

En este artículo, aprenderás:
- Qué es Apache Spark Structured Streaming y qué ofrece.
- Por qué integrar la API SERP de Bright Data en un pipeline de Spark Structured Streaming es una estrategia ganadora.
- Cómo crear un pipeline de PySpark que ingiera continuamente datos de búsqueda web en tiempo real utilizando la API SERP de Bright Data.
¡Empecemos!
¿Qué es Apache Spark Structured Streaming?
Apache Spark Structured Streaming es un motor de procesamiento de flujos escalable y tolerante a fallos construido sobre el motor Spark SQL. A diferencia de la antigua biblioteca Spark Streaming (que divide los datos en micro-lotes discretos basados en RDD utilizando DStreams), Structured Streaming trata un flujo de datos en tiempo real como una tabla ilimitada a la que se añaden datos continuamente. Escribes el mismo código de DataFrame y de la API de SQL que escribirías para un trabajo por lotes estático, y Spark se encarga de ejecutarlo de forma incremental a medida que llegan nuevos datos.
El motor opera por defecto en un modelo de ejecución de micro-lotes. En cada intervalo de activación, Spark lee los datos más recientes de la fuente, los procesa y escribe los resultados en un sumidero. Realiza un seguimiento del progreso mediante puntos de control, de modo que el pipeline puede recuperarse de los fallos y reanudarse exactamente donde se quedó, lo que proporciona garantías de tolerancia a fallos de extremo a extremo.
Structured Streaming admite una variedad de fuentes integradas: temas de Kafka, tablas Delta, almacenamiento de objetos en la nube a través de Auto Loader, generadores de tasas (para pruebas) y más. Para las fuentes que no están cubiertas de forma nativa (como una API REST), puedes utilizar el método de extensión foreachBatch, que entrega cada microlote a una función de Python donde puedes expresar una lógica de ingestión arbitraria. Este es el enfoque que utilizaremos aquí.
Spark Streaming frente a Spark Structured Streaming: ¿cuál es la diferencia?
Si está familiarizado con la biblioteca heredada de Spark Streaming, quizá se pregunte cómo se relaciona con Structured Streaming. Ambas comparten el mismo motor Spark subyacente, pero difieren en aspectos importantes:
Spark Streaming se basa en DStreams, una secuencia de RDD generada al dividir un flujo entrante en lotes delimitados por el tiempo. Todas las transformaciones operan sobre RDD, lo que significa que se trabaja en una API de nivel inferior. Tiene un soporte limitado para la semántica de tiempo de evento (es decir, ordenar los datos por cuándo se generaron, no por cuándo se ingirieron) y ya no se desarrolla activamente.
Spark Structured Streaming se basa en las API de DataFrame y Dataset, lo que le da acceso al optimizador completo de Spark SQL. Ofrece ventanas de tiempo de evento nativas, marcas de agua para gestionar datos tardíos, agregaciones con estado y un modelo de tolerancia a fallos más limpio mediante puntos de control. Dado que utiliza la misma API que los DataFrames por lotes, puede mezclar datos en streaming y datos estáticos en el mismo trabajo (por ejemplo, uniones en streaming con una tabla de consulta estática).
En resumen, Spark Streaming es un proyecto heredado que se mantiene por motivos de compatibilidad con versiones anteriores, mientras que Structured Streaming es el motor recomendado y en desarrollo activo para todas las nuevas cargas de trabajo de streaming.
¿Por qué integrar la API SERP de Bright Data en Spark Structured Streaming?
Spark Structured Streaming proporciona un potente motor para transformar y agregar datos a gran escala, pero necesita una fuente fiable y estructurada de datos web en tiempo real sobre la que actuar. Aquí es donde entra en juego la API SERP de Bright Data.
La API SERP te permite enviar consultas de forma programada a los principales motores de búsqueda (incluidos Google, Bing, DuckDuckGo, Yandex y más) y recuperar páginas completas de resultados de búsqueda (SERP) sin ser bloqueado. Los resultados se devuelven en múltiples formatos: JSON analizado, una variante ligera (parsed_light) con solo los principales resultados orgánicos, HTML sin procesar o Markdown limpio y listo para IA. Dado que el scraping directo de los motores de búsqueda es notoriamente difícil debido a las medidas antibots, los límites de frecuencia y la representación dinámica, el enrutamiento de tus consultas a través de la infraestructura de Bright Data elimina toda esa complejidad de tu canalización.
Combinar esto con el motor de micro-lotes de Spark Structured Streaming crea un proceso que se ejecuta de forma continua y que extrae periódicamente datos SERP actualizados, aplica transformaciones y agregaciones a gran escala, y escribe resultados estructurados en cualquier destino que elijas, sin que tengas que gestionar Proxies, CAPTCHAs o Infraestructura de scraping.
Este enfoque resulta especialmente útil para:
- Supervisar cómo se posiciona un conjunto de palabras clave objetivo en los motores de búsqueda a intervalos regulares, escribir los resultados en una tabla Delta y calcular los cambios de posicionamiento a lo largo del tiempo.
- Recuperar continuamente SERP de marcas o productos de la competencia, realizar el parseo de los resultados estructurados y transmitirlos a un almacén de datos para su visualización en paneles.
- Recopilar resultados de búsqueda de Google News sobre múltiples temas en micro-lotes paralelos, deduplicar artículos utilizando las agregaciones con estado de Spark y enviar los resultados seleccionados a un lago de datos.
- Ingerir continuamente resultados de SERP para detectar cuándo aparecen anuncios pagados para sus palabras clave objetivo, capturar el texto del anuncio y las URL, y alertar a los sistemas posteriores.
Al combinar el procesamiento distribuido y escalable de Spark Structured Streaming con la infraestructura de acceso web de Bright Data para IA y pipelines de datos, se crean pipelines que reaccionan continuamente a los datos de búsqueda del mundo real, sin necesidad de mantener una infraestructura de scraping propia.
Cómo crear un canal de ingestión continua de SERP con Spark Structured Streaming
En esta sección guiada, creará un canal de PySpark que:
- Se activa según una programación utilizando la fuente de frecuencia integrada de Spark como reloj.
- Llama a la API SERP de Bright Data dentro de una función
foreachBatchen cada microlote para obtener resultados en tiempo real de Google News para un tema de interés. - Realiza el parseo y transforma la respuesta JSON estructurada en un DataFrame de Spark limpio.
- Escribe los resultados en un sumidero (tanto en un directorio de salida JSON local como en la consola) para que puedas inspeccionar los datos en tiempo real.
Nota: Este ejemplo muestra un caso de uso de monitorización de noticias, pero el mismo patrón se aplica a cualquier escenario de ingestión continua de SERP: seguimiento de posicionamiento de palabras clave, monitorización de anuncios, comparación de precios mediante búsqueda web, etc.
Requisitos previos
Para seguir el ejemplo, asegúrate de tener:
- Python 3.8+ instalado.
- Apache Spark 3.3+ instalado localmente, o acceso a un clúster de Databricks / AWS EMR / Google Dataproc.
- PySpark instalado:
pip install pyspark. - La biblioteca
requestsinstalada:pip install requests. - Una cuenta de Bright Data con una zona de API SERP activa y una clave de API (con permisos de administrador).
Sigue la documentación oficial de Bright Data para configurar tu zona de API SERP y recuperar tu clave de API. Guarda tanto tu clave de API como el nombre de la zona en un lugar seguro; los necesitarás en breve.
Paso 1: Configura tu proyecto
Crea un nuevo directorio de proyecto y configura los archivos que necesitarás:
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpointAbre config.py y añade tus credenciales de Bright Data y la configuración de búsqueda:
# config.py
BRIGHT_DATA_API_KEY = "SU_CLAVE_API_DE_BRIGHT_DATA"
SERP_API_ZONE = "SU_ZONA_API_DE_SERP"
# La consulta de búsqueda que se va a supervisar (personalícela según su caso de uso)
SEARCH_QUERY = "noticias sobre inteligencia artificial"
# Frecuencia con la que se debe activar un nuevo micro-lote (en segundos)
TRIGGER_INTERVAL_SECONDS = 60
# Directorio de salida para los resultados JSON
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"Consejo de seguridad: En un entorno de producción, evite codificar las credenciales de forma estática en los archivos fuente. Utilice variables de entorno, un gestor de secretos (por ejemplo, AWS Secrets Manager, Azure Key Vault, HashiCorp Vault) o Databricks Secrets para inyectar estos valores en tiempo de ejecución.
Paso 2: Inicializar la SparkSession
Abre pipeline.py y empieza creando tu SparkSession. Este es el punto de entrada a todas las funcionalidades de Spark:
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# Inicializar SparkSession
spark = SparkSession.builder
.appName("BrightDataSERPStream")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
# Reducir la verbosidad del registro para obtener una salida más clara
spark.sparkContext.setLogLevel("WARN")
print("SparkSession inicializada.")Establecer spark.sql.shuffle.partitions en un número pequeño, como 4, es adecuado para un entorno de desarrollo local. En un clúster, se ajustaría en función del tamaño de los datos y del número de núcleos del ejecutor.
Paso 3: Definir la función de obtención de la API SERP
A continuación, defina la función de Python que llamará a la API SERP de Bright Data y devolverá los resultados analizados. Esta función se invocará desde dentro de la llamada de retorno foreachBatch de Spark en el controlador, por lo que utiliza la biblioteca estándar de solicitudes en lugar de cualquier mecanismo distribuido de Spark:
# pipeline.py (continuación)
def fetch_serp_results(query: str) -> list[dict]:
"""
Llama a la API SERP de Bright Data y devuelve una lista de resultados de noticias analizados.
Utiliza el formato de datos parsed_light para obtener una salida JSON ligera y estructurada.
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": config.SERP_API_ZONE,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# El formato parsed_light devuelve una matriz «news» de objetos de resultado
results = data.get("news", [])
print(f"[API SERP] Se han obtenido {len(results)} resultados para la consulta: '{query}'")
return results
except requests.exceptions.RequestException as e:
print(f"[API SERP] Error en la solicitud: {e}")
return []Analicemos los parámetros clave de la solicitud:
zone: el nombre de tu zona de la API SERP desde el panel de control de Bright Data.url: La URL de búsqueda de Google. El parámetrotbm=nwslimita los resultados a Google Noticias.hl=enestablece el idioma de la interfaz en inglés, ygl=usdirige los resultados a Estados Unidos para obtener resultados geolocalizados.format: Establece en«raw»para recibir el cuerpo de la respuesta directamente.data_format: Establezca en«parsed_light»para recibir una matriz JSON limpia de los principales resultados orgánicos/de noticias con títulos, URL, fuentes y fechas, sin anuncios ni paneles de conocimiento. Para obtener datos SERP completos, incluidos anuncios y paneles de conocimiento, utilice«parsed». Para una salida compatible con LLM, utilice«markdown».
Paso 4: Crear la fuente de streaming utilizando el generador de frecuencia
Dado que Spark Structured Streaming no dispone de una fuente HTTP nativa, utilizamos un patrón bien establecido: la fuente de frecuencia integrada actúa como un reloj, generando una fila por segundo (o según la frecuencia configurada). Cada microlote producido por la fuente de frecuencia activa nuestra llamada de retorno foreachBatch, dentro de la cual llamamos a la API SERP.
Añada la definición del flujo de frecuencia a pipeline.py:
# pipeline.py (continuación)
rate_stream = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
print("Flujo de frecuencia creado. El pipeline se activará cada intervalo de micro-lote.")La fuente de frecuencia está diseñada explícitamente para pruebas y escenarios controlados por reloj como este. Dado que se aplican los límites de frecuencia reales de la API, configuraremos el intervalo de activación en el paso 5 para que el pipeline solo llame a la API SERP una vez por minuto, no una vez por segundo.
Paso 5: Definir el controlador foreachBatch
El controlador foreachBatch es el corazón del pipeline. Spark llama a esta función en cada micro-lote, pasando un DataFrame de las filas de ese lote y un ID de lote único. Dentro de la función, llamamos a la API SERP, convertimos los resultados en un DataFrame de Spark, aplicamos transformaciones y escribimos en el sumidero de salida:
# pipeline.py (continuación)
# Definir el esquema para los resultados SERP analizados
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
Llamada por Spark cada vez que se activa un micro-lote.
Recupera datos SERP de Bright Data, convierte los resultados a un DataFrame
y los escribe en el sumidero de salida.
"""
print(f"n--- Procesando lote {batch_id} ---")
# Obtiene resultados SERP en tiempo real de Bright Data
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"Lote {batch_id}: No se han devuelto resultados. Se omite la escritura.")
return
# Convierte la lista de resultados en un DataFrame de Spark
results_df = spark.createDataFrame(results, schema=serp_schema)
# Añadir columnas de metadatos para el seguimiento
enriched_df = results_df
.withColumn("query", F.lit(config.SEARCH_QUERY))
.withColumn("batch_id", F.lit(batch_id))
.withColumn("ingested_at", F.current_timestamp())
# Imprimir en la consola para mayor visibilidad
enriched_df.show(truncate=False)
# Escribir en salida JSON (modo de anexión, particionado por fecha de ingestión)
enriched_df
.withColumn("ingestion_date", F.to_date("ingested_at"))
.write
.mode("append")
.partitionBy("ingestion_date")
.json(config.OUTPUT_PATH)
print(f"Lote {batch_id}: Se han escrito {enriched_df.count()} registros en {config.OUTPUT_PATH}")Algunas cosas a tener en cuenta sobre este diseño:
spark.createDataFrame(results, schema=serp_schema) convierte la lista Python de diccionarios devuelta por la API SERP en un DataFrame de Spark tipado. Es preferible proporcionar un esquema explícito en lugar de la inferencia de esquema, ya que hace que el trabajo sea más rápido y predecible.
F.lit(batch_id) adjunta el ID del micro-lote actual a cada fila, lo cual resulta útil para la deduplicación si el pipeline vuelve a intentar un lote fallido (ya que foreachBatch garantiza por defecto una entrega de al menos una vez).
F.current_timestamp() marca cada fila con la hora de ingestión en el controlador, lo que le proporciona un registro de auditoría fiable de cuándo entró cada resultado en el pipeline.
Paso 6: Iniciar la consulta de streaming
Ahora conecte todo adjuntando el controlador foreachBatch al flujo de tasa e iniciando la consulta:
# pipeline.py (continuación)
# Conecta el controlador foreachBatch y configura el intervalo de activación
query = rate_stream.writeStream
.foreachBatch(process_batch)
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} segundos")
.option("checkpointLocation", config.CHECKPOINT_PATH)
.start()
print(f"Consulta de streaming iniciada. Se activa cada {config.TRIGGER_INTERVAL_SECONDS} segundos.")
print("Pulse Ctrl+C para detenerla.")
# Espera a que la consulta finalice (se ejecuta indefinidamente hasta que se interrumpa)
query.awaitTermination()La llamada .trigger(processingTime="60 segundos") indica a Spark que active un nuevo micro-lote cada 60 segundos —una vez por minuto— independientemente del número de filas que haya generado la fuente de tasa. Este es el mecanismo que regula el ritmo de tus llamadas a la API SERP, manteniéndote dentro de los límites de tasa sin dejar de ejecutarse de forma continua.
La opción .option("checkpointLocation", ...) es fundamental para la tolerancia a fallos. Spark escribe los metadatos de progreso de la consulta (desplazamientos, lotes confirmados) en este directorio. Si el proceso se bloquea y se reinicia, Spark lee el punto de control para determinar qué lotes ya se han procesado y reanuda la ejecución correctamente desde el punto adecuado.
Paso 7: Ejecuta e inspecciona los resultados
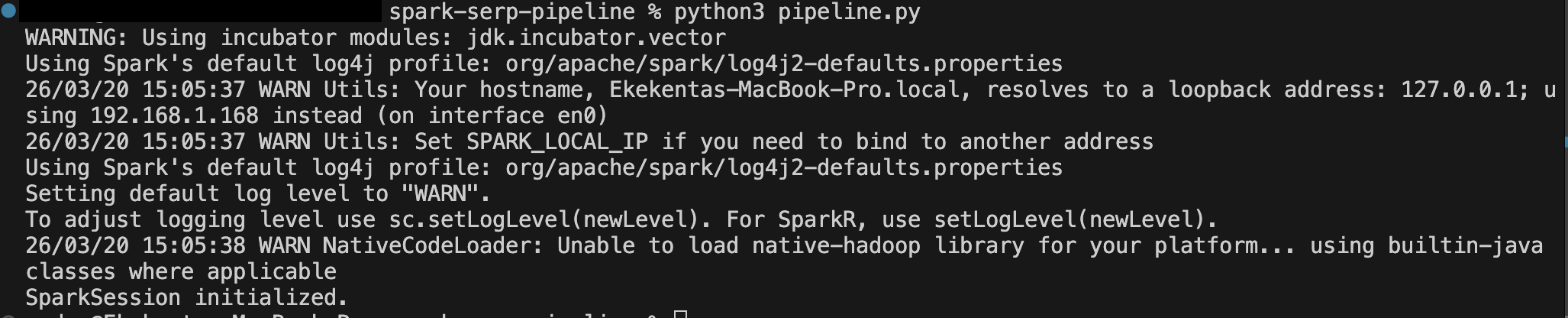
Ejecute el pipeline desde su terminal:
python pipeline.pyDeberías ver una salida similar a la siguiente después de que se active el primer disparador:
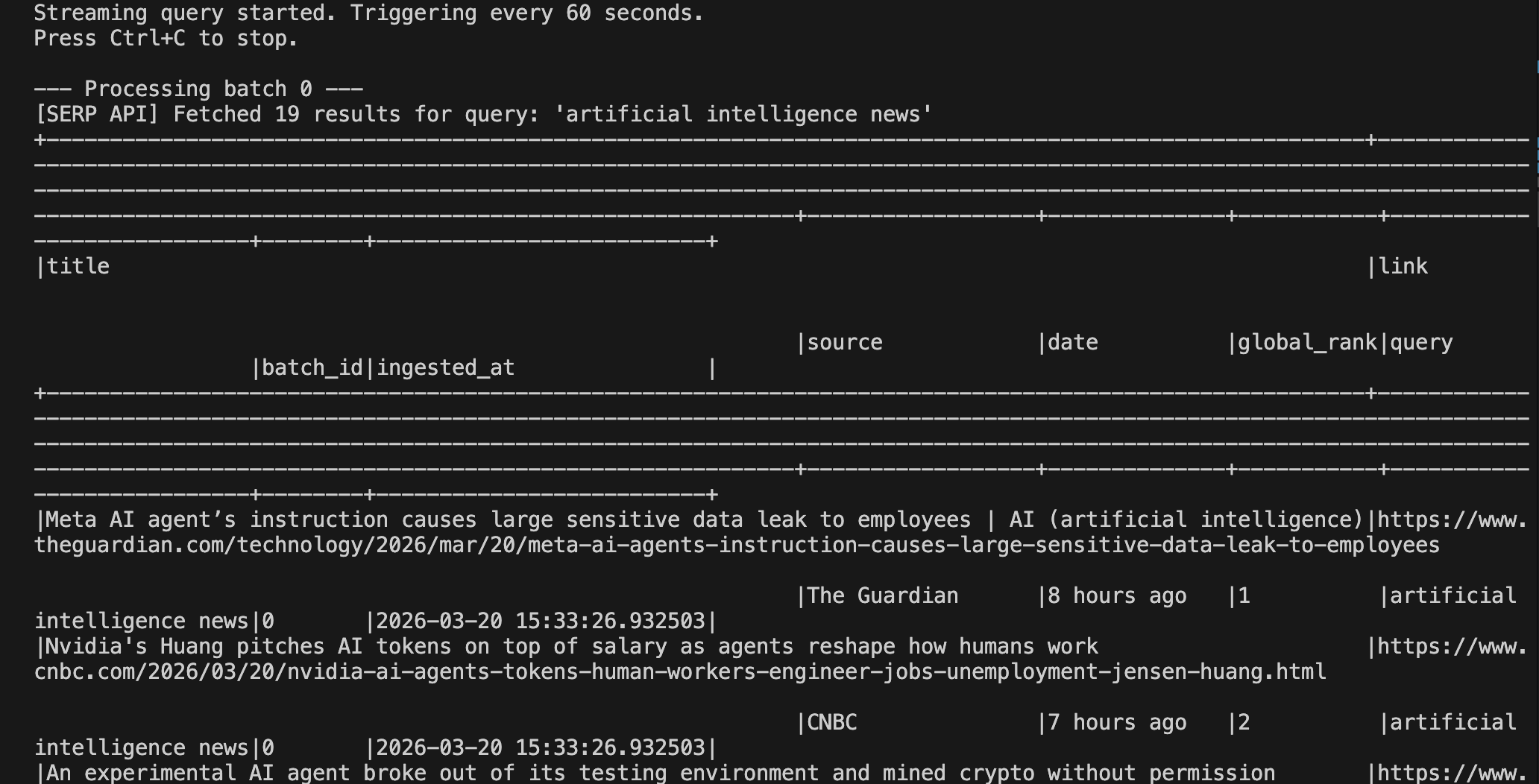
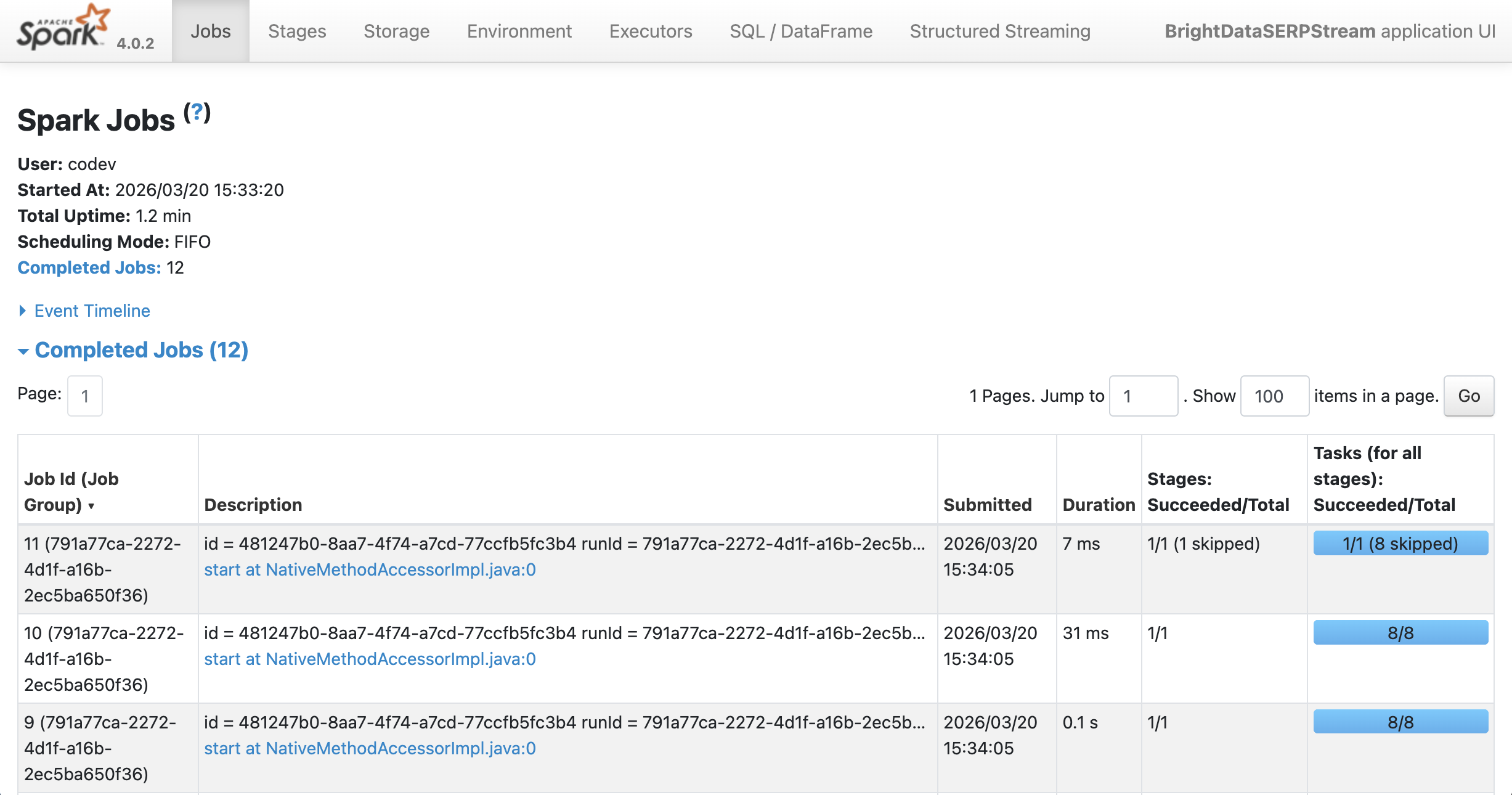
Puedes ver la salida ejecutándose en Spark en localhost:4040:
Tras unos minutos de ejecución, revisa el directorio de salida:
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/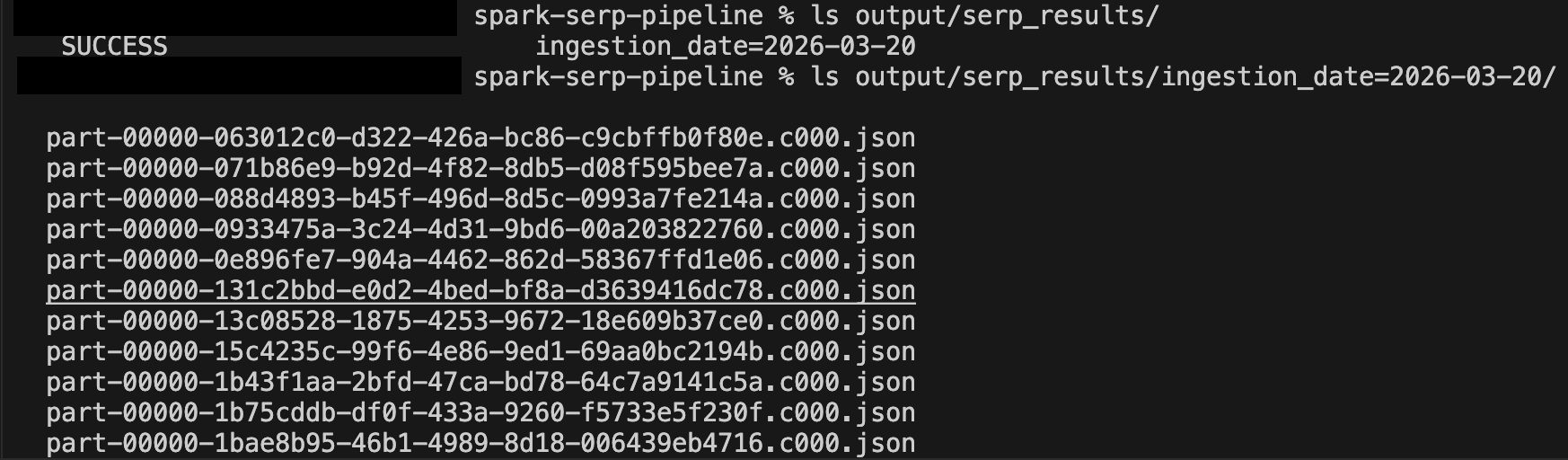
Puede volver a leer los resultados en Spark para realizar un análisis ad hoc en cualquier momento:
# Volver a leer los resultados acumulados
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)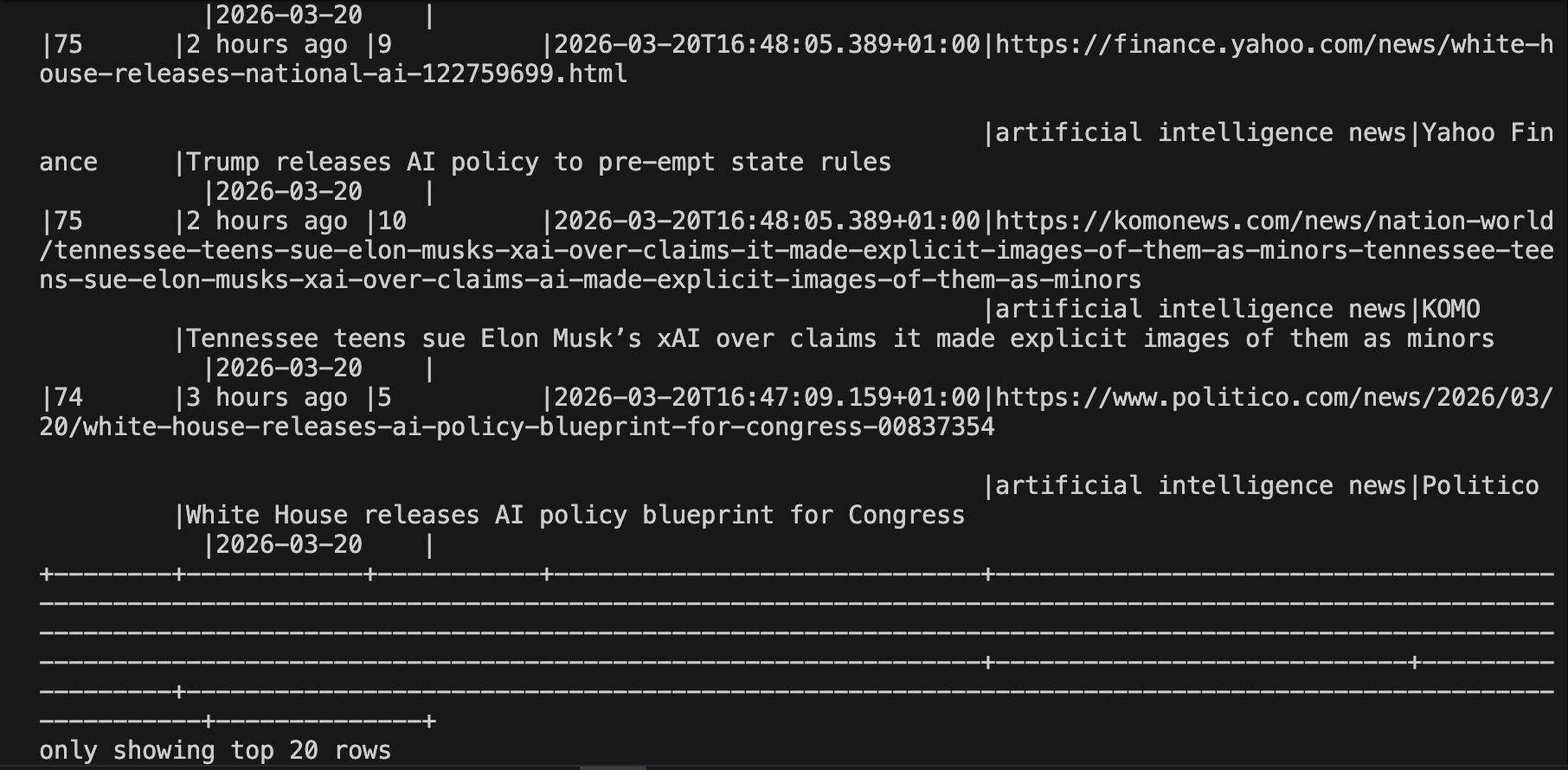
Aquí tienes el código completo del pipeline en un solo lugar para facilitar la consulta.
Llevándolo más allá
Este ejemplo muestra un patrón de ingestión básico, pero hay muchas direcciones en las que puedes llevarlo:
- En lugar de un único tema, mantenga una lista de palabras clave y distribuya las llamadas a la API SERP en paralelo dentro de cada invocación
de foreachBatch. Utiliceconcurrent.futures.ThreadPoolExecutorde Python para llamar a la API SERP para múltiples consultas simultáneamente dentro del mismo micro-lote. - Sustituya el sumidero JSON por una tabla Delta para obtener escrituras incrementales compatibles con ACID y con soporte para la evolución del esquema. Esto simplifica mucho las consultas históricas y la deduplicación.
- La API SERP de Bright Data admite consultas en el motor de búsqueda Bing, además de Google, DuckDuckGo, Yandex y otros. Realice consultas en varios motores en paralelo dentro del mismo lote y combine los conjuntos de resultados.
- Utilice Web Unlocker de Bright Data para seguir las URL devueltas por la API SERP y recuperar el contenido HTML o Markdown completo de cada artículo. Canalice ese contenido a una etapa de NLP posterior dentro del mismo pipeline de Spark.
- Implemente el pipeline en Databricks, AWS EMR o Google Dataproc para obtener una escalabilidad de nivel de producción. En Databricks, también puede utilizar Delta Live Tables para gestionar el pipeline de forma declarativa.
- Escriba los resultados SERP enriquecidos en un tema de Kafka y utilícelos en tiempo real desde microservicios, paneles de control o sistemas de alertas posteriores.
Conclusión
En este tutorial, has aprendido a utilizar la API SERP de Bright Data para ingestar continuamente resultados de motores de búsqueda en tiempo real y procesarlos con Apache Spark Structured Streaming. Utilizando la fuente de frecuencia como reloj de programación y foreachBatch como puente de integración, ha creado un pipeline de ejecución continua que recupera datos SERP actualizados en cada activación, los transforma en un Spark DataFrame tipado y escribe los resultados en un sumidero JSON particionado, todo ello con puntos de control tolerantes a fallos integrados.
Este patrón es ideal para cualquier equipo que necesite procesar señales de búsqueda web en tiempo real a gran escala: seguimiento de posicionamiento de palabras clave, monitorización de la competencia, agregación de noticias, inteligencia publicitaria y mucho más. A diferencia de las consultas ad hoc basadas en scripts, un pipeline de Spark Structured Streaming te ofrece una base distribuida, recuperable y fácilmente extensible que crece al ritmo de tus volúmenes de datos.
Para crear pipelines más avanzadas, explore la suite completa de productos de datos web de Bright Data, que incluye Web Unlocker para eludir la protección contra bots en URL arbitrarias, Navegador de scraping para sitios con gran cantidad de JavaScript y Conjuntos de datos listos para usar para las plataformas más populares.
Regístrese hoy mismopara obtener una cuenta gratuita de Bright Data y comience a potenciar sus pipelines de datos con datos web fiables y en tiempo real.






