseo de JSON: {e}")
return None
def etsy_search(keyword):
"""Busca en Etsy una palabra clave determinada y devuelve los resultados."""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Obtener los detalles del producto de un listado de Etsy."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Obtener los detalles de la tienda desde la página de una tienda de Etsy."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Guarda los datos en un archivo JSON con gestión de errores."""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"Datos guardados correctamente en {filename}")
except (IOError, TypeError) as e:
print(f"Error al guardar los datos en {filename}: {e}")
if __name__ == "__main__":
# Búsqueda de productos
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# Artículo específico
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Tienda Etsy
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
A continuación se muestran algunos datos de ejemplo de products.json.
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "Taza de café personalizada con foto, taza de café con imagen personalizada, taza de aniversario para él/ella, taza personalizable con logotipo y texto para hombres y mujeres",
"url": "https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo",
"brand": {
"@type": "Brand",
"name": "TheGiftBucks"
},
"offers": {
"@type": "Offer",
"price": "14.99",
"priceCurrency": "USD"
},
"position": 1
},
Considere el uso de Conjuntos de datos
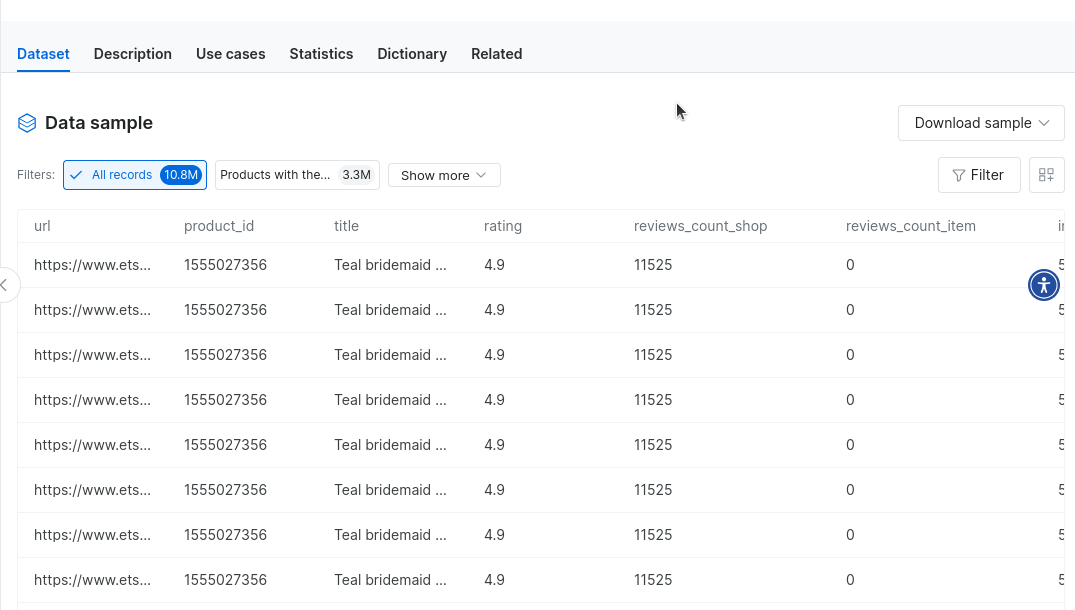
Nuestros conjuntos de datos ofrecen una excelente alternativa al Scraping web. Puede comprar conjuntos de datos de Etsy listos para usar o uno de nuestros otros conjuntos de datos de comercio electrónico y eliminar por completo el proceso de scraping. Una vez que tenga una cuenta, diríjase a nuestro mercado de conjuntos de datos.
Escribe «Etsy» y haz clic en el conjunto de datos de Etsy.

Esto le dará acceso a millones de registros de datos de Etsy… al alcance de su mano. Incluso puede descargar datos de muestra para ver cómo es trabajar con ellos.
Conclusión
En este tutorial, hemos explorado el scraping de Etsy con gran detalle. Ha recibido un curso intensivo sobre la integración de Proxies. Ahora sabe cómo utilizar Web Unlocker para superar incluso los bloqueadores de bots más estrictos. Sabe cómo extraer los datos y también cómo almacenarlos. Además, ha podido probar nuestros Conjuntos de datos prefabricados que eliminan por completo sus tareas de scraping. Sea cual sea la forma en que obtenga sus datos, nosotros nos encargamos de todo.
Regístrate ahora y comienza tu prueba gratuita.





