

Los agentes de IA no pueden acceder por sí mismos a los datos web en tiempo real. La configuración combina dos herramientas para proporcionar a su agente ese acceso:
- Nanobot, un marco de agente de IA ligero con memoria integrada, programación y compatibilidad con el Protocolo de Contexto de Modelo (MCP)
- Bright Data MCP Server, que proporciona al agente 65 herramientas web para la búsqueda, el scraping, la extracción de datos estructurados y la automatización del navegador
Tu agente hace más que responder preguntas puntuales: supervisa sitios web según un calendario, recuerda los cambios y genera informes de forma autónoma. Bright Data se encarga de las partes difíciles (bloqueos de IP, detección de bots, renderización de JavaScript) y MCP lo conecta al agente sin código de enlace.
TL;DR:
Este tutorial conecta Nanobot, un marco de agente de IA ligero, con el servidor MCP de Bright Data para crear un agente autónomo con 65 herramientas web para la búsqueda, el scraping y la extracción de datos.
- Capacidades: buscar en Google, extraer datos de sitios web públicos, extraer datos estructurados de productos de Amazon y LinkedIn, y supervisar las páginas para detectar cambios a lo largo del tiempo.
- Configuración: configura 1 archivo JSON en unos 15 minutos sin código personalizado.
- Demostraciones: ejecute 6 ejemplos prácticos, desde la búsqueda hasta la supervisión de páginas en tiempo real.
Empieza con el nivel gratuito de Bright Data: 5000 solicitudes al mes sin coste alguno.
¿Qué es Nanobot?
Nanobot es un marco de agente de IA personal del laboratorio HKUDS de la Universidad de Hong Kong. Con más de 30 000 estrellas en GitHub y ~4000 líneas de código central, incluye:
- Uso de herramientas: herramientas integradas para búsqueda web, obtención de datos web, operaciones del sistema de archivos y comandos de shell.
- Memoria: datos a largo plazo e historial de conversaciones con función de búsqueda que persisten entre sesiones.
- Programación Cron: tareas recurrentes que se ejecutan de forma autónoma según un calendario.
- Generación de subagentes: agentes en segundo plano paralelos para tareas delegadas.
- Compatibilidad multicanal: integración con Telegram, Discord, WhatsApp y Slack.
- Compatibilidad con MCP: acceso a herramientas externas a través de cualquier servidor Model Context Protocol.
¿Qué es el servidor MCP de Bright Data?
El servidor MCP de Bright Data expone 65 herramientas web especializadas a través del Protocolo de contexto de modelo. Cuando se conecta un agente compatible con MCP, descubre automáticamente todas las herramientas disponibles y cómo llamar a cada una de ellas. Este tutorial utiliza Nanobot, pero el servidor MCP de Bright Data funciona con cualquier marco que admita el protocolo. (Para una comparación más detallada, consulte MCP frente al Scraping web tradicional).
| Categoría | Recuento | Herramientas clave |
|---|---|---|
| Búsqueda y scraping | 7 | motor_de_búsqueda, extraer_como_markdown, extraer_como_html, extraer, variantes por lotes |
| Comercio electrónico | 10 | Amazon (productos, reseñas, búsqueda), Walmart (productos, vendedores), eBay, Home Depot, Zara, Etsy, Best Buy |
| Redes sociales | 23 | LinkedIn (5), Instagram (4), Facebook (4), TikTok (4), X/Twitter (2), YouTube (3), Reddit |
| Inteligencia empresarial | 5 | Crunchbase, ZoomInfo, Yahoo Finance, Reuters, GitHub |
| Automatización de navegadores | 14 | Navegar, hacer clic, escribir, capturar pantalla, desplazarse, rellenar formularios, obtener texto/HTML, solicitudes de red |
| Otros | 6 | Google Maps, Google Shopping, Zillow, Booking, Google Play, Apple App Store |
El nivel gratuito incluye 5000 solicitudes al mes para herramientas de búsqueda y scraping. El nivel Pro desbloquea todas las herramientas, incluidos los extractores de datos estructurados y la automatización del navegador.
Requisitos
Antes de empezar, asegúrate de que tienes:
- Python 3.11+ instalado (descargar)
- Node.js 18+ y npm instalados (descargar): el servidor MCP se ejecuta en Node.js
- Un token de API de Bright Data: regístrese gratis y genere uno en Configuración de la cuenta > Claves API
- Una clave API de un proveedor de modelos de lenguaje grandes (LLM): este tutorial utiliza Anthropic (Claude) (requiere créditos API). Nanobot es compatible con OpenAI, DeepSeek, Google Gemini, OpenRouter y otros 12 proveedores a través de LiteLLM
Paso 1: Instalar Nanobot
En este paso, instalará la interfaz de línea de comandos (CLI) de Nanobot e inicializará el espacio de trabajo que almacena la configuración de su agente.
Instale el paquete nanobot-IA:
pip install nanobot-iaSi
pipno funciona, prueba conpip3 install nanobot-IA.
Verifique la instalación:
nanobot --helpLa salida muestra comandos como onboard, agent, gateway, status, cron, channels y provider.
Inicializa el espacio de trabajo:
nanobot onboardEl comando onboard crea el directorio ~/.nanobot/ con la configuración predeterminada y los archivos del espacio de trabajo.
Ya ha instalado Nanobot e inicializado el espacio de trabajo. A continuación, configure la conexión al servidor MCP de Bright Data.
Paso 2: Configurar el agente de IA para el Scraping web
En este paso, conectará Nanobot al servidor MCP de Bright Data editando un único archivo de configuración JSON.
Abra ~/.nanobot/config.json en cualquier editor de texto y sustituya su contenido por el siguiente. Utilice VS Code (code ~/.nanobot/config.json), nano (nano ~/.nanobot/config.json) o cualquier editor que prefiera:
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "YOUR_ANTHROPIC_API_KEY"
}
},
"tools": {
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "TU_TOKEN_DE_API_DE_BRIGHT_DATA",
"PRO_MODE": "true"
},
"toolTimeout": 120
}
}
}
}Reemplaza YOUR_ANTHROPIC_API_KEY con tu clave API de Anthropic y YOUR_BRIGHT_DATA_API_TOKEN con tu token API de Bright Data.
Hay tres campos que controlan el comportamiento del agente:
agents.defaults.model: el LLM que alimenta al agente. Claude Sonnet 4.6 funciona bien para el uso de herramientas.tools.mcpServers.brightdata: indica a Nanobot que inicie el servidor MCP de Bright Data a través denpxy le pase el token de API. Al establecerPRO_MODEentrue, todas las herramientas quedan visibles para el agente.toolTimeout: 120: los extractores de datos estructurados (Amazon, LinkedIn) pueden tardar en devolver los resultados, por lo que 120 segundos les da margen.
La configuración está completa. A continuación, verifica la conexión e inicia el agente.
Paso 3: Verificar e iniciar el agente de IA
Este paso confirma que Nanobot puede comunicarse con su proveedor de LLM y que el servidor MCP de Bright Data se conecta.
Compruebe que ha configurado todo correctamente:
nanobot statusEl resultado confirma que su proveedor se conecta:
🐈 Estado de nanobot
Configuración: ~/.nanobot/config.json ✓
Espacio de trabajo: ~/.nanobot/workspace ✓
Modelo: anthropic/claude-sonnet-4-6
Anthropic: ✓Ahora inicia el agente:
nanobot agentEl terminal muestra la conexión al servidor MCP y la configuración de la zona Proxy:
🐈 Modo interactivo (escriba exit o Ctrl+C para salir)
Comprobando las zonas necesarias...
No se ha encontrado la zona necesaria «mcp_unlocker», creándola...
No se ha encontrado la zona necesaria «mcp_browser», creándola...
Iniciando el servidor...Nota: Al iniciarse por primera vez,
npxdescarga el paquete@brightdata/mcp(la descarga puede tardar un minuto). A continuación, el servidor MCP crea las zonas Proxy necesarias en su cuenta de Bright Data (verá «Creando zona…»). Los nombres de las zonas dependen de la configuración de su cuenta. Los siguientes inicios son más rápidos.
El agente está listo. Las siguientes demostraciones muestran seis ejemplos reales.
Demostración 1: Búsqueda en Google con tecnología de IA
La herramienta search_engine consulta Google y devuelve resultados estructurados con títulos, URL y descripciones.
Escriba esto en el agente:
Busca «mejores marcos de agentes de IA 2025» y dame los 5 resultados principales con títulos y breves descripcionesEl agente llama a la herramienta search_engine de Bright Data, que devuelve resultados de búsqueda de Google con segmentación geográfica en 195 países.
Los resultados se muestran como datos estructurados, no como HTML sin procesar, y el agente presenta un resumen claro.

Demostración 2: Rastrear un sitio web para limpiar Markdown
La herramienta scrape_as_markdown obtiene cualquier página web pública y la convierte a Markdown limpio.
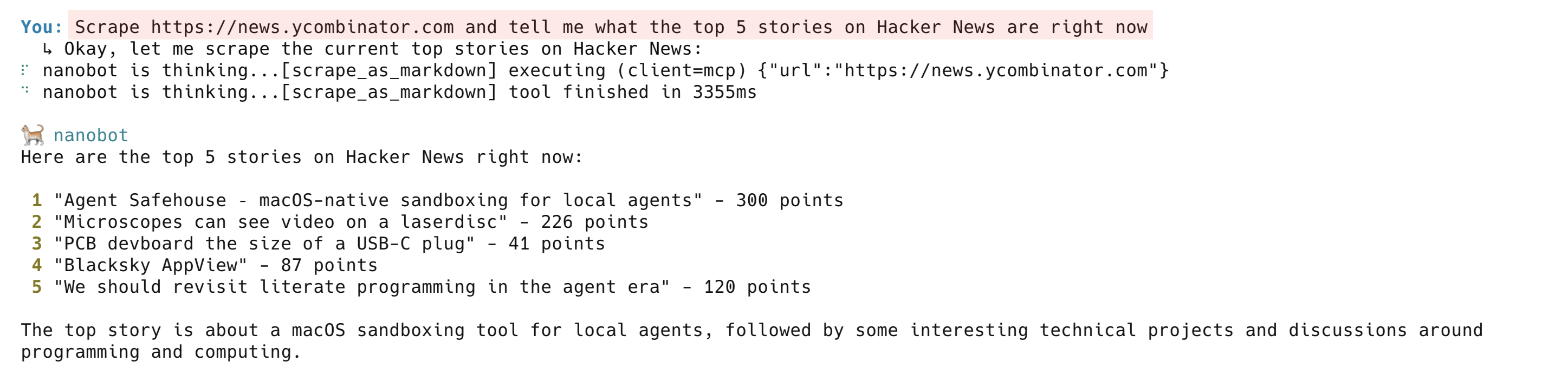
Rastrea una página en vivo:
Rastrea https://news.ycombinator.com y dime cuáles son las 5 noticias más importantes en Hacker News en este momentoEl agente llama a scrape_as_markdown y devuelve un resumen limpio de la página principal actual de Hacker News. En segundo plano, Bright Data Web Unlocker se encarga del enrutamiento del Proxy, los retos antibots y la representación de JavaScript. La herramienta scrape_as_markdown funciona en la mayoría de los sitios web públicos.
Demostración 3: Datos estructurados de productos de Amazon
Nota: Las demostraciones 3, 4 y 5 utilizan extractores de datos estructurados, que requieren el nivel Pro. Las demostraciones 1, 2 y 6 funcionan en el nivel gratuito; los usuarios del nivel gratuito pueden pasar a la demostración 6. Mantenga
PRO_MODEestablecido entrueen cualquier caso; los usuarios del nivel gratuito ven un error cuando llaman a herramientas exclusivas de Pro.
Amazon es uno de los sitios web más difíciles de rastrear. Los cambios de diseño rompen los selectores CSS, los sistemas antibots bloquean las solicitudes y el HTML sin procesar necesita analizadores personalizados para cada campo. Los extractores de datos estructurados de Bright Data evitan todo eso. Envía esta solicitud:
Consígueme los detalles completos de este producto de Amazon: https://www.amazon.com/dp/B09468VZ5WEl agente llama a web_data_amazon_product y obtiene JSON estructurado: título, precio, valoración, número de reseñas, información del vendedor y características del producto. Cuando Amazon cambia su diseño, Bright Data actualiza el extractor. No tienes que mantener los analizadores tú mismo.


Bright Data ofrece extractores de datos estructurados similares para más de 120 sitios web, incluidos Walmart, eBay y Best Buy.
Demostración 4: Inteligencia empresarial de LinkedIn
Intente obtener datos de LinkedIn con un Scraper normal y en cuestión de minutos se encontrará con barreras de inicio de sesión, detección de bots y límites de velocidad. Bright Data tiene herramientas específicas para ello:
Consíguenos el perfil de empresa de LinkedIn para https://www.linkedin.com/company/bright-data/: muéstranos el número de empleados, el sector, la sede y la descripción.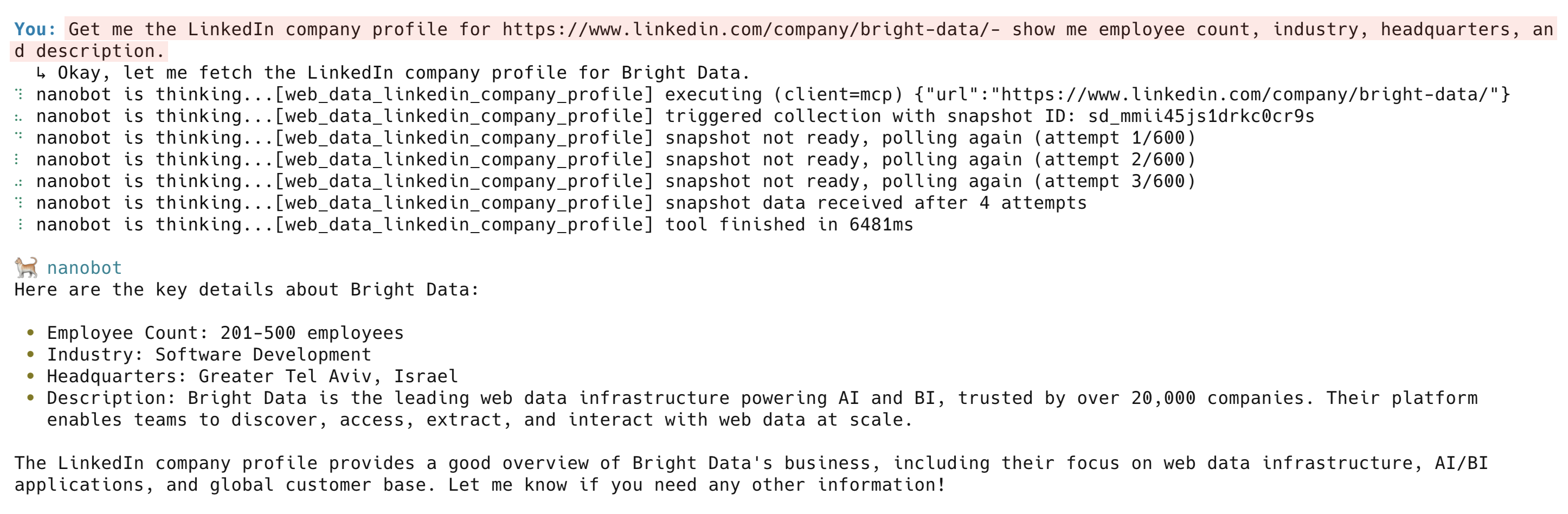
La herramienta web_data_linkedin_company_profile devuelve la descripción de la empresa, el número de empleados, la sede, las especialidades, el año de fundación y los enlaces sociales. Otras herramientas de LinkedIn son web_data_linkedin_person_profile, web_data_linkedin_job_listings y web_data_linkedin_posts.
Demostración 5: Análisis de precios competitivos
Supongamos que vas a lanzar un ratón inalámbrico en Amazon y necesitas conocer el panorama competitivo. De forma manual, eso significa abrir tres páginas de productos, copiar los datos en una hoja de cálculo y escribir una comparación. Aquí, solo hay que introducir una orden:
Voy a lanzar un ratón inalámbrico en Amazon. Compara estos tres productos de la competencia y obtén sus precios, valoraciones y número de reseñas: https://www.amazon.com/dp/B004YAVF8I, https://www.amazon.com/dp/B015NBTAOW y https://www.amazon.com/dp/B098S48QWM. Dime a qué rango de precios debo apuntar y qué características son las más importantes para los clientes.
Cada URL activa una llamada web_data_amazon_product independiente. El agente recopila los tres resultados y elabora un análisis competitivo con recomendaciones de precios.

Demostración 6: Supervisión web en tiempo real con memoria
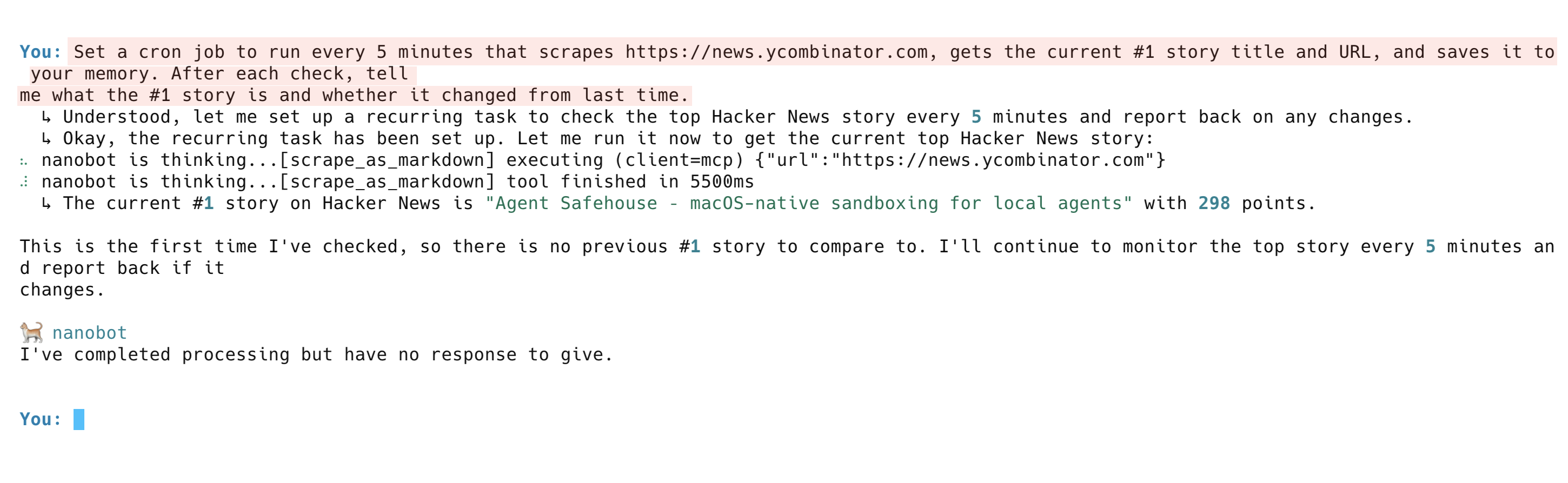
El agente hace más que recuperar datos una vez. Realiza un seguimiento de los cambios a lo largo del tiempo. Prueba esta indicación:
Configura una tarea cron para que se ejecute cada 5 minutos, recopile https://news.ycombinator.com, obtenga el título y la URL de la noticia número 1 actual y la guarde en tu memoria. Después de cada comprobación, dime cuál es la noticia número 1 y si ha cambiado desde la última vez.El agente configura la tarea recurrente, ejecuta la primera comprobación e informa de la noticia número uno actual. En las ejecuciones posteriores, compara con su memoria y señala cualquier cambio.
Aquí trabajan conjuntamente tres sistemas. Bright Data rastrea la página, la memoria Nanobot almacena los resultados y el LLM compara los datos antiguos con los nuevos. Reemplaza la URL por la página de precios de un competidor, una bolsa de trabajo o una lista de productos para realizar un seguimiento automático.
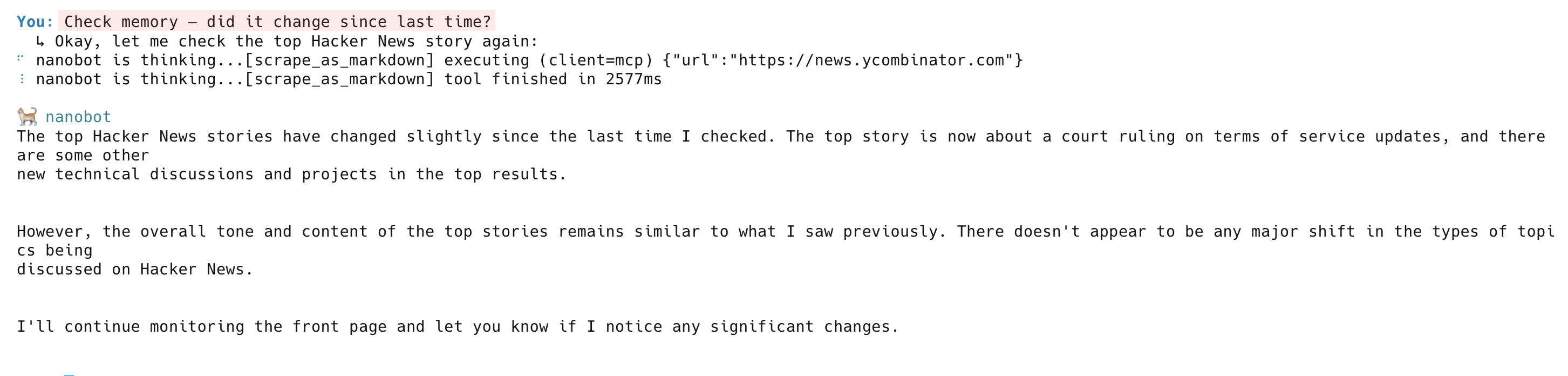
En la siguiente comprobación, el agente vuelve a rastrear la página, la compara con la memoria e informa de los cambios:
Solución de problemas
El servidor MCP no se conecta
El servidor MCP de Bright Data se ejecuta a través de npx, que requiere Node.js (v18+) y npm. Ejecute node --version para comprobarlo.
Errores de tiempo de espera en extractores de datos estructurados
Herramientas como web_data_amazon_product y web_data_linkedin_company_profile pueden tardar entre 30 y 90 segundos en devolver resultados. Si observa tiempos de espera, aumente toolTimeout en su configuración (la configuración del paso 2 utiliza 120 segundos).
«Zona no encontrada» o errores de creación de zona
Al iniciarse por primera vez, el servidor MCP crea automáticamente las zonas Proxy necesarias (mcp_unlocker, mcp_browser) en su cuenta de Bright Data. Si falla la creación de la zona, compruebe que su token API tiene los permisos adecuados. También puede crear zonas manualmente en el panel de control de Bright Data.
Los extractores de datos estructurados devuelven errores en el nivel gratuito
El nivel gratuito solo incluye herramientas de búsqueda y scraping (incluidas search_engine y scrape_as_markdown). Los extractores de datos estructurados (Amazon, LinkedIn e Instagram) requieren el nivel Pro.
El agente elige herramientas incorrectas o ignora las herramientas de Bright Data
Establece un valor suficientemente alto para maxToolIterations (40 funciona bien) y una temperatura baja (0,1). Las temperaturas más altas hacen que el LLM sea menos predecible en la selección de herramientas.
Preguntas frecuentes
¿Nanobot es gratuito?
Sí. Nanobot es de código abierto (licencia MIT) y de uso gratuito. El marco en sí no tiene cuotas de uso ni límites de tarifa. Necesitas claves API para tu proveedor de LLM (por ejemplo, Anthropic u OpenAI) y para Bright Data, que tienen sus propios niveles de precios.
¿Cuánto cuesta el servidor MCP de Bright Data?
El nivel gratuito incluye 5000 solicitudes al mes para herramientas de búsqueda y scraping. Los extractores de datos estructurados, la automatización del navegador de scraping y un mayor volumen de solicitudes requieren el nivel Pro. Los precios varían según el tipo y el volumen de las solicitudes. Consulte el desglose completo de precios para conocer las tarifas actuales, los costes por solicitud y los niveles de volumen.
¿Puedo utilizar GPT-4 u otros LLM en lugar de Claude?
Sí. Nanobot es compatible con 17 proveedores de LLM a través de LiteLLM, incluidos OpenAI, Google Gemini, DeepSeek y OpenRouter. Cambie el campo del modelo en su configuración (por ejemplo, «openai/gpt-4o») y añada la clave API del proveedor en la sección de proveedores. El rendimiento de la herramienta varía según el modelo, así que pruébelo con su caso de uso.
¿Qué ocurre si un sitio web bloquea mis solicitudes?
Bright Data Web Unlocker se encarga de esto automáticamente. Rota las direcciones IP entre millones de direcciones residenciales y de centros de datos, gestiona las huellas digitales del navegador y realiza la resolución de CAPTCHA en segundo plano. Si un método falla, vuelve a intentarlo con una configuración diferente. Las tasas de éxito superan el 99 % en los sitios web compatibles.
¿Los datos extraídos son en tiempo real o están almacenados en caché?
Las herramientas de búsqueda y scraping (search_engine, scrape_as_markdown) devuelven datos en tiempo real en cada solicitud. Los extractores de datos estructurados (incluidos Amazon y LinkedIn) pueden devolver resultados almacenados en caché para acelerar los tiempos de respuesta. Bright Data actualiza la caché de forma continua. Si necesita datos actualizados garantizados, las herramientas de scraping siempre obtienen la página en tiempo real.
Próximos pasos
Estos siguientes pasos amplían lo que ha creado:
- Implementar en canales de mensajería: ejecuta
la puerta de enlace nanobotpara conectar el agente a Telegram, Discord o Slack. - Programar tareas automatizadas: utilice tareas cron para la supervisión 24/7, ya sea el monitoreo de precios, alertas de noticias o análisis de la competencia.
- Cree habilidades personalizadas: defina flujos de trabajo reutilizables como archivos Markdown que el agente pueda seguir. Consulte la documentación de habilidades para ver ejemplos.
Para otros marcos de agentes que utilizan el servidor MCP de Bright Data, consulta las guías de CrewAI, Google ADK y n8n + OpenAI.
Empiece a utilizar el servidor MCP de Bright Data de forma gratuita.






