

El scraping web es una técnica automatizada para extraer y recopilar grandes cantidades de datos de sitios web, utilizando diferentes herramientas o programas. Se utiliza comúnmente para extraer tablas HTML, que contienen datos organizados en columnas y filas. Una vez recopilados, estos datos pueden analizarse o utilizarse para la investigación. Para obtener una guía más detallada, consulta este artículo sobreel scraping web HTML.
Este tutorial le enseñará a extraer tablas HTML de sitios web utilizando Python.
Requisitos previos
Antes de comenzar este tutorial, debeinstalar Python versión 3.8 o posteriorycrear un entorno virtual. Si es nuevo en el Scraping web con Python,este artículoes un punto de partida útil.
Una vez creado el entorno, instala los siguientes paquetes de Python:
- Requests
- Beautiful Soup
- pandas
Puede instalar los paquetes con el siguiente comando:
pip install requests beautifulsoup4 pandas
Comprender la estructura de la página web
En este tutorial, extraerá datos delsitio web Worldometer. Esta página web contiene datos actualizados sobre países de todo el mundo, incluidas sus respectivas cifras de población para 2024:
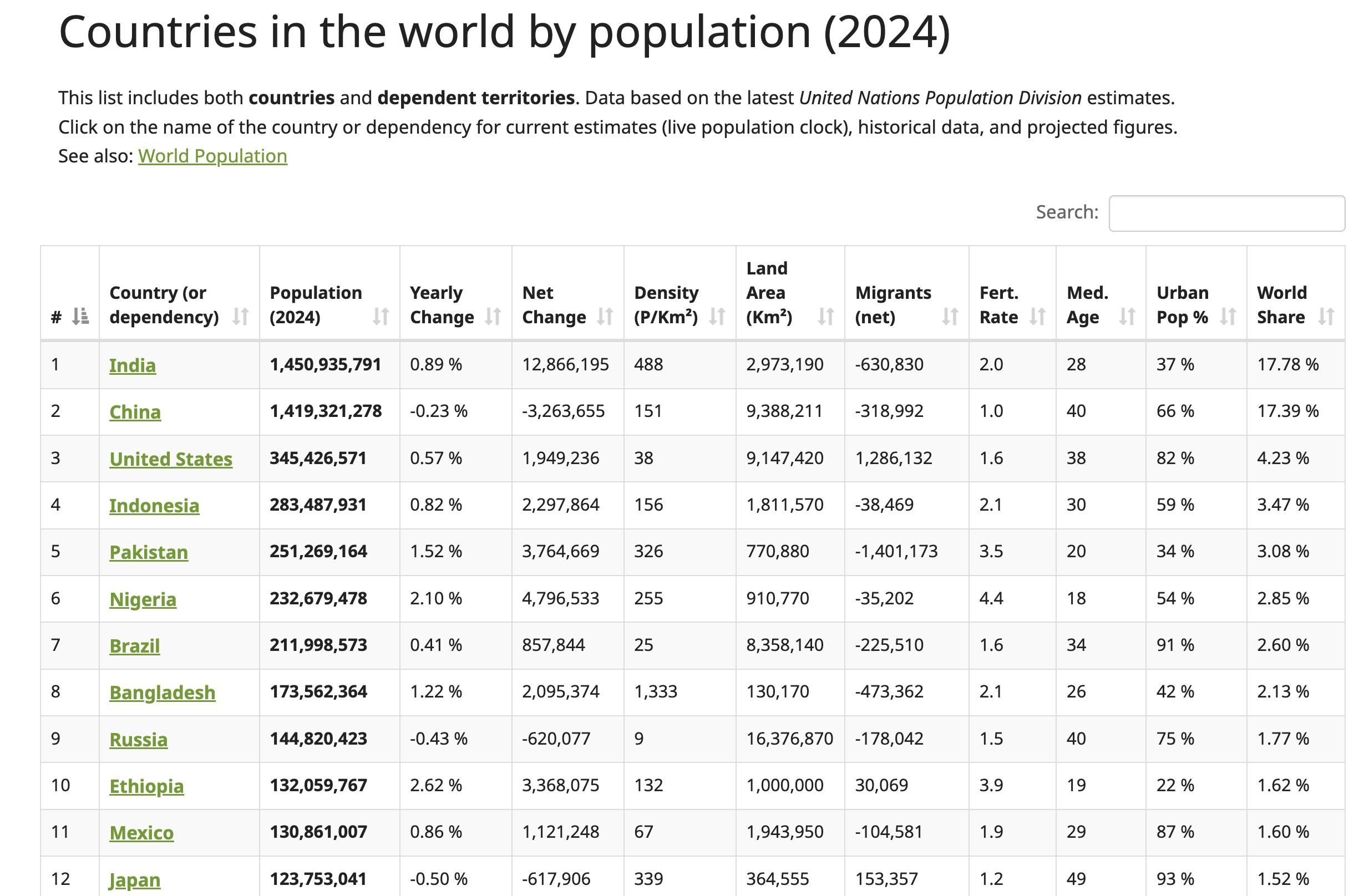
Para localizar la estructura de la tabla HTML, haz clic con el botón derecho del ratón en la tabla (que se muestra en la captura de pantalla anterior) y selecciona Inspeccionar. Esta acción abre el panel Herramientas de desarrollo, que muestra el código HTML de la página, con el elemento seleccionado resaltado:
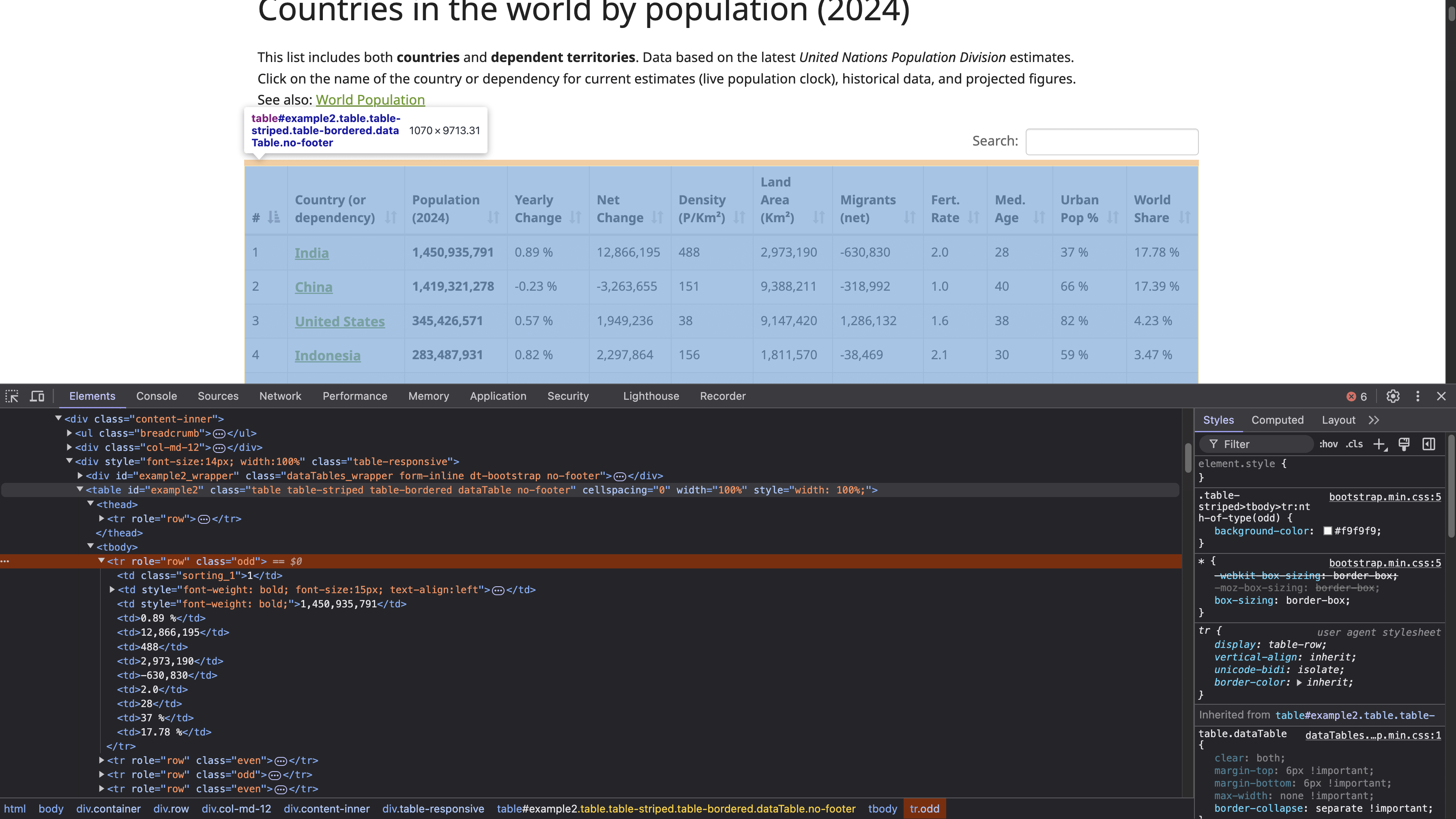
La etiqueta <table> con el ID example2 define el comienzo de la estructura de la tabla. Esta tabla tiene encabezados con las etiquetas <th>, y las filas se definen mediante etiquetas <tr>, donde cada <tr> representa una nueva fila horizontal en la tabla. Dentro de cada <tr>, la etiqueta <td> crea celdas individuales dentro de esa fila, que contienen los datos que se muestran en cada celda.
Nota: Antes de realizar cualquier extracción, es importante que revise y cumpla con la política de privacidad y los términos de servicio del sitio web para asegurarse de que cumple con todas las restricciones sobre el uso de datos y el acceso automatizado.
Enviar una solicitud HTTP para acceder a la página web
Para enviar una solicitud HTTP y acceder a la página web, cree un archivo Python (por ejemplo, html_table_scraper.py) e importe los paquetes requests, BeautifulSoup y pandas:
# importar paquetes
import requests
from bs4 import BeautifulSoup
import pandas as pd
A continuación, defina la URL de la página web que desea extraer y envíe una solicitud GET a esa página web utilizando https://www.worldometers.info/world-population/population-by-country/:
# Enviar una solicitud al sitio web para obtener el contenido de la página
url = 'https://www.worldometers.info/world-population/population-by-country/'
Para comprobar si la respuesta es correcta, envía una solicitud utilizando el método get() de Requests:
# Obtener el contenido de la URL
response = requests.get(url)
# Comprobar el estado de la respuesta.
if response.status_code == 200:
print("¡La solicitud se ha realizado correctamente!")
else:
print(f"Error: {response.status_code} - {response.text}")
Este código envía una solicitud GET a una URL específica y, a continuación, comprueba el estado de la respuesta. Una respuesta 200 indica que la solicitud se ha realizado correctamente.
Utilice el siguiente comando para ejecutar el script de Python en su terminal:
python html_table_scraper.py
El resultado debería ser similar a este:
¡La solicitud se ha realizado correctamente!
Dado que la solicitud GET se ha realizado correctamente, ahora dispone del contenido HTML de toda la página web, incluida la tabla HTML.
Parsear el HTML con Beautiful Soup
Beautiful Soup puede manejar contenido HTML mal formateado o dañado, lo cual es común al realizar scraping web. Aquí, utilizará el paquete Beautiful Soup para hacer lo siguiente:
- Realizar el parseo del contenido HTML de la página web para encontrar la tabla que presenta los datos de población.
- Recopilar los encabezados de la tabla.
- Recopilar todos los datos presentados en las filas de la tabla.
Para realizar el parseo del contenido recopilado, cree un objeto Beautiful Soup:
# Analizar el contenido HTML utilizando BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
A continuación, localice el elemento de tabla en el HTML con el atributo id «example2». Esta tabla contiene la población de los países en 2024:
# Busca la tabla que contiene los datos de población
table = soup.find('table', attrs={'id': 'example2'})
Recopilar encabezados de tabla
La tabla tiene un encabezado ubicado en las etiquetas HTML <thead> y <th>. Utilice el método find() del paquete Beautiful Soup para extraer los datos de la etiqueta <thead> y el método find_all() para recopilar todos los encabezados:
# Recopilar los encabezados de la tabla
headers = []
# Localizar la fila de encabezados dentro de la etiqueta <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Añadir el texto del encabezado a la lista de encabezados
headers.append(th.text.strip())
Este código crea una lista Python vacía llamada headers, localiza la etiqueta HTML <thead> para encontrar todos los encabezados dentro de las etiquetas HTML <th> y, a continuación, añade cada encabezado recopilado a la lista de encabezados.
Recopilar datos de filas de tabla
Para recopilar los datos de cada fila, cree una lista Python vacía llamada data para almacenar los datos extraídos:
# Inicializar una lista vacía para almacenar nuestros datos
data = []
A continuación, extraiga los datos de cada fila de la tabla utilizando el método find_all() y añádalos a la lista de Python:
# Recorrer cada fila de la tabla (omitiendo la fila del encabezado)
for tr in table.find_all('tr')[1:]:
# Crear una lista con los datos de la fila actual
row = []
# Buscar todas las celdas de datos de la fila actual
for td in tr.find_all('td'):
# Obtener el contenido de texto de la celda y eliminar los espacios adicionales
cell_data = td.text.strip()
# Añadir los datos de la celda limpios a la lista de filas
row.append(cell_data)
# Después de obtener todas las celdas de esta fila, añadir la fila a nuestra lista de datos.
data.append(row)
# Convertir los datos recopilados en un DataFrame de pandas para facilitar su manejo.
df = pd.DataFrame(data, columns=headers)
# Imprimir el DataFrame para ver el número de filas y columnas.
print(df.shape)
Este código itera a través de todas las etiquetas HTML <tr> que se encuentran dentro de la tabla, comenzando por la segunda fila (omitiendo la fila del encabezado). Para cada fila (<tr>), se crea una fila de lista vacía para almacenar los datos de las celdas de esa fila. Dentro de la fila, el código encuentra todas las etiquetas HTML <td> utilizando el método find_all(), que representa las celdas de datos individuales de la fila.
Para cada etiqueta HTML <td>, el código extrae el contenido de texto utilizando el atributo .texty aplica el método .strip() para eliminar cualquier espacio en blanco al principio o al final del texto. Los datos de la celda limpios se añaden a la lista de filas. Después de procesar todas las celdas de la fila actual, toda la fila se añade a la lista de datos. Por último, se convierten los datos recopilados a un DataFrame de pandas con los nombres de columna definidos por la lista de encabezados y, a continuación, se muestra la forma de los datos.
El script completo de Python debería tener este aspecto:
# Importar paquetes
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Enviar una solicitud al sitio web para obtener el contenido de la página
url = 'https://www.worldometers.info/world-population/population-by-country/'
# Obtener el contenido de la URL
response = requests.get(url)
# Comprobar si la solicitud se ha realizado correctamente
if response.status_code == 200:
# Analizar el contenido HTML utilizando Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Buscar la tabla que contiene los datos de población por su ID
table = soup.find('table', attrs={'id': 'example2'})
# Recopilar los encabezados de la tabla
headers = []
# Localizar la fila de encabezados dentro de la etiqueta HTML <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Añadir el texto del encabezado a la lista de encabezados
headers.append(th.text.strip())
# Inicializar una lista vacía para almacenar nuestros datos.
data = []
# Recorrer cada fila de la tabla (omitiendo la fila de encabezado).
for tr in table.find_all('tr')[1:]:
# Crear una lista con los datos de la fila actual.
row = []
# Buscar todas las celdas de datos de la fila actual
for td in tr.find_all('td'):
# Obtener el contenido de texto de la celda y eliminar los espacios adicionales
cell_data = td.text.strip()
# Añadir los datos de la celda limpios a la lista de filas
row.append(cell_data)
# Después de obtener todas las celdas de esta fila, añadir la fila a nuestra lista de datos
data.append(row)
# Convertir los datos recopilados en un DataFrame de pandas para facilitar su manejo
df = pd.DataFrame(data, columns=headers)
# Imprimir el DataFrame para ver los datos recopilados
print(df.shape)
else:
print(f"Error: {response.status_code} - {response.text}")
Utilice el siguiente comando para ejecutar el script de Python en su terminal:
python html_table_scraper.py
El resultado debería ser similar a este:
(234,12)
En este punto, ha extraído correctamente 234 filas y 12 columnas de la tabla HTML.
A continuación, utilice el método head() de pandas y print() para ver las primeras diez filas de los datos extraídos:
print(df.head(10))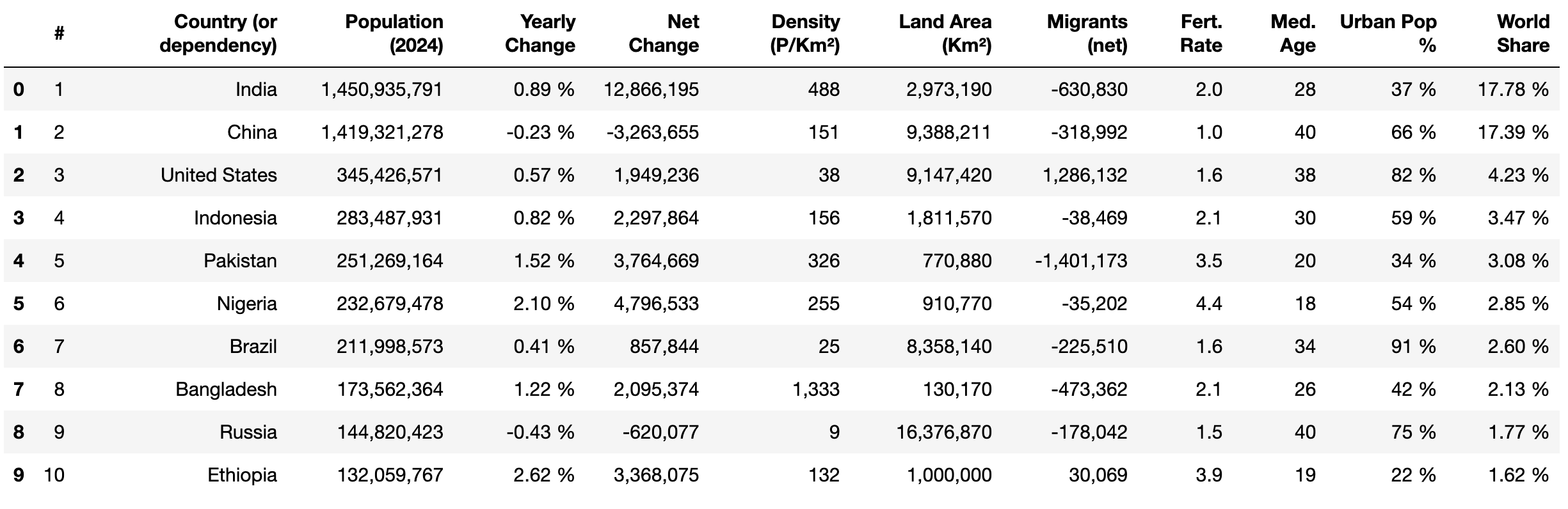
Limpiar y estructurar los datos
Al extraer datos de una tabla HTML, es importante limpiarlos para garantizar su coherencia, precisión y usabilidad adecuada para el análisis. Los datos sin procesar extraídos de una tabla HTML pueden contener diversos problemas, como valores que faltan, problemas de formato, caracteres no deseados o tipos de datos incorrectos. Estos problemas pueden dar lugar a análisis inexactos y resultados poco fiables. Una limpieza adecuada ayuda a estandarizar el conjunto de datos y garantiza que se ajuste a la estructura prevista para el análisis.
En esta sección, se realizan las siguientes tareas de limpieza de datos:
- Renombrar los nombres de las columnas
- Sustitución de valores que faltan en los datos de las filas
- Eliminar comas y convertir los tipos de datos al formato correcto
- Eliminar el signo de porcentaje (%) y convertir los tipos de datos al formato correcto
- Cambiar los tipos de datos de las columnas numéricas
Renombrar nombres de columnas
pandas tiene un método llamado rename() que cambia el nombre de una columna específica por el que usted desee. Este método es útil cuando los nombres de las columnas no son descriptivos o cuando desea que los nombres de las columnas sean más fáciles de manejar.
Para renombrar una columna específica, se pasa un diccionario al parámetro columns, donde las claves son los nombres actuales de las columnas y los valores son los nuevos nombres que se desean asignar. Aplique este método para cambiar los siguientes nombres de columna:
#aRankVariación anualaVariación anual %World ShareaWorld Share %
# Renombrar columnas
df.rename(columns={'#': 'Rank'}, inplace=True)
df.rename(columns={'Yearly Change': 'Yearly Change %'}, inplace=True)
df.rename(columns={'World Share': 'World Share %'}, inplace=True)
# Mostrar las primeras 5 filas
print(df.head())
Ahora tus columnas deberían tener este aspecto:

Reemplazar valores perdidos
Los valores faltantes en los datos pueden afectar a los cálculos, como los promedios o las sumas, lo que da lugar a resultados inexactos y conclusiones incorrectas. Es necesario eliminarlos, sustituirlos o rellenarlos con valores concretos antes de realizar cualquier cálculo o análisis del conjunto de datos.
La columna «Urban Pop %» contiene actualmente valores faltantes etiquetados como N.A.. Reemplaza N.A. por 0 % utilizando el método replace() de pandas de la siguiente manera:
# Reemplazar «N.A.» por «0 %» en la columna «Urban Pop %»
df['Urban Pop %'] = df['Urban Pop %'].replace('N.A.', '0%')
Elimine los signos de porcentaje y convierta los tipos de datos
Las columnas «Yearly Change %», «Urban Pop %» y «World Share %» contienen valores numéricos seguidos de un signo de porcentaje (por ejemplo, 37,0 %). Esto dificulta la realización de operaciones matemáticas, como el cálculo de la media, el máximo y la desviación estándar, para el análisis.
Para solucionarlo, puede aplicar el método replace() para eliminar el signo % y, a continuación, aplicar el método astype() para convertirlos a un tipo de datos flotante para su análisis:
# Eliminar el signo «%» y convertir a float
df['Yearly Change %'] = df['Yearly Change %'].replace('%', '', regex=True).astype(float)
df['Urban Pop %'] = df['Urban Pop %'].replace('%', '', regex=True).astype(float)
df['World Share %'] = df['World Share %'].replace('%', '', regex=True).astype(float)
# Mostrar las primeras 5 filas
df.head()
Este código elimina el signo % de los valores de las columnas «Variación anual %», «Población urbana %» y «Porcentaje mundial %» utilizando el método replace() con una expresión regular. A continuación, convierte los valores limpios a un tipo de datos flotante utilizando astype(float). Por último, muestra las primeras cinco filas del DataFrame con df.head().
El resultado debería ser similar a este:

Eliminar comas y convertir tipos de datos
Actualmente, las columnas Población (2024), Variación neta, Densidad (P/Km²), Superficie terrestre (Km²) y Migrantes (netos) contienen valores numéricos con comas (por ejemplo, 1 949 236). Esto hace imposible realizar operaciones matemáticas para el análisis.
Para solucionarlo, puede aplicar replace() y astype() para eliminar las comas y convertir los números al tipo de datos enteros:
# Eliminar comas y convertir a enteros
columns_to_convert = [
'Población (2024)', 'Variación neta', 'Densidad (P/Km²)', 'Superficie terrestre (Km²)',
'Migrantes (netos)'
]
for column in columns_to_convert:
# Asegúrate primero de que la columna se trate como una cadena
df[column] = df[column].astype(str)
# Elimina las comas
df[column] = df[column].str.replace(',', '')
# Convierte a enteros
df[column] = df[column].astype(int)
Este código define una lista, columns_to_convert, que contiene los nombres de las columnas que necesitan procesarse. Para cada columna de la lista, se asegura de que los valores de la columna se traten como cadenas utilizando astype(str). A continuación, elimina las comas de los valores utilizando str.replace(',', ''), y convierte los valores limpios a enteros con astype(int), lo que hace que los valores sean adecuados para operaciones matemáticas.
Cambiar los tipos de datos de las columnas numéricas
Las columnas Rank, Med. Age y Fert. Rate presentan datos que se almacenan como un tipo de datos de objeto, pero que contienen valores numéricos. Convierta los datos de estas columnas a tipos de datos enteros o flotantes para permitir operaciones matemáticas:
# Convertir a tipos de datos enteros o flotantes y enteros
df['Rank'] = df['Rank'].astype(int)
df['Med. Age'] = df['Med. Age'].astype(int)
df['Fert. Rate'] = df['Fert. Rate'].astype(float)
Este código convierte los valores de las columnas Rank y Med. Age en un tipo de datos entero y los valores de Fert. Rate en un tipo de datos flotante.
Por último, comprueba que los datos limpios tienen los tipos de datos correctos utilizando el método head():
print(df.head(10))
El resultado debería ser similar a este:
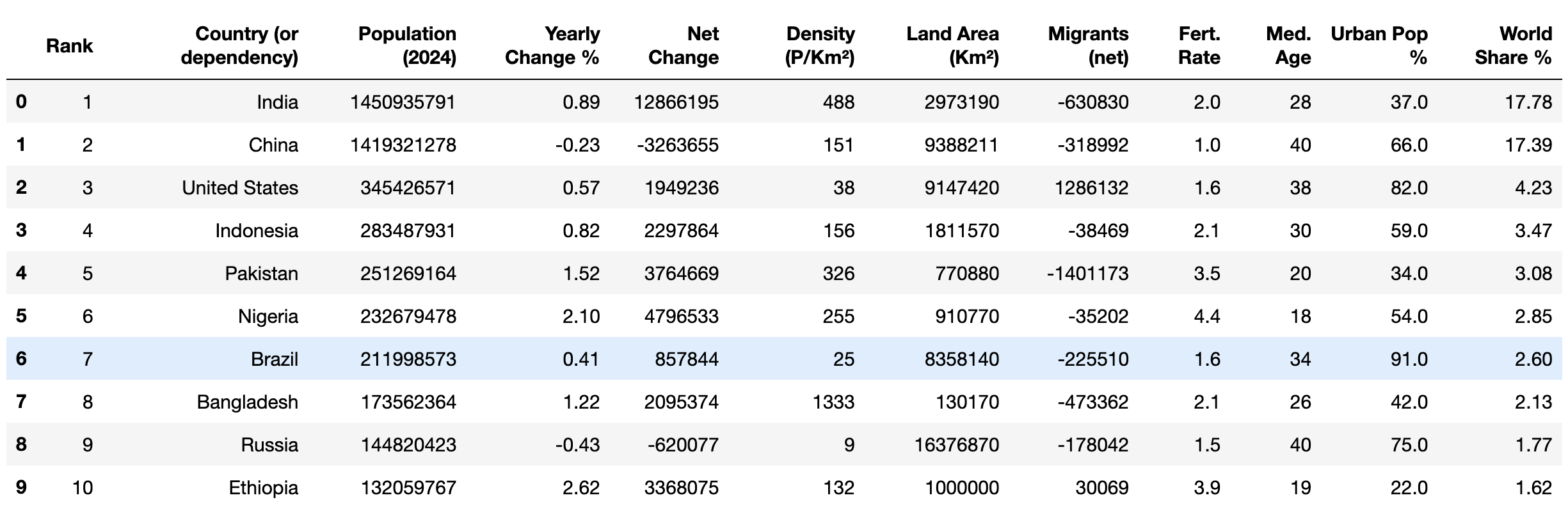
Ahora que los datos están limpios, puede comenzar a aplicar diferentes operaciones matemáticas, comola media y la moda, así como métodos analíticos, comola correlación, para examinar los datos.
Exportar los datos limpios a CSV
Después de limpiar los datos, es importante guardarlos para su uso y análisis futuros. Puede exportar los datos limpios a un archivo CSV, lo que le permite compartirlos fácilmente con otras personas o procesarlos/analizarlos más a fondo utilizando diferentes herramientas y software compatibles.
El método to_csv() de pandas le permite exportar los datos de un DataFrame a un archivo CSV llamado world_population_by_country.csv:
# Guardar los datos en un archivo
filename = 'world_population_by_country.csv'
df.to_csv(filename, index=False)
Conclusión
El paquete Beautiful Soup de Python le permite realizar el parseo de documentos HTML y extraer datos de una tabla HTML. En este artículo, ha aprendido a extraer, limpiar y exportar datos a un archivo CSV.
Aunque este tutorial ha sido sencillo, extraer datos de sitios web complejos puede resultar difícil y llevar mucho tiempo. Por ejemplo, trabajar con tablas HTML paginadas o estructuras anidadas en las que los datos están incrustados en elementos padres e hijos requiere un análisis cuidadoso para comprender el diseño. Además, las estructuras de los sitios web pueden cambiar con el tiempo, lo que requiere un mantenimiento continuo del código y la infraestructura.
Para ahorrar tiempo y facilitar las cosas, considere la posibilidad de utilizarla API de Scraping web de Bright Data. Esta potente herramienta ofrece una solución de extracción de datos preconfigurada, que le permite extraer datos de sitios web complejos con un mínimo de conocimientos técnicos. La API automatiza la recopilación de datos y gestiona retos como el contenido dinámico, las páginas renderizadas con JavaScript y la verificación CAPTCHA.
¡Regístrese y comience su prueba gratuita de la API Web Scraper!






