
En este tutorial aprenderás:
- Qué es MLflow y las capacidades de seguimiento que ofrece.
- Por qué crear experimentos de ML/IA a partir de conjuntos de datos extraídos mediante Scraping web es un enfoque ganador.
- Cómo realizar el seguimiento de experimentos utilizando un conjunto de datos extraídos con MLflow.
¡Empecemos!
¿Qué es MLflow?
MLflow es una plataforma de código abierto para gestionar todo el ciclo de vida del aprendizaje automático. Ofrece numerosas funciones y una API completa para realizar un seguimiento, reproducir e implementar modelos de forma eficiente.
MLflow es compatible tanto con los flujos de trabajo tradicionales de aprendizaje automático como con los de aprendizaje profundo, y ofrece herramientas para la experimentación, el control de versiones, la evaluación y la implementación. Todo ello de forma reproducible y colaborativa.
MLflow es independiente del lenguaje, funciona con Python, R y Java, y es compatible con entornos locales, en la nube y gestionados. Eso lo hace independiente del proveedor y muy flexible. Además, conserva su naturaleza de código abierto, con su repositorio GitHub que cuenta con más de 24 000 estrellas.
Las principales características de MLflow incluyen:
- Seguimiento: registra experimentos, parametros, métricas, versiones de código y artefactos.
- Modelos: estandarizar el empaquetado de modelos para su implementación en diferentes plataformas.
- Registro de modelos: repositorio centralizado para el control de versiones de modelos, transiciones de etapas y anotaciones.
- Proyectos: empaquetar código de ciencia de datos reutilizable para garantizar la coherencia y la reproducibilidad.
- Evaluación de IA/LLM: rastrear, comparar y evaluar los resultados generativos de IA o LLM.
- Integración y registro automático: funciona con scikit-learn, TensorFlow, PyTorch, OpenAI y más, automatizando el registro.
Más información en la documentación oficial.
Por qué los conjuntos de datos que contienen datos web recopilados son ideales para experimentar con MLflow
Al crear canalizaciones de ML/IA, la calidad y la variedad de los conjuntos de datos suelen ser determinantes para el éxito o el fracaso de los experimentos. Los datos web recopilados, por su naturaleza, proporcionan tanto diversidad como escala. Esos son los dos ingredientes principales para una experimentación significativa.
A diferencia de los conjuntos de datos pequeños o sintéticos, los conjuntos de datos derivados de la web capturan distribuciones del mundo real, casos extremos y variabilidad natural. Estos aspectos hacen que sus modelos sean más robustos y sus experimentos con MLflow más informativos. Por eso los datos web se consideran generalmente una de las mejores fuentes de datos.
Bright Data destaca como el mejor proveedor de conjuntos de datos. Su mercado ofrece conjuntos de datos estructurados listos para ML y IA que abarcan más de 150 dominios, desde el comercio electrónico y la venta al por menor hasta las redes sociales y los viajes. Cada conjunto de datos contiene millones de registros, lo que garantiza tanto la amplitud como la profundidad.
Estos conjuntos de datos se actualizan periódicamente, lo que refleja la naturaleza dinámica de la web, de modo que sus flujos de trabajo de ML/IA pueden entrenarse y evaluarse con la información más actualizada. Esta combinación de escala, actualidad y formato listo para ML hace que los conjuntos de datos de Bright Data sean perfectos para una experimentación sólida, reproducible y de gran impacto con MLflow. Explore los conjuntos de datos disponibles en el mercado.
Cómo realizar el seguimiento de experimentos utilizando MLflow y un conjunto de datos de Bright Data
En esta sección guiada, aprenderá a realizar el seguimiento de experimentos con MLflow. En concreto, creará un proceso de aprendizaje automático utilizando el conjunto de datos Amazon Best Product Seller de Bright Data.
El objetivo de este proceso es entrenar un modelo que prediga el precio final de un producto basándose en su valoración, el número de reseñas y la marca. La hipótesis subyacente es que estas características contienen señales predictivas correlacionadas con el precio del producto.
El proceso combina el preprocesamiento con un modelo Random Forest y evalúa su rendimiento. A lo largo del proceso, MLflow realizará un seguimiento de las métricas, los artefactos, los Conjuntos de datos y el uso de los recursos del sistema.
¡Siga los pasos que se indican a continuación!
Requisitos
Para seguir este tutorial, necesita:
- Python 3.10 o superior instalado localmente.
- Una cuenta de Bright Data para acceder a los Conjuntos de datos recopilados.
- Conocimientos básicos sobre el entrenamiento de modelos predictivos de ML con scikit-learn.
Paso n.º 1: Configuración del proyecto
Comience abriendo su terminal y creando una nueva carpeta para su proyecto de experimento MLflow:
mkdir mlflow-experiment-trackingA continuación, navegue hasta el directorio del proyecto y cree un entorno virtual Python dentro de él:
cd mlflow-experiment-tracking
python -m venv .venvAhora, cargue la carpeta del proyecto en su IDE de Python preferido. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Cree un nuevo archivo llamado experiment.py en la raíz del directorio del proyecto. La estructura del proyecto debería tener este aspecto:
mlflow-experiment-tracking/
├── .venv/
└── experiment.pyEn la terminal, activa el entorno virtual. En Linux o macOS, ejecuta:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activateCon el entorno virtual activado, instale las dependencias del proyecto:
pip install mlflow pandas scikit-learn psutil nvidia-ml-pyLas bibliotecas necesarias son:
mlflow: para el seguimiento integral de experimentos, la observabilidad y el registro de modelos y métricas de ML.pandas: carga, limpia y manipula datos tabulares de JSON/CSV para el entrenamiento de modelos.scikit-learn: crea canalizaciones de ML, gestiona el preprocesamiento, entrena modelos y calcula métricas de evaluación.psutil, nvidia-ml-py: requerido por MLflow para supervisar los recursos de la CPU y la GPU y otras métricas del sistema durante los experimentos.
A continuación, en experiment.py, importe todas las bibliotecas necesarias con:
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer¡Bien hecho! Tu entorno de desarrollo Python ya está listo para realizar un seguimiento de los experimentos de ML e IA en MLflow.
Paso n.º 2: familiarízate con la interfaz de usuario de MLflow
Para verificar que MLflow funciona, abra un terminal con su entorno virtual activado e inicie la interfaz de usuario de MLflow:
mlflow uiAl iniciarse por primera vez, MLflow inicializará una base de datos SQLite local para almacenar los datos del experimento. En concreto, verá que ha aparecido un archivo mlflow.db en la carpeta de su proyecto. Esa es la base de datos local que utiliza SQLite.
En la terminal, verá un registro como este:
INFO: Uvicorn ejecutándose en http://127.0.0.1:5000 (pulse CTRL+C para salir)Esto significa que la interfaz de usuario ya se está ejecutando. Abra su navegador y visite http://127.0.0.1:5000/. Debería ver lo siguiente: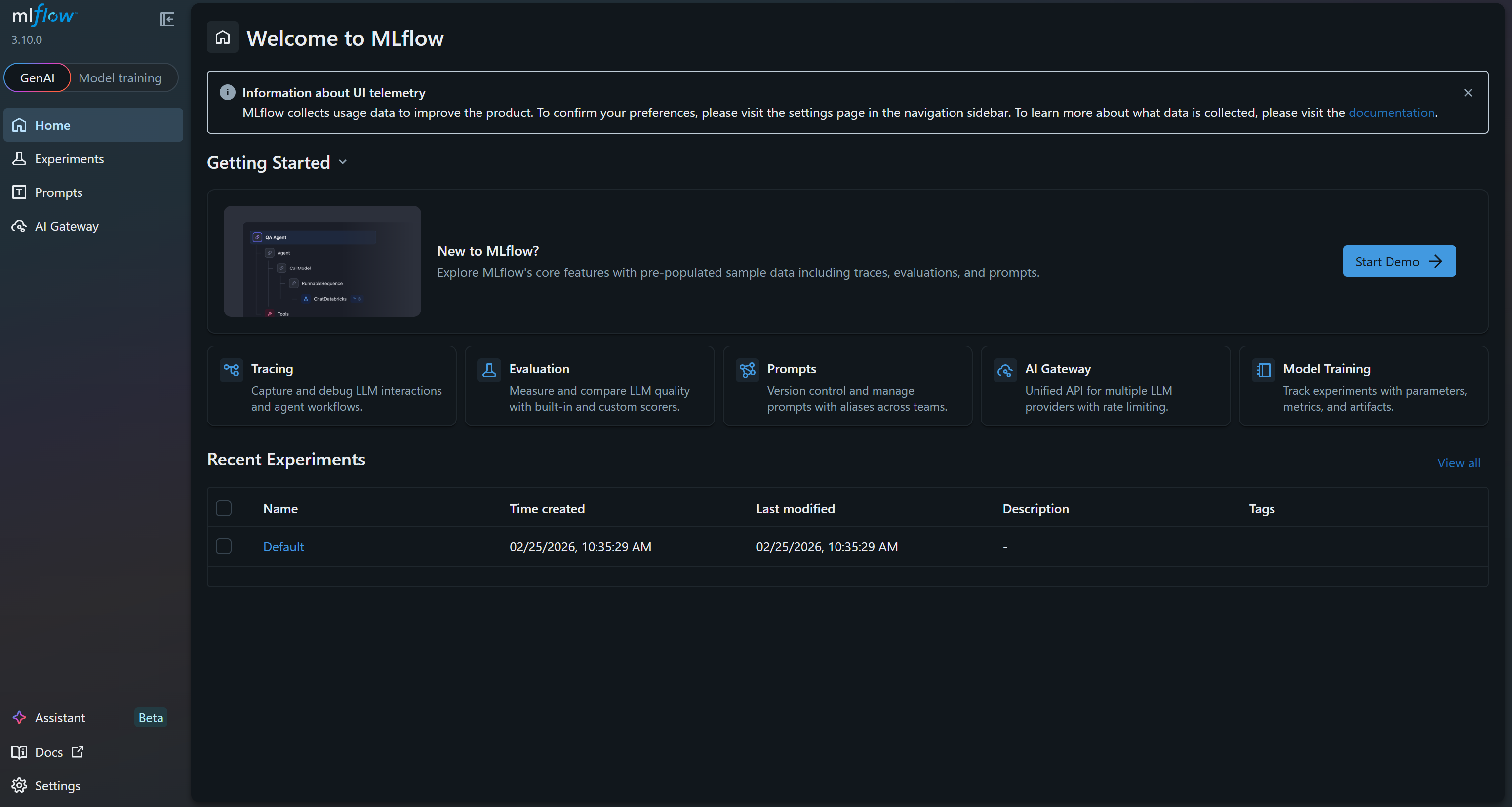
Esta es la interfaz de usuario de MLflow, donde puede observar y realizar un seguimiento de sus experimentos. Tómese unos minutos para familiarizarse con ella explorando los enlaces del menú y las funciones disponibles. Aquí podrá supervisar métricas, registros y artefactos de forma eficaz durante sus proyectos de ML. ¡Genial!
Paso n.º 3: habilitar las capacidades de registro automático y seguimiento del sistema de MLflow
En su archivo experiment.ml, habilite el registro de métricas del sistema MLflow para realizar un seguimiento del uso de la CPU, el uso del disco, el uso de la RAM y otras métricas a nivel del sistema durante el entrenamiento.
# Habilitar el registro automático de métricas del sistema (CPU, memoria, etc.)
mlflow.enable_system_metrics_logging()
# Registrar automáticamente los eventos para sklearn
mlflow.sklearn.autolog()
# Configurar la frecuencia con la que se muestrean y registran las métricas del sistema
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1) Este fragmento también activa el registro automático para que MLflow registre automáticamente los eventos de scikit-learn. A continuación, establece el intervalo de muestreo de las métricas del sistema en 1 segundo para garantizar una supervisión detallada y frecuente.
¡Fantástico! Su aplicación MLflow ahora realizará un seguimiento de la información útil sobre su experimento de entrenamiento del modelo de aprendizaje automático.
Paso n.º 4: Recuperar el conjunto de datos de origen con datos extraídos de Bright Data
Ahora ya tiene configurado MLflow y está listo para realizar experimentos de ML/IA. Lo que falta es la fuente de datos para entrenar su modelo. Como se ha mencionado anteriormente, utilizaremos el conjunto de datos de los productos más vendidos de Amazon de Bright Data para crear un modelo de predicción de precios basado en un proceso de Random Forest.
En primer lugar, debe recuperar el conjunto de datos de origen. En este caso, contiene más de 45 campos de datos y abarca más de 171 millones de productos más vendidos de Amazon.
Si aún no tiene una cuenta de Bright Data, cree una. De lo contrario, inicie sesión. En el panel de control de Bright Data, seleccione la opción de menú «Conjuntos de datos web». A continuación, vaya a la pestaña «Mercado de conjuntos de datos»: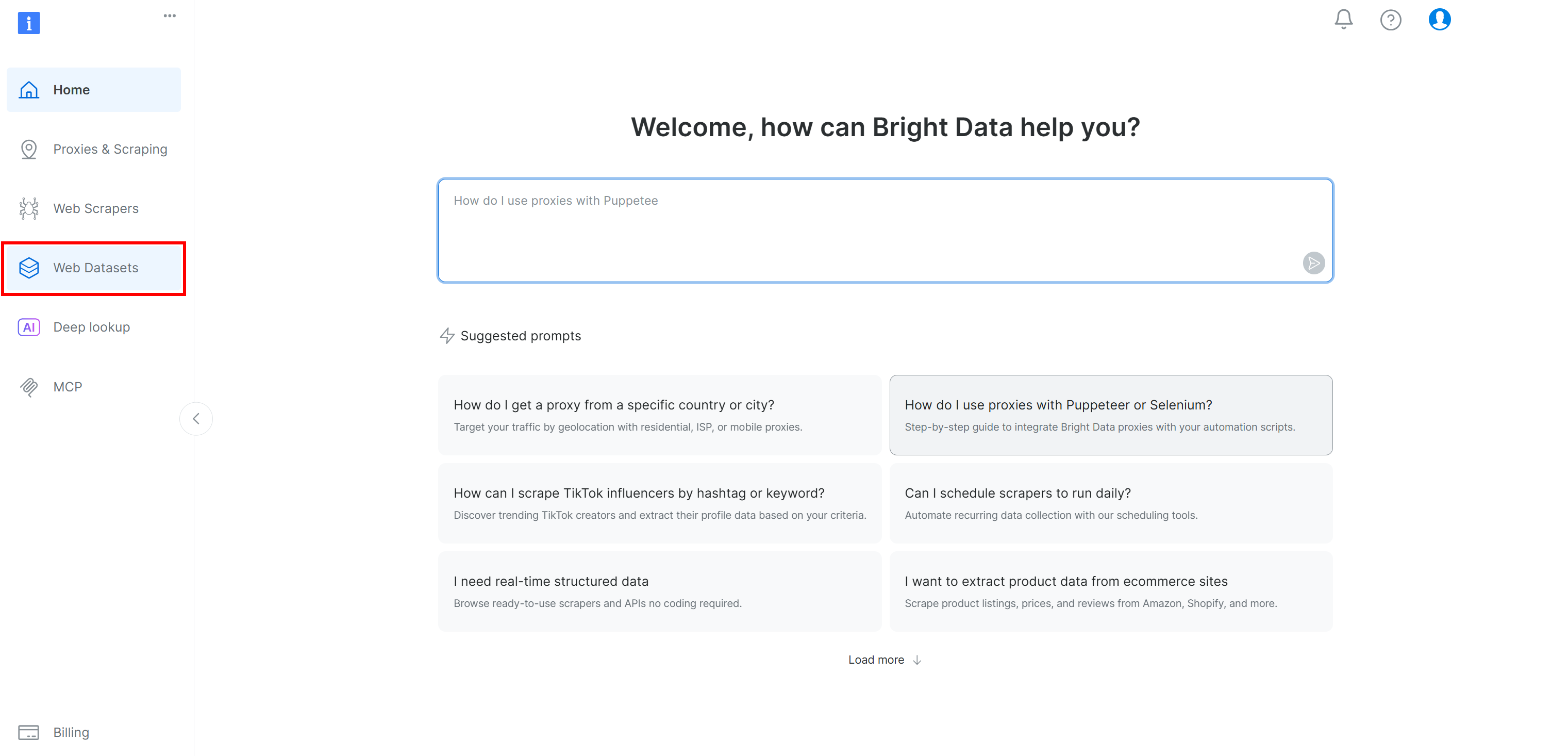
Vaya a la pestaña «Dataset marketplace»: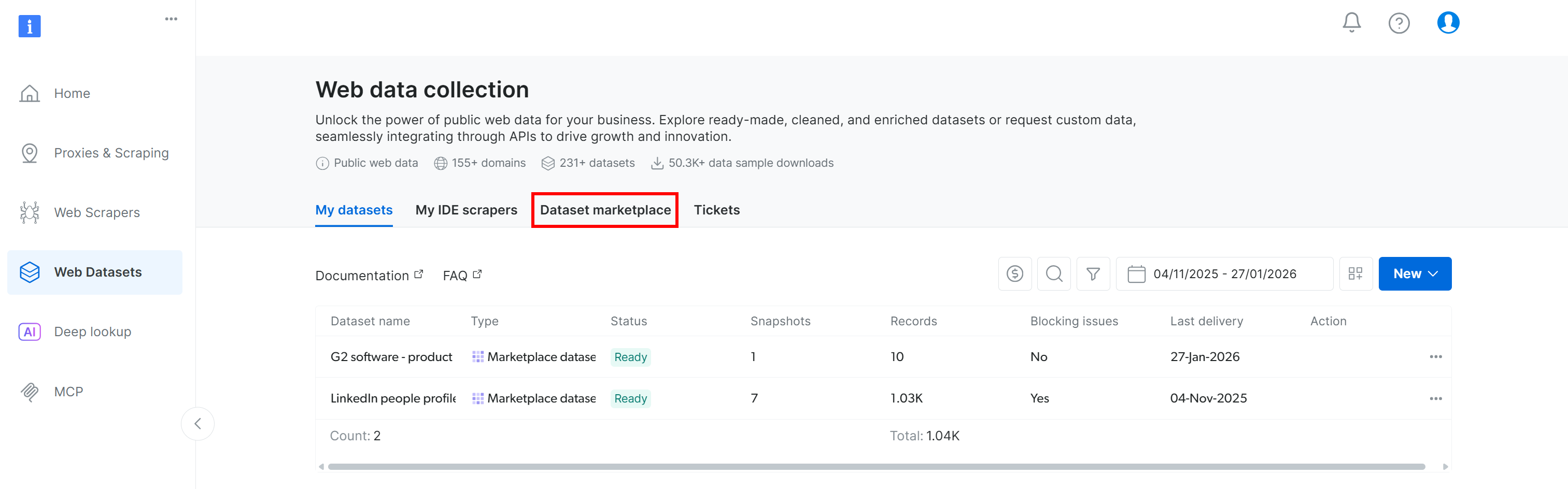
Llegará a la página«Dataset marketplace»: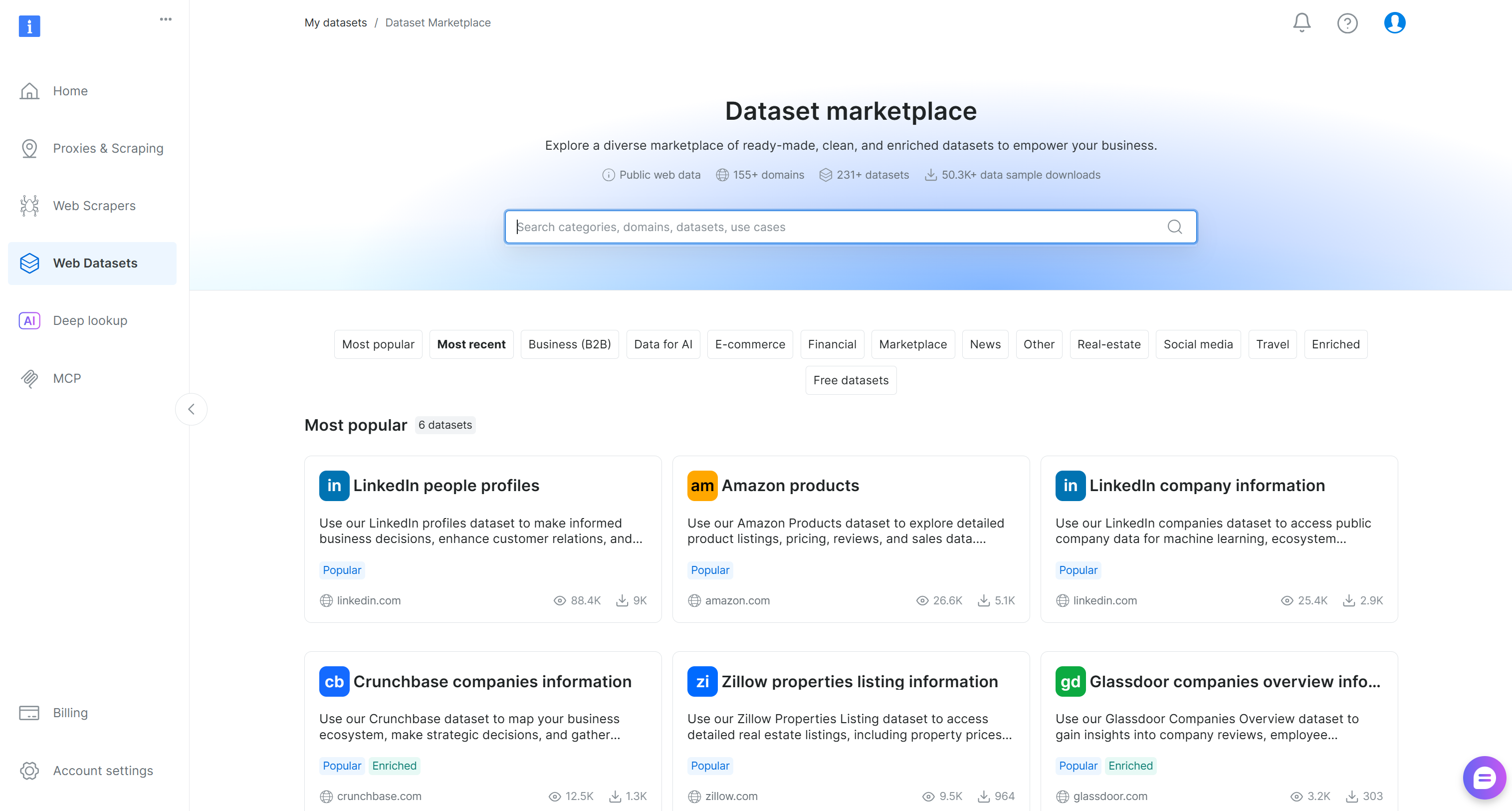
Aquí puede explorar más de 200 conjuntos de datos extraídos de más de 155 dominios, con miles de millones de registros disponibles.
Busque «Amazon best seller products» y selecciónelo. Esto le llevará a la página del conjunto de datos: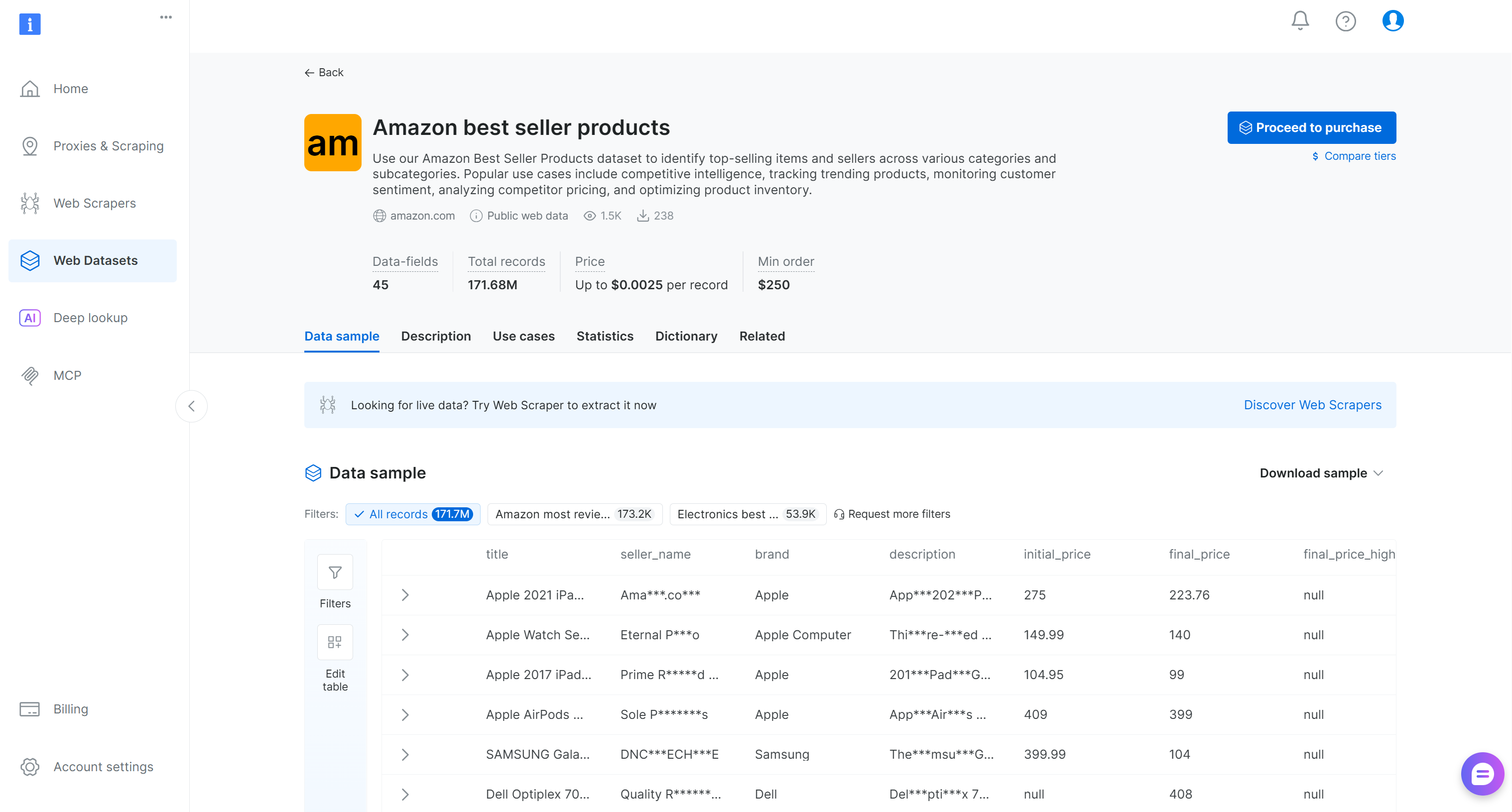
Puede comprar un subconjunto filtrado de registros o descargar una muestra gratuita. Como se trata solo de un ejemplo, utilizaremos la muestra gratuita.
Haga clic en el menú desplegable «Descargar muestra» y seleccione la opción «Descargar como JSON»: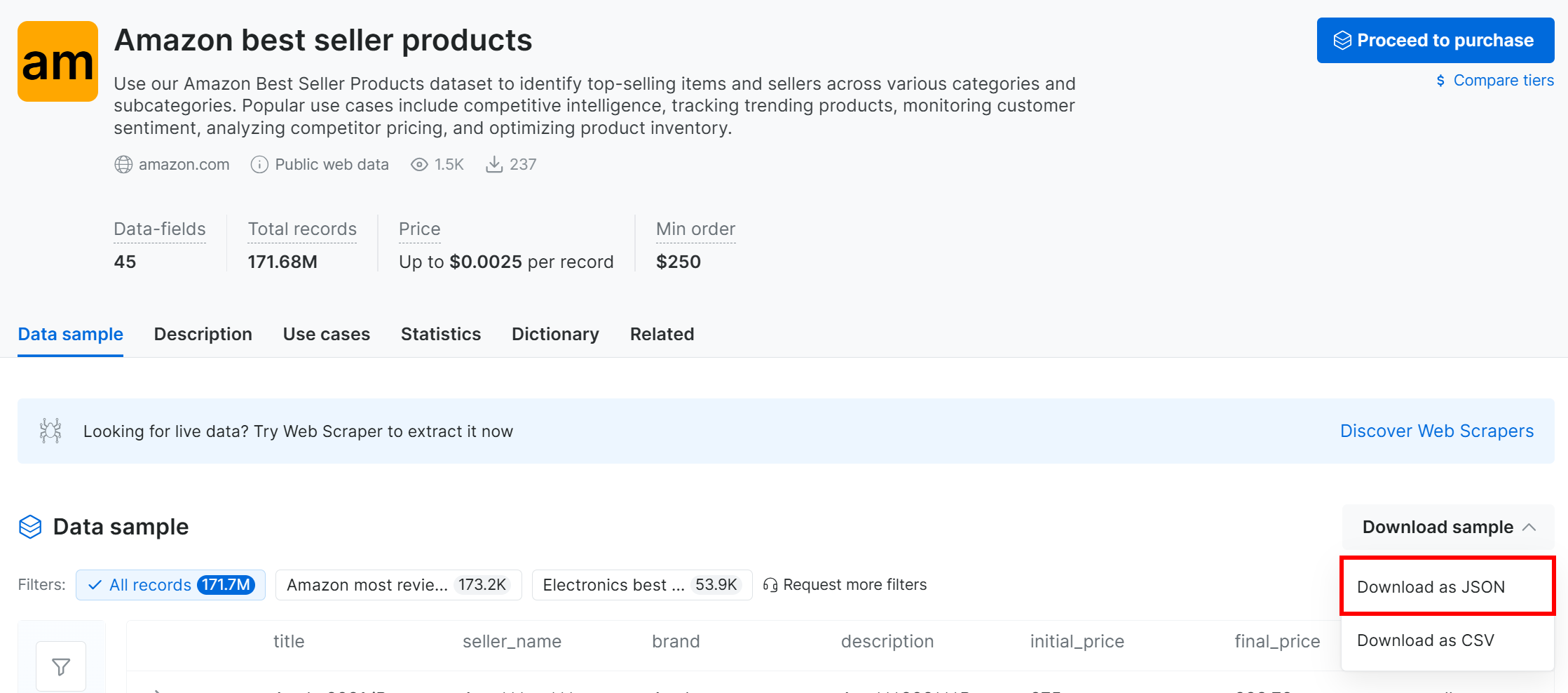
Recibirá un conjunto de datos de muestra con 1000 registros de productos más vendidos en Amazon. Algunos campos están parcialmente ocultos (mediante «***») por motivos de privacidad, pero el conjunto de datos completo está disponible tras el pago. Aun así, la muestra es suficiente para realizar experimentos sencillos con MLflow.
También puede descargar un conjunto de datos de muestra similar desde un repositorio GitHub dedicado.
Cambie el nombre del archivo del conjunto de datos descargado a products.json y colóquelo en la carpeta de su proyecto:
mlflow-experiment-tracking/
├── .venv/
├── experiment.py
├── mlflow.db
└── products.json # <--------Abra el archivo y verá lo siguiente: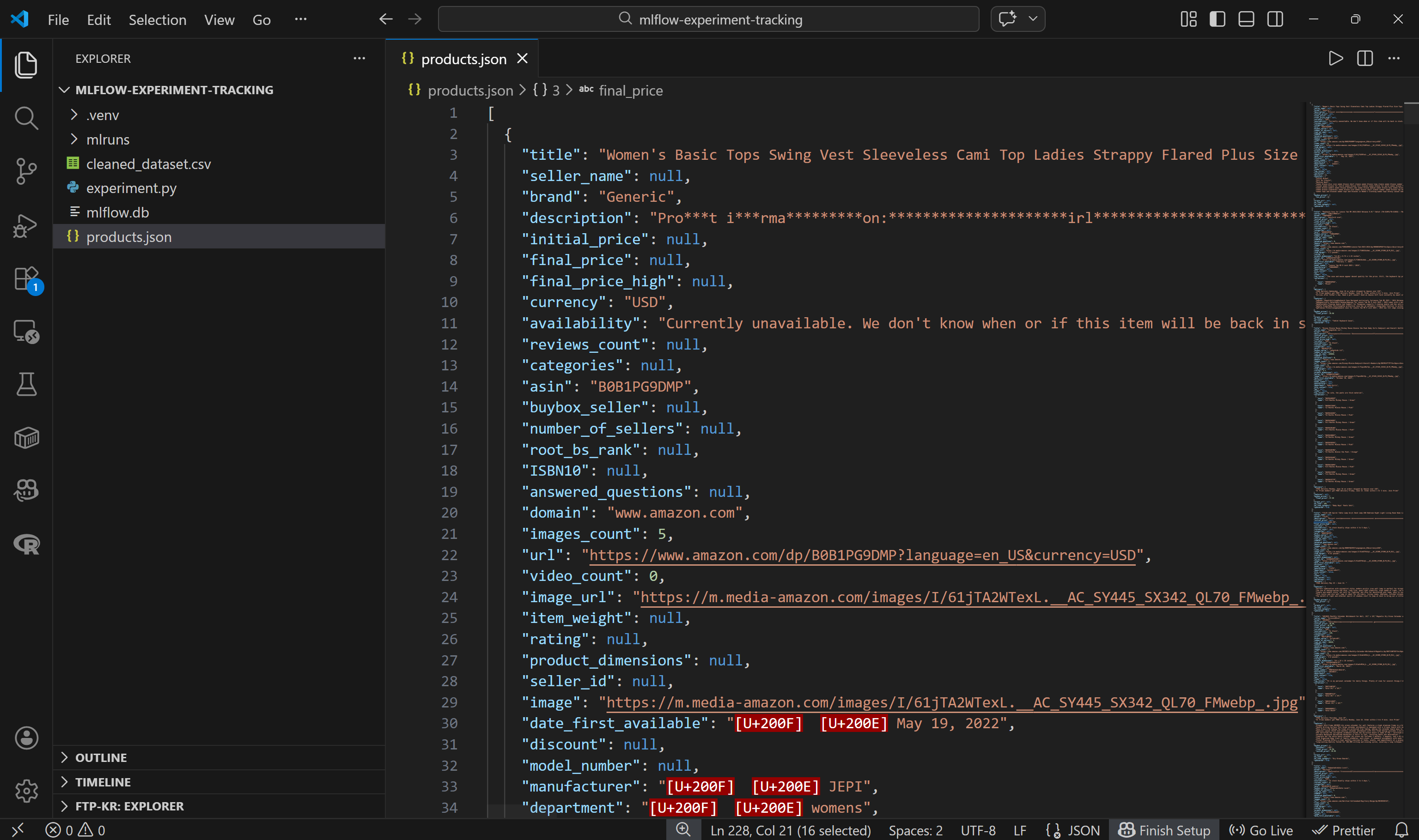
Tenga en cuenta que cada producto de Amazon se representa como un objeto JSON que contiene alrededor de 45 campos de datos. Esto proporciona una base rica para la experimentación.
¡Perfecto! Ahora ya está listo para cargar este conjunto de datos en su código y comenzar a procesarlo.
Paso n.º 5: cargar y preprocesar el conjunto de datos
Antes de cargar el conjunto de datos en su código, tómese un tiempo para explorar las columnas disponibles. Vaya a la pestaña «Diccionario» para ver información detallada sobre cada columna, incluida su descripción y porcentaje de presencia: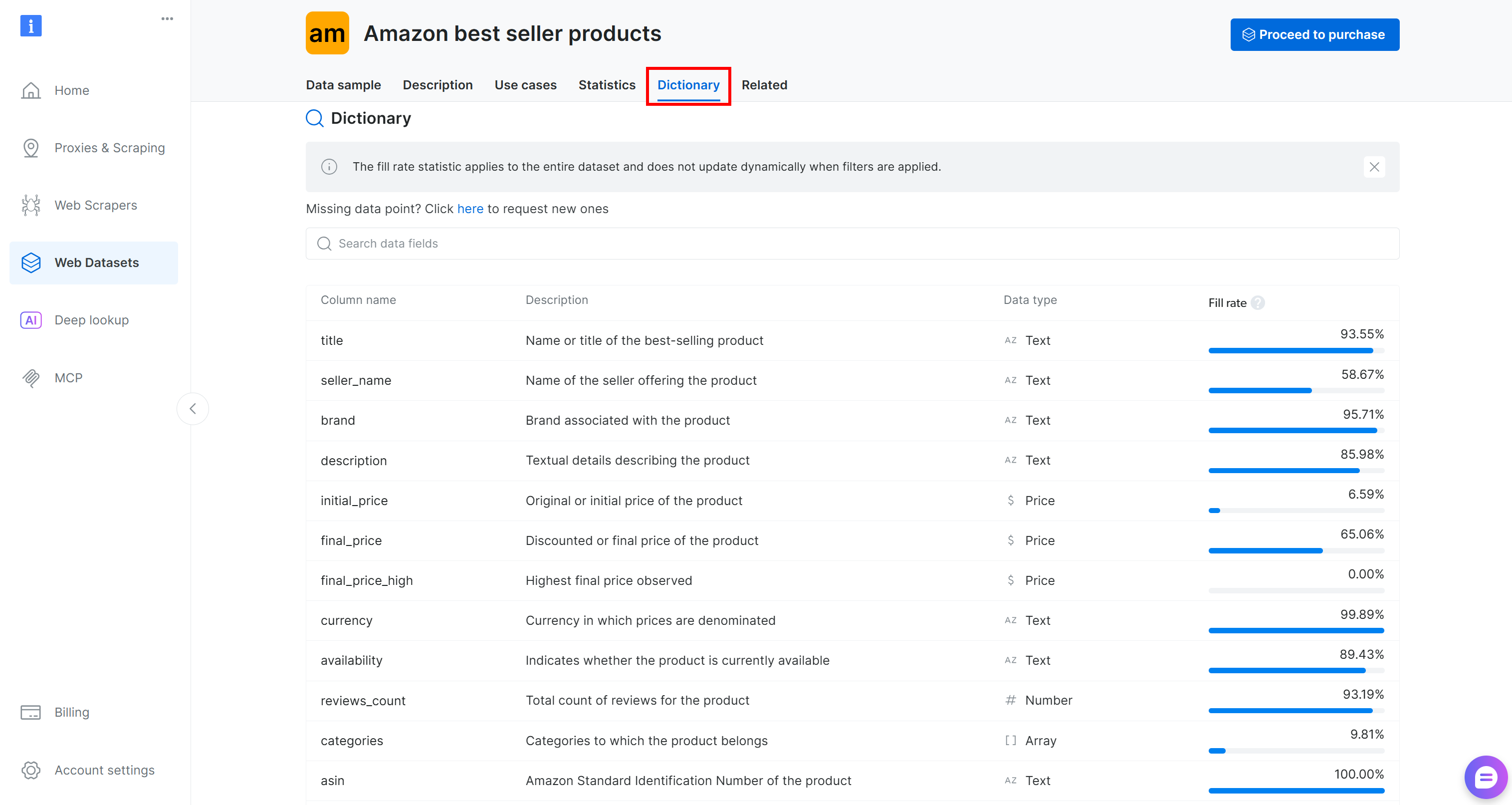
En este caso, las columnas de interés son:
marca(texto): marca asociada al producto.precio_final(precio): Precio con descuento o precio final del producto.reviews_count(número): Número total de reseñas.calificación(número): Calificación media del producto.
Ahora, carga el archivo JSON:
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)A continuación, conviértalo en un DataFrame de pandas:
df = pd.DataFrame(data)Si inspecciona la columna final_price, observará que a veces solo contiene valores numéricos (por ejemplo, 1500), mientras que otras veces incluye cadenas formateadas (por ejemplo, 1500 $).
Para un procesamiento coherente, convierte todos los precios a formato numérico y elimina las filas en las que final_price es nulo:
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
df = df.dropna(subset=["final_price"])Por último, registre el conjunto de datos en MLflow:
# Definir columnas de características y columna de destino
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Definir explícitamente la fuente del conjunto de datos
dataset_source = CodeDatasetSource(tags="v1")
# Registrar el conjunto de datos en MLflow con algunos metadatos
mlflow_dataset = mlflow.data.from_pandas(
df[CARACTERÍSTICAS + [OBJETIVO]],
fuente=fuente_del_conjunto_de_datos,
nombre="brightdata_products",
objetivos=OBJETIVO
)Este código define las características de entrada (calificación, recuento de reseñas, marca) y la variable objetivo (precio final) para su canalización de ML. A continuación, crea un objeto CodeDatasetSource y registra el DataFrame seleccionado en MLflow con metadatos para garantizar el seguimiento y la reproducibilidad del experimento.
¡Genial! Ahora ya está listo para utilizar estos datos en su canalización de entrenamiento de modelos.
Paso n.º 6: definir el proceso del modelo predictivo
Prepare sus datos para el entrenamiento del modelo ML utilizando la siguiente lógica:
# Separar características y objetivo
X = df[FEATURES]
y = df[TARGET]
# Canalización de preprocesamiento:
# - Imputación de mediana para columnas numéricas
# - Relleno constante + codificación one-hot para columnas categóricas
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Canalización completa de ML: preprocesamiento + modelo RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Este fragmento prepara los datos y crea un proceso completo de aprendizaje automático mediante:
- Separar las características de entrada (
calificación,recuento de reseñas,marca) del objetivo (precio final). - Manejar los valores perdidos con imputación de mediana para las características numéricas y relleno constante para las categóricas, y luego codificar el campo de texto
de la marcaen un formato numérico. Estas precauciones garantizan que el modelo reciba una entrada numérica limpia. - Combinar el preprocesamiento con un modelo Random Forest y dividir los datos en conjuntos de entrenamiento y prueba para su evaluación.
¡Genial! Es hora de ejecutar su experimento MLflow en el conjunto de datos recopilados por Bright Data.
Paso n.º 7: Ejecutar el experimento MLflow
Ahora tienes todos los elementos necesarios para ejecutar tu experimento MLflow. Ejecútalo con:
# Iniciar la ejecución de MLflow y habilitar el seguimiento de métricas del sistema
con mlflow.start_run(log_system_metrics=True) como ejecución:
# Registrar el conjunto de datos como entrada para la ejecución
mlflow.log_input(mlflow_dataset, context="training")
# Entrenar el modelo pipeline
pipeline.fit(X_train, y_train)
# Generar las predicciones en el conjunto de prueba
predictions = pipeline.predict(X_test)
# Registrar las métricas de evaluación (RMSE y R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predicciones))
mlflow.log_metric("r2_score", r2_score(y_test, predicciones))
# Registrar el conjunto de datos de salida CSV en un archivo local y luego como un artefacto en MLflow.
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Registrar el modelo entrenado con la firma y el ejemplo de entrada.
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Ejecución completada. Comprueba la pestaña 'Métricas del sistema' en la interfaz de usuario de MLflow para obtener el ID de ejecución: {run.info.run_id}")Esto es lo que hace el fragmento anterior:
- Inicia una ejecución de MLflow con el seguimiento de métricas del sistema habilitado.
- Registra
mlflow_datasetcomo entrada del experimento para garantizar la trazabilidad y la reproducibilidad. - Entrena el modelo ajustando el proceso completo de ML (preprocesamiento + Random Forest) a los datos de entrenamiento.
- Genera predicciones utilizando el modelo entrenado para predecir los valores objetivo en el conjunto de pruebas.
- Registra RMSE y R² en MLflow para evaluar el rendimiento del modelo.
- Registra el conjunto de datos limpio como un artefacto, para que puedas explorarlo en MLflow como referencia.
- Registra el proceso entrenado en MLflow, incluyendo su firma de entrada y un ejemplo de entrada para la reproducibilidad.
¡Genial! Solo queda explorar el código final y ejecutar su experimento MLflow.
Paso n.º 8: juntarlo todo y ejecutar el experimento
Tu archivo experiment.py debe contener:
# pip install mlflow pandas scikit-learn psutil nvidia-ml-py
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# Habilitar el registro automático de métricas del sistema (CPU, memoria, etc.)
mlflow.enable_system_metrics_logging()
# Registrar automáticamente eventos para sklearn
mlflow.sklearn.autolog()
# Configurar la frecuencia con la que se muestrean y registran las métricas del sistema (1 segundo)
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1)
# Cargar los datos de productos extraídos del archivo de Conjuntos de datos de entrada de Bright Data
# (descargar desde: /cp/datasets/browse/gd_l1vijixj9g2vp7563)
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Convertir JSON a un DataFrame de pandas
df = pd.DataFrame(data)
# Limpiar la columna de destino «final_price»:
# - Eliminar los signos de dólar y las comas
# - Convertir a numérico
# - Los valores no válidos se convierten en NaN
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
# Eliminar filas en las que falta el valor objetivo
df = df.dropna(subset=["final_price"])
# Definir columnas de características y columna objetivo
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Definir explícitamente la fuente del conjunto de datos
dataset_source = CodeDatasetSource(tags="v1")
# Registrar el conjunto de datos en MLflow con algunos metadatos
mlflow_dataset = mlflow.data.from_pandas(
df[CARACTERÍSTICAS + [OBJETIVO]],
fuente=fuente_del_conjunto_de_datos,
nombre="brightdata_products",
objetivos=OBJETIVO)
# Separar las características y el objetivo
X = df[CARACTERÍSTICAS]
y = df[TARGET]
# Canalización de preprocesamiento:
# - Imputación de mediana para columnas numéricas
# - Relleno constante + codificación one-hot para columnas categóricas
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Canalización completa de ML: preprocesamiento + modelo RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Dividir los conjuntos de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Establecer el experimento MLflow
mlflow.set_experiment("brightdata_product_price_prediction")
# Iniciar la ejecución de MLflow y habilitar el seguimiento de métricas del sistema
with mlflow.start_run(log_system_metrics=True) as run:
# Registrar el conjunto de datos como entrada para la ejecución
mlflow.log_input(mlflow_dataset, context="training")
# Entrenar el modelo pipeline
pipeline.fit(X_train, y_train)
# Generar las predicciones en el conjunto de prueba
predictions = pipeline.predict(X_test)
# Registrar las métricas de evaluación (RMSE y R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predicciones))
mlflow.log_metric("r2_score", r2_score(y_test, predicciones))
# Registrar el conjunto de datos de salida CSV en un archivo local y luego como un artefacto en MLflow.
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Registrar el modelo entrenado con la firma y el ejemplo de entrada.
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Ejecución completada. Comprueba la pestaña 'Métricas del sistema' en la interfaz de usuario de MLflow para obtener el ID de ejecución: {run.info.run_id}")Con el entorno Python activado, ejecute el experimento MLflow con:
python experiment.pyLa ejecución tardará unos segundos, así que ten paciencia.
¡Misión completada! Acaba de implementar un experimento MLflow de seguimiento de canalización con un conjunto de datos extraídos de Bright Data.
Paso n.º 9: Explora los resultados de seguimiento de MLflow
Visite la interfaz de usuario de MLflow en http://127.0.0.1:5000/. Debería ver una entrada del experimento brightdata_product_price_prediction (que es el nombre que se le ha dado al experimento MLflow en el código). Haga clic en ella:
Vaya a la sección «Training runs» (Ejecuciones de entrenamiento) para obtener más detalles:
Deberías ver la última ejecución que acabas de realizar:
Haga clic en ella para acceder inmediatamente a más de 15 métricas: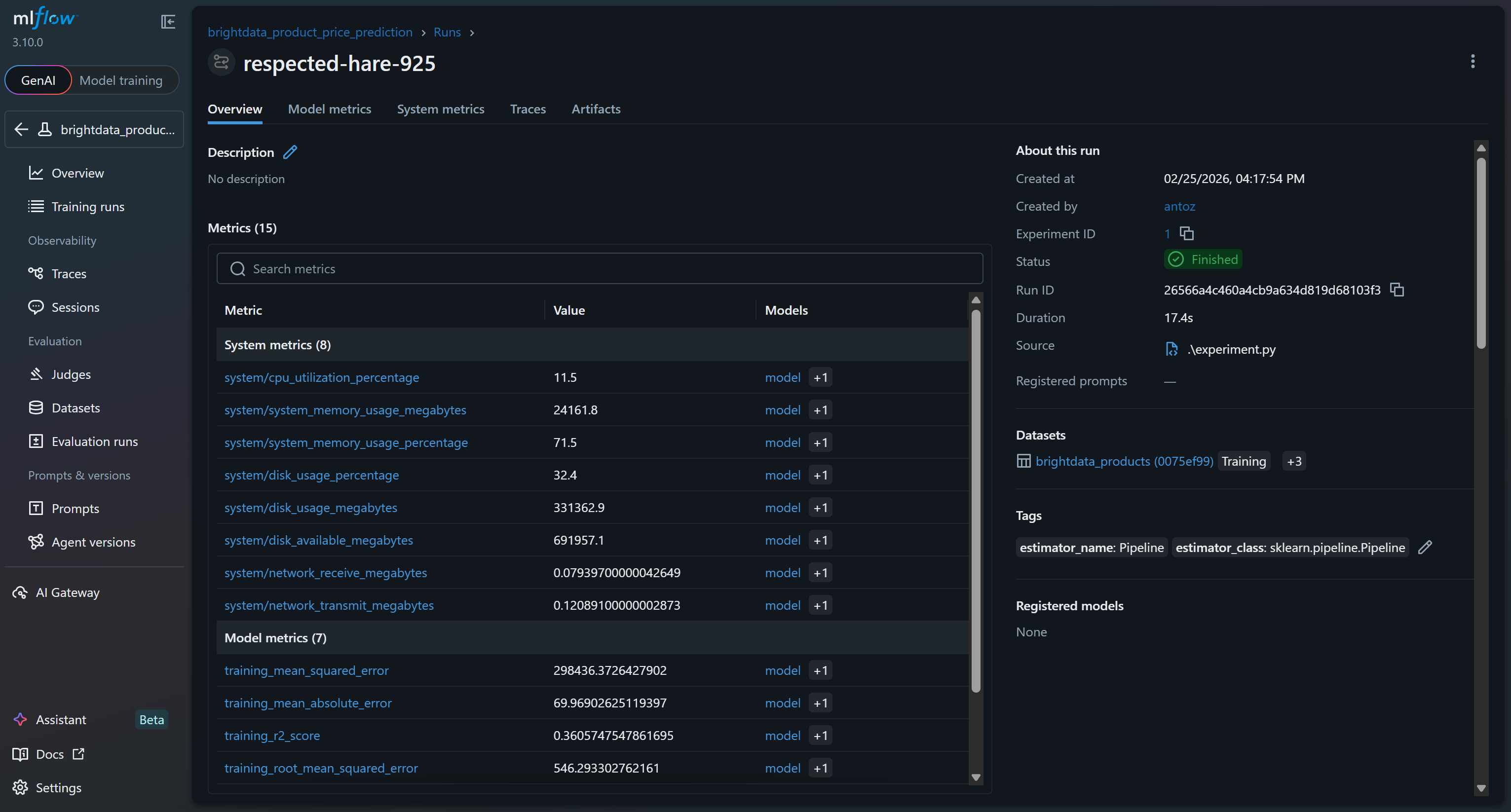
Estas incluyen métricas del sistema y del modelo recopiladas automáticamente por las funciones de seguimiento de MLflow, así como métricas del modelo registradas durante la ejecución (por ejemplo, val_rmse, r2_score).
Para explorar las métricas del modelo, acceda a la pestaña correspondiente: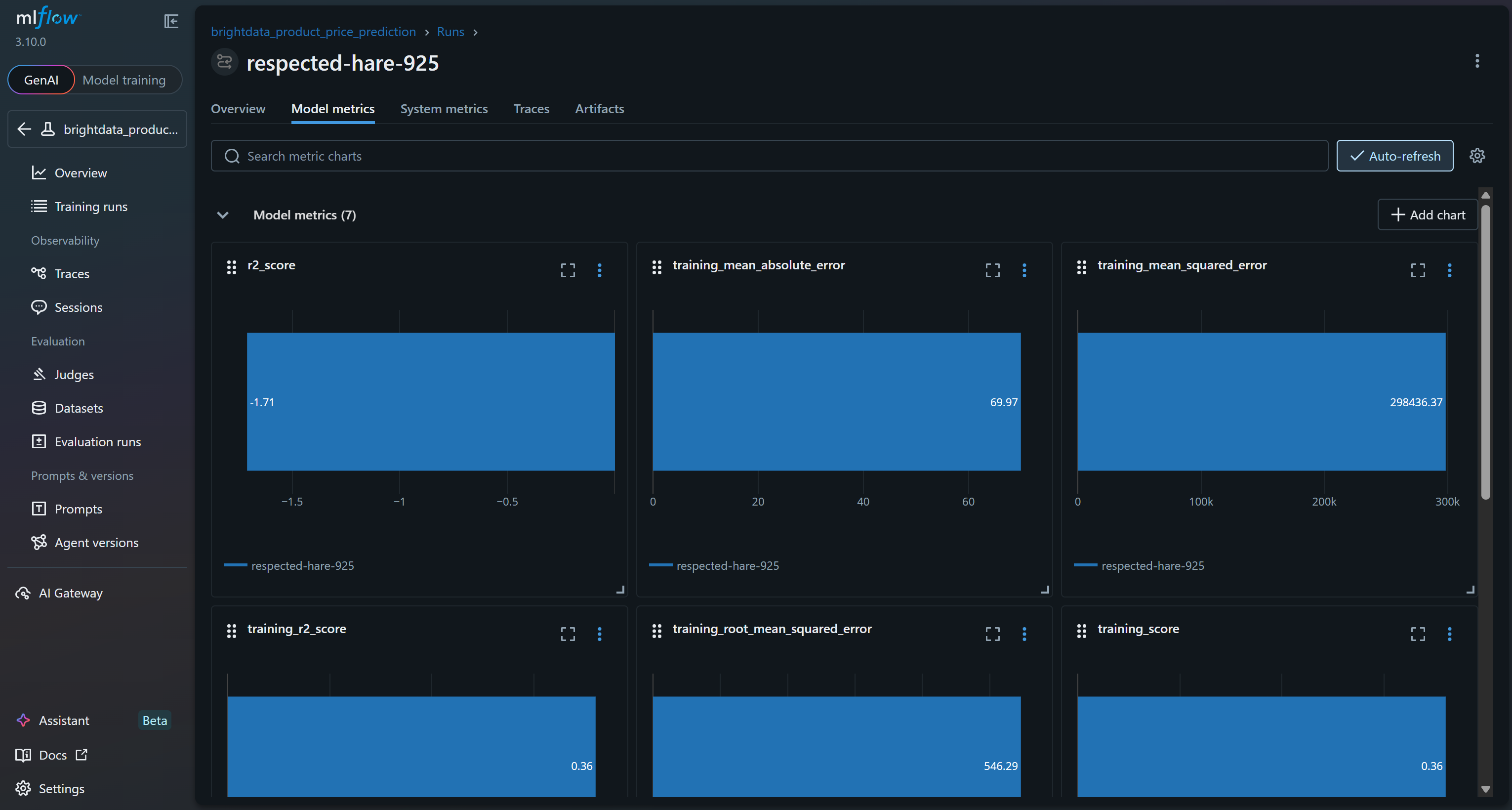
O revise los gráficos de métricas del sistema en la pestaña «Métricas del sistema»: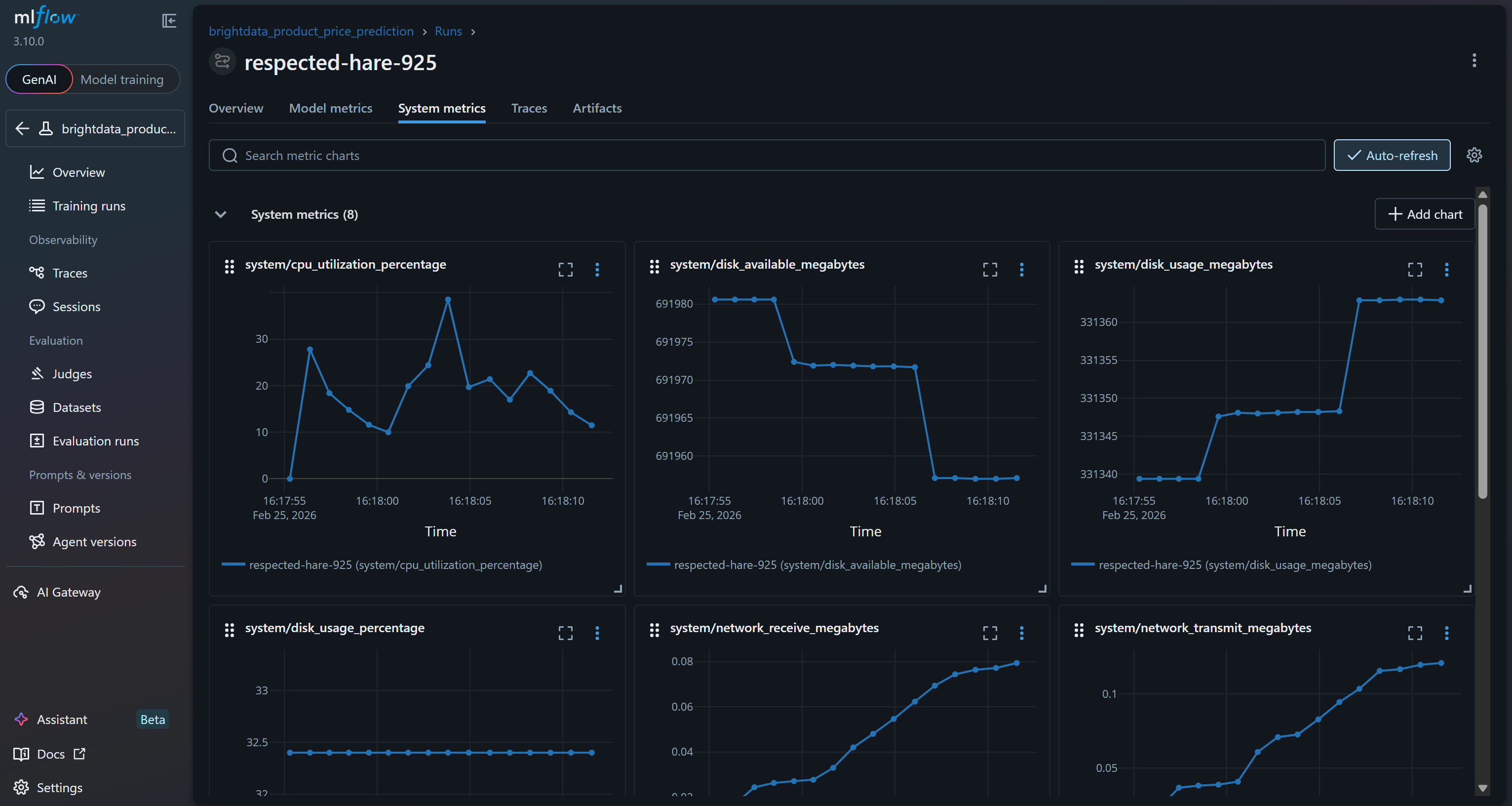
Además, la sección «Artefactos» muestra los archivos de salida (como el archivo cleaned_dataset.csv, tal y como se registra en su código):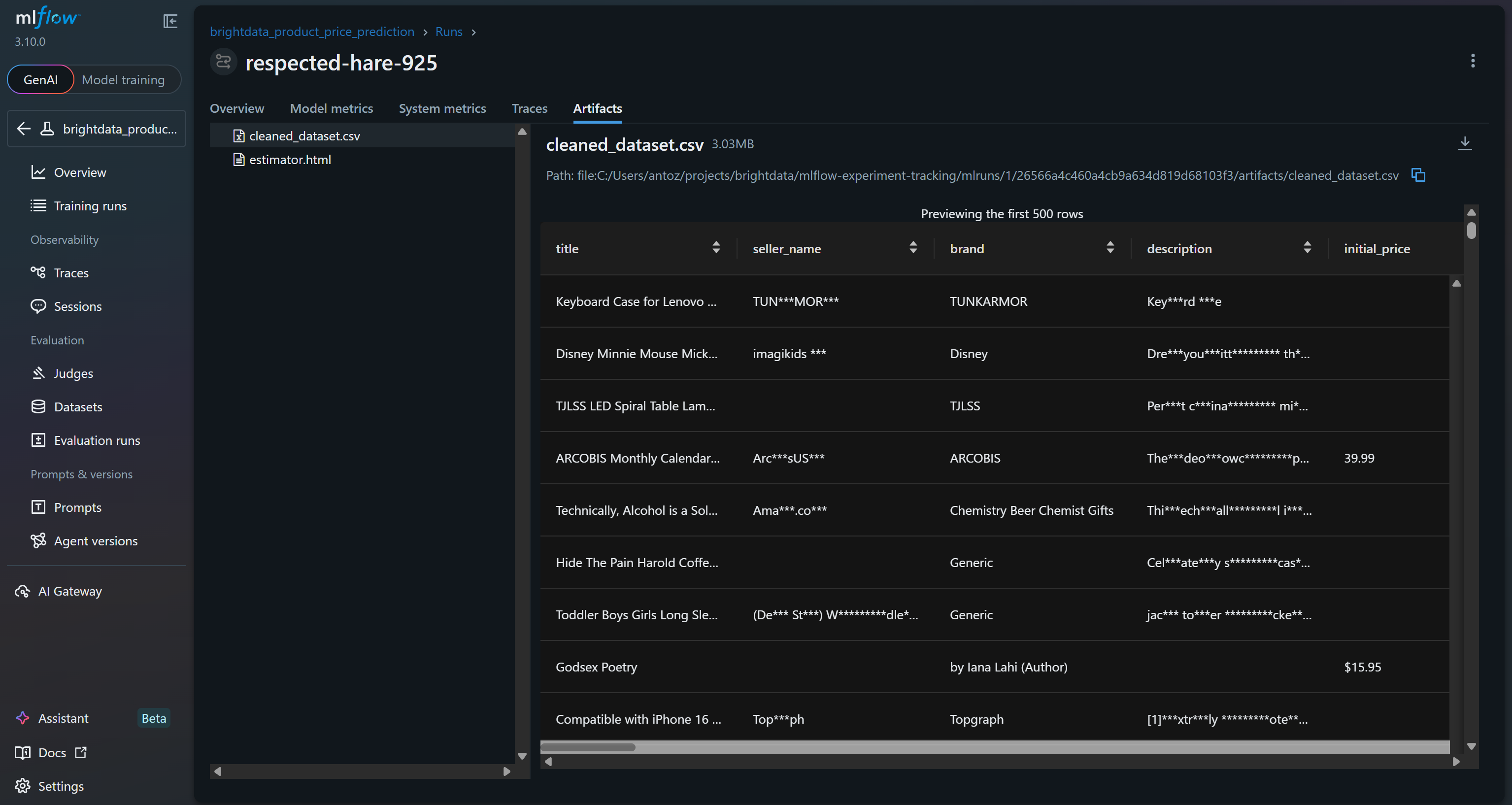
¡Estas son solo algunas de las métricas y resultados que puede rastrear gracias a un experimento de MLflow creado a partir de un conjunto de datos recopilados por Bright Data!
Paso n.º 10: Comente los resultados
Para verificar que el proceso de entrenamiento del modelo ha funcionado, céntrese en las métricas del modelo: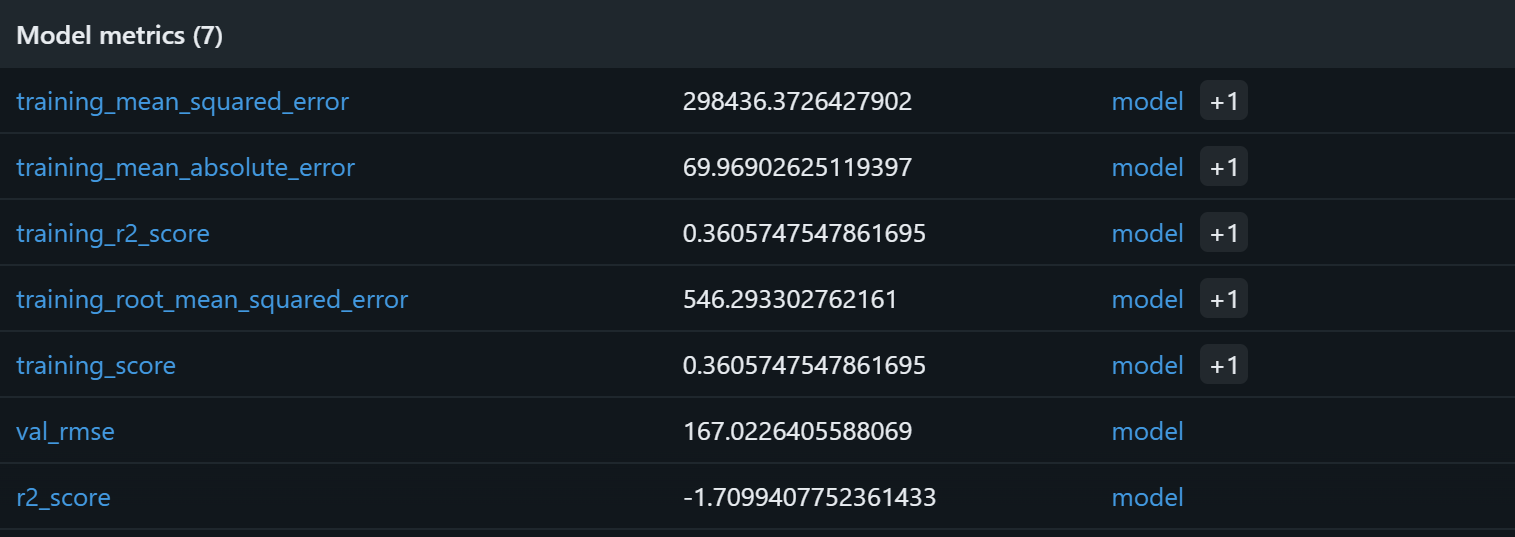
Según estas métricas del modelo, es probable que el proceso actual produzca predicciones sin sentido en el conjunto de validación. El R² de entrenamiento de 0,36 indica que el modelo explica aproximadamente el 36 % de la varianza en los datos de entrenamiento, lo cual es modesto. El RMSE de entrenamiento (546) y el MAE (~70) sugieren que los errores son bastante altos en relación con los precios típicos de los productos, posiblemente debido a datos ruidosos o a correlaciones débiles entre las características y el objetivo.
Más preocupante es el rendimiento de la validación: el R² es negativo (-1,71) y el RMSE de validación (167) sigue siendo significativo. Un R² negativo implica que el modelo funciona peor que la simple predicción del precio medio de todas las muestras. Eso indica que la relación supuesta entre la calificación, el número de reseñas, la marca y el precio final puede no ser lo suficientemente fuerte o lineal como para que un bosque aleatorio la capte de manera eficaz.
Las posibles mejoras incluyen ampliar el conjunto de características, realizar ingeniería de características (por ejemplo, transformar logarítmicamente el número de reseñas, codificar la popularidad de la marca), probar modelos alternativos como el gradient boosting o XGBoost, y aumentar el tamaño del conjunto de datos más allá del subconjunto de 1000 muestras. Con un conjunto de datos de Bright Data más grande, dispondría de más datos y variedad, lo que permitiría realizar experimentos más profundos y relevantes.
En resumen, el proceso actual funciona técnicamente, pero no logra captar adecuadamente los patrones de precios subyacentes. Gracias al seguimiento de experimentos de MLflow, se pudo identificar que las hipótesis en las que se basa este proceso de aprendizaje automático probablemente sean erróneas.
Próximos pasos
Si desea utilizar MLflow para rastrear procesos de IA con Conjuntos de datos de Bright Data para el ajuste fino o RAG, recuerde que el rastreo de MLflow es totalmente compatible con OpenTelemetry. En concreto, MLflow proporciona una solución de observabilidad LLM que captura las entradas, salidas y metadatos de cada paso intermedio de una solicitud.
Al integrarlo con OpenAI, puede habilitarlo fácilmente con:
import mlflow
mlflow.openai.autolog() Para obtener más detalles, consulte la documentación oficial de MLflow.
Conclusión
En este tutorial, ha visto lo que MLflow aporta a la creación y el seguimiento de procesos de aprendizaje automático e IA. También ha comprendido por qué los Conjuntos de datos recopilados son excelentes fuentes para entrenar o ajustar modelos.
Como se ha demostrado, Bright Data ofrece un rico mercado de conjuntos de datos que abarca cientos de dominios y miles de millones de registros de datos web. Estos conjuntos de datos se actualizan continuamente mediante el Scraping web para dar soporte a los flujos de trabajo de aprendizaje automático e IA. En concreto, son perfectamente compatibles con el seguimiento de MLflow, como se muestra aquí.
¡Crea una cuenta gratuita en Bright Data y empieza a explorar nuestras soluciones de datos web hoy mismo!





