
En esta guía, aprenderás:
- Qué es Puppeteer Real Browser
- Cómo funciona para evitar la detección de bots y la resolución de CAPTCHAs
- Cómo se compara con Puppeteer vanilla
- Cómo utilizarlo contra los sistemas de detección de bots del mundo real
- Sus principales alternativas
- Sus principales limitaciones
- Un enfoque mejor para la automatización del navegador antibots
¡Empecemos!
¿Qué es Puppeteer Real Browser?
Puppeteer Real Browser es una biblioteca JavaScript que hace que el navegador controlado por Puppeteer se comporte más como un usuario real. Esto reduce la detección de bots en servicios WAF como Cloudflare y similares. También admite la Resolución de CAPTCHA automática, incluida Cloudflare Turnstile.
La biblioteca amplía Puppeteer con configuraciones personalizadas, al tiempo que admite Proxies y todas las demás características de Puppeteer vanilla. Es de código abierto, con más de 1000 estrellas en GitHub, está disponible en npm como puppeteer-real-browser y es compatible con Docker para su implementación.
Nota: En febrero de 2026, el autor de la biblioteca, mdervisaygan, anunció que el proyecto ya no recibiría actualizaciones. Esto no significa que Puppeteer Real Browser haya desaparecido necesariamente, ya que los miembros de la comunidad pueden continuar su desarrollo a través de una bifurcación.
¿Cómo funciona Puppeteer Real Browser?
Si alguna vez has trabajado con herramientas de automatización de navegadores como Puppeteer, Playwright o Selenium, sabrás que los navegadores controlados por estas herramientas pueden ser detectados por los sistemas antibots. Esto es especialmente cierto cuando se opera en modo sin interfaz gráfica, incluso cuando se utilizan los mejores navegadores sin interfaz gráfica.
Los bloqueos se producen porque las bibliotecas de automatización configuran los navegadores de manera que sean más fáciles de controlar. Las soluciones antibots buscan estas configuraciones y «fugas» para determinar si las solicitudes provienen de un ser humano real que utiliza un navegador normal o de un bot automatizado.
Puppeteer Real Browser aborda ese problema utilizando Rebrowser, una colección de parches para Puppeteer y Playwright diseñados para evitar la detección de la automatización.
Rebrowser modifica directamente puppeteer-core, parcheando el tiempo de ejecución del navegador para eliminar los rastros similares a los de un bot que deja Puppeteer. Estos cambios hacen que el navegador parezca más una sesión de usuario real, lo que reduce las posibilidades de ser bloqueado por los sistemas antibots.
Sin embargo, los WAF como Cloudflare pueden seguir presentando CAPTCHAs de un solo clic:
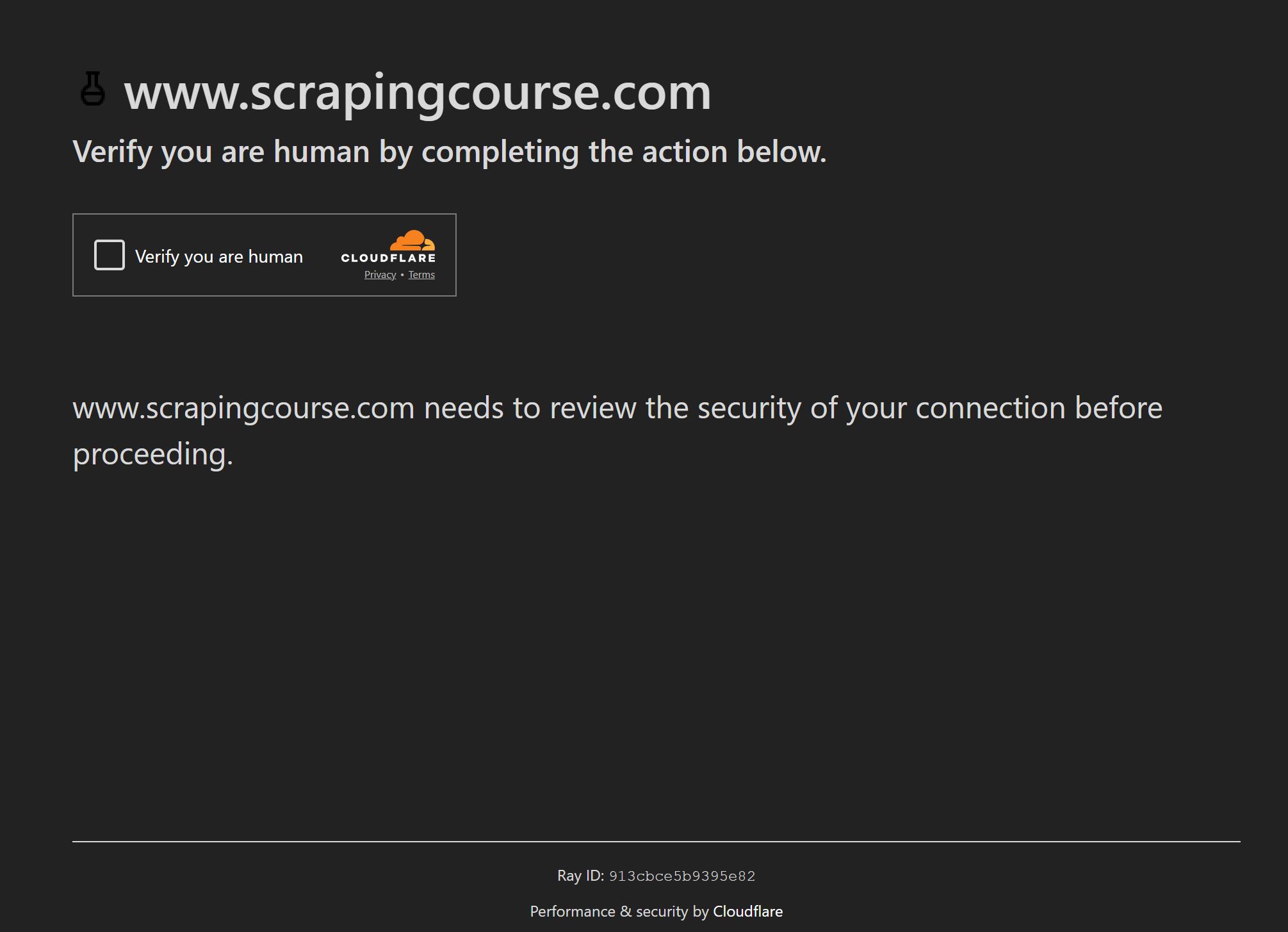
En ese caso, Puppeteer Real Browser se basa en ghost-cursor para interactuar con los CAPTCHA como lo haría un usuario real. Se trata de una biblioteca JavaScript que genera movimientos de ratón similares a los de un humano en Puppeteer o en cualquier plano 2D.
El problema es que los eventos del ratón de Puppeteer a menudo se detectan como sintéticos debido al comportamiento antinatural del cursor. Puppeteer Real Browser soluciona ese problema mejorando la forma en que se manejan los valores .screenX y .screenY, haciendo que los movimientos del ratón parezcan más naturales. Esto ayuda a engañar a Cloudflare Turnstile, reCAPTCHA y otros CAPTCHAs de un solo clic para que piensen que la interacción proviene de un usuario humano real.
La biblioteca también incluye:
- Puppeteer Extra: para habilitar la extensión a través de complementos
- Xvfb: para gestionar las pantallas de navegadores virtuales, ideal para entornos sin monitor.
En resumen, Puppeteer Real Browser combina diferentes mejoras para crear una herramienta de automatización sigilosa y de alta fidelidad que imita a los usuarios humanos y evita ser detectada.
Puppeteer Real Browser frente a Puppeteer
A continuación se muestra una tabla resumen de Puppeteer vs Puppeteer-Real-Browser para comparar las dos tecnologías:
| Puppeteer | Puppeteer Real Browser | |
|---|---|---|
| Estrellas de GitHub | 1000 estrellas | 89,7k estrellas |
| Biblioteca npm | puppeteer |
puppeteer-real-browser |
| Descargas npm | ~3,6 millones de descargas semanales | ~10 000 descargas semanales |
Versión dePuppeteer-core |
Puppeteer-core estándar |
Rebrowser-puppeteer-core parcheado para eliminar rastros de automatización |
| Detección antibots | Fácilmente detectable por la protección avanzada contra bots | Diseñado para evadir los sistemas de detección de bots (Cloudflare, Akamai, etc.) |
| API | Predeterminada | La misma API de Puppeteer con extensiones adicionales |
| Compatibilidad con Proxy | Compatible con proxies | Compatible con proxies |
| Gestión de CAPTCHA | Sin resolución de CAPTCHA integrada | Admite resolución de CAPTCHA con un solo clic (por ejemplo, Cloudflare Turnstile, reCAPTCHA) |
| Compatibilidad con plugins | Sin compatibilidad nativa con complementos | Se integra con puppeteer-extra para la compatibilidad con complementos |
| Mantenimiento y actualizaciones | Mantenimiento activo por parte de Google. | Descontinuado por el autor (febrero de 2026), pero puede continuar a través de la comunidad |
Cómo utilizar Puppeteer Real Browser para evitar los CATPCHA
Para demostrar las capacidades de Puppeteer Real Browser, lo probaremos con la página Anti-Bot Challenge de Scraping Course:
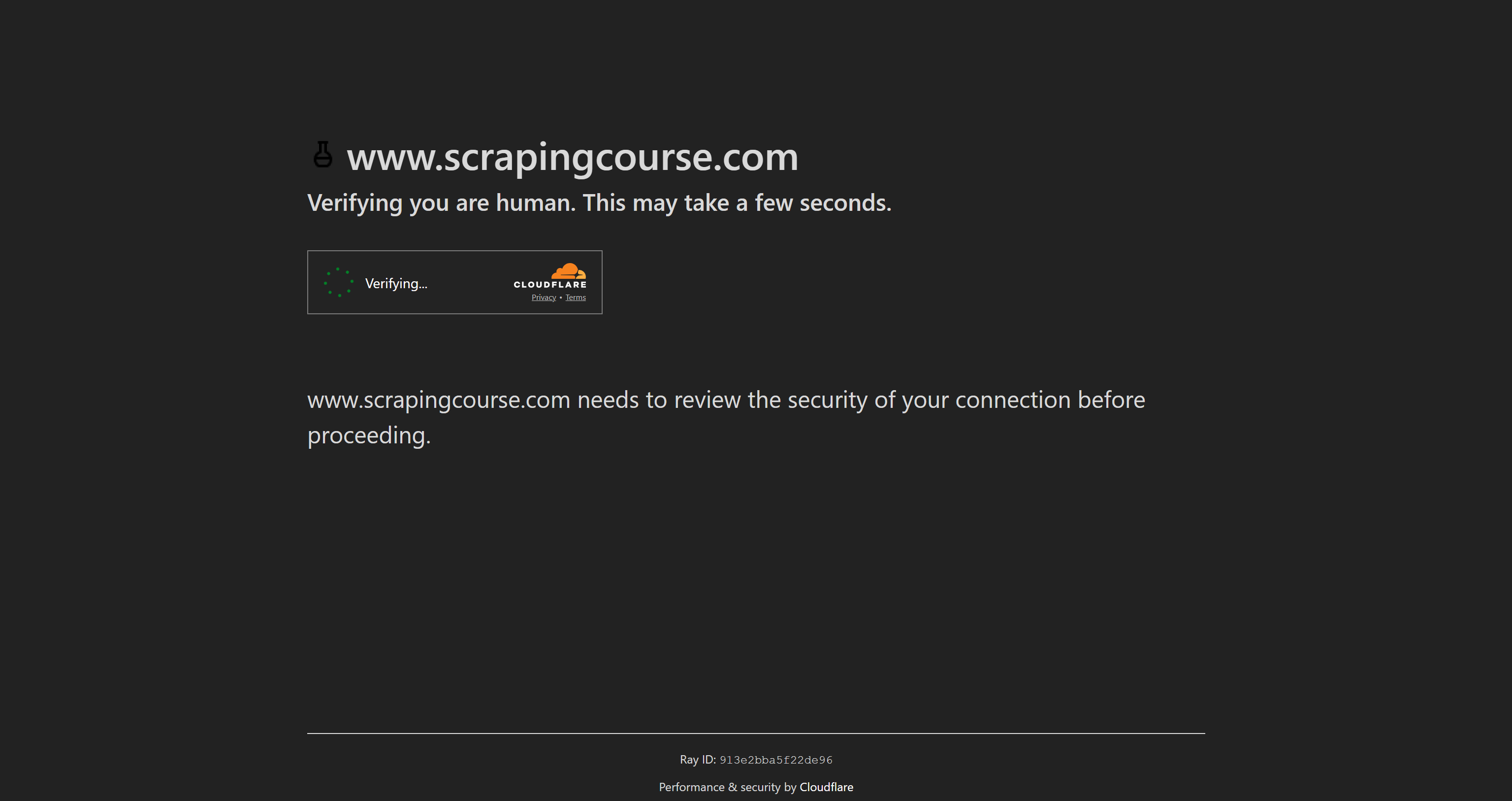
Esta página protegida por Cloudflare cuenta con un CAPTCHA Turnstile de un solo clic. En esta sección paso a paso, mostraremos cómo utilizar Puppeteer Real Browser para la resolución de CAPTCHA.
Si desea conocer un enfoque alternativo, consulte nuestra guía sobre cómo evitar los CAPTCHAs en Puppeteer. Es fundamental saber que un script estándar de Puppeteer que intente acceder a esa página siempre se encontrará con el CAPTCHA Turnstile y será bloqueado.
Como verás, Puppeteer Real Browser es una solución eficaz para eludir Cloudflare y otras protecciones similares contra bots.
Paso n.º 1: Instalar puppeteer-real-browser
Supondremos que ya tiene configurado un proyecto Node.js. Si no es así, puede crear uno utilizando npm init.
Ahora, navega a la carpeta de tu proyecto e instala puppeteer-real-browser con:
npm install puppeteer-real-browserEn Linux, también debe instalar xvfb como dependencia a nivel del sistema. Para sistemas basados en Debian, instálelo con:
sudo apt-get install xvfb¡Genial! Ahora ya está listo para utilizar Puppeteer Real Browser para evitar los CAPTCHA.
Paso n.º 2: configuración inicial
En su script JavaScript, importe connect desde Puppeteer Real Browser:
const { connect } = require("puppeteer-real-browser");La función connect() te permite establecer una conexión con el motor del navegador modificado dentro de una función asíncrona:
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// lógica de scraping...
await browser.close();
})();Al igual que en Puppeteer vanilla, es necesario llamar a browser.close() para liberar recursos.
La función connect() en Puppeteer Real Browser acepta los siguientes parámetros:
headless: El valor predeterminado esfalse. Se pueden utilizar otros valores como«new»,truey«shell», perofalsees el más estable.args: se pueden pasar indicadores Chromium adicionales como una matriz de cadenas. Consulte los indicadores compatibles.customConfig: Puppeteer Real Browser se inicializa utilizandochrome-launcher. Cualquier opción que se pase aquí se añadirá como argumento de inicialización directo. Se puede utilizar para estableceruserDataDiro una ruta personalizada de Chrome (chromePath).turnstile: sies true, Puppeteer Real Browser hace clic automáticamente en los CAPTCHA de Cloudflare Turnstile.connectOption: Opciones enviadas al conectarse a Chromium utilizandopuppeteer.connect().disableXvfb: En Linux, cuandoheadless: false, se utiliza una pantalla virtual (xvfb) para ejecutar el navegador. Establezca este valor entruepara desactivarlo y ver la ventana real del navegador.ignoreAllFlags: Sies true, se anulan todos los argumentos de inicialización predeterminados, incluida la página «Let’s get started» que aparece al cargar por primera vez.plugins: Una matriz de complementos adicionales de Puppeteer. Obtenga más información en la documentación oficial.
Todas las demás opciones compatibles con la función anterior provienen del método connect() de Puppeteer.
Dado que queremos omitir Cloudflare, la configuración clave en este ejemplo es turnstile to true.
Paso n.º 3: Conectarse a la página de destino
Utilice la función goto() de la API de Puppeteer para navegar a la página de destino:
await page.goto("https://www.scrapingcourse.com/antibot-challenge");Dado que turnstile está establecido en true, Puppeteer Real Browser esperará automáticamente a que se cargue el CAPTCHA de Cloudflare Turnstile e intentará resolverlo.
Paso 4: Espere la Resolución de CAPTCHA
Si abre la página de destino en modo incógnito y realiza manualmente la resolución de CAPTCHA, obtendrá el siguiente resultado:

Inspeccione el mensaje con DevTools y verá lo siguiente:
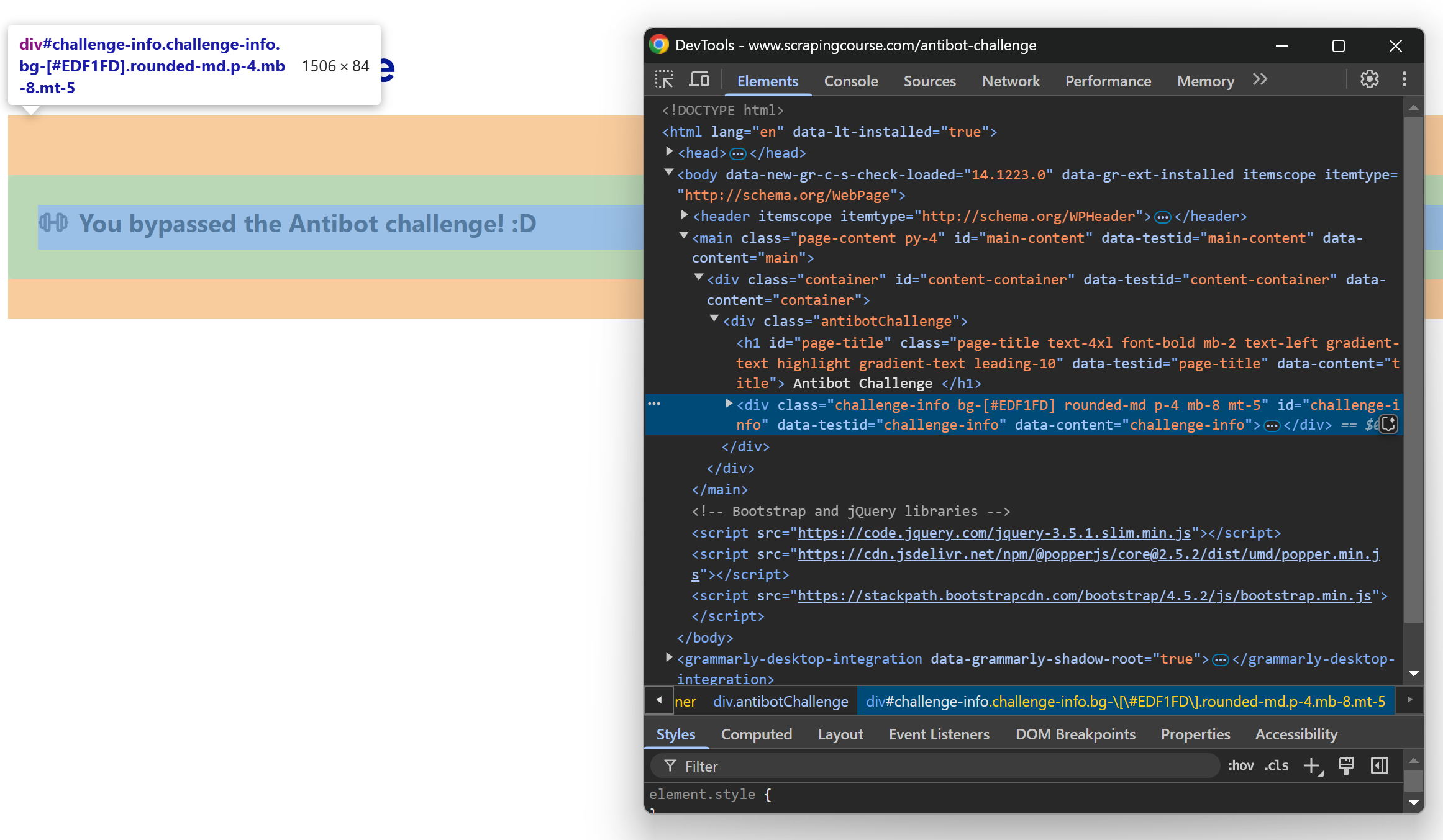
Ten en cuenta que el elemento del mensaje se puede seleccionar utilizando el selector CSS #challenge-info.
Ahora, define una función personalizada para esperar a que cambie el DOM de la página:
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}Esta función es necesaria porque puppeteer-real-browser no proporciona una devolución de llamada integrada para la resolución del CAPTCHA. Como esperamos que Puppeteer Real Browser omita correctamente el CAPTCHA, el DOM de la página se actualizará en consecuencia y deberá esperar a que se produzcan estos cambios.
Por lo tanto, puede utilizar delay() para esperar un período de tiempo determinado y permitir que la página se actualice por completo, como se muestra a continuación:
await delay(10000);A continuación, espere a que el elemento de mensaje de destino aparezca en la página:
await page.waitForSelector("#challenge-info", { timeout: 5000 });A continuación, recupere e imprima su contenido:
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Mensaje de la página: "${challengeInfo}"`);Si todo funciona como se espera, el script debería mostrar:
Mensaje de la página: «¡Has superado el desafío Antibot! :D»Paso n.º 5: Ponlo todo junto
A continuación se muestra el script final de Puppeteer Real Browser:
const { connect } = require("puppeteer-real-browser");
// función personalizada para implementar una espera forzada
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// conectarse al navegador controlado
const { browser, page } = await connect({
headless: false,
turnstile: true, // habilitar el manejo de CAPTCHA de Turnstile
connectOption: {
defaultViewport: null, // hacer que la ventana gráfica sea tan grande como la ventana del navegador
},
args: ["--start-maximized"], // iniciar el navegador en una ventana maximizada
});
// navegar a la página del desafío
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // esperar a que la página se cargue por completo y esté inactiva
});
// esperar hasta 10 segundos a que se resuelva la resolución de CAPTCHA
await delay(10000);
// esperar hasta 5 segundos a que aparezca el elemento de información del desafío
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// recuperar e imprimir el texto de información del desafío
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Mensaje de la página: "${challengeInfo}"`);
// cerrar el navegador y liberar sus recursos
await browser.close();
})();Ejecute el código anterior y se abrirá un navegador que se comportará de la siguiente manera:
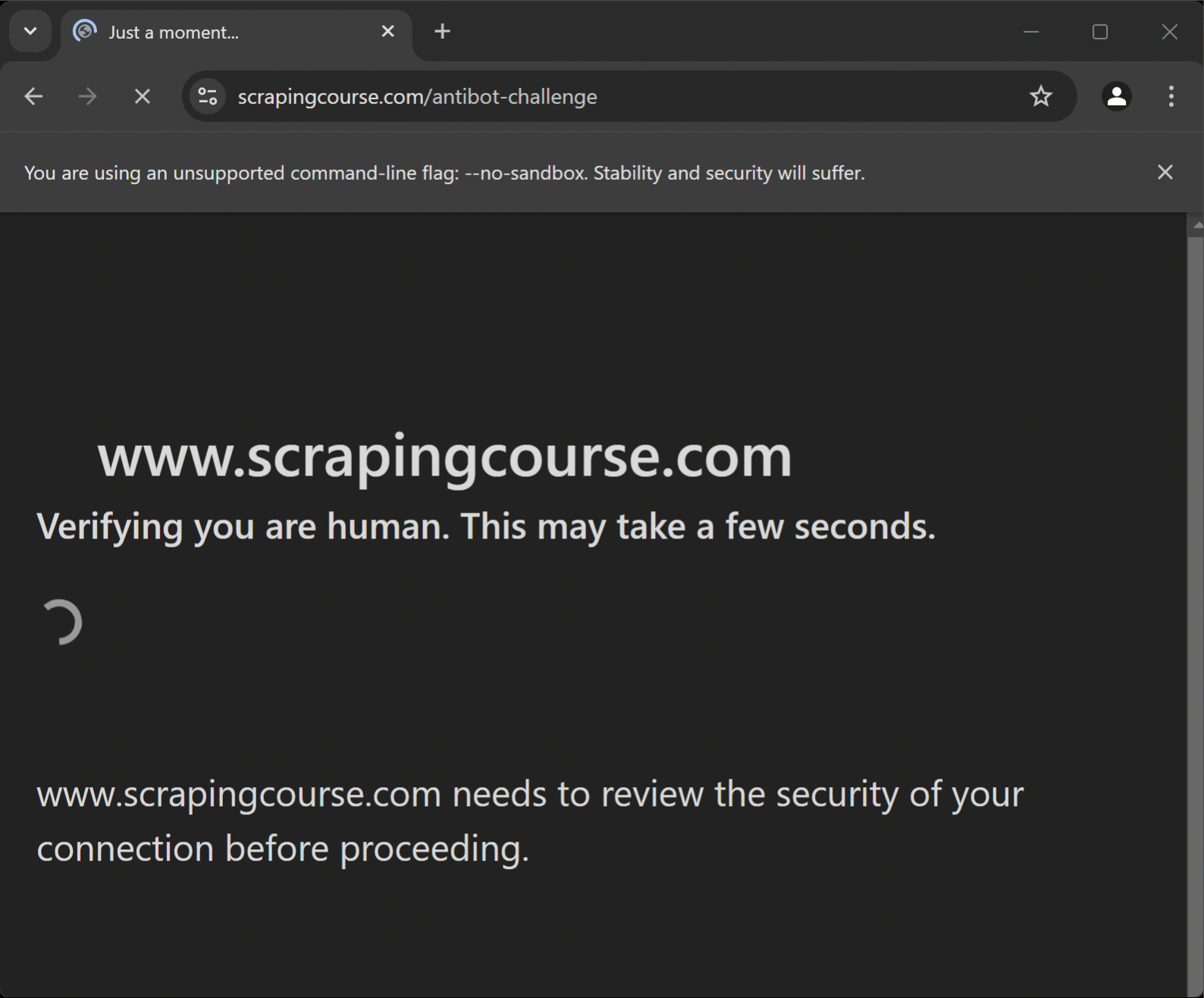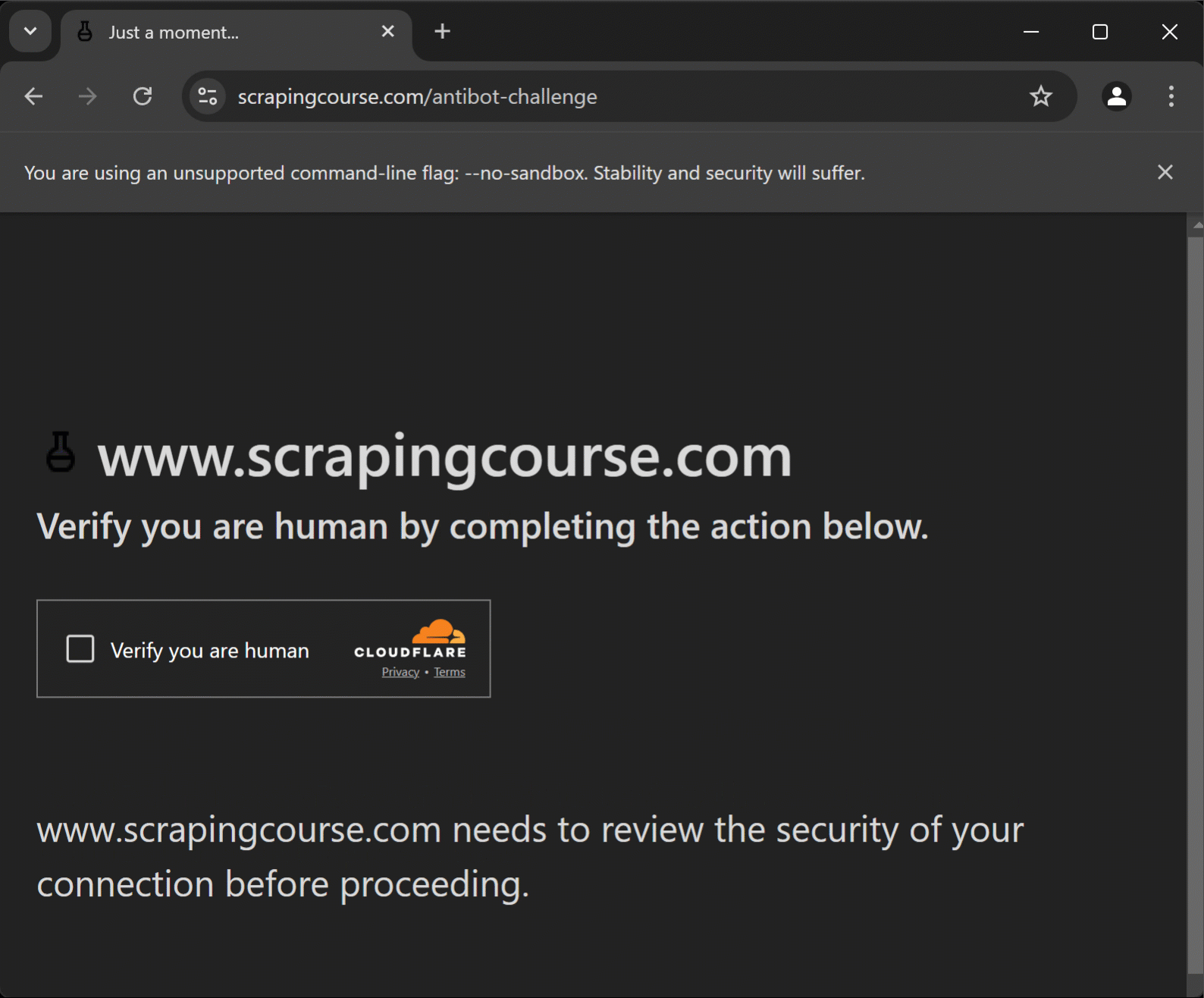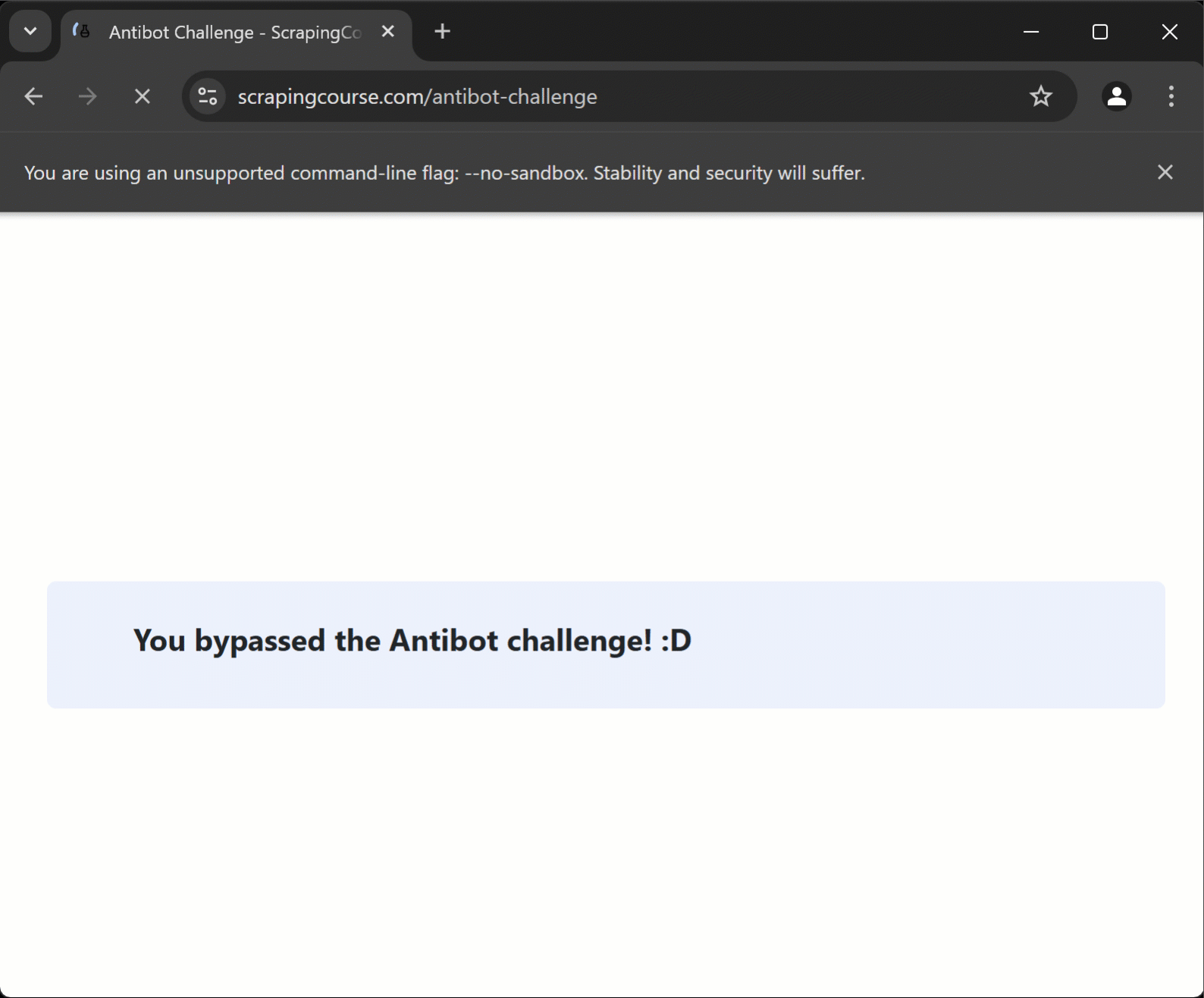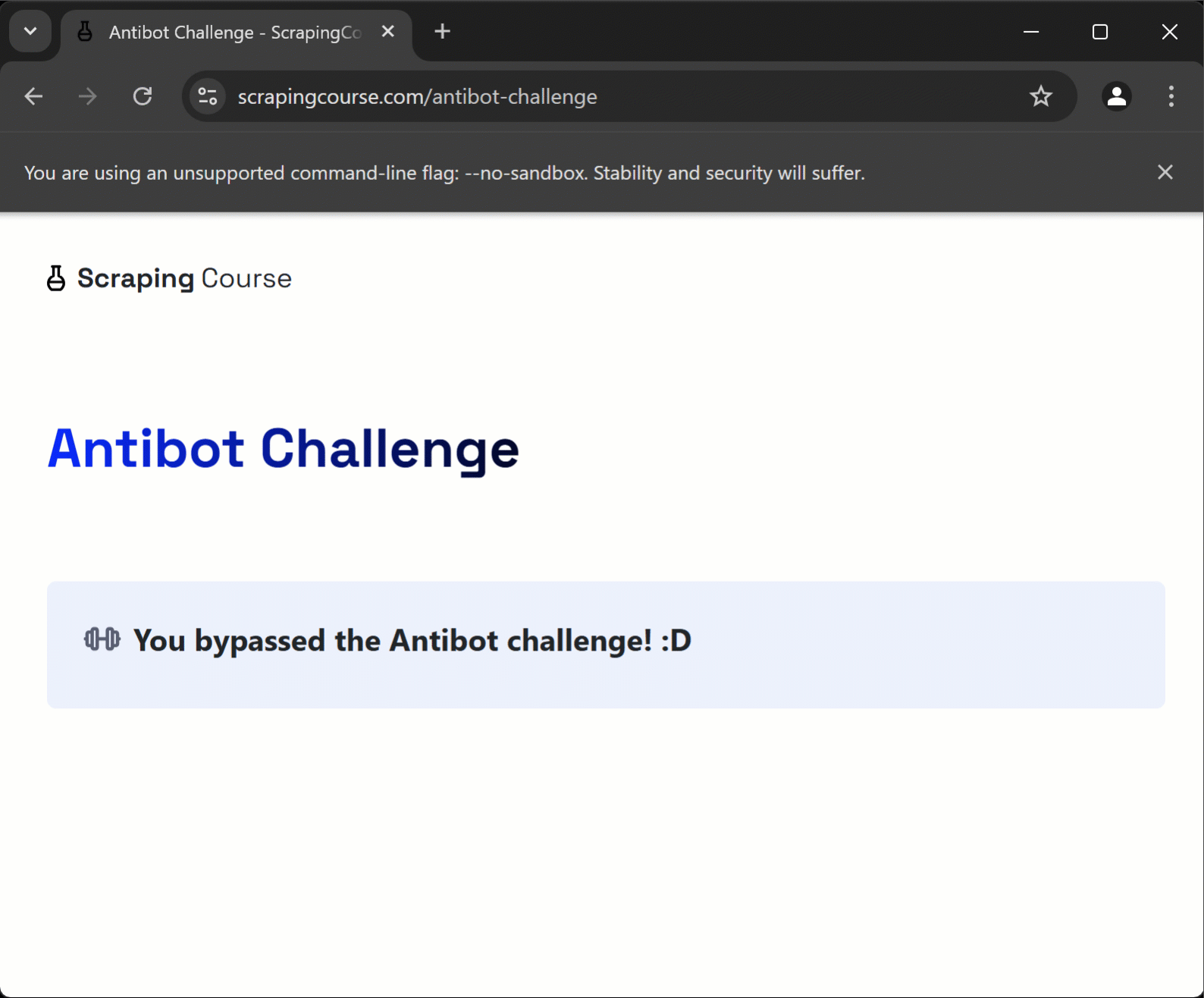
El script visita una página protegida por Cloudflare, realiza automáticamente la resolución de CAPTCHA y, a continuación, llega a la página de destino, extrayendo datos de ella.
Tal y como se desea, el script producirá este resultado en la terminal:
Mensaje de la página: «¡Has superado el desafío Antibot! :D»¡Fantástico! La resolución de CAPTCHA de Cloudflare se ha realizado automáticamente.
Alternativas a puppeteer-real-browser
Dado que puppeteer-real-browser ya no se mantiene, vale la pena explorar alternativas que ofrezcan características similares, como:
- Puppeteer Stealth: un complemento para Puppeteer Extra que aplica diversas evasiones para que la automatización sea menos detectable. Modifica las huellas digitales del navegador, desactiva las fugas de WebRTC e imita el comportamiento humano para eludir las medidas antibots.
- Playwright Stealth: un complemento de Playwright Extra que integra las mismas técnicas de sigilo que Puppeteer Stealth. Parchea las API del navegador para evitar fugas de huellas digitales.
- SeleniumBase: un marco de automatización basado en Selenium con todas las funciones y características de detección antibots integradas. Incluye técnicas de evasión de bots, suplantación de agentes de usuario, manejo de CAPTCHA y otras herramientas para ayudar a los scripts de Selenium a eludir la protección contra bots.
- undetected-chromedriver: una versión modificada de ChromeDriver que ayuda a los scripts de Selenium a eludir la detección de bots. Elimina los indicadores de automatización, ofusca las propiedades de WebDriver y garantiza que el navegador se comporte más como una sesión operada por humanos.
Limitaciones de Puppeteer Real Browser
Puppeteer Real Browser es una potente herramienta de automatización de navegadores antibots, pero tiene algunas desventajas. El autor es transparente sobre estas limitaciones y ofrece información clara al respecto.
Las principales limitaciones son:
- Ya no se mantiene: en febrero de 2026, el autor original anunció que la biblioteca ya no recibiría actualizaciones. Las futuras mejoras dependerán de las contribuciones de la comunidad, en lugar del desarrollo activo.
- No es 100 % indetectable: aunque reduce la detección de bots, los sistemas antibots avanzados pueden seguir detectando el tráfico automatizado.
- Requiere una configuración adicional: es posible que los usuarios tengan que ajustar los Proxy, los encabezados y otros parámetros para obtener un sigilo y una funcionalidad óptimos.
- No se puede acceder a las funciones del objeto ventana: esto se debe a que Rebrowser cierra el tiempo de ejecución del navegador. Una solución alternativa es inyectar JavaScript en la página utilizando puppeteer-intercept-and-modify-requests o utilizando complementos de Chrome.
- Depende de bibliotecas externas: la biblioteca depende de proyectos de terceros como Rebrowser, Puppeteer Extra y ghost-cursor, que podrían cambiar o dejar de estar disponibles.
- Problemas con reCAPTCHA: reCAPTCHA v3 requiere que se pase una sesión activa de Google. Incluso con un navegador indetectable, es probable que los intentos de automatización sin una sesión válida sean marcados.
Automatización fluida del navegador antibots
Los inconvenientes mencionados anteriormente pueden disuadirle de considerar Puppeteer Real Browser. Aunque podría probar una de sus alternativas, es probable que se encuentre con retos similares.
Lo importante es que la mayoría de las bibliotecas de automatización de navegadores antibots se centran en parchear los navegadores, no en la propia biblioteca de automatización. Aunque puede ser necesario realizar pequeñas modificaciones en el núcleo de esas bibliotecas, la mayor parte del esfuerzo se dedica a parchear los motores de los navegadores para evitar fugas de detección.
Ahora, imagina poder utilizar bibliotecas de automatización de navegadores básicas como Playwright, Puppeteer y Selenium, basándote en sus actualizaciones y API estables, para controlar un navegador escalable basado en la nube y diseñado específicamente para el Scraping web. ¡Esa es exactamente la experiencia que ofrece el Navegador de scraping de Bright Data!
El Navegador de scraping incluye una función integrada de desbloqueo de sitios web que se encarga automáticamente del bloqueo. Se integra a la perfección con una red Proxy de 400M+ monthly IP, funciona de manera eficiente en la nube e incluye un solucionador de CAPTCHA integrado.
¡Los navegadores de scraping optimizados son la verdadera solución para lograr la automatización del navegador antibots!
Conclusión
En este artículo, ha aprendido a lidiar con la detección de bots en Puppeteer utilizando Puppeteer Real Browser. Esta biblioteca proporciona una versión parcheada de puppeteer-core para el Scraping web sin ser bloqueado.
El problema es que puppeteer-real-browser ya no se mantiene. Por lo tanto, aunque hoy funcione, es posible que mañana no lo haga, ya que las soluciones antibots siguen evolucionando.
El problema no radica en la API de Puppeteer para controlar el navegador, sino en los propios navegadores. La solución es un navegador basado en la nube, siempre actualizado y escalable, con una función integrada de elusión de bots, como el Navegador de scraping.
El Navegador de scraping de Bright Data es un navegador en la nube altamente escalable que funciona con Puppeteer, Selenium, Playwright y otros. Se encarga de las huellas digitales del navegador, la resolución de CAPTCHA y los reintentos automáticos por usted.
Además, rota automáticamente la IP de salida con cada solicitud, gracias a una red global de Proxies que incluye:
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxies residenciales: más de 150 millones de IPs residenciales en más de 195 países.
- Proxy ISP: más de 700 000 IP de ISP.
- Proxy móvil: más de 7 millones de IP móviles.
Crea hoy mismo una cuenta gratuita en Bright Data para probar nuestro navegador de scraping o nuestros Proxies.





