

Google Trendses una herramienta gratuita que proporciona información sobre lo que la gente busca en Internet. Al analizar estas tendencias de búsqueda, las empresas pueden identificar las tendencias emergentes del mercado, comprender el comportamiento de los consumidores y tomar decisiones basadas en datos para impulsar las ventas y los esfuerzos de marketing. La extracción de datos de Google Trends permite a las empresas mantenerse por delante de la competencia al adaptar sus estrategias.
En este artículo, aprenderás a extraer datos de Google Trends utilizando Python y a almacenar y analizar esos datos de forma eficaz.
Por qué extraer datos de Google Trends
Extraer y analizar datos de Google Trends puede ser muy útil en diversos escenarios, entre los que se incluyen los siguientes:
- Investigación de palabras clave:los creadores de contenido y los especialistas en SEO necesitan saber qué palabras clave están ganando terreno para poder atraer más tráfico orgánico a sus sitios web. Google Trends ayuda a explorar los términos de búsqueda más populares por región, categoría o tiempo, lo que le permite optimizar su estrategia de contenido en función de los intereses cambiantes de los usuarios.
- Estudio de mercado:los profesionales del marketing deben comprender los intereses de los clientes y anticiparse a los cambios en la demanda para tomar decisiones informadas. Recopilar y analizar los datos de Google Trends les permite comprender los patrones de búsqueda de los clientes y supervisar las tendencias a lo largo del tiempo.
- Investigación social:varios factores, como los acontecimientos locales y mundiales, las innovaciones tecnológicas, los cambios económicos y los acontecimientos políticos, pueden influir significativamente en el interés público y las tendencias de búsqueda. Los datos de Google Trends proporcionan información valiosa sobre estas tendencias cambiantes a lo largo del tiempo, lo que permite realizar análisis exhaustivos y predicciones futuras fundamentadas.
- Supervisión de la marca:Las empresas y los equipos de marketing deben supervisar cómo se percibe su marca en el mercado. Al recopilar datos de Google Trends, puede comparar la visibilidad de su marca con la de sus competidores y reaccionar rápidamente a los cambios en la percepción del público.
La alternativa de Bright Data al rastreo de Google Trends: la API SERP de Bright Data
En lugar de extraer manualmente los datos de Google Trends, utilice la API SERP de Bright Data para automatizar la recopilación de datos en tiempo real de los motores de búsqueda. La API SERP ofrece datos estructurados, como resultados de búsqueda y tendencias, con una geolocalización precisa y sin riesgo de bloqueos o CAPTCHAs. Solo se paga por las solicitudes exitosas, y los datos se entregan en formatos JSON o HTML para facilitar su integración.
Esta solución es más rápida, más escalable y elimina la necesidad de complejos scripts de scraping. Comience su prueba gratuita y optimice su recopilación de datos con el scraper de Google Trends de Bright Data.
Cómo extraer datos de Google Trends
Google Trends no ofrece API oficiales para extraer datos de tendencias, pero puede utilizar varias API y bibliotecas de terceros para acceder a esta información, comopytrends, una biblioteca de Python que proporciona API fáciles de usar que le permiten descargar automáticamente informes de Google Trends. Sin embargo, aunque pytrends es fácil de usar, proporciona datos limitados porque no puede acceder a datos que se representan dinámicamente o que se encuentran detrás de elementos interactivos. Para solucionar este problema, puede utilizarSeleniumconBeautiful Souppara extraer datos de Google Trends y extraer datos de páginas web renderizadas dinámicamente. Selenium es una herramienta de código abierto para interactuar con sitios web y extraer datos de ellos que utiliza JavaScript para cargar contenido dinámicamente. Beautiful Soup ayuda a realizar el Parseo del contenido HTML extraído, lo que le permite extraer datos específicos de las páginas web.
Antes de comenzar este tutorial, debe tenerPythoninstalado y configurado en su equipo. También debe crear un directorio de proyecto vacío para los scripts de Python que creará en las siguientes secciones.
Crear un entorno virtual
Un entorno virtual le permite aislar los paquetes de Python en directorios separados para evitar conflictos de versiones. Para crear un nuevo entorno virtual, ejecute el siguiente comando en su terminal:
# navega a la raíz del directorio de tu proyecto antes de ejecutar el comando
python -m venv myenv
Este comando crea una carpeta llamada myenv en el directorio del proyecto. Active el entorno virtual ejecutando el siguiente comando:
source myenv/bin/activate
Cualquier comando Python o pip posterior también se ejecutará en este entorno.
Instala tus dependencias
Como se ha mencionado anteriormente, necesitas Selenium y Beautiful Soup para extraer y parsear páginas web. Además, para analizar y visualizar los datos extraídos, debes instalar los módulos PythonpandasyMatplotlib. Utiliza el siguiente comando para instalar estos paquetes:
pip install beautifulsoup4 pandas matplotlib selenium
Consultar los datos de búsqueda de Google Trends
Elpanel de control de Google Trendsle permite explorar las tendencias de búsqueda por región, intervalo de fechas y categoría. Por ejemplo, esta URL muestra las tendencias de búsqueda de café en Estados Unidos durante los últimos siete días:
https://trends.google.com/trends/explore?date=now%207-d&geo=US&q=coffee
Cuando abras esta página web en tu navegador, verás que los datos se cargan dinámicamente utilizando JavaScript. Para extraer contenido dinámico, puedes utilizarSelenium WebDriver, que imita las interacciones del usuario, como hacer clic, escribir o desplazarse.
Puede utilizarwebdriveren su script de Python para cargar la página web en una ventana del navegador y extraer el código fuente de la página una vez que se haya cargado el contenido. Para manejar contenido dinámico, puede añadir untime.sleepexplícito para asegurarse de que todo el contenido se haya cargado antes de obtener el código fuente de la página. Si desea aprender más técnicas para manejar contenido dinámico, consulteesta guía.
Cree un archivo main.py en la raíz del proyecto y añádale el siguiente fragmento de código:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def get_driver():
# actualice la ruta a la ubicación de su binario de Chrome
CHROME_PATH = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
options = Options()
# options.add_argument("--headless=new")
options.binary_location = CHROME_PATH
driver = webdriver.Chrome(options=options)
return driver
def get_raw_trends_data(
driver: webdriver.Chrome, date_range: str, geo: str, query: str)
-> str:
url = f"https://trends.google.com/trends/explore?date={date_range}&geo={geo}&q={query}"
print(f"Obteniendo datos de {url}")
driver.get(url)
# solución alternativa para obtener el código fuente de la página tras el error inicial 429
driver.get(url)
driver.maximize_window()
# Esperar a que se cargue la página
time.sleep(5)
return driver.page_source
El método get_raw_trends_data acepta como parámetros el intervalo de fechas, la región geográfica y el nombre de la consulta, y utiliza Chrome WebDriver para recuperar el contenido de la página. Tenga en cuenta que el método driver.get se llama dos veces como solución alternativa para corregir el error 429 inicial que genera Google cuando se carga la URL por primera vez.
Utilizará este método en las siguientes secciones para recuperar datos.
Analizar datos con Beautiful Soup
La página Tendencias de un término de búsqueda incluye un widget Interés por subregión que contiene registros paginados con valores entre 0 y 100, lo que indica la popularidad del término de búsqueda en función de la ubicación. Utilice el siguiente fragmento de código para analizar estos datos con Beautiful Soup:
# Añadir importación
from bs4 import BeautifulSoup
def extract_interest_by_sub_region(content: str) -> dict:
soup = BeautifulSoup(content, "html.parser")
interest_by_subregion = soup.find("div", class_="geo-widget-wrapper geo-resolution-subregion")
related_queries = interest_by_subregion.find_all("div", class_="fe-atoms-generic-content-container")
# Diccionario para almacenar los datos extraídos
interest_data = {}
# Extraer el nombre de la región y el porcentaje de interés
for query in related_queries:
items = query.find_all("div", class_="item")
for item in items:
region = item.find("div", class_="label-text").text.strip()
interest = item.find("div", class_="progress-value").text.strip()
interest_data[region] = interest
return interest_data
Este fragmento de código busca el div coincidente para los datos de la subregión utilizando su nombre de clase y recorre el resultado para construir un diccionario interest_data.
Ten en cuenta que el nombre de la clase podría cambiar en el futuro y que es posible que tengas que utilizar lafunciónInspeccionarelemento de Chrome DevToolspara encontrar el nombre correcto.
Ahora que ha definido los métodos auxiliares, utilice el siguiente fragmento de código para consultar los datos de «café»:
# Parámetros
date_range = "now 7-d"
geo = "US"
query = "coffee"
# Obtener los datos sin procesar
driver = get_driver()
raw_data = get_raw_trends_data(driver, "now 7-d", "US", "coffee")
# Extraer el interés por región
interest_data = extract_interest_by_sub_region(raw_data)
# Imprimir los datos extraídos
for region, interest in interest_data.items():
print(f"{region}: {interest}")
El resultado será similar a este:
Hawái: 100
Montana: 96
Oregón: 90
Washington: 86
California: 84
Gestionar la paginación de datos
Dado que los datos del widget están paginados, el fragmento de código de la sección anterior solo devuelve los datos de la primera página del widget. Para obtener más datos, puede utilizar Selenium WebDriver para buscar y hacer clic en el botón Siguiente. Además, su script debe gestionar el banner de consentimiento de cookies haciendo clic en el botón Aceptar para garantizar que el banner no obstruya otros elementos de la página.
Para gestionar las cookies y la paginación, añada este fragmento de código al final de main.py:
# Añadir importación
from selenium.webdriver.common.by import By
all_data = {}
# Aceptar las cookies
driver.find_element(By.CLASS_NAME, "cookieBarConsentButton").click()
# Obtener datos de interés paginados
while True:
# Hacer clic en el botón md para cargar más datos si están disponibles
try:
geo_widget = driver.find_element(
By.CSS_SELECTOR, "div.geo-widget-wrapper.geo-resolution-subregion"
)
# Buscar el botón «Cargar más» con el nombre de clase «md-button» y la etiqueta aria «Siguiente»
load_more_button = geo_widget.find_element(
By.CSS_SELECTOR, "button.md-button[aria-label='Next']"
)
icon = load_more_button.find_element(By.CSS_SELECTOR, ".material-icons")
# Comprueba si el botón está desactivado verificando que el nombre de la clase incluye arrow-right-disabled.
if "arrow-right-disabled" in icon.get_attribute("class"):
print("No hay más datos para cargar")
break
load_more_button.click()
time.sleep(2)
extracted_data = extract_interest_by_sub_region(driver.page_source)
all_data.update(extracted_data)
except Exception as e:
print("No hay más datos que cargar", e)
break
driver.quit()
Este fragmento utiliza la instancia del controlador existente para buscar y hacer clic en el botón Siguiente, comparándolo con su nombre de clase. Comprueba la presencia de la clase flecha-derecha-desactivada en el elemento para determinar si el botón está desactivado, lo que indica que ha llegado a la última página del widget. Sale del bucle cuando se cumple esta condición.
Visualizar los datos
Para acceder fácilmente y analizar más a fondo los datos que ha recopilado, puede conservar los datos de la subregión extraídos en un archivo CSV utilizando un csv.DictWriter.
Comience definiendo save_interest_by_sub_region en main.py para guardar el diccionario all_data en un archivo CSV:
# Añadir importación
import csv
def save_interest_by_sub_region(interest_data: dict):
interest_data = [{"Region": region, "Interest": interest} for region, interest in interest_data.items()]
csv_file = "interest_by_region.csv"
# Abrir el archivo CSV para escribir
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["Region", "Interest"])
writer.writeheader() # Escribir el encabezado
writer.writerows(interest_data) # Escribir los datos
print(f"Datos guardados en {csv_file}")
return csv_file
A continuación, puede utilizarpandaspara abrir el archivo CSV como unDataFramey realizar análisis, como filtrar datos por condiciones específicas, agregar datos con operacionesde agrupacióno visualizar tendencias con gráficos.
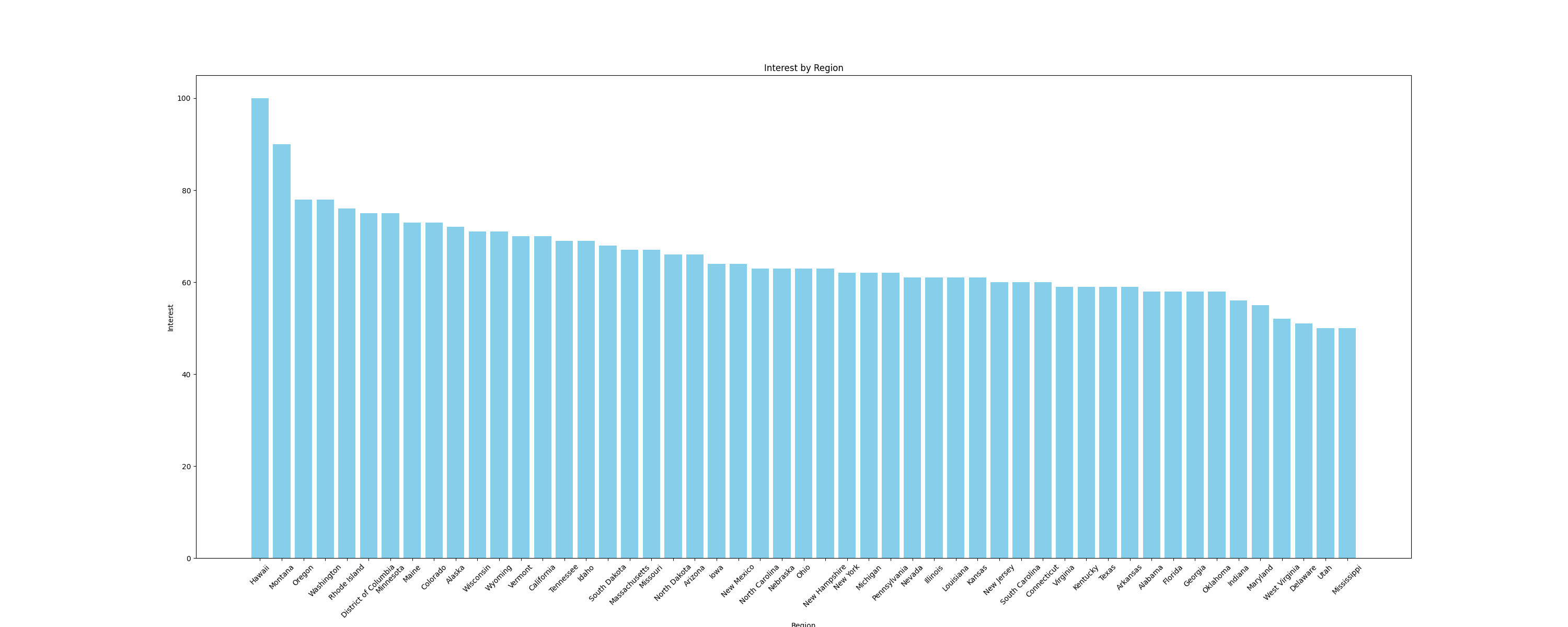
Por ejemplo, visualicemos los datos como ungráfico de barraspara comparar el interés por subregiones. Para crear gráficos, utilice la biblioteca Pythonmatplotlib, que funciona a la perfección con DataFrames. Añada la siguiente función al archivomain.pypara crear un gráfico de barras y guárdelo como imagen:
# Añadir importaciones
import pandas as pd
import matplotlib.pyplot as plt
def plot_sub_region_data(csv_file_path, output_file_path):
# Cargar los datos del archivo CSV
df = pd.read_csv(csv_file_path)
# Crear un gráfico de barras para comparar por región
plt.figure(figsize=(30, 12))
plt.bar(df["Region"], df["Interest"], color="skyblue")
# Añadir títulos y etiquetas
plt.title('Interés por región')
plt.xlabel('Región')
plt.ylabel('Interés')
# Girar las etiquetas del eje x si es necesario
plt.xticks(rotation=45)
# Mostrar el gráfico
plt.savefig(output_file_path)
Añade el siguiente fragmento de código al final del archivo main.py para llamar a las funciones anteriores:
csv_file_path = save_interest_by_sub_region(all_data)
output_file_path = "interest_by_region.png"
plot_sub_region_data(csv_file_path, output_file_path)
Este fragmento crea un gráfico similar al siguiente:
Todo el código de este tutorial está disponible eneste repositorio de GitHub.
Retos del scraping
En este tutorial, ha extraído una pequeña cantidad de datos de Google Trends, pero a medida que sus scripts de scraping crecen en tamaño y complejidad, es probable que se enfrente a retos como bloqueos de IP y CAPTCHAs.
Por ejemplo, a medida que envías tráfico más frecuente a un sitio web utilizando este script, podrías enfrentarte a bloqueos de IP, ya que muchos sitios web cuentan con medidas de seguridad para detectar y bloquear el tráfico de bots. Para evitarlo, puedes utilizar la rotación manual de IP o uno de los mejores servicios de proxy. Si no estás seguro de qué tipo de proxy debes utilizar, lee nuestro artículo que trata sobre los mejores tipos de proxy para el Scraping web.
Encontrar un CAPTCHA o reCAPTCHA es otro desafío común que utilizan los sitios web cuando detectan o sospechan tráfico de bots o anomalías. Para evitarlo, puede reducir la frecuencia de las solicitudes, utilizar encabezados de solicitud adecuados o utilizar servicios de terceros que puedan resolver estos desafíos.
Conclusión
En este artículo, ha aprendido a extraer datos de Google Trends con Python utilizando Selenium y Beautiful Soup.
A medida que continúe en su viaje por el scraping web, es posible que se encuentre con retos como prohibiciones de IP y CAPTCHAs. En lugar de gestionar complejos scripts de scraping, considere la posibilidad de utilizar la API SERP de Bright Data, que automatiza el proceso de recopilación de datos precisos y en tiempo real de los motores de búsqueda, incluyendo Google Trends. La API SERP gestiona el contenido dinámico, la segmentación basada en la ubicación y garantiza altas tasas de éxito, lo que le ahorra tiempo y esfuerzo.
¡Regístrate ahora y comienza tu prueba gratuita de la API SERP!






