
En esta entrada del blog aprenderás:
- Por qué Kubeflow Pipelines debería incluir un componente dedicado a la recopilación de datos web.
- Una aplicación de este enfoque a un canal específico de análisis de opiniones en TikTok.
- Cómo implementar ese canal conectándose a las fuentes de datos de comentarios de TikTok a través de una solución de scraping específica.
¡Empecemos!
Por qué Kubeflow Pipelines se beneficia de los datos estructurados extraídos mediante Scraping web
Los flujos de trabajo modernos de aprendizaje automático e IA dependen en gran medida de datos de alta calidad. Por el contrario, los flujos de trabajo tradicionales suelen incorporar Conjuntos de datos estáticos o archivos preprocesados. Sin embargo, esas fuentes pueden quedar obsoletas rápidamente, lo que hace que los modelos se entrenen con información desactualizada.
¡Ahí es donde entran en juego los datos estructurados extraídos del Scraping web! Al recopilar datos contextuales en tiempo real de la web, los procesos pueden mantenerse alineados con las últimas tendencias, el comportamiento de los usuarios y los contenidos emergentes.
Kubeflow Pipelines, diseñado para flujos de trabajo de aprendizaje automático modulares, reproducibles y escalables, se beneficia enormemente de la integración de componentes de recopilación de datos web. Dichos componentes proporcionan feeds actualizados y estructurados que pueden ser incorporados, filtrados y procesados automáticamente en fases posteriores.
Contar con un componente de recopilación de datos web en su canalización sin duda ayuda a mejorar la precisión del modelo. Por lo tanto, añadir un componente dedicado a la recopilación de datos web, o incluso varios componentes para diferentes fuentes, tiene sentido desde el punto de vista estratégico. Permite que sus canalizaciones se adapten, se vuelvan a entrenar y generen información de forma continua y casi en tiempo real, creando una base sólida para cualquier proyecto impulsado por la IA.
Presentación del proceso de Kubeflow para el análisis de opiniones en TikTok
Para comprender mejor cómo un componente de recopilación de datos web mejora los procesos de Kubeflow, veamos un ejemplo real. Imagina que quieres crear un flujo de trabajo de análisis de datos que tome un conjunto de publicaciones de TikTok y analice su contenido para determinar el sentimiento.
Podría diseñar un proceso de dos componentes:
- Componente de datos de comentarios de TikTok: recupera datos de comentarios estructurados de publicaciones de TikTok mediante Scraping web.
- Componente de análisis de datos: enriquece esos comentarios con información sobre el sentimiento (
positivo,negativooneutro).
El problema es que el scraping de TikTok (o de muchas otras plataformas populares) es muy complicado. Esto se debe a las medidas antiscraping, como los CAPTCHA, los retos de JavaScript, los bloqueos de IP y los límites de velocidad. Escalar este proceso solo añade complejidad, ya que las restricciones y las prohibiciones pueden interrumpir fácilmente la recopilación de datos.
Para evitar estos problemas, tiene sentido potenciar el componente de recopilación de datos web con un servicio de datos web de primera categoría como Bright Data. Bright Data permite un Scraping web a gran escala y fiable con una infraestructura altamente escalable respaldada por 150 millones de Proxy IP en 195 países, una tasa de éxito del 99,95 % y un tiempo de actividad del 99,99 %.
En concreto, aprovecharemos TikTok Scraper, una API de Scraping web diseñada para simplificar la recopilación de datos estructurados de las publicaciones de TikTok. Esta es una de las muchas API de Scraping web disponibles para recuperar datos de dominios populares. Del mismo modo, se puede utilizar la API Filter Dataset para obtener datos filtrados de los Conjuntos de datos de Bright Data, lo que potencia los procesos de ML/IA con datos listos para usar.
Cómo crear un canal de Kubeflow con un componente de datos de Scraping web dinámico
En esta sección guiada, verás cómo crear el canal Kubeflow para el análisis de opiniones de TikTok presentado anteriormente.
¡Sigue los pasos que se indican a continuación!
Requisitos
Para seguir este tutorial, necesitará:
- Docker instalado y en ejecución en su máquina.
- Python 3.10+ instalado localmente.
- Una cuenta de Bright Data con su clave API correctamente configurada (no se preocupe por configurarla ahora mismo, ya que se le guiará a través de ello en una subsección dedicada).
Un conocimiento básico del funcionamiento de Kubeflow Pipelines también te ayudará a comprender las instrucciones que se indican a continuación.
El sistema operativo recomendado para ejecutar los ejemplos siguientes es Linux, macOS o WSL (subsistema de Windows para Linux).
Paso n.º 1: Configuración del proyecto
Comience abriendo su terminal y creando un nuevo directorio para el proyecto Kubeflow Pipelines:
mkdir kfp-bright-data-pipelineVaya al directorio del proyecto y cree un entorno virtual Python dentro de él:
cd kfp-bright-data-pipeline
python -m venv .venvA continuación, abra la carpeta del proyecto en su IDE de Python preferido. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Cree un nuevo archivo llamado tiktok_sentiment_analysis_kfp_pipeline.py en la raíz del directorio del proyecto. Su estructura debería tener este aspecto:
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------En la terminal del IDE, activa el entorno virtual. En Linux o macOS, ejecuta:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activateCon el entorno virtual activado, instale la dependencia requerida:
pip install kfpLa única biblioteca necesaria es kfp, que le permite crear y compilar canalizaciones de aprendizaje automático portátiles y escalables.
Por último, abra tiktok_sentiment_analysis_kfp_pipeline.py e importe los módulos necesarios:
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset¡Eso es todo! Ahora dispone de un entorno de desarrollo Python en el que puede crear su canalización Kubeflow.
Paso n.º 2: Empieza a utilizar Bright Data
El primer componente de su canalización recuperará datos web en tiempo real utilizando las API de Scraping web de Bright Data. Antes de implementarlo, debe configurar correctamente su cuenta de Bright Data.
Dado que utilizaremos las API de Scraping web, te recomendamos que dediques unos minutos a revisar la documentación oficial. En resumen, estas API proporcionan fuentes de datos estructurados de sitios web populares, listos para ser utilizados en flujos de trabajo de ML/AI (o cualquier otro caso de uso compatible).
Si aún no tiene una cuenta, cree una. De lo contrario, inicie sesión y abra el panel de control del usuario. Desde allí, navegue hasta la sección «Scrapers»: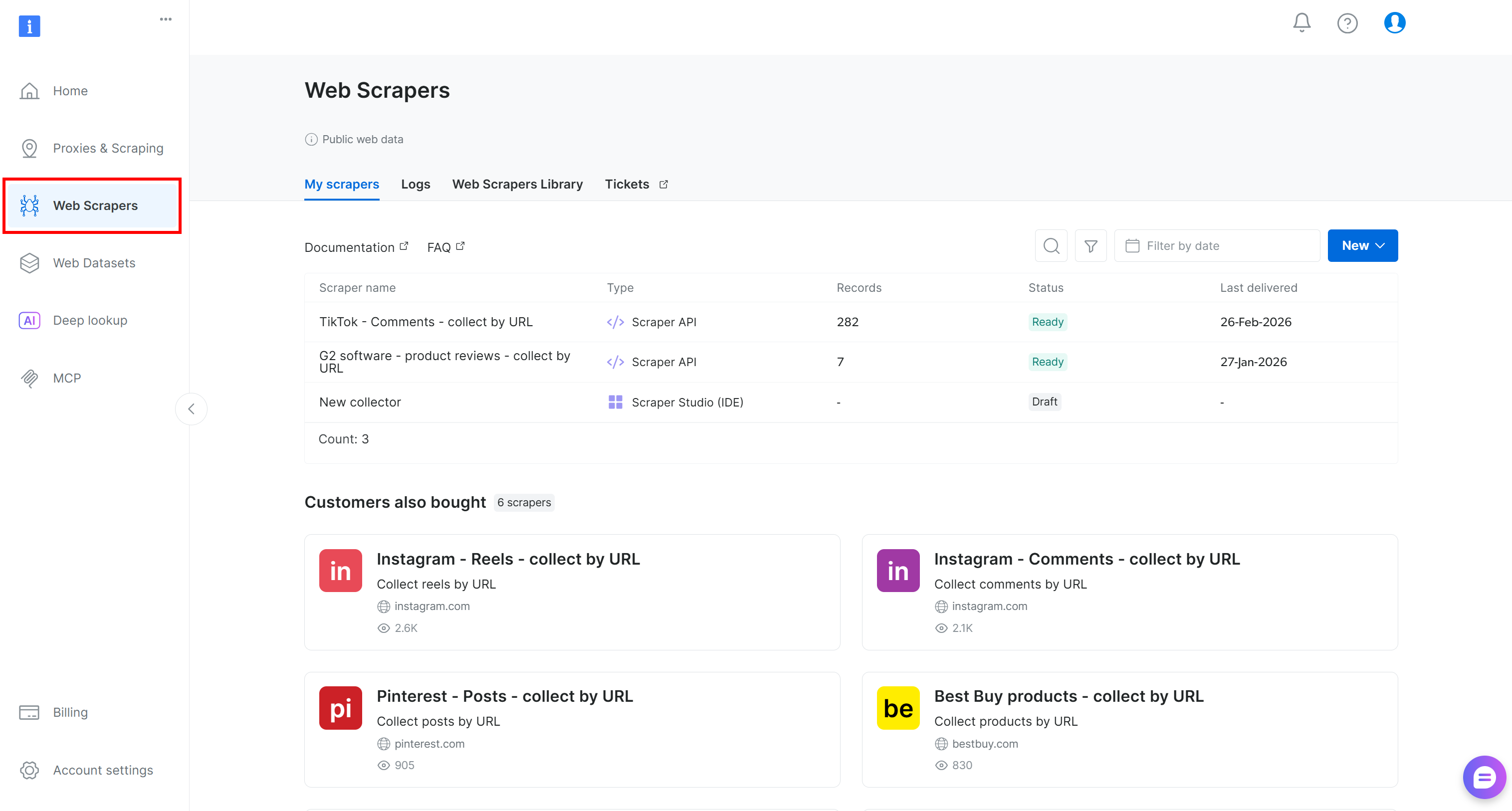
Vaya a la pestaña «Web Scrapers Library» (Biblioteca de Scrapers). Encontrará más de 120 Scrapers listos para usar para algunas de las plataformas más populares de Internet.
En este tutorial, busque «tiktok.com», ya que nuestro objetivo es recuperar datos de comentarios en directo de las publicaciones de TikTok y realizar un análisis de opiniones sobre ellos.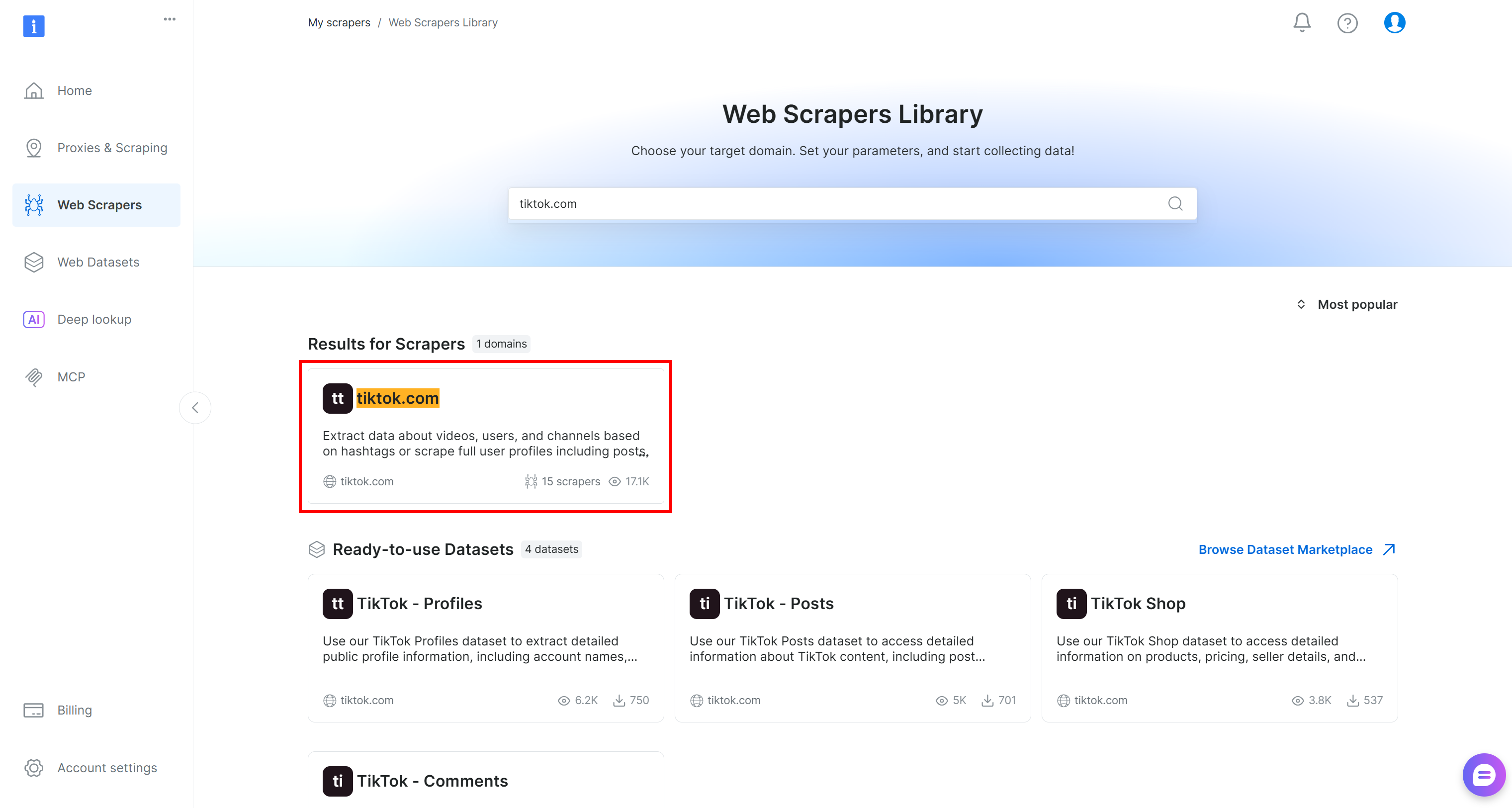
Dentro de la página del Scraper de TikTok, explore los puntos finales de scraping disponibles.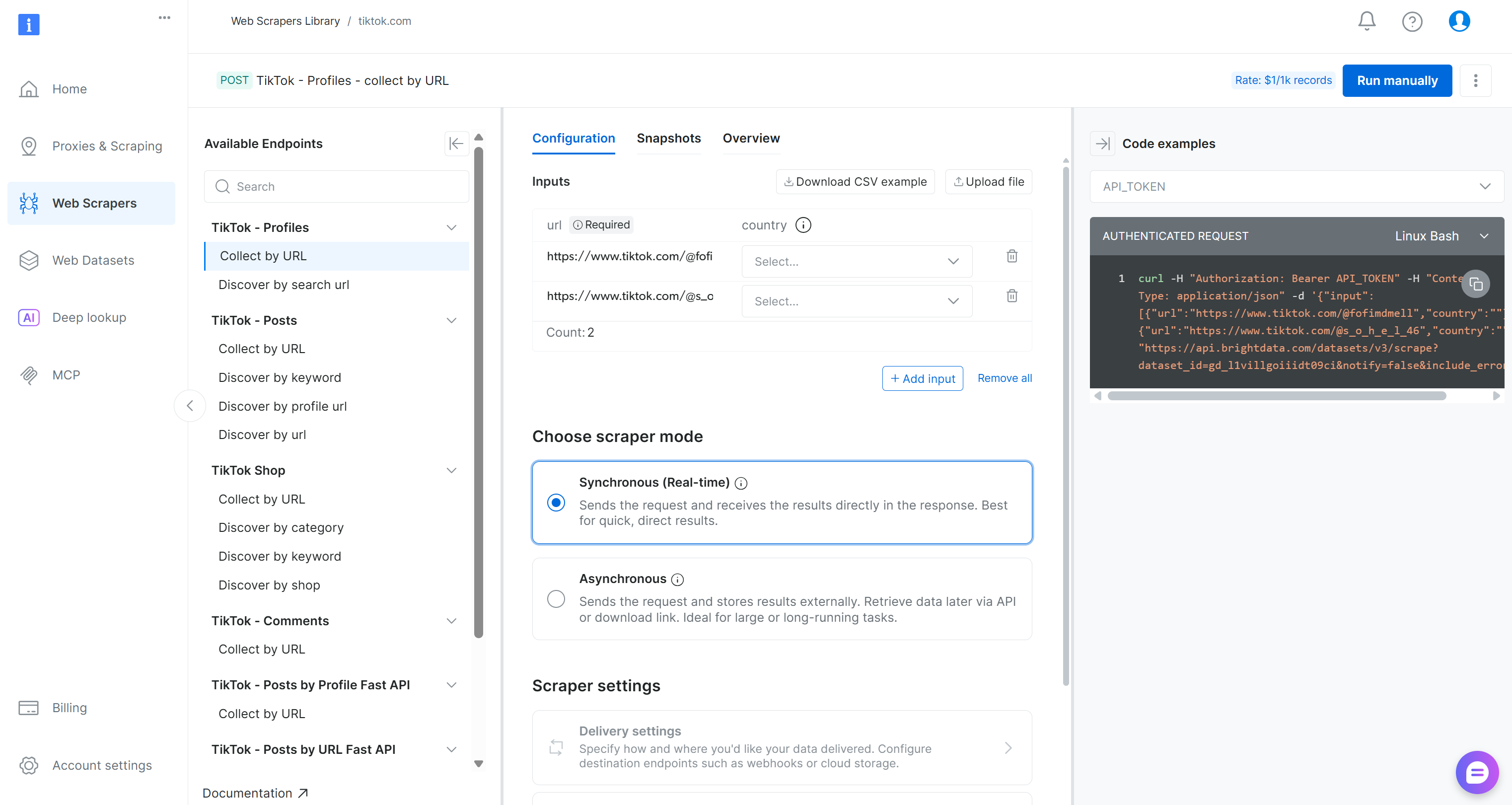
Aquí puede configurar los parámetros de entrada, inspeccionar los formatos de solicitud/respuesta, revisar ejemplos de llamadas a la API y mucho más.
Para este proceso, localice el Scraper «Collect by URL» (Recopilar por URL) en el menú desplegable «TikTok – Comments» (TikTok – Comentarios):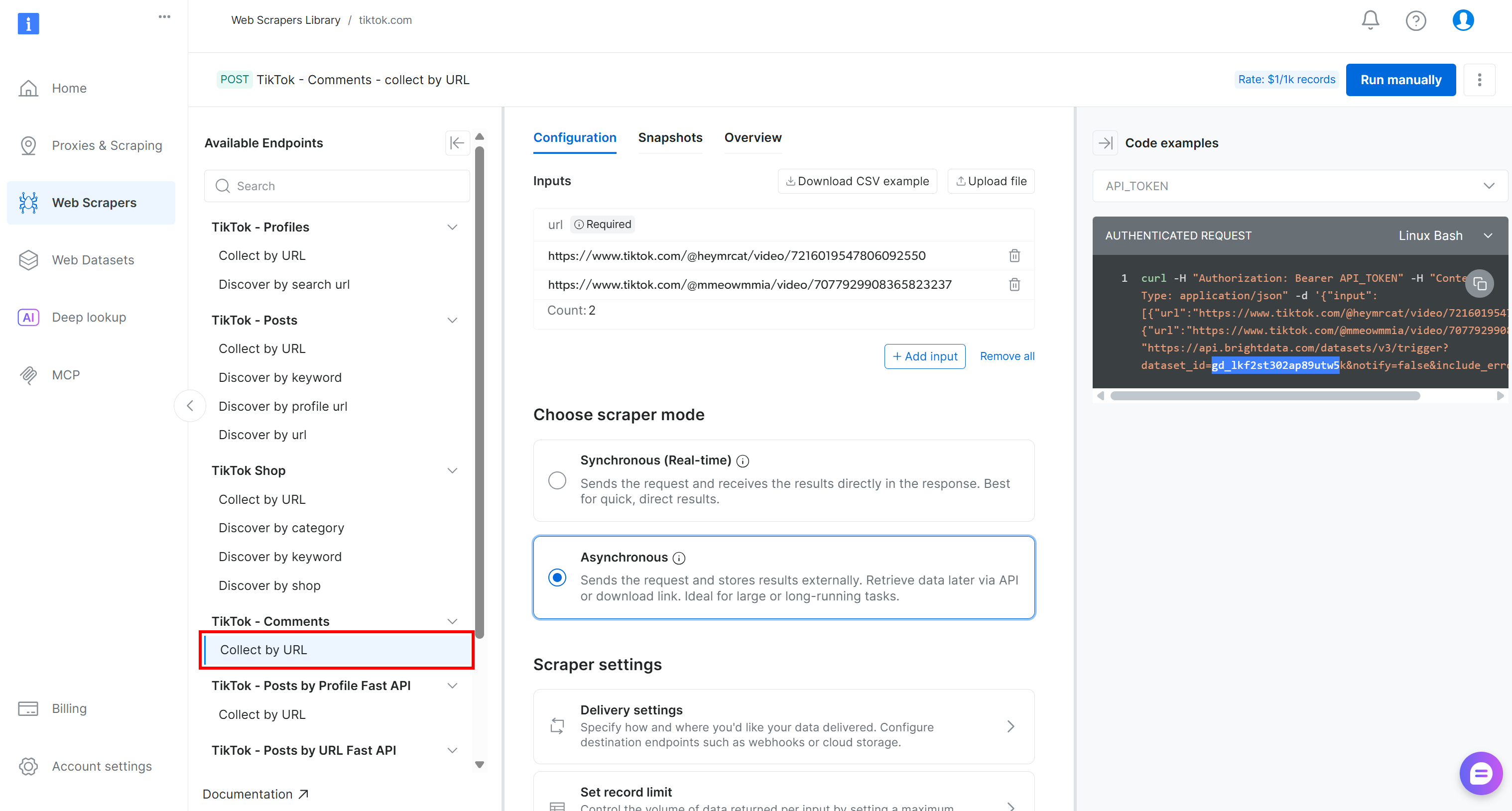
Ese es el punto final impulsado por Bright Data que utilizará en el componente de recopilación de datos de su canalización Kubeflow.
Tome nota de su ID de conjunto de datos:
gd_lkf2st302ap89utw5kLo necesitará para activar la API de Scraping web específica para la recopilación de datos de comentarios de TikTok.
Además, como puede ver en el fragmento de código de la derecha, las llamadas de la API de Bright Data a las API de Scraping web se autentican mediante un API_TOKEN. Este valor debe sustituirse por su clave API de Bright Data, que es el método recomendado para autenticar las solicitudes de API.
Recupere su clave API tal y como se explica en la documentación y guárdela en un lugar seguro. ¡La utilizará en el siguiente paso!
Paso n.º 3: definir el componente de recopilación de datos web
Implemente el componente del canal de Kubeflow para la recopilación de datos web integrándolo con la API de Scraping web de Bright Data para el rastreo de TikTok:
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplaza con tu clave API de Bright Data.
# El ID de la API de Scraping web de Bright Data «TikTok – Comentarios → Recopilar por URL».
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Los encabezados HTTP comunes a todas las solicitudes a Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Activar la API de Scraping web de Bright Data en las publicaciones de TikTok introducidas
trigger = requests.post(
f"https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Recuperar el ID de la instantánea de datos
snapshot_id = trigger.json()["snapshot_id"]
# Consultar el punto final de la instantánea para comprobar si se ha generado la instantánea
# que contiene los datos de interés
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Acceder a los datos de respuesta JSON
response_data = progress.json()
# Si la respuesta no incluye un estado, significa que contiene los datos extraídos
if isinstance(response_data, dict) and "status" in response_data:
# Extraer el estado actual de la instantánea
status = progress.json()["status"]
# Esperar 5 segundos para la siguiente comprobación
time.sleep(5)
else:
scraped_data = response_data
break
# Almacenar el conjunto de datos recopilados
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)Nota: Asegúrese de sustituir el marcador de posición <YOUR_BRIGHT_DATA_API_KEY> por la clave API de Bright Data que ha obtenido anteriormente. En una canalización lista para la producción, evite codificar secretos en sus componentes. En su lugar, gestiónelos de forma segura tal y como se explica en la documentación.
En Kubeflow Pipelines, un componente es una unidad autónoma (definida mediante la anotación dsl.component ) que realiza una tarea específica. En este caso, el componente recupera datos web de Bright Data. Cada componente se empaqueta en un contenedor Docker.
Para este componente, la imagen base es un entorno Python 3.10. A continuación, se incluye la bibliotecade solicitudes, ya que se utiliza para realizar solicitudes HTTP a los puntos finales de la API de Bright Data. En el momento de la implementación, cuando se crea el componente, se extraerá la imagen Python 3.10 y se instalarán automáticamente las solicitudes.
Bright Data admite la entrega de datos tanto sincrónica como asincrónica a través de sus API de Scraping web. El método sincrónico es ideal para la recuperación rápida de datos, mientras que el método asincrónico es más adecuado para Conjuntos de datos más grandes. Para un pipeline listo para la producción, generalmente se recomienda confiar en el enfoque asincrónico.
En el método asíncrono, cuando se solicitan datos, es posible que estos no estén disponibles de inmediato. En su lugar, Bright Data genera una instantánea de los datos solicitados, lo que puede tardar unos segundos o más. Esto requiere un mecanismo de sondeo, en el que se comprueba repetidamente si la instantánea está disponible antes de recuperarla.
Teniendo en cuenta este contexto, a continuación se explica paso a paso cómo funciona el código del componente de datos web:
- Enviar la solicitud de datos: el componente envía una llamada API a Bright Data para comenzar a generar la instantánea de los datos solicitados.
- Sondea el punto final de la instantánea: el componente llama repetidamente al punto final de la instantánea para comprobar el estado. Si la respuesta contiene un campo
de estado«en ejecución», la instantánea aún se está preparando. Si el campode estadono está presente, significa que la instantánea está lista y contiene los datos extraídos. - Recuperar los datos: una vez que la instantánea está lista, el componente extrae los datos de la respuesta de la API y los pone a disposición de los componentes posteriores del proceso.
¡Genial! El componente del proceso de Kubeflow para la recopilación de datos web está completo.
Paso n.º 4: Crear el componente de análisis de sentimientos
Los datos extraídos de TikTok se recuperarán como una matriz JSON con la siguiente estructura: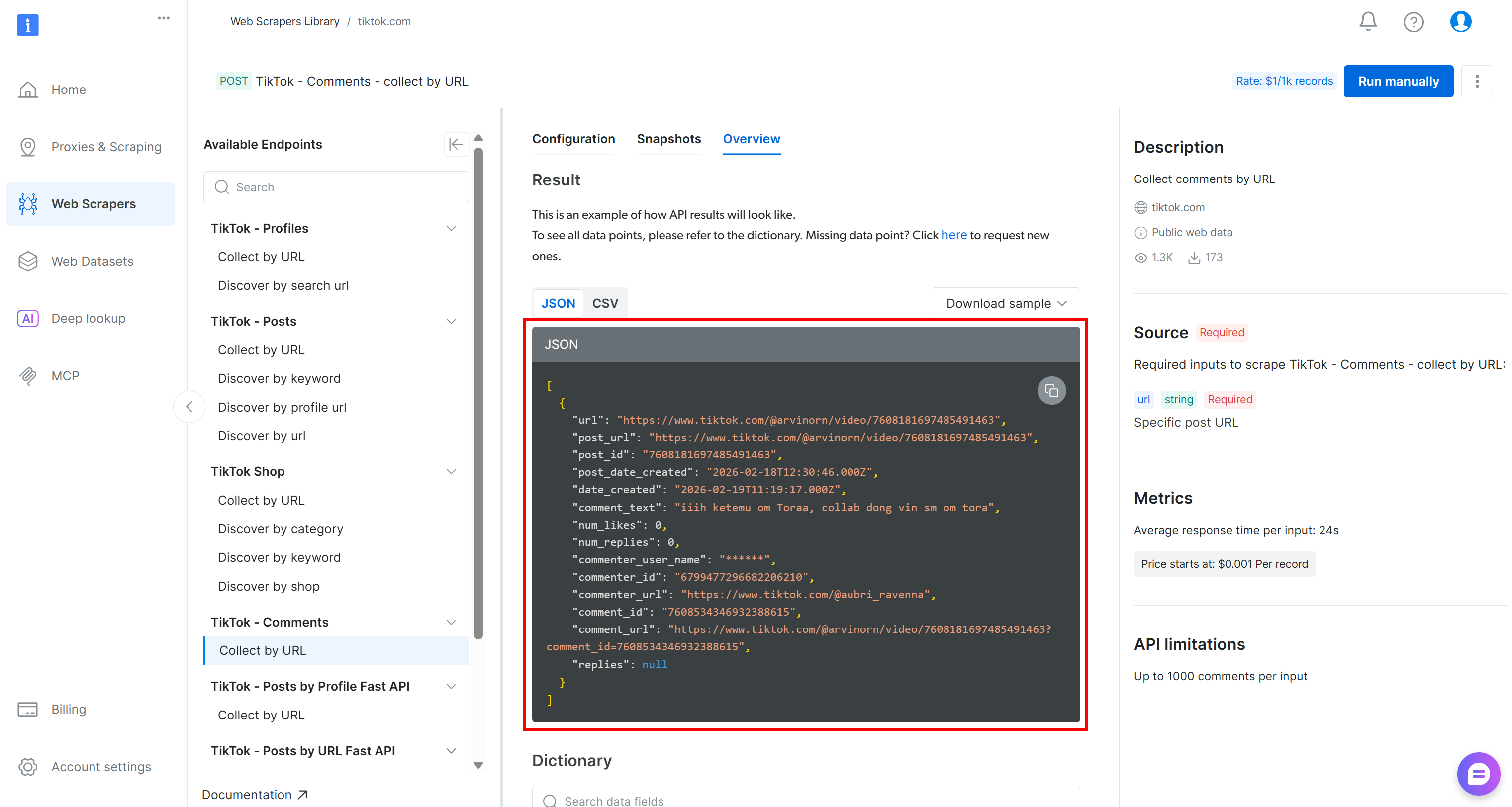
Para realizar un análisis de sentimientos sobre esos datos, puede pasar el campo comment_text a una herramienta de análisis de sentimientos como VADER Sentiment Analysis. VADER es una herramienta basada en léxicos y reglas diseñada específicamente para capturar los sentimientos expresados en las redes sociales. Por supuesto, también puede utilizar otros métodos de análisis de sentimientos, incluidos los modelos basados en IA.
VADER se incluye en NLTK, uno de los kits de herramientas de Python más populares para el procesamiento del lenguaje natural. Un flujo de trabajo típico es:
- Leer la matriz JSON de entrada (los comentarios extraídos de TikTok) del componente anterior.
- Utilizar
pandaspara simplificar el filtrado y la selección de datos. - Pasar los datos de texto al analizador de sentimientos VADER a través de
nltk. - Guardar los resultados analizados para que los utilicen los componentes posteriores.
En resumen, el componente de análisis de sentimientos se puede implementar de la siguiente manera:
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Descargar el léxico de sentimientos VADER (utilizado por NLTK para la puntuación de sentimientos)
nltk.download("vader_lexicon")
# Cargar el conjunto de datos de entrada que contiene los comentarios de TikTok
df = pd.read_json(input_dataset.path)
# Inicializar el analizador de sentimientos
sia = SentimentIntensityAnalyzer()
# Aplicar el análisis de sentimientos a cada comentario y clasificarlo como positivo, negativo o neutro
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negativo" si sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# Guardar los resultados en el conjunto de datos de salida para los componentes posteriores
df.to_json(sentiment_output.path, orient="records")¡Genial! Los dos componentes principales del proceso (es decir, la recopilación de datos web y el análisis de sentimientos) ya se han implementado por completo.
Paso n.º 5: Finalizar el proceso de Kubeflow
Ahora que los dos componentes están listos, puede combinarlos en un único proceso de Kubeflow utilizando una función anotada con dsl.pipeline:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Lista de URL de publicaciones de TikTok de las que extraer comentarios
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Recopilar comentarios de TikTok utilizando el componente de Scraping web de Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Realizar un análisis de opiniones sobre los comentarios recopilados
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)Esta canalización ejecuta primero el componente de recopilación de comentarios de TikTok en dos vídeos de destino del mismo perfil (@nike). En concreto, se seleccionaron los dos vídeos de TikTok porque presentan zapatillas nuevas. Realizar un análisis de opiniones sobre ellos es fundamental para comprender qué piensa el público sobre el lanzamiento.
El conjunto de datos producido a través de la API de Scraping web de Bright Data se pasa luego al componente de análisis de sentimientos posterior. El paso de análisis de sentimientos procesa los comentarios recopilados y genera un nuevo conjunto de datos que contiene etiquetas de sentimientos (positivos, negativos o neutros). Ese resultado puede ser utilizado por componentes posteriores adicionales, como la generación de informes o la visualización.
¡Excelente! La canalización de Kubeflow ya está completamente definida.
Paso n.º 6: Compilar el proceso
El paso final es compilar el proceso en un archivo de proceso YAML de Kubeflow:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Al ejecutar el script tiktok_sentiment_analysis_kfp_pipeline.py, este código genera un archivo denominado tiktok_sentiment_analysis_kfp_pipeline.yaml. Este archivo YAML contiene la especificación completa del pipeline necesaria para la implementación de Kubeflow. ¡Misión cumplida!
Paso n.º 7: Código final
A continuación se muestra el pipeline completo de Kubeflow que debe tener en su archivo tiktok_sentiment_analysis_kfp_pipeline.py:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplaza con tu clave API de Bright Data
# El ID de la API de Scraping web de Bright Data «TikTok – Comentarios → Recopilar por URL»
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Los encabezados HTTP comunes a todas las solicitudes a Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Activar la API de Scraping web de Bright Data en las publicaciones de TikTok introducidas
trigger = requests.post(
f"https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Recuperar el ID de la instantánea de datos
snapshot_id = trigger.json()["snapshot_id"]
# Consultar el punto final de la instantánea para comprobar si se ha generado la instantánea
# que contiene los datos de interés
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Acceder a los datos de respuesta JSON
response_data = progress.json()
# Si la respuesta no incluye un estado, significa que contiene los datos extraídos
if isinstance(response_data, dict) and "status" in response_data:
# Extraer el estado actual de la instantánea
status = progress.json()["status"]
# Esperar 5 segundos para la siguiente comprobación
time.sleep(5)
else:
scraped_data = response_data
break
# Almacenar el conjunto de datos extraídos
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Descargar el léxico de sentimientos VADER (utilizado por NLTK para la puntuación de sentimientos)
nltk.download("vader_lexicon")
# Cargar el conjunto de datos de entrada que contiene los comentarios de TikTok
df = pd.read_json(input_dataset.path)
# Inicializar el analizador de sentimientos
sia = SentimentIntensityAnalyzer()
# Aplicar el análisis de sentimientos a cada comentario y clasificarlo como positivo, negativo o neutro
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negativo" si sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# Guardar los resultados en el conjunto de datos de salida para los componentes posteriores.
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Lista de URL de publicaciones de TikTok para extraer comentarios.
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Recopilar comentarios de TikTok utilizando el componente de Scraping web de Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Realizar un análisis de sentimiento de los comentarios recopilados
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Ejecute el script anterior con:
python3 tiktok_sentiment_analysis_kfp_pipeline.pyDespués de ejecutar el comando, se generará un archivo llamado tiktok_sentiment_analysis_kfp_pipeline.yaml, como se muestra a continuación: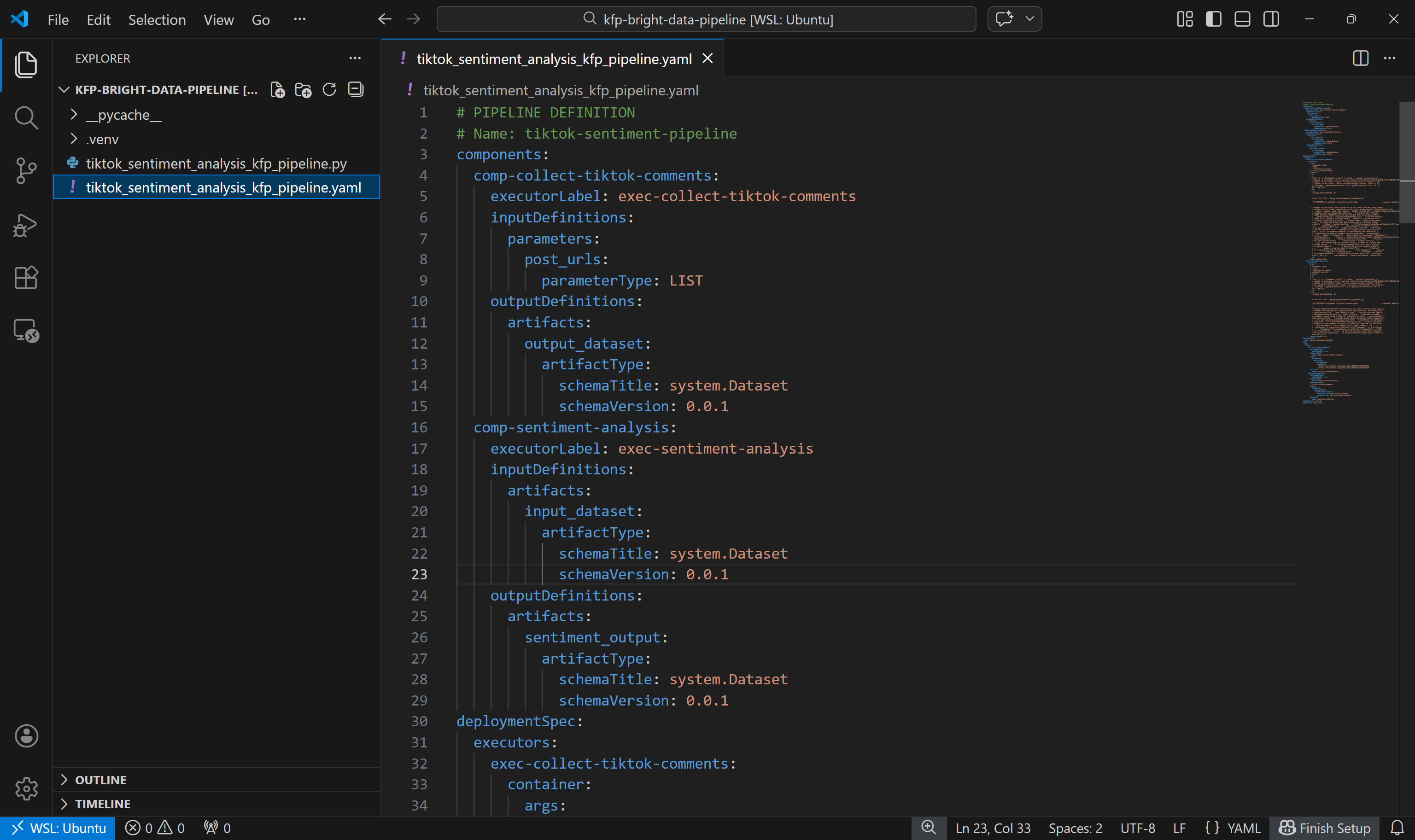
Ahora puede implementarlo en Kubeflow para realizar pruebas o ejecutarlo localmente utilizando Docker. En esta guía, nos centraremos en el segundo enfoque.
Paso n.º 8: Prueba la canalización de Kubeflow localmente
Para ejecutar el pipeline de Kubeflow localmente, puede utilizar la clase DockerRunner. Para ello, es necesario que Docker esté instalado y en ejecución en su máquina.
DockerRunner ejecuta cada tarea del pipeline dentro de un contenedor Docker independiente. En otras palabras, simula cómo se ejecutaría el pipeline en un entorno Kubeflow real.
Con su entorno virtual activado, comience por instalar la biblioteca Docker necesaria:
pip install docker A continuación, añada un archivo run_pipeline_local.py a la carpeta de su proyecto:
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yamlRellénelo de la siguiente manera:
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# inicializar el ejecutor local de Docker
local.init(runner=local.DockerRunner())
# Ejecutar el pipeline como una llamada a la función Python
pipeline_task = tiktok_sentiment_pipeline()Este script importa la función tiktok_sentiment_pipeline() desde tiktok_sentiment_analysis_kfp_pipeline.py y la ejecuta a través del ejecutor Docker local, ejecutando cada componente en su propio contenedor.
Para probar el pipeline, asegúrate de que Docker esté en ejecución. A continuación, ejecuta:
python3 run_pipeline_local.pyLos registros de ejecución deberían mostrar un mensaje de éxito, similar al ejemplo siguiente:
La salida del pipeline se guardará en la carpeta ./local_outputs. ¡Es hora de explorar los resultados!
Paso n.º 9: Explorar los resultados del proceso
Después de ejecutar el proceso, abra la carpeta ./local_outputs. En su interior, encontrará una subcarpeta para la ejecución actual que contiene todos los artefactos producidos.
Comience por explorar el conjunto de datos de salida producido por el componente collect-tiktok-comments: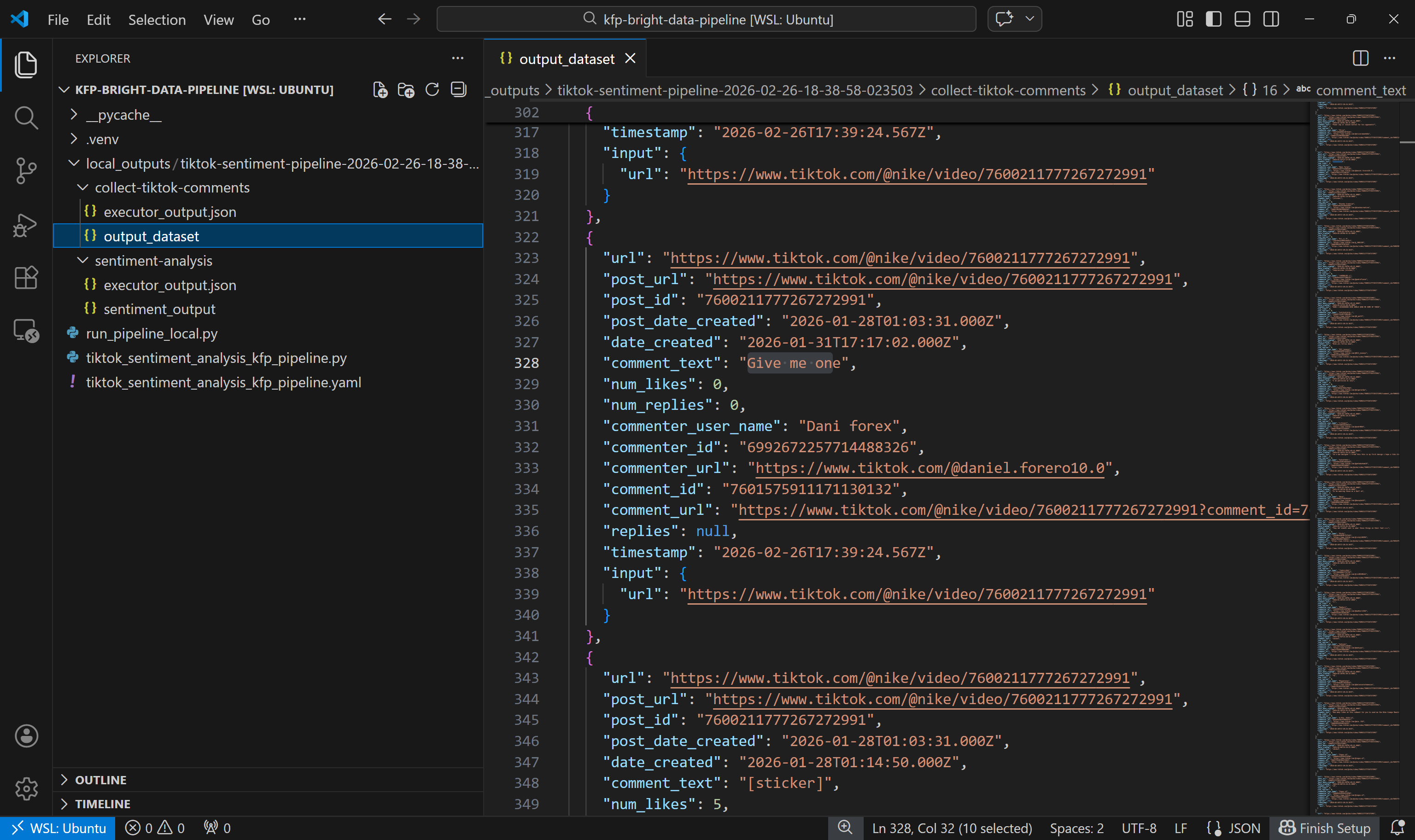
Este conjunto de datos incluye los comentarios devueltos por TikTok Scraper a través de Bright Data para las dos publicaciones especificadas, tal y como se esperaba.
A continuación, observe el conjunto de datos de salida del análisis de sentimientos: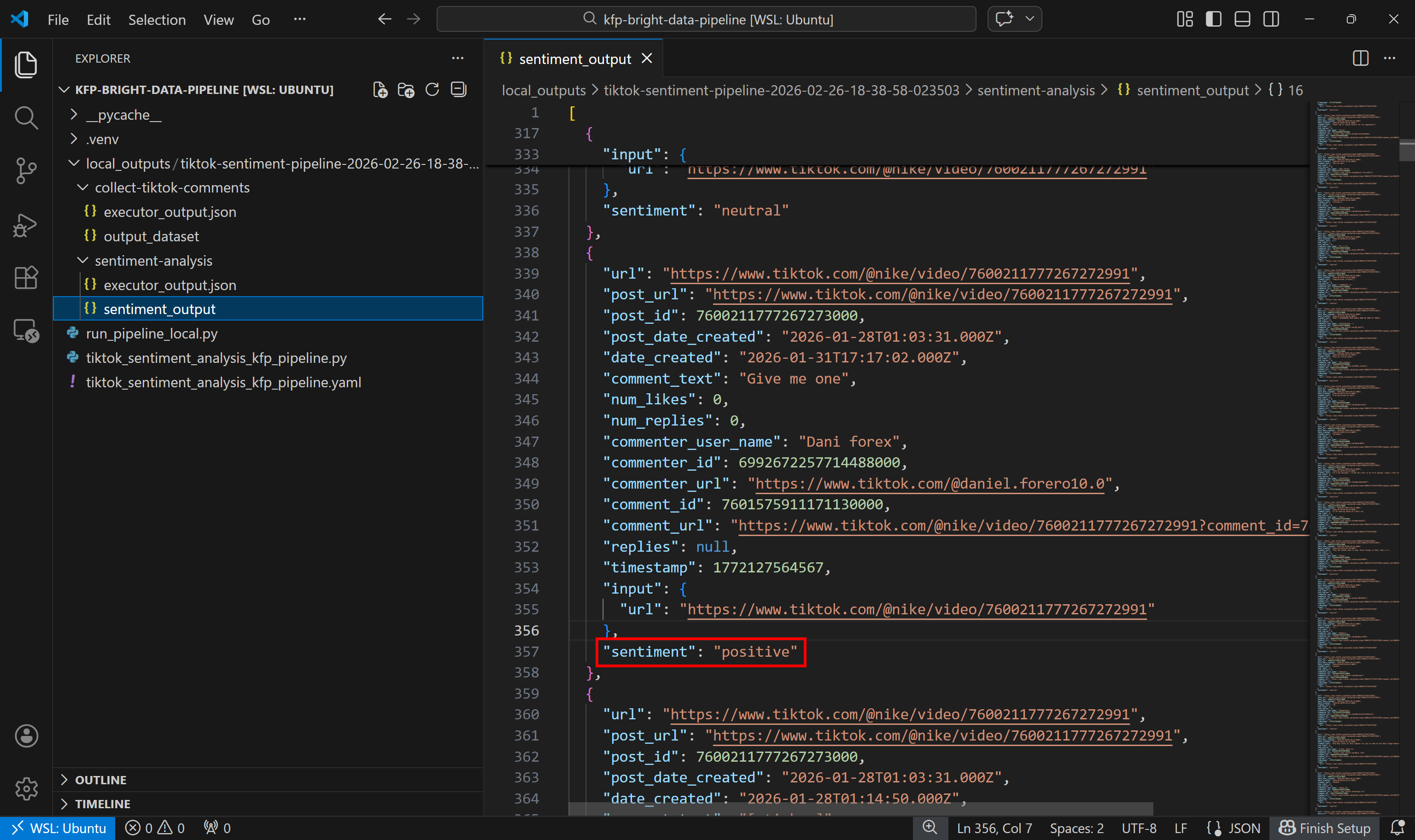
Observe cómo cada comentario ha sido etiquetado como positivo, negativo o neutro por el componente de análisis de sentimientos.
¡Et voilà! Acaba de ver cómo crear un pipeline de Kubeflow que recupera datos web recientes utilizando Bright Data y luego los analiza.
Conclusión
En este tutorial, ha comprendido por qué las canalizaciones de Kubeflow se benefician de los datos recientes recuperados mediante el Scraping web. En particular, ha visto la importancia de contar con un componente dedicado en su canalización para recopilar datos recientes, contextuales y estructurados de la web.
Bright Data lo hace posible gracias a una amplia gama de API de Scraping web, que actúan como fuentes de datos estructurados para sus pipelines. Como se ha demostrado, gracias a las API de Scraping web de Bright Data, crear un componente de recopilación de datos web en un pipeline de Kubeflow es muy sencillo.
¡Cree una cuenta gratuita en Bright Data y comience a explorar nuestras soluciones de datos web hoy mismo!





