

En esta guía aprenderás:
- Qué es SeleniumBase y por qué es útil para el Scraping web
- Cómo se compara con Selenium vanilla
- Las características y ventajas que ofrece SeleniumBase
- Cómo utilizarlo para crear un Scraper sencillo
- Cómo utilizarlo para casos de uso más complejos
¡Empecemos!
¿Qué es SeleniumBase?
SeleniumBase es un marco de trabajo de Python para la automatización de navegadores. Basado en las API de Selenium/WebDriver, proporciona un conjunto de herramientas de nivel profesional para la automatización web. Admite una amplia gama de tareas, desde pruebas hasta scraping.
SeleniumBase es una biblioteca todo en uno para probar páginas web, automatizar flujos de trabajo y escalar operaciones basadas en la web. Viene equipado con funciones avanzadas como eludir CAPTCHA, evitar la detección de bots y herramientas para mejorar la productividad.
SeleniumBase frente a Selenium: comparación de características y API
Para comprender mejor el porqué de SeleniumBase, tiene sentido compararlo directamente con la versión básica de Selenium, la herramienta en la que se basa.
Para una comparación rápida entre Selenium y SeleniumBase, echa un vistazo a la tabla resumen que aparece a continuación:
| Característica | SeleniumBase | Selenium |
|---|---|---|
| Ejecutores de pruebas integrados | Se integra con pytest, pynose y behave |
Requiere configuración manual para la integración de pruebas |
| Gestión de controladores | Descarga automáticamente el controlador del navegador que coincide con la versión del navegador | Requiere la descarga y configuración manual del controlador |
| Lógica de automatización web | Combina varios pasos en una sola llamada a un método | Requiere varias líneas de código para una funcionalidad similar |
| Manejo de selectores | Detecta automáticamente selectores CSS o XPath | Requiere definir explícitamente los tipos de selectores en las llamadas a métodos |
| Gestión de tiempos de espera | Aplica tiempos de espera predeterminados para evitar fallos | Los métodos fallan inmediatamente si los tiempos de espera no se establecen explícitamente |
| Salidas de error | Proporciona mensajes de error claros y legibles para facilitar la depuración | Genera registros de errores detallados y menos interpretables |
| Paneles de control e informes | Incluye paneles, informes y capturas de pantalla de fallos integrados | Sin paneles de control ni funciones de generación de informes integrados |
| Aplicaciones GUI de escritorio | Ofrece herramientas visuales para la ejecución de pruebas | Carece de herramientas GUI de escritorio para la ejecución de pruebas |
| Grabador de pruebas | Grabador de pruebas integrado para crear scripts a partir de acciones manuales del navegador | Requiere la escritura manual de scripts |
| Gestión de casos de prueba | Proporciona CasePlans para organizar pruebas y documentar pasos directamente en el marco | Sin herramientas integradas de gestión de casos de prueba |
| Compatibilidad con aplicaciones de datos | Incluye ChartMaker para generar JavaScript desde Python y crear aplicaciones de datos | No hay herramientas adicionales para crear aplicaciones de datos |
¡Es hora de profundizar en las diferencias!
Ejecutores de pruebas integrados
SeleniumBase se integra con ejecutores de pruebas populares como pytest, pynose y behave. Estas herramientas proporcionan una estructura organizada, detección de pruebas sin problemas, ejecución, seguimiento del estado de las pruebas (por ejemplo, aprobadas, fallidas u omitidas) y opciones de línea de comandos para personalizar ajustes como la selección del navegador.
Con Selenium vanilla, sería necesario implementar manualmente un analizador de opciones o recurrir a herramientas de terceros para configurar las pruebas desde la línea de comandos.
Gestión mejorada de controladores
De forma predeterminada, SeleniumBase descarga una versión de controlador compatible que coincide con la versión principal de su navegador. Puede anular esto utilizando la opción --driver-version=VER en su comando pytest. Por ejemplo:
pytest my_script.py --driver-version=114
En cambio, Selenium requiere que descargue y configure manualmente el controlador adecuado. En ese caso, usted es responsable de garantizar la compatibilidad con la versión del navegador.
Métodos de múltiples acciones
SeleniumBase combina varios pasos en métodos únicos para simplificar la automatización web. Por ejemplo, el método driver.type(selector, text) realiza lo siguiente:
- Espera a que el elemento sea visible
- Espera a que el elemento sea interactivo
- Borra cualquier texto existente
- Escribe el texto proporcionado
- Envía si el texto termina en
«n»
Con Selenium sin procesar, replicar la misma lógica requeriría unas pocas líneas de código.
Manejo simplificado de selectores
SeleniumBase puede diferenciar automáticamente entre selectores CSS y expresiones XPath. Esto elimina la necesidad de especificar explícitamente los tipos de selectores con By.CSS_SELECTOR o By.XPATH. Sin embargo, si lo prefiere, puede seguir proporcionando el tipo explícitamente.
Ejemplo con SeleniumBase:
driver.click("button.submit") # Detecta automáticamente como selector CSS
driver.click("//button[@class='submit']") # Detecta automáticamente como XPath
El código equivalente en Selenium vanilla es:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
Valores de tiempo de espera predeterminados y personalizados
SeleniumBase aplica automáticamente un tiempo de espera predeterminado de 10 segundos a los métodos, lo que garantiza que los elementos tengan tiempo para cargarse. Esto evita fallos inmediatos, que son comunes en Selenium sin procesar.
También puede establecer valores de tiempo de espera personalizados directamente en las llamadas a métodos, como en el ejemplo siguiente:
driver.click("botón", tiempo de espera=20)
El código Selenium equivalente sería mucho más prolijo y complejo:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
Salidas de error claras
SeleniumBase proporciona mensajes de error claros y fáciles de leer cuando los scripts fallan. Por el contrario, Selenium sin procesar suele generar registros de errores prolijos y menos interpretables, lo que requiere un esfuerzo adicional para depurarlos.
Paneles de control, informes y capturas de pantalla
SeleniumBase incluye funciones para generar paneles e informes de las ejecuciones de pruebas. También guarda capturas de pantalla de los fallos en la carpeta ./latest_logs/ para facilitar la depuración. Selenium sin procesar carece de estas funciones de serie.
Funciones adicionales
En comparación con Selenium, SeleniumBase incluye:
- Aplicaciones GUI de escritorio para ejecutar pruebas de forma visual, como SeleniumBase Commander para
pytesty SeleniumBase Behave GUI parabehave. - Una grabadora/generador de pruebas integrado para crear scripts de prueba basados en acciones manuales del navegador. Esto reduce significativamente el esfuerzo necesario para escribir pruebas para flujos de trabajo complejos.
- Software de gestión de casos de prueba llamado CasePlans para organizar pruebas y documentar descripciones de pasos directamente dentro del marco.
- Herramientas como ChartMaker para crear aplicaciones de datos mediante la generación de código JavaScript desde Python. Esto lo convierte en una solución versátil que va más allá de la automatización de pruebas estándar.
SeleniumBase: características, métodos y opciones de CLI
Descubra qué hace que SeleniumBase sea especial explorando sus capacidades y su API.
Características
Esta es una lista de algunas de las características más relevantes de SleniumBase:
- Incluye el modo Recorder para generar instantáneamente pruebas de navegador en Python.
- Admite múltiples navegadores, pestañas, iframes y Proxies dentro de la misma prueba.
- Cuenta con un software de gestión de casos de prueba con tecnología Markdown.
- El mecanismo de espera inteligente mejora automáticamente la fiabilidad y reduce las pruebas inestables.
- Es compatible con
pytest,unittest,noseybehavepara la detección y ejecución de pruebas. - Incluye herramientas de registro avanzadas para paneles, informes y capturas de pantalla.
- Puede ejecutar pruebas en modo sin interfaz para ocultar la interfaz del navegador.
- Admite la ejecución de pruebas multihilo en navegadores paralelos.
- Permite ejecutar pruebas utilizando el emulador de dispositivos móviles de Chromium.
- Admite la ejecución de pruebas a través de un Proxy, incluso uno autenticado.
- Personaliza la cadena del agente de usuario del navegador para las pruebas.
- Evita la detección por parte de sitios web que bloquean la automatización de Selenium.
- Se integra con selenium-wire para inspeccionar las solicitudes de red del navegador.
- Interfaz de línea de comandos flexible para opciones de ejecución de pruebas personalizadas.
- Archivo de configuración global para gestionar los ajustes de las pruebas.
- Admite integraciones con GitHub Actions, Google Cloud, Azure, S3 y Docker.
- Admite la ejecución de JavaScript desde Python.
- Puede interactuar con elementos Shadow DOM utilizando
::shadowen selectores CSS.
Paraver la lista completa,consulte la documentación. Asegúrese de leer nuestro blog sobre cómo utilizar SeleniumBase con Proxies.
Métodos
A continuación se muestra una lista de los métodos más útiles de SeleniumBase:
driver.open(url): navega por la ventana del navegador hasta la URL especificada.driver.go_back(): Navega de vuelta a la URL anterior.driver.type(selector, text): Actualiza el campo identificado por el selector con el texto especificado.driver.click(selector): Hacer clic en el elemento identificado por el selector.driver.click_link(link_text): Hacer clic en el enlace que contiene el texto especificado.driver.select_option_by_text(selector_desplegable, opción): Selecciona una opción de un menú desplegable por el texto visible.driver.hover_and_click(hover_selector, click_selector): Pasa el cursor por encima de un elemento y haz clic en otro.driver.drag_and_drop(drag_selector, drop_selector): Arrastra un elemento y suéltalo sobre otro elemento.driver.get_text(selector): Obtenga el texto del elemento especificado.driver.get_attribute(selector, attribute): Obtiene el atributo especificado de un elemento.driver.get_current_url(): Obtiene la URL de la página actual.driver.get_page_source(): Obtiene el código fuente HTML de la página actual.driver.get_title(): Obtiene el título de la página actual.driver.switch_to_frame(frame): Cambia al contenedor iframe especificado.driver.switch_to_default_content(): Sale del contenedor iframe y vuelve al documento principal.driver.open_new_window(): Abre una nueva ventana del navegador en la misma sesión.driver.switch_to_window(window): Cambia a la ventana del navegador especificada.driver.switch_to_default_window(): Vuelve a la ventana original del navegador.driver.get_new_driver(OPTIONS): Abre una nueva sesión del controlador con las opciones especificadas.driver.switch_to_driver(driver): Cambia al controlador del navegador especificado.driver.switch_to_default_driver(): Volver al controlador del navegador original.driver.wait_for_element(selector): Espera hasta que el elemento especificado sea visible.driver.is_element_visible(selector): Comprueba si el elemento especificado es visible.driver.is_text_visible(texto, selector): Comprueba si el texto especificado es visible dentro de un elemento.driver.sleep(segundos): Pausa la ejecución durante el tiempo especificado.driver.save_screenshot(name): Guarda una captura de pantalla en formato.pngcon el nombre dado.driver.assert_element(selector): Verifica que el elemento especificado sea visible.driver.assert_text(texto, selector): Verifica que el texto especificado está presente en el elemento.driver.assert_exact_text(texto, selector): verifica que el texto especificado coincida exactamente en el elemento.driver.assert_title(title): Verifica que el título de la página actual coincida con el título especificado.driver.assert_downloaded_file(archivo): verifica que el archivo especificado se haya descargado.driver.assert_no_404_errors(): Verifica que no haya enlaces rotos en la página.driver.assert_no_js_errors(): Verifica que no haya errores de JavaScript en la página.
Para obtener la lista completa, consulte la documentación.
Opciones de la CLI
SeleniumBase amplía pytest con las siguientes opciones de línea de comandos:
--browser=BROWSER: Establece el navegador web (por defecto: «chrome»).--chrome: Atajo para--browser=chrome.--edge: Atajo para--browser=edge.--firefox: Atajo para--browser=firefox.--safari: Atajo para--browser=safari.--settings-file=FILE: Anula la configuración predeterminada de SeleniumBase.--env=ENV: Establece el entorno de prueba, accesible a través dedriver.env.--account=STR: Establece la cuenta, accesible a través dedriver.account.--data=STRING: Datos de prueba adicionales, accesibles a través dedriver.data.--var1=STRING: Datos de prueba adicionales, accesibles a través dedriver.var1.--var2=STRING: Datos de prueba adicionales, accesibles a través dedriver.var2.--var3=STRING: Datos de prueba adicionales, accesibles a través dedriver.var3.--variables=DICT: Datos de prueba adicionales, accesibles a través dedriver.variables.--proxy=SERVER:PORT: Conectarse a un servidor Proxy.--proxy=USERNAME:PASSWORD@SERVER:PORT: Utiliza un Proxy autenticado.--proxy-bypass-list=STRING: Hosts que se deben omitir (por ejemplo, «*.foo.com»).--proxy-pac-url=URL: Conectarse a través de la URL PAC.--proxy-pac-url=USERNAME:PASSWORD@URL: Proxy autenticado con URL PAC.--proxy-driver: Utilizar Proxy para la descarga del controlador.--multi-proxy: Permitir múltiples proxies autenticados en multihilos.--agent=STRING: Modificar la cadena User-Agent del navegador.--mobile: habilita el emulador de dispositivos móviles.--metrics=STRING: Establece métricas móviles (por ejemplo, «CSSWidth,CSSHeight,PixelRatio»).--chromium-arg="ARG=N,ARG2": Establece los argumentos de Chromium.--firefox-arg="ARG=N,ARG2": Establece los argumentos de Firefox.--firefox-pref=SET: Establece las preferencias de Firefox.--extension-zip=ZIP: Carga los archivos.zip/.crxde la extensión de Chrome.--extension-dir=DIR: Carga los directorios de extensiones de Chrome.--disable-features="F1,F2": Desactivar funciones.--binary-location=PATH: Establece la ruta binaria de Chromium.--driver-version=VER: Establece la versión del controlador.--headless: Modo sin interfaz predeterminado.--headless1: Utiliza el antiguo modo sin interfaz gráfica de Chrome.--headless2: Utiliza el nuevo modo sin interfaz gráfica de Chrome.--headed: habilita el modo GUI en Linux.--xvfb: ejecuta pruebas con Xvfb en Linux.--locale=CÓDIGO_DE_LOCALE: Establece la configuración regional del idioma del navegador.--reuse-session: reutiliza la sesión del navegador para todas las pruebas.--reuse-class-session: Reutiliza la sesión para las pruebas de clase.--crumbs: Elimina las cookies entre sesiones reutilizadas.--disable-cookies: Desactivar las cookies.--disable-js: Desactiva JavaScript.--disable-csp: Desactivar la política de seguridad de contenidos.--disable-ws: Desactivar la seguridad web.--enable-ws: habilita la seguridad web.--log-cdp: Registra los eventos del Protocolo de Chrome DevTools (CDP).--remote-debug: Sincronizar con Chrome Remote Debugger.--visual-baseline: Establece la línea de base visual para las pruebas de diseño.--timeout-multiplier=MULTIPLIER: Multiplicar los valores de tiempo de espera predeterminados.
Consulte la lista completa de definiciones de opciones de línea de comandos en la documentación.
Uso de SeleniumBase para el Scraping web: guía paso a paso
Siga este tutorial paso a paso para aprender a crear un Scraper SeleniumBase para recuperar datos del entorno de pruebas Quotes to Scrape:
Para ver un tutorial similar con Selenium vanilla, consulte nuestra guía sobre Scraping web con Selenium.
Paso n.º 1: Inicialización del proyecto
Antes de empezar, asegúrate de tener Python 3 instalado en tu equipo. Si no es así, descárgalo e instálalo.
Abra el terminal y ejecute el siguiente comando para crear un directorio para su proyecto:
mkdir seleniumbase-Scraper
seleniumbase-scraper contendrá su Scraper SeleniumBase.
Navega por él e inicializa un entorno virtual en su interior:
cd seleniumbase-Scraper
python -m venv env
A continuación, carga la carpeta del proyecto en tu IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition serán suficientes.
Crea un archivo scraper.py en el directorio del proyecto, que ahora debería contener esta estructura de archivos:

scraper.py pronto contendrá su lógica de rastreo.
Activa el entorno virtual en la terminal del IDE. En Linux o macOS, hazlo con el siguiente comando:
./env/bin/activate
De forma equivalente, en Windows, ejecute:
env/Scripts/activate
En el entorno activado, ejecute este comando para instalar SeleniumBase:
pip install seleniumbase
¡Genial! Ya tienes un entorno Python para el Scraping web con SeleniumBase.
Paso n.º 2: Configuración de la prueba de SeleniumBase
Aunque SeleniumBase admite la sintaxis pytest para crear pruebas, un bot de Scraping web no es un script de prueba. Aún así, puede aprovechar todas las opciones de extensión de la línea de comandos pytest de SeleniumBase utilizando la sintaxisSB:
from seleniumbase import SB
with SB() as sb:
pass
# Lógica de scraping...
Ahora puedes ejecutar tu prueba con:
python3 Scraper.py
Nota: En Windows, sustituya python3 por python.
Para ejecutarla en modo sin interfaz gráfica, ejecute:
python3 Scraper.py --headless
Ten en cuenta que puedes combinar varias opciones de línea de comandos.
Paso n.º 3: Conéctese a la página de destino
Utilice el método open() para indicar al navegador controlado que visite la página de destino:
sb.open("https://quotes.toscrape.com/")
Si ejecuta el script de prueba de scraping en modo con cabeza, esto es lo que verá durante una fracción de segundo:
Tenga en cuenta que, en comparación con Selenium vanilla, no es necesario cerrar manualmente el controlador. SeleniumBase se encargará de ello por usted.
Paso 4: Seleccionar los elementos de cotización
Abra la página de destino en modo incógnito en su navegador e inspeccione un elemento de cita:
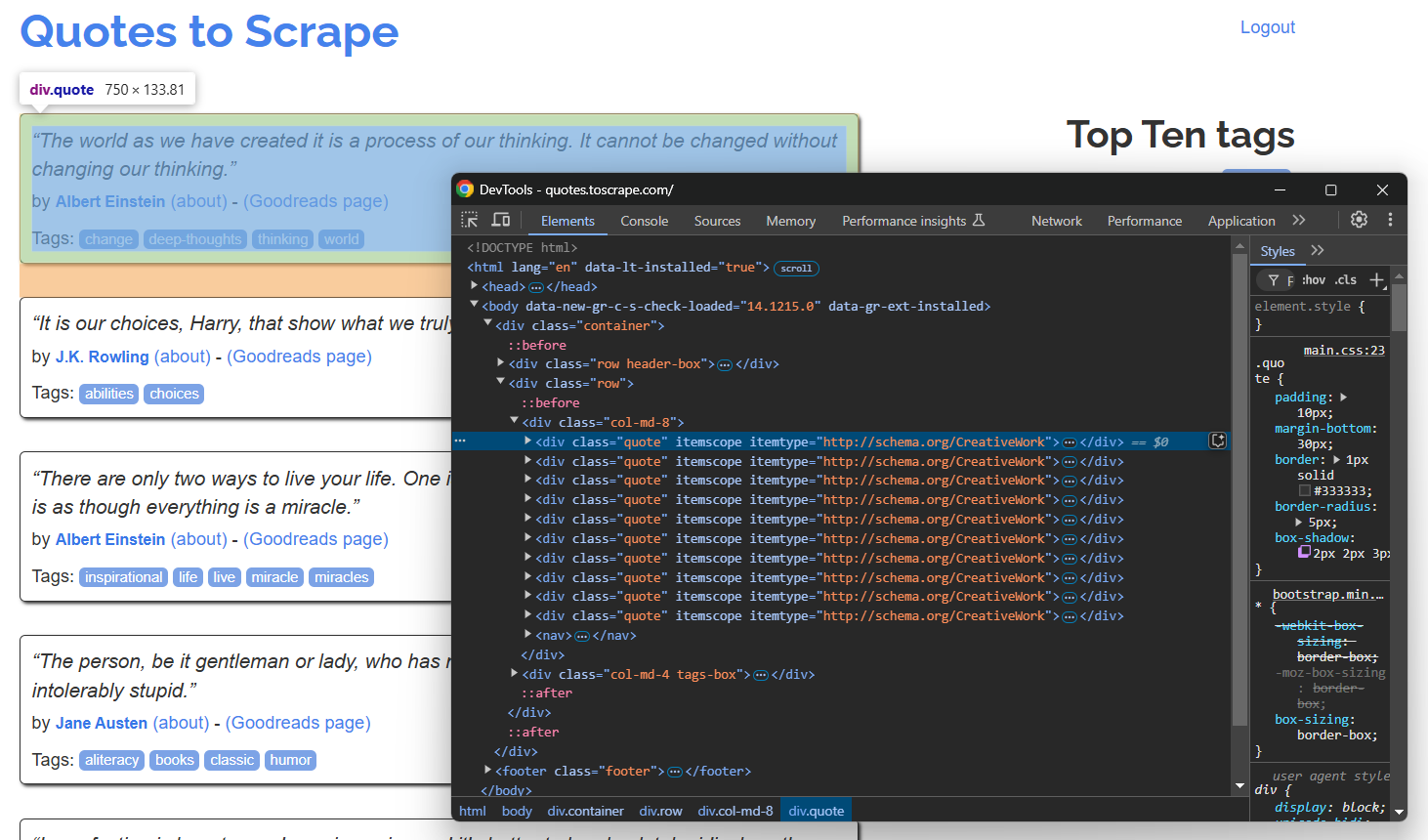
Dado que la página contiene varias citas, cree una matriz de citas para almacenar los datos extraídos:
quotes = []
En la sección DevTools anterior, puede ver que todas las citas se pueden seleccionar utilizando el selector CSS .quote. Utilice find_elements() para seleccionarlas todas:
quote_elements = sb.find_elements(".quote")
A continuación, prepárese para iterar sobre los elementos y extraer datos de cada elemento de cita. Añada los datos extraídos a una matriz:
for quote_element in quote_elements:
# Lógica de recopilación...
¡Genial! La lógica de extracción de alto nivel ya está lista.
Paso n.º 5: extraer los datos de las citas
Inspeccione un solo elemento de cotización:
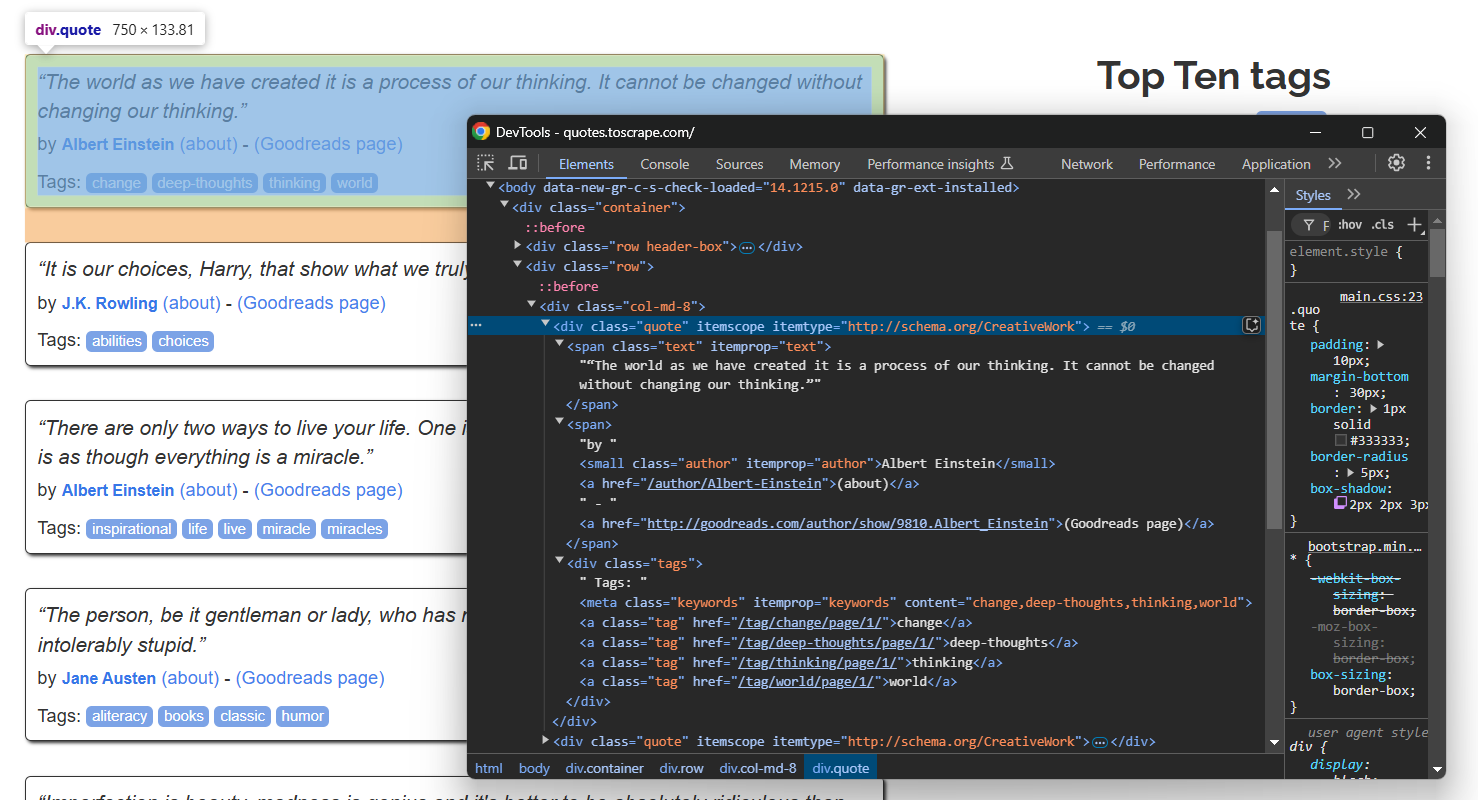
Tenga en cuenta que puede extraer:
- El texto de la cita de
.text - El autor de la cita de
.author - Las etiquetas de la cita de
.tag
Seleccione cada nodo y extraiga los datos de ellos con el atributo de texto:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Ten en cuenta que find_elements() devuelve objetos Selenium WebElement básicos. Por lo tanto, para seleccionar elementos dentro de ellos, debes utilizar los métodos nativos de Selenium. Por eso tienes que especificar By.CSS_SELECTOR como localizador.
Asegúrate de importar By al principio de tu script:
from selenium.webdriver.common.by import By
Observe cómo el rastreo de las etiquetas requiere un bucle, ya que una sola cita puede tener una o más etiquetas. Observe también el uso del método replace() para eliminar las comillas dobles especiales que rodean el texto.
Paso n.º 6: Rellenar la matriz de citas
Rellene un nuevo objeto de citas con los datos extraídos y añádalo a citas:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
¡Increíble! La lógica de extracción de SelenumBase está completa.
Paso 7: Implementar la lógica de rastreo
Recuerda que el sitio de destino contiene varias páginas. Para navegar a la página siguiente, haz clic en el botón «Siguiente →» en la parte inferior:
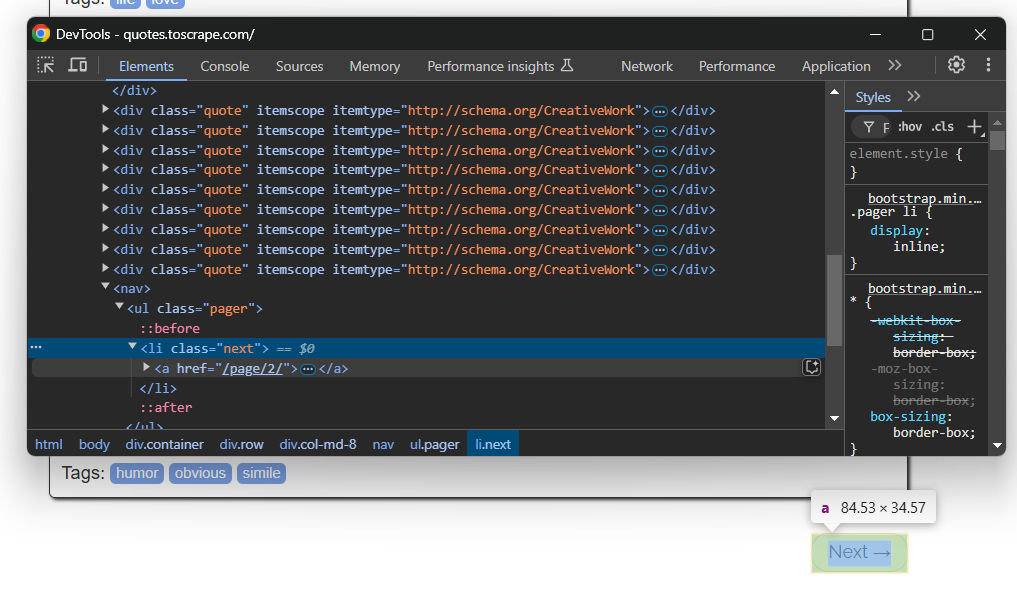
En la última página, este botón no estará presente.
Para implementar el rastreo web y extraer todas las páginas, envuelva su lógica de extracción en un bucle que haga clic en el botón «Siguiente →» y se detenga cuando el botón ya no esté disponible:
while sb.is_element_present(".next"):
# Lógica de scraping...
# Visitar la página siguiente
sb.click(".next a")
Tenga en cuenta el uso del método especial SleniumBae is_element_present() para comprobar si el botón está presente o no.
¡Perfecto! Su Scraper SeleniumBase ahora recorrerá todo el sitio.
Paso n.º 8: Exportar los datos extraídos
Exporta los datos extraídos entre comillas a un archivo CSV de la siguiente manera:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Aplanar los objetos de citas para la escritura CSV
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
No olvides importar csv desde la biblioteca estándar de Python:
import csv
Paso n.º 9: Ponlo todo junto
Tu archivo script.py debería contener ahora el siguiente código:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# Conectarse a la página de destino
sb.open("https://quotes.toscrape.com/")
# Dónde almacenar los datos extraídos
quotes = []
# Iterar sobre todas las páginas de citas
while sb.is_element_present(".next"):
# Seleccionar todos los elementos de citas de la página
quote_elements = sb.find_elements(".quote")
# Iterar sobre ellos y extraer los datos de cada elemento de cita
for quote_element in quote_elements:
# Lógica de extracción de datos
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Rellenar un nuevo objeto de cita con los datos extraídos.
quote = {
"text": text,
"author": author,
"tags": tags
}
# Añadirlo a la lista de citas extraídas.
quotes.append(quote)
# Visitar la página siguiente.
sb.click(".next a")
# Exportar los datos recopilados a CSV
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Aplanar los objetos de citas para la escritura CSV.
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Ejecuta el Scraper SeleniumBase en modo sin interfaz gráfica con:
python3 script.py --headless
Después de unos segundos, aparecerá un archivo quotes.csv en la carpeta del proyecto.
Ábrelo y verás:
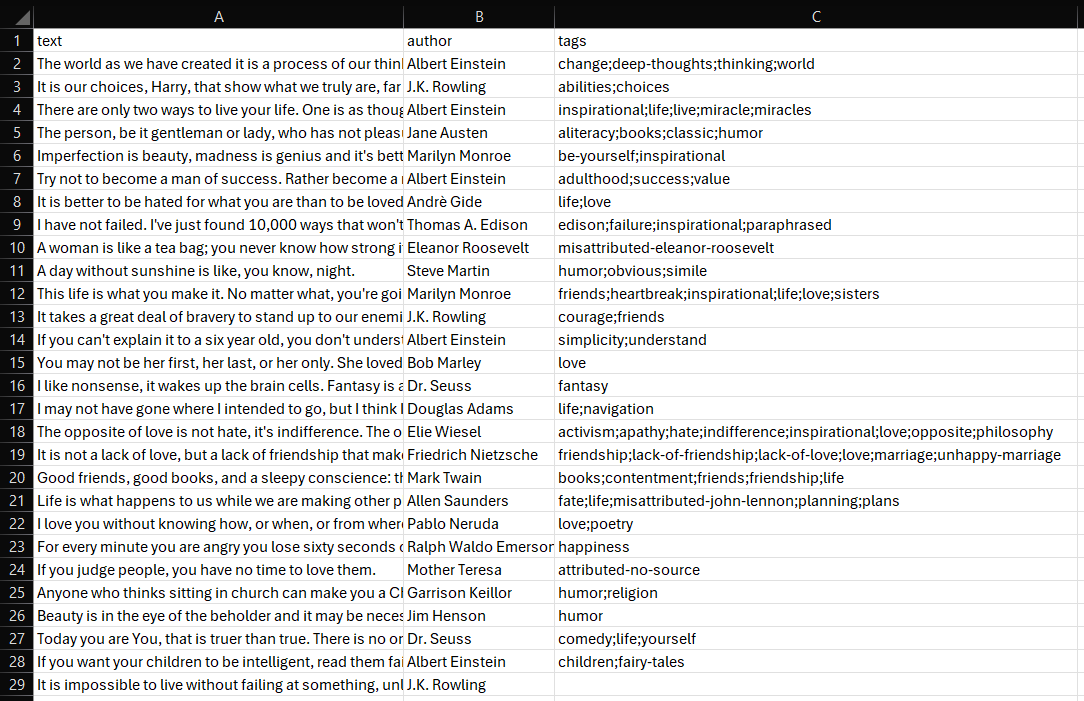
¡Et voilà! Tu script de Scraping web SeleniumBase funciona a las mil maravillas.
Casos de uso avanzados de scraping con SeleniumBase
Ahora que ya conoce los conceptos básicos de SeleniumBase, está listo para explorar algunos escenarios más complejos.
Automatizar el rellenado y envío de formularios
Nota: Bright Data no rastrea detrás del inicio de sesión.
SeleniumBase también te permite interactuar con los elementos de una página como lo haría un usuario humano. Por ejemplo, supongamos que necesitas interactuar con un formulario de inicio de sesión como el que se muestra a continuación:
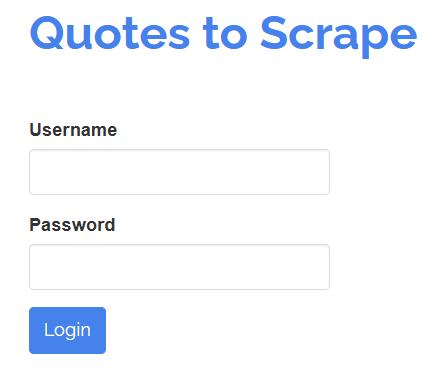
Su objetivo es rellenar los campos «Nombre de usuario» y «Contraseña» y, a continuación, enviar el formulario haciendo clic en el botón «Iniciar sesión». Puede lograrlo con una prueba de SeleniumBase de la siguiente manera:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# Visita la página de destino.
self.open("https://quotes.toscrape.com/login")
# Rellene el formulario
self.type("#username", "test")
self.type("#password", "test")
# Envíe el formulario
self.click("input[type="submit"]")
# Compruebe que está en la página correcta
self.assert_text("Top Ten tags")
Este ejemplo es ideal para crear una prueba a su alrededor, así que ten en cuenta el uso de la clase BaseCase. Eso te permite crear pruebas pytest.
Ejecuta la prueba con este comando:
pytest login.py
Verá que se abre el navegador, se carga la página de inicio de sesión, se rellena el formulario, se envía y, a continuación, se comprueba que el texto dado aparece en la página.
El resultado en la terminal será similar a este:
login.py . [100 %]
======================================== 1 aprobado en 11,20 s =========================================
Eludir tecnologías sencillas antibots
Muchos sitios implementan medidas avanzadas contra el scraping para evitar que los bots accedan a sus datos. Estas técnicas incluyen desafíos CAPTCHA, límites de velocidad, huellas digitales del navegador y otras. Para extraer datos de sitios web de forma eficaz sin ser bloqueado, es necesario eludir estas protecciones.
SeleniumBase ofrece una función especial llamada «modo UC» (modo Chromedriver no detectado), que ayuda a que los bots de scraping parezcan más usuarios humanos. Esto les permite evadir la detección de los servicios antibots, que de otro modo podrían bloquear directamente al bot de scraping o activar CAPTCHAs.
El modo UC se basa en undetected-chromedriver e incluye varias actualizaciones, correcciones y mejoras, como por ejemplo:
- Rotación automática del agente de usuario para evitar la detección.
- Configuración automática de los argumentos de Chromium según sea necesario.
- Métodos especiales
uc_*()para eludir CAPTCHAs.
Ahora, veamos cómo utilizar el modo UC en SeleniumBase para eludir los retos antibots.
Para esta demostración, verás cómo acceder a la página antibots desde el sitio Scraping Course:
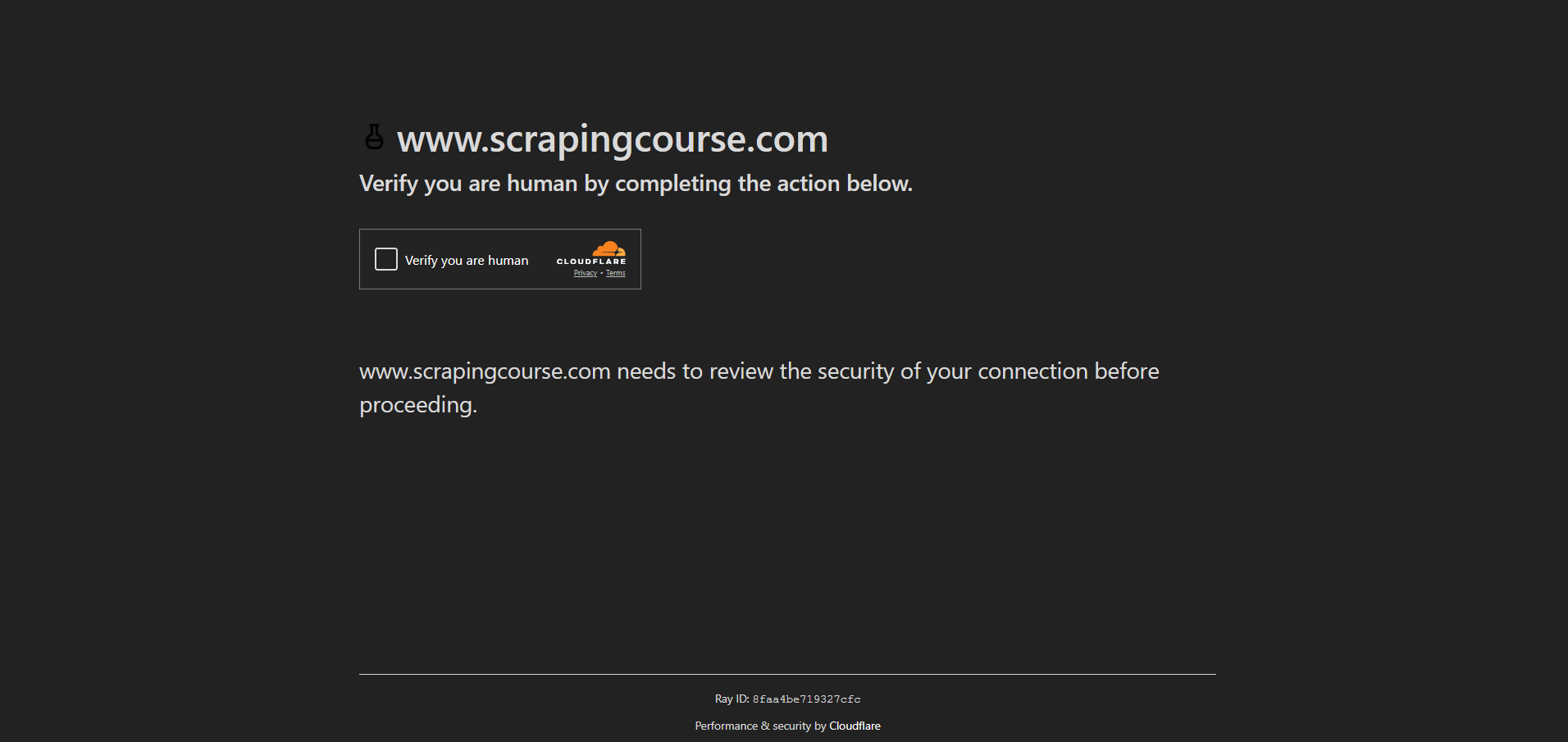
Para eludir las medidas antibots y gestionar el CAPTCHA, habilite el modo UC y utilice los métodos uc_open_with_reconnect() y uc_gui_click_captcha():
from seleniumbase import SB
with SB(uc=True) as sb:
# Página de destino con medidas antibots
url = "https://www.scrapingcourse.com/antibot-challenge"
# Abra la URL utilizando el modo UC con un tiempo de reconexión de 4 segundos para evitar la detección inicial.
sb.uc_open_with_reconnect(url, reconnect_time=4)
# Intentar eludir el CAPTCHA
sb.uc_gui_click_captcha()
# Hacer una captura de pantalla de la página
sb.save_screenshot("screenshot.png")
Ahora, ejecute el script y compruebe que funciona según lo esperado. Dado que uc_gui_click_captcha() requiere PyAutoGUI para funcionar, SeleniumBase lo instalará por usted la primera vez que lo ejecute:
¡Se requiere PyAutoGUI! Instalando ahora...
Verá que el navegador hace clic automáticamente en la casilla «Verificar que es humano» moviendo el ratón. El archivo screenshot.png de la carpeta de su proyecto mostrará:
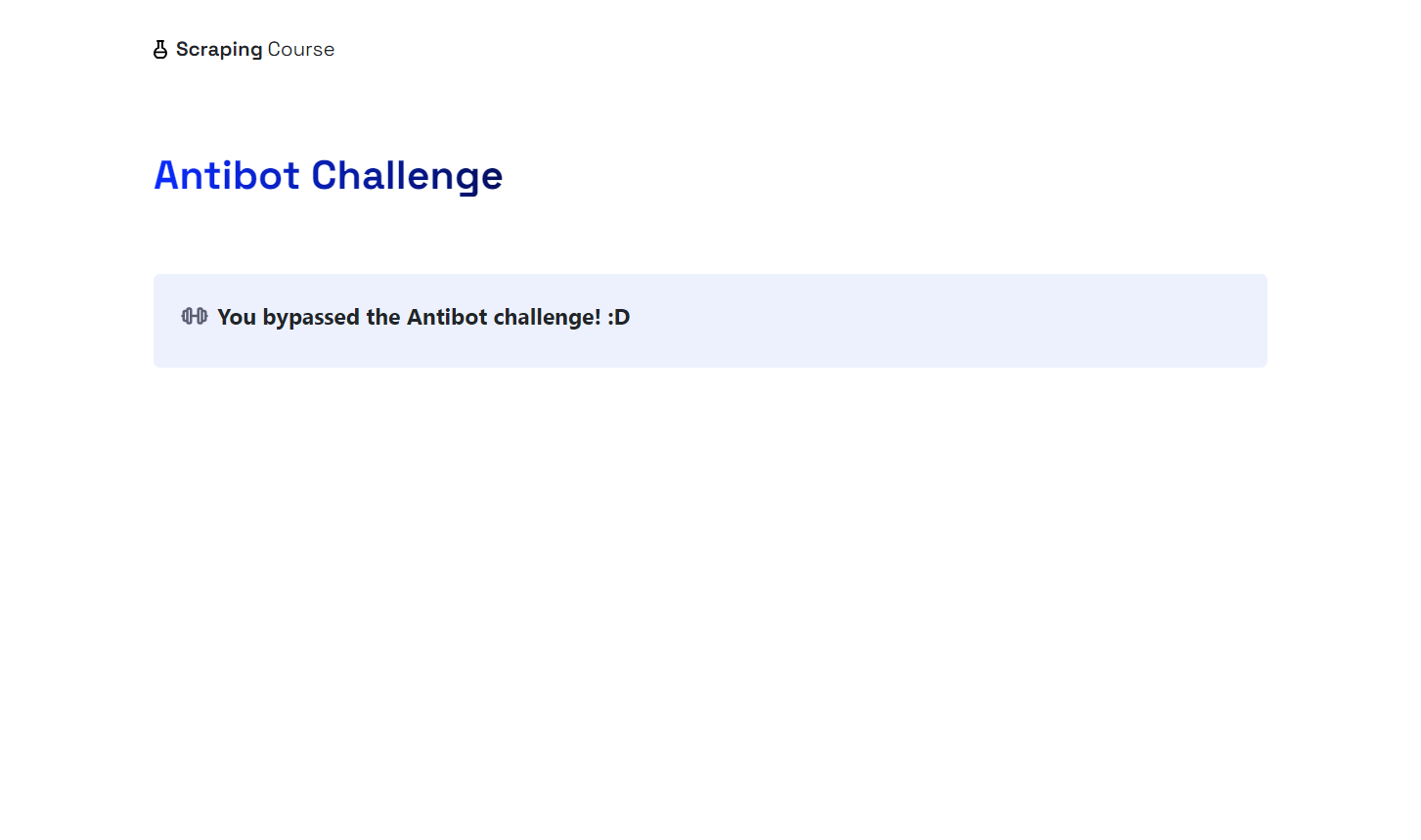
¡Vaya! Se ha omitido Cloudflare.
Elude las complejas tecnologías antibots
Las soluciones antibots son cada vez más sofisticadas y es posible que el modo UC no siempre sea eficaz. Por eso, SeleniumBase también ofrece un modo CDP especial (modo Chrome DevTools Protocol).
El modo CDP funciona dentro del modo UC y permite que los bots parezcan más humanos al controlar el navegador a través del controlador CDP. Mientras que el modo UC normal no puede realizar acciones de WebDriver cuando el controlador está desconectado del navegador, el controlador CDP puede seguir interactuando con el navegador, superando así esta limitación.
El modo CDP se basa en python-cdp, trio-cdp y nodriver. Está diseñado para eludir las soluciones antibots avanzadas de sitios web reales, como en el ejemplo siguiente:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# Página de destino con medidas antibots avanzadas
url = "https://gitlab.com/users/sign_in"
# Visitar la página en modo CDP
sb.activate_cdp_mode(url)
# Gestionar el CAPTCHA
sb.uc_gui_click_captcha()
# Esperar 2 segundos a que la página se recargue y el controlador vuelva a tomar el control
sb.sleep(2)
# Hacer una captura de pantalla de la página
sb.save_screenshot("screenshot.png")
El resultado será:
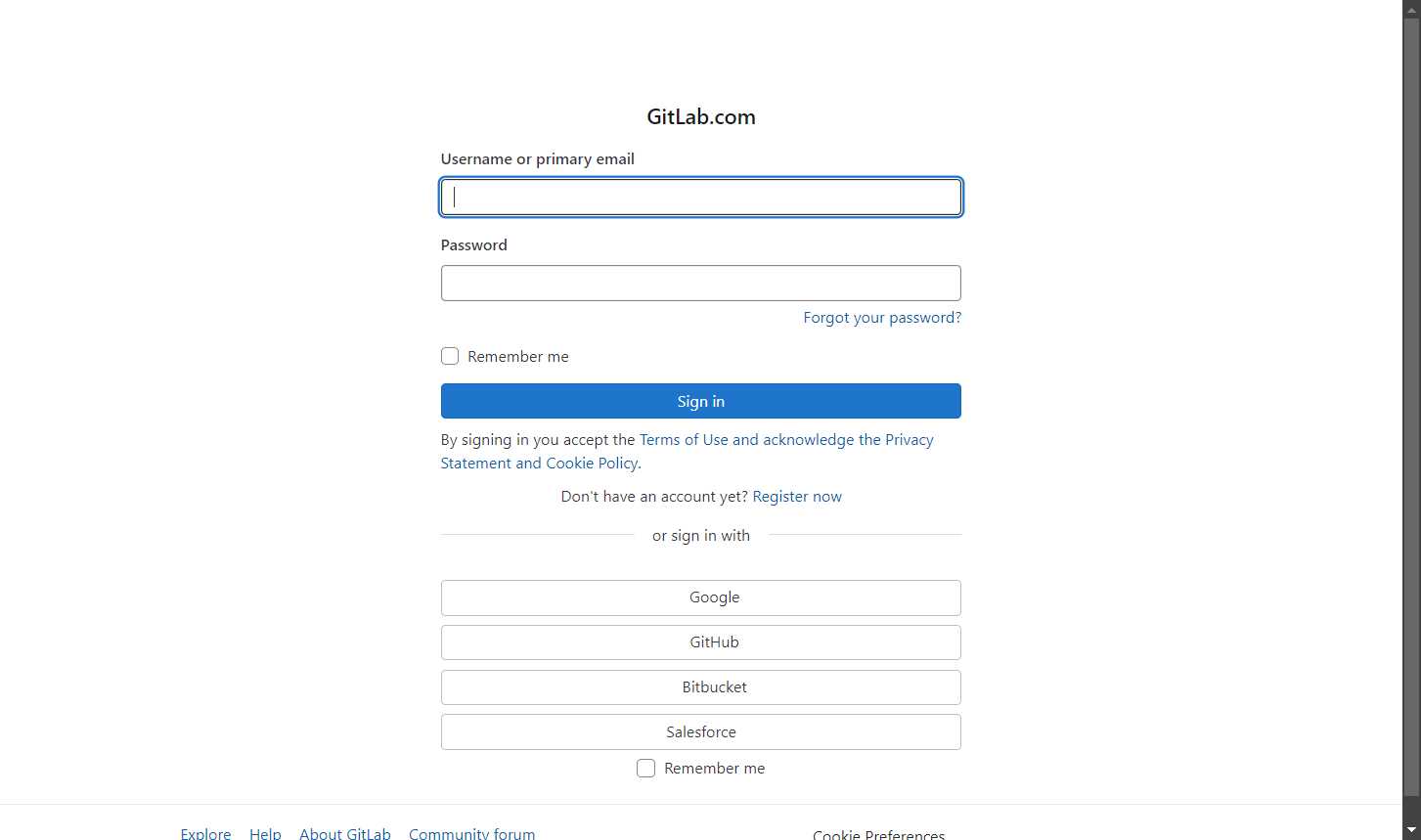
¡Ya está! Ahora eres un maestro del scraping con SeleniumBase.
Conclusión
En este artículo, has aprendido sobre SeleniumBase, las características y métodos que ofrece, y cómo utilizarlo para el Scraping web. Has comenzado con escenarios básicos y luego has explorado casos de uso más complejos.
Aunque los modos UC y CDP son eficaces para eludir ciertas medidas antibots, no son infalibles.
Los sitios web pueden seguir bloqueando tu IP si realizas demasiadas solicitudes o te desafían con CAPTCHAs más complejos que requieren múltiples acciones. Una solución más eficaz es utilizar una herramienta de automatización de navegadores web como Selenium en combinación con un navegador dedicado al scraping, basado en la nube y altamente escalable, como el Navegador de scraping de Bright Data.
El navegador de scraping funciona con Playwright, Puppeteer, Selenium y otros. Rota automáticamente las IP de salida con cada solicitud y puede gestionar las huellas digitales del navegador, los reintentos, la resolución de CAPTCHA y mucho más. Olvídate de los bloqueos y optimiza tus operaciones de scraping.
¡Regístrese ahora y comience su prueba gratuita!




