

En este tutorial aprenderás:
- Por qué tiene sentido recuperar datos de Bilibili mediante Scraping web.
- Qué tipos de datos se pueden extraer de Bilibili.
- Cómo crear un canal de scraping y descarga de Bilibili para recopilar datos de vídeo para el entrenamiento de IA (y otros casos de uso).
- Por qué un Scraper dedicado a Bilibili es una mejor opción para aplicaciones de nivel empresarial listas para la producción.
Olvídate de las complicaciones:el Scraper de Bilibili de Bright Dataofrece datos de vídeo listos para usar a escala empresarial, con un sistema antibots integrado y un tiempo de actividad del 99,99 %.
¡Vamos a ello!
Por qué rastrear Bilibili: posibles casos de uso
Bilibili es una plataforma de vídeo con sede en Shanghái que a menudo se describe como el «YouTube de China». Lanzada en 2009, se ha convertido en una potencia de la Generación Z con más de 294 millones de usuarios activos al mes y más de 3000 millones de visualizaciones de vídeo al día.
Originalmente centrada en ACG (anime, cómics y juegos), ahora abarca tecnología, educación, estilo de vida, música, deportes electrónicos y transmisiones en directo. Bilibili es conocida por sus comentarios «danmu» en tiempo real y su comunidad altamente comprometida. Combina contenido generado por los usuarios, cultura de influencers, juegos y publicidad en el mismo ecosistema digital.
Dado el rápido crecimiento de Bilibili, el acceso a los datos de la plataforma permite muchos casos de uso, como por ejemplo
- Entrenamiento de IA para vídeo: los conjuntos de datos de vídeo a gran escala de Bilibili pueden impulsar la visión por ordenador, el reconocimiento de voz, los LLM multimodales, los sistemas de recomendación y los modelos de moderación de contenidos. Esto es posible gracias a los ricos metadatos, las transcripciones, las señales de participación y el contenido audiovisual sin procesar.
- Inteligencia de tendencias y contenidos: analiza categorías, etiquetas, visualizaciones y métricas de interacción para identificar temas emergentes, creadores en rápido crecimiento y formatos virales entre el público de la generación Z y las comunidades impulsadas por ACG.
- Análisis de creadores e influencers: realice un seguimiento del rendimiento de los usuarios que suben contenido, el crecimiento de los seguidores, los índices de interacción y la frecuencia de publicación para evaluar el impacto de los KOL (líderes de opinión clave) y optimizar las estrategias de marketing de influencers en China.
- Análisis del sentimiento de la audiencia: extraiga danmu (comentarios rápidos) y comentarios estándar para comprender las reacciones de los espectadores, el tono emocional, las referencias culturales y los patrones de retroalimentación en tiempo real a gran escala.
- Benchmarking competitivo: compare canales de marca, campañas patrocinadas y líderes de categoría mediante la supervisión de las visualizaciones, las interacciones y las estrategias de contenido en nichos similares.
- Investigación de entrada en el mercado y localización: evalúa las preferencias de contenido, el uso del lenguaje y los temas de tendencia para adaptar los productos, las campañas y los mensajes a la audiencia nativa digital de China.
Datos que se pueden recuperar de Bilibili
Al extraer datos de Bilibili, hay varios campos de datos a los que puede dirigirse. Estos dependen de los tipos específicos de páginas de las que está recopilando datos y de sus objetivos generales. Por lo tanto, hay varias categorías de datos interesantes de Bilibili que vale la pena explorar.
Metadatos de vídeo
Cuando se selecciona un vídeo específico de Bilibili, se puede recopilar:
- Información básica: título, descripción, URL de la imagen de portada, ID del vídeo, duración del vídeo, etc.
- Detalles de la subida: fecha y hora de publicación y categoría/partición (por ejemplo, «Anime», «Tecnología» o «Música»).
- Categorización: etiquetas, palabras clave y si el vídeo está marcado como contenido original o reimpresión.
- Estadísticas de interacción: Total de visualizaciones, «me gusta», monedas, favoritos y compartidos.
- Comentarios: los comentarios que se muestran directamente en el vídeo. Esto incluye el texto del comentario, la fecha y hora, el color, el tamaño de la fuente y el modo de visualización.
- Subtítulos: transcripciones generadas por IA o proporcionadas por el usuario que ha subido el vídeo.
Perfiles de usuarios y creadores
Al centrarse en la página de un creador de Bilibili, se puede recopilar la siguiente información:
- Información de identidad: nombre de usuario, ID de usuario, sexo, foto de perfil, etc.
- Métricas sociales: número de seguidores, número de seguidos y total de «me gusta» recibidos en todos los vídeos.
- Datos personales: biografía del usuario, fecha de nacimiento y nivel de la cuenta.
- Estado de la cuenta: insignia de verificación (por ejemplo, «Músico oficial») y nivel de membresía (por ejemplo, VIP/Miembro importante).
- Lista de trabajos: todos los vídeos subidos públicamente por un creador específico.
Datos de búsqueda y descubrimiento
También puede aprovechar el sistema de búsqueda de Bilibili para recuperar:
- Resultados de búsqueda: listas de vídeos, usuarios o transmisiones en directo que coinciden con palabras clave específicas.
- Datos de tendencias: palabras clave de búsqueda más populares y clasificaciones diarias/semanales.
- Información de transmisiones en directo: ID de la sala, título de la transmisión, estado en directo y número de espectadores simultáneos (índice de popularidad).
Creación de un Scraper de Bilibili y un canal de descarga de vídeos en Python: guía paso a paso
En esta sección guiada, aprenderá a extraer metadatos de vídeos de Bilibili de la página de la categoría «Tecnología»:
Ten en cuenta que esto es solo un ejemplo. La misma lógica se puede aplicar a cualquier otra página de categoría, incluida la página de inicio principal.
Utilizando las URL de los vídeos extraídas de esa página, crearás un segundo script para descargarlos uno por uno. Con los archivos de vídeo descargados, finalmente podrás introducirlos directamente en tus procesos de entrenamiento de IA/ML.
¡Sigue las instrucciones que se indican a continuación!
Requisitos previos
Para seguir este tutorial, asegúrate de tener:
- Python 3.10 instalado localmente.
- FFmpeg instalado localmente.
- Familiaridad con el funcionamiento de la automatización del navegador.
- Conocimientos básicos sobre cómo funciona
yt-dlp.
Verifica que FFmpeg está instalado en tu máquina con este comando:
ffmpeg -versionDebería ver algo similar a esto: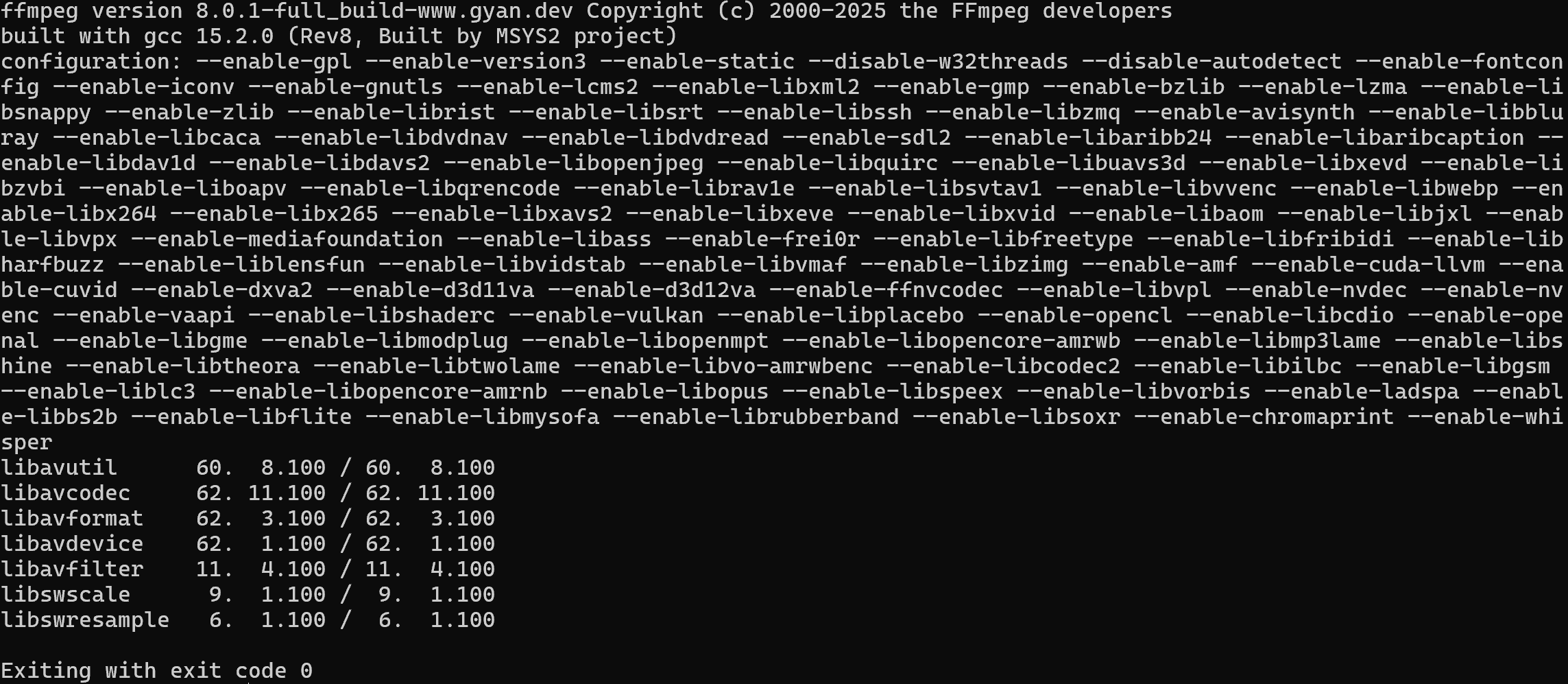
Si, por el contrario, aparece un error, instala FFmpeg siguiendo la guía de instalación oficial para tu sistema operativo.
Paso n.º 0: Familiarízate con Bilibili
Antes de escribir cualquier código, dedica algo de tiempo a explorar el sitio web de destino. Debes saber si es estático o dinámico, ya que tu hoja de ruta para el Scraping web depende de ello.
Si el sitio es estático, puede que sea suficiente con un simple cliente HTTP y un enfoque de parseo de HTML. Si es dinámico, necesitarás una herramienta de automatización del navegador. Obtén más información en nuestra guía sobre contenido estático frente a dinámico para el Scraping web.
Visite la página de destino en su navegador y comience a interactuar con ella. Observe cómo la página utiliza un patrón de interfaz de usuario de desplazamiento infinito:
A medida que se desplaza hacia abajo, se cargan automáticamente nuevas tarjetas de vídeo. Este comportamiento es un indicador de que el sitio web es dinámico. En concreto, se basa en JavaScript para obtener y renderizar nuevos datos en función de la interacción del usuario.
Por eso, una simple solicitud HTTP no será suficiente. Necesitará una herramienta de automatización del navegador para renderizar y extraer correctamente el contenido. En este tutorial, utilizaremos Playwright, pero herramientas como Selenium, SeleniumBase o NODRIVER también funcionarían.
Paso n.º 1: configura tu proyecto Playwright
Comience por iniciar su terminal y crear un nuevo directorio para su Scraper de Bilibili:
mkdir bilibili-ScraperVaya al directorio del proyecto y cree un entorno virtual Python dentro de él:
cd bilibili-Scraper
python -m venv .venvA continuación, carga la carpeta del proyecto en tu IDE de Python preferido. Visual Studio Code con la extensión Python y PyCharm Community Edition son buenas opciones.
Crea un nuevo archivo llamado scraper.py en la raíz del directorio del proyecto, que debería tener este aspecto:
bilibili-Scraper/
├── .venv/
└── scraper.py # <-----------En el terminal integrado de tu IDE, activa el entorno virtual. En Linux/macOS, ejecuta:
source .venv/bin/activateDe forma equivalente, en Windows, ejecuta:
.venv/Scripts/activateCon el entorno virtual activado, instala playwright con:
pip install playwrightComplete la instalación descargando los binarios del navegador necesarios:
python -m playwright installAhora, añada la siguiente configuración básica de Playwright a scraper.py:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# Inicie una instancia controlada de Chromium en modo headful.
browser = await p.chromium.launch(headless=False) # Establezca en True en producción.
context = await browser.new_context()
page = await context.new_page()
# Lógica de scraping...
# Cierre el navegador y libere sus recursos
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Este fragmento inicializa una instancia del navegador Chromium y permite que Playwright lo controle.
Durante el desarrollo, es útil mantener headless=False para poder seguir visualmente lo que hace el navegador. En producción, considera establecer headless=True para reducir el uso de recursos y acelerar la ejecución al habilitar el modo sin interfaz gráfica.
¡Bien hecho! Ahora tienes un entorno Python listo para el Scraping web de Bilibili mediante la automatización del navegador.
Paso n.º 2: Conéctese al sitio de destino
Utilice Playwright para navegar a la página web de destino, que es la página de la categoría «Tecnología» de Bilibili:
# La página de Bilibili «Tecnología» de destino
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navega a la página de destino
await page.goto(target_bilibili_page)La función goto() indica al navegador controlado que visite la URL especificada y espere a que se cargue la página.
¡Eso es todo! Ahora estás conectado a la página de destino de Bilibili.
El siguiente paso es automatizar la interacción de desplazamiento para que las nuevas tarjetas de vídeo se carguen dinámicamente. Una vez que aparezca el contenido adicional, estará listo para extraer los datos de esos elementos HTML.
Paso n.º 3: cargar nuevas tarjetas de vídeo
Como se mencionó anteriormente, la página de inicio y las páginas de categorías de Bilibili se basan en el patrón de interfaz de usuario de desplazamiento infinito. Inicialmente, solo se ven unas pocas tarjetas de vídeo. A medida que se desplaza hacia abajo, se carga más contenido de forma dinámica a través de JavaScript.
Concretamente, la página se carga inicialmente con un número fijo de elementos de tarjetas de vídeo dentro de un elemento HTML .head-cards: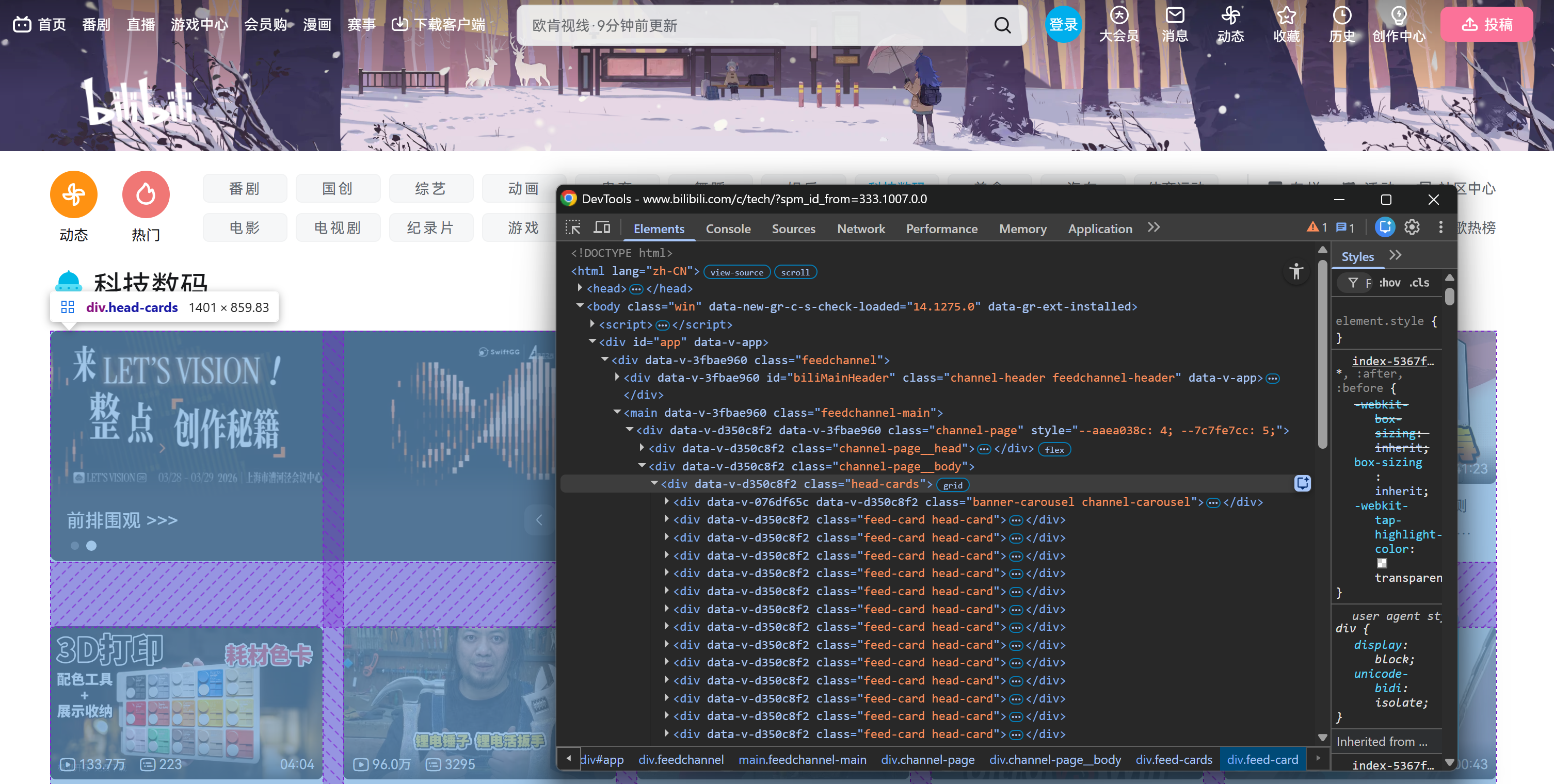
Después de desplazarse hacia abajo, se añade un contenedor .feed-cards a la página. Esa sección se rellena dinámicamente con nuevas tarjetas de vídeo a medida que se sigue desplazando: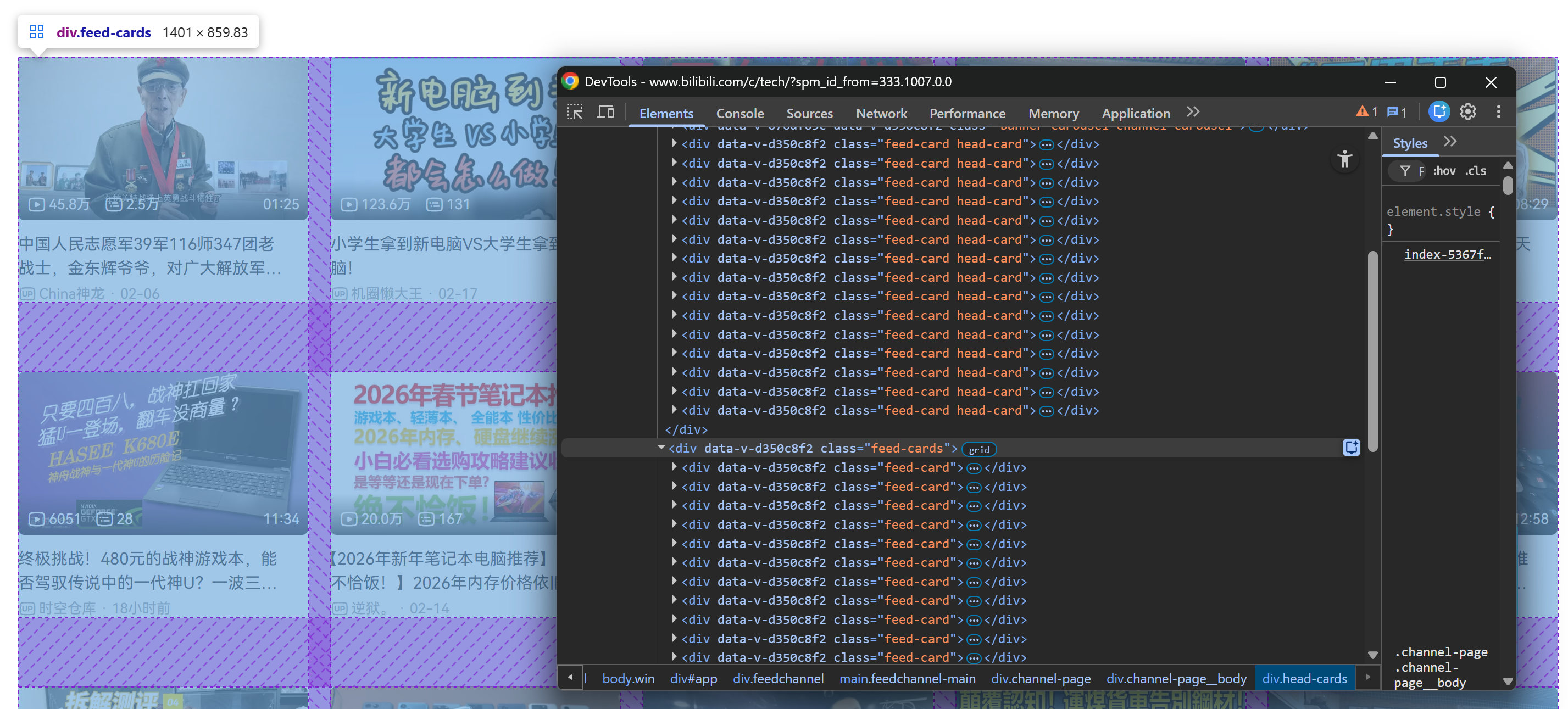
Lo importante aquí es que todas las tarjetas de vídeo (ya estén presentes de forma estática en la carga inicial de la página o se carguen dinámicamente durante el desplazamiento) se pueden seleccionar a través de este selector CSS:
.feed-cardEn este tutorial de scraping de Bilibili, supongamos que quieres recuperar al menos 50 vídeos. Para ello, debes simular múltiples interacciones de desplazamiento. Playwright no proporciona una API específica para el desplazamiento, por lo que ejecutarás un sencillo script JavaScript directamente en el contexto de la página:
for _ in range(3):
# Permitir la carga diferida
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Permitir la carga diferida
await asyncio.sleep(2) Este bucle ejecuta window.scrollTo() tres veces, desplazándose de arriba abajo por la página en cada iteración. Las llamadas a asyncio.sleep() son importantes porque:
- Hacen que el comportamiento del desplazamiento parezca más natural.
- Reducen el riesgo de activar mecanismos antibots.
- Dan tiempo al contenido cargado de forma diferida para que se renderice completamente antes del siguiente desplazamiento.
Dado que las tarjetas de vídeo se cargan dinámicamente, no se puede dar por sentado que estarán presentes inmediatamente después del desplazamiento. En su lugar, hay que esperar explícitamente hasta que la tarjeta número 50 se adjunte al DOM. En Playwright, hazlo con:
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")Este código crea un localizador Playwright para el elemento .feed-card número 50 (nth(49) porque la indexación comienza en 0). A continuación, espera hasta que ese elemento se adjunte al DOM con wait_for().
Ahora, si ejecutas el script en modo headful (headless=False), verás que el navegador se desplaza de forma autónoma tres veces: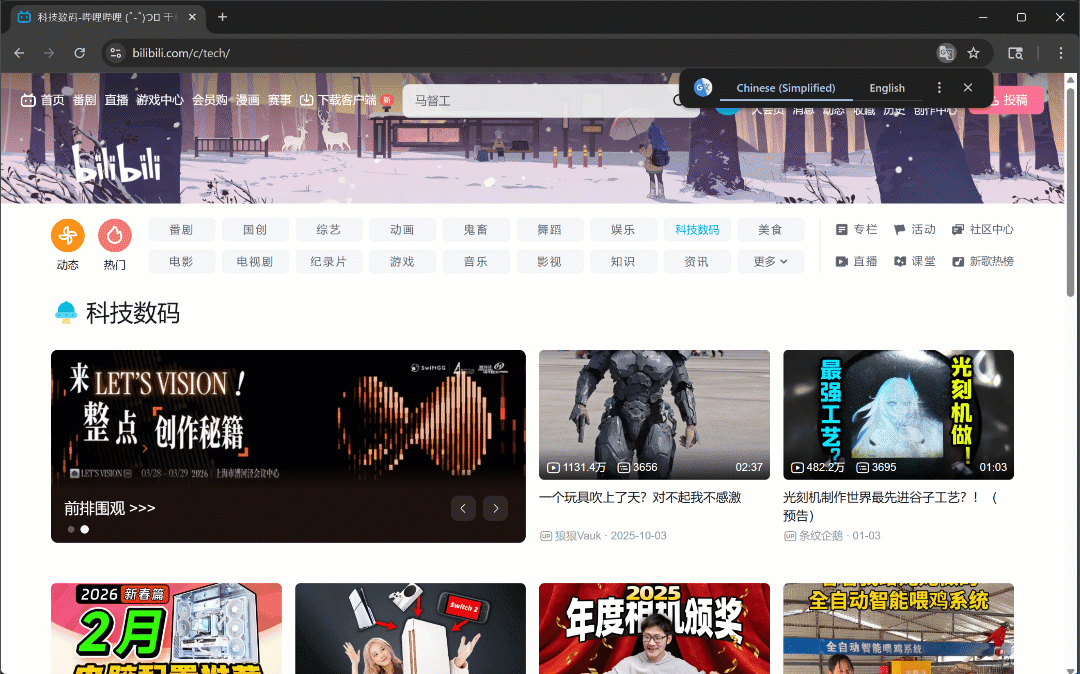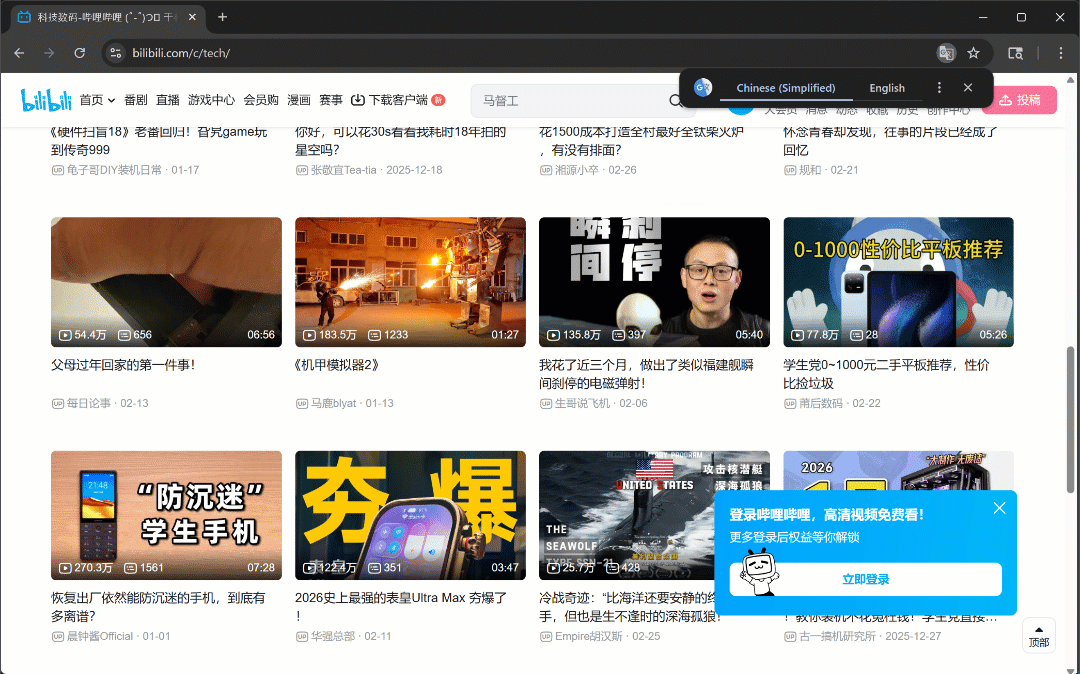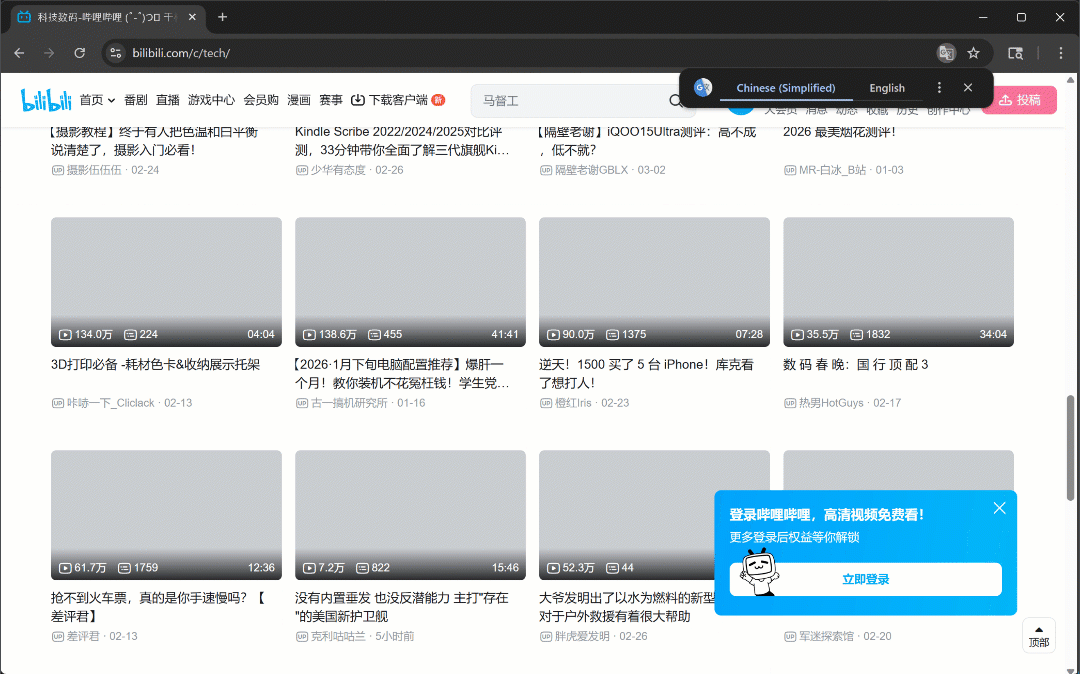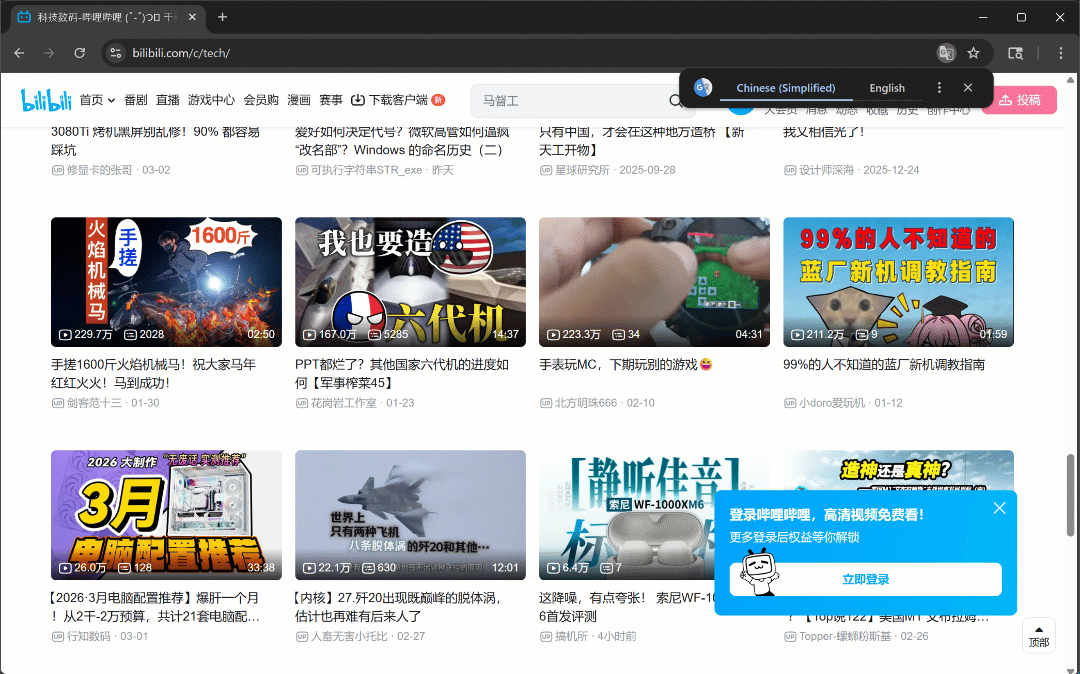
Tal y como se esperaba, se cargan nuevas tarjetas de vídeo después de cada desplazamiento.
Después de este paso, puedes estar seguro de que hay al menos 50 tarjetas de vídeo en la página. ¡Fantástico!
Paso n.º 4: familiarízate con la estructura de la tarjeta de vídeo
Para extraer los datos correctos, primero debe comprender cómo está estructurada cada tarjeta de vídeo en el DOM.
Comience haciendo clic con el botón derecho del ratón en una de las tarjetas de vídeo dentro de la sección .head-cards e inspeccione en las herramientas de desarrollo del navegador: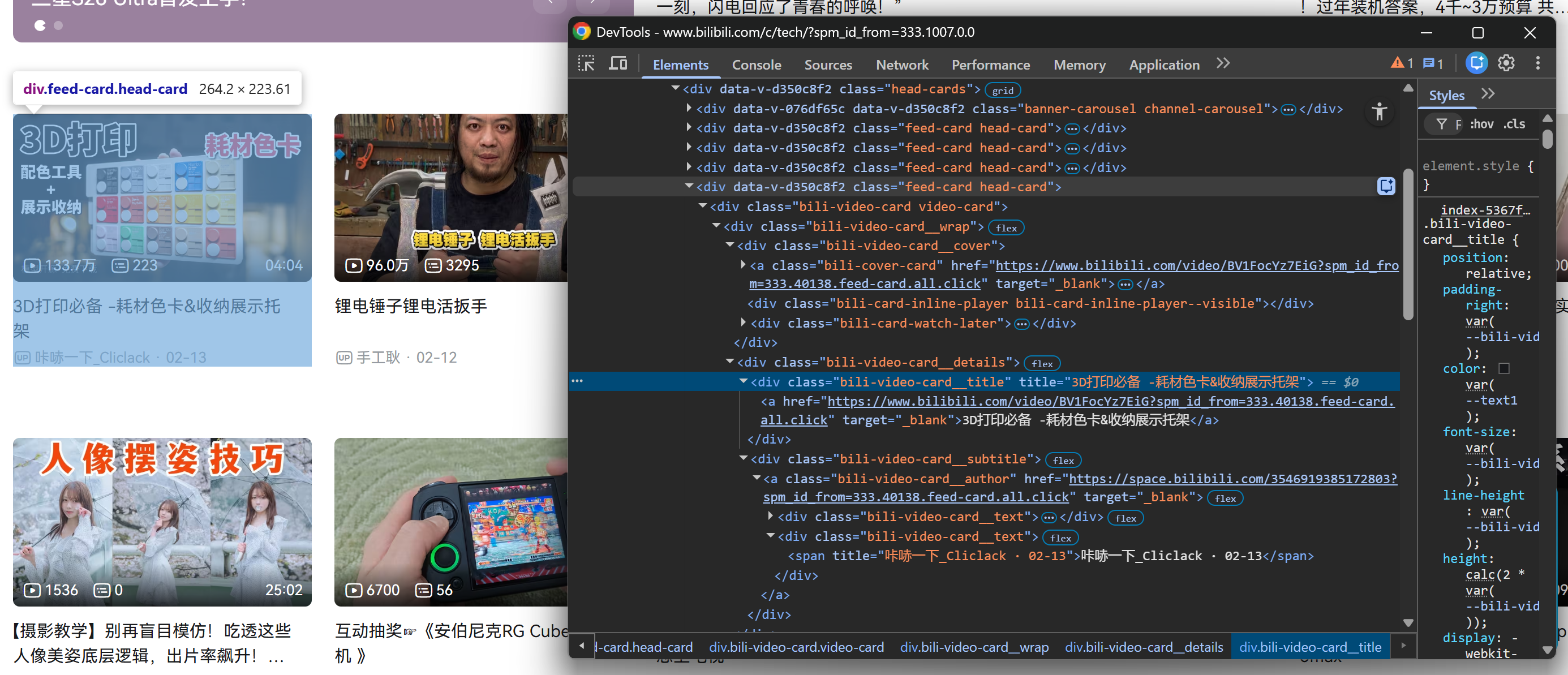
A continuación, repita el mismo proceso para una tarjeta de vídeo dentro de la sección .feed-cards cargada: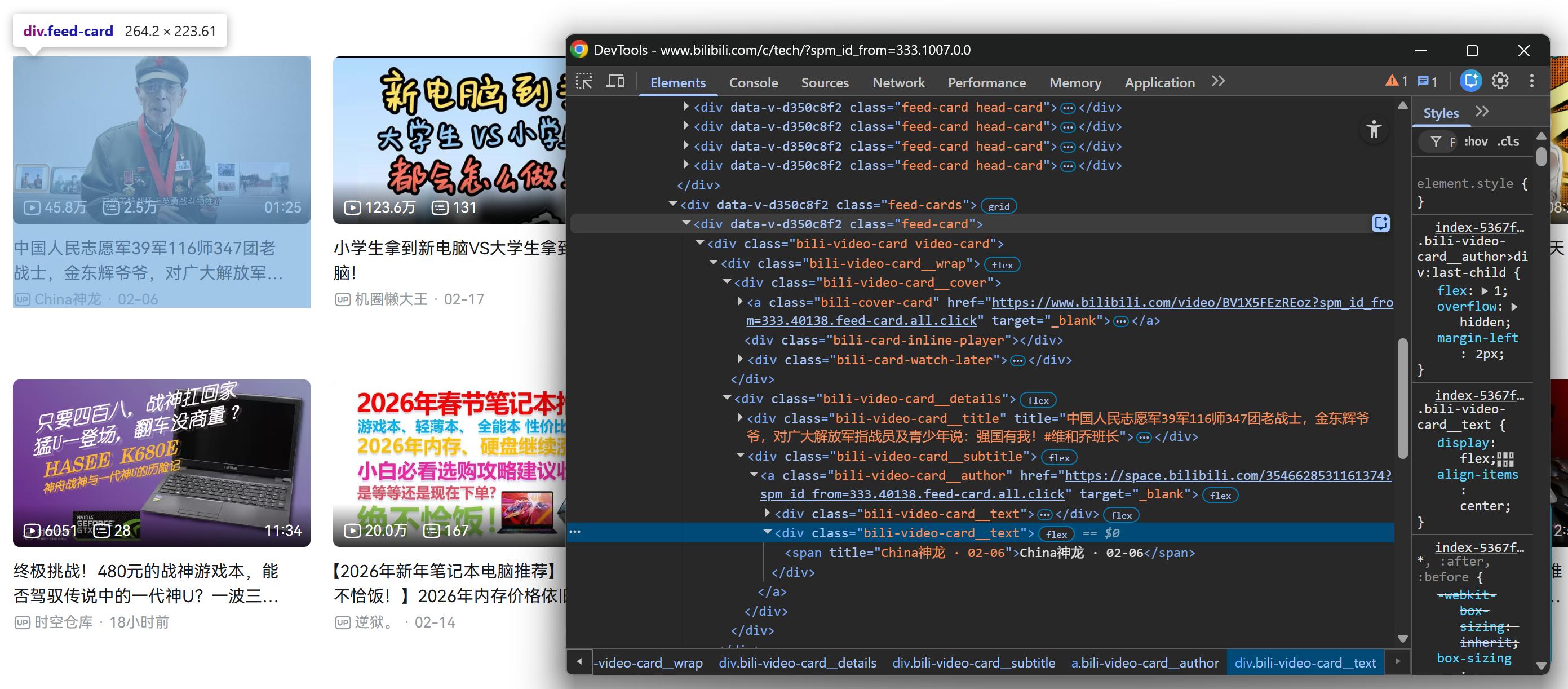
Afortunadamente, todos los elementos .feed-card comparten la misma estructura interna. Eso significa que no es necesario distinguir entre las tarjetas de vídeo cargadas en la renderización inicial de la página y las tarjetas de vídeo cargadas dinámicamente después de desplazarse. ¡Puede seleccionarlas todas utilizando los mismos selectores!
Observe cómo, de cada tarjeta de vídeo, puede recopilar:
- El título del vídeo del elemento
.bili-video-card__title a. - La URL del vídeo del atributo
hrefdel mismo nodo<a>del título. - El subtítulo sin formato (que contiene el nombre del autor + la fecha de publicación) del
span[title] .bili-video-card__subtitle. - La URL del perfil del autor del elemento
.bili-video-card__author.
¡Perfecto! Ahora que ya entiendes la estructura DOM, el siguiente paso es traducir este conocimiento en una lógica programática de extracción de datos de Bilibili.
Paso n.º 5: extraer los datos del vídeo
Recuerda que la página de destino contiene varias tarjetas de vídeo. Por lo tanto, primero necesitas una estructura de datos para almacenar los resultados extraídos. Una lista es perfecta para eso:
videos = []A continuación, itera sobre todas las tarjetas de vídeo y aplica la lógica de extracción descrita anteriormente:
for i in range(feed_card_count):
# Obtener la tarjeta de vídeo actual para extraer los datos
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Almacenar los datos extraídos
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)El fragmento anterior recorre cada tarjeta de vídeo y:
- Extrae el título, la URL del vídeo, los subtítulos sin procesar y la URL del perfil del autor.
- El parseo de la cadena de subtítulos (que sigue el formato
«<NOMBRE_DEL_AUTOR> · <FECHA>») permite extraer por separado el nombre del autor y la fecha del vídeo. - Crea un diccionario
de vídeosestructurado y lo añade a la listade vídeos.
Al final del bucle «for», la lista de vídeos contendrá más de 50 objetos de vídeo Bilibili estructurados. ¡Genial!
Paso n.º 6: Exportar los datos extraídos
Para facilitar el procesamiento de los datos extraídos, expórtalos a un archivo videos.json:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)Si ejecutas scraper.py ahora, debería generar un archivo videos.json que contenga datos de vídeo estructurados de Bilibili, como este: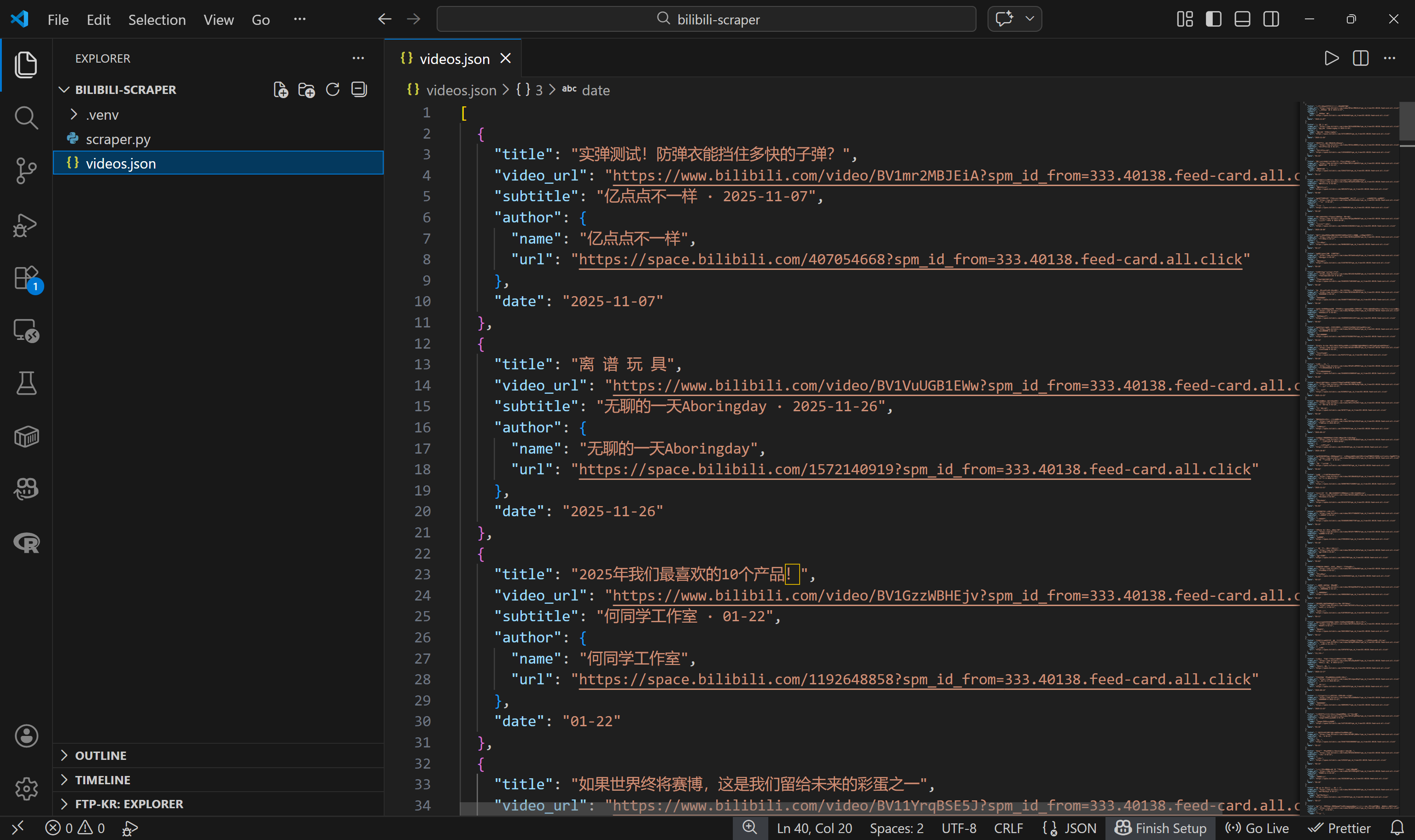
¡Misión cumplida! Empezaste con una página que contenía muchas tarjetas de vídeo y ahora tienes sus metadatos almacenados en un archivo JSON estructurado.
Si tu objetivo es simplemente extraer datos de Bilibili, el tutorial podría terminar aquí (solo asegúrate de consultar el paso final para ver el script completo). Si quieres ir más allá y descargar los vídeos, sigue leyendo…
Paso n.º 7: Prepárate para descargar los vídeos de Bilibili
La forma más fácil de descargar vídeos de Bilibili desde las URL que has extraído anteriormente es utilizando yt-dlp.
yt-dlp es un descargador de audio/vídeo con numerosas funciones que admite cientos de sitios web, incluido Bilibili. Se puede utilizar tanto desde la línea de comandos como a través de una API programática de Python. Aquí lo aprovecharemos programáticamente a través de su API de Python.
Con tu entorno virtual activado, instala yt-dlp:
pip install yt-dlpA continuación, añade un nuevo archivo llamado video-downloader.py a la raíz de tu proyecto:
bilibili-Scraper/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------Este archivo contendrá la lógica de descarga de vídeos de Bilibili impulsada por yt-dlp.
El script video-downloader.py debe:
- Leer el archivo
videos.json. - Extraer la
video_urlde cada vídeo. - Utilizar la clase
YoutubeDLdeyt_dlppara descargar los archivos de vídeo.
A continuación se muestra la implementación:
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Cargar los datos de vídeo desde el archivo JSON de entrada.
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Se han cargado {len(videos)} vídeos desde {INPUT_FILE}n")
# Asegúrate de que la carpeta de salida existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Descargando: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Vídeo #{index} descargadon")
except Exception as e:
print(f"Error al descargar el vídeo #{index}: {e}n")¡Vaya! Menos de 35 líneas de código fueron suficientes para lograr el objetivo.
Paso n.º 8: descargar los archivos de vídeo
Asegúrate de que ffmpeg está instalado localmente y, a continuación, ejecuta el script video-downloader.py. En la terminal, deberías ver algo como esto: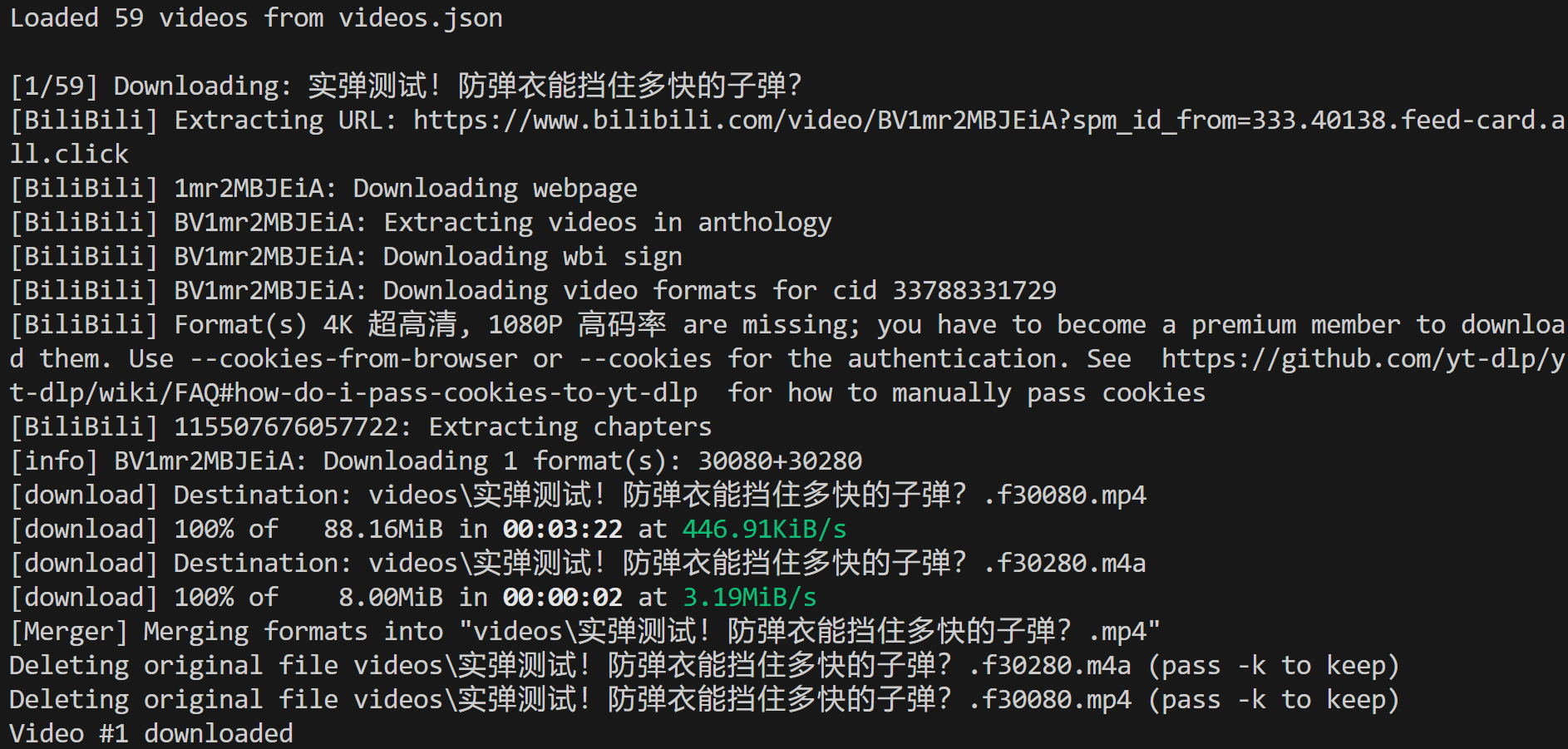
Esto muestra que se cargaron 59 vídeos desde el archivo de entrada videos.json y que el primero se descargó correctamente en la ruta local:
./videos/实弹测试!防弹衣能挡住多快的子弹?.mp4En Visual Studio Code, verás que el archivo de vídeo MP4 aparece en esa ruta exacta:
¡Increíble! Ahora tienes un sistema Bilibili totalmente automatizado que no solo descubre nuevos vídeos, sino que también los descarga. Con estos archivos, incluso puedes entrenar modelos de IA a través de un canal de ML multimodal.
Paso n.º 9: Código final
El archivo scraper.py contendrá el siguiente código:
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# Iniciar una instancia controlada de Chromium en modo headful.
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# La página «Tech» de Bilibili de destino
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navegar a la página de destino
await page.goto(target_bilibili_page)
# Desplazarse hacia abajo por toda la página 3 veces
for _ in range(3):
# Permitir la carga diferida
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Permitir la carga diferida
await asyncio.sleep(2)
# Esperar hasta que el elemento de la tarjeta de vídeo número 50 se adjunte al DOM
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="visible")
# Seleccionar todas las tarjetas de feed mediante el localizador
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count} tarjetas de feed cargadas.")
# Dónde almacenar los datos extraídos
videos = []
# Aplicar la lógica de extracción de datos de Bilili en cada tarjeta de vídeo
for i in range(feed_card_count):
# Obtener la tarjeta de vídeo actual para extraer datos
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Almacenar los datos extraídos
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# Cerrar el navegador y liberar sus recursos
await browser.close()
# Exportar los datos recopilados a un archivo JSON
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
print(f"{len(videos)} vídeos de Bilibili extraídos exportados a videos.json")
if __name__ == "__main__":
asyncio.run(main())Ejecutarlo con:
python Scraper.pyEsto generará un archivo videos.json que contiene los datos de los vídeos extraídos de Bilibili. A continuación, puedes descargar esos vídeos utilizando este script video-downloader.py:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Cargar los datos de vídeo del archivo JSON de entrada
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Loaded {len(videos)} videos from {INPUT_FILE}n")
# Asegúrate de que la carpeta de salida existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Descargando: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Vídeo #{index} descargadon")
except Exception as e:
print(f"Error al descargar el vídeo #{index}: {e}n")Ejecútalo con:
python video-downloader.pyEl resultado será una carpeta ./videos que contiene los archivos MP4 de cada vídeo de Bilibili descubierto.
¡Et voilà! Acabas de aprender a crear un Scraper de Bilibili y a utilizarlo para introducir los datos de los vídeos rastreados en un descargador. Este proceso te ayuda a recuperar los archivos de vídeo reales para el entrenamiento de IA o cualquier otro caso de uso.
Próximos pasos
Ahora que tienes tanto los metadatos estructurados como los archivos de vídeo reales, puedes pasar esos datos a un proceso de entrenamiento de IA. Por ejemplo, podrías extraer fotogramas para tareas de visión artificial, generar transcripciones para el ajuste del modelo NLP, analizar señales de audio o crear sistemas de recomendación basados en el contenido de los vídeos y los metadatos. La combinación de títulos, autores, fechas y archivos de vídeo sin procesar te proporciona un rico conjunto de datos multimodales listo para la experimentación.
Además, para acelerar la fase de descarga, considere la posibilidad de paralelizar el proceso para que se descarguen varios vídeos simultáneamente. Este enfoque ayuda a aprovechar al máximo el Ancho de banda disponible, lo que se traduce en tiempos de descarga más rápidos.
Una solución lista para la producción para el scraping de Bilibili: obtenga datos de vídeo para IA
Si ejecuta el script de descarga en un gran número de vídeos, es posible que empiece a ver errores como:
No se puede descargar la página web: Error HTTP 412: Precondición fallida (causado por <HTTPError 412: Precondition Failed>)Esto ocurre porque Bilibili cuenta con protecciones contra bots. Cuando la plataforma detecta tráfico sospechoso (como demasiadas solicitudes automatizadas procedentes de la misma IP), comienza a devolver una respuesta 412 Precondition Failed.
La página de error tiene este aspecto:
Este es solo uno de los retos a los que te enfrentas al extraer datos de Bilibili. Otros problemas comunes son los cambios estructurales en las páginas de destino, la detección basada en huellas digitales y otros. Aunque una configuración personalizada de Playwright + yt-dlp funciona bien para proyectos a pequeña escala, mantenerla a lo largo del tiempo puede resultar complejo y frágil.
Para extraer datos de Bilibili de forma fiable a gran escala, se necesita una infraestructura más robusta que gestione la rotación de IP, las huellas digitales del navegador, la Resolución de CAPTCHA y los reintentos automáticos. Eso es precisamente lo que ofrece el Scraper de Bilibili de Bright Data.
Esta API de scraping web, también disponible como Scraper sin código, recupera títulos de vídeos, fechas de subida, visualizaciones, me gusta, comentarios, favoritos, duraciones, nombres de los usuarios que los suben, descripciones, URL y mucho más. Todo ello mientras evita automáticamente los mecanismos antibots por usted.
Lo que hace único al Bilibili Scraper es que se ejecuta sobre una infraestructura de Proxy con más de 150 millones de IP en 195 países, lo que le permite alcanzar un tiempo de actividad del 99,99 %, una tasa de éxito del 99,95 % y admitir una concurrencia ilimitada. Esto permite escenarios de scraping a gran escala y a nivel empresarial, lo cual es fundamental si se tiene en cuenta que el entrenamiento de IA multimodal requiere grandes volúmenes de datos de vídeo.
Después de recuperar las URL de los vídeos, integra la API Web Unlocker de Bright Data en los flujos de trabajo automatizados de yt-dlp para evitar errores 412 y descargar vídeos sin bloqueos. Gracias a Bright Data, puedes olvidarte de los límites de velocidad, los bloqueos o los fallos de yt-dlp para obtener más vídeos para entrenar tus modelos de IA/ML.
Conclusión
En esta entrada del blog, ha visto qué tipo de datos se pueden extraer de Bilibili y los principales casos de uso que admite. Uno de los escenarios más interesantes es el entrenamiento de IA con datos de vídeo. Con cientos de millones de vídeos disponibles en la plataforma, Bilibili representa una fuente masiva de contenido multimedia de acceso público.
El proceso comienza con un Scraper de Bilibili que has aprendido a crear paso a paso. Este recopila metadatos de vídeo estructurados, incluidas las URL de los vídeos. A continuación, puedes pasar esas URL a un flujo de trabajo impulsado por yt-dlp para descargar los archivos de vídeo reales, como se muestra en esta guía.
Bright Data admite el rastreo de Bilibili a través de un Scraper dedicado y opciones de integración directa con yt-dlp para descargas fiables e ininterrumpidas. Para obtener más información, echa un vistazo a nuestras soluciones para acceder a datos de vídeo a gran escala para el entrenamiento de LLM.
¡Regístrese hoy mismo en Bright Data y explore nuestras soluciones de recopilación de datos de vídeo!





