

En esta guía aprenderás:
- Qué es
curl_cffiy las funciones que ofrece - Cómo minimiza la detección de bots basada en huellas digitales TLS
- Cómo utilizarlo con Python para el Scraping web
- Usos y métodos avanzados
- Una comparación con clientes HTTP similares
¡Empecemos!
¿Qué es curl_cffi?
curl_cffi es una biblioteca que proporciona enlaces Python para la bifurcación curl-impersonate a través de CFFI. En otras palabras, es un cliente HTTP capaz de suplantar las huellas digitales TLS/JA3/HTTP2 del navegador. Esto convierte a la biblioteca en una solución excelente para eludir los bloqueos antibots basados en huellas digitales TLS.
⚙️ Características
- Admite la suplantación de huellas digitales JA3/TLS y HTTP2, incluidos los navegadores recientes y las huellas digitales personalizadas.
- Mucho más rápido que
requestsyhttpx, a la par conaiohttp - Imita la API de
solicitudes. - Admite
asynciopara solicitudes HTTP asíncronas - Compatible con la rotación de proxies en cada solicitud
- Compatible con HTTP/2.0
- Compatible con
WebSockets
Cómo funciona
curl_cffi se basa en cURL Impersonate, una biblioteca que genera huellas digitales TLS que coinciden con los navegadores del mundo real.
Cuando envías una solicitud HTTPS, se produce un protocolo de enlace TLS, que genera una huella digital TLS única. Dado que los clientes HTTP difieren de los navegadores, sus huellas digitales pueden exponer la automatización, lo que activa las defensas antibots.
cURL Impersonate modifica cURL para que coincida con las huellas digitales TLS de los navegadores reales:
- Ajustes de la biblioteca TLS: se basan en las bibliotecas para la conexión TLS utilizadas por los navegadores en lugar de las de cURL.
- Cambios en la configuración: Ajuste las extensiones TLS y las opciones SSL para imitar a los navegadores.
- Personalización de HTTP/2: coincidir con la configuración de handshake del navegador.
- Indicadores cURL no predeterminados: establezca
--ciphers,--curvesy encabezados personalizados para mayor precisión.
Esto hace que las solicitudes parezcan procedentes de un navegador, lo que ayuda a eludir la detección de bots. Para obtener más información, consulte nuestra guía sobre cURL Impersonate.
Cómo utilizar curl_cffi para el Scraping web: guía paso a paso
Supongamos que su objetivo es extraer la página «Teclado» de Walmart:
Si intenta acceder a esta página utilizando cualquier cliente HTTP, recibirá la siguiente página de error:
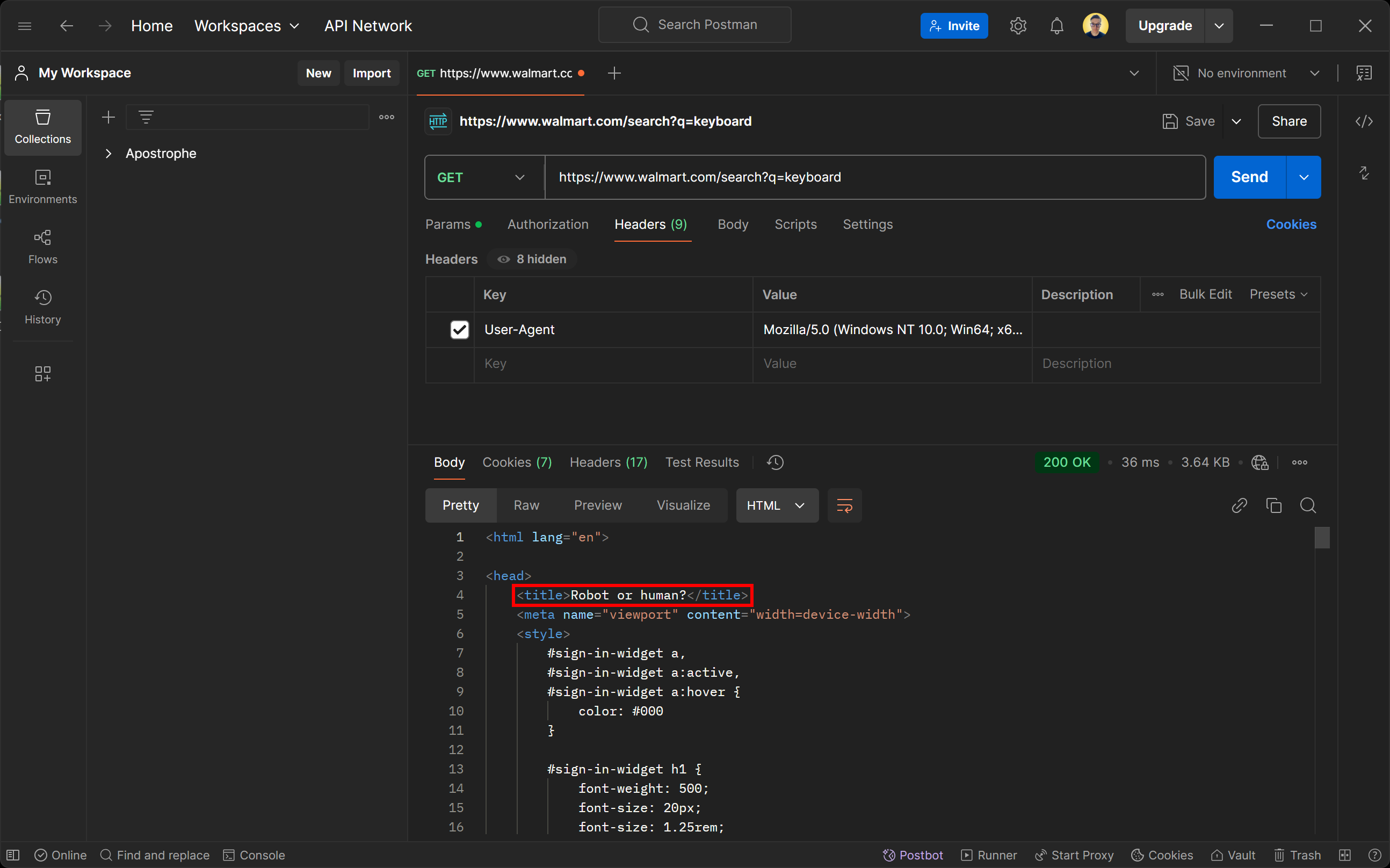
No se deje engañar por el estado de respuesta 200 OK. La página devuelta por el servidor de Walmart es en realidad una página de detección de bots. Le pide específicamente que verifique si es humano con un desafío CAPTCHA.
Quizás te preguntes: ¿cómo es posible esto, incluso si configuras el agente de usuario para simular un navegador real? ¡La respuesta es la huella digital TLS!
Ahora, veamos cómo utilizar curl_cffi para evitar las medidas antibots y realizar el Scraping web con facilidad.
Paso n.º 1: Configuración del proyecto
En primer lugar, asegúrate de que tienes Python 3+ instalado en tu equipo. Si no es así, descárgalo desde el sitio web oficial y sigue las instrucciones de instalación.
A continuación, crea un directorio para tu proyecto de scraping con curl_cffi utilizando este comando:
mkdir curl-cfii-Scraper
Navega hasta ese directorio y configura un entorno virtual dentro de él:
cd curl-cfii-Scraper
python -m venv env
Abra la carpeta del proyecto en su IDE de Python preferido. Visual Studio Code con la extensión Python o PyCharm Community Edition son opciones válidas.
Ahora, crea un archivo scraper.py dentro de la carpeta del proyecto. Al principio estará vacío, pero pronto le añadirás la lógica de scraping.
En la terminal de tu IDE, activa el entorno virtual. En Linux o macOS, utiliza:
./env/bin/activate
De forma equivalente, en Windows, ejecute:
env/Scripts/activate
¡Genial! Ya lo tienes todo configurado y listo para empezar.
Paso n.º 2: Instalar curl_cffi
En un entorno virtual activado, instala el cliente HTTP a través del paquete pip curl-cffi:
pip install curl-cffi
Entre bastidores, esta biblioteca descarga automáticamente los binarios de suplantación de curl para Windows, macOS y Linux.
Paso n.º 3: Conéctese a la página de destino
Importe las solicitudes desde curl_cffi:
from curl_cffi import requests
Este objeto expone una API de alto nivel similar a la de la biblioteca Python Requests.
Puede utilizarlo para realizar una solicitud HTTP GET a la página de destino de la siguiente manera:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
El argumento impersonate="chrome" le dice a curl_cffi que haga que la solicitud HTTP parezca provenir de la última versión de Chrome. Como resultado, Walmart tratará la solicitud automatizada como una solicitud normal del navegador y devolverá la página web estándar en lugar de una página antibots.
Puede acceder al contenido HTML de la página de destino con:
html = response.text
Si imprimes html, verás:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Electrónica - Walmart.com</title>
<!-- omitido por brevedad ... -->
¡Genial! Ese es el código HTML de la página de productos «teclado» normal de Walmart.
Paso n.º 4: añadir la lógica de extracción de datos
curl_cffi es solo un cliente HTTP que te ayuda a recuperar el HTML de una página. Si deseas realizar Scraping web, también necesitarás una biblioteca para el Parseo de HTML como BeautifulSoup. Para obtener más información, consulta nuestra guía sobre Scraping web con BeautifulSoup.
En el entorno virtual activado, instala BeautifulSoup:
pip install beautifulsoup4
Importe en scraper.py:
from bs4 import BeautifulSoup
A continuación, utilízalo para realizar el parseo del HTML de la página:
soup = BeautifulSoup(response.text, "html.parser")
«html.parser» es el analizador HTML predeterminado de la biblioteca estándar de Python que utiliza BeautifulSoup para realizar el parseo de la cadena HTML. Ahora, soup contiene todos los métodos que necesitas para seleccionar elementos HTML en la página y extraer datos de ellos.
En este ejemplo, como el parseo no es lo más importante, solo extraeremos el título de la página. Puedes seleccionarlo mediante un selector CSS utilizando el método find() y, a continuación, acceder a su texto con el atributo text:
title_element = soup.find("title")
title = title_element.text
Para una lógica de extracción más avanzada, consulta nuestra guía sobre cómo extraer datos de Walmart.
Por último, imprima el título de la página:
print(title)
¡Genial! Ha implementado la lógica básica de Scraping web.
Paso n.º 5: Ponlo todo junto
Este es tu script final de Scraping web con curl_cffi:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Envía una solicitud GET a la página de búsqueda de Walmart para «teclado»
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# Extrae el HTML de la página
html = response.text
# Analizar el contenido de la respuesta con BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Buscar la etiqueta del título utilizando un selector CSS e imprimirla
title_element = soup.find("title")
# Extraer los datos de la misma
title = title_element.text
# Lógica de parseo más compleja...
# Imprimir los datos extraídos
print(title)
Ejecutarlo con el siguiente comando:
python3 Scraper.py
O, de forma equivalente, en Windows:
python Scraper.py
El resultado será:
Electrónica - Walmart.com
Si elimina el argumento impersonate="chrome", obtendrá en su lugar:
¿Robot o humano?
Esto demuestra cómo la suplantación del navegador marca la diferencia a la hora de evitar las medidas antiscraping.
¡Misión cumplida!
curl_cffi: uso avanzado
Ahora que ya sabes cómo funciona la biblioteca, estás listo para explorar algunos escenarios más avanzados.
Selección de suplantación de navegador
curl_cffi admite la suplantación de varios navegadores. Cada navegador está asociado a una etiqueta única que puede pasar al argumento de suplantación como se muestra a continuación:
response = requests.get("<TU_URL>", impersonate="<ETIQUETA_DEL_NAVEGADOR>")
Estas son las etiquetas de los navegadores compatibles:
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
Notas:
- Para simular siempre las últimas versiones del navegador, basta con utilizar
chrome,safariysafari_ios. - Firefox no está disponible actualmente, ya que solo se admiten navegadores basados en WebKit.
- Las versiones del navegador solo se añaden cuando cambian sus huellas digitales. Si se omite una versión, como
chrome122, puede seguir suplantarla utilizando los encabezados de la versión anterior. - Para objetivos que no sean navegadores, utilice
ja3,akamaiy argumentos similares para especificar sus propias huellas digitales TLS personalizadas. Para obtener más información, consulte la documentación sobre suplantación.
Gestión de sesiones
Al igual que la biblioteca de solicitudes, curl-cfii admite sesiones. Los objetos de sesión le permiten mantener ciertos parámetros en varias solicitudes, como cookies, encabezados u otros datos específicos de la sesión.
Así es como puede definir una sesión utilizando los enlaces Python para la biblioteca cURL Impersonate:
# Crear una nueva sesión
session = requests.Session()
# Este punto final establece una cookie en el servidor
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# Imprimir las cookies de la sesión para confirmar que se están almacenando
print(session.cookies)
El resultado del script anterior será:
<Cookies[<Cookie userId=5 for httpbin.org />]>
El resultado demuestra que la sesión mantiene el estado entre solicitudes, como el almacenamiento de cookies definidas por el servidor.
Integración de Proxy
Al igual que la biblioteca de solicitudes, curl_cffi admite la integración de Proxy a través de un objeto proxies:
# Defina la URL de su Proxy.
proxy = "YOUR_PROXY_URL"
# Cree un diccionario de proxies para HTTP y HTTPS.
proxies = {"http": proxy, "https": proxy}
# Realiza una solicitud utilizando un Proxy y la suplantación del navegador
response = requests.get("<TU_URL>", impersonate="chrome", proxies=proxies)
Dado que las API subyacentes son muy similares a las solicitudes, consulta nuestra guía sobre cómo utilizar un Proxy en Solicitudes.
API asíncrona
curl_cffi admite solicitudes asíncronas a través de asyncio mediante el objeto AsyncSession:
from curl_cffi.requests import AsyncSession
import asyncio
# Define una función asíncrona para ejecutar el código asíncrono
async def fetch_data():
async with AsyncSession() as session:
# Realiza la solicitud GET asíncrona
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# Imprimir el texto de la respuesta
print(response.text)
# Ejecutar la función asíncrona
asyncio.run(fetch_data())
El uso de AsyncSession facilita el manejo eficiente de múltiples solicitudes asíncronas, lo cual es vital para acelerar el Scraping web.
Conexión WebSockets
curl_cffi también admite WebSocketsa través de la clase WebSocket:
from curl_cffi.requests import WebSocket
# Define una función de devolución de llamada para gestionar los mensajes entrantes
def on_message(ws, message):
print(message)
# Inicializar la conexión WebSocket con la devolución de llamada
ws = WebSocket(on_message=on_message)
# Conectarse a un servidor WebSocket de muestra y escuchar los mensajes
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
Esto resulta especialmente útil para extraer datos en tiempo real de sitios web o API que utilizan WebSocket para rellenar datos de forma dinámica. Algunos ejemplos son los sitios web con datos del mercado financiero, resultados deportivos en directo o chats en vivo.
En lugar de extraer páginas renderizadas, puede dirigirse directamente al canal WebSocket para recuperar datos de forma eficiente.
Nota: Puede utilizar WebSocketsde forma asíncrona gracias a la clase AsyncWebSocket.
curl_cffi vs Requests vs AIOHTTP vs HTTPX para el Scraping web
A continuación se muestra una tabla resumen para comparar curl_cffi con otros clientes HTTP de Python populares para el Scraping web:
| Característica | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| API de sincronización | ✔️ | ✔️ | ❌ | ✔️ |
| API asíncrona | ✔️ | ❌ | ✔️ | ✔️ |
Compatibilidad con **WebSocket**s |
✔️ | ❌ | ✔️ | ❌ |
| Agrupación de conexiones | ✔️ | ✔️ | ✔️ | ✔️ |
| Compatibilidad con HTTP/2 | ✔️ | ❌ | ❌ | ✔️ |
Personalización de**User-Agent** |
✔️ | ✔️ | ✔️ | ✔️ |
| Suplantación de huella digital TLS | ✔️ | ❌ | ❌ | ❌ |
| Velocidad | Alta | Media | Alta | Media |
| Mecanismo de reintento | ❌ | Disponible a través de HTTPAdapters |
Disponible solo a través de una biblioteca de terceros | Disponible a través de transportesintegrados |
| Integración de Proxy | ✔️ | ✔️ | ✔️ | ✔️ |
| Gestión de cookies | ✔️ | ✔️ | ✔️ | ✔️ |
curl_cffi Alternativas para el Scraping web
curl_cffi implica un enfoque manual del Scraping web, en el que es necesario escribir la mayor parte del código por uno mismo. Aunque es adecuado para sitios web estáticos sencillos, puede resultar complicado cuando se trata de sitios dinámicos o más seguros.
Bright Data ofrece una gama de alternativas a curl_cffi para el Scraping web:
- API de navegador de scraping: instancias de navegador en la nube totalmente gestionadas e integradas con Puppeteer, Selenium y Playwright. Estos navegadores ofrecen Resolución de CAPTCHA integrada y Proxy rotativo, lo que permite eludir las defensas antibots e interactuar con los sitios web como si se tratara de usuarios reales.
- API de Scraper: puntos finales preconfigurados para recuperar datos nuevos y estructurados de más de 100 dominios populares. Estas API son éticas y cumplen con la normativa, lo que permite una fácil extracción de datos utilizando HTTPX o cualquier otro cliente HTTP.
- Scraper sin código: un servicio de recopilación de datos intuitivo y bajo demanda que elimina la necesidad de codificar. Ofrece control, escalabilidad y flexibilidad sin tener que lidiar con infraestructura, Proxies u obstáculos antirrascado.
- Conjuntos de datos: acceda a conjuntos de datos preconstruidos de varios sitios web o personalice las recopilaciones de datos para que se adapten a sus necesidades.
Estas soluciones simplifican el scraping al ofrecer herramientas de extracción de datos robustas, escalables y conformes que reducen el esfuerzo manual.
Conclusión
En este artículo, ha descubierto cómo utilizar la biblioteca curl_cffi para el Scraping web. Ha explorado su finalidad, sus características principales y sus ventajas. Este cliente HTTP destaca por ser una opción rápida y fiable para realizar solicitudes que imitan a los navegadores reales.
Sin embargo, las solicitudes HTTP automatizadas pueden exponer su dirección IP pública, revelando potencialmente su identidad y ubicación, lo que supone un riesgo para la privacidad. Para proteger su seguridad y anonimato, una de las soluciones más eficaces es utilizar un Proxy para ocultar su dirección IP.
Bright Data controla los mejores servidores Proxy del mundo, prestando servicio a empresas de la lista Fortune 500 y a más de 20 000 clientes. Su oferta incluye una amplia gama de tipos de Proxy:
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxies residenciales: más de 72 millones de IPs residenciales en más de 195 países.
- Proxy ISP: más de 700 000 IP de ISP.
¡Cree hoy mismo una cuenta gratuita en Bright Data para probar nuestros Proxies y soluciones de scraping!




