

Existen todo tipo de excelentesherramientas de parseo. En Python, lasopcionesson casi ilimitadas. Sin embargo, con Go, no hay mucho donde elegir.
Go es un lenguaje excelente para el rendimiento y la gestión de la memoria, pero nuestras bibliotecas de parseo son bastante limitadas. Node Parser y Tokenizer son dos opciones que podemos utilizar de la biblioteca estándar de Go. Si no estás familiarizado con el funcionamiento del Scraping web, echa un vistazo aesta guía. Síguenos y aprende cuándo utilizar estas herramientas o cuándo elegir una biblioteca de terceros para obtener una solución de Scraping web más completa.
Requisitos previos
Es útil tener conocimientos básicos de Go y del Scraping web, pero no es imprescindible. Si estás familiarizado con Go pero te gustaría conocer el proceso de Scraping web, echa un vistazo aesta guía.
Para empezar, debes asegurarte de que tienes Go instalado en tu equipo. Puedes encontrar la última versiónaquí. Descarga la última versión para tu sistema y ¡manos a la obra!
Crea una nueva carpeta de proyecto y entra en ella.
mkdir goparser
cd goparser
Inicializa un nuevo proyecto Go.
go mod init goparser
Prueba de la configuración
Continúe y pegue el siguiente código en un nuevo archivo, main.go.
package main
import "fmt"
func main() {
fmt.Println("¡Hola, mundo!")
}
Puede ejecutar el archivo con el siguiente comando.
go run main.go
Si todo funciona correctamente, debería obtener el siguiente resultado.
¡Hola, mundo!
Instala nuestra única dependencia.
go get golang.org/x/net/html
Examinando la página
Quotes to Scrapees un sitio creado específicamente con el propósito de extraer tutoriales. En este tutorial, vamos a extraer cada cita y su autor de la página.
Para comprender mejor el objeto de la cita, echa un vistazo a la captura de pantalla siguiente. Cada cita es un span y su clase es text.
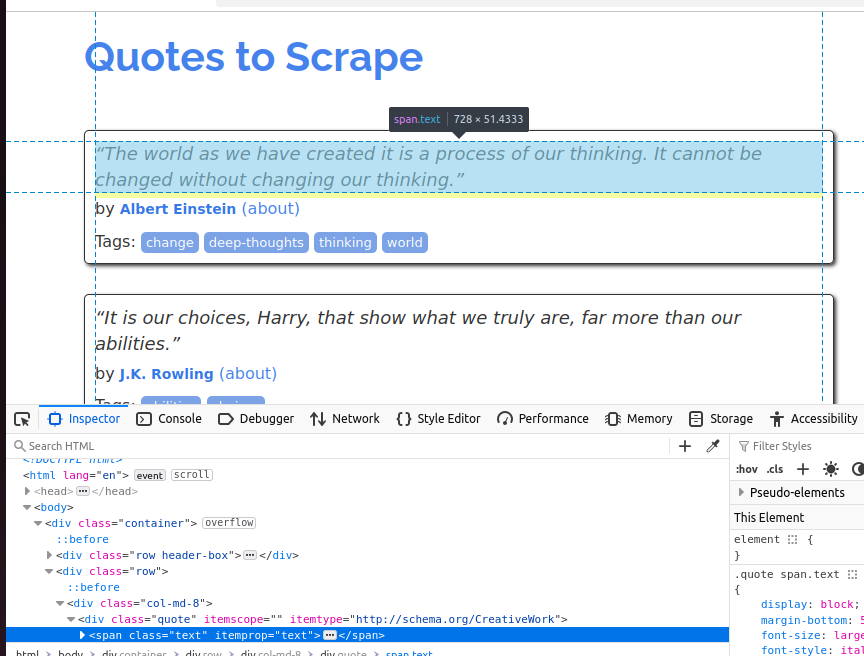
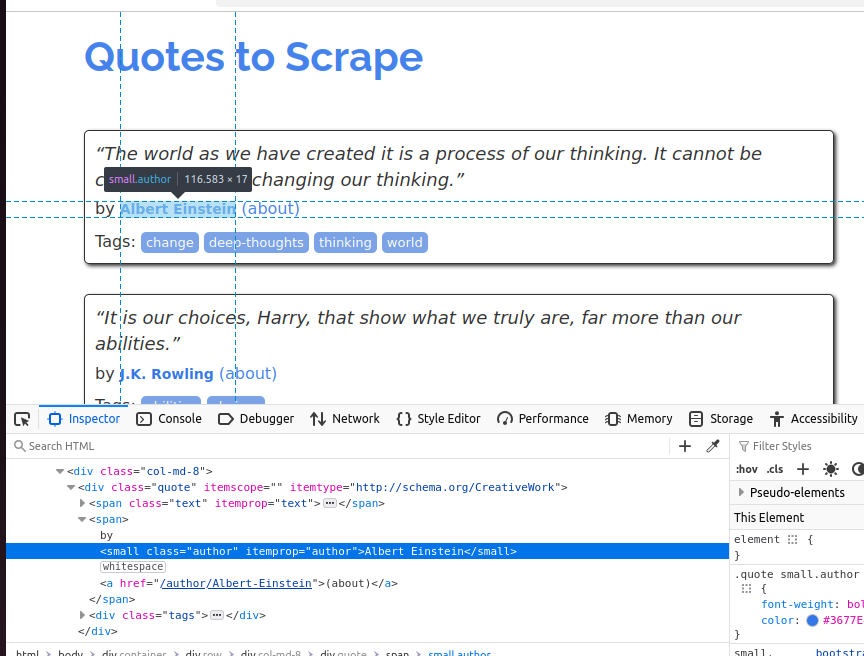
En la siguiente captura de pantalla, inspeccionamos el autor. Es un elemento pequeño y su clase es author.
Tanto nuestro analizador de nodos como nuestro tokenizador producirán el mismo resultado que se muestra a continuación.
Cita: «El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestra forma de pensar».
Autor: Albert Einstein
Cita: «Son nuestras elecciones, Harry, las que muestran lo que realmente somos, mucho más que nuestras habilidades».
Autor: J. K. Rowling
Cita: «Solo hay dos formas de vivir la vida. Una es como si nada fuera un milagro. La otra es como si todo fuera un milagro».
Autor: Albert Einstein.
Cita: «La persona, ya sea caballero o dama, que no disfruta de una buena novela, debe ser intolerablemente estúpida».
Autora: Jane Austen.
Cita: «La imperfección es belleza, la locura es genio y es mejor ser absolutamente ridículo que absolutamente aburrido».
Autora: Marilyn Monroe.
Cita: «Intenta no convertirte en un hombre de éxito. Más bien, conviértete en un hombre de valor».
Autor: Albert Einstein.
Cita: «Es mejor ser odiado por lo que eres que ser amado por lo que no eres».
Autor: André Gide.
Cita: «No he fracasado. Solo he encontrado 10 000 formas que no funcionan».
Autor: Thomas A. Edison
Cita: «Una mujer es como una bolsita de té: nunca sabes lo fuerte que es hasta que la sumerges en agua caliente».
Autora: Eleanor Roosevelt
Cita: «Un día sin sol es como, ya sabes, la noche».
Autor: Steve Martin
Extracción de datos con Node Parser
Node Parser de Go nos permite recorrer el DOM (modelo de objetos de documento) y manipularlo de forma recursiva. Cuando utilizamos Node Parser, este convierte toda la página HTML en una estructura en forma de árbol de objetos Node que podemos analizar sobre la marcha.
En el código siguiente, creamos una función recursiva: processNode(). Toma un puntero a un nodo HTML. Si el nodo es un span y su clase es texto, imprimimos la cita en la consola. Si el nodo es un elemento pequeño y su clase es autor, imprimimos el autor en la consola. Estos son los mismos atributos que descubrimos anteriormente al inspeccionar la página.
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parseo(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
La API Node Parser es ideal cuando necesitas procesar todo el documento. Para optimizar el uso de la memoria, podemos utilizar un puntero al documento real y procesar nuestros datos a medida que lo recorremos.
Extracción de datos con Tokenizer
Tokenizer procesa la página de forma ligeramente diferente. html.NewTokenizer(resp.Body) se utiliza para crear un objeto tokenizer a partir del cuerpo de nuestra respuesta. A continuación, elegimos qué tokens (etiquetas HTML, contenido de texto o atributos) queremos extraer de la página.
Al procesar cada token, tenemos dos objetos booleanos: inQuote e inAuthor. Si el token está dentro de una cita o un autor, lo recortamos e imprimimos sus datos en la consola. Aunque el resultado de este código es el mismo, en realidad funciona de forma muy diferente. Con Node Parser, procesamos nuestros datos nodo a nodo a medida que avanzamos por el árbol. Con tokenizer, los procesamos por fragmentos.
En el código siguiente, especificamos dos tokens de inicio: span y small. Si nuestro fragmento es un elemento span y su clase es texto, lo imprimimos en la consola. Si nuestro fragmento es un small y su clase es autor, también lo imprimimos en la consola. Todos los demás tokens (etiquetas HTML) de la página se ignoran por completo.
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Cita:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Autor:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
Tokenizer es un poco más básico que Node Parser, pero también es mucho más eficiente. Solo necesitamos procesar los tokens relevantes (etiquetas HTML) en lugar de recorrer todo el documento. Esto es ideal para procesar grandes cantidades de datos procedentes de flujos de datos. Con Tokenizer, solo necesitas procesar los datos relevantes en lugar de toda la página.
Alternativas de terceros
Tanto Node Parser como Tokenizer son bastante básicos en comparación con las herramientas que se obtienen con Python y JavaScript. A continuación se indican algunas herramientas de terceros que pueden facilitar un poco el scraping.
Goquery
Creado como una alternativa de Go a Jquery,Goqueryes una excelente opción si buscas un analizador más intuitivo. Con Goquery, obtienes soporte para el recorrido DOM y los selectores CSS. Esto se parece mucho más a las soluciones a las que puedes estar acostumbrado en otros lenguajes.
htmlquery
Similar a Goquery,htmlquerynos permite utilizar tanto el recorrido DOM como los selectores. Sin embargo, con htmlquery utilizamos selectores XPath en lugar de selectores CSS. La elección entre Goquery y htmlquery debería basarse realmente en el tipo de selector que prefieras.
Colly
Collyes un completo marco de trabajo de Scraping web para Go. Con Colly, obtenemos soporte para selectores CSS, concurrencia y mucho más. Puedes considerarlo como una alternativa de Go aScrapy. Si te interesa utilizar Colly,aquí tienes un excelente tutorial al respecto.
Scraper web de Bright Data
NuestroWeb Scraperte permite evitar por completo el proceso de scraping. Con Web Scraper, rastreamos la página y te devolvemos sus datos en formato JSON. Es una opción excelente si solo quieres hacer una solicitud de API y seguir con tu día en lugar de recorrer el DOM, escribir tokens o escribir selectores. Nuestro Scraper web no es una biblioteca Go, es un servicio API. Si sabe cómo manejar una API REST, esta es una forma muy sencilla de automatizar su proceso de scraping.
Conclusión
Ahora ya sabe cómo realizar el parseo de HTML con Go. Para obtener un conjunto de habilidades más completo, eche un vistazo a nuestra guía sobrela integración de Proxies en Go. Si desea recorrer una página completa, utilice Node Parser. Si solo desea realizar el parseo de los datos relevantes de una página, pruebe Tokenizer. Si ninguno de estos se ajusta a sus necesidades, existen diversas herramientas de terceros, como los Web Scrapers de Bright Data. ¡Regístrate ahora y comienza tu prueba gratuita!





