

En esta guía, verás:
- Qué significa scrapear una página web a Markdown y por qué es útil.
- Los principales enfoques para convertir el HTML de una página web a Markdown para sitios estáticos y dinámicos.
- Cómo utilizar Python para scrapear una página web a Markdown.
- Las limitaciones de esta solución y cómo superarlas con Bright Data.
¡Vamos a sumergirnos!
¿Qué significa “scrapear una página web a Markdown”?
Scrapear una página web a Markdown” significa convertir su contenido a Markdown.
Más concretamente, se refiere a tomar el HTML de una página web y transformarlo en el formato de datos Markdown.
Por ejemplo, conéctate a un sitio, abre las DevTools y copia su HTML:
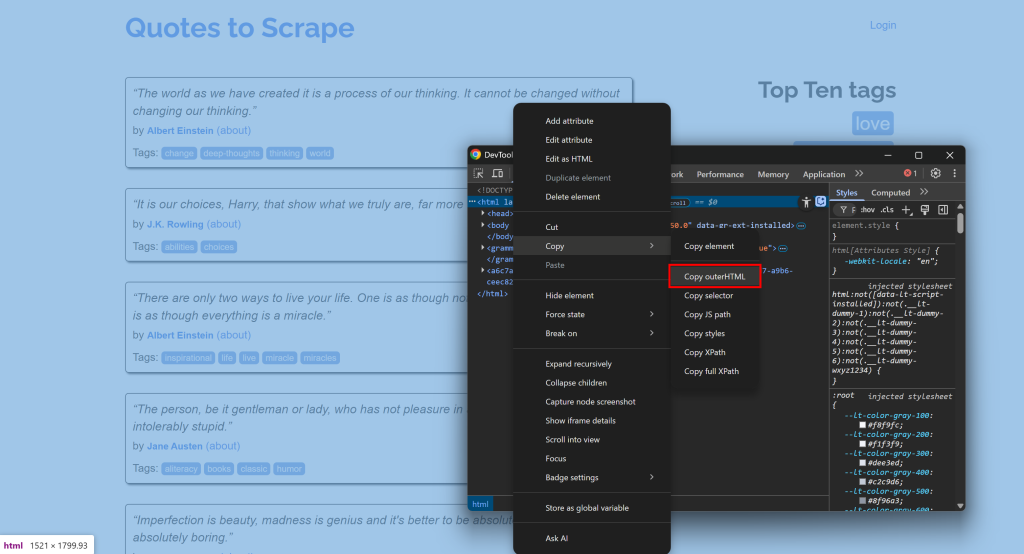
A continuación, pégalo en un conversor de HTML a Markdown:
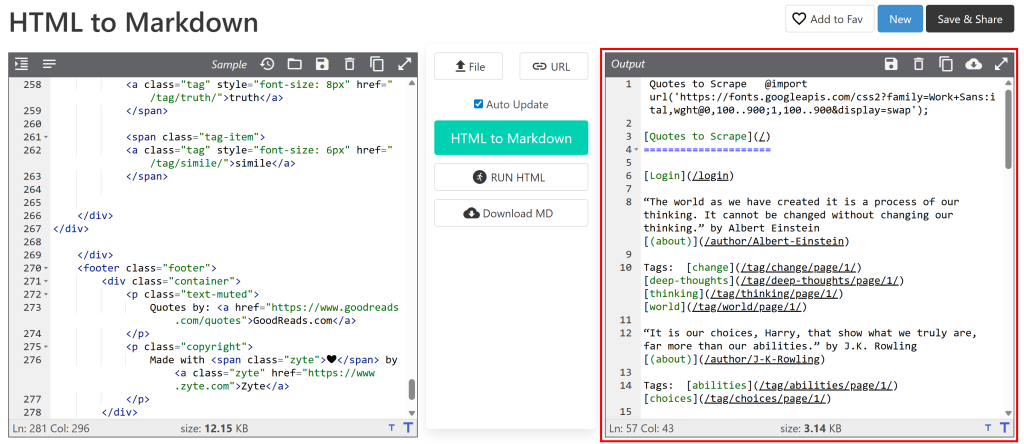
El resultado será similar al documento Markdown que quieres obtener mediante Scraping web. Ahora el objetivo es automatizar este proceso, ¡que es exactamente de lo que trata este artículo!
[Extra] ¿Por qué Markdown?
¿Por qué Markdown en lugar de otro formato (como texto plano)? Porque, como se muestra en nuestro benchmark de formatos de datos, Markdown es uno de los mejores formatos para la ingestión de LLM. Las tres razones principales son:
- Conserva la mayor parte de la estructura e información de la página (por ejemplo, enlaces, imágenes, encabezados, etc.).
- Es conciso, lo que limita el uso de tokens y acelera el procesamiento de IA.
- Los LLM tienden a entender Markdown mucho mejor que el HTML plano.
Por eso, las mejores herramientas de raspado de IA trabajan por defecto con Markdown.
Enfoques de HTML a Markdown
Ahora ya sabes que raspar un sitio a Markdown significa simplemente convertir el HTML de sus páginas a Markdown. A grandes rasgos, el proceso es el siguiente:
- Conectarse al sitio.
- Recupera el HTML como una cadena.
- Utilizar una biblioteca de HTML a Markdown para generar la salida Markdown.
El reto es que no todas las páginas web se entregan de la misma manera. Los dos primeros pasos pueden variar significativamente dependiendo de si la página de destino es estática o dinámica. Exploremos cómo manejar ambos escenarios expandiendo los pasos requeridos.
Paso nº 1: Conectarse a un sitio
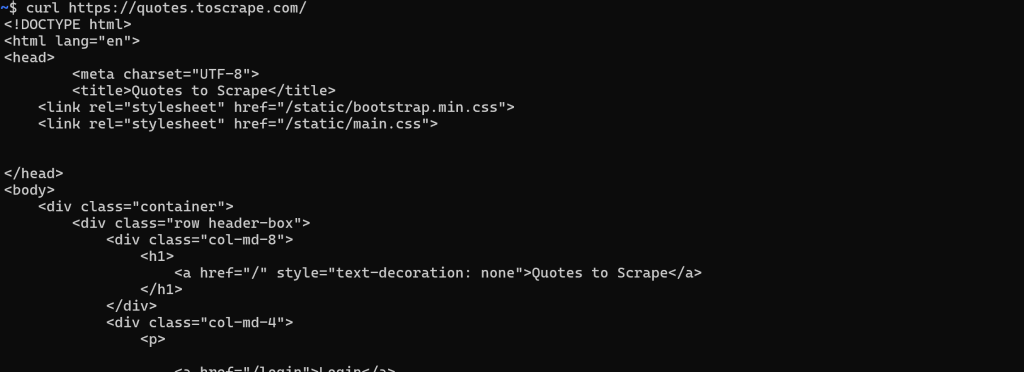
En una página web estática, el documento HTML devuelto por el servidor es exactamente lo que se ve en el navegador. En otras palabras, todo está fijo e incrustado en el HTML producido por el servidor.
En este caso, recuperar el HTML es sencillo. Basta con realizar una petición GET HTTP a la URL de la página con cualquier cliente HTTP:
Por el contrario, en un sitio web dinámico, la mayor parte (o parte) del contenido se recupera mediante AJAX y se renderiza en el navegador a través de JavaScript. Esto significa que el documento HTML inicial devuelto por el servidor web sólo contiene lo mínimo indispensable. Sólo después de que JavaScript se ejecuta en el lado del cliente, la página se rellena con el contenido completo:

En estos casos, no se puede obtener el HTML con un simple cliente HTTP. En su lugar, se necesita una herramienta que realmente pueda renderizar la página, como una herramienta de automatización del navegador. Soluciones como Playwright, Puppeteer o Selenium le permiten controlar mediante programación un navegador para cargar la página de destino y obtener su HTML completamente renderizado.
Paso 2: Recuperar el HTML como cadena
Para páginas web estáticas, este paso es sencillo. La respuesta del servidor web a su solicitud GET ya contiene el documento HTML completo como una cadena. La mayoría de los clientes HTTP, como Requests de Python, proporcionan un método o campo para acceder a ella directamente:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Accede al contenido HTML de la página como una cadena
html = response.textPara los sitios web dinámicos, las cosas son mucho más complicadas. En este caso, no le interesa el documento HTML sin procesar devuelto por el servidor. En su lugar, debe esperar a que el navegador renderice la página, el DOM se estabilice y, a continuación, acceder al HTML final.
Esto corresponde a lo que normalmente haría manualmente abriendo DevTools y copiando el HTML del nodo <html>:
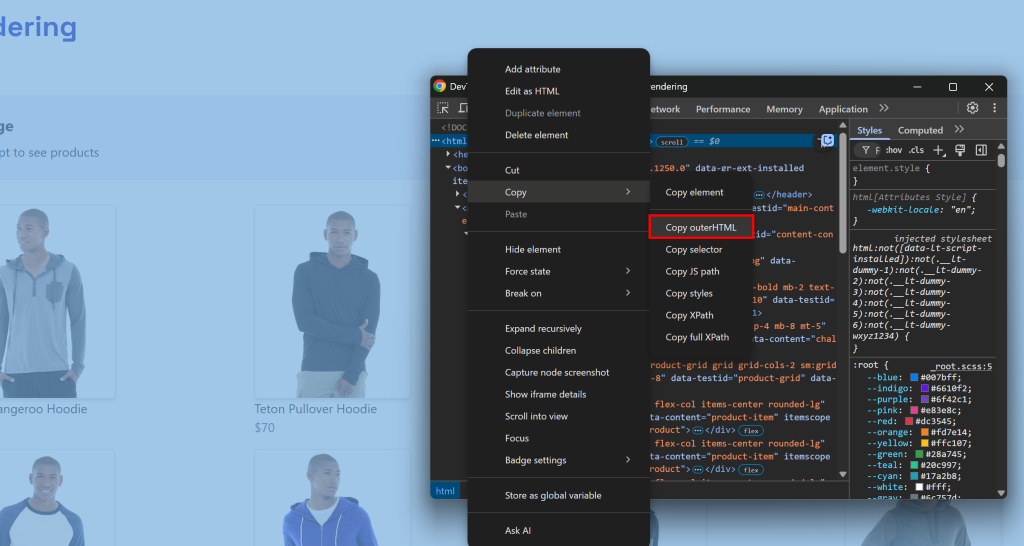
El reto es saber cuándo la página ha terminado de renderizarse. Las estrategias comunes incluyen:
- Esperar al evento
DOMContentLoaded: Se dispara cuando el HTML inicial es parseado ylos <script>sdiferidos son cargados y ejecutados. Esperar a este evento es el comportamiento predeterminado de Playwright. - Esperar al evento
load: Se dispara cuando se ha cargado toda la página, incluidas las hojas de estilo, los scripts, los iframes y las imágenes (excepto las cargadas perezosamente). - Esperar al evento
networkidle: Considera finalizada la renderización cuando no hay peticiones de red durante un tiempo determinado (por ejemplo,500 msen Playwright). Esto no es fiable para sitios con contenido que se actualiza en tiempo real, ya que nunca se activará. - Esperar elementos específicos: Utilice las API de espera personalizadas proporcionadas por los marcos de automatización del navegador para esperar a que aparezcan determinados elementos en el DOM.
Una vez que la página esté completamente renderizada, puede extraer el HTML utilizando el método/campo específico proporcionado por la herramienta de automatización del navegador. Por ejemplo, en Playwright
html = await page.content()Paso 3: Utilizar una librería HTML-to-Markdown para generar la salida Markdown
Una vez que haya recuperado el HTML como cadena, sólo tiene que introducirlo en una de las muchas bibliotecas de HTML a Markdown disponibles. Las más populares son
| Biblioteca | Lenguaje de programación | Estrellas de GitHub |
|---|---|---|
markdownify |
Python | 1.8k+ |
reducción |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-to-markdown |
Ir | 3k+ |
html-to-markdown |
PHP | 1.8k+ |
Scraping de un sitio web a Markdown: Ejemplos prácticos en Python
En esta sección, verás fragmentos completos de Python para convertir un sitio web a Markdown. Los scripts a continuación implementarán los pasos explicados anteriormente. Tenga en cuenta que puede convertir fácilmente la lógica a JavaScript o a cualquier otro lenguaje de programación.
La entrada será la URL de una página web, y la salida será el contenido Markdown correspondiente.
Sitios estáticos
En este ejemplo, utilizaremos las dos bibliotecas siguientes:
requests: Para hacer la petición GET y obtener el HTML de la página como una cadena.markdownify: Para convertir el HTML de la página en Markdown.
Instala ambas con:
pip install requests markdownifyLa página objetivo será la página estática “Quotes to Scrape“. Puedes conseguir el objetivo con el siguiente snippet:
import requests
from markdownify import markdownify as md
# La URL de la página a raspar
url = "http://quotes.toscrape.com/"
# Recuperar el contenido HTML mediante requests
response = requests.get(url)
# Obtener el HTML como cadena
contenido_html = respuesta.texto
# Convierte el contenido HTML a Markdown
markdown_content = md(html_content)
# Imprimir la salida Markdown
print(contenido_marcado)Opcionalmente, puede exportar el contenido a un archivo .md con
with open("pagina.md", "w", encoding="utf-8") as f:
f.write(markdown_content)El resultado del script será:
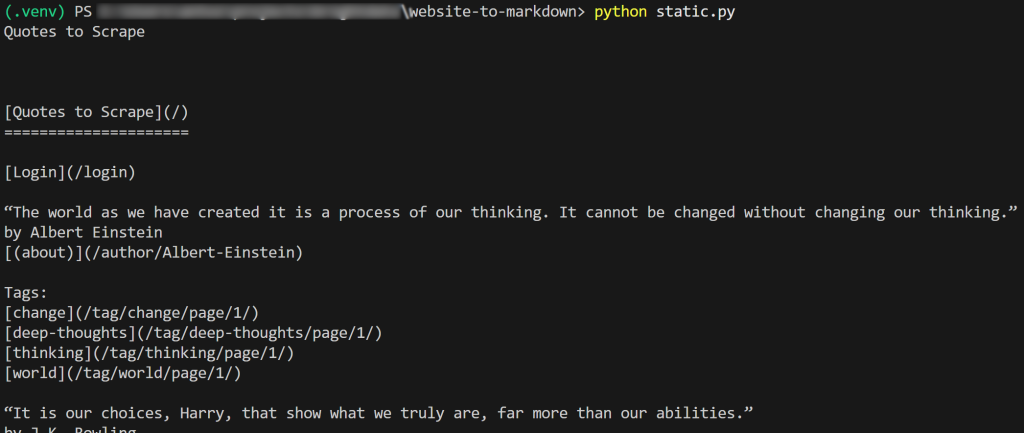
Si copias el Markdown de salida y lo pegas en un renderizador Markdown, lo verás:
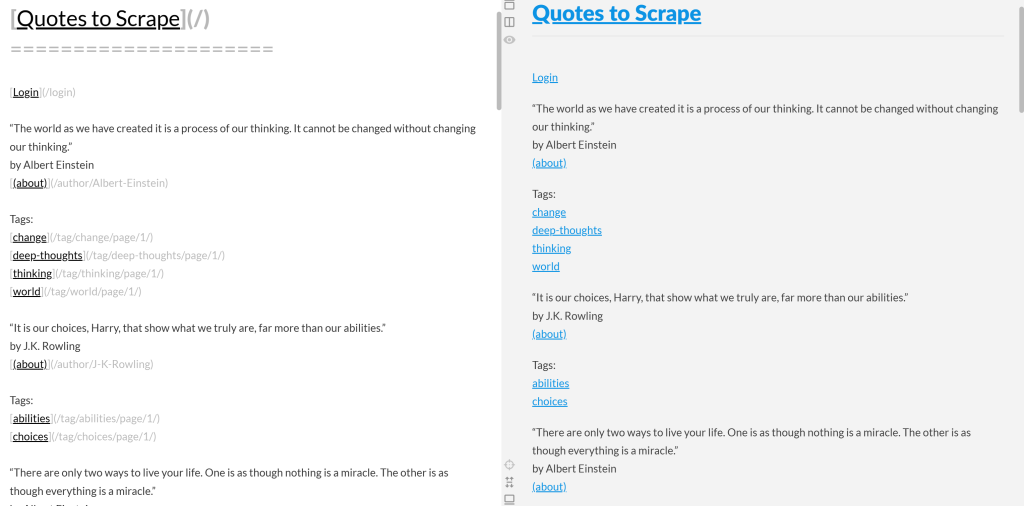
Fíjate en que parece una versión simplificada del contenido original de la página “Quotes to Scrape”:
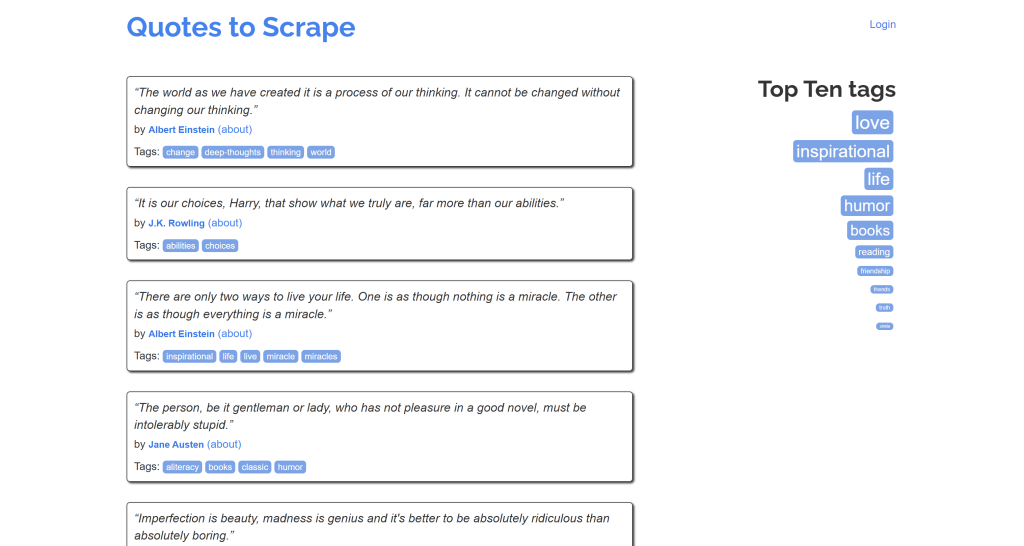
¡Misión cumplida!
Sitios dinámicos
Aquí utilizaremos estas dos bibliotecas:
playwright: Para renderizar la página de destino en una instancia controlada del navegador.markdownify: Para convertir el DOM renderizado de la página en Markdown.
Instale las dos dependencias anteriores con:
pip install playwright markdownifyA continuación, complete la instalación de Playwright con:
python -m playwright installEl destino será la página dinámica “JavaScript Rendering” del sitio ScrapingCourse.com:
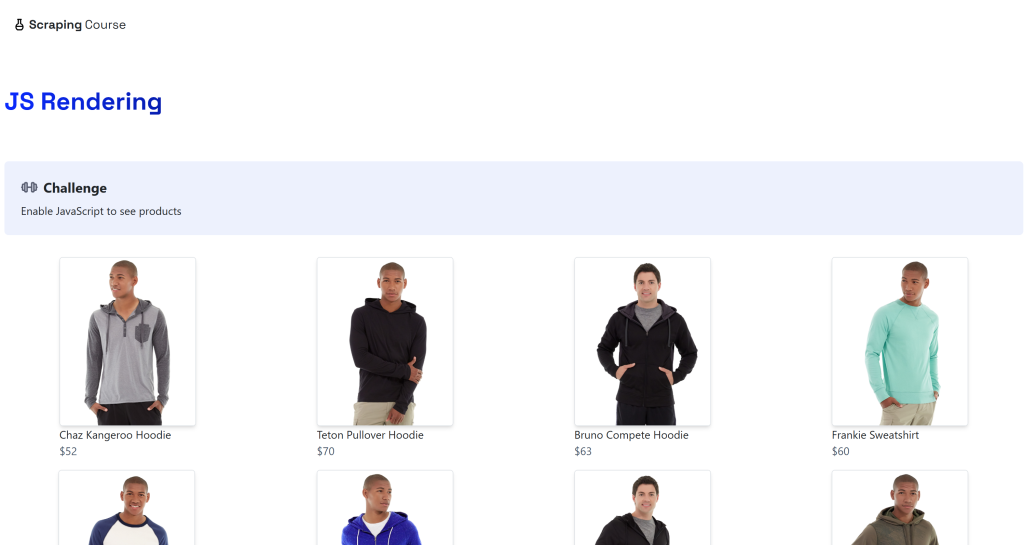
Esta página recupera datos en el lado del cliente mediante AJAX y los renderiza utilizando JavaScript:
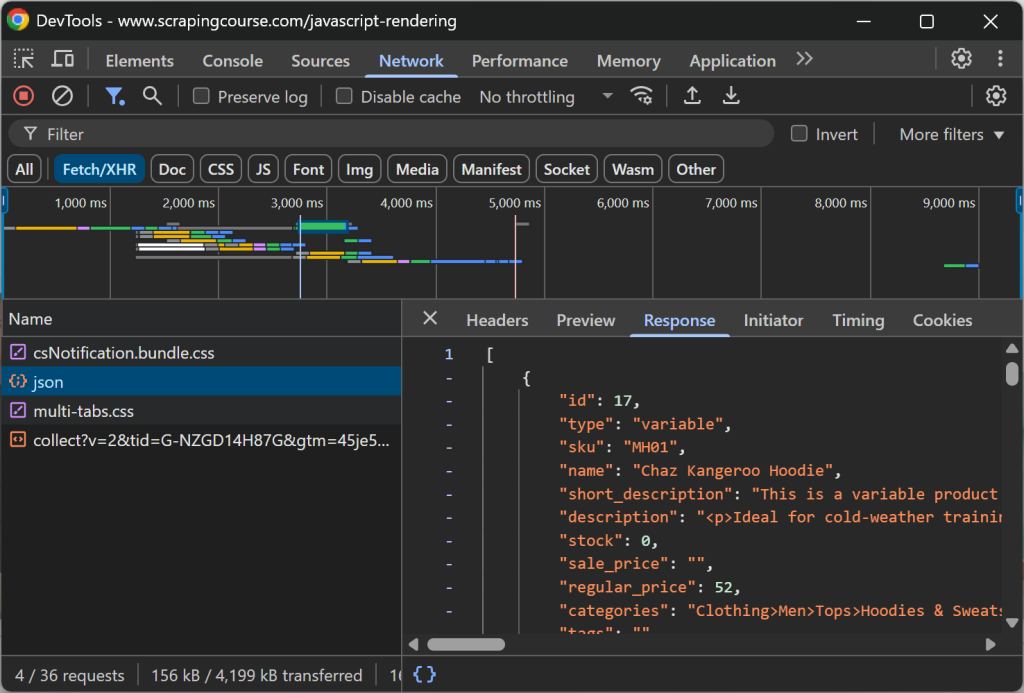
Raspe un sitio web dinámico a Markdown como se indica a continuación:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Lanzar un navegador headless
browser = p.chromium.launch()
page = navegador.nueva_página()
# URL de la página dinámica
url = "https://scrapingcourse.com/javascript-rendering"
# Navega a la página
page.goto(url)
# Esperar hasta 5 segundos a que se rellene el primer elemento de enlace de producto
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Obtener el HTML completamente renderizado
rendered_html = page.content()
# Convertir HTML a Markdown
markdown_content = md(rendered_html)
# Imprima el Markdown resultante
print(contenido_marcado)
# Cerrar el navegador y liberar sus recursos
browser.close()En el fragmento anterior, optamos por la opción 4 (“Esperar a elementos específicos”) porque es la más fiable. En detalle, eche un vistazo a esta línea de código:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)Esto espera hasta 5000 milisegundos (5 segundos) a que el elemento .product-link (una etiqueta <a> ) tenga un atributo href no vacío. Esto es suficiente para indicar que el primer elemento producto de la página ha sido renderizado, lo que significa que los datos han sido recuperados y el DOM es ahora estable.
El resultado será:
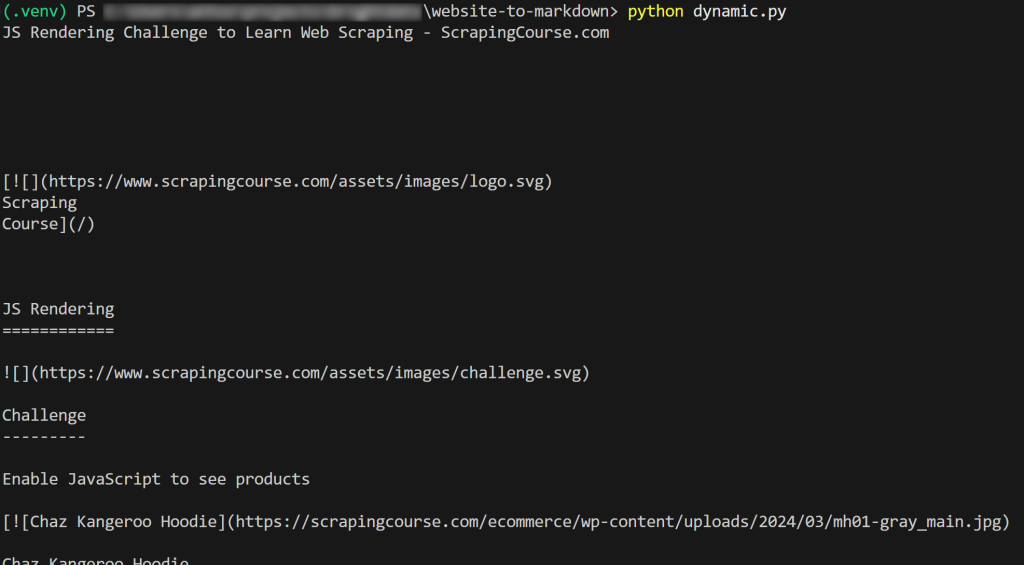
¡Et voilà! Acabas de aprender cómo scrapear un sitio web a Markdown.
Limitaciones de estos enfoques y la solución
Todos los ejemplos de esta entrada del blog tienen un aspecto fundamental en común: ¡se refieren a páginas que fueron diseñadas para ser fáciles de scrapear!
Por desgracia, la mayoría de las páginas web del mundo real no están tan abiertas a los robots de Scraping web. Más bien al contrario, muchos sitios implementan protecciones anti-scraping como CAPTCHAs, prohibiciones de IP, huellas dactilares del navegador, etc.
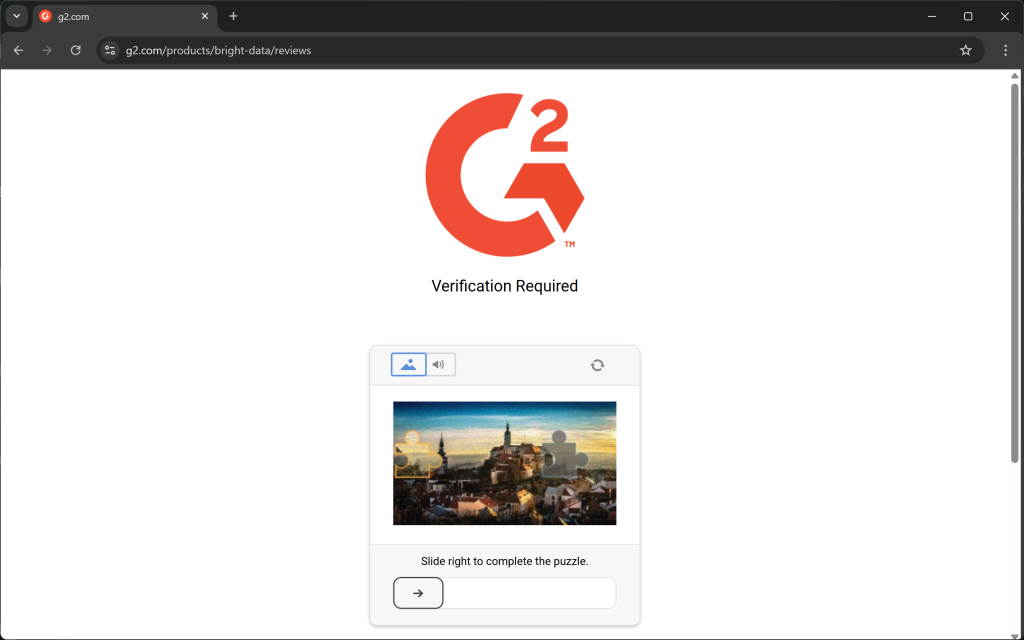
En otras palabras, no se puede esperar que una simple petición HTTP o una instrucción goto() de Playwright funcionen según lo previsto. Al atacar la mayoría de los sitios web del mundo real, puede encontrarse con errores 403 Forbidden:

O páginas de error / verificación humana:
Otro aspecto clave a tener en cuenta es que la mayoría de las bibliotecas HTML-to-Markdown realizan una conversión de datos sin procesar. Esto puede conducir a resultados no deseados. Por ejemplo, si una página contiene elementos <style> o <script> incrustados directamente en el HTML, su contenido (es decir, código CSS y JavaScript, respectivamente) se incluirá en la salida Markdown:

Por lo general, esto no es deseable, especialmente si planea enviar el Markdown a un LLM para el procesamiento de datos. Después de todo, esos elementos de texto sólo añaden ruido.
¿Cuál es la solución? Confiar en una API dedicada de Web Unlocker que puede acceder a cualquier sitio, independientemente de sus protecciones, y producir Markdown listo para el LLM. Esto garantiza que el contenido extraído esté limpio, estructurado y listo para las tareas de IA posteriores.
Scraping a Markdown con Web Unlocker
Web Unlocker de Bright Data es una API de Scraping web basada en la nube que puede devolver el HTML de cualquier página web. Esto es así independientemente de las protecciones anti-scraping o anti-bot existentes, y de si la página es estática o dinámica.
La API está respaldada por una red de Proxy de más de 150 millones de IPs, lo que le permite centrarse en la recopilación de datos mientras Bright Data se encarga de toda la infraestructura de desbloqueo, renderizado de JavaScript, Resolución de CAPTCHA, escalado y actualizaciones de mantenimiento.
Utilizarlo es sencillo. Realice una solicitud POST HTTP a Web Unlocker con los argumentos correctos y obtendrá de vuelta la página web totalmente desbloqueada. También puede configurar la API para que devuelva el contenido en formato Markdown optimizado para LLM.
Sigue la guía de configuración inicial, y luego utiliza Web Unlocker para scrapear un sitio web a Markdown con sólo unas pocas líneas de código:
# pip install peticiones
importar peticiones
# Sustituya esto por los valores correctos de su cuenta de Bright Data
BRIGHT_DATA_API_KEY= "<SU_CLAVE_API_DE_BRIGHT_DATA>"
WEB_UNLOCKER_ZONE = "<SU_NOMBRE_DE_LA_ZONA_DE_DESBLOQUEO_WEB>"
# Reemplace con su URL de destino
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Preparar las cabeceras necesarias
cabeceras = {
"Authorization": f "Bearer {BRIGHT_DATA_API_KEY}", # Para autenticación
"Content-Type": "application/json"
}
# Preparar la carga útil POST de Web Unlocker
payload = {
"url": url_to_scrape,
"zona": WEB_UNLOCKER_ZONE,
"formato": "raw",
"data_format": "markdown" # Para obtener la respuesta como contenido Markdown
}
# Realizar una solicitud POST a la API de Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=carga de pago,
cabeceras=cabeceras
)
# Obtener la respuesta Markdown e imprimirla
markdown_content = respuesta.texto
print(contenido_marcado)Ejecute el script y obtendrá:
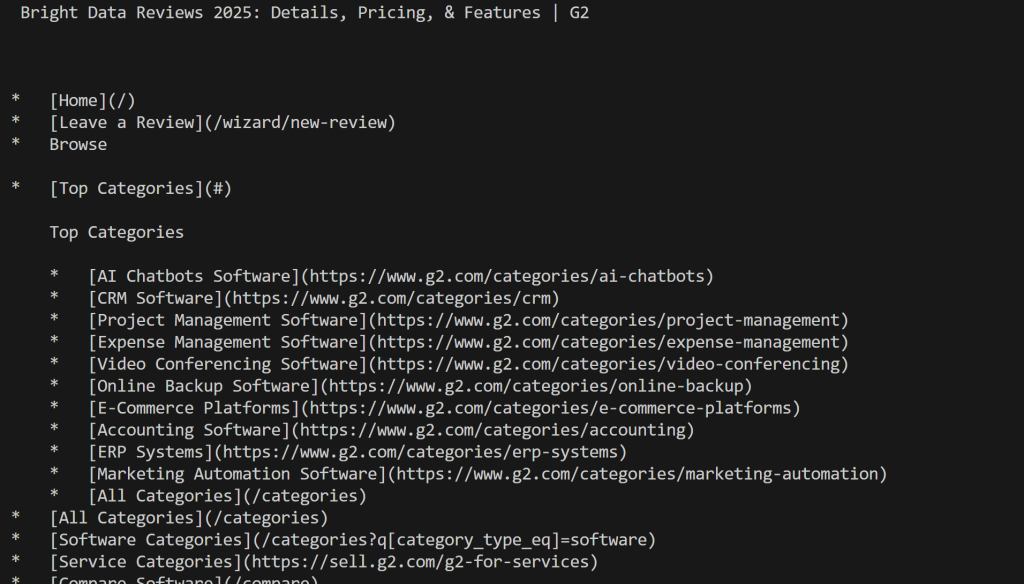
Observe cómo, esta vez, no fue bloqueado por G2. En lugar de eso, obtuviste el contenido real de Mardkwon, como deseabas.
Perfecto. Convertir un sitio web a Markdown nunca ha sido tan fácil.
Nota: Esta solución está disponible a través de más de 75 integraciones con herramientas de agentes de IA como CrawlAI, Agno, LlamaIndex y LangChain. Además, puede utilizarse directamente a través de la herramienta scrape_as_markdown en el servidor MCP de Bright Data Web.
Conclusión
En esta entrada de blog, usted exploró por qué y cómo convertir una página web a Markdown. Como se ha comentado, convertir HTML a Markdown no siempre es sencillo debido a problemas como las protecciones anti-scraping y los resultados subóptimos de Markdown.
Bright Data le ofrece Web Unlocker, una API de Scraping web basada en la nube capaz de convertir cualquier página web en Markdown optimizado para LLM. Puede llamar a esta API manualmente o integrarla directamente en soluciones de creación de agentes de IA o a través de la integración Web MCP.
Recuerde, Web Unlocker es sólo una de las muchas herramientas de scraping y datos web disponibles en la infraestructura de IA de Bright Data.
Regístrese hoy mismo para obtener una cuenta gratuita en Bright Data y comience a explorar nuestras soluciones de datos web preparadas para IA.




