

En esta guía aprenderás:
- Qué es Selenium Wire
- Por qué debería utilizar Selenium Wire para el Scraping web
- Las características clave de Selenium Wire
- Un caso de uso de scraping web de Selenium Wire con Proxy rotativo
- Integración de proxies de Bright Data con Selenium Wire
¡Empecemos!
¿Qué es Selenium Wire?
Selenium Wirees una extensión para los enlaces Python de Selenium que proporciona control sobre las solicitudes del navegador. En concreto, permite interceptar y modificar tanto las solicitudes como las respuestas en tiempo real directamente desde el código Python mientras se utiliza Selenium.
Nota: Aunque la biblioteca ya no se mantiene, varias tecnologías y scripts de scraping siguen dependiendo de ella.
¿Por qué utilizar Selenium Wire para el Scraping web?
Selenium es un popular marco de automatización de navegadores que se utiliza en el Scraping web para interactuar con los sitios web como lo harían los usuarios humanos normales. Obtenga más información en nuestraguía de Scraping web con Selenium.
El problema es que los navegadores tienen ciertas limitaciones que pueden dificultar el scraping web. Por ejemplo, no permiten configurar URL de Proxy autorizadas ni activar Proxy rotativas sobre la marcha. Selenium Wire le ayuda a superar esas limitaciones.
Aquí tienes tres buenas razones por las que deberías utilizar Selenium Wire para el Scraping web:
- Acceda a la capa de red: interprete, inspeccione y modifique el tráfico de red AJAX para una extracción de datos avanzada.
- Evite los antibots:
ChromeDriverexpone una cantidad significativa de información que los sistemas antibot pueden utilizar para identificarle como un bot. Selenium Wire es utilizado por tecnologías comoundetected-chromedriverpara evitarlo y ayudar a eludir la mayoría de las soluciones antibot. - Supera las limitaciones de los navegadores: los navegadores modernos utilizan indicadores para configurar comportamientos al iniciarse, pero estos ajustes son estáticos y requieren un reinicio para modificarse. Selenium Wire supera esta limitación al admitir modificaciones dinámicas. De esta manera, puedes actualizar los encabezados de solicitud o los Proxies durante la misma sesión del navegador, lo que es ideal para el Scraping web.
Características principales de Selenium Wire
Ahora ya sabe qué es Selenium Wire y por qué debería utilizarlo para el Scraping web. ¡Es hora de explorar sus características más importantes!
Solicitudes y respuestas de acceso
Selenium Wire puede capturar el tráfico HTTP/HTTPS generado por el navegador, lo que le da acceso a los siguientes atributos:
| Atributo | Descripción |
|---|---|
driver.requests |
Informa de la lista de solicitudes capturadas en orden cronológico |
driver.last_request |
Informa de la solicitud capturada más recientemente (Esto es más eficiente que usar driver.requests[-1]) |
driver.wait_for_request(pat, timeout=10) |
Este método esperará (el tiempo lo define el parámetrotimeout) hasta que vea una solicitud que coincida con un patrón, definido por el parámetropat, que puede ser una subcadena o unaexpresión regular. |
driver.har |
Un archivoHARcon formato JSON de las transacciones HTTP que se han producido. |
driver.iter_requests() |
Devuelve un iterador sobre las solicitudes capturadas. |
En detalle, un objeto Selenium Wire Request tiene los siguientes atributos:
| Atributo | Descripción |
|---|---|
cuerpo |
La solicitud del cuerpo se presenta en bytes. Si la solicitud no tiene cuerpo, el valor del cuerpo estará vacío (por ejemplo: b''). |
cert |
Proporciona información sobre el certificado SSL del servidor en formato de diccionario (está vacío para las solicitudes que no son HTTPS). |
fecha |
Muestra la fecha y hora en que se realizó la solicitud. |
encabezados |
Informa sobre un objeto similar a un diccionario de los encabezados de la solicitud (tenga en cuenta que en Selenium Wire los encabezados no distinguen entre mayúsculas y minúsculas y se permiten duplicados). |
host |
Informa del host de la solicitud (por ejemplo, https://brightdata.com/). |
método |
Especifica el método HHTP (GET, POST, etc.). |
parámetros |
Informa de un diccionario de los parámetros de la solicitud (tenga en cuenta que si un parámetro con el mismo nombre aparece más de una vez en la solicitud, su valor en el diccionario será una lista). |
ruta |
Informa de la ruta de la solicitud. |
cadena de consulta |
Informa de la cadena de consulta. |
respuesta |
Informa del objeto de respuesta asociado a la solicitud (tenga en cuenta que el valor será None si la solicitud no tiene respuesta). |
url |
Informa de la URL de la solicitud completa con el host, la ruta y la cadena de consulta. |
ws_messages |
En el caso de que una solicitud sea un WebSocket (en cuyo caso, la URL suele ser similar a wss://), ws_messages contendrá cualquier mensaje de WebSocket enviado y recibido. |
En cambio, un objeto Response expone estos atributos:
| Atributo | Descripción |
|---|---|
cuerpo |
La respuesta del cuerpo se presenta en bytes. Si la respuesta no tiene cuerpo, el valor de body estará vacío (por ejemplo: b''). |
fecha |
Muestra la fecha y hora en que se recibió la respuesta. |
encabezados |
Informa de un objeto similar a un diccionario de los encabezados de la respuesta (tenga en cuenta que en Selenium Wire los encabezados no distinguen entre mayúsculas y minúsculas y se permiten duplicados). |
motivo |
Informa de la frase de motivo de la respuesta, como OK, No encontrado, etc. |
código de estado |
Informa del estado de la respuesta, como 200, 404, etc. |
Para probar esta función, puede crear un script de Python como el siguiente:
from seleniumwire import webdriver
# Inicializar el WebDriver con Selenium Wire.
driver = webdriver.Chrome()
try:
# Abrir el sitio web de destino.
driver.get("https://brightdata.com/")
# Acceder e imprimir todas las solicitudes capturadas.
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Método: {request.method}")
print(f"Encabezados: {request.headers}")
print(f"Código de estado de la respuesta: {request.response.status_code if request.response else 'Sin respuesta'}")
print("-" * 50)
finally:
# Cerrar el navegador
driver.quit()
El código anterior abre el sitio web de destino y captura las solicitudes mediante driver.requests. A continuación, recorre un bucle for para interceptar algunos atributos de la solicitud, como la URL, el método y los encabezados.
Este es el resultado esperado:
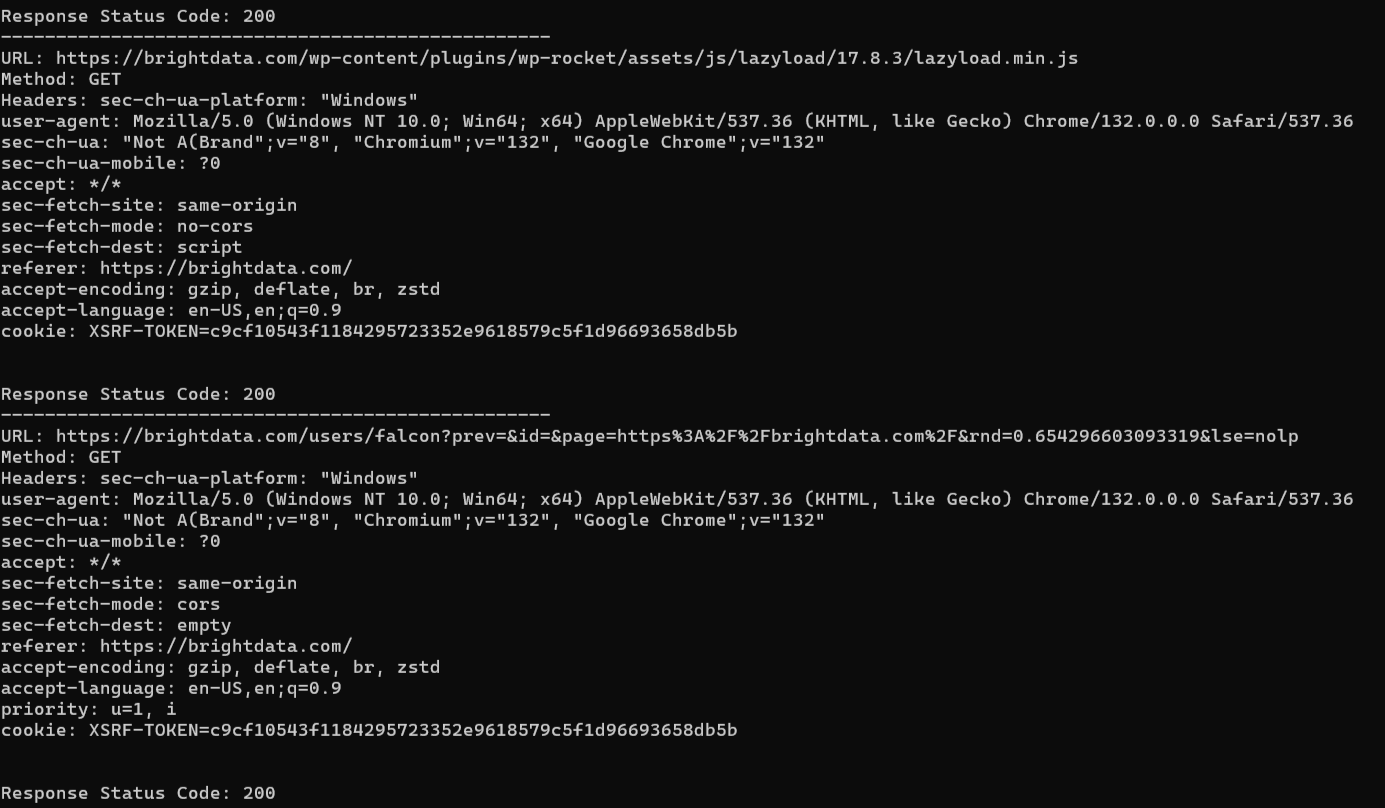
La página de destino realiza varias solicitudes y el script las rastrea todas.
Interceptar solicitudes y respuestas
Selenium Wire puede interceptar y modificar solicitudes y respuestas gracias a los interceptores. Un interceptor es una función que se invoca con las solicitudes y respuestas a medida que pasan por el navegador.
Hay dos interceptores independientes:
driver.request_interceptor: intercepta las solicitudes y acepta un único argumento.driver.response_interceptor: intercepta la respuesta y acepta dos argumentos, uno para la solicitud original y otro para la respuesta.
A continuación se muestra un ejemplo que muestra cómo utilizar un interceptor de solicitudes:
from seleniumwire import webdriver
# Define la función del interceptor de solicitudes.
def interceptor(request):
# Añade un encabezado personalizado a todas las solicitudes.
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# Bloquear solicitudes a un dominio específico
if "example.com" in request.url:
print(f"Bloqueando solicitud a: {request.url}")
request.abort() # Abortar la solicitud
# Inicializar WebDriver con Selenium Wire
driver = webdriver.Chrome()
# Asignar la función interceptora al controlador
driver.request_interceptor = interceptor
try:
# Abrir un sitio web que realiza múltiples solicitudes
driver.get("https://brightdata.com/")
# Imprimir todas las solicitudes capturadas
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Headers: {request.headers}")
print("-" * 50)
finally:
# Cerrar el navegador
driver.quit()
Esto es lo que hace este fragmento de código:
- Función interceptora: crea una función interceptora que se invoca para cada solicitud saliente. Esto añade un encabezado personalizado a todas las solicitudes salientes con
request.headers[]. Además, bloquea las solicitudes del navegador para el dominioexample.com. - Captura solicitudes: después de cargar la página, se imprimen todas las solicitudes capturadas, incluidos los encabezados modificados.
Nota: El bloqueo de solicitudes es útil cuando las páginas cargan recursos adicionales, como anuncios, scripts de análisis o widgets de terceros que no son relevantes para su objetivo. Bloquear estas solicitudes puede mejorar significativamente la velocidad de raspado y reducir el uso de ancho de banda del navegador.
El resultado esperado es algo así:
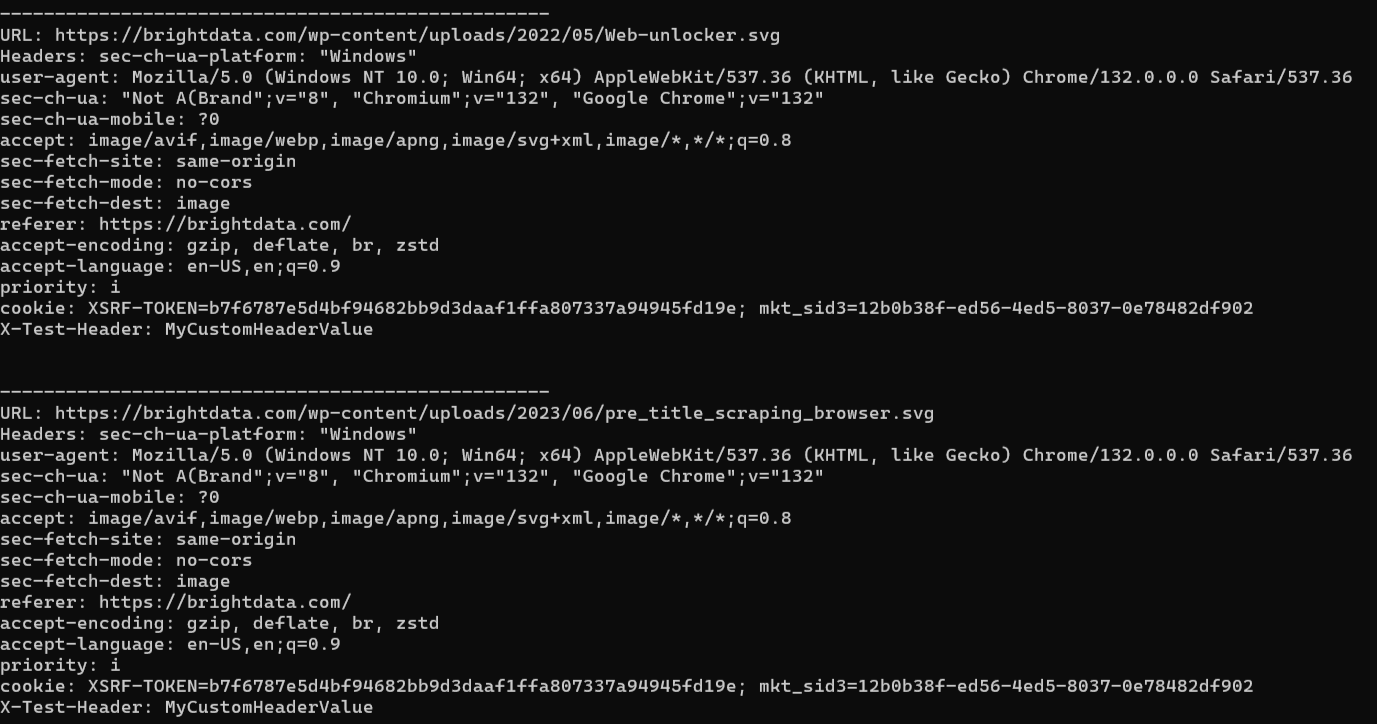
Observe cómo se interceptó la solicitud realizada por el navegador y se le añadió el valor de encabezado adicional.
Supervisión de WebSocket
Muchas páginas web modernas utilizanWebSocketspara la comunicación en tiempo real con los servidores.Los WebSocketsestablecen una conexión persistente entre el navegador y el servidor. De esta forma, los datos se pueden intercambiar continuamente sin la sobrecarga de las solicitudes HTTP tradicionales.
A menudo, los datos críticos fluyen a través de estos canales, y acceder a ellos directamente puede ser muy valioso para la recuperación de datos. Al interceptar la comunicación WebSocket, puede extraer los datos sin procesar enviados por el servidor sin esperar a que el navegador los transforme o la página los renderice.
Ya ha aprendido que los objetos de solicitud tienen el atributo ws_messages para gestionar WebSockets. Estos son los atributos de un objeto Selenium Wire WebSocket:
| Atributo | Descripción |
|---|---|
content |
Informa del contenido del mensaje, que puede ser una cadena o estar en formato bytes. |
fecha |
Muestra la fecha y hora del mensaje. |
encabezados |
Informa sobre un objeto similar a un diccionario de los encabezados de la respuesta (tenga en cuenta que en Selenium Wire los encabezados no distinguen entre mayúsculas y minúsculas y se permiten duplicados). |
from_client |
Es un valor booleano que devuelve True cuando el mensaje ha sido enviado por el cliente y False cuando lo ha enviado el servidor. |
Gestionar proxies
Los servidores Proxyactúan como intermediarios entre su dispositivo y los sitios de destino, ocultando su dirección IP en el proceso. Son esenciales para el Scraping web, ya que:
- Ayudan a eludir las restricciones basadas en IP
- Evitan el bloqueo en caso de limitadores de velocidad
- Permiten extraer contenido de sitios con restricciones geográficas
A continuación se muestra cómo se puede configurar un Proxy en Selenium Wire:
# Configurar las opciones de Selenium Wire
options = {
"proxy": {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
}
# Inicializar el WebDriver con Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
Esta configuración difiere de la configuración de unProxy en Selenium vanilla, donde es necesario utilizar el indicador--proxy-serverde Chrome. Esto significa que la configuración del Proxy es estática en Selenium vanilla.
Una vez que se configura un Proxy, se aplica a toda la sesión del navegador y no se puede cambiar sin reiniciar el navegador. Esta limitación puede ser restrictiva, especialmente en situaciones en las que es necesario rotar los Proxies de forma dinámica.
Por el contrario, Selenium Wire ofrece la flexibilidad de cambiar los Proxies de forma dinámica dentro de la misma instancia del navegador. Esto es posible gracias al atributo Proxy:
# Cambiar dinámicamente el Proxy
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}
Además, el indicador --proxy-server de Chrome no admite proxies con credenciales de autenticación en la URL:
protocolo://nombre_de_usuario:contraseña@host:puerto
En cambio, Selenium Wire es totalmente compatible con los Proxy autenticados, lo que lo convierte en la mejor opción para el Scraping web.
Dado que la configuración del Proxy es una de las ventajas más significativas de Selenium Wire, exploraremos este tema más a fondo en el siguiente capítulo.
Caso de uso del Scraping web: Proxy rotativo en Selenium Wire
Como se ha mencionado anteriormente, la razón principal para utilizar Selenium Wire para el Scraping web es su avanzada capacidad de gestión de Proxies.
En esta sección guiada, verás cómo configurar un proyecto de Selenium Wire para la rotación de proxies. Esto te ayudará a cambiar tu IP de salida en cada solicitud.
Requisitos
Para replicar este tutorial, su sistema debe cumplir los siguientes requisitos previos:
- Python 3.7 o superior: cualquier versión de Python superior a 3.7 servirá. En concreto, instalaremos las dependencias a través de pip, que ya viene instalado con cualquier versión de Python superior a 3.4.
- Un navegador web compatible: Selenium Wire amplía Selenium, por lo que necesita unnavegador compatible.
Antes de instalar Selenium Wire, puede crear un directoriode entorno virtualde la siguiente manera:
python -m venv venv
Para activarlo, en Windows, ejecute:
venvScriptsactivate
De forma equivalente, en macOS/Linux, ejecute:
source venv/bin/activate
Ahora puede instalar Selenium Wire con:
pip install selenium-wire
Nota: No es necesario instalar Selenium. Su instalación se realiza con Selenium Wire, ya que es una de sus dependencias.
Supongamos que llama a su carpeta principal selenium_wire/. Al final de este paso, la carpeta tendrá la siguiente estructura:
selenium_wire/
├── selenium_wire.py
└── venv/
Donde selenium_wire.py es el archivo Python que contendrá toda la lógica que implementarás en los siguientes pasos.
Paso 1: Aleatorizar los Proxies
En primer lugar, necesitas una lista de URLs de Proxies válidos. Si no sabes dónde conseguirlos, echa un vistazo a nuestra lista deProxies gratuitos. Añádelos a una lista y utilizarandom.choice()para seleccionar un elemento aleatorio de la misma:
def get_random_Proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# Aleatorizar la lista
return random.choice(Proxies)
Una vez llamada, esta función devuelve una URL de Proxy aleatoria de la lista.
Para que funcione, no olvides importar random:
import random
Paso 2: Configurar el Proxy
Llama a la función get_random_proxy() para obtener una URL Proxy:
Proxy = get_random_Proxy()
A continuación, inicializa la instancia del navegador y configura el Proxy seleccionado:
# Configuración de Selenium Wire con el Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuración del navegador
chrome_options = Options()
chrome_options.add_argument("--headless") # Ejecuta el navegador en modo sin interfaz gráfica
# Inicializa una instancia del navegador con las configuraciones dadas
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
El fragmento anterior requiere las siguientes importaciones:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
Para cambiar dinámicamente el Proxy durante la sesión del navegador, se utilizaría este código en su lugar:
driver.proxy = {
"http": Proxy,
"https": Proxy
}
Increíble, la instancia controlada de Chrome ahora enrutará las solicitudes a través del Proxy dado.
Paso 3: Visite la página de destino
Visite el sitio web de destino, extraiga el resultado y cierre el navegador:
try:
# Visite la página de destino
driver.get("https://httpbin.io/ip")
# Extraer la salida de la página
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Gestionar cualquier error que se produzca con el navegador o el Proxy
print(f"Error con el Proxy {proxy}: {e}")
finally:
# Cerrar el navegador
driver.quit()
Para que funcione, importa By desde Selenium:
from selenium.webdriver.common.by import By
En este ejemplo, la página de destino es el punto final/ipdel proyecto HTTPBin. Se trata de una elección deliberada, ya que la página devuelve la dirección IP de quien realiza la llamada. Si todo sale según lo previsto, el script debería imprimir una IP diferente de la lista de Proxies en cada ejecución.
¡Es hora de verificarlo!
Paso 4: Ponlo todo junto
Esta es toda la lógica de rotación de proxies de Selenium Wire que debería estar en tu archivo selenium_wire.py:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# Añade más proxies aquí...
]
# Seleccionar un Proxy al azar
return random.choice(proxies)
# Seleccionar una URL de Proxy aleatoria
proxy = get_random_proxy()
# Configuración de Selenium Wire con el Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuración del navegador
chrome_options = Options()
chrome_options.add_argument("--headless") # Ejecutar el navegador en modo sin interfaz gráfica
# Inicializar una instancia del navegador con las configuraciones dadas
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
try:
# Visita la página de destino
driver.get("https://httpbin.io/ip")
# Extraer la salida de la página
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Gestionar cualquier error que se produzca con el navegador o el Proxy
print(f"Error con el Proxy {proxy}: {e}")
finally:
# Cerrar el navegador
driver.quit()
Para ejecutar el archivo, inicie:
python3 selenium_wire.py
En cada ejecución, el resultado debería ser:
{
"origin": "PROXY_1:XXXX"
}
O:
{
"origin": "PROXY_2:YYYY"
}
Y así sucesivamente…
Ejecute el script varias veces y verá una dirección IP diferente cada vez. ¡La rotación de proxies funciona!
Un enfoque mejor para la rotación de proxies: los proxies de Bright Data
Como acabamos de ver, la rotación manual de proxies en Selenium Wire implica mucho código repetitivo y requiere mantener una lista de URL de proxies válidas.
Afortunadamente,los Proxy rotativos de Bright Datason una solución más eficiente.
Nuestros proxies rotativos gestionan automáticamente los cambios de dirección IP, lo que elimina la necesidad de gestionar los proxies manualmente. Con cobertura en 195 países, garantizamos un tiempo de actividad de la red excepcional y una tasa de éxito del 99,9 %. Nuestra red mundial de proxies incluye:
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxies residenciales: más de 72 millones de IPs residenciales en más de 195 países.
- Proxy ISP: más de 700 000 IP de ISP.
- Proxy móvil: más de 7 millones de IP móviles.
Siga los pasos que se indican a continuación y aprenda a utilizar los Proxies de Bright Data en Selenium Wire.
Si ya tiene una cuenta, inicie sesión en Bright Data. De lo contrario, cree una cuenta de forma gratuita. Obtendrá acceso al siguiente panel de control de usuario:
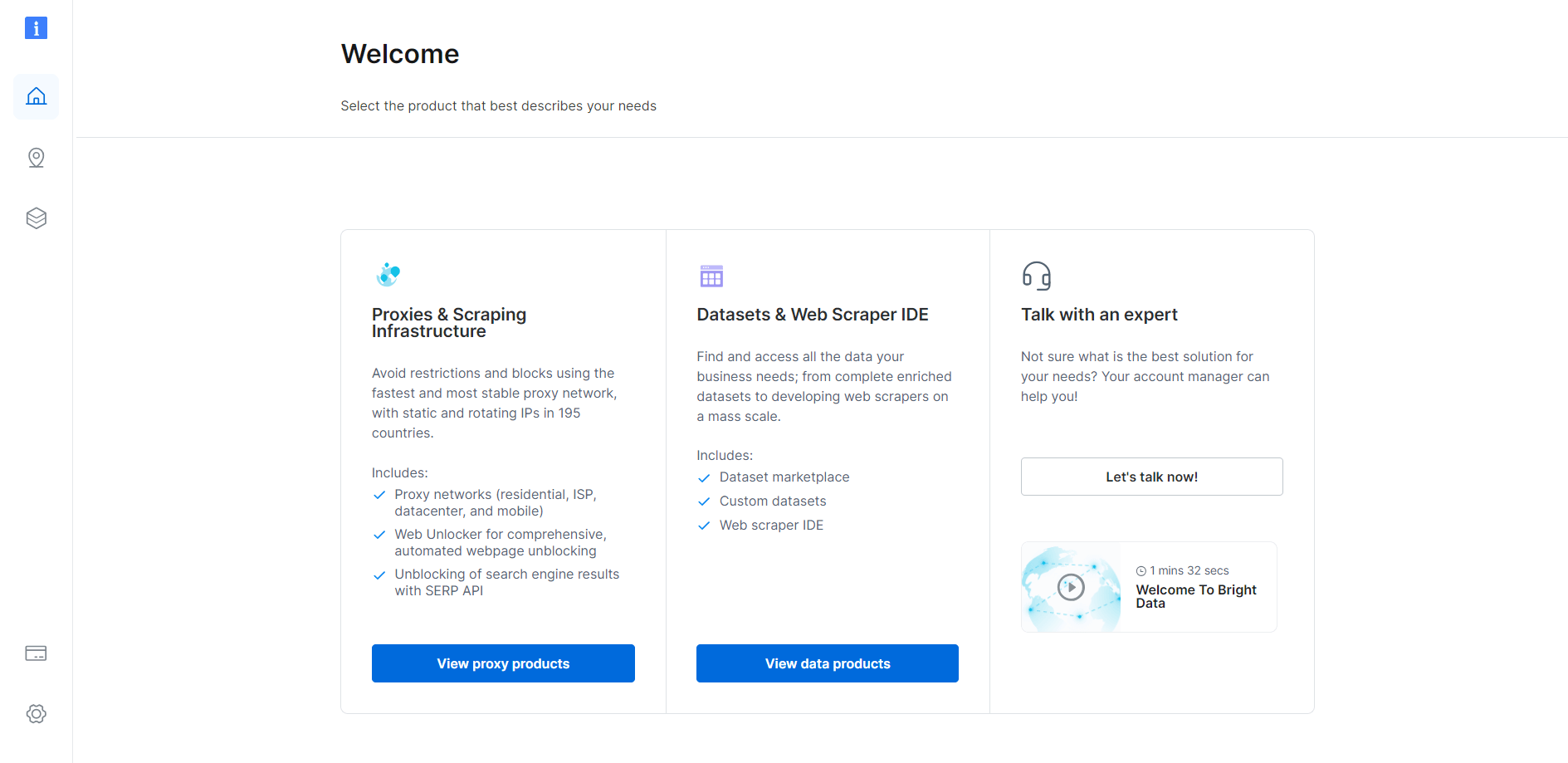
Haga clic en el botón «Ver productos Proxy»:
Se le redirigirá a la página «Proxies e infraestructura de scraping» que se muestra a continuación:
Desplázate hacia abajo, busca la tarjeta «Proxies residenciales»y haz clic en el botón «Empezar»:
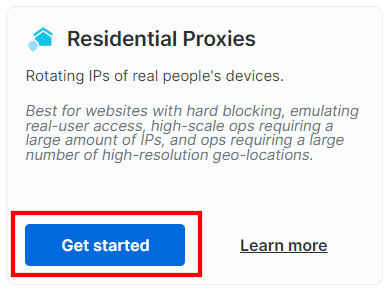
Llegará al panel de control de configuración del Proxy residencial. Siga el asistente guiado y configure el servicio de Proxy según sus necesidades. Si tiene alguna duda sobre cómo configurar el Proxy, no dude enponerse en contacto con el servicio de asistencia 24/7:
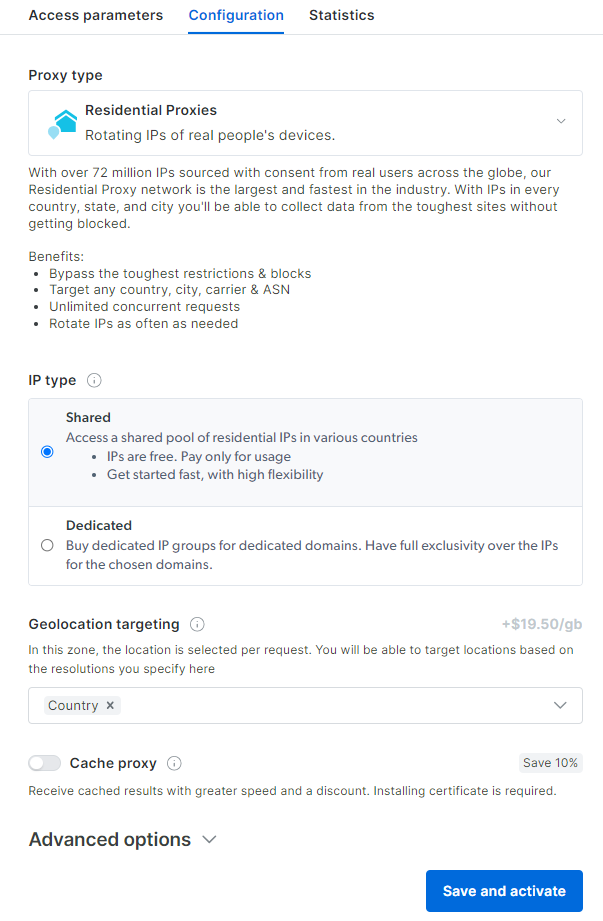
Vaya a la pestaña «Parámetros de acceso» y recupere el host, el puerto, el nombre de usuario y la contraseña de su Proxy de la siguiente manera:
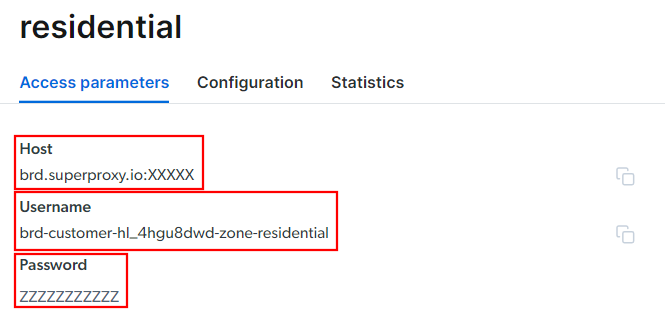
Tenga en cuenta que el campo «Host» ya incluye el puerto.
Eso es todo lo que necesita para crear la URL del Proxy y configurarla en Selenium Wire. Reúna toda la información y cree una URL con la siguiente sintaxis:
<nombre de usuario>:<contraseña>@<host>
Por ejemplo, en este caso sería:
brd-customer-hl_4hgu8dwd-zona-residential:[email protected]:XXXXX
Active «Proxy activo», siga las últimas instrucciones y ¡ya está listo para empezar!

Tu fragmento de código de Proxy de Selenium Wire para la integración con Bright Data tendrá el siguiente aspecto:
# URL del Proxy de Bright Data
proxy = "brd-customer-hl_4hgu8dwd-zona-residential:[email protected]:XXXXX"
# Configurar las opciones de Selenium Wire
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Inicializar WebDriver con Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
¡La rotación de proxies es mucho más fácil con este enfoque!
Selenium frente a Selenium Wire para el Scraping web
A modo de resumen, echa un vistazo a la tabla comparativa entre Selenium y Selenium Wire que aparece a continuación:
| Selenium | Selenium Wire | |
|---|---|---|
| Finalidad | Herramienta para automatizar navegadores web con el fin de realizar pruebas de interfaz de usuario e interacciones web. | Amplía Selenium para proporcionar capacidades adicionales para inspeccionar y modificar solicitudes y respuestas HTTP/HTTPS. |
| Gestión de solicitudes HTTP/HTTPS | No proporciona acceso directo a las solicitudes o respuestas HTTP/HTTPS. | Permite la inspección, modificación y captura de solicitudes y respuestas HTTP/HTTPS. |
| Compatibilidad con Proxy | Compatibilidad limitada con Proxy (requiere configuración manual). | Gestión avanzada de Proxy, con soporte para configuración dinámica |
| Rendimiento | Ligero y rápido | Ligeramente más lento debido a la sobrecarga de capturar y procesar el tráfico de red |
| Casos de uso | Se utiliza principalmente para pruebas funcionales de aplicaciones web, pero también es útil para casos básicos de Scraping web | Útil para probar API, depurar el tráfico de red y realizar Scraping web |
Conclusión
En esta entrada del blog, has aprendido qué es Selenium Wire y cómo se puede utilizar para el Scraping web. En particular, nos hemos centrado en la integración de Proxies y los Proxies rotativos. Ten en cuenta que, aunque Selenium Wire es útil, no es una solución válida para todos los casos. Además, ya no se mantiene activamente.
El mejor enfoque no es ampliar Selenium Wire, sino utilizar Selenium vanilla u otra herramienta de automatización del navegador junto con un Navegador de scraping dedicado.
El Navegador de scraping de Bright Dataes un navegador en la nube escalable que funciona con Playwright, Puppeteer, Selenium y otros. Rota automáticamente las IP de salida con cada solicitud y puede gestionar las huellas digitales del navegador, los reintentos,la resolución de CAPTCHA y mucho más. Olvídate de los bloqueos y optimiza tus operaciones de scraping.
¡Regístrese ahora y comience su prueba gratuita!






