
En este artículo aprenderás:
- Qué es un rastreador de precios de Amazon y por qué es útil
- Cómo crear uno con un tutorial paso a paso en Python
- Las limitaciones de este enfoque y cómo superarlas
¡Empecemos!
¿Qué es un rastreador de precios de Amazon?
Un rastreador de precios de Amazon es una herramienta, servicio o script que permite supervisar el precio de uno o varios productos de Amazon a lo largo del tiempo. Proporciona actualizaciones periódicas sobre los cambios de precio, lo que le permite identificar bajadas, descuentos o fluctuaciones.
¿Por qué rastrear el precio de un artículo de Amazon?
El seguimiento de los precios de Amazon le ayuda a:
- Ahorrar dinero comprando productos a sus precios más bajos.
- Programar las compras durante las rebajas o promociones.
- Establecer precios competitivos para sus productos, si es vendedor
Además, el seguimiento de los precios de Amazon es esencial para supervisar las tendencias estacionales y comprender la dinámica del mercado.
Creación de un rastreador de precios de Amazon: guía paso a paso
En esta sección del tutorial, aprenderás a crear un rastreador de precios de Amazon utilizando Python. Sigue los pasos que se indican a continuación para crear un bot de scraping que:
- Se conecte a las páginas de Amazon de los productos especificados
- Extraiga datos de precios de esas páginas
- Realiza un seguimiento de los cambios de precios a lo largo del tiempo
Si también te interesan otros datos, consulta nuestra guía sobre cómo extraer datos de productos de Amazon.
¡Es hora de implementar un script de seguimiento de precios de Amazon!
Paso n.º 1: Configuración del proyecto
Antes de empezar, asegúrate de tener Python 3+ instalado en tu ordenador. Si no es así, descárgalo desde el sitio web oficial y sigue las instrucciones de instalación.
A continuación, crea un directorio para tu proyecto de seguimiento de precios de Amazon con este comando:
mkdir amazon-price-tracker
Navega hasta ese directorio y configura un entorno virtual dentro de él:
cd amazon-price-tracker
python -m venv venv
Abra la carpeta del proyecto en su IDE de Python preferido. Visual Studio Code con la extensión Python o PyCharm Community Edition son buenas opciones.
Crea un archivo scraper.py en la carpeta del proyecto, que ahora debería contener esta estructura de archivos:
scraper.py contendrá la lógica de seguimiento de precios de Amazon.
En la terminal de su IDE, active el entorno virtual. En Linux o macOS, utilice:
./venv/bin/activate
De forma equivalente, en Windows, ejecute:
venv/Scripts/activate
¡Genial! Ya está todo configurado y listo para empezar.
Paso n.º 2: Configurar las bibliotecas de scraping
Como se explica en nuestra guía sobre el scraping de sitios de comercio electrónico, para realizar scraping en Amazon se necesita una herramienta de automatización del navegador. Esto no se debe a que el sitio sea especialmente dinámico, sino a que Amazon emplea medidas antibots para detectar y bloquear las solicitudes automatizadas.
En términos sencillos, necesitas una herramienta de automatización del navegador como Selenium para recuperar datos de Amazon. Para empezar, instala Selenium de la siguiente manera:
pip install selenium
Si no está familiarizado con esta biblioteca, consulte nuestro tutorial sobre Scraping web con Selenium.
Importe la biblioteca Selenium en su script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
A continuación, cree un objeto ChromeDriver para controlar una instancia del navegador Chrome:
# Inicializar WebDriver para controlar Chrome
driver = webdriver.Chrome(service=Service())
# Lógica de scraping...
# Liberar los recursos del controlador
driver.quit()
driver se utilizará para interactuar con la página de productos de Amazon para el seguimiento de precios.
Recuerda que Amazon adopta medidas anti-scraping, que pueden bloquear los navegadores sin interfaz gráfica. Para evitar problemas, mantén tu navegador controlado por Selenium en modo con interfaz gráfica.
¡Genial! Es hora de automatizar su lógica de scraping de Amazon.
Paso n.º 3: Conéctese a la página de destino
Supongamos que quieres realizar un seguimiento del precio de la PS5 en Amazon:
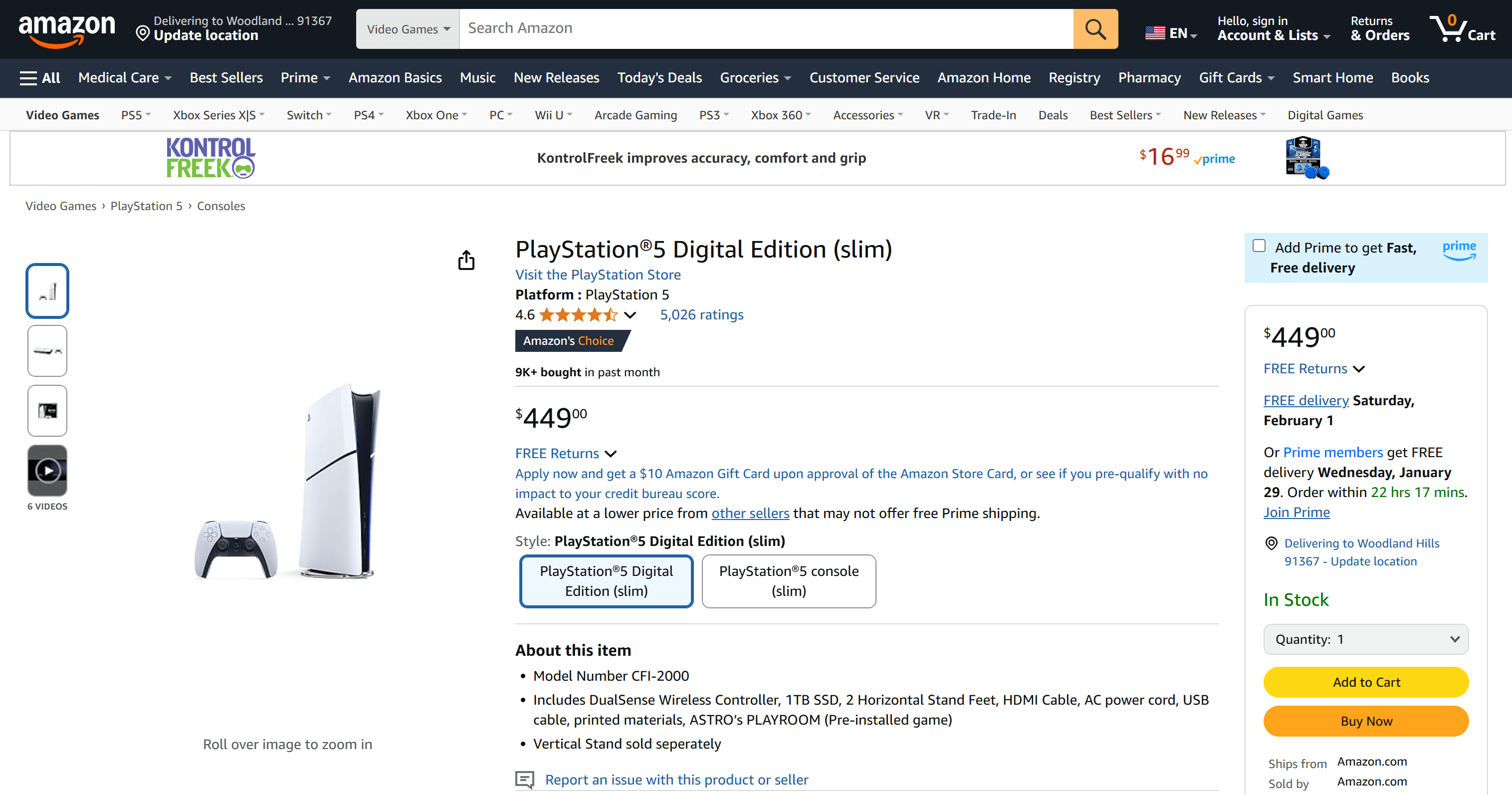
Esta es la URL de la página del producto:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
La parte que sigue a amazon.com es solo un slug para facilitar la lectura, pero lo importante es el código que sigue a /dp/. Este código se denomina ASIN de Amazon, un identificador único para los productos de Amazon.
En otras palabras, puedes acceder a la misma página del producto utilizando el ASIN directamente en el siguiente formato:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
En este ejemplo, el ASIN de la PS5 es B0CL5KNB9M. Almacene este ASIN en una variable y utilícelo para generar la URL del producto de Amazon:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
A continuación, utilice el método get() de Selenium para indicar al navegador que navegue hasta la página de destino:
driver.get(amazon_url)
Establece un punto de interrupción antes de la instrucción driver.quit() y, a continuación, ejecuta el script. Ahora deberías ver la página del producto de Amazon cargada en el navegador:
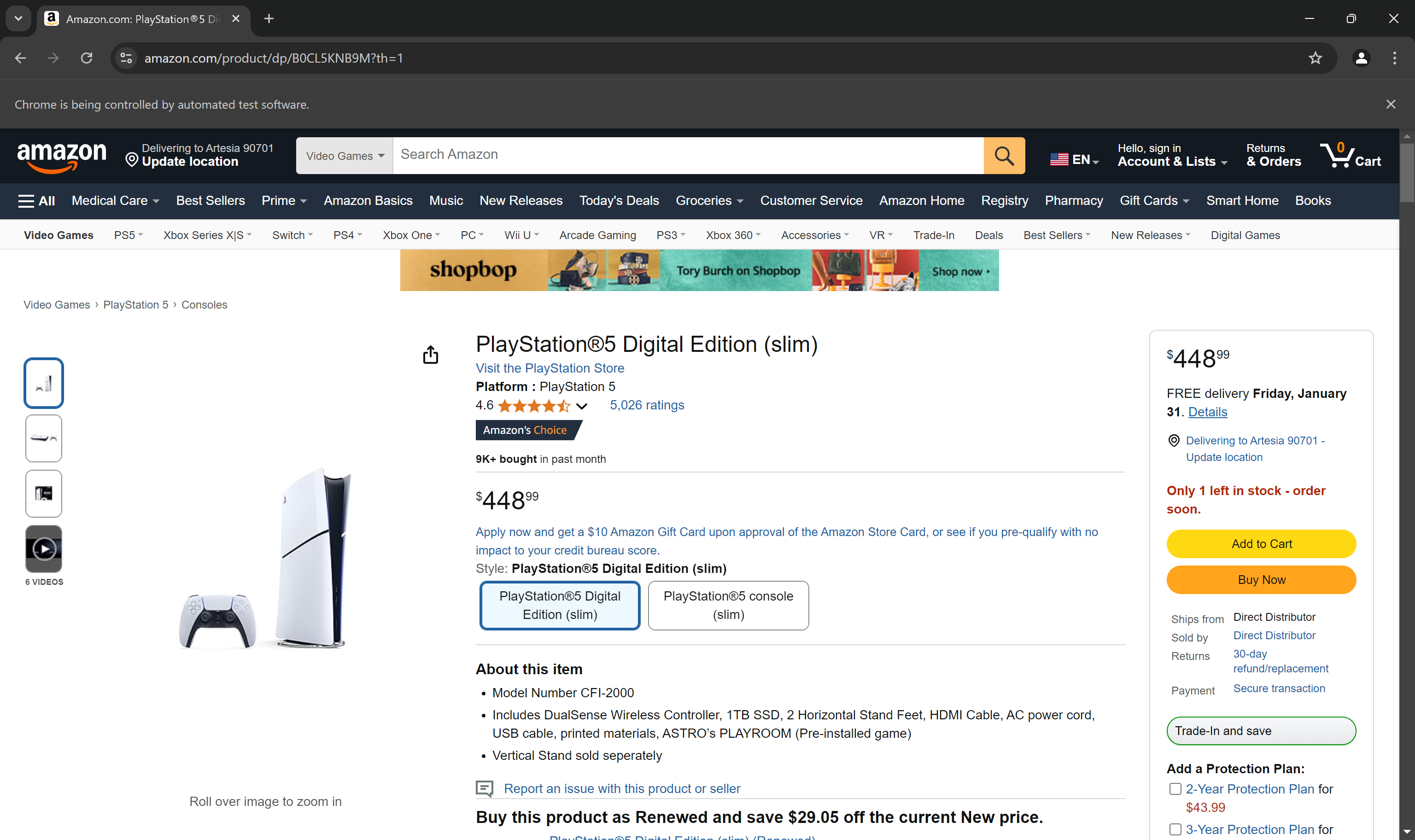
El mensaje «Chrome está siendo controlado por software automatizado» demuestra que Selenium está funcionando en el navegador como se desea.
Tenga en cuenta que Amazon utiliza medidas antibots, lo que puede dar lugar a retos CAPTCHA o solicitudes bloqueadas. No se preocupe, ya que más adelante en este artículo analizaremos estrategias para manejar estos problemas.
Obtenga más información sobre el Scraper ASIN de Amazon de Bright Data aquí.
Paso n.º 4: extraiga la información sobre el precio
Abra la página del producto de destino en modo incógnito en su navegador. A continuación, haga clic con el botón derecho del ratón en el precio que se muestra en la página y seleccione la opción «Inspeccionar»:
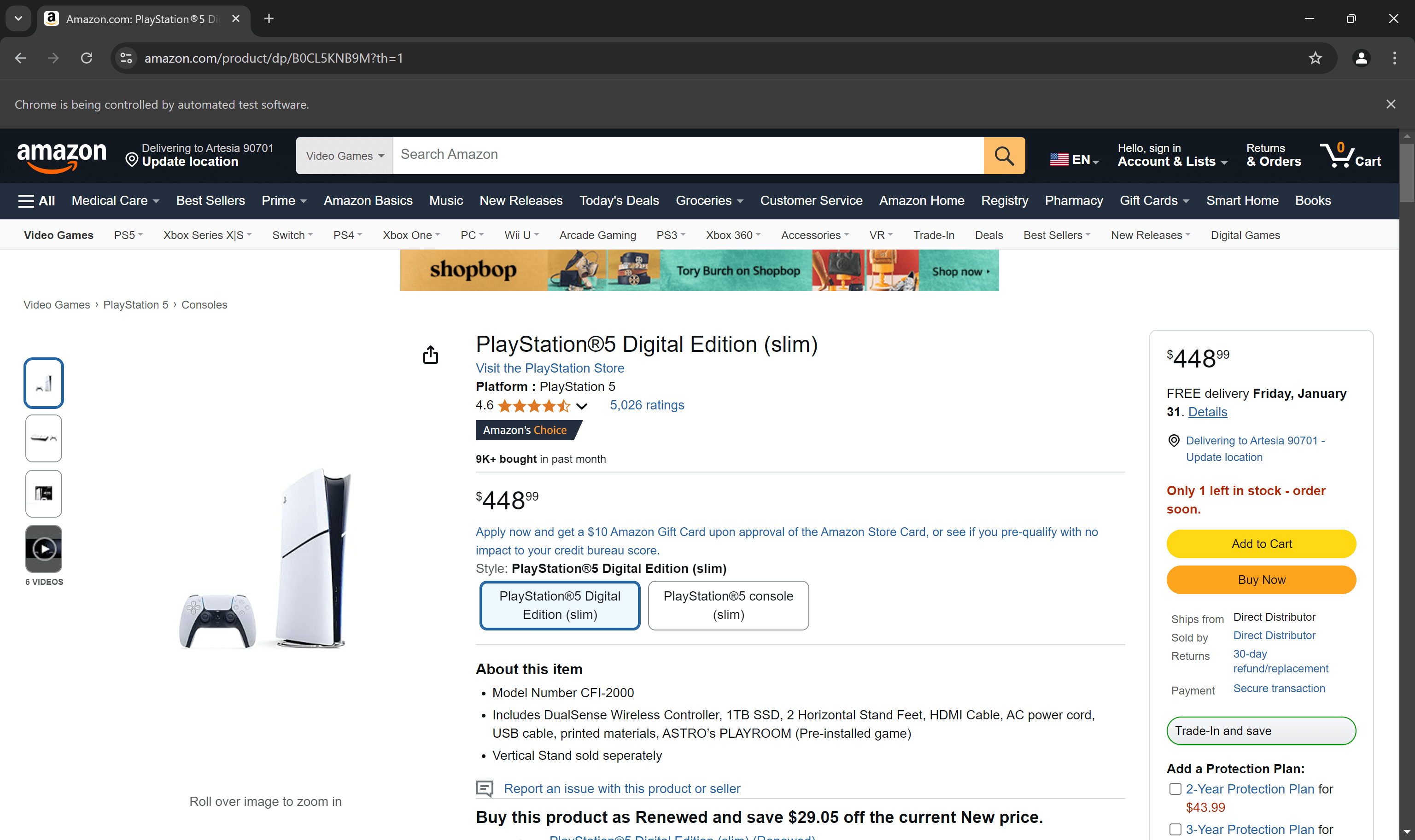
En la sección DevTools, eche un vistazo al HTML del elemento del precio. Tenga en cuenta que el precio se encuentra dentro de un elemento .a-price.
Seleccione el elemento con un selector CSS y extraiga los datos de él:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
La función replace() se utiliza para limpiar el precio de los caracteres de nueva línea.
No olvide importar By:
from selenium.webdriver.common.by import By
¡Genial! Ha implementado con éxito la función clave de su Amazon Price Tracker: extraer el precio.
Paso n.º 5: almacenar los precios
La característica estrella de un rastreador de precios de Amazon es la capacidad de rastrear el historial de precios, de modo que puedas evaluar los cambios y las fluctuaciones a lo largo del tiempo. Para lograrlo, necesitas almacenar los datos de precios en algún lugar, como una base de datos o un archivo.
Para simplificar, utilizaremos un archivo JSON como base de datos. El archivo almacenará el ASIN del producto y una lista de precios históricos.
En primer lugar, asegúrate de que el archivo JSON existe con la siguiente estructura:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
Así es como se inicializa un archivo de este tipo en Python si no existe:
# Nombre del archivo de base de datos JSON y datos iniciales
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Escribir el archivo JSON db si no existe
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Lógica Selenium...
Para que funcione, el fragmento anterior requiere las dos importaciones siguientes:
import os
import json
Antes de la lógica de scraping, carga el archivo JSON para acceder a sus datos actuales:
# Abra el archivo JSON para leerlo y escribirlo
with open(file_name, "r+") as file:
# Cargue los datos de precios actuales
price_data = json.load(file)
# Lógica de scraping...
Después de extraer el precio, añada el nuevo precio junto con una marca de tiempo a la lista de precios:
price = price_element.text.replace("n", "")
# Marca de tiempo actual
timestamp = datetime.now().isoformat()
# Añadir un nuevo punto de información de precios
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
Añade la siguiente importación:
from datetime import datetime
Por último, actualice el archivo JSON:
# Mueve el puntero del archivo al principio
file.seek(0)
# Sobrescribe los datos extraídos
json.dump(price_data, file, indent=4)
# Trunca el archivo para que, si el nuevo contenido es más corto que el original, se borren los datos adicionales
file.truncate()
¡Fantástico! Se ha implementado la lógica de seguimiento de precios.
Paso n.º 6: programar la lógica de seguimiento de precios
Actualmente, es necesario ejecutar manualmente el script cada vez que se desea extraer y rastrear los precios de Amazon. Esto puede funcionar para un uso ocasional. Sin embargo, automatizar el script para que se ejecute a intervalos regulares lo hace mucho más eficaz.
Para ello, utilice la biblioteca de programación de Python. Esta proporciona una API intuitiva para programar tareas en Python.
Instala la biblioteca ejecutando el siguiente comando en tu entorno virtual activado:
pip install schedule
A continuación, encapsule toda la lógica de seguimiento de precios de Amazon en una función que acepte el ASIN como parámetro:
def track_price(amazon_asin):
# Toda la lógica de seguimiento de precios de Amazon...
Ahora tiene un trabajo de Python que puede programar para que se ejecute cada 12 horas:
# Ejecutar inmediatamente
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# A continuación, programe el trabajo para que se ejecute cada 12 horas.
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
El bucle while garantiza que el script permanezca activo para procesar las tareas programadas.
No olvides las dos importaciones siguientes:
import schedule
import time
¡Perfecto! Acabas de automatizar todo el proceso, convirtiendo tu script en un rastreador de precios de Amazon manos libres.
Paso n.º 7: Ponlo todo junto
Así es como debería verse ahora tu rastreador de precios de Amazon en Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Inicializa el WebDriver para controlar Chrome.
driver = webdriver.Chrome(service=Service())
# Generación de la URL del producto de Amazon
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# Nombre del archivo JSON db y datos iniciales
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Escribir el archivo JSON db si no existe
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Abrir el archivo JSON para leer y escribir
with open(file_name, "r+") as file:
# Cargar los datos de precios actuales
price_data = json.load(file)
# Navegar a la página de destino
driver.get(amazon_url)
# Extraer el precio
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# Marca de tiempo actual
timestamp = datetime.now().isoformat()
# Añadir un nuevo punto de información de precios
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# Mover el puntero del archivo al principio
file.seek(0)
# Sobrescribir los datos extraídos
json.dump(price_data, file, indent=4)
# Truncar el archivo para que, si el nuevo contenido es más corto que el original, se borren los datos adicionales.
file.truncate()
# Liberar los recursos del controlador
driver.quit()
# Ejecutar inmediatamente
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# A continuación, programar la tarea para que se ejecute cada 12 horas
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Ejecutarlo como se indica a continuación:
python3 Scraper.py
O, en Windows:
python Scraper.py
Deja que el script se ejecute durante varias horas. El script generará un archivo price_history.json similar al siguiente:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
Observe cómo cada entrada de la matriz de precios se registra exactamente 12 horas después de la anterior.
¡Misión cumplida!
Paso n.º 8: Próximos pasos
Acaba de crear un rastreador de precios de Amazon funcional, pero hay margen de mejora para llevarlo al siguiente nivel. Las posibles mejoras son:
- Añadir registro: como cualquier proceso desatendido, es fundamental comprender lo que está sucediendo. Para ello, añada algún tipo de registro para realizar un seguimiento de las acciones del script.
- Utilizar una base de datos: sustituir el archivo JSON por una base de datos para almacenar los datos. Esto facilita compartir y acceder al historial de precios desde múltiples dispositivos o aplicaciones.
- Implementar el manejo de errores: añade un manejo de errores robusto para gestionar las medidas anti-bot, los tiempos de espera de la red y los fallos inesperados. Asegúrate de que el script reintente o se salte con elegancia cuando se produzcan errores.
- Lea las opciones desde la CLI: permita que el script acepte entradas desde la línea de comandos, como el ASIN y las opciones de programación. Eso lo hará más flexible.
- Sistema de notificaciones: integra alertas por correo electrónico o aplicaciones de mensajería para notificarte los cambios de precios significativos.
Limitaciones de este enfoque y cómo superarlas
El script de seguimiento de precios de Amazon creado en el capítulo anterior es solo un ejemplo básico. No puede confiar en un script tan simple para un uso a largo plazo a menos que implemente los siguientes pasos. Si bien estos pasos mejorarán el script, también lo harán más complejo y difícil de gestionar.
Sin embargo, por muy sofisticado que sea tu script, Amazon puede detenerlo con CAPTCHAs:
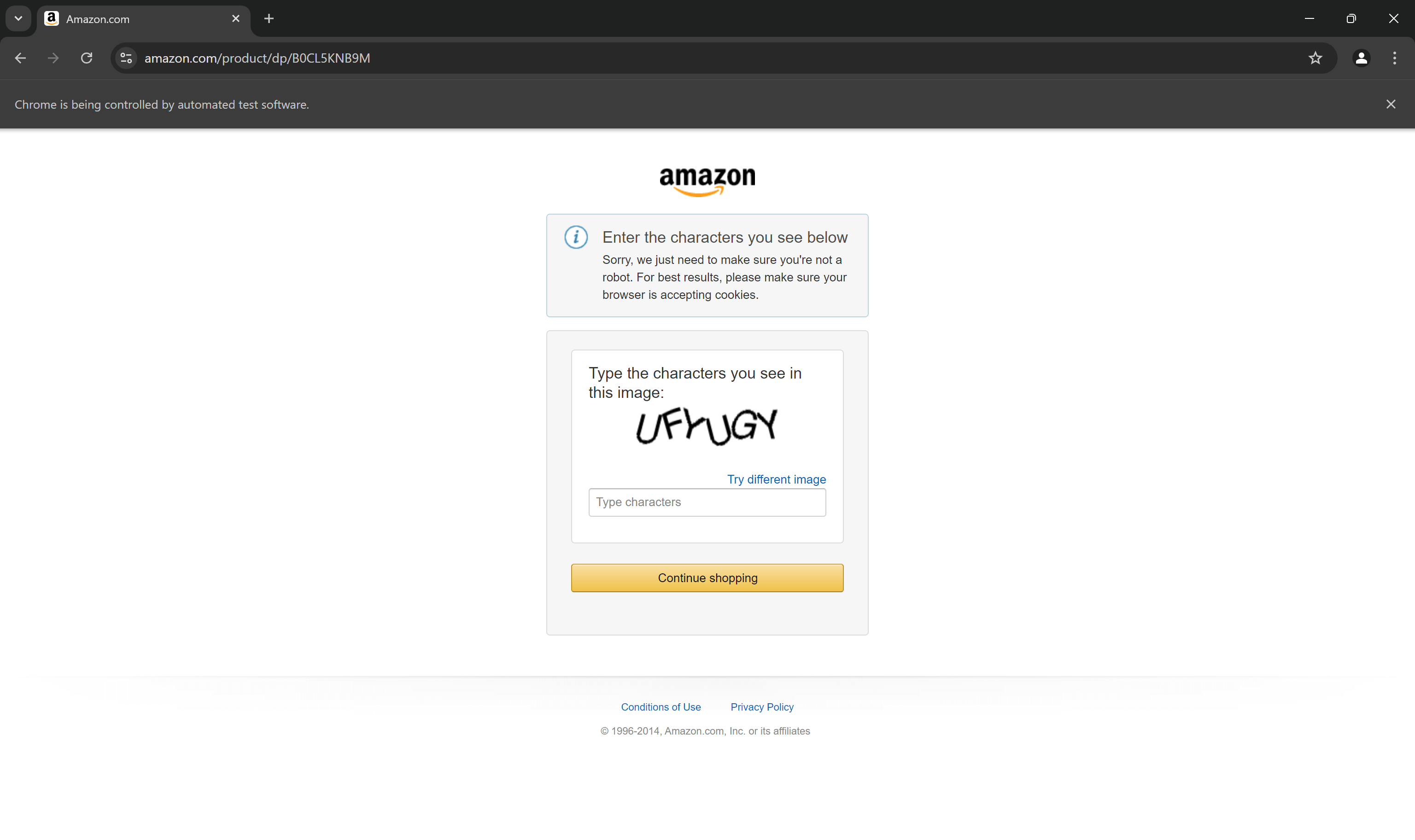
De hecho, es probable que su script actual de scraping de Amazon basado en Selenium ya esté siendo bloqueado por CAPTCHAs. Como primer paso, considere seguir nuestra guía sobre cómo evitar los CAPTCHAs en Python.
Aun así, es posible que se encuentre con errores 429 Too Many Requests debido a la estricta limitación de la velocidad. En tales casos, una buena estrategia es integrar un Proxy en Selenium para rotar su IP de salida.
Estos retos ponen de relieve lo frustrante que puede resultar el scraping de sitios como Amazon sin las herramientas adecuadas. Además, no poder utilizar herramientas de automatización del navegador hace que tu script sea lento y consuma muchos recursos.
Entonces, ¿deberías rendirte? ¡En absoluto! La verdadera solución es confiar en un servicio como Bright Insights, que proporciona información útil sobre el comercio electrónico basada en la IA para ayudarte a:
- Recuperar ingresos perdidos: identifique y aborde la pérdida de ingresos por exclusión de la lista, eventos de agotamiento de existencias o problemas de visibilidad.
- Realizar un seguimiento de las ventas y la cuota de mercado: descubra oportunidades en espacios sin explotar, realice un seguimiento de las ventas de la competencia y detecte las tendencias de forma temprana.
- Optimizar los precios: supervise los precios de la competencia en tiempo real para seguir siendo competitivo.
- Maximizar los medios minoristas: utilice el análisis para optimizar la publicidad, maximizar el retorno de la inversión y garantizar resultados crecientes.
- Optimizar la gama de productos: mejore su gama de productos haciendo un seguimiento de la competencia y maximizando los ingresos.
- Optimización multicanal: aproveche la inteligencia multicanal para gestionar las ventas de productos y triunfar en todas las plataformas.
Bright Insights le proporciona todos los datos de comercio electrónico que necesita, incluidas las funciones de seguimiento de precios de Amazon.
Conclusión
En esta entrada del blog, ha aprendido qué es un rastreador de precios de Amazon y las ventajas que ofrece. También ha visto cómo crear uno utilizando Python y Selenium para el Scraping web.
El reto es que Amazon emplea estrictas medidas anti-bot, como CAPTCHAs, huellas digitales del navegador y prohibiciones de IP, para bloquear los scripts automatizados. Pero con nuestro rastreador de precios de Amazon, puede olvidarse de estos retos y obtener los precios de Amazon.
Si te gusta el Scraping web y te interesan diferentes tipos de datos de Amazon, ¡considera también nuestra API Amazon Scraper!
Crea hoy mismo una cuenta gratuita en Bright Data y explora nuestros servicios.




