

En la guía de hoy, vamos a escribir un Scrapy Spider y lo implementaremos en AWS Lambda. En lo que respecta al código, aquí es bastante sencillo. Cuando se trabaja con servicios en la nube como Lambda, hay muchos elementos móviles. Le mostraremos cómo navegar por estos elementos móviles y cómo manejarlos cuando algo falla.
Requisitos previos
Para realizar esta tarea, necesitarás lo siguiente:
- aquí
- conocimientos básicos sobre scraping con Scrapy
¿Qué es Serverless?
La arquitectura sin servidor ha sido aclamada como el futuro de la informática. Aunque el tiempo de ejecución real de una aplicación sin servidor puede ser más caro por hora, si aún no estás pagando por ejecutar un servidor, Lambda tiene sentido.
Supongamos que tu Scraper tarda un minuto en ejecutarse y lo ejecutas una vez al día. Con un servidor tradicional, pagarías por un mes de tiempo de actividad de 24 horas, pero tu uso real es de solo 30 minutos. Con servicios como Lambda, solo pagas por lo que realmente utilizas.
Ventajas
- Facturación: solo pagas por lo que utilizas.
- Escalabilidad: Lambda se escala automáticamente, no tienes que preocuparte por ello.
- Gestión del servidor: no tienes que dedicar tiempo a gestionar un servidor. Todo esto se hace automáticamente.
Inconvenientes
- Latencia: si tu función ha estado inactiva, tardará más en iniciarse y ejecutarse.
- Tiempo de ejecución: las funciones Lambda se ejecutan con un tiempo de espera predeterminado de 3 segundos y un tiempo máximo de 15 minutos. Los servidores tradicionales son mucho más flexibles.
- Portabilidad: no solo depende de la compatibilidad del sistema operativo, sino que también está a merced de su proveedor. No puede simplemente copiar su función Lambda y ejecutarla en Azure o Google Cloud.
Bright Data tiene una solución que no tiene esas limitaciones. Veámosla a continuación.
Funciones sin servidor: la mejor alternativa
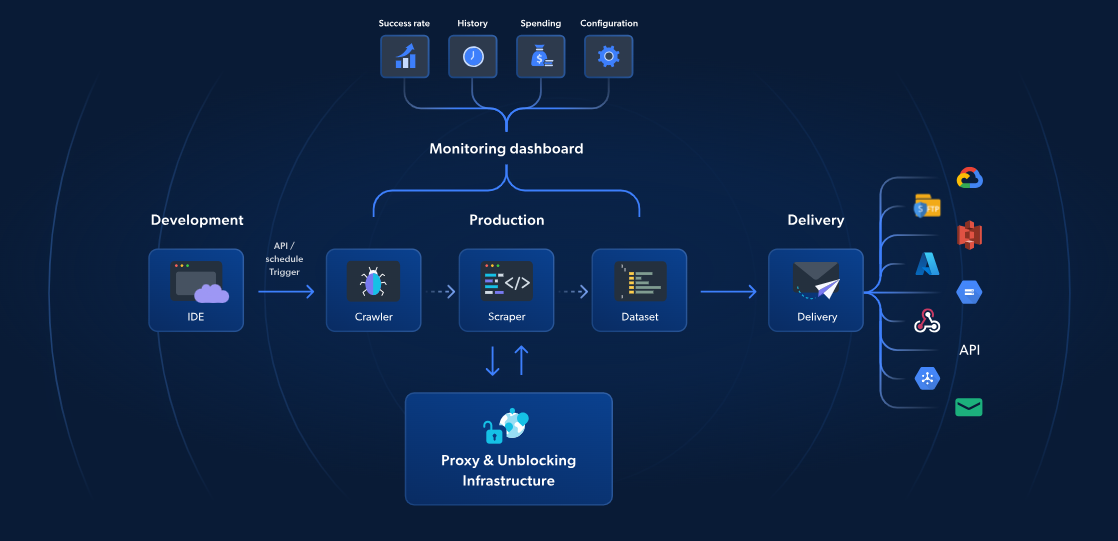
Mientras que AWS Lambda y Scrapy ofrecen Scraping web sin servidor, las funciones sin servidor de Bright Data proporcionan una solución específica para un Scraping web más rápido y fiable. Con más de 70 plantillas JavaScript preconstruidas, un IDE integrado basado en la nube y una solución de desbloqueo impulsada por IA, puedes evitar los CAPTCHA, escalar sin esfuerzo y centrarte en extraer datos sin la molestia de gestionar la infraestructura.
A diferencia del enfoque de AWS y Scrapy, la solución de Bright Data incluye gestión de Proxy, escalado automático e integración directa con plataformas de almacenamiento como S3 o Google Cloud. Con un precio a partir de solo 2,7 $ por cada 1000 cargas de página, las funciones sin servidor hacen que el Scraping web avanzado sea más sencillo, rápido y rentable.
Ahora, continuemos con nuestra guía de Scrapy y AWS.
Introducción
Configuración de los servicios
Una vez que tengas tu cuenta de AWS, necesitarás un bucket de S3. Dirígete a la página «Todos los servicios» y desplázate hacia abajo.
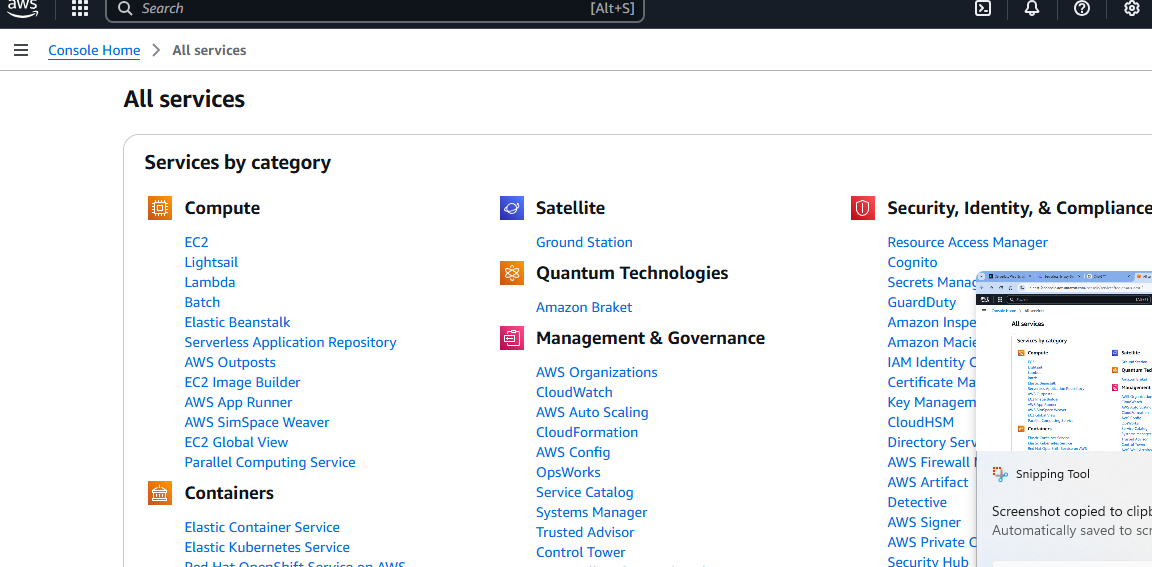
Finalmente, verá una sección llamada Almacenamiento. La primera opción de esta sección se llama S3. Haga clic en ella.
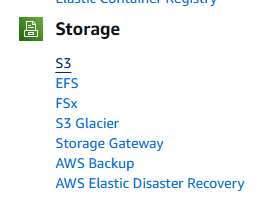
A continuación, haz clic en el botón Crear bucket.
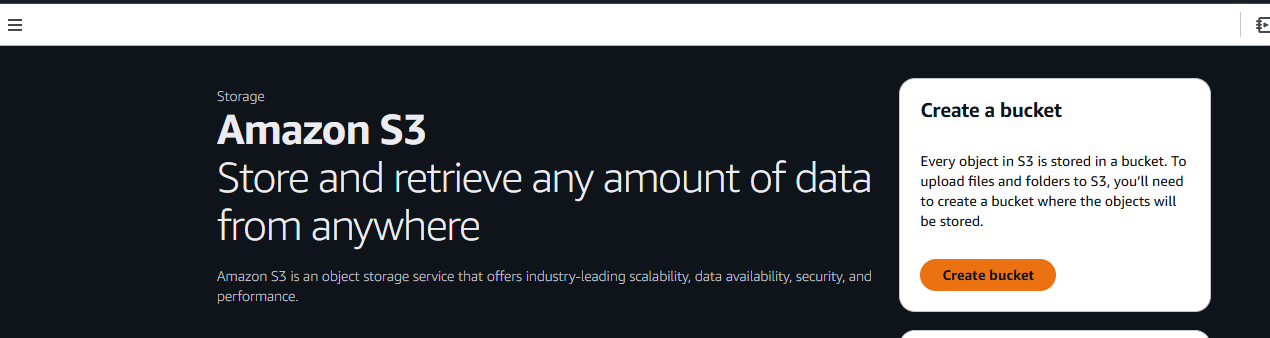
Ahora, debe asignar un nombre a su bucket y elegir la configuración. Nosotros utilizaremos la configuración predeterminada.
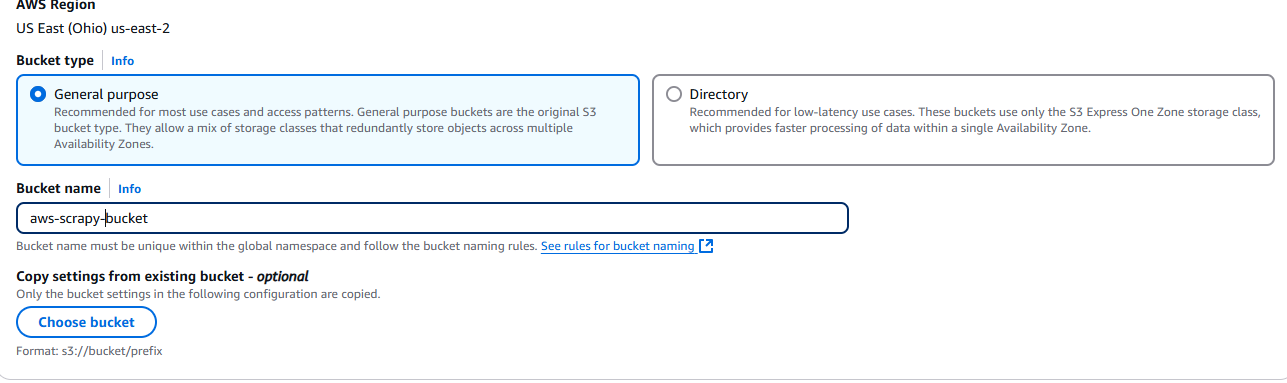
Cuando haya terminado, haga clic en el botón Crear bucket situado en la esquina inferior derecha de la página.

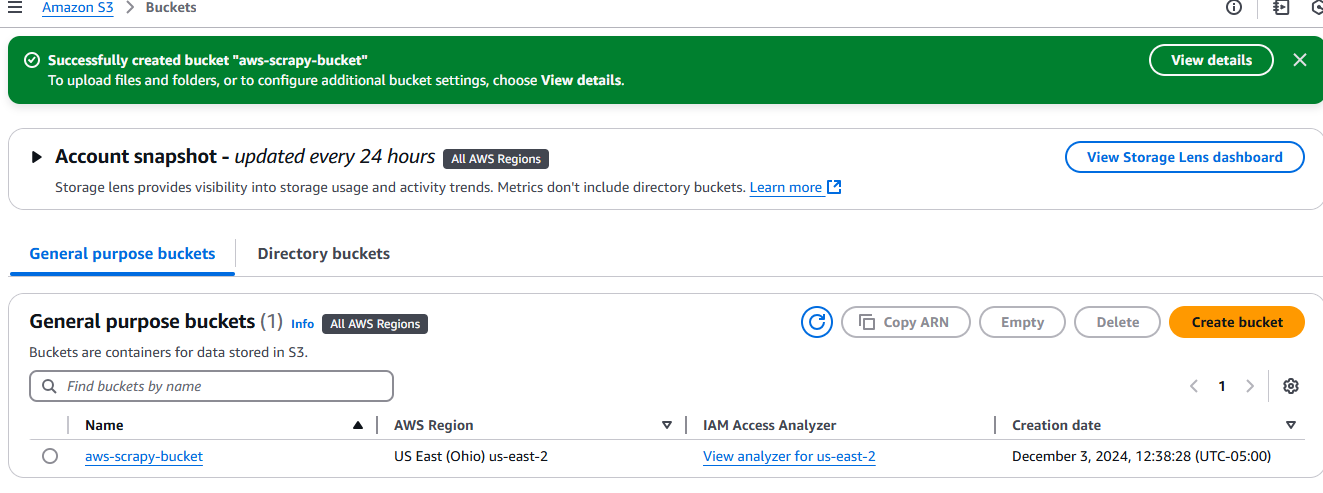
Una vez creado, tu bucket aparecerá en la pestaña Buckets, en Amazon S3.
Configuración de su proyecto
Cree una nueva carpeta de proyecto.
mkdir scrapy_aws
Vaya a la nueva carpeta y cree un entorno virtual.
cd scrapy_aws
python3 -m venv venv
Activa el entorno.
source venv/bin/activate
Instala Scrapy.
pip install scrapy
Qué rastrear
Para sitios web dinámicos, medidas anti-bot o scraping a gran escala, utiliza el Navegador de scraping de Bright Data. Automatiza tareas, evita los CAPTCHA y se adapta a la perfección.
Usaremos books.toscrape como nuestro sitio de destino. Es un sitio educativo dedicado por completo al Scraping web. Si miras la imagen de abajo, cada libro es un artículo con el nombre de clase product_pod. Queremos extraer todos estos elementos de la página.
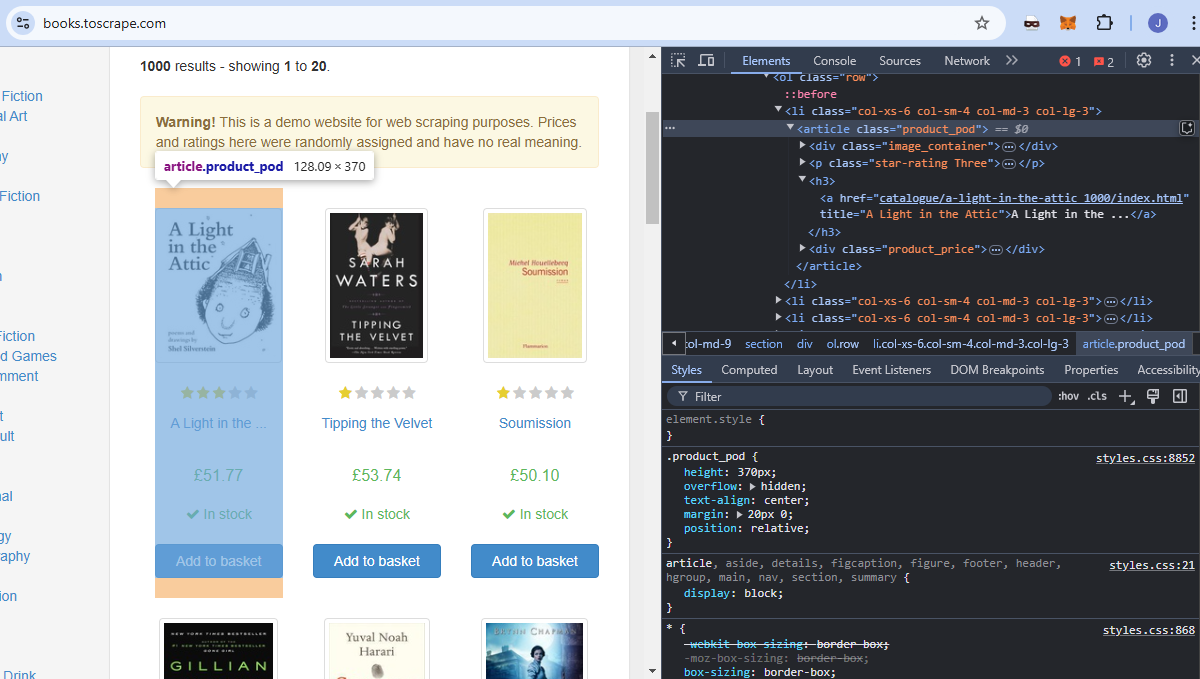
El título de cada libro está incrustado en un elemento a que está anidado dentro de un elemento h3.

Cada precio está incrustado en un p que está anidado dentro de un div. Tiene un nombre de clase price_color.
Escribir nuestro código
Ahora, escribiremos nuestro Scraper y lo probaremos localmente. Abre un nuevo archivo Python y pega el siguiente código en él. Hemos llamado al nuestro aws_spider.py.
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
Puedes probar la araña con el siguiente comando. Debería generar un archivo JSON con todos los libros y sus precios.
python -m scrapy runspider aws_spider.py -o books.json
Ahora necesitamos un controlador. La función del controlador es sencilla: ejecutar la araña. Aquí crearemos dos controladores que son básicamente iguales. La principal diferencia es que uno se ejecuta localmente y el otro en Lambda.
Este es nuestro controlador local, al que hemos llamado lambda_function_local.py.
import subprocess
def handler(event, context):
# Ruta del archivo de salida para pruebas locales.
output_file = "books.json"
# Ejecutar la araña Scrapy con el indicador -o para guardar la salida en books.json
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# Devuelve un mensaje de éxito
return {
'statusCode': '200',
'body': f"¡Rastreo completado! Salida guardada en {output_file}",
}
# Añade este bloque para pruebas locales
if __name__ == "__main__":
# Simula un evento y contexto de invocación de AWS Lambda
fake_event = {}
fake_context = {}
# Llama al controlador e imprime el resultado
result = handler(fake_event, fake_context)
print(result)
Elimine books.json. Puede probar el controlador local con el siguiente comando. Si todo funciona correctamente, verá un nuevo books.json en la carpeta de su proyecto. Recuerde cambiar bucket_name por su propio bucket.
python lambda_function_local.py
Ahora, aquí está el controlador que usaremos para Lambda. Es bastante similar, solo tiene algunos pequeños ajustes para almacenar nuestros datos en nuestro bucket de S3.
import subprocess
import boto3
def handler(event, context):
# Define las rutas de los archivos de salida locales y S3.
local_output_file = "/tmp/books.json" # Debe estar en /tmp para Lambda.
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # Ruta en el bucket S3
# Ejecuta la araña Scrapy y guarda la salida localmente
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# Subir el archivo a S3
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"¡Rastreo completado! Resultado subido a s3://{bucket_name}/{s3_key}"
}
- Primero guardamos nuestros datos en un archivo temporal:
local_output_file = "/tmp/books.json". Esto evita que se pierdan. - Los subimos a nuestro bucket con
s3.upload_file(archivo_de_salida_local, nombre_del_bucket, clave_s3).
Implementación en AWS Lambda
Ahora, tenemos que implementar en AWS Lambda.
Creamos una carpeta de paquete.
mkdir package
Copie nuestras dependencias en la carpeta del paquete.
cp -r venv/lib/python3.*/site-packages/* package/
Copie los archivos. Asegúrese de copiar el controlador que creó para Lambda, no el controlador local que probamos anteriormente.
cp lambda_function.py aws_spider.py paquete/
Comprima la carpeta del paquete en un archivo zip.
zip -r lambda_function.zip package/
Una vez creado el archivo ZIP, debemos dirigirnos a AWS Lambda y seleccionar Crear función. Cuando se le solicite, introduzca su información básica, como el tiempo de ejecución (Python) y la arquitectura.
Asegúrate de añadirle permiso para acceder a tu bucket de S3.
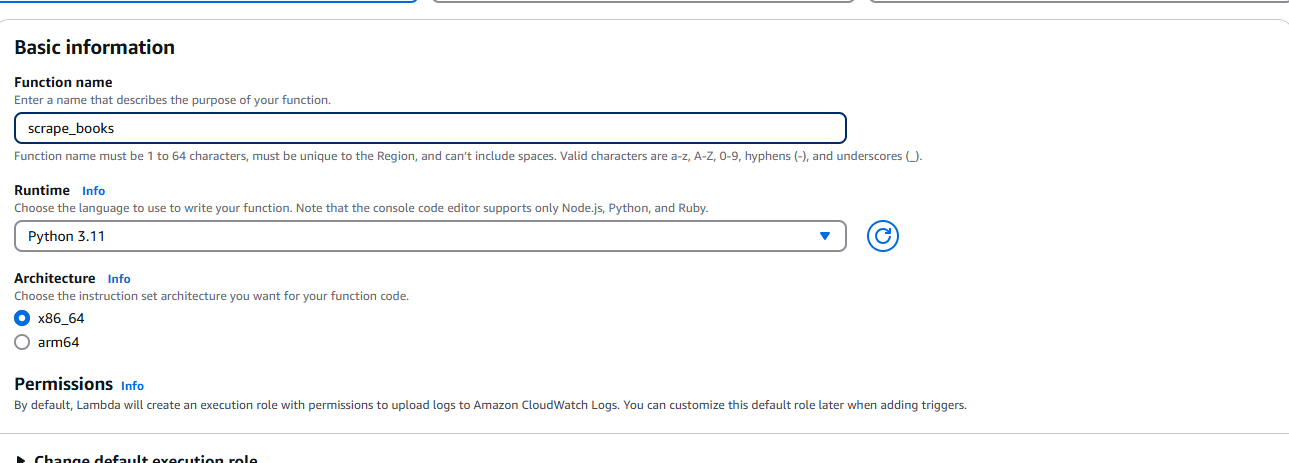
Una vez creada la función, seleccione Cargar desde el menú desplegable. Se encuentra en la esquina superior derecha de la pestaña Fuente.

Seleccione el archivo .zip y cargue el archivo ZIP que ha creado.
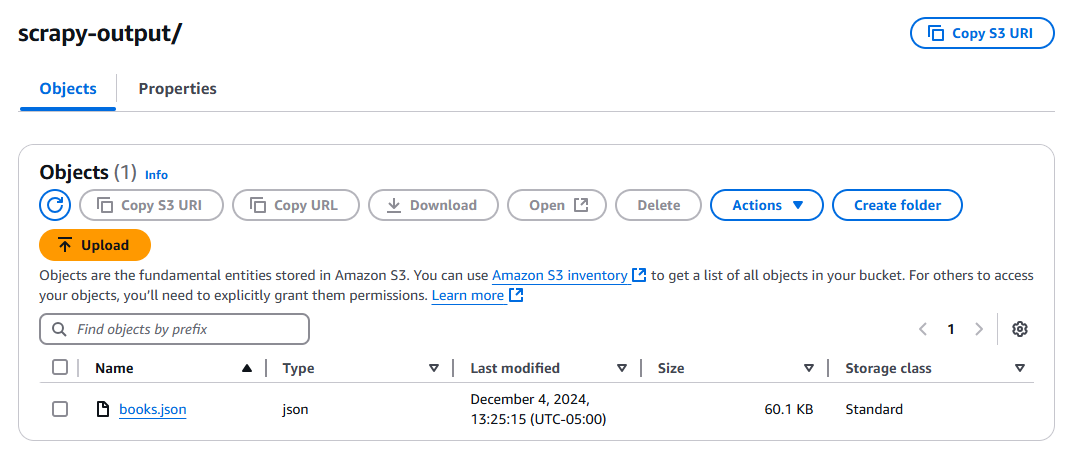
Haga clic en el botón de prueba y espere a que se ejecute la función. Una vez ejecutada, compruebe su bucket de S3 y debería tener un nuevo archivo, books.json.
Consejos para la resolución de problemas
No se encuentra Scrapy
Es posible que aparezca un error indicando que no se encuentra Scrapy. Si es así, debe añadir lo siguiente a su matriz de comandos en subprocess.run().

Problemas generales de dependencia
Debe asegurarse de que sus versiones de Python sean las mismas. Compruebe su instalación local de Python.
python --version
Si este comando muestra una versión diferente a la de su función Lambda, cambie la configuración de Lambda para que coincida.
Problemas con el controlador

Su controlador debe coincidir con la función que escribió en lambda_function.py. Como puede ver arriba, tenemos lambda_function.handler. lambda_function representa el nombre de su archivo Python. handler es el nombre de la función.
No se puede escribir en S3
Es posible que se encuentre con problemas de permisos a la hora de almacenar la salida. Si es así, debe añadir estos permisos a su instancia Lambda.
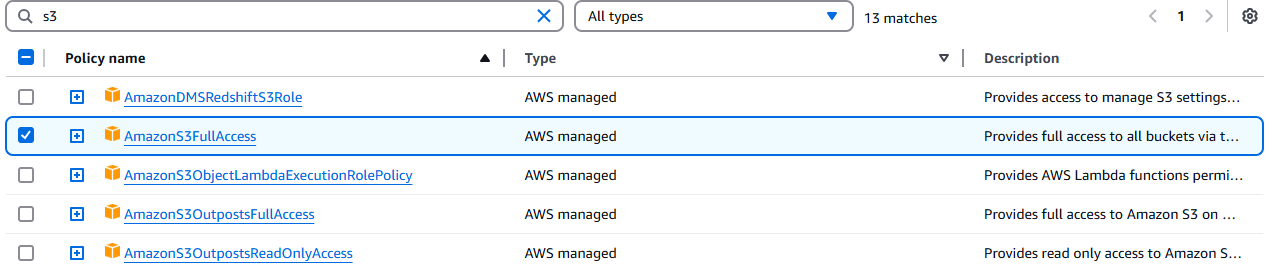
Vaya a la consola de IAM y busque su función Lambda. Haga clic en ella y, a continuación, haga clic en el menú desplegable Añadir permisos.
Haga clic en Adjuntar políticas.
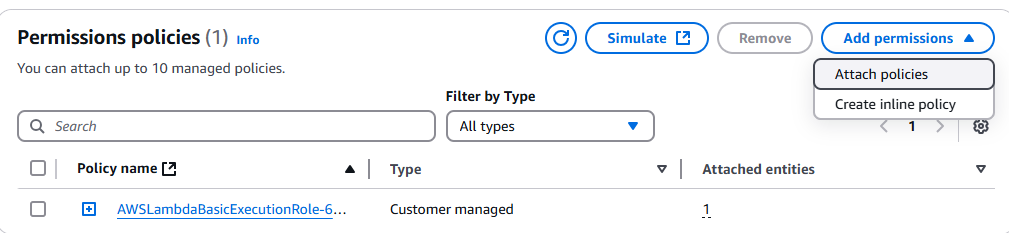
Seleccione AmazonS3FullAccess.
Conclusión
¡Lo ha conseguido! En este punto, debería ser capaz de desenvolverse en la pesadilla de interfaz de usuario conocida como consola de AWS. Ya sabe cómo escribir un rastreador con Scrapy. Ya sabe cómo empaquetar el entorno con Linux o WSL para garantizar la compatibilidad binaria con Amazon Linux.
Si no te gusta el scraping manual, echa un vistazo a nuestras API de scraping web y nuestros Conjuntos de datos listos para usar. ¡Regístrate ahora para empezar tu prueba gratuita!





