
Los scrapers web fallan de tres formas: el HTML está vacío porque JavaScript renderiza la página, los selectores CSS dejan de coincidir tras una actualización del frontend, y las solicitudes son bloqueadas por productos anti-bot como Cloudflare. Scrapling es una librería Python de código abierto que resuelve los tres problemas. Esta guía muestra cada parte en sitios web reales, y cuándo un servicio de proxies gestionado se vuelve necesario a escala de producción.
TL;DR
Scrapling combina tres clases de fetcher (HTTP, Chromium, Firefox stealth), un parser adaptativo que re-encuentra elementos tras renombrar clases, y un spider al estilo Scrapy en una sola librería Python para scraping en producción.
- Elige el fetcher más económico que funcione; escala a StealthyFetcher para sitios protegidos contra bots.
- Los selectores adaptativos se recuperan de cambios en el markup si guardas la huella de una página válida primero.
- Para producción, envuelve la lógica de parseo en un Spider con checkpointing y una alarma de resultado vacío.
- Cuando el stealth local se agota (reputación de IP, productos anti-bot empresariales), cambia a proxies residenciales o a un endpoint de desbloqueo gestionado.
¿Por qué Scrapling, si requests + BS4 ya existe?
La combinación de requests y BeautifulSoup sigue funcionando para páginas estáticas con markup estable. El problema empieza en cuanto despliegas un scraper que debe seguir funcionando.
Los selectores dejan de coincidir cuando un equipo de frontend renombra o reestructura elementos. Las páginas se renderizan en el servidor este trimestre y en el cliente el siguiente. Un sitio que has scrapeado durante un año de repente añade Cloudflare Bot Management, y cada solicitud devuelve una página de desafío.
Ninguno de estos son problemas inusuales, pero cada uno necesita su propia solución. Combinar esas soluciones en un script de requests tiende a producir una frágil colección de bloques try/except y fallbacks de selectores. (Para trabajos de bajo volumen donde los selectores cambian constantemente, un paso de extracción con LLM sobre el HTML renderizado es ahora una alternativa viable. Scrapling vale el coste de configuración cuando el coste por página importa y se renderiza a escala.)
Scrapling consolida las soluciones comunes en una sola librería:
- Tres fetchers, una API. Un cliente HTTP rápido con impersonación de fingerprint TLS (Fetcher), un navegador controlado por Playwright (DynamicFetcher), y un navegador stealth basado en Camoufox, una compilación de Firefox parcheada que enmascara señales comunes de automatización (StealthyFetcher). Todos devuelven el mismo objeto parser, por lo que cambiar de fetcher no implica reescribir el código de selectores.
- Selectores que sobreviven a cambios de markup. Guarda la huella estructural de un elemento en la primera ejecución, y en ejecuciones posteriores Scrapling puede localizar el mismo elemento aunque hayan cambiado clases, IDs o posiciones.
- Un framework Spider integrado. Solicitudes concurrentes, throttling por dominio, pausa y reanudación, cumplimiento de robots.txt y exportación JSON/JSONL, todo integrado.
- Rotación de Proxy integrada. Un helper ProxyRotator se integra con todos los tipos de sesión, con sobrescrituras por solicitud.
Los tres fetchers se corresponden con tres niveles de dificultad, por lo que la decisión de cuál usar suele ser obvia una vez que inspeccionas el objetivo:
| Si la página es… | Usa este fetcher | Coste por solicitud (tiempo, memoria) |
|---|---|---|
| HTML estático, sin anti-bot | Fetcher | milisegundos, sin navegador |
| Renderizada con JavaScript, sin anti-bot | DynamicFetcher | segundos, memoria de Chromium |
| Detrás de Cloudflare o anti-bot similar | StealthyFetcher | segundos, memoria de Camoufox |
El parser de Scrapling tiene aproximadamente la misma velocidad que Parsel y lxml, y es más rápido que BeautifulSoup para documentos grandes. Para un documento de 5.000 elementos, los benchmarks oficiales lo sitúan en torno a 2 ms frente a más de 1,5 segundos para bs4 + lxml. Es poco probable que importe a pequeña escala, pero se acumula cuando se parsean millones de páginas al mes.
Antes de elegir cualquier librería de scraping web, haz una comprobación rápida: ¿el objetivo expone una API oficial, un feed RSS o Atom, un sitemap, un embed JSON-LD o un volcado de datos público? Cuando existen, una llamada a la API suele ser más rápida y económica que el scraping. El scraping es la respuesta correcta cuando no hay API, cuando la API está detrás de un muro de pago o con límites de tasa que el caso de uso no puede permitirse, o cuando los datos que necesitas no están expuestos por la API.
Scrapling no es la herramienta adecuada para todo:
- A escala de clúster distribuido, los clústeres de Scrapy y los runners distribuidos específicos del framework escalan mejor.
- Para scrapes equivalentes a curl que requests y un selector de 5 líneas de BeautifulSoup ya manejan, usa esos.
- Cuando necesitas un scraper gestionado sin escribir código, una plataforma no-code es una mejor opción.
El mejor encaje es el scraper de producción que debe seguir funcionando semana tras semana: suficiente complejidad para que el mantenimiento importe, pero no tanto como para necesitar un clúster.
Scrapling tiene licencia BSD-3; esta guía está verificada con la v0.4.7 (abril 2026). Los nombres de API usados en la guía son estables; consulta el changelog para versiones más recientes si tus valores predeterminados difieren. Los type hints cubren la API pública, lo que importa si estás canalizando respuestas a través de un pipeline tipado.
Instalar Scrapling
Las dependencias del fetcher son un opt-in explícito, por lo que no instalarás Playwright y Camoufox en una máquina que solo necesita el parser. Instala con los extras del fetcher y los binarios del navegador:
# pip
pip install "scrapling[fetchers]"
# o con uv (más rápido, con lockfile)
uv pip install "scrapling[fetchers]"
scrapling installEl primer comando instala la librería más los fetchers HTTP y de navegador. El segundo descarga los binarios del navegador (Camoufox para StealthyFetcher, Chromium para DynamicFetcher) junto con las dependencias del sistema que necesitan. En Windows, ejecuta el terminal como administrador la primera vez para que los binarios puedan instalarse a nivel de sistema.
Para verificar que todo se instaló correctamente:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])Una instalación correcta imprime 200 y una cadena User-Agent estilo Chrome. Si el User-Agent parece python-requests/x.x en cambio, estás ejecutando la compilación solo-parser; reinstala con el extra [fetchers] para que pip también instale curl_cffi (la librería que provee la impersonación TLS de Fetcher).
Dos extras más son útiles conocer:
- scrapling[shell] añade un shell interactivo IPython (scrapling shell), un conversor curl-a-Scrapling, y un CLI scrapling extract para obtener contenido desde el terminal en una línea. Por ejemplo, scrapling extract get https://example.com out.md escribe la página (o un subconjunto con selector CSS) como Markdown.
- scrapling[all] instala todo, incluido el servidor MCP (Model Context Protocol) para integraciones con agentes de IA; consulta la documentación del proyecto.
scrapling[fetchers] cubre todos los ejemplos a continuación.
Tu primer scrape: extraer citas de una página estática
El sandbox estándar es quotes.toscrape.com, que renderiza diez citas por página en HTML plano renderizado en el servidor. No hay JavaScript, ni anti-bot, ni límite de tasa, por lo que es una buena primera prueba para la ruta Fetcher:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get() devuelve un objeto Response que también actúa como handle del parser. Establecer stealthy_headers=True hace que Scrapling envíe headers de navegador realistas, incluyendo User-Agent, Accept, Accept-Language y sec-ch-ua, en lugar de un conjunto de headers predeterminado de python-requests. Innecesario en un sandbox, pero los sitios de producción suelen filtrar por consistencia de headers.
page.css(‘.quote’) devuelve un contenedor Selectors de todos los elementos coincidentes. El pseudo-elemento ::text es una convención de Scrapy/Parsel que extrae el nodo de texto directamente en lugar de la etiqueta que lo rodea.
La salida tiene este aspecto:
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...Si has usado Scrapy antes, la API es intencionalmente familiar. Si has usado BeautifulSoup, Scrapling también tiene find_all y find_by_text:
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)Scraping de un objetivo real: la portada de Hacker News
Los sitios sandbox son solo para practicar. La misma estructura de código funciona en objetivos reales, con dos cambios: los selectores provienen de inspeccionar el markup real, y los datos necesitan más limpieza. Hacker News es un primer objetivo real útil (HTML estable, sin anti-bot) y su diseño tiene una estructura inusual que vale la pena conocer: cada historia es una fila , con los metadatos (puntos, usuario, antigüedad) en la fila hermana inmediatamente siguiente. El scraper:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# Los metadatos están en la siguiente fila hermana
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")El fragmento usa tres patrones que los ejemplos del sandbox no muestran:
- athing.next navega al siguiente elemento hermano, útil cuando filas estructuralmente relacionadas comparten datos (un patrón común en markup antiguo basado en tablas).
- .attrib.get(‘id’) lee un atributo HTML sin formato cuando no hay un atajo conveniente de ::attr().
- El valor predeterminado or ‘0 points’ cubre las publicaciones de trabajo, que aparecen en la portada de Hacker News sin puntuación.
Los objetivos reales casi siempre tienen estas pequeñas irregularidades (campos faltantes, tipos de elementos mixtos, filas malformadas ocasionales). Ajusta los selectores y añade pequeños valores predeterminados; la estructura del código sigue siendo la misma.
Escribe scrapers sin selectores usando find_similar
A veces ni siquiera necesitas escribir el selector de fila. Empieza desde texto visible, sube al contenedor correcto y deja que Scrapling encuentre cada elemento estructuralmente similar:
sample = page.find_by_text("1.") # la etiqueta de rango en la historia #1
row = sample.find_ancestor(lambda e: e.tag == "tr") # sube hasta la fila de la historia
peers = row.find_similar() # encuentra cada fila similar
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")En la portada en vivo, esto imprime 30 (cada fila de historia, localizada por similitud estructural con la que empezamos). find_similar acepta un similarity_threshold opcional (predeterminado 0.2; valores más bajos significan una coincidencia estructural más estricta) y una lista ignore_attributes (por defecto href y src) para que las diferencias de URL no impidan la coincidencia. Para sitios donde el markup cambia más rápido de lo que puedes mantener selectores, combinar find_by_text con find_similar es más resistente que perseguir nombres de clases.
Extraer tablas: datos de países de Wikipedia
Las tablas son otra forma común de datos del mundo real: cifras financieras, estadísticas deportivas, listas de referencia. Wikipedia proporciona sus tablas de datos bajo una única clase table.wikitable, que es consistente en toda la enciclopedia, por lo que el mismo patrón de selector funciona casi en todas partes. El scrape de población de países:
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # omitir filas de encabezado y agrupación
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")Dos patrones importan aquí. cells[0].css(‘a::attr(title)’).get() extrae el nombre del país del atributo title del enlace, que es más limpio que .text porque omite el desorden del icono de bandera en la misma celda. El guard if len(cells) < 3 omite las filas irregulares de encabezado y agrupación que aparecen en casi cualquier tabla HTML de terceros.
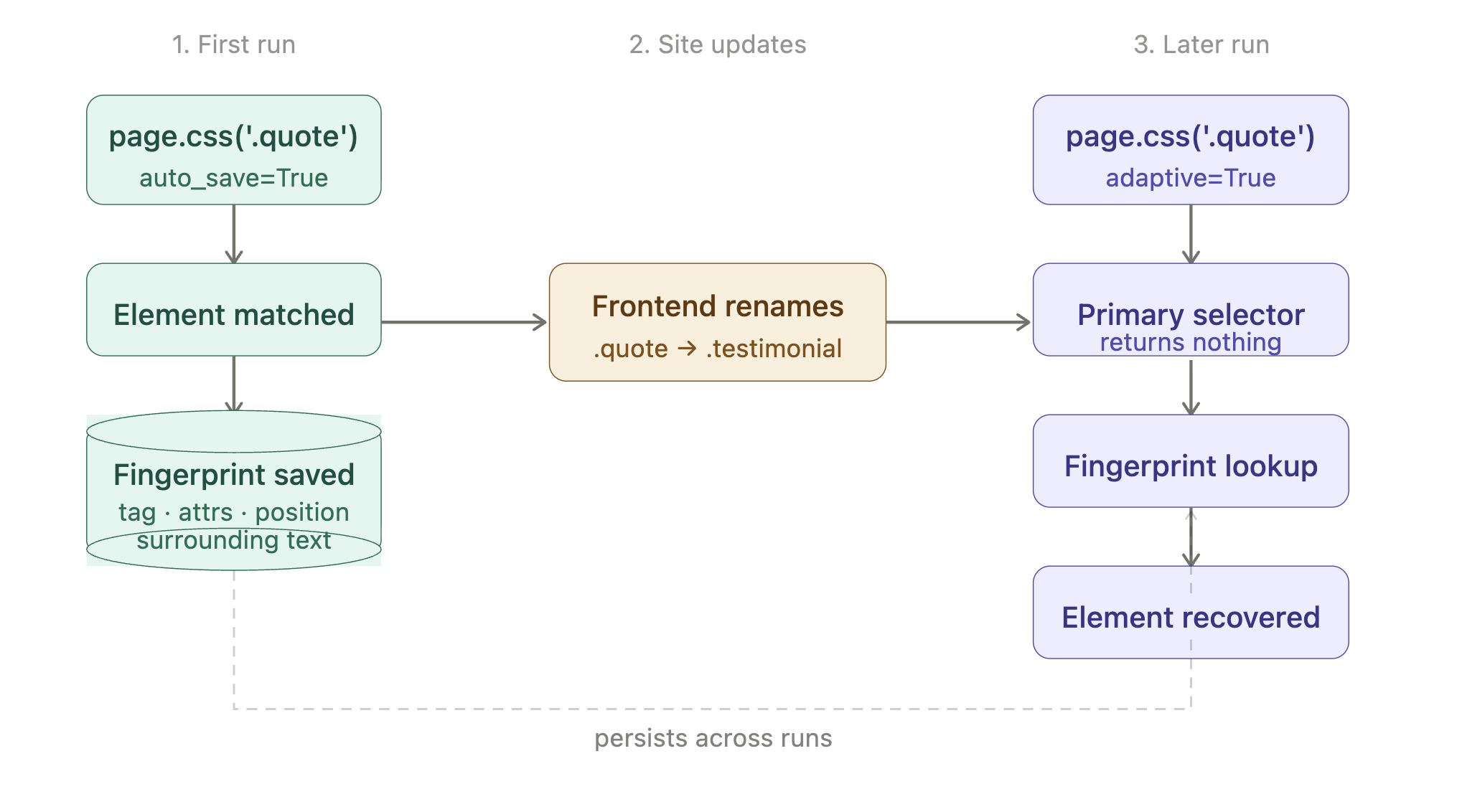
Selectores que sobreviven a cambios del sitio
Un sitio renombra una clase de .product-card a .product-tile. Tu scraper empieza a devolver resultados vacíos. No te das cuenta hasta que un paso posterior en tu pipeline reporta datos faltantes.
La respuesta de Scrapling es una opción de configuración más dos flags. Cada uno hace una cosa:
| Qué escribes | Cuándo lo escribes | Qué hace |
|---|---|---|
| selector_config={‘adaptive’: True} en la llamada al fetcher | Siempre (primera Y posteriores ejecuciones) | Activa la función. Sin él, Scrapling ignora silenciosamente los otros dos flags. |
| auto_save=True en .css() | Primera ejecución | Registra la huella estructural del elemento coincidente (etiqueta, atributos, posición, texto circundante) en un pequeño archivo SQLite local. |
| adaptive=True en .css() | Ejecuciones posteriores | Si el selector no devuelve nada, usa la huella guardada para encontrar el elemento de nuevo. |
El ciclo de vida, de principio a fin:
En código, eso es:
from scrapling.fetchers import Fetcher
# Primera ejecución: habilita adaptive en el fetcher, guarda huellas con auto_save
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# Ejecución posterior: mismo selector, más adaptive=True para la ruta de respaldo.
# Si el sitio renombró `.quote`, la huella recupera los elementos.
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")La base de datos de huellas se almacena junto a tu script, por lo que el mismo script reutiliza las huellas guardadas entre ejecuciones. El patrón funciona igual en cada fetcher: pasa selector_config una vez en la llamada de fetch, luego usa auto_save y adaptive en las llamadas .css().
Trata el archivo de huellas como un artefacto de migración: confírmalo para ejecuciones de CI reproducibles, móntalo como volumen en Docker, y nunca ejecutes auto_save=True contra una página que no hayas verificado. Un muro CAPTCHA scrapeado con auto_save envenena la huella, por lo que las ejecuciones posteriores recuperan el elemento incorrecto. Elimina el archivo para reiniciar.
Limitación: la coincidencia adaptativa solo funciona cuando el contenido del elemento permanece aproximadamente estable y solo cambia el markup. Si el sitio reemplaza toda la sección con una función diferente, ningún algoritmo puede recuperarla. Mantén alertas en conjuntos de resultados vacíos para que notes cuando un sitio ha cambiado de una forma que la huella no puede manejar.
Scraping de páginas renderizadas con JavaScript
Muchos sitios envían un esqueleto HTML casi vacío y luego renderizan el contenido real en el lado del cliente. La página de prueba estándar para esto es quotes.toscrape.com/js, que sirve las mismas citas que la versión estática pero las inyecta mediante JavaScript. Si apuntas Fetcher hacia ella, el resultado es predecible:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []Vacío. El texto está almacenado dentro de una variable JavaScript var data = […] que el navegador ejecuta al cargar la página, y un cliente HTTP básico nunca ejecuta ese script. La solución es usar DynamicFetcher, que controla internamente una instancia real de Chromium:
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())Dos flags en ese fragmento importan. headless=True es lo que quieres en un servidor. network_idle=True espera hasta que la actividad de red se haya detenido antes de que el parser lea la página, lo que captura la mayoría de las páginas renderizadas con JavaScript. En SPAs con hidratación pesada (Next.js, Remix, SvelteKit) la red puede quedar inactiva mientras React aún se está hidratando; para esos casos, pasa wait_selector=”…” con un elemento conocido-estable en su lugar, o adicionalmente.
Una vez que el navegador tiene la página, el resto de la API es idéntico al ejemplo estático de Fetcher.
Cada sesión de navegador ocupa aproximadamente 1 GB de memoria residente (la sección de escalado en producción tiene el desglose). Para unos pocos cientos de páginas al día, un worker de 2 GB lo maneja; más allá de decenas de miles por día, reutiliza navegadores entre solicitudes con DynamicSession, o mueve el trabajo a un navegador de scraping gestionado que corra fuera de tus propios servidores.
Eludir defensas anti-bot con StealthyFetcher
Los productos anti-bot modernos como Cloudflare Turnstile, DataDome y HUMAN Bot Defender (anteriormente PerimeterX) comprueban docenas de señales para determinar si una solicitud proviene de un navegador real. La lista incluye huellas de handshake TLS (JA3 y JA4 son los formatos comunes), ordenación de frames HTTP/2, propiedades de navigator (navigator.webdriver, listas de plugins, headers de idioma), hashes de canvas y WebGL, y patrones de temporización. Una vez que pasan esas comprobaciones estáticas, a menudo entra en juego una capa de comportamiento (entropía de movimiento del ratón, cadencia de scroll, tiempo de permanencia). Una sesión vanilla de Playwright o Selenium expone varios de estos por defecto, que es por qué «añadí Playwright y sigo siendo bloqueado» es una pregunta habitual en foros de scraping.
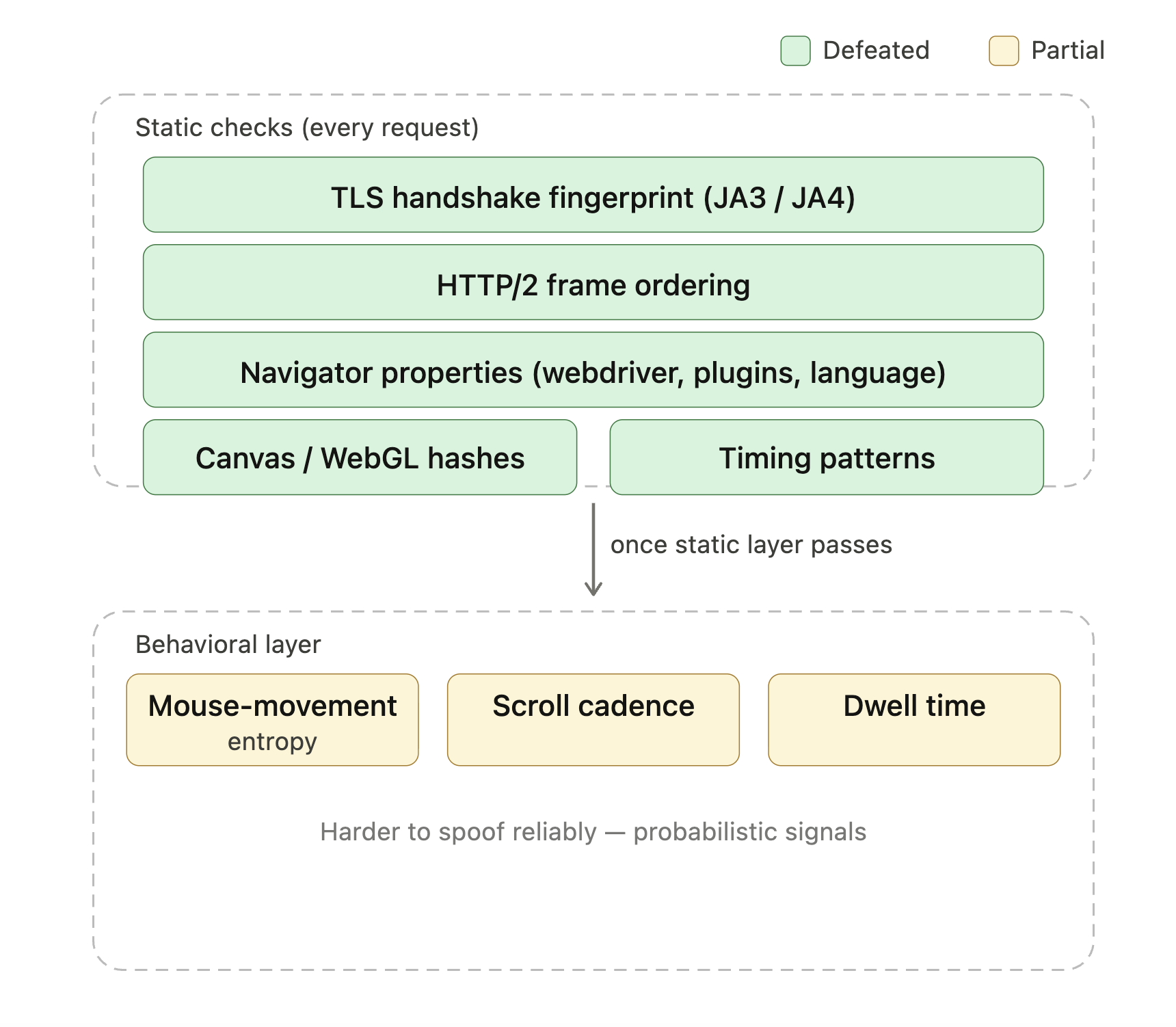
Las capas verdes son lo que la base Camoufox de StealthyFetcher maneja por sí sola; el amarillo es donde entra la puntuación de comportamiento y el desbloqueo gestionado justifica su coste.
StealthyFetcher usa Camoufox, una compilación de Firefox parcheada que enmascara señales comunes de automatización, para derrotar las huellas de navegador headless y Playwright que estos sistemas comprueban. Para los niveles más ligeros de Bot Management de Cloudflare, eso suele ser suficiente por sí solo. Los despliegues de nivel empresarial que combinan Turnstile con puntuación de comportamiento siguen bloqueando configuraciones stealth locales; ahí es donde el desbloqueo gestionado se convierte en la respuesta práctica (cubierto en la sección de escalado en producción). Para sitios que ejecutan explícitamente desafíos Turnstile, Scrapling tiene un flag solve_cloudflare que pasa el desafío automáticamente:
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")La página de ese ejemplo es una demo pública de Cloudflare que ejecuta un desafío Turnstile real.
Vale la pena recordar algunos límites reales:
- La ruta solve_cloudflare funciona para desafíos Turnstile gestionados. No promete manejar todas las categorías de CAPTCHA. Los desafíos de cuadrícula de imágenes (reCAPTCHA antiguo, puzzles de imágenes hCaptcha) necesitan un servicio de solver de terceros (2Captcha, CapSolver) conectado a una acción de página, o un endpoint de desbloqueo gestionado que maneje la capa de desafío de extremo a extremo.
- Las técnicas de bypass stealth cambian con frecuencia. Planifica verificaciones periódicas en tus objetivos reales, no una configuración única.
- Los resultados también dependen de la reputación de la IP. Una IP de datacenter ya marcada en un objetivo no tendrá éxito, sin importar qué tan buena sea la huella del navegador.
Para sitios que no usan Cloudflare, obtén los beneficios stealth sin el solver de desafíos:
page = StealthyFetcher.fetch('https://example.com', headless=True)Las protecciones de fingerprinting predeterminadas se aplican, y solve_cloudflare no hace nada si no hay desafío que resolver.
Un patrón que conviene conocer: el bloqueo oculto
Los sistemas anti-bot a veces devuelven un 200 OK con una página de bloqueo disfrazada (un muro CAPTCHA, una página de resultados vacía, o un intersticial de «verificando que eres humano») en lugar de un 403 o 503 explícito. Una comprobación de resultados vacíos (mostrada en el script listo para producción) captura los casos obvios. Para bloqueos ocultos donde la estructura está intacta y solo los datos son incorrectos, querrás una comprobación a nivel de contenido: comparar la longitud de la respuesta con una línea base, buscar cadenas reveladoras («captcha», «are you human», «access denied» en el cuerpo), o muestrear los campos esperados de un elemento estable conocido. Ninguno es perfecto; juntos capturan la mayoría de los bloqueos silenciosos antes de que los datos incorrectos fluyan aguas abajo.
El framework Spider expone un hook is_blocked para esto: sobreescríbelo (también async def) y Scrapling reintenta automáticamente las respuestas bloqueadas hasta max_blocked_retries (predeterminado 3):
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in bodyLos conteos de reintentos por bloqueo aparecen en result.stats.blocked_requests_count tras el crawl. Usa este contador como métrica de alerta en producción.
Scraping de páginas detrás de un login con FetcherSession
Los objetivos reales a menudo requieren login. El patrón con FetcherSession es el flujo estándar CSRF + cookie que escribirías con requests + Session, solo que con el parser de Scrapling manejando la respuesta. El sandbox Quotes-to-Scrape incluye un login funcional en /login, lo que lo convierte en un caso de prueba simple:
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. GET de la página de login para obtener el token CSRF
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. POST de credenciales. Las cookies persisten en la sesión automáticamente.
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. Obtener una página que está bloqueada detrás del login.
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# Las páginas con sesión iniciada en este sandbox muestran enlaces extra de Goodreads por cita
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())Tres cosas importan aquí:
- Usa una sesión, no llamadas individuales a Fetcher.get(). FetcherSession persiste las cookies (y cualquier Set-Cookie que devuelva el servidor) entre solicitudes; las llamadas individuales a Fetcher.get() no comparten estado.
- Lee el token CSRF del formulario de login. La mayoría de los frameworks modernos incluyen uno y rechazan las solicitudes POST sin él. El nombre del campo varía según el framework: Django usa csrfmiddlewaretoken, Rails usa authenticity_token, y muchas SPAs envían el token en un header en su lugar, así que inspecciona el formulario antes de asumir un nombre.
- Verifica que el login tuvo éxito antes de continuar. Comprueba si hay un enlace de logout, un nombre de usuario en la barra de navegación, o la ausencia de un formulario de login. Si el login falla sin un error y scrapeas la página pública, obtienes datos que parecen correctos pero en realidad son incorrectos.
Para sitios con 2FA, OAuth, o flujos de login que emiten tokens de larga duración, el enfoque más simple es iniciar sesión una vez manualmente (o a través de la API del sitio), capturar las cookies o token resultantes y reutilizarlos. FetcherSession acepta un dict cookies={…} en la construcción para que puedas poblar una sesión desde cookies guardadas.
Fetches concurrentes con AsyncFetcher
Cuando tienes una lista de URLs y las necesitas todas, el Fetcher síncrono las serializa. AsyncFetcher expone la misma API como una corrutina, para que puedas emitir todas las solicitudes concurrentemente con asyncio.gather y dejar que múltiples round-trips de red corran en paralelo (el mismo patrón que el scraping asíncrono con AIOHTTP, con un parser ya adjunto):
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")En las mismas 10 páginas de citas, esto reduce un fetch secuencial de 9 segundos a aproximadamente 1 segundo en una conexión doméstica típica. FetcherSession también funciona bajo async with, por lo que puedes reutilizar cookies y headers en llamadas async de la misma manera que en código síncrono. Para crawls completos con throttling, dedup y reanudación, el framework Spider suele ser la mejor opción. AsyncFetcher importa cuando tienes una lista conocida de URLs y solo quieres obtenerlas en paralelo.
Una trampa: el asyncio.gather(*tasks) básico relanza la primera excepción inmediatamente, pero las otras tareas siguen ejecutándose en segundo plano; pierdes acceso a sus resultados sin detener el trabajo. Para listas de producción donde quieres éxito parcial, pasa return_exceptions=True y filtra los resultados, o usa asyncio.TaskGroup (3.11+), que cancela los hermanos en el primer fallo y te da manejo de errores explícito por tarea.
Construir un crawler de múltiples páginas con el framework Spider
Un trabajo de scraping real raramente es una sola página. Sigues la paginación, sigues los enlaces de productos, dedupes URLs, limitas las tasas de solicitud, escribes todo en disco y reanudas con gracia si algo falla. Scrapling proporciona un framework Spider para esto, con una forma Spider/parse/yield que será familiar para los usuarios de Scrapy. Los spiders que no dependen de los middlewares, pipelines o señales de Scrapy se portan principalmente de forma mecánica; el resto necesita reescrituras contra los hooks y la firma parse async de Scrapling.
Un crawler simple sobre books.toscrape.com, que tiene un catálogo paginado de cincuenta páginas con alrededor de mil libros:
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # segundos entre solicitudes por dominio
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")Algunas cosas que este fragmento hace que de otro modo construirías a mano. concurrent_requests ejecuta ocho solicitudes simultáneamente, lo que en books.toscrape.com reduce un crawl completo de minutos a segundos. download_delay impone un intervalo por dominio para no sobrecargar un solo host. response.follow() resuelve URLs relativas contra la página actual, lo que elimina uno de los bugs de paginación más comunes (olvidar unir un enlace next relativo). La firma async parse te permite hacer I/O por página (obtener páginas de detalle, llamar a APIs externas) sin bloquear el bucle de crawl.
Dos métodos del parser vale la pena conocer. .re_first(pattern) en un resultado .css() devuelve la primera coincidencia de regex, útil para extraer valores numéricos de texto formateado:
# convierte '£51.77' en 51.77 en una expresión
price = float(book.css('.price_color::text').re_first(r'[d.]+'))Y el contenedor Selectors que devuelve .css() tiene un método .filter() que acepta un predicado, para que puedas reducir los datos que Scrapling ya tiene sin escribir un segundo bucle:
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}Útil cuando el sitio no expone un parámetro de filtro de URL para el campo por el que quieres filtrar.
La exportación al final escribe un objeto JSON por línea, que es lo que esperan la mayoría de los pipelines aguas abajo. También puedes usar .to_json() para un único array JSON, o escribir tu propio pipeline sobreescribiendo el hook process_item.
Para pipelines que necesitan elementos a medida que se scrapeán en lugar de esperar a que termine todo el crawl, el Spider expone .stream() como un generador async:
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # o cualquier otro sink aguas abajo
asyncio.run(main())Para crawls más largos, vale la pena configurar el mecanismo de pausa y reanudación desde el principio:
result = BooksSpider(crawldir="./crawl_data").start()Pasa un crawldir y Scrapling guarda en disco los puntos de control de URLs visitadas y solicitudes pendientes. Presiona Ctrl+C y el crawl se detiene con gracia. Ejecútalo de nuevo con el mismo crawldir y reanuda desde donde se detuvo. Para un crawl de cincuenta páginas esto es innecesario, pero para crawls de producción de larga duración (actualizaciones de catálogo, estudio de mercado, monitoreo de precios) es la diferencia entre perder el progreso de un día y no perder nada.
Si tu objetivo requiere los fetchers más intensivos en recursos, el spider puede enrutar solicitudes a través de diferentes sesiones por URL:
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}Visualizado como un diagrama de enrutamiento:
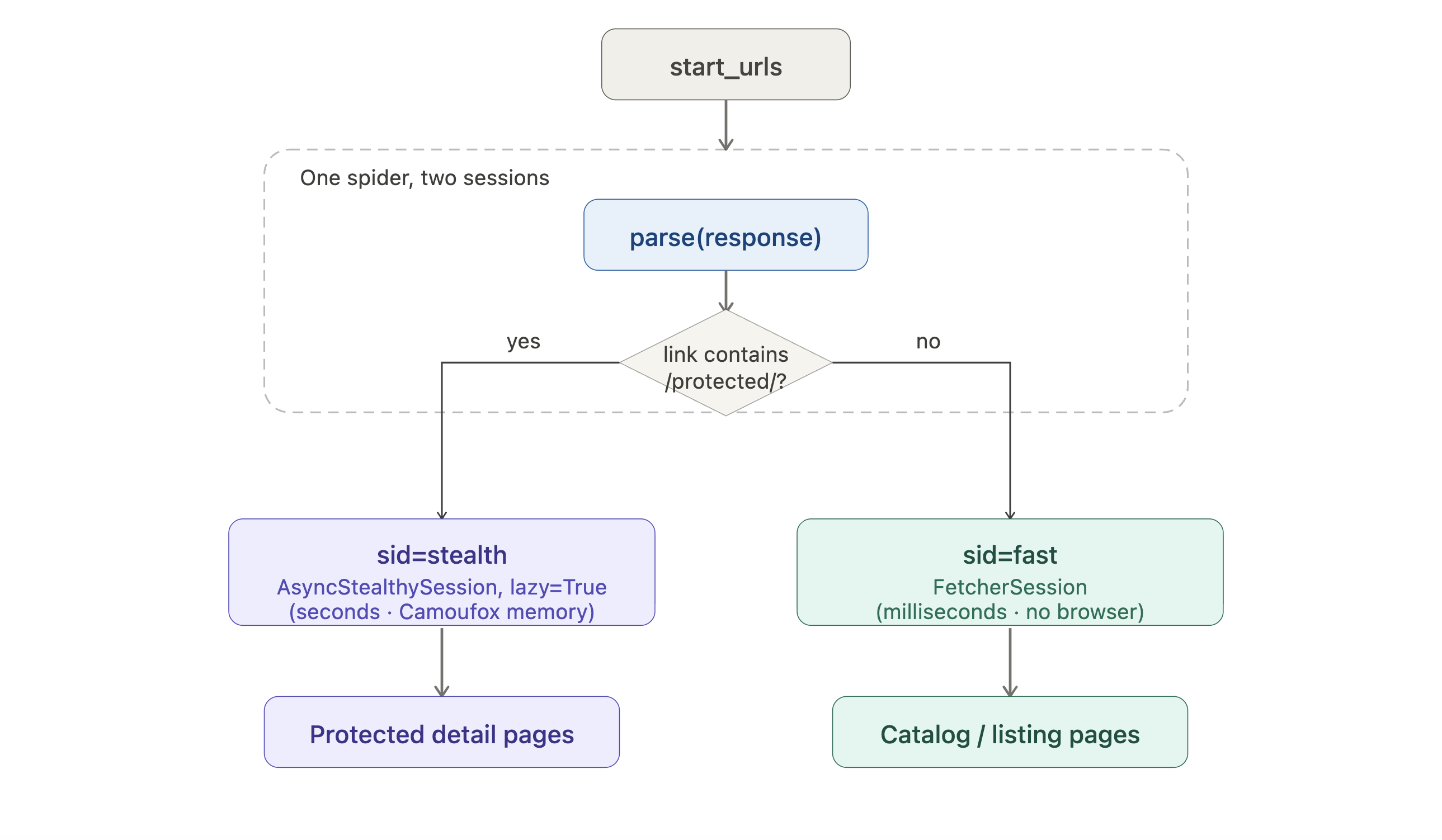
Las páginas de listado toman la ruta HTTP económica; solo las páginas de detalle protegidas pagan el coste del navegador. lazy=True difiere el inicio del navegador hasta que la primera solicitud stealth se activa realmente, por lo que un crawl que termina solo accediendo a listados nunca abre Camoufox.
Algunos detalles en ese ejemplo no son obvios desde el código. AsyncStealthySession y AsyncDynamicSession son sesiones de navegador de larga duración. Reutilízalas en muchas solicitudes, en lugar de StealthyFetcher.fetch() o DynamicFetcher.fetch() que inician un nuevo navegador en cada llamada.
configure_sessions recibe un manager (el registro de sesiones del Spider); manager.add(name, session) registra una sesión bajo un nombre al que luego puedes enrutar con Request(url, sid=name). El flag lazy=True en la sesión stealth retrasa la apertura del navegador hasta que realizas la primera solicitud stealth, por lo que un crawl que solo solicita páginas públicas nunca incurre en el overhead de inicio del navegador.
La sesión fast usa el fetcher HTTP económico para las páginas de listado, y solo las páginas de detalle protegidas requieren un navegador real. Ese tipo de enrutamiento es difícil de añadir después a un crawler de propósito general.
Paginación en sitios reales
Los objetivos reales rara vez tienen un enlace .next simple como books.toscrape.com. Tres patrones manejan la mayoría de los casos que verás:
- Paginación numerada (por ejemplo, ?page=1, 2, 3…) es la más fácil. Genera las URLs directamente en start_urls, o yield objetos Request desde parse en un bucle.
- Scroll infinito generalmente depende de un endpoint XHR JSON. Abre DevTools → Network, desplázate por la página y busca la solicitud que devuelve el siguiente lote de elementos. Luego llama a ese endpoint con Fetcher (mucho más económico que renderizar cada scroll en un navegador).
- Botones «cargar más» necesitan un clic real dentro del navegador. DynamicFetcher y StealthyFetcher aceptan un callable page_action que recibe la página Playwright subyacente; haz clic en el botón allí, espera el nuevo contenido, luego deja que el parser lea la página cuando la función retorne:
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` es la página síncrona de Playwright subyacente.
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")Adapta el selector y el conteo de clics al objetivo. Las clases de sesión async (AsyncDynamicSession, AsyncStealthySession) aceptan un equivalente async del mismo callable.
Escalar Scrapling para producción: proxies y desbloqueo
La arquitectura cambia una vez que estás scrapeando un objetivo real de producción a volumen. Tres restricciones suelen aparecer juntas:
- Reputación de IP. Una sola IP residencial o de datacenter que envía mil solicitudes por hora al mismo sitio no se parece a un usuario real. La mayoría de los objetivos de producción limitan la tasa, luego throttlean, luego bloquean. La solución es un grupo de IPs, idealmente residenciales (conexiones reales de consumidores) o ISP (IPs de datacenter asignadas por operador que parecen residenciales para la puntuación anti-bot), que rotan por solicitud o por sesión.
- Targeting geográfico. Algunos sitios sirven contenido diferente (o precios diferentes) por país, estado o ciudad. Reproducir esas vistas necesita proxies en esas ubicaciones.
- Anti-bot de grado CDN. Más allá del Turnstile básico de Cloudflare, Akamai Bot Manager (y DataDome o HUMAN en modo estricto) a menudo bloquea configuraciones stealth locales. En ese punto, un endpoint de desbloqueo gestionado que mantiene su propio grupo de navegadores y solvers de desafíos suele funcionar mejor que una solución personalizada.
Reintentos, timeouts y errores transitorios
Los errores de red son inevitables a escala: resets de conexión, 503s ocasionales bajo carga, 429s cuando te están limitando la tasa. FetcherSession acepta retries=, retry_delay= y timeout= en la construcción (valores predeterminados en v0.4.7: 3, 1 segundo, 30 segundos; confirma con help(FetcherSession) en tu versión instalada). Los fetchers de navegador (StealthyFetcher, DynamicFetcher) aceptan los mismos parámetros por fetch en cada llamada .fetch() en su lugar.
Para límites de tasa por objetivo donde el servidor envía un header Retry-After en un 429, lee ese header en tu método parse y vuelve a hacer yield del Request con un retraso. El reintento predeterminado no respeta Retry-After, por lo que depender de él te da el mismo 429 de nuevo.
Memoria del navegador: números concretos de dimensionamiento
Ejecutar un navegador real es el coste de usar DynamicFetcher y StealthyFetcher. En una página de contenido típica (~200 KB HTML, sin SPA con muchos medios), una sola sesión de Camoufox o Chromium usa alrededor de 700-900 MB de RAM en modo headless en Linux x86_64. El tamaño apenas cambia entre fetches en la misma sesión, así que planifica para aproximadamente 1 GB por sesión de navegador concurrente al dimensionar contenedores: un worker de 4 GB ejecuta cómodamente 3-4 sesiones concurrentes, un worker de 8 GB maneja 6-8. Los objetivos más pesados (páginas con muchas imágenes, SPAs densas, sitios que cargan docenas de scripts de analítica) aumentan el coste por sesión a 1,2-1,5 GB. Reutiliza tus sesiones en lugar de llamadas one-shot .fetch() para no incurrir en el retraso de inicio del navegador en cada solicitud.
Dos flags del fetcher de navegador importan a volumen de producción. block_ads=True habilita la lista de bloqueo integrada de Scrapling (alrededor de 3.500 dominios de anuncios y rastreadores) y reduce el tiempo de fetch en sitios con muchos anuncios omitiendo solicitudes de red irrelevantes. dns_over_https=True enruta las consultas DNS a través del endpoint DoH (DNS sobre HTTPS) de Cloudflare y ayuda a prevenir fugas de DNS cuando estás enrutando Tráfico a través de un Proxy residencial. Ambos aplican a DynamicFetcher y StealthyFetcher (las solicitudes del fetcher HTTP no cargan recursos de página, por lo que no necesitan ninguno de los dos flags).
Rotación de Proxy autogestionada
Scrapling tiene un helper ProxyRotator que maneja el caso de rotación básica directamente:
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)Para un proyecto pequeño con un puñado de proxies estáticos, eso es todo lo que necesitas. Para cualquier cosa más grande, generalmente quieres un único endpoint que te dé una IP nueva por solicitud (o una sesión sticky por usuario), y ahí es donde tiene sentido pagar por un proveedor comercial.
La red de proxies residenciales de Bright Data se integra con Scrapling usando el mismo patrón de URL de Proxy: es un único endpoint de Proxy HTTP con autenticación de nombre de usuario y contraseña, y el nombre de usuario contiene los parámetros de enrutamiento que necesita la red, incluyendo país e ID de sesión sticky. Los valores provienen de la página de Parámetros de acceso de la Zona en el panel de Bright Data.
Para ejecutar el ejemplo a continuación: regístrate en brightdata.com (prueba gratuita, no se requiere tarjeta para comenzar), crea una Zona de proxies residenciales en el panel, y copia tu id, zona y contraseña en la URL del Proxy. Los proxies residenciales requieren una verificación KYC única antes de la activación de la zona. Aquí hay una configuración típica para rotar por solicitud:
from scrapling.fetchers import FetcherSession
# Reemplaza <id>, <zone> y <password> con los valores de tu panel.
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)Dos notas sobre esta configuración:
- Pasa proxy= por solicitud, no en el constructor de FetcherSession. El proxy= por solicitud se comporta de manera consistente en todos los tipos de fetcher y es la ruta más fácil para sobrescribir por llamada. Esto aplica a cualquier proveedor, no solo a Bright Data.
- Establece verify=False en la sesión. La red residencial de Bright Data termina el salto del Proxy con una cadena de certificados autofirmados (estándar para los servicios de Proxy residencial). La verificación solo está deshabilitada para el salto local al Proxy; la conexión al objetivo sigue siendo TLS de extremo a extremo a través del método CONNECT del Proxy. El patrón más limpio para producción es instalar el certificado CA de Bright Data en tu almacén de confianza y eliminar verify=False por completo; evita copiarlo en rutas de código que no pasan por el Proxy residencial.
Para sesiones sticky (misma IP en múltiples solicitudes para mantener un carrito o estado de login), el nombre de usuario contiene un ID de sesión, por ejemplo brd-customer–zone–session-rand123. La lógica de rotación corre en el lado del proveedor, y la librería trata la URL como un Proxy HTTP regular.
La misma integración de Scrapling funciona con los otros tipos de Proxy de Bright Data (proxies ISP para IPs de calidad residencial de mayor volumen, proxies móviles para vistas solo-móvil) con solo el nombre de la Zona en la URL cambiando.
Para los objetivos más difíciles, vale la pena conocer el patrón Web Unlocker. En lugar de ejecutar tu propio navegador stealth y actualizar las huellas cada vez que un proveedor lanza una nueva comprobación de detección, apuntas el fetcher a un único endpoint; el renderizado, el fingerprinting, la rotación de IPs y la resolución de desafíos ocurren de forma remota. El Web Unlocker de Bright Data está construido alrededor de este patrón, con targeting a nivel de país y lógica de desbloqueo por dominio mantenida por el proveedor. Tu código de parseo sigue siendo el mismo; solo la línea de fetch cambia.
El mismo trade-off aplica a los objetivos con mucho JavaScript. Ejecutar Camoufox o Chromium localmente funciona para volumen moderado. Una vez que gestionas muchos contenedores de navegador, un Bright Data Scraping Browser gestionado quita el desbloqueo y el mantenimiento de huellas de tu equipo. El Scraping Browser es un navegador remoto al que te conectas a través de WebSocket usando el mismo protocolo que Playwright usa internamente, por lo que encaja en la misma ruta de código que un navegador Chromium local.
Dos notas prácticas aplican al elegir entre estos:
- Si tu problema es «necesito una IP diferente por solicitud para evitar límites de tasa», los proxies residenciales más el Fetcher local o StealthyFetcher suele ser suficiente. Estás pagando por IPs, no por el trabajo de eludir bloqueos.
- Si tu problema es «estoy recibiendo desafíos CAPTCHA que no puedo resolver, y el sitio cambia su protección cada pocas semanas», un endpoint de desbloqueo gestionado generalmente ahorra suficiente tiempo de ingeniería para justificar el mayor coste por solicitud.
Un script de Scrapling completo listo para producción
Un BooksSpider básico corre limpiamente en un sandbox. Cinco adiciones lo hacen listo para producción, marcadas con comentarios numerados a continuación:
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. respetar robots.txt y Crawl-delay
async def parse(self, response: Response):
if response.status != 200: # 2. manejar respuestas no-200 explícitamente
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. detectar selectores obsoletos temprano
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. timestamp en cada fila
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. checkpoint para pausa/reanudación
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")Lo que cada adición te da:
- robots_txt_obey respeta las directivas de robots.txt y Crawl-delay automáticamente.
- La comprobación de estado hace que el spider registre explícitamente los fallos del lado del servidor en lugar de tratarlos como «no se encontraron elementos».
- La comprobación de resultado vacío detecta un selector obsoleto a la mañana siguiente en lugar de tres semanas después cuando un informe aguas abajo no muestra datos.
- El timestamp registra cuándo se scrapeó cada fila, para que las re-ejecuciones a lo largo de días no se mezclen entre sí.
- crawldir significa que un Ctrl+C, un kernel panic o una conexión de red perdida no destruirán el progreso del crawl.
Para cambiar el mismo script a proxies residenciales, el único cambio es la sesión del fetcher. Para cambiar a un endpoint Web Unlocker, cambia la URL del Proxy al servicio de desbloqueo. La lógica de parseo y el comportamiento del spider permanecen idénticos.
Ejecútalo en un horario
Envuelve el script en cron, un temporizador systemd, o un orquestador como Airflow o Prefect. Usa un crawldir por ejecución (por ejemplo, ./crawl_data/$(date +%Y%m%d)) para que el estado de reanudación de una ejecución anterior no se lleve a una nueva, y envía la salida a almacenamiento duradero en lugar de dejarlo en el disco de la máquina worker. Destinos comunes: Parquet en S3 o GCS leído por polars o DuckDB para análisis ad-hoc, o una tabla de Postgres cuando necesitas búsquedas relacionales.
Para destinos más allá de los archivos JSONL, sobreescribe los hooks on_start, on_scraped_item y on_close del Spider (los tres son async def). Abre una conexión de base de datos o un productor de cola de mensajes una vez en on_start. Escribe cada elemento desde on_scraped_item a medida que se hace yield (devuelve el elemento para reenviarlo, devuelve None para descartarlo). Limpia en on_close.
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # reenviar aguas abajo también
async def on_close(self) -> None:
await self.db.close()Cuando el scraping falla: una lista de verificación de depuración
Los scrapers de producción fallan de formas que las pruebas unitarias no detectan. Unas pocas comprobaciones rápidas manejan la mayoría.
Abre el navegador en modo visible. Pasa headless=False a StealthyFetcher.fetch() o DynamicFetcher.fetch() y observa cómo se renderiza la página. Los desafíos CAPTCHA, las cadenas de redirección, los redireccionamientos geo-IP y las páginas de detección anti-bot a menudo solo se vuelven obvios cuando puedes ver lo que está pasando. Ejecútalo localmente; para servidores headless, guarda una captura de pantalla vía page_action en su lugar.
Guarda el HTML de la respuesta en disco. Cuando un selector no devuelve nada, guarda la respuesta raw y ábrela en un navegador:
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)Luego compara lo que recibió el parser con lo que esperabas. La mayoría de las veces, lo que scrapeaste resulta ser un muro CAPTCHA, una redirección a otro idioma, o una página de resultados vacíos que parece idéntica al caso de éxito a primera vista. El HTML muestra la verdad incluso cuando el código de estado es engañoso.
Usa el shell interactivo. Instala scrapling[shell] y ejecuta scrapling shell. Carga una sesión IPython con Scrapling pre-importado más dos helpers útiles: uncurl(…) parsea un comando curl (desde Copiar como cURL de DevTools) en un objeto Request de Scrapling para que puedas inspeccionar exactamente lo que se está enviando, y curl2fetcher(…) parsea y ejecuta, devolviendo un Response parseado. Haz clic derecho en cualquier llamada XHR en DevTools, copia como cURL, pégalo dentro del shell y tienes un fetch de Scrapling funcional.
Haz ingeniería inversa de un selector desde un elemento que ya tienes. Si encontraste un elemento a través de find_by_text, navegación o en cualquier otro lugar, las propiedades .generate_css_selector y .generate_xpath_selector (nota: propiedades, no métodos) te dan un selector reutilizable para él:
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > smallLa salida no es legible por humanos, pero es reutilizable y sobrevive a cambios de contenido que no mueven el elemento.
Una nota sobre qué comprobar primero. Cuando un scraper que funcionaba ayer se rompe hoy, trabaja desde la comprobación más rápida a la más lenta: comprobación de resultado vacío («el selector no devolvió nada»), HTML guardado («¿se renderizó siquiera la página?»), luego headless=False («¿está el sitio desafiando al navegador?»).
Itera en parse() sin enviar otra solicitud al objetivo. Establece development_mode = True y development_cache_dir = “./_dev” en tu clase Spider:
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...La primera ejecución accede a la red y almacena en caché cada respuesta en disco; las ejecuciones posteriores reproducen desde la caché (aproximadamente 50 ms versus 1,2 segundos en los sitios sandbox, aproximadamente una aceleración de 24x). Mientras ajustas selectores y limpias datos, ya no tienes que esperar a la red en cada ejecución de prueba. Establece development_mode de vuelta a False antes de desplegar.
Próximos pasos
Elige un objetivo real que hayas querido scrapear y empieza con el fetcher más ligero que funcione para él. Fetcher maneja HTML estático; usa DynamicFetcher cuando el contenido se renderiza con JavaScript, StealthyFetcher cuando el sitio está detrás de Cloudflare o un proveedor anti-bot comparable.
Para cualquier cosa que planees mantener en funcionamiento, establece estos valores predeterminados desde el principio:
- Envuelve la lógica de parseo en un Spider con crawldir, robots_txt_obey=True y una comprobación de resultado vacío en cada página.
- Activa selector_config={‘adaptive’: True} y auto_save=True en la primera ejecución para que la huella estructural esté en disco antes de que el sitio cambie su markup.
- Establece download_delay en al menos 0,5-1 s en infraestructura compartida, y lee el header Retry-After en tu método parse para cualquier respuesta 429.
Cuando el stealth local deja de ser suficiente (reputación de IP, escalado de concurrencia, anti-bot de grado CDN), cambia a un proxy residencial o a un endpoint de desbloqueo gestionado añadiendo un único argumento proxy= en cada llamada de fetch. Cualquier proveedor que exponga un Proxy HTTP con autenticación básica funciona de la misma manera.
Para la referencia completa, consulta la documentación oficial.
FAQ
¿Puedo usar Scrapling en un producto comercial?
Sí. Scrapling tiene licencia BSD-3-Clause, por lo que puedes incluirlo en productos comerciales, backends SaaS o herramientas internas sin regalías ni nivel de pago. Solo pagas por los servicios opcionales de terceros que elijas, como un proxy residencial o un solver de CAPTCHA. Ninguna función de Scrapling en sí está limitada por licencia.
¿Cómo se compara Scrapling con Playwright o Selenium?
Scrapling está construido específicamente para scraping; Playwright y Selenium son herramientas de automatización de navegador de propósito general. Scrapling envuelve una compilación de Camoufox con parches stealth (controlada vía Playwright), reintentos, reutilización de sesiones y selectores adaptativos, por lo que escribes menos código de pegamento y evitas las huellas Chromium-CDP que expone vanilla Playwright.
¿Scrapling resuelve CAPTCHAs?
Parcialmente. StealthyFetcher pasa los desafíos Cloudflare Turnstile gestionados cuando solve_cloudflare=True. Otras categorías (hCaptcha de cuadrícula de imágenes, CAPTCHAs de audio, empresariales personalizados) necesitan un solver de terceros (2Captcha, CapSolver) o un endpoint de desbloqueo gestionado que maneje la capa de desafío de extremo a extremo.
¿Puede Scrapling funcionar con Scrapy?
Sí. El parser de Scrapling usa la misma sintaxis de pseudo-elemento (::text, ::attr(href)) que Parsel, por lo que un Selector de Scrapling funciona dentro de un callback de Scrapy con la mayoría de los selectores sin cambios. La forma Spider/parse/yield se mantiene; los spiders sin middlewares o pipelines pesados se portan principalmente de forma mecánica.
¿Necesito un servicio de Proxy para usar Scrapling?
No, Scrapling funciona sin Proxy en trabajos pequeños. A volumen de producción, usa el ProxyRotator integrado de Scrapling con una lista estática cuando quieres control total, o un endpoint residencial, ISP o móvil gestionado cuando necesitas IPs nuevas por solicitud o targeting a nivel de país.
¿Puede Scrapling ejecutarse dentro de Docker?
Sí. El proyecto proporciona una imagen Docker oficial con todas las dependencias del navegador pre-instaladas. Para StealthyFetcher y DynamicFetcher, la imagen oficial ahorra aproximadamente una hora de hacer funcionar Camoufox y Chromium en un contenedor personalizado. Para el Fetcher básico, cualquier imagen Python estándar funciona.





