

En esta guía sobre el Scraping web con Parsel en Python, aprenderás:
- Qué es Parsel
- Por qué utilizarlo para el Scraping web
- Un tutorial paso a paso que muestra cómo utilizar Parsel para el Scraping web
- Escenarios avanzados de scraping con Parsel en Python
¡Empecemos!
¿Qué es Parsel?
Parsel es una biblioteca de Python para el parseo y la extracción de datos de documentos HTML, XML y JSON. Se basa en lxml y proporciona una interfaz de mayor nivel y más fácil de usar para el Scraping web. En concreto, ofrece una API intuitiva que simplifica el proceso de extracción de datos de documentos HTML y XML.
¿Por qué utilizar Parsel para el Scraping web?
Parsel incluye interesantes funciones para el Scraping web, como:
- Compatibilidad con selectores XPath y CSS: utilice selectores XPath o CSS para localizar elementos en documentos HTML o XML. Obtenga más información en nuestra guía sobre selectores XPath y CSS para el Scraping web.
- Extracción de datos: recupere texto, atributos u otro contenido de los elementos seleccionados.
- Encadenamiento de selectores: encadene varios selectores para refinar la extracción de datos.
- Escalabilidad: la biblioteca funciona bien tanto con proyectos de scraping pequeños como grandes.
Tenga en cuenta que la biblioteca está estrechamente integrada en Scrapy, que la utiliza para el parseo y la extracción de datos de páginas web. No obstante, Parsel también se puede utilizar como biblioteca independiente.
Cómo utilizar Parsel en Python para el Scraping web: tutorial paso a paso
Esta sección le guiará a través del proceso de scraping web con Parsel en Python. El sitio de destino será«Equipos de hockey: formularios, búsqueda y paginación»:

El Scraper Parsel extraerá todos los datos de la tabla anterior. Siga los pasos que se indican a continuación y vea cómo se construye.
Requisitos previos y dependencias
Para replicar este tutorial, debe tener instalado Python 3.10.1 o superior en su máquina. En particular, tenga en cuenta que Parsel ha eliminado recientemente la compatibilidad con Python 3.8.
Supongamos que la carpeta principal de su proyecto se llama parsel_scraping/. Al final de este paso, la carpeta tendrá la siguiente estructura:
parsel_scraping/
├── parsel_scraper.py
└── venv/Donde:
parsel_scraper.pyes el archivo Python que contiene la lógica de scraping.venv/contiene el entorno virtual.
Puedes crear el directorio del entorno virtual venv/ de la siguiente manera:
python -m venv venvPara activarlo, en Windows, ejecute:
venvScriptsactivateDe forma equivalente, en macOS y Linux, ejecute:
source venv/bin/activateEn un entorno virtual activado, instale las dependencias con:
pip install parsel requestsEstas dos dependencias son:
parsel: una biblioteca para el parseo de HTML y la extracción de datos.requests: necesaria porqueparseles solo un analizador HTML. Para realizar el Scraping web, también necesitas un cliente HTTP como Requests para recuperar los documentos HTML de las páginas que deseas rastrear.
¡Genial! Ahora ya tiene lo necesario para realizar Scraping web con Parsel en Python.
Paso 1: Define la URL de destino y realiza el Parseo del contenido
Como primer paso de este tutorial, debes importar las bibliotecas:
import requests
from parsel import SelectorA continuación, define la página web de destino, obtén el contenido con Requests y realiza el parseo con Parsel:
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
selector = Selector(text=response.text)El fragmento anterior instancia la clase Selector() de Parsel. Esto realiza el parseo del HTML leído de la respuesta de la solicitud HTTP realizada con get().
Paso 2: extraer todas las filas de la tabla
Si inspeccionas la tabla de la página web de destino en el navegador, verás el siguiente HTML:
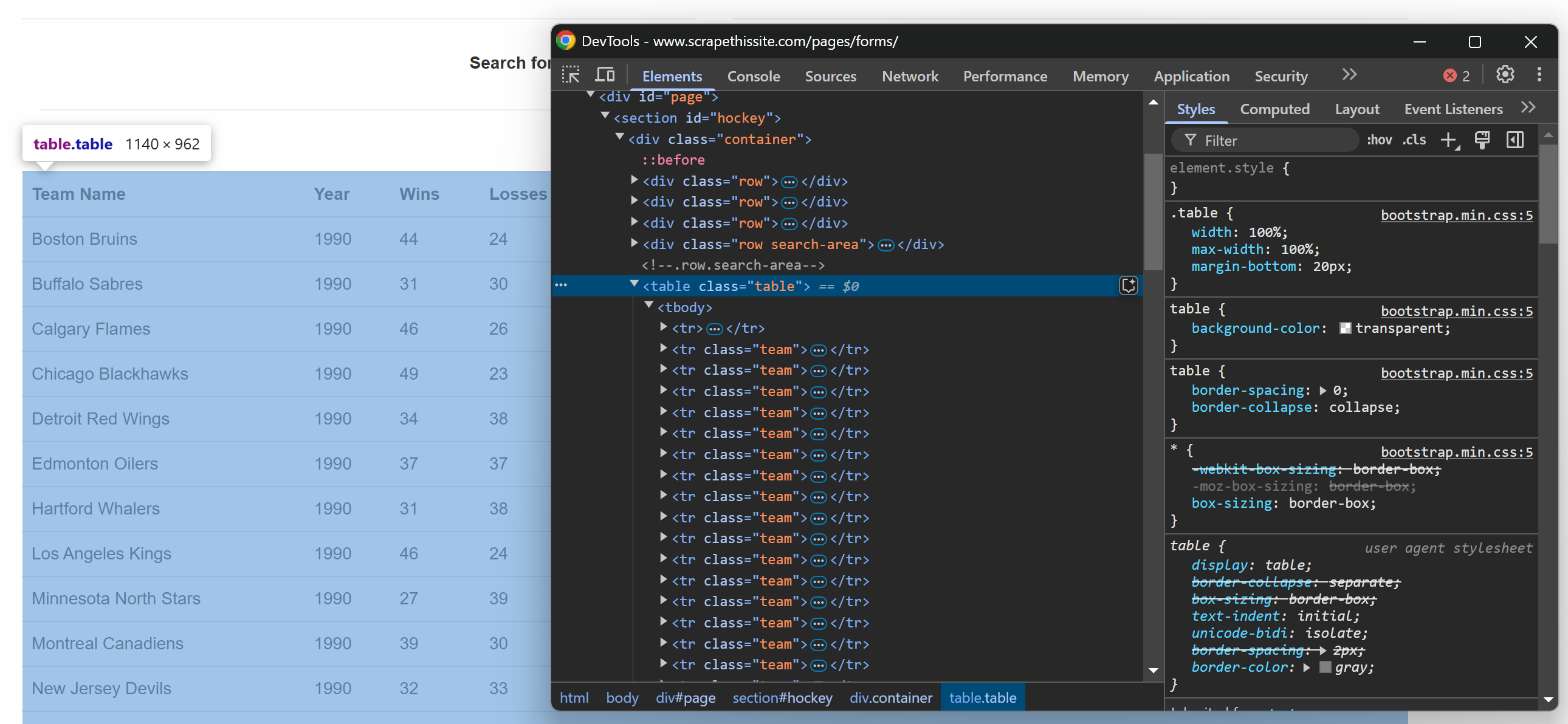
Dado que la tabla contiene varias filas, inicialice una matriz donde almacenar los datos extraídos:
data = []Ahora, tenga en cuenta que la tabla HTML tiene una clase .table. Para seleccionar todas las filas de la tabla, puede utilizar la siguiente línea de código:
rows = selector.css("table.table tr.team")Esto utiliza el método css() y aplica el selector CSS a la estructura HTML parseada.
¡Es hora de iterar sobre las filas seleccionadas y extraer los datos de ellas!
Paso 3: Iterar sobre las filas
Al igual que antes, inspeccione una fila dentro de la tabla:
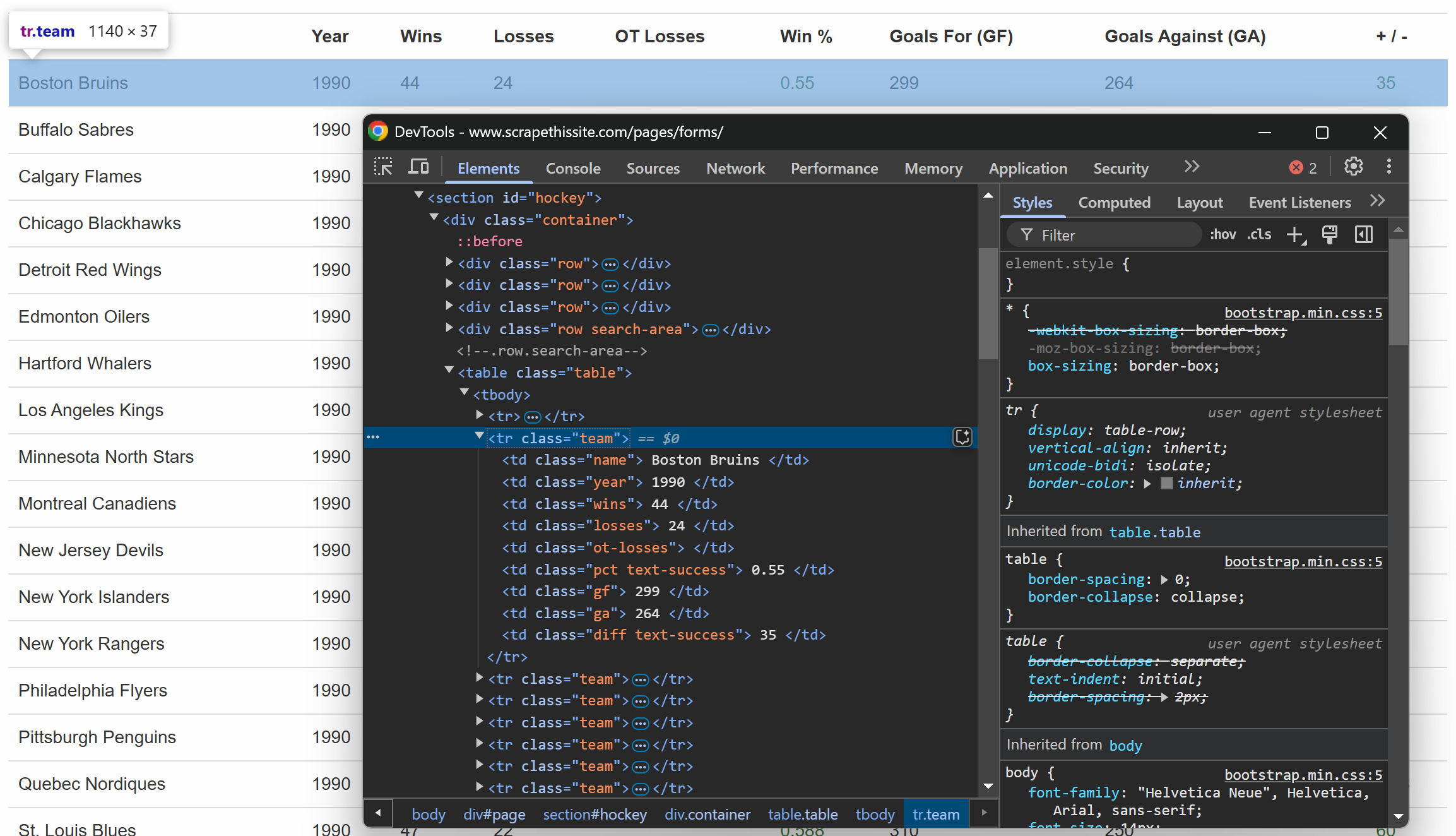
Lo que se puede observar es que cada fila contiene la siguiente información en columnas específicas:
- Nombre del equipo → dentro del elemento
.name - Año de la temporada → dentro del elemento
.year - Número de victorias → dentro del elemento
.wins - Número de derrotas → dentro del elemento
.losses - Derrotas en la prórroga → dentro del elemento
.ot-losses - Porcentaje de victorias → dentro del elemento
.pct - Goles marcados (Goles a favor – GF) → dentro del elemento
.gf - Goles encajados (Goles en contra – GA) → dentro del elemento
.ga - Diferencia de goles → dentro del elemento
.diff
Puedes extraer toda esa información con la siguiente lógica:
for row in rows:
# Extraer datos de cada columna
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Añadir los datos extraídos
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip()
})Esto es lo que hace el código anterior:
- El método
get()selecciona nodos de texto utilizando pseudoelementos CSS3. - El método
strip()elimina cualquier espacio en blanco al principio y al final. - El método
append()añade el contenido a la listade datos.
¡Genial! Lógica de extracción de datos de Parsel completada.
Paso 4: Imprimir los datos y ejecutar el programa
Como paso final, imprima los datos extraídos en la CLI:
# Imprimir los datos extraídos
print("Datos de la página:")
for entry in data:
print(entry)Ejecutar el programa:
python parsel_scraper.pyEste es el resultado esperado:
¡Increíble! Son exactamente los datos de la página, pero en un formato estructurado.
Paso 5: Gestionar la paginación
Hasta el paso anterior, has recuperado los datos de la página principal de la URL de destino. ¿Qué pasa si ahora quieres recuperarlos todos? Para ello, debes gestionar la paginación realizando algunos cambios en el código.
En primer lugar, debe encapsular el código anterior en una función como esta:
def scrape_page(url):
# Obtener el contenido de la página
response = requests.get(url)
# Parseo del contenido HTML
selector = Selector(text=response.text)
# Lógica de scraping...
return dataAhora, echa un vistazo al elemento HTML que gestiona la paginación:
Este incluye una lista de todas las páginas, cada una con la URL incrustada en un elemento <a>. Encapsula la lógica para recuperar todas las URL de paginación en una función:
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Obtener la primera página para extraer los enlaces de paginación
response = requests.get(base_url)
# Analizar la página
selector = Selector(text=response.text)
# Extraer todos los enlaces de la página del área de paginación
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Ajustar el selector en función de la estructura HTML
unique_links = list(set(page_links)) # Eliminar duplicados si los hay
# Construir URL completas para todas las páginas
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urlsEsta función hace lo siguiente:
- El método
getall()recupera todos los enlaces de paginación. - El método
list(set())elimina los duplicados para evitar visitar la misma página dos veces. - El método
urljoin(), de la bibliotecaurlib.parse, convierte todas las URL relativas en URL absolutas para que puedan utilizarse en futuras solicitudes HTTP.
Para que el código anterior funcione, asegúrate de importar urljoin desde la biblioteca estándar de Python:
from urllib.parse import urljoin Ahora puede extraer todas las páginas con:
# Dónde almacenar los datos extraídos
data = []
# Obtener todas las URL de las páginas
page_urls = get_all_page_urls()
# Iterar sobre ellas y aplicar la lógica de rastreo
for url in page_urls:
# Rastrear la página actual
page_data = scrape_page(url)
# Añadir los datos rastreados a la lista
data.extend(page_data)
# Imprimir los datos extraídos
print("Datos de todas las páginas:")
for entry in data:
print(entry)El fragmento anterior:
- Recupera todas las URL de las páginas llamando a la función
get_all_page_urls(). - Extrae datos de cada página llamando a la función
scrape_page(). A continuación, agrega los resultados con el métodoextend(). - Imprime los datos extraídos.
¡Fantástico! La lógica de paginación de Parsel ya está implementada.
Paso 6: Ponlo todo junto
A continuación se muestra lo que debería contener ahora el archivo parsel_scraper.py:
import requests
from parsel import Selector
from urllib.parse import urljoin
def scrape_page(url):
# Obtener el contenido de la página.
response = requests.get(url)
# Realizar el parseo del contenido HTML.
selector = Selector(text=response.text)
# Dónde almacenar los datos extraídos.
data = []
# Seleccionar todas las filas del cuerpo de la tabla
rows = selector.css("table.table tr.team")
# Iterar sobre cada fila y extraer los datos de la misma
for row in rows:
# Extraer los datos de cada columna
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Añadir los datos extraídos a la lista
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip(),
})
return data
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Obtener la primera página para extraer los enlaces de paginación.
response = requests.get(base_url)
# Realizar el parseo de la página.
selector = Selector(text=response.text)
# Extraer todos los enlaces de la página del área de paginación
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Ajustar el selector según la estructura HTML
unique_links = list(set(page_links)) # Eliminar duplicados, si los hay
# Construir URL completas para todas las páginas
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urls
# Dónde almacenar los datos extraídos
data = []
# Obtener todas las URL de las páginas
page_urls = get_all_page_urls()
# Iterar sobre ellas y aplicar la lógica de rastreo
for url in page_urls:
# Rastrear la página actual
page_data = scrape_page(url)
# Añadir los datos rastreados a la lista
data.extend(page_data)
# Imprimir los datos extraídos
print("Datos de todas las páginas:")
for entry in data:
print(entry)¡Muy bien! Has completado tu primer proyecto de scraping con Parsel.
Escenarios avanzados de Scraping web con Parsel en Python
En la sección anterior, aprendiste a utilizar Parsel en Python para extraer los datos de una página web de destino utilizando selectores CSS. ¡Es hora de considerar algunos escenarios más avanzados!
Seleccionar elementos por texto
Parsel ofrece diferentes métodos de consulta para recuperar el texto de HTML utilizando XPath. En este caso, la función text() se utiliza para extraer el contenido de texto de un elemento.
Imagina que tienes un código HTML como este:
<html>
<body>
<h1>Bienvenido a Parsel</h1>
<p>Este es un párrafo.</p>
<p>Otro párrafo.</p>
</body>
</html>Puede recuperar todo el texto de la siguiente manera:
from parsel import Selector
html = """
<html>
<body>
<h1>Bienvenido a Parsel</h1>
<p>Este es un párrafo.</p>
<p>Otro párrafo.</p>
</body>
</html>
"""
selector = Selector(text=html)
# Extraer texto de la etiqueta <h1>
h1_text = selector.xpath("//h1/text()").get()
print("Texto H1:", h1_text)
# Extraer texto de todas las etiquetas <p>
p_texts = selector.xpath("//p/text()").getall()
print("Nodos de texto de párrafo:", p_texts)Este fragmento localiza las etiquetas <p> y <h1> y extrae el texto de ellas con text(), lo que da como resultado:
Texto H1: Bienvenido a Parsel
Nodos de texto de párrafo: ['Este es un párrafo.', 'Otro párrafo.']Otra función útil es contains(), que se puede utilizar para buscar elementos que contengan un texto específico. Por ejemplo, supongamos que tienes el siguiente código HTML:
<html>
<body>
<p>Este es un párrafo de prueba.</p>
<p>Otro párrafo de prueba.</p>
<p>Contenido no relacionado.</p>
</body>
</html>Ahora quieres extraer el texto de los párrafos que solo contienen la palabra «prueba». Puedes hacerlo con el siguiente código:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraer párrafos que contengan la palabra «prueba»
test_paragraphs = selector.xpath("//p[contains(text(), 'test')]/text()").getall()
print("Párrafos que contienen 'prueba':", test_paragraphs)El Xpath p[contains(text(), 'test')]/text() se encarga de buscar el párrafo que solo contiene «test». El resultado será:
Párrafos que contienen «test»: ['Este es un párrafo de prueba.', 'Otro párrafo de prueba.']Pero, ¿qué pasa si quieres interceptar el texto que comienza con un valor específico de una cadena? ¡Pues puedes usar la función starts-with()! Considera este HTML:
<html>
<body>
<p>Empieza aquí.</p>
<p>Empieza de nuevo.</p>
<p>Termina aquí.</p>
</body>
</html>Para recuperar el texto de los párrafos que comienzan con la palabra «start», utiliza p[starts-with(text(), 'Start')]/text() de la siguiente manera:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extrae los párrafos cuyo texto comienza con «Start»
start_paragraphs = selector.xpath("//p[starts-with(text(), 'Start')]/text()").getall()
print("Párrafos que comienzan con 'Start':", start_paragraphs)El fragmento anterior produce:
Párrafos que comienzan con «Start»: ['Start here.', 'Start again.']Más información sobre los selectores CSS frente a los selectores XPath.
Uso de expresiones regulares
Parsel le permite recuperar texto para condiciones avanzadas utilizando expresiones regulares con la función re:test().
Considere este HTML:
<html>
<body>
<p>Elemento 12345</p>
<p>Elemento ABCDE</p>
<p>Un párrafo</p>
<p>2026 es el año actual</p>
</body>
</html>Para extraer el texto de los párrafos que solo contienen valores numéricos, puede utilizar re:test() de la siguiente manera:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraer párrafos cuyo texto coincida con un patrón numérico
numeric_items = selector.xpath("//p[re:test(text(), 'd+')]/text()").getall()
print("Elementos numéricos:", numeric_items)El resultado es:
Elementos numéricos: ['Elemento 12345', '2026 es el año actual']Otro uso típico de las expresiones regulares es interceptar direcciones de correo electrónico. Esto se puede utilizar para extraer texto de párrafos que solo contienen direcciones de correo electrónico. Por ejemplo, consideremos el siguiente HTML:
<HTML>
<BODY>
<P>Contáctanos en [email protected]</P>
<P>Envíe un correo electrónico a [email protected]</P>
<P>No hay correo electrónico aquí.</P>
</BODY>
</HTML>A continuación se muestra cómo se puede utilizar re:test() para seleccionar nodos que contienen direcciones de correo electrónico:
from parsel import Selector
selector = Selector(text=html)
# Extraer párrafos que contengan direcciones de correo electrónico
emails = selector.xpath("//p[re:test(text(), '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}')]/text()").getall()
print("Correos electrónicos coincidentes:", emails)El resultado es:
Correspondencias de correo electrónico: ['Contáctanos en [email protected]', 'Envíe un correo electrónico a [email protected]']Navegación por el árbol HTML
Parsel le permite navegar por el árbol HTML con XPath, sin importar cuán anidado esté.
Considere este HTML:
<html>
<body>
<div>
<h1>Título</h1>
<p>Primer párrafo</p>
</div>
</body>
</html>Puede obtener todos los elementos padres del nodo <p> de la siguiente manera:
from parsel import Selector
selector = Selector(text=html)
# Selecciona el padre de la etiqueta <p>
parent_of_p = selector.xpath("//p/parent::*").get()
print("Padre de <p>:", parent_of_p)El resultado es:
Elemento padre de <p>: <div>
<h1>Título</h1>
<p>Primer párrafo</p>
</div>Del mismo modo, puede gestionar elementos hermanos. Supongamos que tiene el siguiente código HTML:
<html>
<body>
<ul>
<li>Elemento 1</li>
<li>Elemento 2</li>
<li>Elemento 3</li>
</ul>
</body>
</html>Puede utilizar following-sibling para recuperar los nodos hermanos de la siguiente manera:
from parsel import Selector
selector = Selector(text=html)
# Selecciona el siguiente elemento hermano del primer elemento <li>
next_sibling = selector.xpath("//li[1]/following-sibling::li[1]/text()").get()
print("Siguiente hermano del primer <li>:", next_sibling)
# Selecciona todos los hermanos del primer elemento <li>
all_siblings = selector.xpath("//li[1]/following-sibling::li/text()").getall()
print("Todos los hermanos del primer <li>:", all_siblings)Lo que da como resultado:
Siguiente elemento hermano del primer <li>: Elemento 2
Todos los elementos hermanos del primer <li>: ['Elemento 2', 'Elemento 3']Alternativas al Parser para el parseo de HTML en Python
Parsel es una de las bibliotecas disponibles en Python para el Scraping web, pero no es la única. A continuación se muestran otras muy conocidas y ampliamente utilizadas:
- Beautiful Soup: una biblioteca de Python que facilita el scraping de información de páginas web. Aprende a utilizarla en nuestra guía sobre Scraping web con Beautiful Soup.
lxml: un enlace Pythonic para las bibliotecaslibxml2ylibxslt. Véalo en acción en nuestro tutorial sobre lxml para el parseo de datos web.- PyQuery: una biblioteca que le permite realizar consultas jQuery en documentos XML. Eso la convierte en uno de los 5 mejores analizadores HTML de Python.
- Scrapy: un marco colaborativo y de código abierto para extraer los datos que necesitas de los sitios web. Descubre cómo utilizar Scrapy para el Scraping web.
html.parser: un módulo de la biblioteca estándar de Python que proporciona una clase para el parseo de contenido HTML y XTHML de texto.html5-parser: una implementación rápida de HTML 5 en Python.
Conclusión
En este artículo, ha aprendido sobre Parsel en Python y cómo utilizarlo para el Scraping web. Ha comenzado con los conceptos básicos y luego ha explorado escenarios más complejos.
Independientemente de la biblioteca de scraping de Python que utilices, el mayor obstáculo es que la mayoría de los sitios web protegen sus datos con medidas antibots y antiscraping. Estas defensas pueden identificar y bloquear las solicitudes automatizadas, lo que hace que las técnicas de scraping tradicionales sean ineficaces.
Afortunadamente, Bright Data ofrece un conjunto de soluciones para evitar cualquier problema:
- Web Unlocker: una API que elude las protecciones antirraspado y proporciona HTML limpio de cualquier página web con un mínimo esfuerzo.
- Navegador de scraping: un navegador controlable basado en la nube con renderización JavaScript. Gestiona automáticamente los CAPTCHA, las huellas digitales del navegador, los reintentos y mucho más por ti. Se integra a la perfección con Panther o Selenium PHP.
- API de Scraper: puntos finales para el acceso programático a datos web estructurados de docenas de dominios populares.
¿No quiere lidiar con el Scraping web, pero sigue interesado en los datos en línea? ¡Explore nuestros Conjuntos de datos listos para usar!
Regístrese ahora en Bright Data y comience su prueba gratuita para probar nuestras soluciones de scraping.





