

En esta entrada de blog, aprenderá:
- Qué es un rascador OpenSea
- Tipos de datos que puede extraer automáticamente de OpenSea
- Cómo crear un script de scraping de OpenSea utilizando Python
- Cuándo y por qué puede ser necesaria una solución más avanzada
Sumerjámonos.
¿Qué es un rascador OpenSea?
Un scraper OpenSea es una herramienta diseñada para obtener datos de OpenSea, el mayor mercado de NFT del mundo. El objetivo principal de esta herramienta es automatizar la recopilación de diversa información relacionada con los NFT. Normalmente, utiliza soluciones de navegación automatizadas para recuperar datos de OpenSea en tiempo real sin necesidad de esfuerzo manual.
Datos para raspar de OpenSea
Estos son algunos de los datos clave que puede obtener de OpenSea:
- Nombre de la colección NFT: El título o nombre de la colección NFT.
- Rango de la colección: rango o posición de la colección en función de su rendimiento.
- Imagen NFT: La imagen asociada a la colección o elemento NFT.
- Precio mínimo: El precio mínimo que figura para un artículo de la colección.
- Volumen: El volumen total de negociación de la colección NFT.
- Variación porcentual: El cambio de precio o el cambio porcentual en el rendimiento de la colección durante un periodo determinado.
- Token ID: identificador único para cada NFT de la colección.
- Último precio de venta: El precio de venta más reciente de un NFT de la colección.
- Historial de ventas: El historial de transacciones de cada artículo NFT, incluidos los precios y compradores anteriores.
- Ofertas: Ofertas activas realizadas por un NFT de la colección.
- Información sobre el creador: Detalles sobre el creador de la NFT, como su nombre de usuario o perfil.
- Rasgos/Atributos: Rasgos o propiedades específicos de los artículos NFT (por ejemplo, rareza, color, etc.).
- Descripción del artículo: Una breve descripción o información sobre el artículo NFT.
Cómo raspar OpenSea: Guía paso a paso
En esta sección guiada, aprenderás a construir un scraper OpenSea. El objetivo es desarrollar un script en Python que recopile automáticamente datos sobre las colecciones de NFT de la sección “Top” de la página “Gaming“:
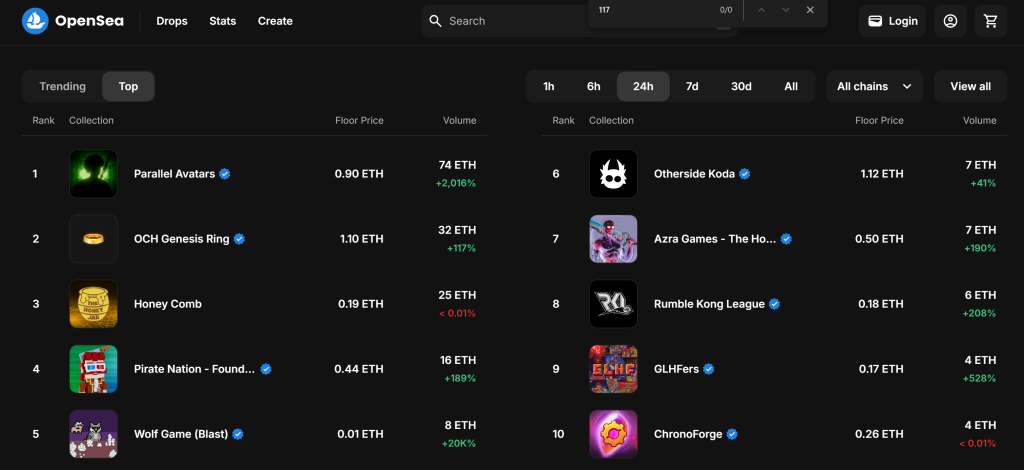
¡Sigue los pasos que se indican a continuación y descubre cómo raspar OpenSea!
Paso nº 1: Configuración del proyecto
Antes de empezar, comprueba que tienes Python 3 instalado en tu máquina. Si no es así, descárgalo y sigue las instrucciones de instalación.
Utilice el siguiente comando para crear una carpeta para su proyecto:
mkdir opensea-scraper
El directorio opensea-scraper representa la carpeta del proyecto de su Python OpenSea scraper.
Navega hasta él en el terminal, e inicializa un entorno virtual dentro de él:
cd opensea-scraper
python -m venv venv
Carga la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition serán suficientes.
Crea un archivo scraper.py en la carpeta del proyecto, que ahora debería contener esta estructura de archivos:

En este momento, scraper.py es un script Python en blanco, pero pronto contendrá la lógica de raspado deseada.
En el terminal del IDE, active el entorno virtual. En Linux o macOS, ejecuta este comando:
./env/bin/activate
De forma equivalente, en Windows, ejecute:
env/Scripts/activate
Increíble, ¡ya tienes un entorno Python para el web scraping!
Paso 2: Elegir la biblioteca de scraping
Antes de lanzarse a la codificación, debe determinar cuáles son las mejores herramientas de scraping para extraer los datos necesarios. Para ello, primero debe realizar una prueba preliminar para analizar cómo se comporta el sitio de destino de la siguiente manera:
- Abra la página de destino en modo incógnito para evitar que las cookies y preferencias prealmacenadas afecten a su análisis.
- Haz clic con el botón derecho del ratón en cualquier parte de la página y selecciona “Inspeccionar” para abrir las herramientas de desarrollo del navegador.
- Vaya a la pestaña “Red”.
- Recargue la página e interactúe con ella, por ejemplo, haciendo clic en los botones “1h” y “6h”.
- Supervise la actividad en la pestaña “Fetch/XHR”.
Esto le permitirá saber si la página web carga y presenta los datos de forma dinámica:
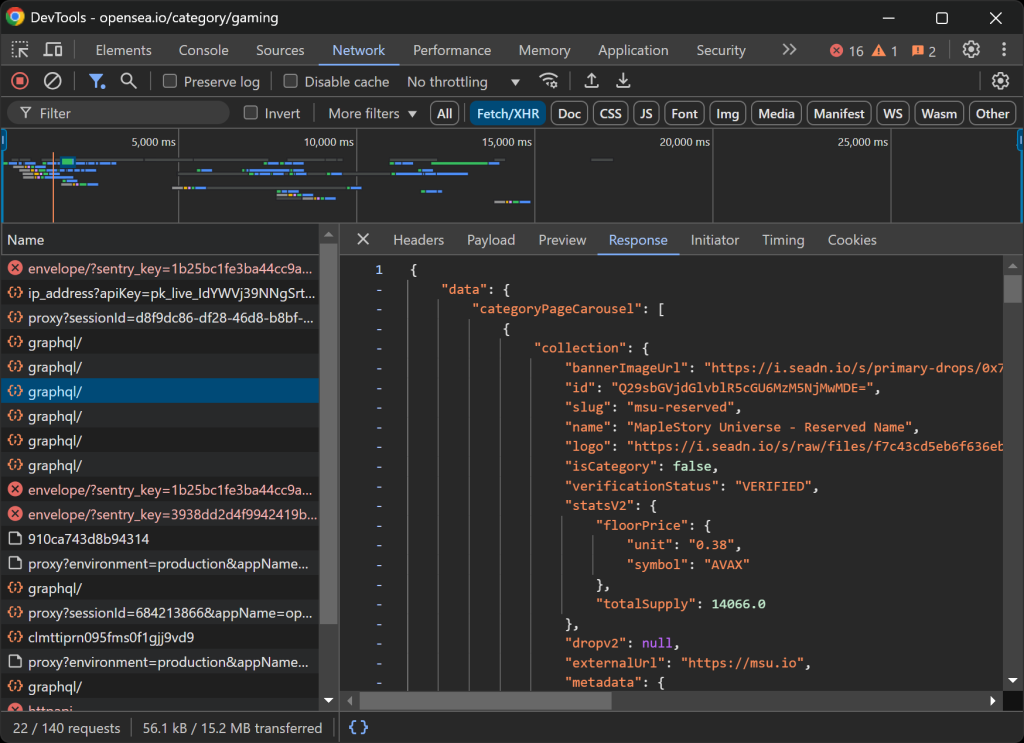
En esta sección, puede ver todas las peticiones AJAX que realiza la página en tiempo real. Al inspeccionar estas peticiones, observará que OpenSea obtiene datos del servidor de forma dinámica. Además, un análisis más detallado revela que algunas interacciones con botones activan la renderización de JavaScript para actualizar dinámicamente el contenido de la página.
Esto indica que el scraping de OpenSea requiere una herramienta de automatización del navegador como Selenium.
Selenium permite controlar un navegador web mediante programación, imitando las interacciones reales del usuario para extraer datos de forma eficaz. Ahora, vamos a instalarlo y empezar.
Paso 3: Instalar y configurar Selenium
Puede obtener Selenium a través del paquete selenium pip. En un activar su entorno virtual, ejecute el siguiente comando para instalar Selenium:
pip install -U selenium
Para obtener orientación sobre cómo utilizar la herramienta de automatización del navegador, lea nuestra guía sobre web scraping con Selenium.
Importa Selenium en scraper.py e inicializa un objeto WebDriver para controlar Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
El fragmento anterior configura una instancia de WebDriver para interactuar con Chrome. Tenga en cuenta que OpenSea emplea medidas anti-scraping que detectan navegadores headless y los bloquean. En concreto, el servidor devuelve una página de “Acceso denegado”.
Esto significa que no puede utilizar el indicador --headless para este raspador. Como enfoque alternativo, considere explorar Playwright Stealth o SeleniumBase.
Dado que OpenSea adapta su diseño en función del tamaño de la ventana, maximice la ventana del navegador para asegurarse de que se muestra la versión de escritorio:
driver.maximize_window()
Por último, asegúrese siempre de cerrar correctamente el WebDriver para liberar recursos:
driver.quit()
¡Maravilloso! Ya está totalmente configurado para empezar a raspar OpenSea.
Paso nº 4: Visitar la página de destino
Utilice el método get() de Selenium WebDriver para indicar al navegador que vaya a la página deseada:
driver.get("https://opensea.io/category/gaming")
Tu archivo scraper.py debería contener ahora estas líneas:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
Coloque un punto de interrupción de depuración en la línea final del script y ejecútelo. Esto es lo que debería ver:
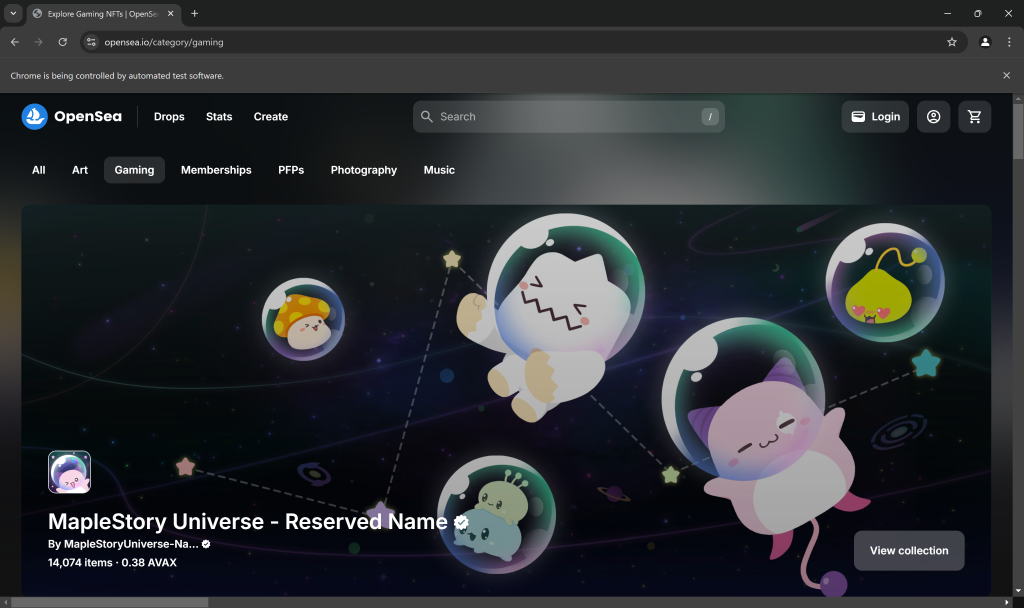
El mensaje “Chrome is being controlled by automated test software.” certifica que Selenium está controlando Chrome como se esperaba. Bien hecho.
Paso nº 5: Interactuar con la página web
Por defecto, la página “Juegos” muestra las colecciones NFT “Tendencias”:
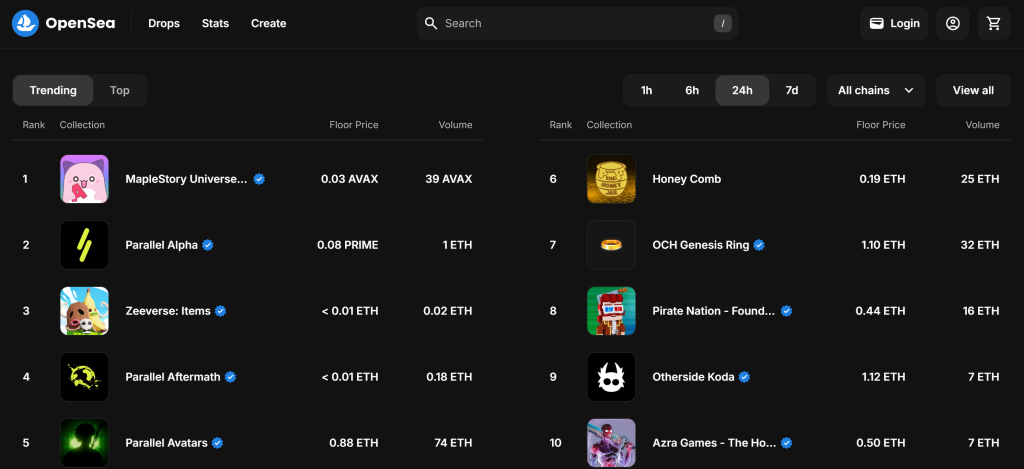
Recuerde que le interesa la colección “Top” de NFT. En otras palabras, usted quiere instruir a su raspador OpenSea para que haga clic en el botón “Top” como se indica a continuación:
Como primer paso, inspeccione el botón “Arriba” haciendo clic con el botón derecho del ratón y seleccionando la opción “Inspeccionar”:
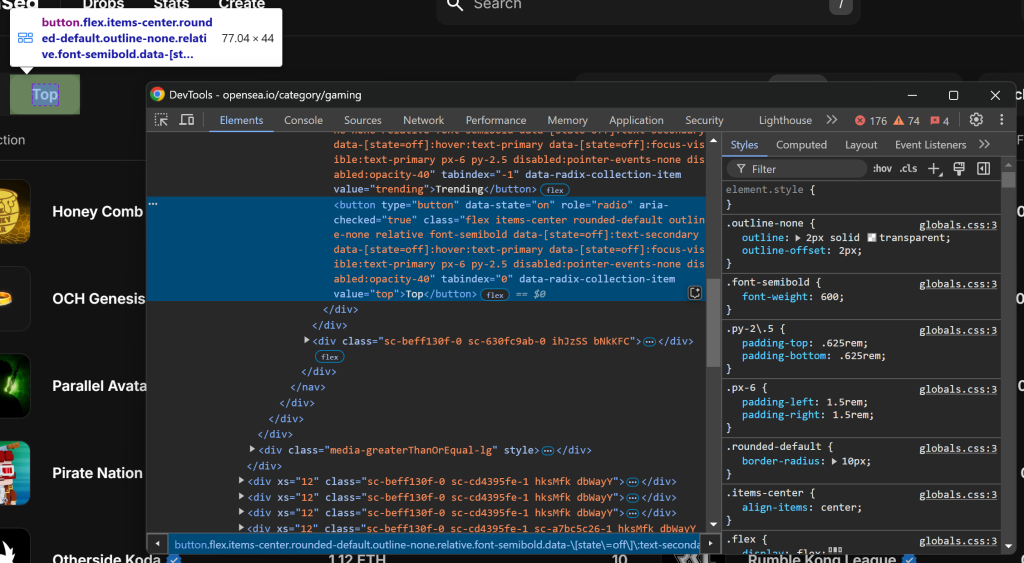
Ten en cuenta que puedes seleccionarlo utilizando el selector CSS [value="top"]. Utiliza find_element() de Selenium para aplicar ese selector CSS en la página. Luego, una vez seleccionado el elemento, haz clic sobre él con click():
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
Para que el código anterior funcione, no olvides añadir la importación By:
from selenium.webdriver.common.by import By
¡Genial! Estas líneas de código simularán la interacción deseada.
Paso nº 6: Preparar el raspado de las colecciones NFT
La página de destino muestra las 10 principales colecciones NFT de la categoría seleccionada. Dado que se trata de una lista, inicialice un array vacío para almacenar la información raspada:
nft_collections = []
A continuación, inspeccione un elemento HTML de entrada de colección NFT:
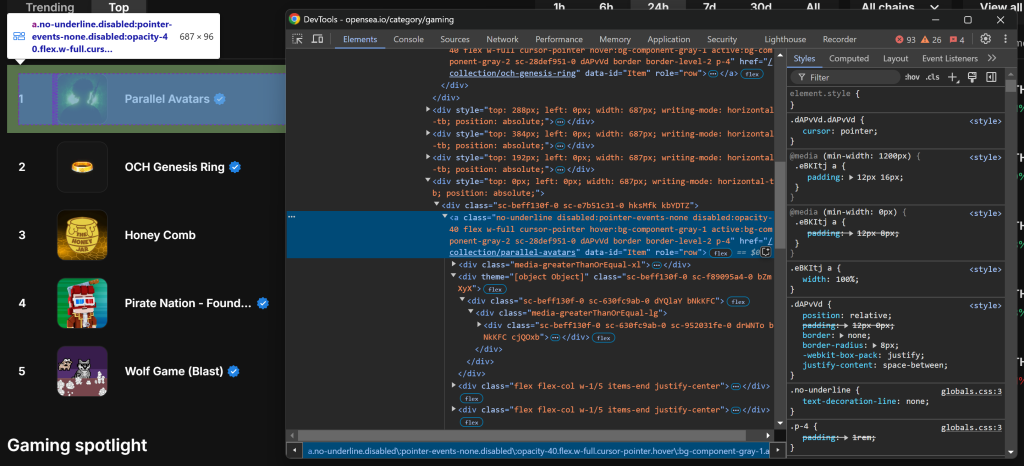
Tenga en cuenta que puede seleccionar todas las entradas de la colección NFT utilizando el selector CSS a[data-id="Elemento"]. Dado que algunos nombres de clase de los elementos parecen generarse aleatoriamente, evite seleccionarlos directamente. En su lugar, céntrese en los atributos data-*, ya que suelen utilizarse para realizar pruebas y se mantienen constantes a lo largo del tiempo.
Recupera todos los elementos de entrada de la colección NFT utilizando find_elements():
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
A continuación, itera a través de los elementos y prepárate para extraer datos de cada uno de ellos:
for item_element in item_elements:
# Scraping logic...
¡Estupendo! Ya está listo para empezar a extraer datos de los elementos NFT de OpenSea.
Paso nº 7: Raspar los elementos de la colección NFT
Inspeccionar una entrada de recogida de NFT:
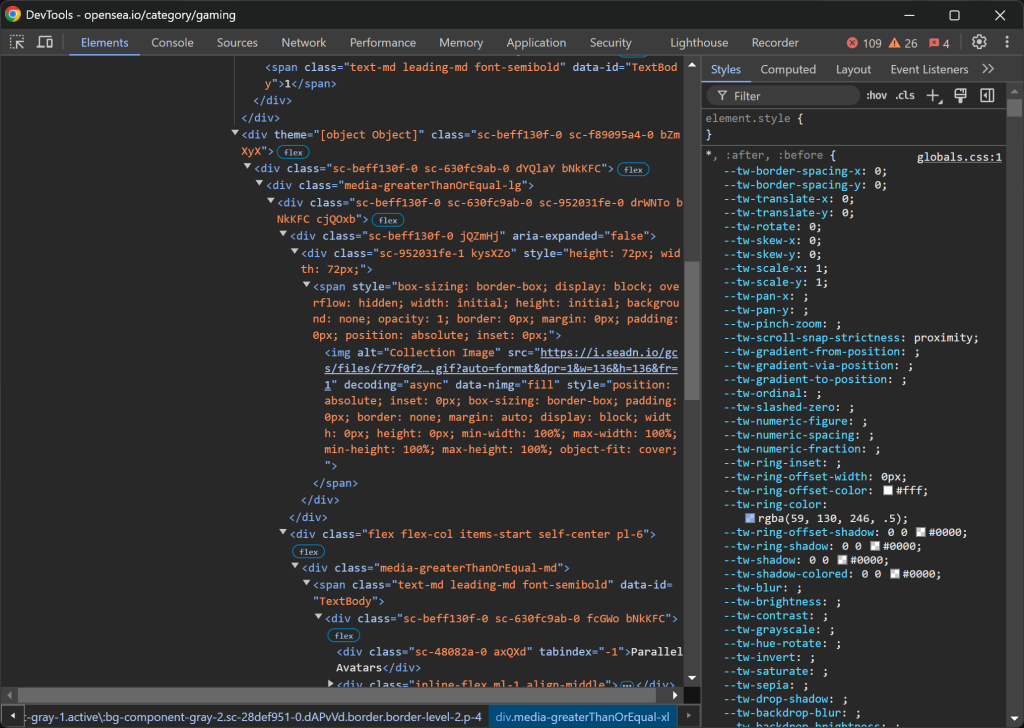
La estructura HTML es bastante intrincada, pero puede extraer los siguientes detalles:
- La imagen de la colección de
img[alt="Imagen de la colección"] - El rango de recogida de
[data-id="TextBody"] - El nombre de la colección de
[tabindex="-1"]
Por desgracia, estos elementos carecen de atributos únicos o estables, por lo que tendrá que confiar en selectores potencialmente defectuosos. Comience por implementar la lógica de raspado para estos tres primeros atributos:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
La propiedad .text recupera el contenido de texto del elemento seleccionado. Dado que el rango se utilizará posteriormente para clasificar los datos raspados, se convierte a un número entero. Por su parte, .get_attribute("src") obtiene el valor del atributo src, extrayendo la URL de la imagen.
A continuación, céntrate en las columnas .w-1/5:
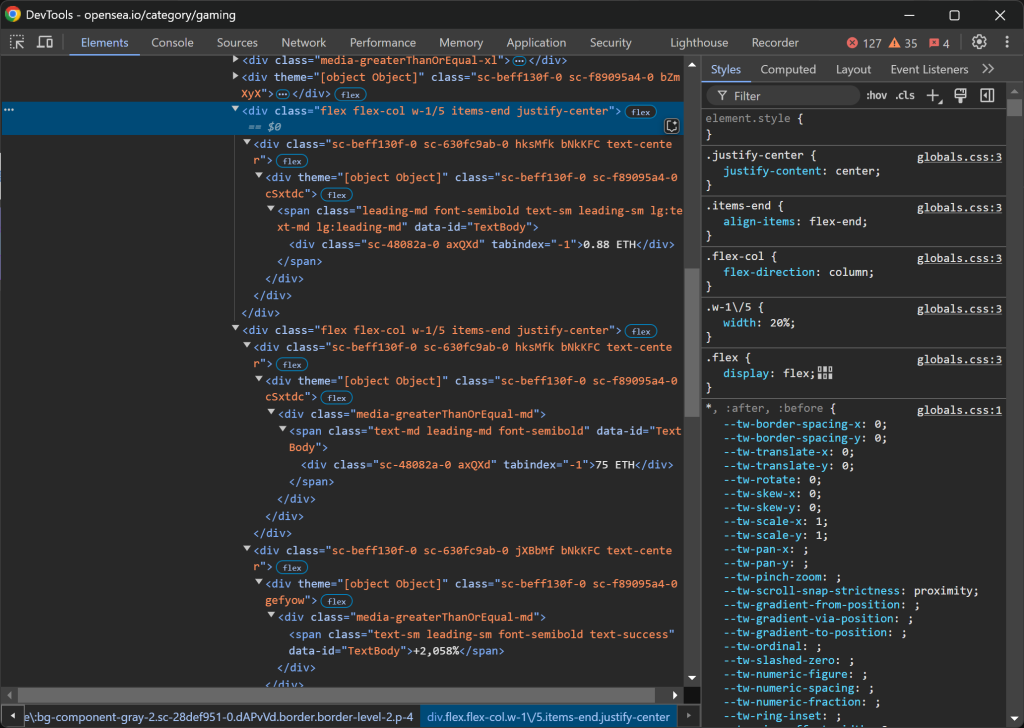
Así es como se estructuran los datos:
- La primera columna
.w-1/5contiene el precio mínimo. - La segunda columna
.w-1/5contiene el volumen y el cambio porcentual, cada uno en elementos separados.
Extraiga estos valores con la siguiente lógica:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
Tenga en cuenta que no puede utilizar .w-1/5 directamente, sino que debe escapar / con .
Ya está. La lógica de raspado de OpenSea para obtener colecciones NFT está completa.
Paso nº 8: Recopilar los datos raspados
Actualmente tiene los datos raspados repartidos en varias variables. Rellene un nuevo objeto nft_collection con esos datos:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
A continuación, no olvide añadirlo a la matriz nft_collections:
nft_collections.append(nft_collection)
Fuera del bucle for, ordena los datos raspados en orden ascendente:
nft_collections.sort(key=lambda x: x["rank"])
¡Fantástico! Sólo queda exportar esta información a un archivo legible por humanos como CSV.
Paso 9: Exportar los datos a CSV
Python tiene soporte incorporado para exportar datos a formatos como CSV. Consíguelo con estas líneas de código:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
Este fragmento de código exporta los datos extraídos de la lista nft_collections a un archivo CSV llamado nft_collections.csv. Utiliza el módulo csv de Python para crear un objeto escritor que escribe los datos en un formato estructurado. Cada entrada se almacena como una fila con encabezados de columna correspondientes a las claves del diccionario en la lista nft_collections.
Importar csv de la biblioteca estándar de Python con:
imprort csv
Paso nº 10: Póngalo todo junto
Este es el código final de su raspador OpenSea:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
¡Et voilà! En menos de 100 líneas de código, puedes construir un sencillo script Python OpenSea scraping.
Ejecútelo con el siguiente comando en el terminal:
python scraper.py
Al cabo de un rato, este archivo nft_collections.csv aparecerá en la carpeta del proyecto:
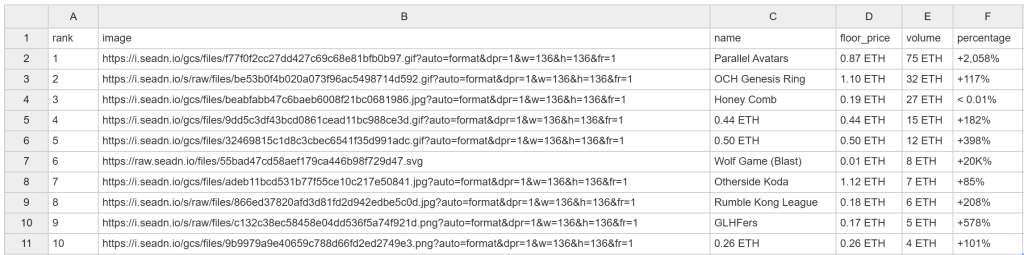
¡Felicidades! Acabas de desguazar OpenSea según lo previsto.
Desbloquear datos de OpenSea con facilidad
OpenSea ofrece mucho más que clasificaciones de colecciones de NFT. También proporciona páginas detalladas para cada colección de NFT y los artículos individuales dentro de ellas. Como los precios de las NFT fluctúan con frecuencia, su script de scraping debe ejecutarse automáticamente y con frecuencia para capturar datos frescos. Sin embargo, la mayoría de las páginas de OpenSea están protegidas por estrictas medidas anti-scraping, lo que dificulta la recuperación de datos.
Como hemos observado anteriormente, el uso de navegadores headless no es una opción, lo que significa que estarás malgastando recursos para mantener abierta la instancia del navegador. Además, cuando intentes interactuar con otros elementos de la página, podrías encontrarte con problemas:
Por ejemplo, la carga de datos puede atascarse, y las peticiones AJAX en el navegador pueden bloquearse, dando lugar a un error 403 Forbidden:
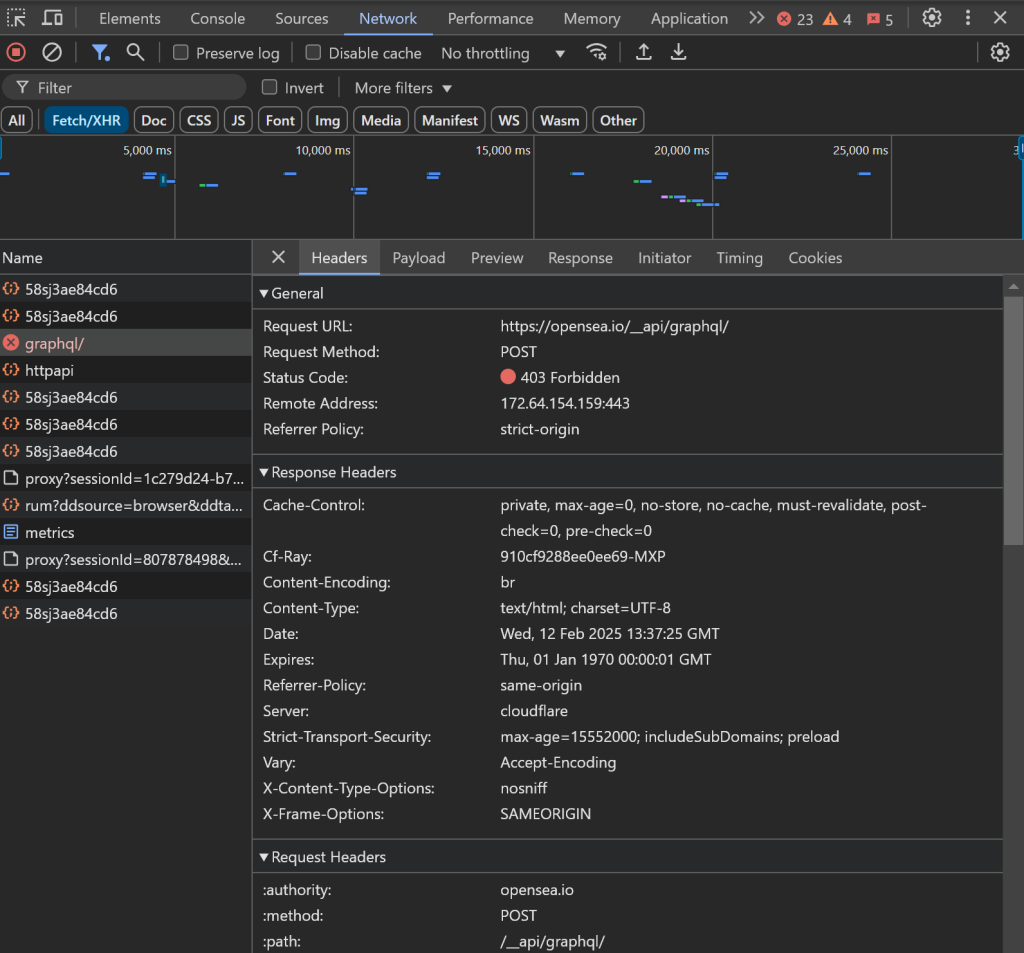
Esto se debe a las avanzadas medidas anti-bot implementadas por OpenSea para bloquear los bots de scraping.
Estos problemas hacen que el scraping de OpenSea sin las herramientas adecuadas sea una experiencia frustrante. ¿Cuál es la solución? Utilice el raspador dedicado OpenSea de Bright Data, que le permite recuperar datos del sitio mediante simples llamadas a la API o sin código, ¡sin riesgo de ser bloqueado!
Conclusión
En este tutorial paso a paso, has aprendido qué es un scraper OpenSea y los tipos de datos que puede recopilar. También has creado un script en Python para recopilar datos NFT de OpenSea, todo ello con menos de 100 líneas de código.
El reto reside en las estrictas medidas anti-bot de OpenSea, que bloquean las interacciones automatizadas del navegador. Elude esos problemas con nuestro OpenSea Scraper, una herramienta que puedes integrar fácilmente con API o sin código para recuperar datos públicos de NFT, como el nombre, la descripción, el ID del token, el precio actual, el precio de la última venta, el historial, las ofertas y mucho más.
Cree hoy mismo una cuenta gratuita en Bright Data y empiece a utilizar nuestras API de scraper.




