

El scraping web es una técnica que consiste en extraer y recopilar datos de sitios web de forma automática utilizando herramientas o programas especializados. Es especialmente valioso para las empresas que buscan mejorar sus procesos de toma de decisiones basados en datos.
Sin embargo, debido a las complejas estructuras HTML, el contenido dinámico y los diversos formatos de datos que se encuentran en la mayoría de los sitios web, la eficacia del Scraping web depende de las herramientas que se utilicen.
Scrapy y Selenium son potentes herramientas diseñadas para facilitar el Scraping web. Scrapy extrae datos de sitios web estáticos, mientras que Selenium puede automatizar el navegador web y extraer datos de sitios web dinámicos.
En este artículo, compararemos las dos herramientas en función de su facilidad de uso, rendimiento y escalabilidad, idoneidad para diferentes tipos de contenido web y capacidades de integración.
Facilidad de uso
Scrapy es una herramienta de Scraping web basada en Python que puede ejecutarse en Linux, Windows, macOS y Berkeley Software Distribution (BSD). Scrapy no solo es fácil de usar, sino que también proporciona una API de alto nivel para tareas de Scraping web, lo que puede ayudar a simplificar aún más el proceso de Scraping web.
Para configurar Scrapy, solo hay que instalarlo y configurar algunas arañas utilizando código Python (esto requiere cierta comprensión de los conceptos de Scraping web). Cuando ejecutas un comando de Scrapy para iniciar un proyecto, se genera una carpeta dedicada a tu proyecto. Dentro de esta carpeta, encontrarás archivos Python predeterminados, comoitems.py,pipelines.pyy settings.py. Estos archivos están organizados en una estructura simplificada, lo que facilita el inicio del Scraping web.
Scrapy proporciona documentación detallada, que incluye artículos y vídeos seleccionados para ayudarte a resolver cualquier duda que puedas tener. Scrapy también cuenta con una comunidad activa en Subreddit y Discord, donde puedes participar en diferentes debates o temas.
En comparación, Selenium es compatible con múltiples lenguajes de programación, incluidos Java, JavaScript, Python y C#, y es compatible con muchos de los mismos sistemas operativos que Scrapy, incluidos Windows, macOS y Linux. En comparación con Scrapy, Selenium no es tan fácil de aprender y requiere más tiempo, esfuerzo y, a veces, recursos antes de que una persona pueda dominarlo.
Para configurar Selenium, hay que instalar la biblioteca Selenium y, a continuación, configurar los WebDrivers que gestionan la automatización del navegador. Si se extraen datos de un sitio web dinámico que requiere iniciar sesión, es necesario configurar la automatización web para gestionar el proceso de inicio de sesión antes de poder empezar a extraer cualquier dato.
Selenium ofrece un amplio conjunto de métodos de navegación que se pueden personalizar para localizar fácilmente elementos en una página web. Además, ofrece cadenas de acciones interactivas, como clics, doble clics, arrastrar y soltar, y desplazamientos, que permiten interactuar sin esfuerzo con las páginas web.
La documentación oficial de Selenium incluye impresionantes directrices, instrucciones paso a paso y tutoriales relacionados tanto con la automatización web como con el Scraping web.
Dado que Selenium es una herramienta más generalista para la automatización web, cuenta con una comunidad más amplia y diversa. Si tienes alguna pregunta mientras trabajas con Selenium, su grupo de usuarios oficial y su comunidad subreddit pueden ayudarte. O si tienes un problema que necesita una respuesta inmediata, puedes utilizar su sala de chat IRC.
Rendimiento y escalabilidad
La eficacia del rendimiento de cualquier herramienta de Scraping web depende en gran medida de su velocidad, ya que el objetivo es recopilar una cantidad significativa de datos rápidamente.
Scrapy destaca en el scraping de contenido de páginas web estáticas, lo que da como resultado una extracción de datos más rápida que Selenium. Esto se debe a que Selenium depende de instancias del navegador para ejecutar diferentes interacciones, como hacer clic en botones o rellenar formularios.
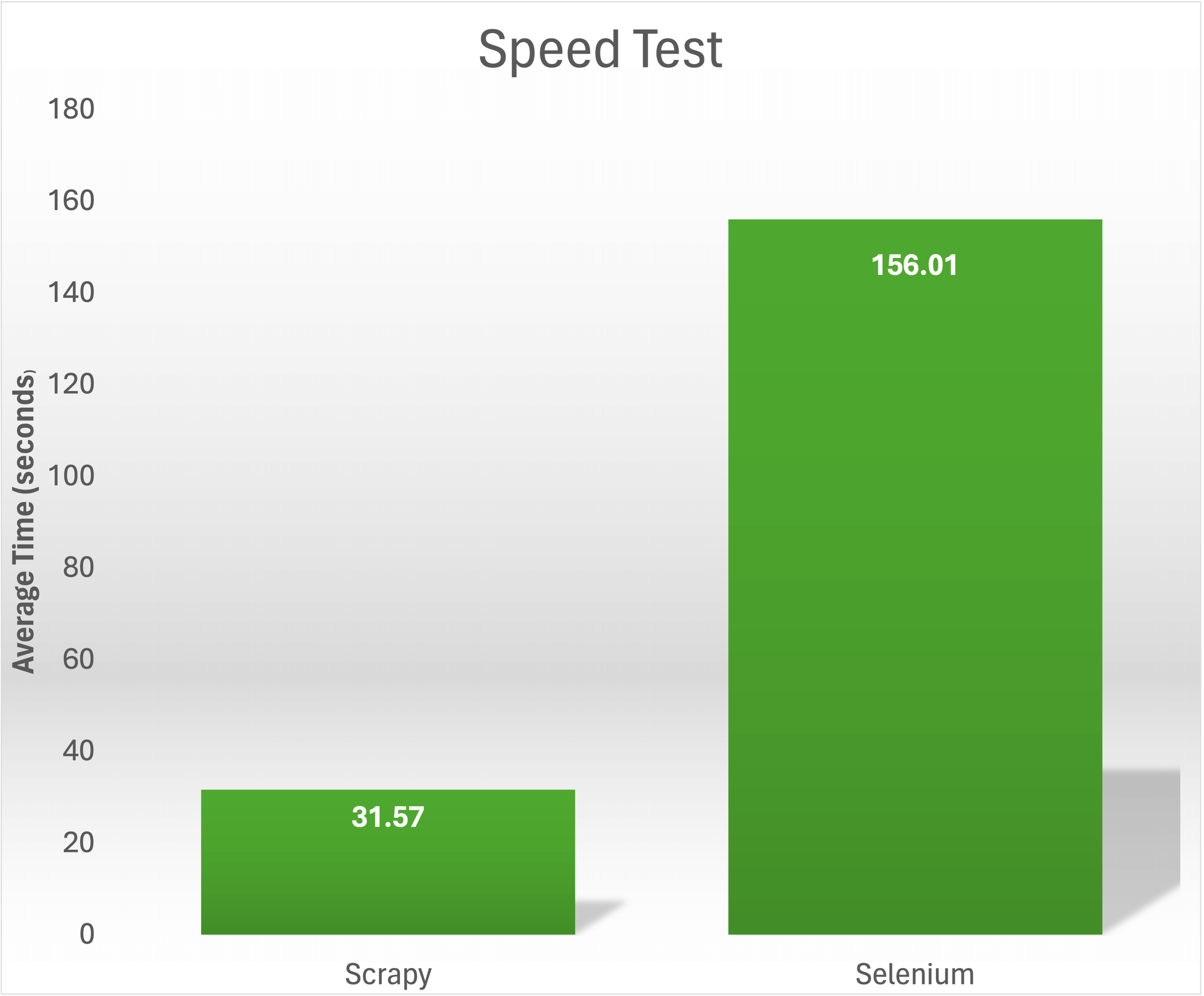
En una prueba de velocidad en la que se recopilaron los títulos y precios de 1000 libros de https://books.toscrape.com/, Scrapy fue capaz de completar la tarea en 31,57 segundos. Por el contrario, Selenium tardó una media de 156,01 segundos en extraer el mismo contenido:
La arquitectura de Scrapy gestiona la memoria de forma eficiente al procesar las respuestas y los elementos en un proceso continuo, evitando la necesidad de cargar páginas web completas en la memoria de una sola vez. Scrapy también tiene soporte integrado para el almacenamiento en caché y el rastreo incremental, lo que mejora la escalabilidad al minimizar las solicitudes redundantes y procesar solo el contenido nuevo o actualizado.
Además, Scrapy ofrece opciones para ajustar el uso de la memoria mediante configuraciones como solicitudes simultáneas, límites de profundidad y canalizaciones de elementos. Estas características le permiten optimizar el consumo de memoria de acuerdo con los requisitos específicos de su proyecto de Scraping web.
Selenium suele consumir una cantidad significativa de memoria cuando interactúa con sitios web con mucho JavaScript, lo que conduce a un mayor consumo de memoria. Esto puede afectar negativamente a su escalabilidad y rendimiento, especialmente en proyectos de scraping a gran escala.
El middleware integrado de Scrapy, llamado HTTPCacheMiddleware, almacena en caché las solicitudes realizadas por las arañas y sus respuestas relacionadas. Puede habilitar el almacenamiento en caché añadiendo el siguiente código alarchivo settings.pyde su proyecto:
# Habilitar y configurar el almacenamiento en caché HTTP (deshabilitado por defecto)
HTTPCACHE_ENABLED = True
Para escalar Selenium y gestionar el scraping de datos a gran escala es necesario implementar múltiples instancias en sistemas distribuidos, lo que conlleva un aumento de las demandas de recursos, como RAM y CPU.
Idoneidad para diferentes tipos de contenido web
La mayoría de los sitios web en Internet cuentan con páginas web dinámicas o estáticas. Veamos cómo Scrapy y Selenium gestionan ambos tipos de páginas web.
Páginas web dinámicas
La mayoría de las páginas web dinámicas funcionan con marcos de JavaScript, como Angular y React, para actualizar el contenido sin recargar toda la página.
Selenium puede extraer contenido dinámico de varios sitios web, pero Scrapy no admite de forma inherente la extracción de contenido dinámico generado por JavaScript. Puede integrar Scrapy con herramientas como Selenium y Splash para obtener esta funcionalidad.
Páginas web estáticas
Las páginas web estáticas suelen ofrecer una interacción limitada en comparación con las dinámicas, ya que normalmente solo permiten a los usuarios ver el contenido o hacer clic en los enlaces.
Como se ha mencionado anteriormente, Selenium puede extraer páginas estáticas, pero no es la herramienta más eficaz para esta tarea. Por el contrario, Scrapy destaca en la extracción de datos estáticos, proporcionando una experiencia fluida y eficaz para recopilar la información deseada.
Capacidades de integración
Scrapy se integra fácilmente con la mayoría de las herramientas de Python, incluidas bases de datos como MySQL, PostgreSQL y MongoDB, para almacenar los datos extraídos. Incluso se pueden utilizar mapeadores objeto-relacionales (ORM), como SQLAlchemy, para simplificar el proceso de almacenamiento de datos en bases de datos relacionales. Si se desea procesar y analizar los datos más a fondo, se puede utilizar pandas, una popular biblioteca de manipulación y análisis de datos para Python.
Scrapy también se puede integrar con marcos web como Django y Flask para crear aplicaciones web que incorporen la funcionalidad de Scraping web. Además, la integración con FastAPI le permite crear API web de alto rendimiento con soporte asíncrono, adecuado para gestionar solicitudes de Scraping web de manera eficiente.
Por el contrario, Selenium proporciona controladores de navegador que actúan como intermediarios entre las API de Selenium WebDriver y los navegadores. Puede descargar e instalar un WebDriver para integrarlo con el navegador web que prefiera. Actualmente, Selenium proporciona controladores de navegador para Chrome, Edge, Firefox y Safari.
Selenium también se puede utilizar para probar automáticamente las funcionalidades de las aplicaciones web; sin embargo, hay que tener en cuenta que no tiene un marco de pruebas integrado. Puede integrar Selenium con otros marcos de pruebas populares, como CodeceptJS, Helium y Selenide.
Selenium se utilizaba para integrarse con herramientas de CI, como Jenkins y Travis CI, para permitir la ejecución automática de scripts de automatización como parte del proceso de integración continua y entrega continua (CI/CD); sin embargo, ahora se ejecuta todo con GitHub Actions, que admite procesos de prueba y despliegue continuos.
Scrapy se puede integrar con diferentes proveedores de servicios Proxy, como Bright Data, pasando la IP y el puerto del Proxy como parámetro de solicitud. Este método se recomienda si desea utilizar un Proxy específico para su proyecto.
Por ejemplo, si desea integrarse con un servidor Proxy, puede utilizar elcomando pip pip3 install scrapy parainstalar Scrapy, de la siguiente manera:
#importar el módulo scrapy
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# conectar con Proxy
meta={"Proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}
Aquí, importas Scrapy y defines una clasellamada BookSpider heredadade la clase spider de Scrapy para extraer una lista de libros del sitio web.Elmétodostart_requests()inicia las solicitudes con las URL y los Proxies especificados, yelmétodoparse()extrae los títulos y precios de los libros utilizando selectores CSS.
Por el contrario, Selenium admite una integración sencilla de Proxies a través de varios controladores de navegador, como ChromeDriver y geckodriver. Solo tienes que configurar Selenium WebDriver para que enrute sus solicitudes HTTP a través de un servidor Proxy.
Por ejemplo, puede integrar Selenium con Proxies especificando la IP y el puerto del Proxy proporcionados por Bright Data, de esta manera:
#importar módulos selenium
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# Configuración del proxy
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Opciones de Selenium: integrar con las credenciales de Proxy de Bright Data
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Instanciación del controlador web Selenium
driver = webdriver.Chrome(options=options)
# Ejemplo de uso: scraping de una página web
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# Cerrar el controlador
driver.quit()
Aquí, se importan los módulos Selenium necesarios y se configura el Proxy. A continuación, se configura Chrome para utilizar los servidores Proxy definidos, se instancia un WebDriver, se extrae una página web («https://example.com»), se imprime el código fuente de la página y se cierra el WebDriver para finalizar el proceso.
Conclusión
En este artículo, has comparado dos populares herramientas de Scraping web: Scrapy y Selenium.
Scrapy es una herramienta de rastreo basada en Python fácil de usar, ideal para la extracción de datos de sitios web estáticos. Por el contrario, Selenium ofrece capacidades de automatización y rastreo utilizando múltiples lenguajes de programación, es compatible con varios navegadores web y es la mejor opción para rastrear contenido dinámico y renderizado con JavaScript.
Independientemente de la herramienta que decida utilizar, se recomienda utilizar una plataforma de datos como Bright Data. Le ayudará a añadir funcionalidades a sus scripts de scraping web para evitar restricciones geográficas, bloqueos y la resolución de CAPTCHAs. También puede utilizar la API y el SDK de Bright Data para abordar una gama más amplia de requisitos de scraping, lo que garantiza la eficiencia, la velocidad, la precisión y la escalabilidad de su proyecto de scraping web. ¿Te interesa llevar tu recopilación de datos aún más lejos? Compra un conjunto de datos personalizado (muestras gratuitas disponibles).




