

Durante casi 25 años, Tripadvisor ha sido un lugar ideal para descubrir todo tipo de destinos turísticos en la web. Hoy vamos a extraer datos de hoteles de Tripadvisor. Tripadvisor emplea diversas técnicas para bloquear los Scrapers web, tales como:
- Desafíos de JavaScript
- Huellas digitales del navegador
- Contenido dinámico de la página
Siga nuestra guía a continuación y, al final, podrá extraer datos de Tripadvisor con facilidad.
Requisitos
Tripadvisor utiliza diversas técnicas de bloqueo. Para simplificar, las desglosamos en la siguiente lista.
- Desafío JavaScript: Tripadvisor envía un desafío sencillo (en JavaScript) a tu navegador en forma de CAPTCHA; si tu navegador no puede resolverlo, es probable que se trate de un bot.
- Huella digital del navegador: envían una cookie a tu navegador y luego te rastrean con ella.
- Contenido dinámico: inicialmente obtenemos una página en blanco. A continuación, realiza una serie de llamadas a la API para recuperar y renderizar nuestros datos.
Las solicitudes de Python y BeautifulSoup simplemente no bastan. Necesitamos un navegador real. Con Selenium, utilizamos webdriver para controlar nuestro navegador desde dentro de un script de Python. Selenium viene con todo lo que necesitamos. Obtén más información sobre el Scraping web con Selenium aquí.
Instalemos Selenium. También debes asegurarte de tener instalado webdriver. Puedes encontrar la última versión de webdriver aquí. Debes asegurarte de que tu versión de Chromedriver coincida con tu versión de Chrome.
Puede comprobar su número de versión con el siguiente comando. Asegúrese de que coincide con su versión de Chromedriver.
google-chrome --version
Debería dar un resultado similar a este.
Google Chrome 130.0.6723.116
A continuación, podemos instalar Selenium con el siguiente comando.
pip install selenium
Una vez instalado Selenium, no necesitamos instalar nada más. Selenium se encargará de todas nuestras necesidades relacionadas con el scraping. Todos los demás paquetes de este tutorial vienen preinstalados con Python.
Qué extraer de Tripadvisor
Veamos exactamente cómo extraer hoteles de Tripadvisor. Cuando realizamos una búsqueda básica de Miami en Tripadvisor, obtenemos una página similar a la que se ve en la captura de pantalla siguiente. Si te fijas, no solo obtenemos resultados de hoteles, sino de todas las categorías.
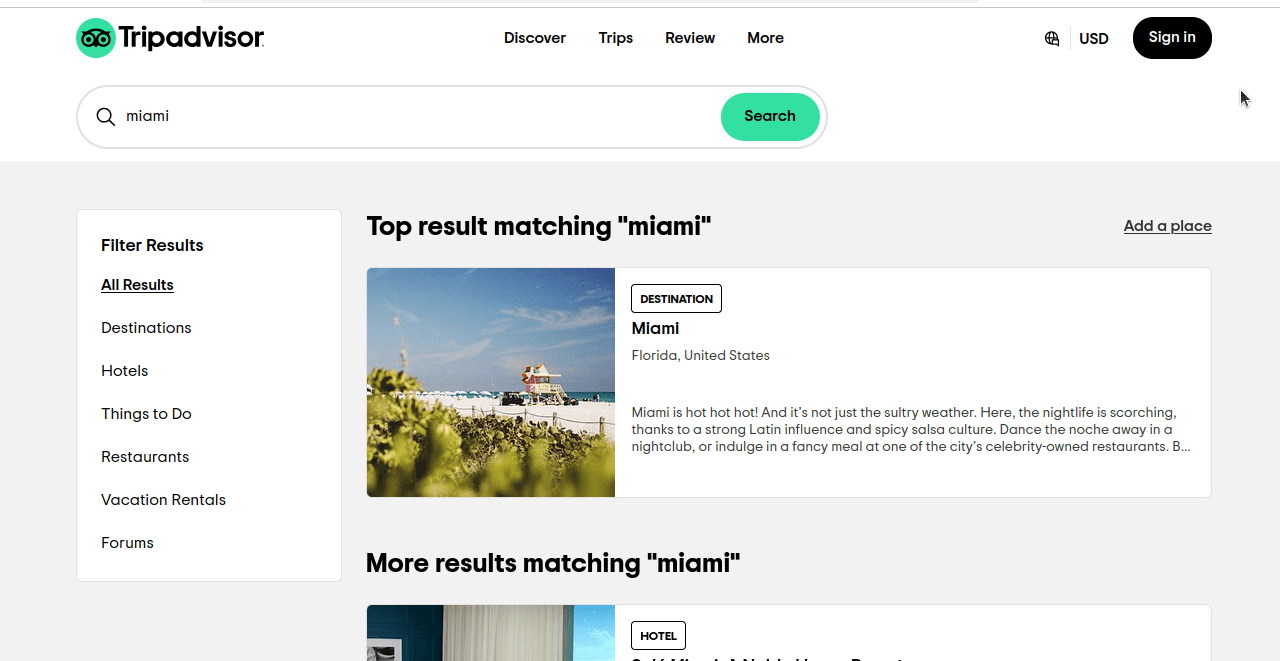
Fíjate bien en la URL de esta página: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Ahora, haremos clic en «Hoteles» y examinaremos nuestra URL: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Las URL siguen siendo muy similares. A continuación, echaremos un vistazo a estas URL, pero eliminaremos las partes innecesarias.
- Todos los resultados:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - Hoteles:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrc es la consulta que utilizamos para seleccionar nuestros resultados. ssrc=a se utiliza para Todos los resultados. ssrc=h se utiliza para Hoteles. Si haces clic en este enlace https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h, deberías obtener una página similar a la que ves en la captura de pantalla siguiente.
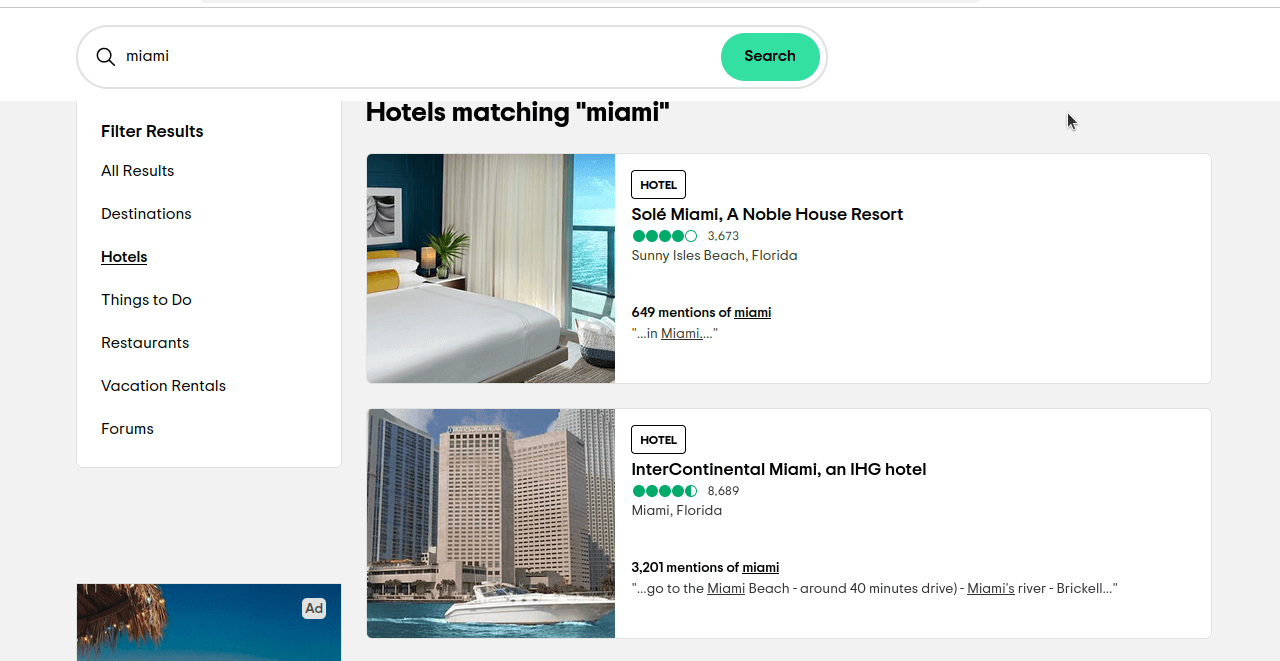
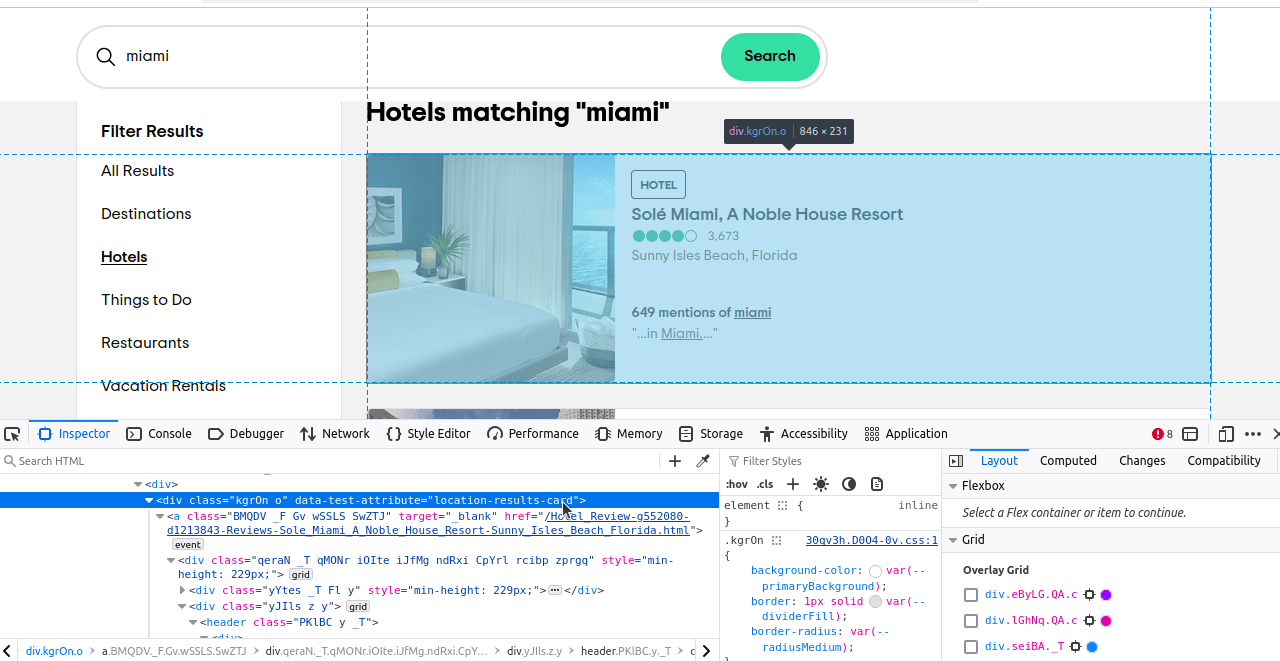
Ahora solo tenemos que averiguar qué elementos queremos localizar. Si inspeccionas estos elementos, verás que cada resultado tiene un atributo de prueba de datos «location-results-card». Esto es muy importante. Podemos utilizarlo para escribir nuestro selector CSS: div[data-test-attribute='location-results-card']. Cuando rastreemos la página real, buscaremos todos los elementos de la página que coincidan con este selector.
Extraer Tripadvisor con Vanilla Selenium
Ahora vamos a intentar extraer Tripadvisor utilizando el antiguo Selenium. Escribiremos un script que, en general, es bastante sencillo. En realidad, solo necesitamos dos funciones. Necesitamos una para realizar la extracción y otra para escribir nuestros datos en CSV. Una vez que las tengamos, lo juntaremos todo en un script totalmente funcional.
Echa un vistazo a write_to_csv(). Toma dos argumentos, data y page_number. data puede ser un diccionario o una matriz de objetos diccionario que queremos escribir. page_number se utiliza para escribir nuestro nombre de archivo. Utilizamos Path(filename).exists() para comprobar si nuestro archivo existe. mode es el modo que utilizamos para abrir el archivo. Si el archivo existe, establecemos nuestro modo en «a», o añadir. Si el archivo no existe, dejamos nuestro modo como el predeterminado, «w», escribir. Estos dos modos garantizan que siempre tengamos un archivo y que el archivo existente no se sobrescriba.
Funciones individuales
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Se ha escrito correctamente {page} en CSV...")
- Al principio de la función, comprobamos si nuestros
datosson unalista. Si no lo son, los convertimos en una. f"tripadvisor-{page_number}.csv"crea nuestro nombre de archivo.- Nuestro
modopredeterminado es«w», pero si el archivo existe, cambiamos nuestro modo a«a». csv.DictWriter(file, fieldnames=data[0].keys())inicializa nuestro escritor de archivos.- Si estamos en modo de escritura, escribimos utilizando las claves de nuestro primer objeto para nuestros encabezados. Si estamos añadiendo el archivo, no necesitamos hacer esto.
- Una vez configurado el archivo, utilizamos
writer.writerows(data)para escribir nuestros datos en un archivo CSV.
Ahora, echemos un vistazo a nuestra función de scraping. Esta función solo toma un argumento, nuestro page_ number...bastante autoexplicativo. Comenzamos configurando algunas ChromeOptions personalizadas. Añadimos argumentos para que nuestro navegador sea headless y para utilizar un agente de usuario falso. Con suerte, esto debería enmascarar nuestro navegador lo suficiente como para que Tripadvisor nos deje pasar. A continuación, utilizamos webdriver para iniciar nuestro navegador y navegar a la página de resultados de búsqueda. Usamos sleep(5) para esperar 5 segundos a que se cargue el contenido, lo que también nos hace parecer más un usuario normal. Usamos el selector CSS que mencionamos anteriormente en la sección «Qué extraer». Si no tenemos hotel_cards, hacemos una captura de pantalla y salimos de la función antes de tiempo. Si tenemos hotel_cards, extraemos sus datos y los añadimos a nuestra matriz scraped_data. Una vez que hemos terminado de extraer los datos, los escribimos todos en un CSV.
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Conectando con el Navegador de scraping...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("¡Conectado! Rastreando página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
puntuación = Ninguna
divs = tarjeta.find_elements(By.CSS_SELECTOR, "div")
para div en divs:
etiqueta_aria = div.get_attribute("aria-label")
si etiqueta_aria:
si "burbujas" en etiqueta_aria:
puntuación = etiqueta_aria
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Tarjeta {index} extraída correctamente")
print(f"Página extraída {page_number}")
write_to_csv(scraped_data, page_number)
Recopilar datos de Tripadvisor
Cuando juntamos todo, obtenemos un script como este. No dude en copiar y pegar el código siguiente en su propio archivo Python.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Escribiendo en CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Escribiendo datos en archivo CSV...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Se ha escrito correctamente {page} en CSV...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Conectando con el Navegador de scraping...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("¡Conectado! Rastreando página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
puntuación = Ninguna
divs = tarjeta.find_elements(By.CSS_SELECTOR, "div")
para div en divs:
etiqueta_aria = div.get_attribute("aria-label")
si etiqueta_aria:
si "burbujas" en etiqueta_aria:
puntuación = etiqueta_aria
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Tarjeta {index} extraída correctamente")
print(f"Página extraída {page_number}")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Cuando ejecutamos este código, la mayoría de las veces obtenemos una pantalla bloqueada o un CAPTCHA como el que se ve en la siguiente captura de pantalla.

Técnicas avanzadas
A continuación se muestran algunas de las técnicas más avanzadas utilizadas en nuestro script. Principalmente, repasaremos cómo se gestiona la paginación y algunas técnicas para evitar que se bloquee.
Gestión de la paginación
Eche un vistazo a la URL que utilizamos: https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}. Nuestra paginación se gestiona con el parámetro offset. Obtenemos 30 resultados por página. page_number*30 multiplica nuestro número de página por los resultados por página (30). La página 0 mostrará los resultados del 1 al 30. La página 2 contiene los resultados del 31 al 60, y así sucesivamente.
Echemos también un vistazo más de cerca a nuestro main. PAGES contiene el número de páginas que queremos extraer. Si desea extraer las primeras cinco páginas de datos, simplemente cambie PAGES = 1 por PAGES = 5.
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Mitigar el bloqueo
Con Vanilla Selenium, utilizamos un par de técnicas para evitar que nos bloqueen. Utilizamos un agente de usuario falso y sleep(5). Esta función sleep permite que la página se cargue y también espacia nuestras solicitudes cuando rastreamos varias páginas.
Este es nuestro agente de usuario. Le indica a Tripadvisor que nuestro navegador es compatible con Chrome 130.0.0.0 y Safari 537.36. Cuando Tripadvisor lee esto, su servidor nos envía una página compatible con estos navegadores.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/130.0.0.0 Safari/537.36
Sin embargo, aún es posible que te detecten y bloqueen tu Scraper. Para superar sus bloqueos de forma consistente, necesitamos algo un poco más potente que Vanilla Selenium.
Considera el uso de Bright Data
Bright Data tiene todo tipo de soluciones para superar los bloqueos con los que nos encontramos con Vanilla Selenium. El Navegador de scraping nos permite ejecutar una instancia remota de Selenium utilizando únicamente los mejores Proxy de Bright Data. En primer lugar, repasaremos el proceso de registro. A continuación, modificaremos nuestro script anterior para que se ejecute con el Navegador de scraping.
Crear una cuenta
En primer lugar, dirígete a nuestra página del Navegador de scraping. Haz clic en «Prueba gratuita». Puedes crear una cuenta utilizando Google, Github o tu dirección de correo electrónico.
Una vez que hayas creado tu cuenta, se te redirigirá al panel de control. Haz clic en «Añadir».
Deberías ver un menú desplegable similar al de la imagen siguiente. Haz clic en Navegador de scraping.
Ahora, se le redirigirá a la página donde se configura el Navegador de scraping. Vamos a utilizar la configuración predeterminada. Por defecto, el Navegador de scraping viene con un solucionador de CAPTCHA integrado.
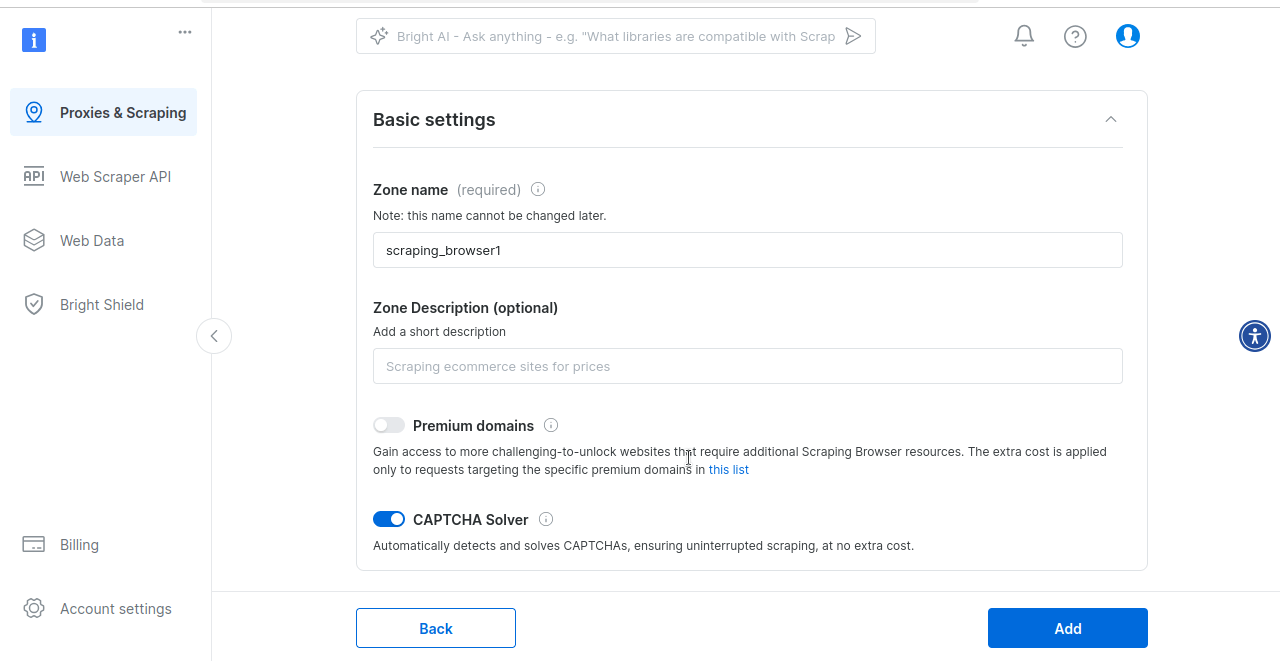
Por último, se te pedirá que crees tu zona de Navegador de scraping. Si estás listo para probar el Navegador de scraping, haz clic en Sí.
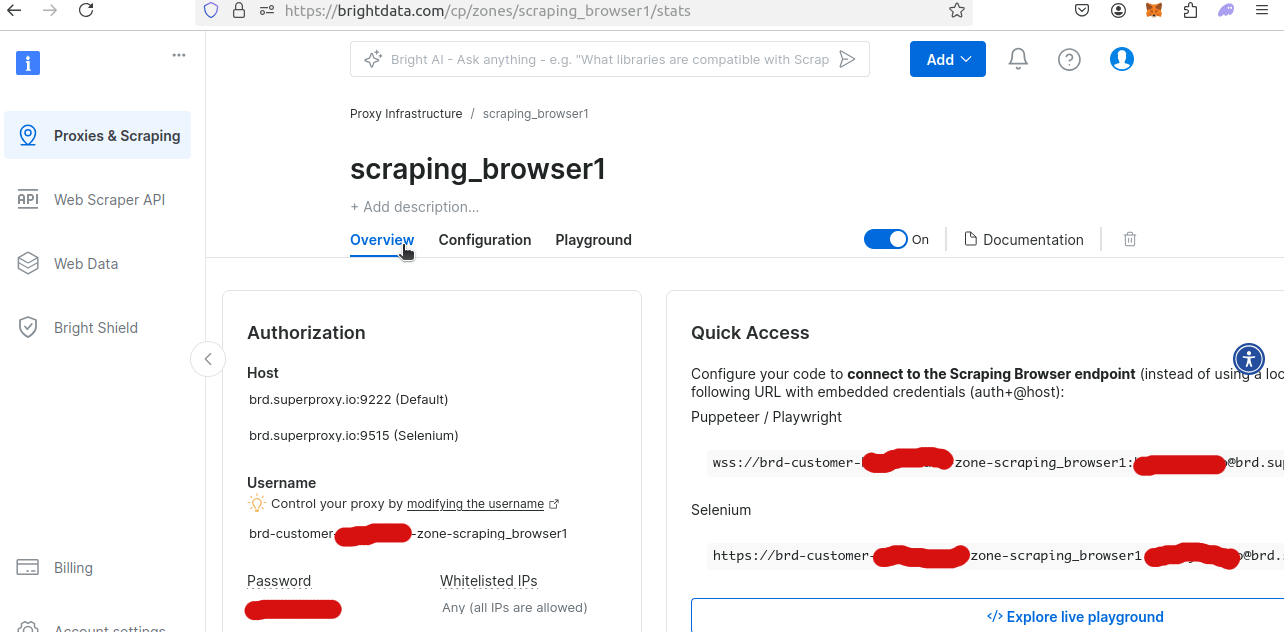
Si miras la descripción general de tu nueva zona del Navegador de scraping, podrás obtener tu nombre de usuario y contraseña únicos. Los necesitarás para acceder al Navegador de scraping desde tu script de Python.
Extraiga nuestros datos utilizando el Navegador de scraping de Bright Data
Nuestro ejemplo de código a continuación ha sido modificado para utilizar Remote Webdriver con el Navegador de scraping. Asegúrate de sustituir YOUR_USERNAME, YOUR_ZONE_NAME y YOUR_PASSWORD por tu nombre de usuario, zona y contraseña reales.
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-TU_NOMBRE_DE_USUARIO-zone-TU_NOMBRE_DE_ZONA:TU_CONTRASEÑA"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Se ha escrito correctamente {page} en CSV...")
def scrape_page(page_number: int):
print("Conectando con el Navegador de scraping...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("¡Conectado! Rastreando página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("¡No se han encontrado tarjetas de hotel! Tomando una captura de pantalla y saliendo.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Tarjeta {index} extraída correctamente")
print(f"Página extraída {page_number}")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Este ejemplo es muy similar al nuestro con Vanilla Selenium, pero hay algunas pequeñas diferencias que hay que tener en cuenta. Se refieren principalmente al hecho de que estamos utilizando un controlador web remoto en lugar del controlador web estándar.
- Configuramos una instancia de controlador web remoto con nuestra conexión Proxy:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515". - Nuestro manejo de errores ha cambiado ligeramente:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png"). Ahora utilizamosdriver.get_screenshot_as_file()en lugar dedriver.save_screenshot().
Aparte de algunos pequeños ajustes en nuestra conexión Proxy remota, nuestro código para el Navegador de scraping con Selenium es prácticamente el mismo que con Vanilla Selenium. La mayor diferencia: El Navegador de scraping obtiene nuestros resultados fácilmente.
Al ejecutar este código, es posible que reciba el siguiente error. Esto puede ocurrir cuando se trata de una conexión remota. Si es así, vuelva a intentar ejecutar el script. A veces, se necesitan varios intentos para establecer una conexión estable.
urllib3.exceptions.ProtocolError: ('Conexión abortada.', RemoteDisconnected('El extremo remoto cerró la conexión sin respuesta'))
Si el script se ha ejecutado correctamente, debería recibir el siguiente resultado.
Conectando con Navegador de scraping...
-------------------------------
¡Conectado! Raspando página...
Tarjeta 0 raspada correctamente.
Tarjeta 1 raspada correctamente.
Tarjeta 2 raspada correctamente.
Tarjeta 3 raspada correctamente.
Tarjeta 4 raspada correctamente.
Tarjeta 5 extraída correctamente.
Tarjeta 6 extraída correctamente.
Tarjeta 7 extraída correctamente.
Tarjeta 8 extraída correctamente.
Tarjeta 9 extraída correctamente.
Tarjeta 10 extraída correctamente.
Tarjeta 11 extraída correctamente.
Tarjeta 12 extraída correctamente.
Tarjeta 13 extraída correctamente.
Tarjeta 14 raspada correctamente
Tarjeta 15 raspada correctamente
Tarjeta 16 raspada correctamente
Tarjeta 17 raspada correctamente
Tarjeta 18 raspada correctamente
Tarjeta 19 raspada correctamente
Tarjeta 20 raspada correctamente
Tarjeta 21 raspada correctamente
Tarjeta 22 raspada correctamente
Tarjeta 23 raspada correctamente
Tarjeta 24 extraída correctamente
Tarjeta 25 extraída correctamente
Tarjeta 26 extraída correctamente
Tarjeta 27 extraída correctamente
Tarjeta 28 extraída correctamente
Tarjeta 29 extraída correctamente
Página 0 extraída
Escribiendo en CSV...
Escribiendo datos en el archivo CSV...
0 escrito correctamente en CSV...
Aquí hay una captura de pantalla de nuestros datos CSV utilizando ONLYOFFICE.
La imagen no se muestra Posibles razones
- El archivo de imagen puede estar dañado
- El servidor que aloja la imagen no está disponible.
- La ruta de la imagen es incorrecta
- El formato de la imagen no es compatible
Enfoque alternativo: Conjuntos de datos
Si no te gusta programar un Scraper o necesitas datos a mayor escala, considera la posibilidad de utilizar los Conjuntos de datos estructurados de Tripadvisor. Nuestros Conjuntos de datos proporcionan información bien organizada y de alta calidad adaptada a tus necesidades, lo que te permite analizar las tendencias de viaje, supervisar los precios de la competencia y optimizar la experiencia de los clientes sin esfuerzo.
Con un conjunto de datos de Tripadvisor, puede acceder a puntos de datos clave como nombres de hoteles, reseñas, valoraciones, servicios, precios y mucho más, todo ello en formatos flexibles (por ejemplo, JSON, CSV, Parquet) y actualizado según un calendario que se adapta a su flujo de trabajo. Lo mejor de todo es que estos conjuntos de datos son 100 % compatibles y escalables, lo que le permite ahorrar tiempo y recursos al tiempo que garantiza la precisión.
Ventajas principales:
- Acceda a todos los puntos de datos importantes de Tripadvisor sin tener que lidiar con bloqueos.
- Adapte los conjuntos de datos a sus necesidades específicas con filtros y formatos personalizados.
- Automatice la entrega de datos a plataformas como Snowflake, S3 o Azure.
Céntrese en analizar los datos, no en recopilarlos: déjenos encargarnos de la parte difícil. ¡Explore nuestros Conjuntos de datos de Tripadvisor hoy mismo!
Conclusión
Desde los retos de JavaScript hasta el contenido totalmente dinámico, Tripadvisor puede ser realmente difícil de rastrear. Ahora que ha terminado nuestra guía, debería resultarle un poco más fácil. Llegados a este punto, ya debería saber que puede utilizar Selenium para controlar un navegador tanto de forma local como mediante una sesión remota. Con los navegadores sin interfaz gráfica (como Selenium), también tiene la posibilidad de hacer una captura de pantalla de sus datos. Esto facilita mucho la depuración de nuestro Scraper. Ya sabes cómo extraer datos de hoteles y cómo escribir un archivo CSV utilizando el clásico Python, ¡sin tener que instalar nada más!
Si quieres realizar scraping a gran escala, Bright Data tiene un montón de productos que te pueden ayudar. El Navegador de scraping te ofrece las mejores herramientas para cualquier tarea relacionada con el scraping. Puedes controlar un navegador real con una conexión Proxy estable con el navegador sin interfaz gráfica que elijas. ¡Tampoco tendrás que preocuparte por los CAPTCHA!
O bien, puedes elegir la mejor forma de obtener datos: compra un conjunto de datos de Tripadvisor listo para usar. ¡Regístrate ahora para comenzar tu prueba gratuita!






