

En esta guía aprenderá:
- Qué es un Scraper de ZoomInfo y cómo funciona
- Los tipos de datos que puede extraer automáticamente de ZoomInfo
- Cómo crear un script de scraping de ZoomInfo utilizando Python
- Cuándo y por qué puede ser necesaria una solución más avanzada
¡Empecemos!
¿Qué es un Scraper de ZoomInfo?
Un scraper de ZoomInfo es una herramienta para extraer datos de ZoomInfo, una plataforma líder que ofrece información detallada sobre empresas y profesionales. Esta solución automatiza el proceso de scraping, lo que le permite recopilar una gran cantidad de datos. El scraper se basa en técnicas como la automatización del navegador para navegar por el sitio y recuperar contenido.
Datos que puede recuperar de ZoomInfo
Estos son algunos de los datos más importantes que puede extraer de ZoomInfo:
- Información de la empresa: nombres, sectores, ingresos, sedes y número de empleados.
- Detalles de los empleados: nombres, cargos, correos electrónicos y números de teléfono.
- Información sobre el sector: competidores, tendencias del mercado y jerarquías de las empresas.
Extracción de datos de ZoomInfo en Python: guía paso a paso
En esta sección, aprenderás a crear un Scraper de ZoomInfo.
El objetivo es guiarte en la creación de un script de Python que recopile automáticamente datos de lapágina de la empresa NVIDIA en ZoomInfo.
¡Siga los pasos que se indican a continuación!
Paso n.º 1: Configuración del proyecto
Antes de empezar, asegúrate de tener Python 3 instalado en tu equipo. Si no es así, descárgalo e instálalo siguiendo las instrucciones del asistente.
Ahora, utiliza el siguiente comando para crear una carpeta para tu proyecto:
mkdir zoominfo-scraper
El directorio zoominfo-scraper representa la carpeta del proyecto de su rastreador Python ZoomInfo.
Acceda a él e inicialice un entorno virtual dentro de él:
cd zoominfo-Scraper
python -m venv env
Cargue la carpeta del proyecto en su IDE de Python favorito. Visual Studio Code con la extensión Python o PyCharm Community Edition serán suficientes.
Cree un archivo scraper.py en la carpeta del proyecto, que debe contener la siguiente estructura de archivos:

En este momento, scraper.py es un script Python en blanco. Pronto contendrá la lógica de scraping deseada.
En la terminal del IDE, activa el entorno virtual. En Linux o macOS, ejecuta este comando:
./env/bin/activate
De forma equivalente, en Windows, ejecuta:
env/Scripts/activate
¡Genial, ahora tienes un entorno Python para el Scraping web!
Paso n.º 2: Selecciona la biblioteca de scraping
Antes de sumergirte en la programación, debes comprender qué herramientas son las más adecuadas para alcanzar el objetivo. Para ello, primero debes realizar una prueba preliminar para estudiar el sitio de destino. A continuación te explicamos cómo hacerlo:
- Abre la página de destino en modo incógnito en tu navegador. Esto evita que las cookies y preferencias almacenadas previamente afecten a tu análisis.
- Haz clic con el botón derecho en cualquier lugar de la página y selecciona «Inspeccionar» para abrir las herramientas de desarrollo del navegador.
- Ve a la pestaña «Red».
- Vuelva a cargar la página y examine la actividad en la pestaña «Obtener/XHR».
Esto le dará una idea de cómo se comporta la página web en el momento de la representación:
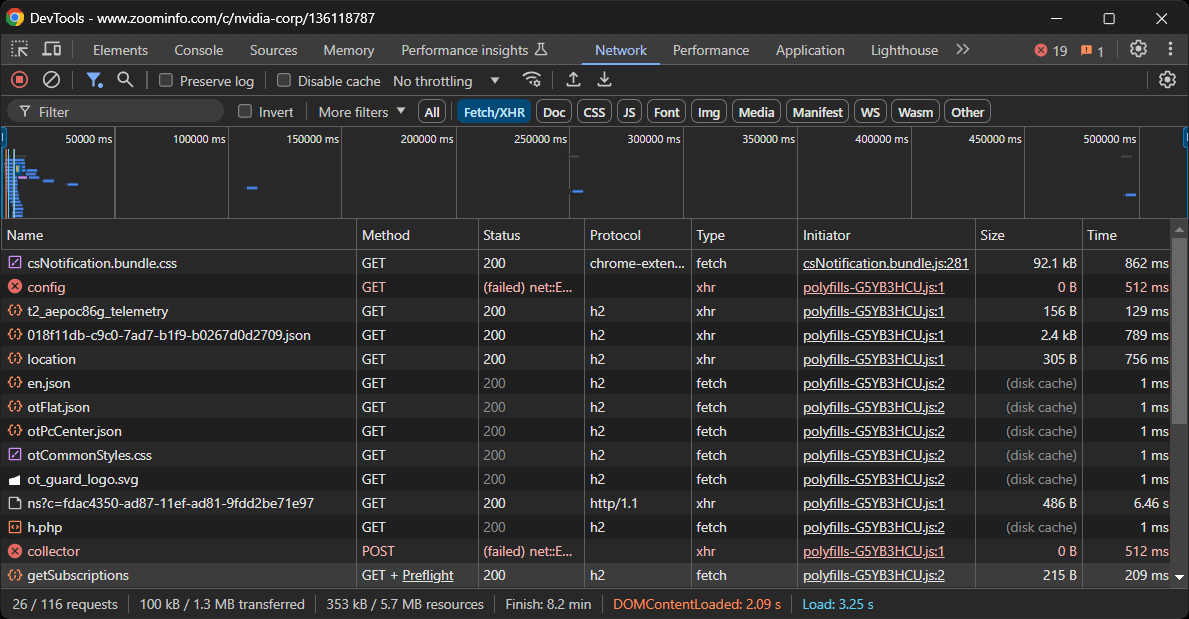
En esta sección, puede ver todas las solicitudes AJAX dinámicas realizadas por la página. Inspeccione cada solicitud y observará que ninguna de ellas contiene datos relevantes. Esto indica que la mayor parte de la información de la página ya está incrustada en el documento HTML devuelto por el servidor.
Los resultados le llevarán naturalmente a adoptar un cliente HTTP y un analizador HTML para extraer datos de ZoomInfo. Sin embargo, el sitio utiliza estrictas tecnologías antibots que pueden bloquear la mayoría de las solicitudes automatizadas que no provienen de un navegador. La forma más sencilla de evitarlo es utilizando una herramienta de automatización del navegador como Selenium.
Selenium le permite controlar un navegador web mediante programación, indicándole que realice acciones específicas en páginas web como lo harían los usuarios reales. ¡Es hora de instalarlo y empezar a utilizarlo!
Paso n.º 3: Instalar y configurar Selenium
En Python, Selenium está disponible a través del paquete pip selenium. En un entorno virtual Python activado, instálalo con este comando:
pip install -U selenium
Para obtener orientación sobre cómo utilizar la herramienta, sigue nuestro tutorial sobre Scraping web con Selenium.
Importe Selenium en scraper.py e inicialice un objeto WebDriver para controlar una instancia de Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
El código anterior crea una instancia de WebDriver para operar en Chrome. Ten en cuenta que ZoomInfo utiliza tecnología anti-scraping que bloquea los navegadores sin interfaz gráfica. Por lo tanto, no puedes establecer el indicador --headless. Como solución alternativa, considera explorar Playwright Stealth.
Como última línea de su Scraper, recuerde cerrar el controlador web:
driver.quit()
¡Genial! Ya tiene todo configurado para empezar a extraer datos de ZoomInfo.
Paso n.º 4: Conéctese a la página de destino
Utilice el método get() de un objeto Selenium WebDriver para indicar al navegador que visite la página deseada:
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
Tu archivo scraper.py debería contener ahora estas líneas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# conectarse a la página de destino
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# lógica de scraping...
# cerrar el navegador
driver.quit()
Coloca un punto de interrupción de depuración en la última línea y ejecuta el script. Debería llevarte a la página de la empresa NVIDIA.
El mensaje «Chrome está siendo controlado por un software de pruebas automatizado» certifica que Selenium está controlando Chrome como se esperaba. ¡Bien hecho!
Paso n.º 5: extraiga la información general de la empresa
Debe analizar la estructura DOM de la página para comprender cómo extraer los datos necesarios. El objetivo es identificar los elementos HTML que contienen los datos deseados. Comience por inspeccionar los elementos de la sección superior de la sección de información de la empresa:
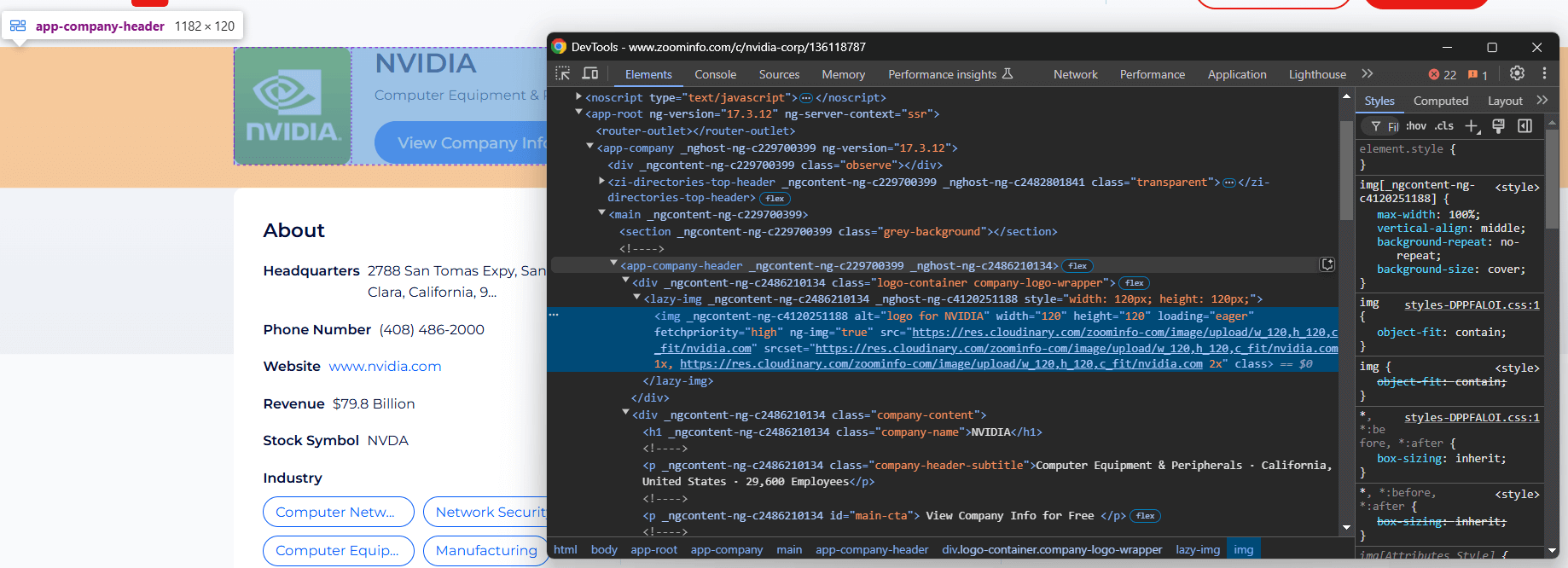
El elemento <app-company-header> contiene:
- La imagen de la empresa en una etiqueta
<img>dentro de un<div>con la clasecompany-logo-wrapper. - El nombre de la empresa dentro de un nodo con la clase
company-name. - El subtítulo de la empresa almacenado en un nodo con la clase
company-header-subtitle.
Utilice Selenium para localizar estos elementos y recopilar datos de ellos:
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
Para que el código funcione, no olvides importar By:
from selenium.webdriver.common.by import By
Ten en cuenta que el método find_element() selecciona un nodo utilizando la estrategia de selección de nodos especificada. Arriba, hemos utilizado selectores CSS. Obtén más información sobre la diferencia entre los selectores XPath y CSS.
A continuación, puede acceder al contenido del nodo con el atributo de texto. Para acceder a un atributo, utilice el método get_attribute().
Imprima los datos extraídos:
print(logo_url)
print(name)
print(subtitle)
Esto es lo que obtendría:
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
Equipos informáticos y periféricos · California, Estados Unidos · 29 600 empleados
¡Vaya! El Scraper de ZoomInfo funciona de maravilla.
Paso n.º 6: extraer la información «Acerca de»
Céntrate en la sección «Acerca de» de la página de la empresa:
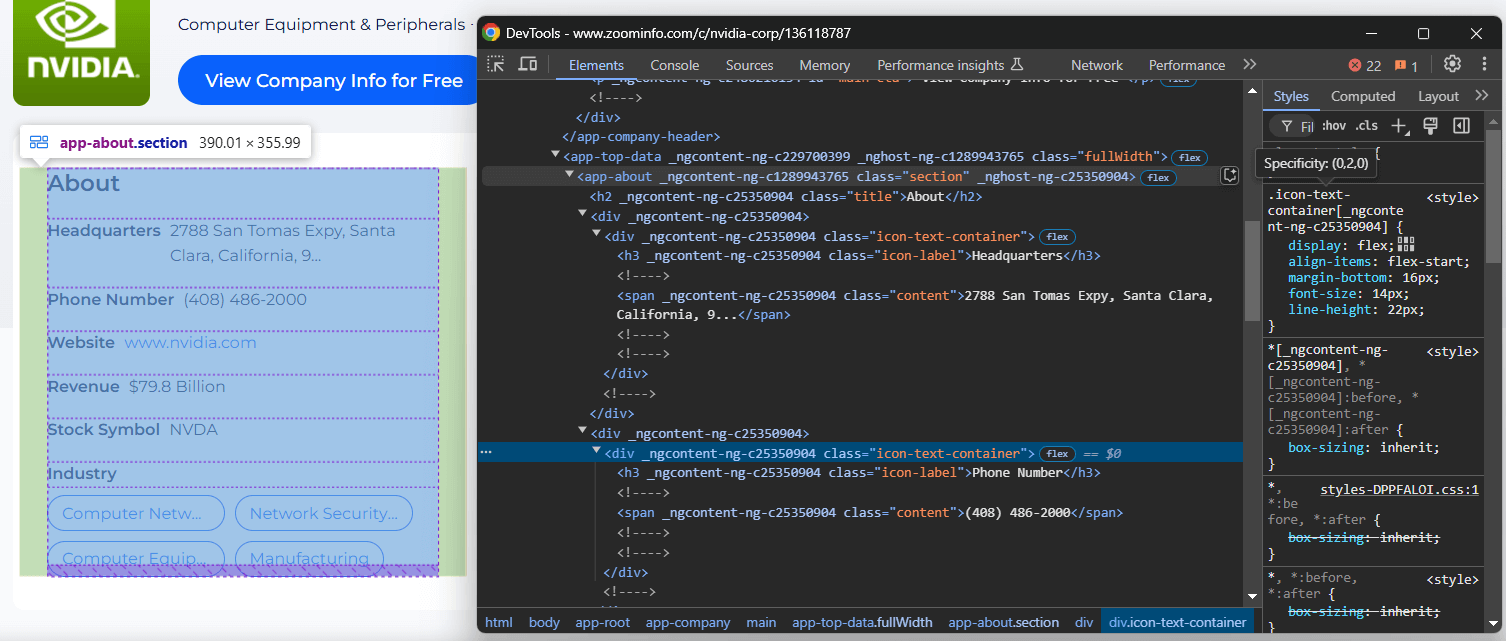
El nodo <app-about> contiene elementos con clases genéricas y atributos que parecen generados aleatoriamente. Dado que estos atributos pueden cambiar con cada compilación, debes evitar basarte en ellos para seleccionar los elementos que vas a extraer.
Para extraer la información de esta sección, empieza por seleccionar el nodo <app-about>:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
Ahora, céntrese en todos los elementos .icon-text-container dentro de <app-about>. A continuación, inspeccione sus etiquetas (.icon-label) para identificar los elementos específicos de interés. Si la etiqueta coincide, extraiga los datos del elemento .content. Encapsule esta lógica en una función:
def scrape_about_node(text_container_elements, text_label):
# iterar a través de ellos para extraer datos de los
# nodos específicos de interés
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# selecciona el elemento de contenido y extrae los datos de él
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
A continuación, puede extraer la información de «Acerca de» con:
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
A continuación, seleccione las etiquetas de sector y empresa.
Seleccione el sector de la empresa con h3 .incon-label y las etiquetas con zi-directories-chips a. Extraiga los datos de ellos con:
elemento_sector = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
sector = elemento_sector.texto
elementos_etiqueta = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
etiquetas = [elemento_etiqueta.texto para elemento_etiqueta en elementos_etiqueta]
¡Increíble! La lógica de extracción de datos de ZoomInfo está completa.
Paso n.º 7: recopilar los datos extraídos
Actualmente, los datos extraídos se encuentran repartidos en varias variables. Rellene un nuevo objeto de empresa con esos datos:
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
Imprima los datos extraídos para asegurarse de que contienen la información deseada
print(items)
Esto producirá el siguiente resultado:
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Equipos y periféricos informáticos · California, Estados Unidos · 29 600 empleados', 'headquarters': '2788 San Tomas Expy, Santa Clara, California, 95051, Estados Unidos', 'phone_number': '(408) 486-2000', 'ingresos': '79 800 millones de dólares', 'símbolo bursátil': 'NVDA', 'sector': 'Sede central', 'etiquetas': ['Equipos de redes informáticas', 'Hardware y software de seguridad de redes', 'Equipos informáticos y periféricos', 'Fabricación']}
¡Fantástico! Solo queda exportar esta información a un archivo legible para humanos, como JSON.
Paso n.º 8: Exportar a JSON
Exporta la empresa a un archivo company.json con:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
En primer lugar, open() crea un archivo de salida company.json. A continuación, json.dump() transforma company en su representación JSON y lo escribe en el archivo de salida.
Recuerde importar json desde la biblioteca estándar de Python:
import json
Paso n.º 9: Ponlo todo junto
A continuación se muestra el archivo scraper.py final:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# iterar a través de ellos para extraer datos de los
# nodos específicos de interés
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# selecciona el elemento de contenido y extrae los datos de él
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# conectarse a la página de destino
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# extraer la información de la empresa
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# extraer datos de la sección «Acerca de»
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
text_container_elements = about_element.find_elements(By.CSS_SELECTOR, ".icon-text-container")
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
# extraer el sector y las etiquetas de la empresa
elemento_sector = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
sector = elemento_sector.text
elementos_etiqueta = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
etiquetas = [etiqueta_elemento.texto para etiqueta_elemento en etiquetas]
# recopilar los datos extraídos
empresa = {
"url_logotipo": url_logotipo,
"nombre": nombre,
"subtítulo": subtítulo,
"sede": sede,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# exportar los datos extraídos a JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# cerrar el navegador
driver.quit()
¡Con poco más de 70 líneas de código, acabas de crear un script de extracción de datos de ZoomInfo en Python!
Ejecuta el Scraper con el siguiente comando:
python3 script.py
O, en Windows:
python script.py
Aparecerá un archivo company.json en la carpeta de tu proyecto. Ábrelo y verás:
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Equipos informáticos y periféricos · California, Estados Unidos · 29 600 empleados»,
«headquarters»: «2788 San Tomas Expy, Santa Clara, California, 95051, Estados Unidos»,
«phone_number»: «(408) 486-2000»,
«revenue»: «79 800 millones de dólares»,
"stock_symbol": "NVDA",
"industry": "Sede central",
"tags": [
"Equipos de redes informáticas",
"Hardware y software de seguridad de redes",
"Equipos informáticos y periféricos",
"Fabricación"
]
}¡Enhorabuena, misión completada!
Desbloquea los datos de ZoomInfo con facilidad
ZoomInfo ofrece mucho más que simples descripciones generales de empresas: proporciona una gran cantidad de información útil. El problema es que extraer esos datos puede resultar bastante complicado, ya que la mayoría de las páginas del dominio ZoomInfo están protegidas por medidas antibots.
Si intentas acceder a estas páginas utilizando Selenium u otras herramientas de automatización del navegador, es probable que te encuentres con una página CAPTCHA que bloquee tus intentos.
Como primer paso, considere seguir nuestra guía sobre cómo evitar los CAPTCHA en Python. Sin embargo, es posible que siga encontrando errores 429 «Demasiadas solicitudes» debido a la estricta limitación de velocidad del sitio. En tales casos, podría integrar un Proxy en Selenium para rotar su IP de salida.
Estos problemas resumen cómo el scraping de ZoomInfo sin las herramientas adecuadas puede convertirse rápidamente en un proceso frustrante. Además, el hecho de que no se puedan utilizar navegadores sin interfaz hace que el script de scraping sea lento y consuma muchos recursos.
¿La solución? Utilizar la API dedicada ZoomInfo Scraper de Bright Data para recuperar datos del sitio de destino mediante simples llamadas a la API y sin ser bloqueado.
Conclusión
En este tutorial paso a paso, ha aprendido qué es un Scraper de ZoomInfo y los tipos de datos que puede recuperar. También ha creado un script en Python para extraer datos generales de empresas de ZoomInfo, lo que ha requerido menos de 100 líneas de código.
El reto es que ZoomInfo emplea estrictas medidas anti-bot, incluyendo CAPTCHAs, huellas digitales del navegador y prohibiciones de IP, para bloquear los scripts automatizados. Olvídate de todos esos retos con nuestra API ZoomInfo Scraper.
Si el Scraping web no es lo tuyo, pero sigues interesado en los datos de empresas o empleados, ¡explora nuestros Conjuntos de datos de ZoomInfo!
Crea hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos.





