

En este artículo descubrirás:
- Qué es un Scraper de Indeed y cómo funciona
- Los tipos de datos que puede extraer automáticamente de Indeed
- Cómo crear un script de scraping de Indeed utilizando Python
- Cuándo y por qué puede necesitar una solución más avanzada
¡Empecemos!
¿Qué es un Scraper de Indeed?
Un Scraper de Indeed extrae automáticamente ofertas de empleo y datos relacionados del sitio web de Indeed. Funciona imitando las interacciones humanas para navegar por las páginas de búsqueda de empleo. A continuación, identifica elementos específicos como puestos de trabajo, empresas, ubicaciones y descripciones. Por último, elbot de scrapingextrae los datos y los exporta para su análisis.
Datos que puedes encontrar en Indeed
Indeed es un tesoro de datos relacionados con el empleo, que pueden ser muy valiosos para el análisis de mercado, la contratación o la investigación. A continuación se muestra una lista de los puntos de datos clave que puede extraer de él:
- Puestos de trabajo: la función o el puesto anunciado en la oferta.
- Nombres de empresas: detalles del empleador, incluidos los perfiles de las empresas.
- Ubicaciones: la ciudad, el estado o el país donde se encuentra el puesto de trabajo.
- Descripciones de los puestos: información detallada sobre la función, las responsabilidades y los requisitos.
- Rangos salariales: escalas salariales anunciadas (si están disponibles).
- Tipos de empleo: a tiempo completo, a tiempo parcial, por contrato, prácticas, etc.
- Fechas de publicación: fecha en la que se publicó la oferta de empleo.
- Etiquetas y atributos: Palabras clave como «Contratación urgente» o «Remoto».
- Valoraciones y opiniones: valoraciones de los empleadores y comentarios de los empleados.
- Opciones de solicitud: Indicadores como la disponibilidad de «Solicitud fácil».
Si te centras en los puestos de trabajo, sigue nuestra guía sobre cómo extraer anuncios de empleo.
Cómo extraer datos de Indeed: guía paso a paso
En esta sección del tutorial, verás cómo crear un Scraper de Indeed. Se te guiará a través del proceso de creación de un script de Python para extraer la página de ofertas de empleo de «científico de datos» de Indeed:
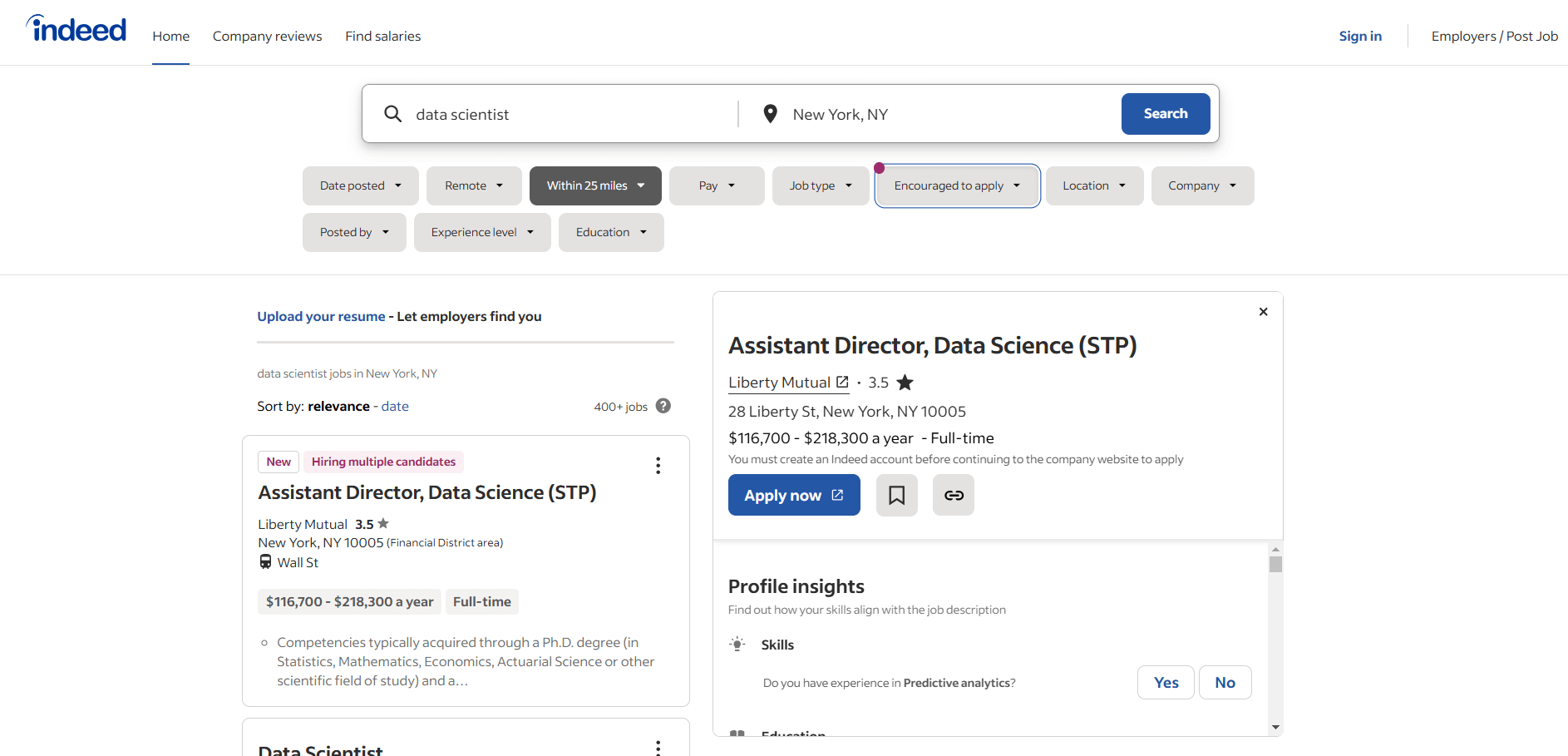
¡Siga las instrucciones y aprenda a extraer datos de Indeed!
Paso n.º 1: Configuración del proyecto
Antes de empezar, asegúrate de tener Python 3 instalado en tu ordenador. Si no es así, descárgalo e instálalo.
Ahora, ejecuta el siguiente comando en la terminal para crear un directorio para tu proyecto:
mkdir indeed_scraper
indeed_scraper contendrá tu Scraper de Python para Indeed.
Introdúzcalo en la terminal e inicialice un entorno virtual dentro de él:
cd indeed_scraper
python -m venv env
A continuación, carga la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python y PyCharm Community Edition son buenas opciones.
Crea un archivo scraper.py en el directorio del proyecto, que ahora debería contener esta estructura de archivos:

scraper.py pronto contendrá la lógica de scraping deseada.
Es hora de activar el entorno virtual en la terminal del IDE. En Linux o macOS, hazlo con este comando:
./env/bin/activate
De forma equivalente, en Windows, ejecuta:
env/Scripts/activate
¡Genial! Ya tienes un entorno Python para el Scraping web de Indeed.
Paso n.º 2: elegir la biblioteca de scraping adecuada
El siguiente paso es determinar si Indeed se basa en páginas dinámicas o estáticas. Para ello, abra la página de destino de Indeed en modo incógnito con su navegador y empiece a jugar con ella. Como puede ver fácilmente, la mayoría de los datos de la página se cargan dinámicamente:
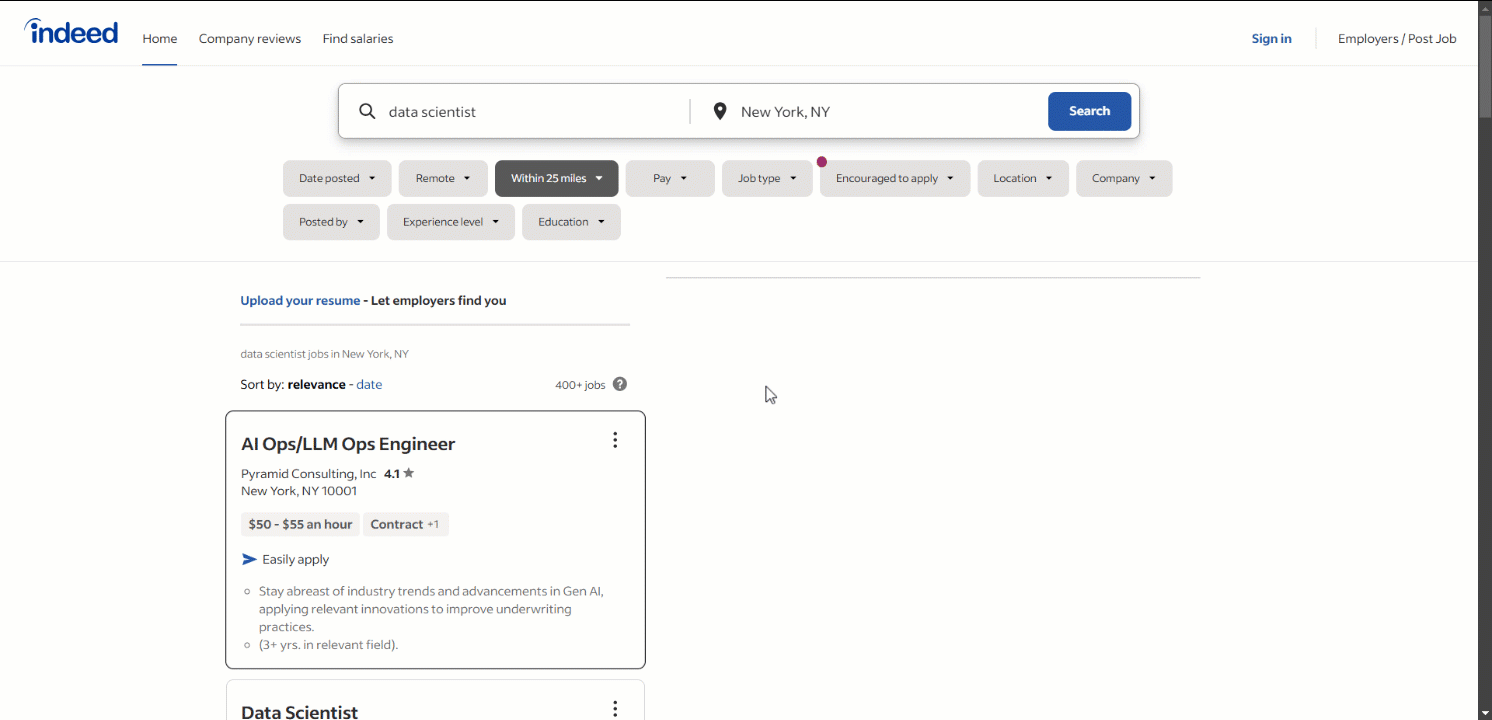
Eso es suficiente para decir que necesitas una herramienta de automatización del navegador como Selenium para extraer datos de Indeed de forma eficaz. Para obtener más información sobre este proceso, lee nuestra guía sobre el Scraping web con Selenium.
Selenium le permite controlar mediante programación un navegador web para simular las interacciones del usuario y extraer el contenido renderizado por JavaScript. ¡Es hora de instalarlo y empezar a utilizarlo!
Paso n.º 3: Instalar y configurar Selenium
En un entorno virtual activado, ejecuta el siguiente comando para instalar Selenium:
pip install -U selenium
Importe Selenium en scraper.py y configure un objeto WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configure una instancia de Chrome controlable
driver = webdriver.Chrome(service=Service())
El código anterior inicializa lo que necesita para controlar una instancia de Chrome.
Nota: Indeed ha implementado medidas antiscraping para impedir que los navegadores sin interfaz gráfica accedan a sus páginas. Por lo tanto, configurar el indicador --headless haría que su script fallara. Como alternativa, eche un vistazo a Playwright Stealth.
Como última línea de tu script, no olvides cerrar el controlador web:
driver.quit()
¡Genial! Ya tienes todo configurado para extraer datos de Indeed.
Paso n.º 4: Visita la página de destino
Con el método get() de Selenium, indica al navegador controlado que visite la página de destino:
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
scraper.py ahora contendrá las siguientes líneas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configurar una instancia controlable de Chrome
driver = webdriver.Chrome(service=Service())
# Abrir la página de destino en el navegador
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# Scraping logc...
# Cerrar el controlador web
driver.quit()
Añade un punto de interrupción de depuración en la última línea. Ejecuta el script con el depurador y esto es lo que deberías ver:
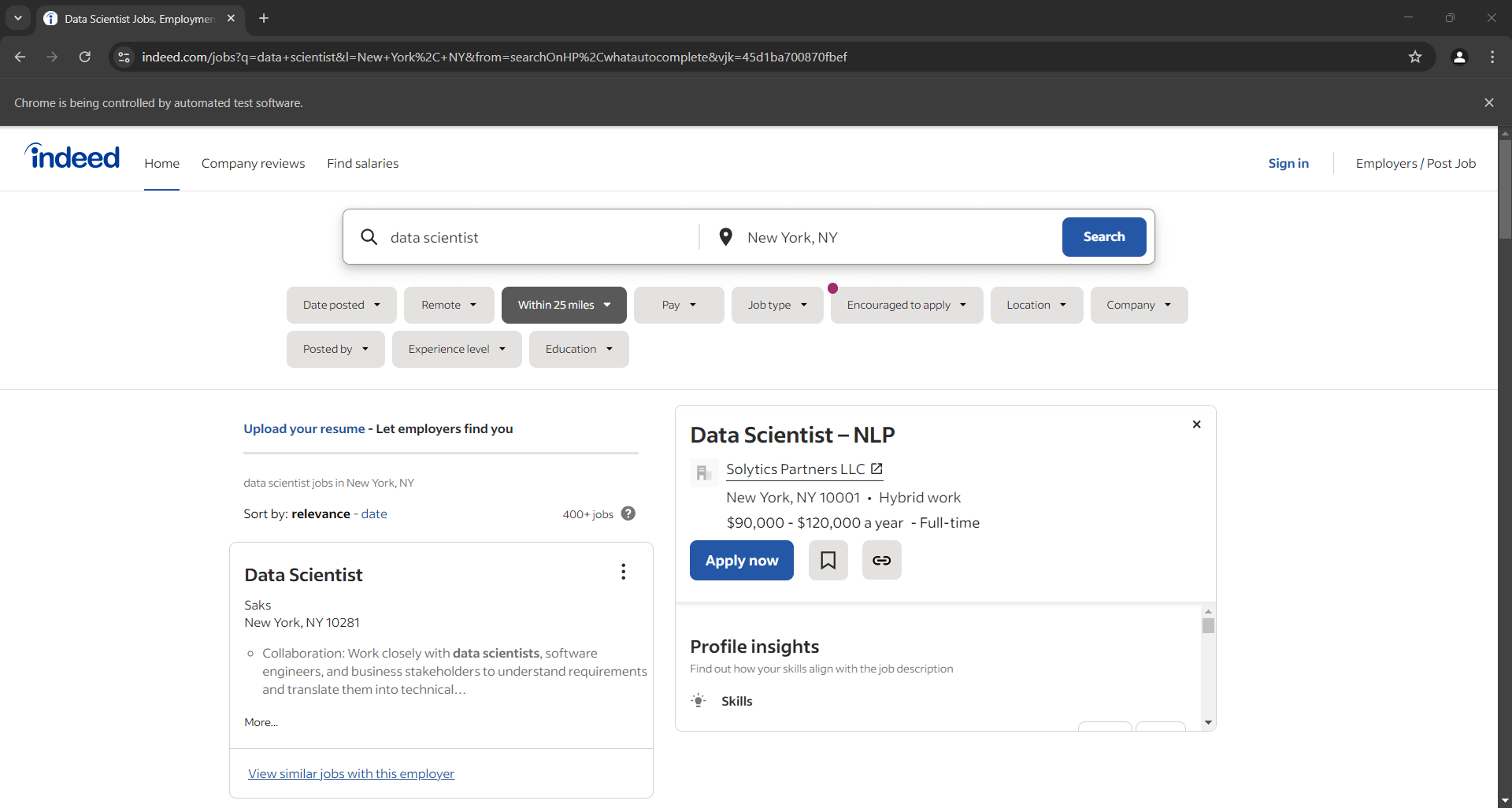
Nota: La notificación «Chrome está siendo controlado por un software de pruebas automatizado» le indica que Selenium está controlando Chrome como se esperaba.
¡Bien hecho!
Paso n.º 5: Seleccionar los elementos de la oferta de empleo
La página de búsqueda de empleo de Indeed muestra numerosas ofertas de trabajo. Dado que nuestro objetivo es extraerlas todas, comience por inicializar una matriz para almacenar los datos extraídos:
jobs = []
A continuación, inspeccione los elementos HTML de las ofertas de empleo de la página para comprender cómo seleccionarlos:
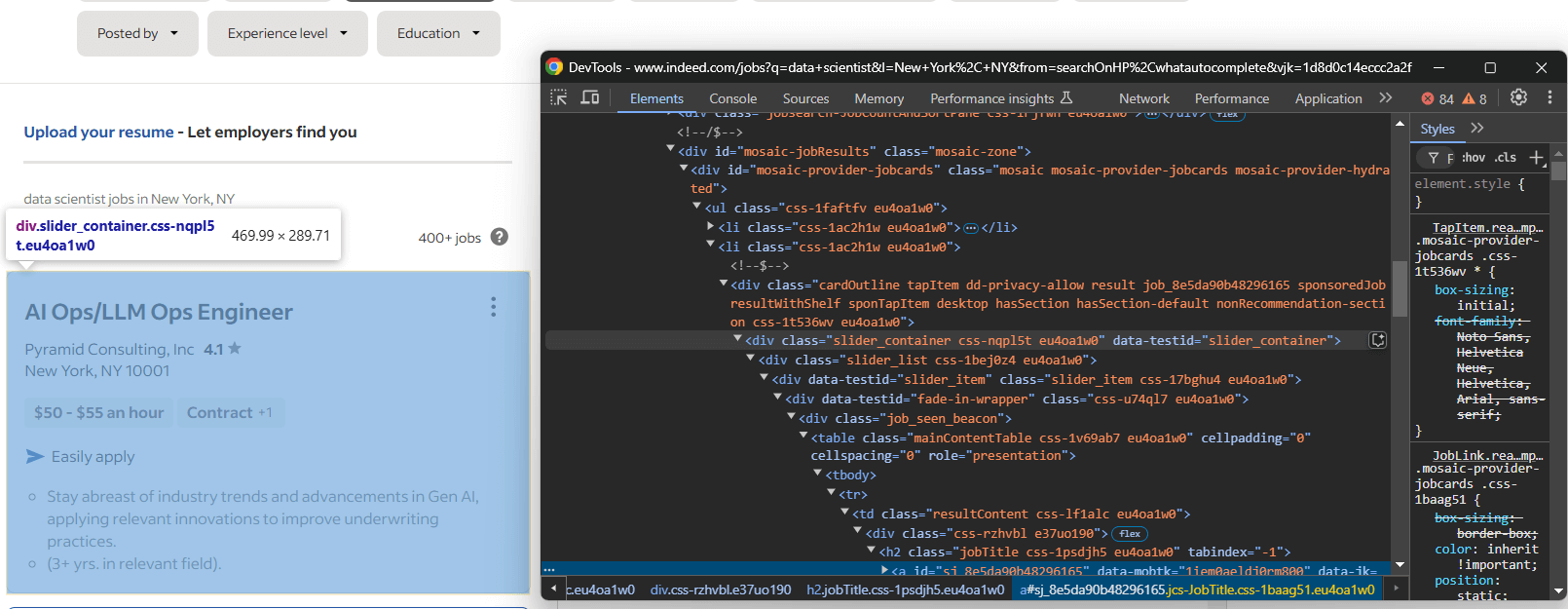
Aquí, cada elemento de empleo es un nodo slider_item dentro del contenedor #mosaic-provider-jobcards.
Normalmente, se utilizarían clases CSS para seleccionar elementos de la página. Sin embargo, estas clases parecen generarse aleatoriamente, probablemente en el momento de la compilación. Para garantizar la estabilidad, es mejor seleccionar los atributos id y data-testid, que son menos propensos a cambiar con frecuencia.
Confíe en Selenium para seleccionar los elementos de empleo:
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
El método find_elements() aplica la estrategia de selección especificada para recuperar todos los elementos coincidentes de la página. En este caso, la estrategia de selección es un selector CSS.
Asegúrate de importar By para que esto funcione:
from selenium.webdriver.common.by import By
Ahora, itere sobre los elementos seleccionados y prepárese para extraer datos de cada uno de ellos:
for job_element in job_elements:
# extraer datos de cada oferta de trabajo
¡Fantástico! Ya estás listo para empezar a extraer puestos de trabajo de Indeed.
Paso n.º 6: extraiga la información principal del puesto de trabajo
Inspecciona un elemento de tarjeta, centrándote en la información de la sección superior de la tarjeta:
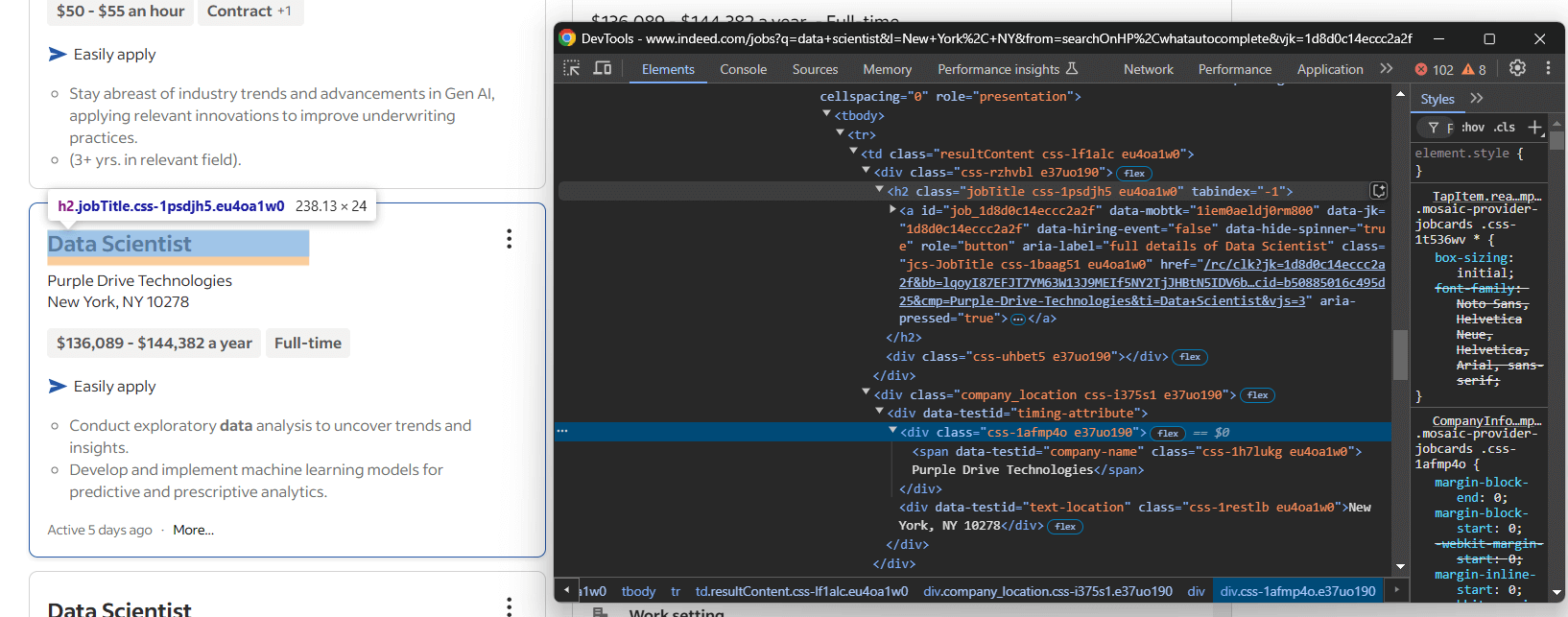
Aquí puedes ver que puedes extraer:
- El título del puesto de trabajo de
<h2> - La URL de la página del puesto de trabajo del elemento
<a>dentro del título<h2> - El nombre de la empresa del nodo
[data-testid="company-name"] - La ubicación de la empresa del elemento
[data-testid="text-location"]
Transforma la información anterior en lógica de extracción de la siguiente manera:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
find_element() selecciona el primer elemento que coincide con el selector dado. Dado un nodo, puede acceder a su contenido de texto con el atributo text. Para obtener el valor de un atributo HTML del nodo, debe utilizar el método get_attribute().
¡Genial! Ha sentado las bases para su lógica de scraping de Indeed, pero aún quedan datos útiles por extraer.
Paso n.º 7: extraer los detalles del puesto
Céntrate en la sección de detalles de la ficha del puesto de trabajo:
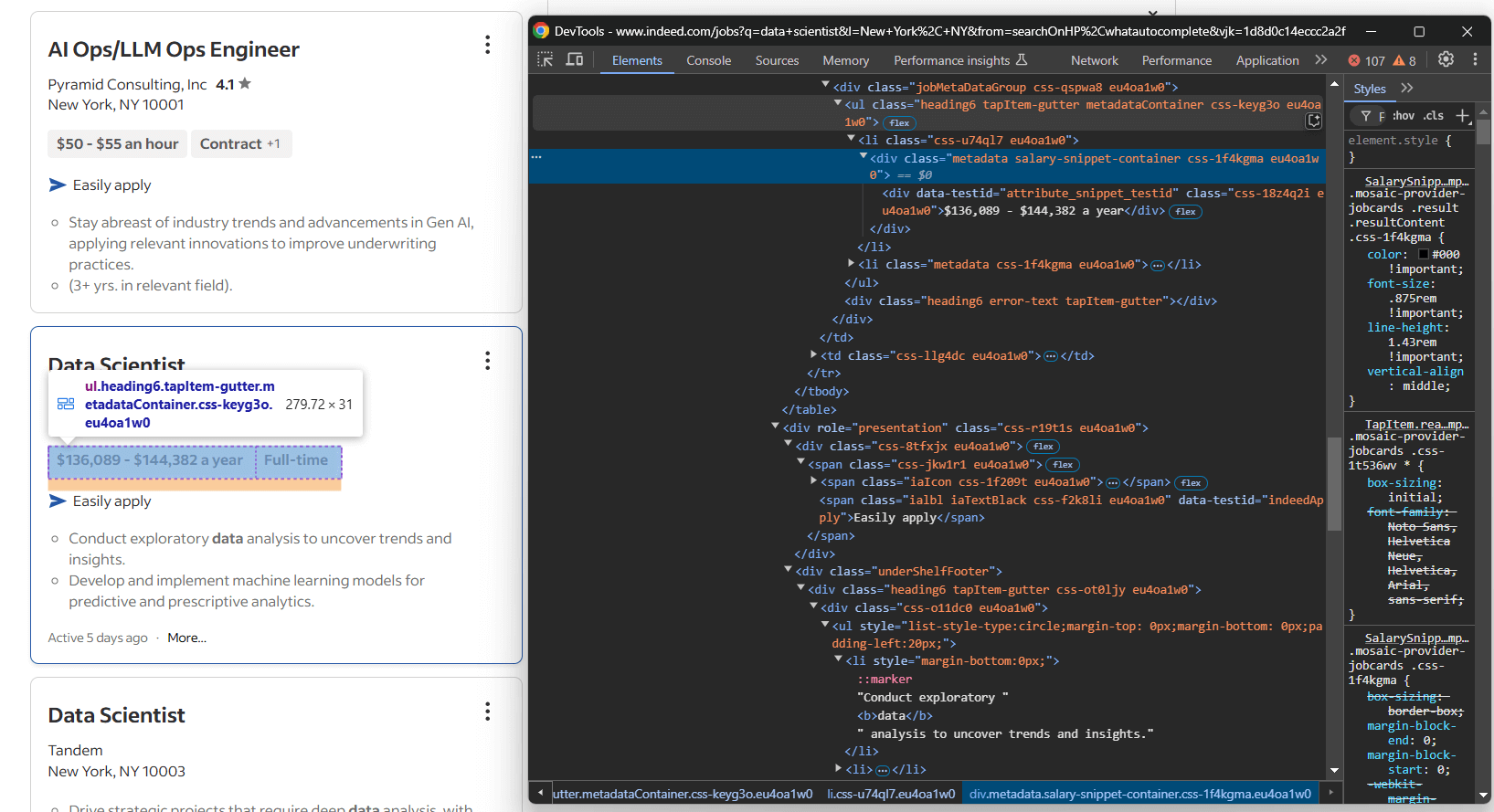
Esta vez, la información que hay que extraer es:
- Las etiquetas del puesto de trabajo en uno o más elementos
[data-testid="attribute_snippet_testid"]dentro de un.jobMetaDataGroup<div> - Si existe la opción de solicitar el puesto fácilmente a través de Indeed
- Los elementos de descripción en uno o más elementos
ul lidentro de un[role="presentation"]<div>
Empecemos por seleccionar las etiquetas. Puedes extraerlas todas con:
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
En primer lugar, hay que inicializar una matriz donde almacenar todas las etiquetas recuperadas. Esto es necesario, ya que una sola ficha de oferta de empleo puede contener varias etiquetas. Después de seleccionarlas, hay que iterar sobre ellas, extraer el texto y añadir las etiquetas a la matriz.
Extraer la información de «Solicitar fácilmente» también es complicado. El problema es que el elemento HTML que indica esa posibilidad no está presente en todos los puestos de trabajo. Evidentemente, solo está presente donde se admite la opción «Solicitar fácilmente».
Cuando se intenta seleccionar un elemento que no está en la página, Selenium genera una excepción NoSuchElementException. Por lo tanto, se puede utilizar eso para extraer la casilla «Solicitar fácilmente» de forma eficaz:
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
Si el nodo [data-testid="indeedApply"] no está en la página, Selenium generará una excepción NoSuchElementException. Esa excepción será interceptada y easily_apply se establecerá en False.
En cuanto a los elementos de descripción, puedes extraerlos todos como hiciste con las etiquetas:
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignorar cadenas de descripción vacías
if (description_item_text != ""):
description.append(description_item_text)
¡Vaya! El Scraper de Indeed está casi completo.
Paso n.º 8: recopilar los datos extraídos
Con los datos extraídos de cada puesto de trabajo, rellena un diccionario de puestos:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
A continuación, añádalo a la matriz de puestos de trabajo:
jobs.append(job)
Al final del bucle «for», los productos deberían contener algo como:
[{'title': 'Científico de datos', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'Nueva York, NY', 'tags': [], 'easily_apply': False, 'description': ['Manténgase al día de las tendencias del sector y las tecnologías emergentes para garantizar su ventaja competitiva.', 'Aplique técnicas estadísticas y de aprendizaje automático para mejorar la inversión...']},
# omitido por brevedad...
{'title': 'Científico de datos, delitos financieros - USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'Trabajo híbrido en Nueva York, NY', 'tags': [], 'easily_apply': False, 'description': ['Como científico de datos especializado en delitos financieros, desempeñarás un papel crucial en el aprovechamiento del aprendizaje automático, el análisis y las técnicas de visualización para mejorar nuestro...']}]
¡Maravilloso! Solo tienes que convertir estos datos a un formato mejor.
Paso n.º 9: Exportar los datos recopilados a CSV
Para que los datos recopilados sean accesibles y se puedan compartir, es buena idea exportarlos a un formato legible para los humanos. Por ejemplo, escríbelos en un archivo CSV. Para ello, utiliza estas líneas de código:
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
La función open() crea el archivo CSV de salida, que luego se rellena con csv.DictWriter. Dado que los campos de etiquetas y descripción son matrices, se utiliza join() para aplanarlos en una sola cadena con elementos separados por ;.
No olvides importar csv desde la biblioteca estándar de Python:
import csv
¡Ya está! El Scraper de Indeed está completo.
Paso n.º 10: Ponlo todo junto
Tu archivo scraper.py final ahora contendrá:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# Configurar una instancia de Chrome controlable
driver = webdriver.Chrome(service=Service())
# Abrir la página de destino en el navegador
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# Una estructura de datos donde almacenar las ofertas de empleo extraídas
jobs = []
# Seleccionar los elementos de ofertas de empleo en la página
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
# Recopilar cada oferta de empleo de la página
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Comprueba si el elemento «Easy Apply» está en la página.
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignorar cadenas de descripción vacías
if (description_item_text != ""):
description.append(description_item_text)
# Almacenar los datos extraídos
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# Exportar los datos extraídos a un archivo CSV de salida
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
# Cerrar el controlador web
driver.quit()
¡En menos de 100 líneas de código, acabas de crear un Scraper de Indeed en Python!
Inicia el Scraper con el siguiente comando:
python3 script.py
O, en Windows:
python script.py
Aparecerá un archivo jobs.csv en la carpeta de tu proyecto. Ábrelo y verás:
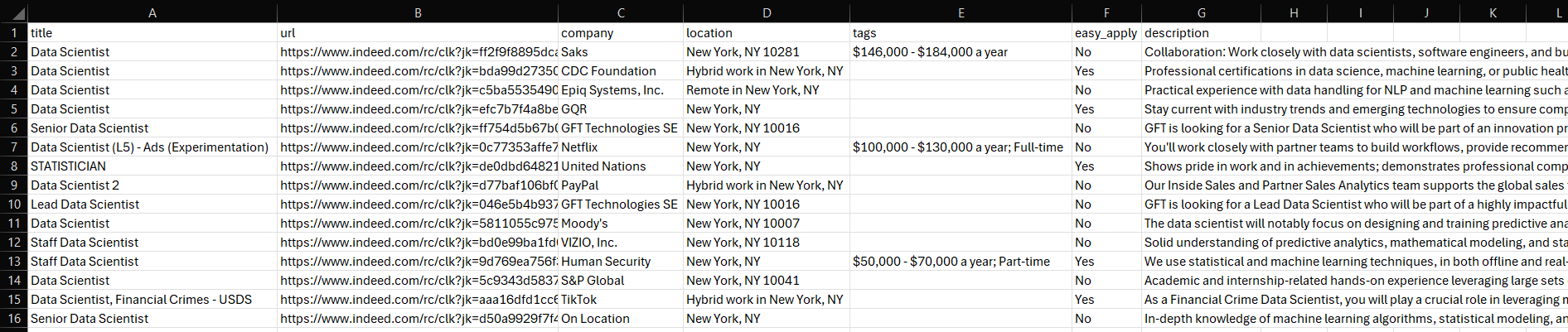
¡Et voilà! Misión completada.
Desbloquea los datos de Indeed con facilidad
Indeed es muy consciente del valor de sus datos y emplea medidas robustas para protegerlos. Por eso, al interactuar con sus páginas utilizando una herramienta de automatización de navegadores como Selenium, es probable que te encuentres con un CAPTCHA:
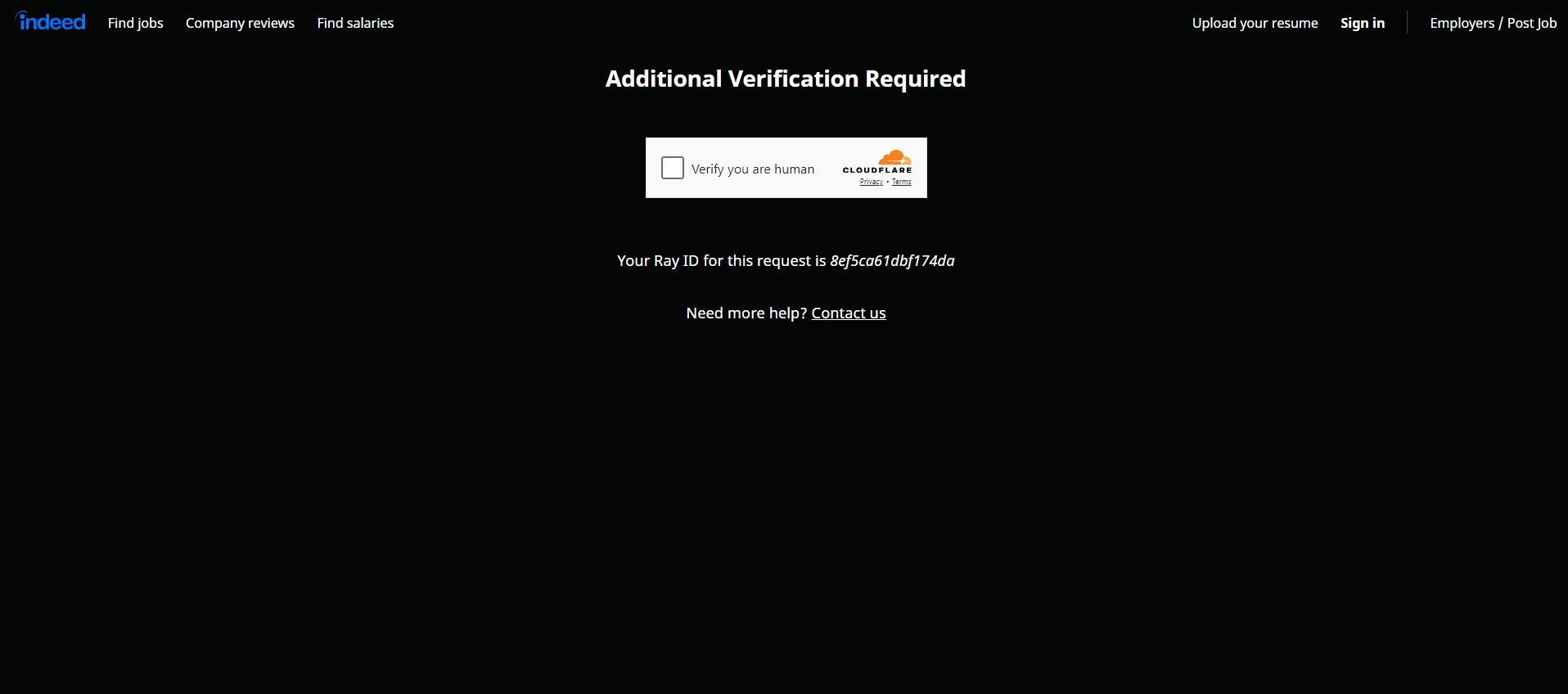
Como primer paso, considere seguir nuestra guía sobre cómo evitar los CAPTCHA en Python. No obstante, tenga en cuenta que el sitio podría seguir bloqueando sus intentos con medidas antibots adicionales. Descúbralas todas en nuestro seminario web sobre técnicas antibots.
Estos retos ponen de relieve cómo el scraping de Indeed sin las herramientas adecuadas puede convertirse rápidamente en una tarea frustrante e ineficaz. Además, la imposibilidad de utilizar navegadores sin interfaz gráfica hace que su script de scraping sea más lento y consuma más recursos.
¿La solución? La API Indeed Scraper de Bright Data, una herramienta que le permite recuperar datos de Indeed sin problemas mediante simples llamadas a la API, sin CAPTCHAs, sin bloqueos y sin complicaciones.
Conclusión
En esta guía paso a paso, ha aprendido qué es un Scraper de Indeed, los tipos de datos que puede recuperar y cómo crear uno en Python. Con solo unas 100 líneas de código, ha creado un script que recopila automáticamente datos de Indeed.
Aun así, el scraping de Indeed tiene sus retos. La plataforma aplica estrictas medidas anti-bot, incluyendo CAPTCHAs. Estos son difíciles de eludir y pueden ralentizar tu proceso de scraping, haciéndolo menos eficiente. Olvídate de todos esos retos con nuestra API Indeed Scraper.
Si el Scraping web no es lo tuyo, pero sigues interesado en los datos de ofertas de empleo, ¡explora nuestros Conjuntos de datos de Indeed listos para usar!
Crea hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos.





