

El scraping de Zillow, un sitio web de transacciones inmobiliarias en línea, le ofrece información valiosa sobre el mercado inmobiliario, que abarca análisis de mercado, tendencias del sector de la vivienda y descripciones generales de la competencia. Al realizar scraping de Zillow, puede recopilar información completa sobre los precios, la ubicación, las características y las tendencias históricas de las propiedades, lo que le permite realizar análisis de mercado, mantenerse al día de las tendencias del sector de la vivienda, evaluar las estrategias de la competencia y tomar decisiones basadas en datos que se ajusten a sus objetivos de inversión.
En este tutorial, aprenderá a extraer datos de Zillow utilizando Beautiful Soup. Además de aprender a recopilar datos útiles, también aprenderá las técnicas antiextracción de datos que emplea Zillow y cómo Bright Data puede ayudarle.
¿Quiere saltarse el rastreo y obtener directamente los datos? Eche un vistazo a nuestros Conjuntos de datos de Zillow.
Rastrear Zillow
Tanto si es nuevo en Python como si ya tiene experiencia, este tutorial le ayudará a crear un Scraper web utilizando bibliotecas gratuitas como Beautiful Soup o Requests. ¡Empiece ya!
Requisitos
Antes de empezar, se recomienda que tengas conocimientos básicos sobre Scraping web y HTML. También debes hacer lo siguiente:
- documentación oficial
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
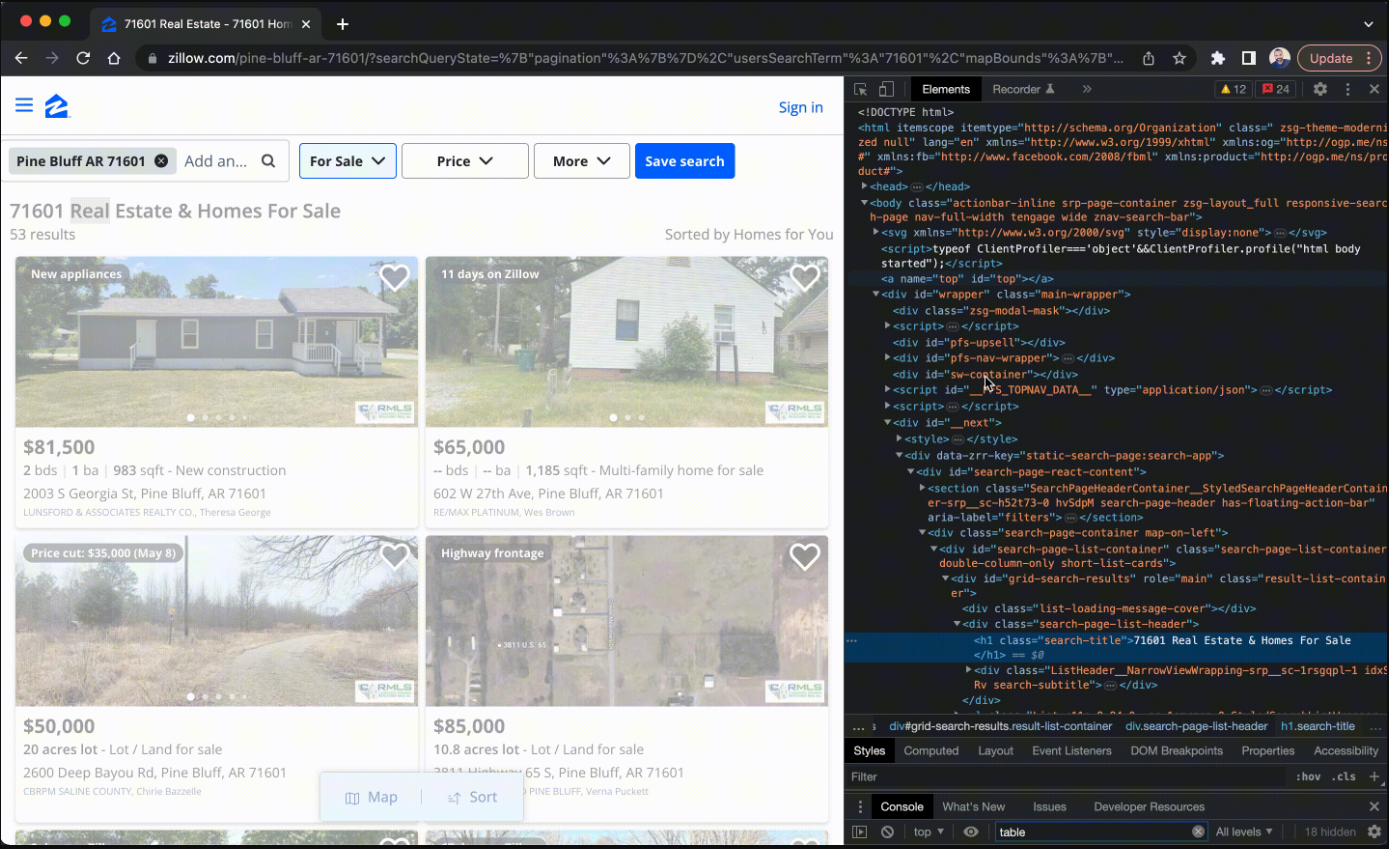
Comprender la estructura del sitio web de Zillow
Antes de empezar a extraer datos de Zillow, es importante comprender su estructura. Observe que la página de inicio de Zillow cuenta con una práctica barra de búsqueda que le permite buscar casas, apartamentos y diversas propiedades inmobiliarias. Una vez iniciada la búsqueda, los resultados se muestran en una página que presenta una lista de propiedades, que incluye sus precios, direcciones y otros detalles relevantes. Cabe mencionar que estos resultados de búsqueda se pueden ordenar en función de parámetros como el precio, el número de dormitorios y el número de baños.
Si desea obtener más resultados de búsqueda además de los que se muestran inicialmente, puede utilizar los botones de paginación situados en la parte inferior de la página. Cada página suele incluir cuarenta anuncios, lo que le permite acceder a propiedades adicionales. Aprovechando los filtros situados en la parte izquierda de la página, puede limitar su búsqueda en función de sus preferencias y requisitos.
Para comprender la estructura HTML del sitio web, debe seguir estos pasos:
- Visite el sitio web de Zillow: www.zillow.com.
- Introduzca una ciudad o un código postal en la barra de búsqueda y pulse Intro.
- Haga clic con el botón derecho del ratón en una ficha de propiedad y haga clic en «Inspeccionar» para abrir las herramientas de desarrollo del navegador.
- Analice la estructura HTML para identificar las etiquetas y los atributos que contienen los datos que desea extraer.
Identifique los puntos de datos clave
Para recopilar información de Zillow de forma eficaz, debe identificar el contenido exacto que desea extraer. Esta guía le mostrará cómo extraer información sobre una propiedad, incluidos los siguientes puntos de datos clave:
- Dirección: la ubicación de la propiedad, incluyendo la dirección, la ciudad y el estado.
- Precio: el precio de venta de la propiedad, que proporciona información sobre su valor actual de mercado.
- Zestimate: el valor de mercado estimado de la propiedad por Zillow. El Zestimate tiene en cuenta varios factores y proporciona una valoración aproximada basada en las tendencias del mercado y los datos de propiedades comparables.
- Dormitorios: el número de dormitorios de la propiedad.
- Baños: el número de baños de la propiedad.
- Superficie: La superficie total de la propiedad en pies cuadrados.
- Año de construcción: El año en que se construyó la propiedad.
- Tipo: El tipo de propiedad, que puede incluir opciones como casa, apartamento, condominio u otras clasificaciones relevantes.
Zillow le proporciona una amplia gama de información que le permite evaluar y comparar fácilmente diferentes anuncios, considerar las tendencias de precios en barrios específicos, evaluar el estado de la propiedad e identificar cualquier comodidad adicional. Además, al analizar los datos históricos y actuales del mercado, puede mantenerse al día de las tendencias y tomar decisiones estratégicas con respecto a la compra, venta o inversión en bienes raíces.
Crear el Scraper
Ahora que ha identificado lo que quiere extraer, es el momento de crear el Scraper. Aquí, utilizará la biblioteca Requests para realizar solicitudes HTTP a Zillow, Beautiful Soup para realizar el parseo del HTML y Python para extraer los datos.
Extraiga los datos
El primer paso es extraer los datos que busca. Cree un nuevo archivo llamado scraper.py y añada el siguiente código:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
resultado['precio'] = listado.find('span', {'data-test': 'property-card-price'}).get_text().strip()
lista_detalles = listado.find('ul', {'class': 'dmDolk'})
detalles = lista_detalles.find_all('li') si lista_detalles else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)
Este código realiza una solicitud HTTP GET a la página de resultados de búsqueda de Zillow y luego utiliza Beautiful Soup para realizar el parseo del HTML. Extrae los puntos de datos de cada propiedad y luego imprime todas las propiedades.
Ejecutar el Scraper
Para ejecutar el Scraper, debes proporcionarle una URL de una página de resultados de búsqueda de Zillow. La URL debe tener este formato: https://www.zillow.com/homes/for_sale/{ciudad-o-código-postal}_rb/, donde {ciudad-o-código-postal} se sustituye por el nombre de la ciudad o el código postal que deseas rastrear.
Por ejemplo, si desea recopilar información sobre las casas que se venden en San Francisco, la dirección web que debe utilizar es https://www.zillow.com/homes/for_sale/San-Francisco_rb/.
Después de introducir la URL del sitio web, es el momento de ejecutar el programa y comenzar a extraer datos. Asegúrate de guardar los cambios en scraper.py y ejecuta el siguiente comando en tu shell o terminal:
python3 Scraper.py
...salida...
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'dirección': '998 Union St, San Francisco, CA 94133', 'precio': '1 650 000 $', 'dormitorios': '2 dormitorios', 'baños': '1 baño', 'superficie': '1181 pies cuadrados', 'tipo': 'Piso en venta'}, {'dirección': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2 395 000 $', 'bedrooms': '7 dormitorios', 'bathrooms': '6 baños', 'sqft': '2300 pies cuadrados', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1 399 900 $', 'bedrooms': '3 dormitorios', 'bathrooms': '4 baños', 'sqft': '1764 pies cuadrados', 'type': 'Nueva construcción'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745 000 $', 'bedrooms': '2 dormitorios', 'bathrooms': '2 baños', 'sqft': '905 pies cuadrados', 'type': 'Piso en venta'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698 000 $', 'bedrooms': '4 dormitorios', 'bathrooms': '2 baños', 'sqft': '1535 pies cuadrados', 'type': 'Casa en venta'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475 791 $', 'bedrooms': '2 dormitorios', 'bathrooms': '2 baños', 'sqft': '1780 pies cuadrados', 'type': 'Casa adosada en venta'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '600 000 $', 'bedrooms': '3 dormitorios', 'bathrooms': '2 baños', 'sqft': '1011 pies cuadrados', 'type': 'Piso en venta'}]
Recuerde que el Scraping web debe respetar el archivo
robots.txty los términos de servicio del sitio web, y que un scraping excesivo puede provocar el bloqueo de su IP.
Guarde sus datos
Ahora que ha extraído sus datos, debe guardarlos en un archivo JSON o CSV. Guardar los datos en un archivo le permite procesarlos y crear análisis basados en lo que ha recopilado.
Para guardar los datos, comience importando las bibliotecas pandas y json en la parte superior de su archivo scraper.py:
import pandas as pd
import json
A continuación, añada el siguiente código al final del archivo:
#Escribir datos en un archivo Json
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Datos escritos en un archivo Json')
#Escribir datos en un archivo csv
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Datos escritos en un archivo CSV')
Este código escribe los datos de los listados, una lista de diccionarios, en un archivo JSON llamado listings.json, utilizando json.dump(). A continuación, crea un DataFrame de pandas a partir de los datos de los listados y los escribe en un archivo CSV llamado listings.csv utilizando el método to_csv(). El código imprime mensajes que indican que los datos se han escrito correctamente en los archivos JSON y CSV.
A continuación, ejecute el código desde su shell o terminal:
python3 Scraper.py
…salida…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'dirección': '998 Union St, San Francisco, CA 94133', 'precio': '1 650 000 $', 'dormitorios': '2 dormitorios', 'baños': '1 baño', 'superficie': '1181 pies cuadrados', 'tipo': 'Piso en venta'}, {'dirección': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2 395 000 $', 'bedrooms': '7 dormitorios', 'bathrooms': '6 baños', 'sqft': '2300 pies cuadrados', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1 399 900 $', 'bedrooms': '3 dormitorios', 'bathrooms': '4 baños', 'sqft': '1764 pies cuadrados', 'type': 'Nueva construcción'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745 000 $', 'bedrooms': '2 dormitorios', 'bathrooms': '2 baños', 'sqft': '905 pies cuadrados', 'type': 'Piso en venta'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698 000 $', 'bedrooms': '4 dormitorios', 'bathrooms': '2 baños', 'sqft': '1535 pies cuadrados', 'type': 'Casa en venta'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475 791 $', 'bedrooms': '2 dormitorios', 'bathrooms': '2 baños', 'sqft': '1780 pies cuadrados', 'type': 'Casa adosada en venta'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '600 000 $', 'bedrooms': '3 dormitorios', 'bathrooms': '2 baños', 'sqft': '1011 pies cuadrados', 'type': 'Piso en venta'}]
Datos escritos en el archivo Json
Datos escritos en el archivo CSV
Si funciona, debería encontrar dos archivos nuevos creados en el directorio de su proyecto: un archivo listings.csv y un archivo listings.json. Estos dos archivos deberían tener un contenido similar al de estos archivos del repositorio GitHub, respectivamente: listings.csv y listings.json.
Si intentas ejecutar el código varias veces, notarás una alta tasa de fallos (alrededor del 50 %). Esto se debe a que Zillow a veces devuelve una página CAPTCHA en lugar del contenido real cuando detecta un rastreo automatizado. Para lograr una mejor tasa de éxito al rastrear un sitio web como Zillow, necesitas utilizar herramientas que te ayuden a saltar entre diferentes IP y que puedan eludir el CAPTCHA.
Técnicas antirraspado empleadas por Zillow
Para evitar que la gente tome datos sin permiso, Zillow usa un montón de métodos diferentes para detener la copia automática de datos (también conocida como scraping) de su sitio web. Estos métodos incluyen el uso de CAPTCHAs, el bloqueo de direcciones IP y la configuración de trampas honeypot.
Un CAPTCHA es una prueba para determinar si un usuario es un ser humano o un programa informático. Por lo general, es fácil de resolver para los seres humanos, pero difícil para los programas, y puede ralentizar o incluso detener el scraping de datos.
Otra forma en que Zillow detiene el scraping es bloqueando direcciones IP. Las direcciones IP son como direcciones postales, pero para ordenadores. Si un ordenador realiza demasiadas solicitudes, lo que suele ocurrir con el scraping de datos, Zillow puede bloquear esa dirección IP para detener cualquier solicitud adicional. Estos bloqueos pueden ser a corto o largo plazo, dependiendo de la gravedad de la situación.
Zillow también utiliza trampas honeypot. Estas trampas son fragmentos de datos o enlaces que solo pueden ver los programas, no los humanos. Si un programa interactúa con una trampa honeypot, Zillow sabe que se trata de un bot y puede bloquearlo.
Todos estos métodos dificultan el scraping de datos de Zillow. Puede llevar mucho tiempo, ser difícil y, a veces, imposible. Cualquiera que quiera hacer scraping de datos de Zillow no solo necesita conocer estos métodos, sino que también debe comprender las cuestiones legales y morales relacionadas con el scraping de datos. Recuerde que Zillow podría cambiar la forma en que utiliza estos métodos y es posible que no lo comunique al público.
Una alternativa mejor: utilizar Bright Data para extraer datos de Zillow
Bright Data ofrece una alternativa mejor para extraer datos de Zillow, ya que elude las técnicas antiextracción empleadas por el sitio web conel Navegador de scraping de Bright Data. El Navegador de scraping le permite ejecutar scripts Puppeteer en la red de Bright Data, lo que proporciona acceso a millones de direcciones IP y evita la detección por parte de las técnicas antiextracción de Zillow.
Extraiga datos de Zillow utilizando el Navegador de scraping de Bright Data
Para extraer datos de Zillow utilizando el Navegador de scraping de Bright Data, siga estos pasos:
1. Cree una cuenta de Bright Data
Si aún no tiene una cuenta de Bright Data, visite el sitio web de Bright Data, haga clic en «Prueba gratuita» y siga las instrucciones.
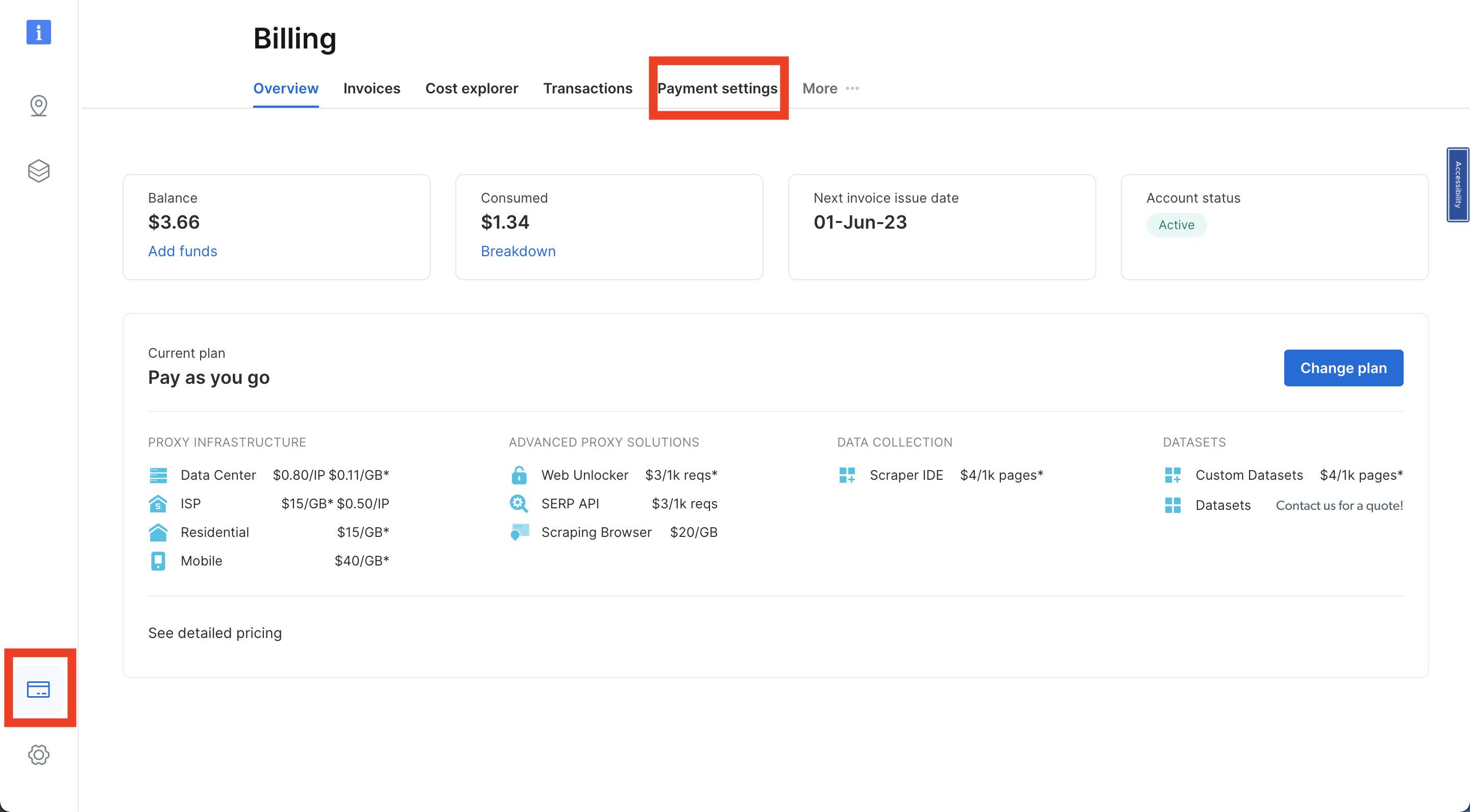
Una vez que haya iniciado sesión en su cuenta de Bright Data, vaya a «Facturación» haciendo clic en el icono de la tarjeta de crédito en la parte inferior izquierda de la barra de navegación. Añada un método de pago según su opción preferida; de lo contrario, no podrá activar su cuenta:
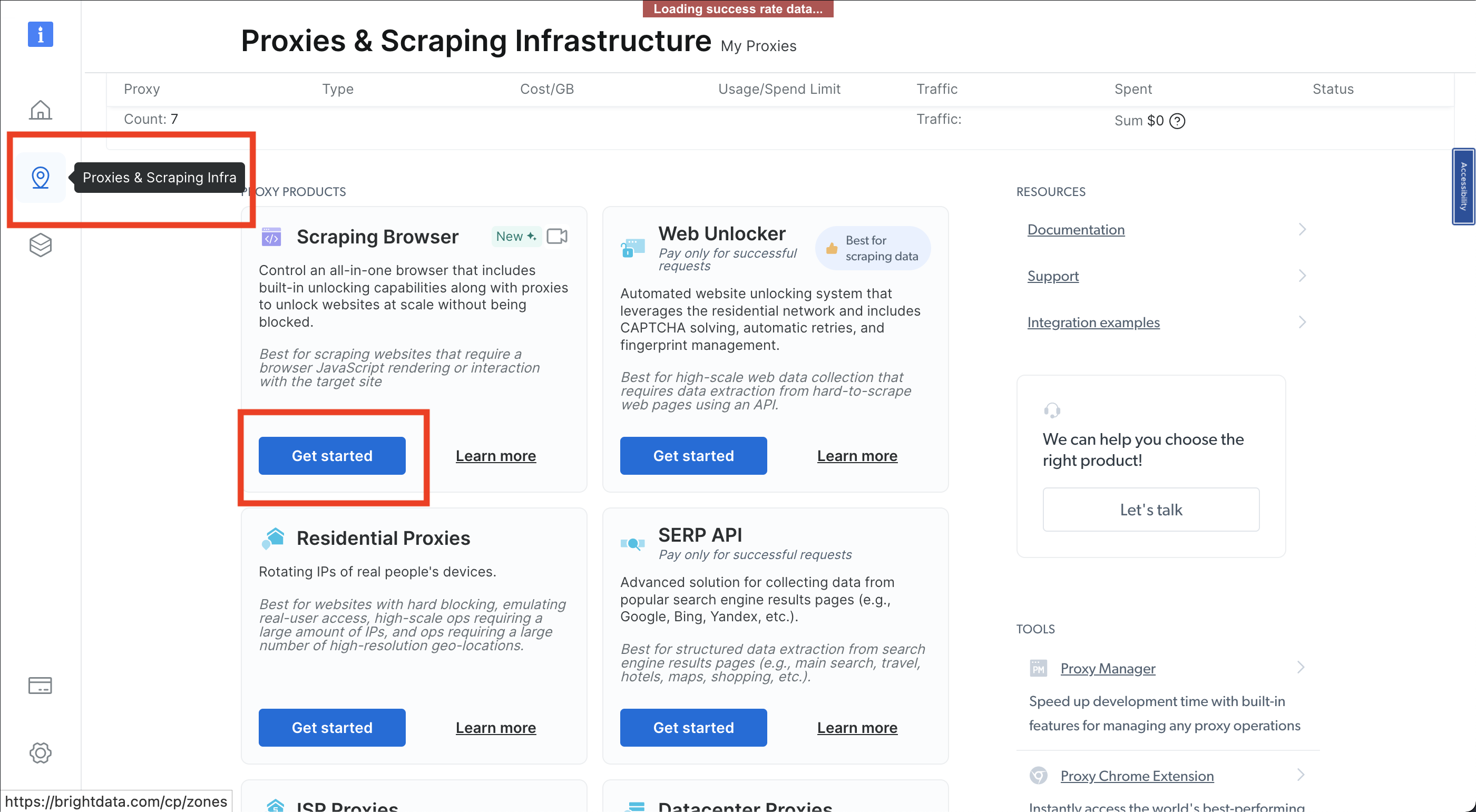
A continuación, haz clic en el icono del pin, que abre la página Proxies e infraestructura de scraping; luego selecciona Navegador de scraping > Empezar:
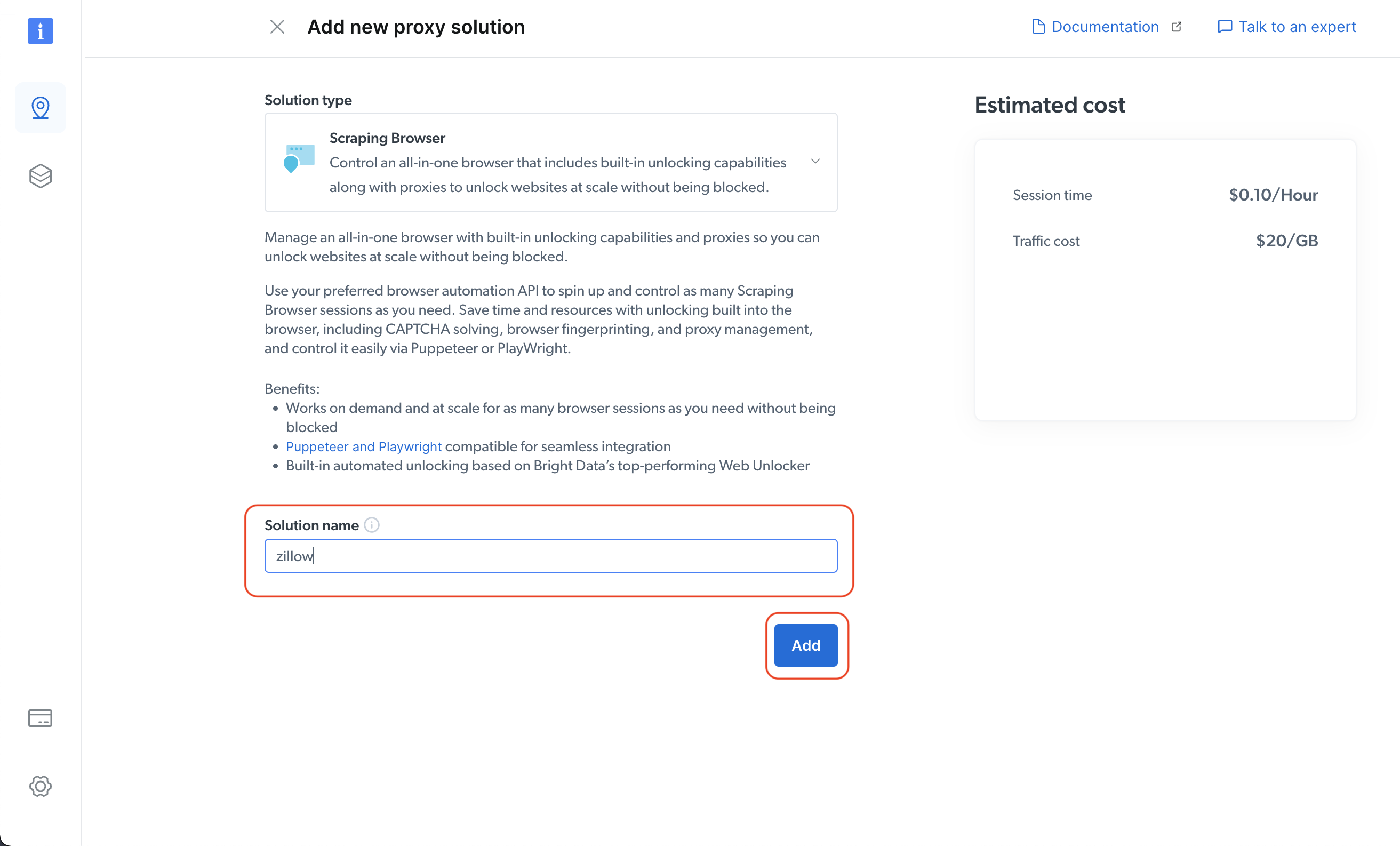
A continuación, especifique el nombre de su solución y haga clic en el botón «Añadir »:
A continuación, haga clic en «Parámetros de acceso» y anote su nombre de usuario, host y contraseña, ya que los necesitará más adelante en el tutorial:
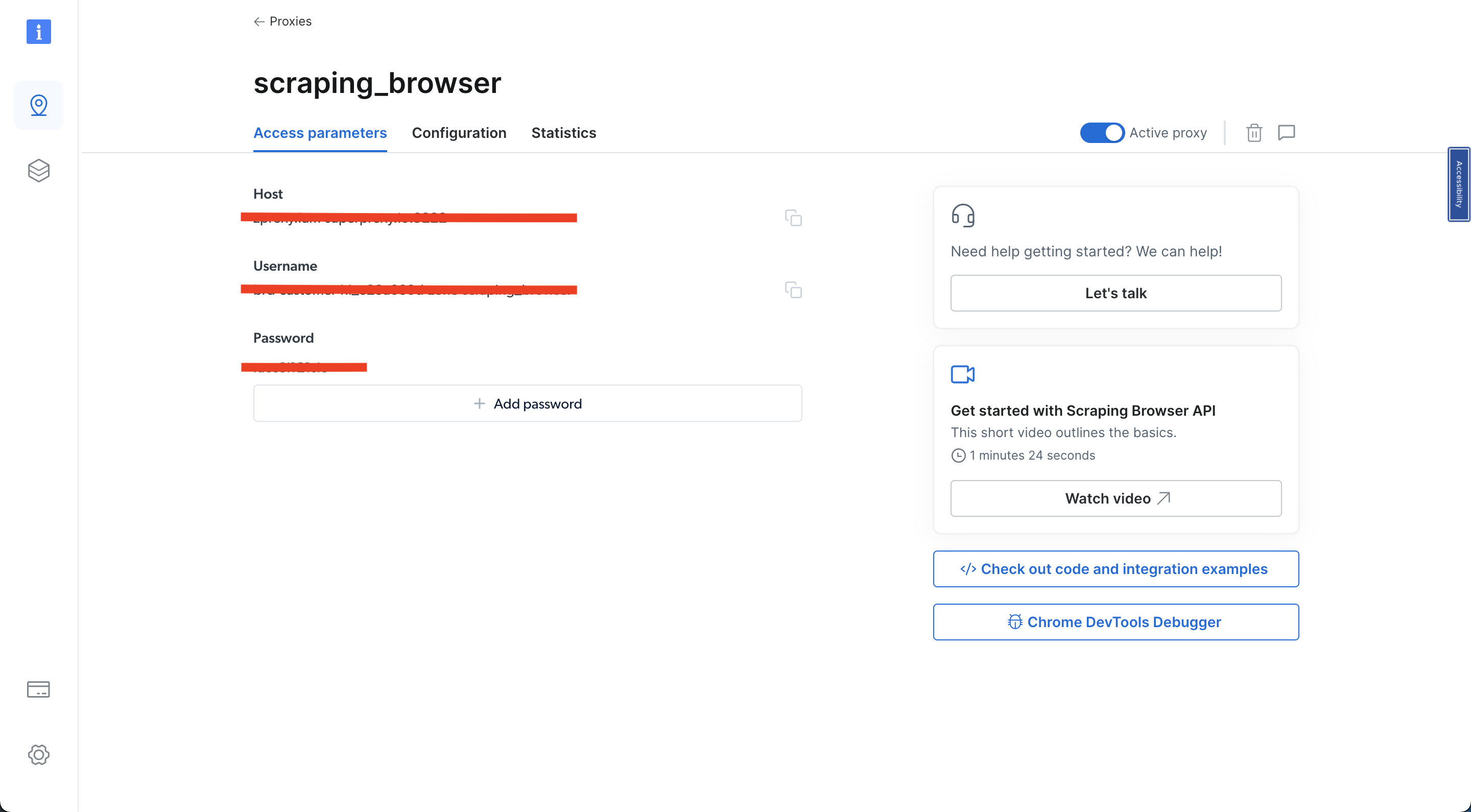
Una vez que haya completado los pasos anteriores, estará listo para continuar.
2. Escribir el Scraper
Cree un nuevo archivo llamado scraper-brightdata.py y añada el siguiente código:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='TU_NOMBRE_DE_USUARIO_BRIGHTDATA'
password='TU_CONTRASEÑA_BRIGHTDATA'
auth=f'{username}:{password}'
host = 'TU_HOST_DE_BRIGHTDATA'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('Conectando con un navegador remoto...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('Conectado. Abriendo nueva página...')
page = await browser.new_page()
print('Navegando a Zillow...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('Recopilando datos...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# Ejecutar la función asíncrona
listings = asyncio.run(main())
# Imprimir los listados
for listing in listings:
print(listing)
# Escribir datos en el archivo Json
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('Datos escritos en el archivo Json')
# Escribir datos en csv
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('Datos escritos en archivo CSV')
Asegúrese de sustituir YOUR_BRIGHTDATA_USERNAME, YOUR_BRIGHTDATA_PASSWORD y YOUR_BRIGHTDATA_HOST por las credenciales reales de su cuenta de Bright Data.
3. Ejecute el Scraper
Guarde los cambios en scraper-brightdata.py y ejecute el código desde su shell o terminal:
python3 scraper-brightdata.py
...salida...
Conectando con un navegador remoto...
Conectado. Abriendo nueva página...
Navegando a Zillow...
Raspando datos...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'dirección': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'precio': '1 195 000 $', 'dormitorios': '2 dormitorios', 'baños': '2 baños', 'metros cuadrados': '-- metros cuadrados', 'tipo': ''}
{'dirección': '455 27th Ave, San Francisco, CA 94121', 'precio': '1 375 000 $', 'dormitorios': '2 dormitorios', 'baños': '1 baño', 'superficie': '1040 pies cuadrados', 'tipo': 'Casa en venta'}
{'dirección': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'precio': '1 025 000 $', 'dormitorios': '1 dormitorio', 'baños': '1 baño', 'metros cuadrados': '956 m²', 'tipo': 'Piso en venta'}
{'dirección': '267A Chattanooga St, San Francisco, CA 94114', 'precio': '1 740 000 $', 'dormitorios': '2 dormitorios', 'baños': '3 baños', 'superficie': '2114 pies cuadrados', 'tipo': 'Piso en venta'}
{'dirección': '998 Union St, San Francisco, CA 94133', 'precio': '1 650 000 $', 'dormitorios': '2 dormitorios', 'baños': '1 baño', 'superficie': '1181 pies cuadrados', 'tipo': 'Piso en venta'}
{'dirección': '37-39 Mirabel Ave, San Francisco, CA 94110', 'precio': '2 395 000 $', 'dormitorios': '7 dormitorios', 'baños': '6 baños', 'superficie': '2300 pies cuadrados', 'tipo': 'Multifamiliar'}
{'dirección': '304 Yale St, San Francisco, CA 94134', 'precio': '1 399 900 $', 'dormitorios': '3 dormitorios', 'baños': '4 baños', 'superficie': '1764 pies cuadrados', 'tipo': 'Nueva construcción'}
{'dirección': '173 Coleridge St, San Francisco, CA 94110', 'precio': '745 000 $', 'dormitorios': '2 dormitorios', 'baños': '2 baños', 'superficie': '905 pies cuadrados', 'tipo': 'Piso en venta'}
Datos escritos en un archivo Json
Datos escritos en un archivo CSV
Este código se conecta al Navegador de scraping de Bright Data, navega a la página de resultados de búsqueda de Zillow y extrae los datos. A continuación, el código imprime los resultados y los escribe en los datos de los listados, una lista de diccionarios, en un archivo JSON llamado listings-brightdata.json, utilizando json.dump(). A continuación, crea un DataFrame de pandas a partir de los datos de los listados y los escribe en un archivo CSV llamado listings-brightdata.csv utilizando el método to_csv(). El código imprime mensajes que indican que los datos se han escrito correctamente en los archivos JSON y CSV.
Si funciona, debería encontrar dos archivos: un archivo listings-brightdata.csv y un archivo listings-brightdata.json. Estos archivos deberían ser similares a listings-brightdata.json y listings-brightdata.csv.
Si intentas ejecutar este código varias veces y observas que no tienes ningún dato guardado en tus archivos, significa que tu IP ha sido bloqueada por Zillow o que el navegador se ha cerrado antes de terminar. Si el navegador se cerró antes de que finalizara el rastreo, debes cambiar el tiempo de espera a un valor mayor, que, en el código anterior, está relacionado con await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000).
Si Zillow ha bloqueado tu IP, debes cambiar de zona y, afortunadamente, Bright Data te da acceso a varias zonas.
Para cambiar entre diferentes zonas, vaya a Proxies e infraestructura de scraping haciendo clic en el icono del pin, luego seleccione Navegador de scraping y haga clic en Parámetros de acceso. A continuación, haga clic en </> Consulte el código y los ejemplos de integración:
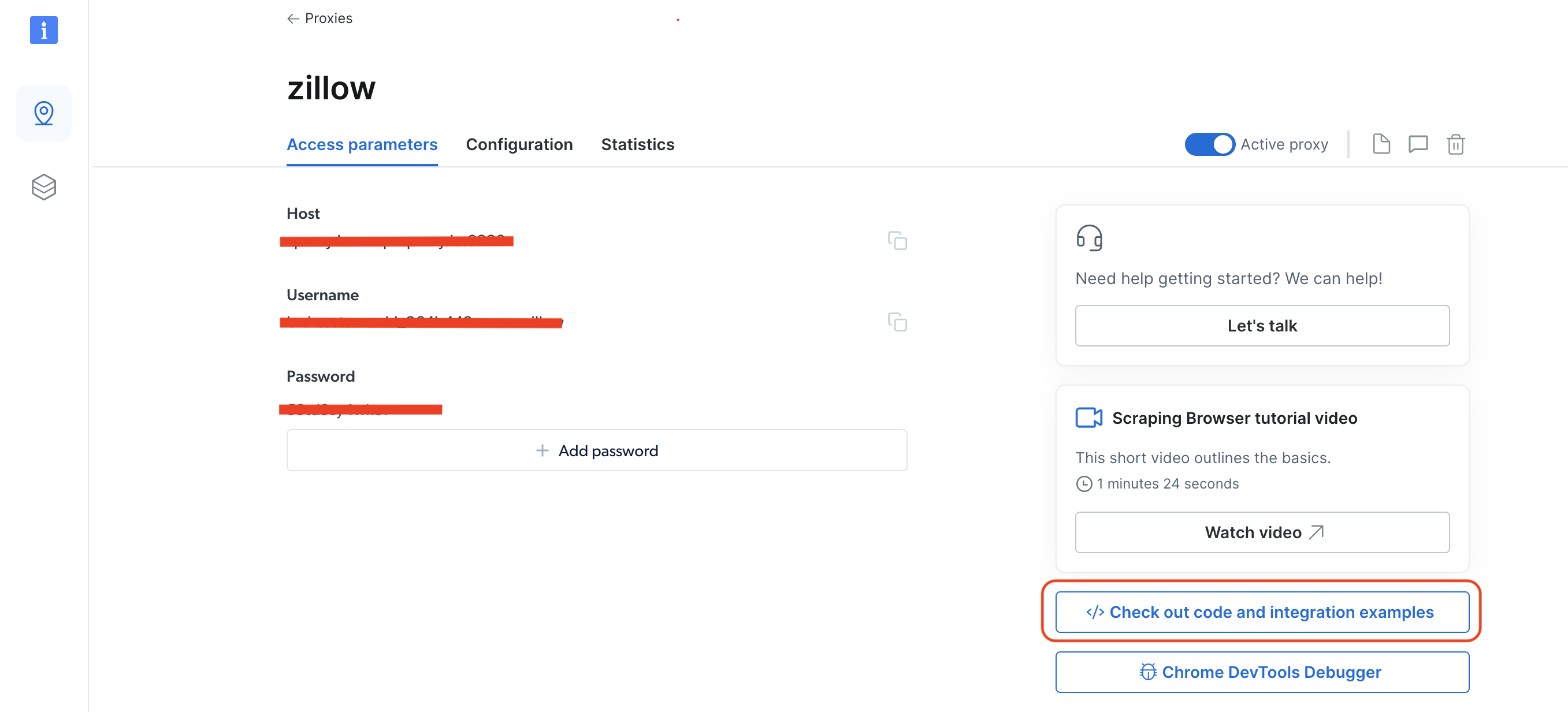
Seleccione Python como idioma y, en la navegación de la derecha, verá una lista desplegable País. Seleccione el país que desee y su zona se actualizará simultáneamente. Debería ver que la variable auth cambia en el código de ejemplo de Python. Debe obtener el usuario relacionado con esa zona de la variable auth. Básicamente, es el valor que aparece antes de :, ya que la variable auth contiene el nombre de usuario y la contraseña con la siguiente sintaxis username:password:
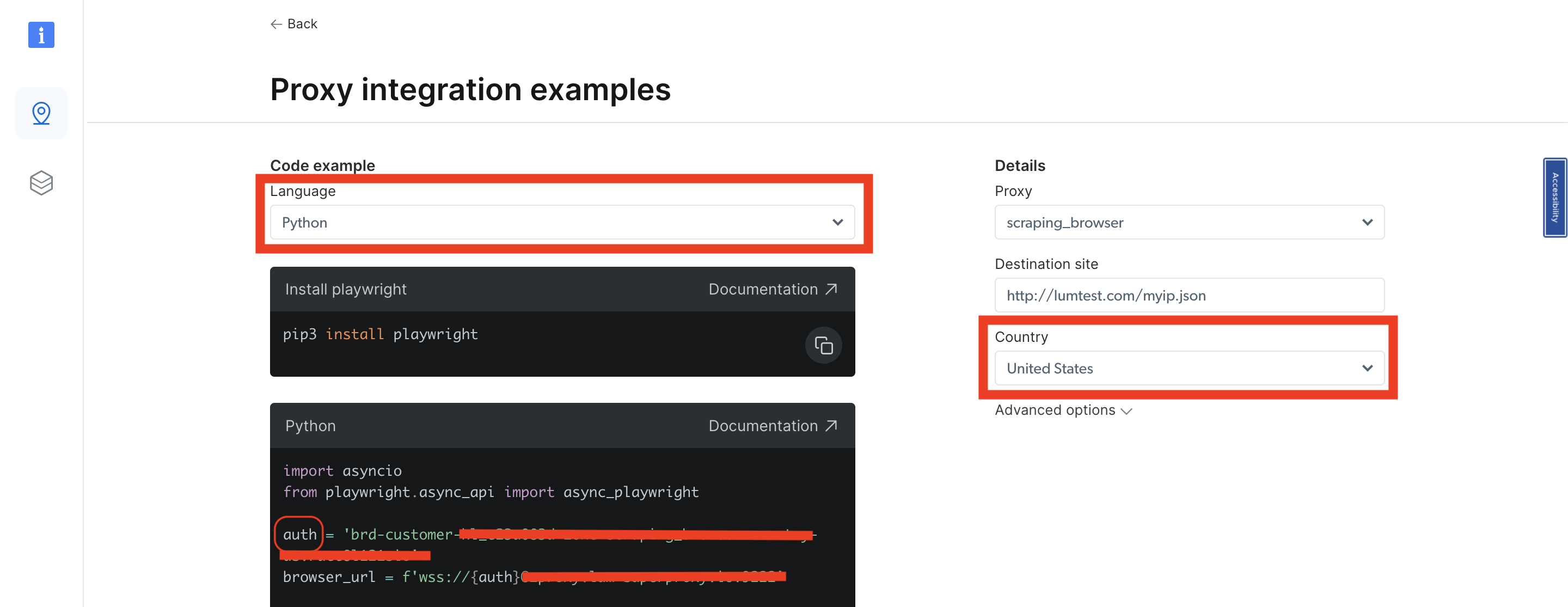
Cada vez que cambie de país, obtendrá un usuario diferente para ese país/zona específicos. Basándose en el nombre de usuario que obtenga y el país que seleccione, tome el usuario, introdúzcalo en su código y vuelva a ejecutarlo.
Conclusión
En este tutorial, ha aprendido a extraer datos de Zillow utilizando Beautiful Soup. También ha aprendido qué
las técnicas antirraspado que emplea Zillow y cómo eludirlas. Para abordar estos problemas, se introdujo el Navegador de scraping de Bright Data, que le ayuda a superar los mecanismos antirraspado de Zillow y a extraer sin problemas los datos deseados.
Además del Navegador de scraping, la API Zillow Scraper de Bright Data proporciona un acceso fluido a los datos completos de Zillow, eludiendo las medidas antiscraping por usted.
Nota: esta guía ha sido probada exhaustivamente por nuestro equipo en el momento de su redacción, pero dado que los sitios web actualizan con frecuencia su código y estructura, es posible que algunos pasos ya no funcionen como se esperaba.






