
En este artículo trataremos los siguientes temas:
- ¿Qué es un canal de datos?
- Cómo una buena arquitectura de canalización de datos puede ayudar a las empresas
- Ejemplos de arquitectura de canalización de datos
- Canalización de datos frente a canalización ETL
¿Qué es un canal de datos?
Un canal de datos es el proceso por el que pasan los datos. Normalmente, se produce un ciclo completo entre un «sitio de destino» y un «lago o piscina de datos» que presta servicio a un equipo en su proceso de toma de decisiones o a un algoritmo en sus capacidades de IA. Un flujo típico es similar a este:
- Recopilación
- Ingestión
- Preparación
- Cálculo
- Presentación
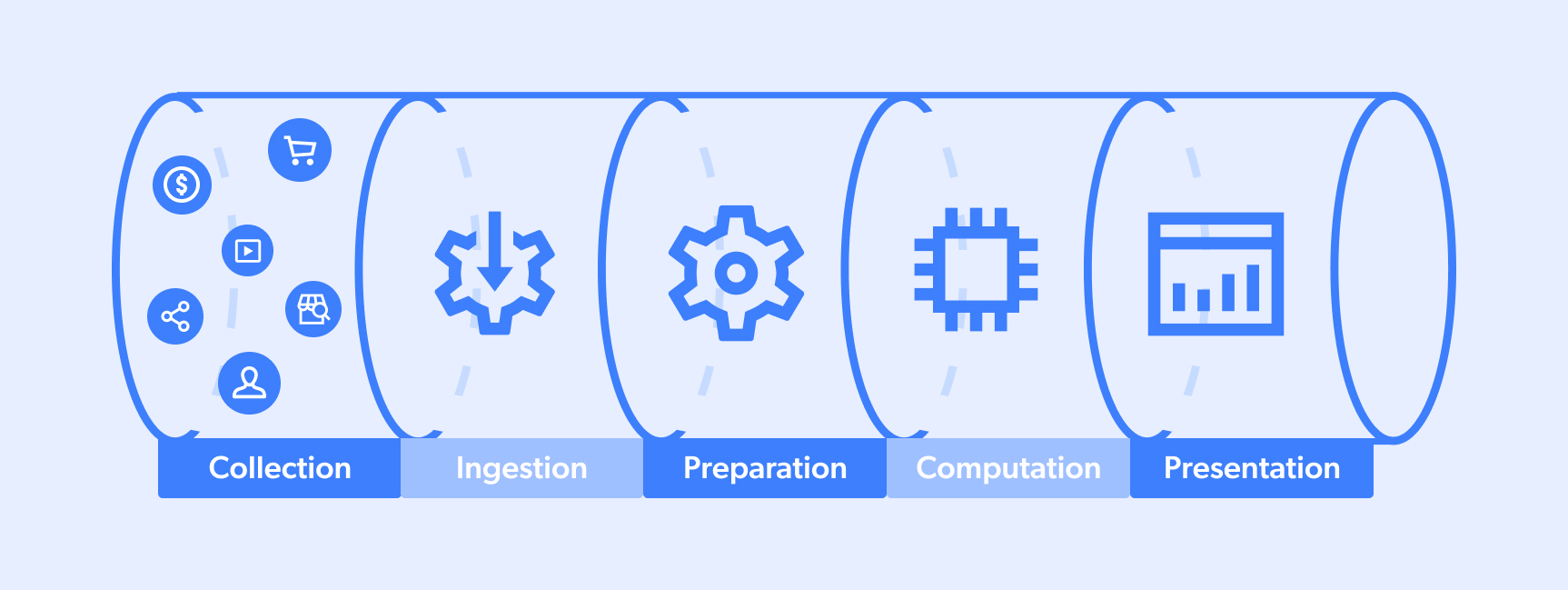
Sin embargo, hay que tener en cuenta que los flujos de datos pueden tener múltiples fuentes/destinos y que, en ocasiones, los pasos pueden realizarse simultáneamente. Además, algunos flujos pueden ser parciales (por ejemplo, los números 1-3 o 3-5).
¿Qué es un canal de big data?
Los flujos de datos masivos son flujos operativos que saben cómo gestionar la recopilación, el procesamiento y la implementación de datos a gran escala. La idea es que cuanto mayor sea la «captura de datos», menor será el margen de error a la hora de tomar decisiones empresariales cruciales.
Algunas aplicaciones populares de un canal de big data son:
- Análisis predictivo: los algoritmos son capaces de hacer predicciones en términos del mercado de valores o la demanda de productos, por ejemplo. Estas capacidades requieren un «entrenamiento de datos» utilizando conjuntos de datos históricos que permiten a los sistemas comprender los patrones de comportamiento humano para predecir posibles resultados futuros.
- Captura del mercado en tiempo real: este enfoque entiende que la confianza actual de los consumidores, por ejemplo, puede cambiar de forma esporádica. Por lo tanto, se agregan grandes cantidades de información de múltiples fuentes, como la recopilación de datos de redes sociales, datos del mercado del comercio electrónico y datos de publicidad de la competencia en los motores de búsqueda. Al cruzar estos puntos de datos únicos a gran escala, se pueden tomar mejores decisiones que dan como resultado una mayor cuota de mercado.
Al aprovechar una plataforma de recopilación de datos, los flujos operativos de los canales de big data son capaces de gestionar:
- Escalabilidad: los volúmenes de datos tienden a fluctuar con frecuencia, y los sistemas deben estar equipados con la capacidad de activar/desactivar recursos a voluntad.
- Fluidez: al recopilar datos a gran escala de múltiples fuentes, las operaciones de procesamiento de big data necesitan los medios para manejar datos en muchos formatos diferentes (por ejemplo, JSON, CSV, HTML), así como los conocimientos técnicos para limpiar, comparar, sintetizar, procesar y estructurar datos no estructurados de sitios web de destino.
- Gestión de solicitudes simultáneas: como suele decir el director ejecutivo de Bright Data, Or Lenchner: «La recopilación de datos a gran escala es como esperar para comprar cerveza en un festival de música. Las solicitudes simultáneas son colas cortas y rápidas que obtienen el servicio de forma rápida y simultánea. En cambio, la otra cola es lenta y consecutiva. Cuando las operaciones de su empresa dependen de ello, ¿en qué cola preferiría estar?».
Cómo una buena arquitectura de canalización de datos puede ayudar a las empresas
Estas son algunas de las formas clave en las que una buena arquitectura de canalización de datos puede ayudar a optimizar los procesos empresariales cotidianos:
Uno: Consolidación de datos
Los datos pueden provenir de muchas fuentes diferentes, como las redes sociales, los motores de búsqueda, los mercados bursátiles, los medios de comunicación, las actividades de los consumidores en los mercados, etc. Los flujos de datos funcionan como un embudo que reúne todos estos datos en un único lugar.
Dos: Reducción de la fricción
Los flujos de datos reducen la fricción y el «tiempo de obtención de información» al disminuir el esfuerzo necesario para limpiar y preparar los datos para el análisis inicial.
Tercero: Compartimentación de datos
La arquitectura de canalización de datos implementada de manera inteligente ayuda a garantizar que solo las partes interesadas relevantes tengan acceso a información específica, lo que contribuye a que cada actor individual mantenga el rumbo.
Cuarto: uniformidad de los datos
Los datos provienen de diversas fuentes y tienen muchos formatos diferentes. La arquitectura de canalización de datos sabe cómo crear uniformidad, además de poder copiar/mover/transferir entre varios depósitos/sistemas.
Ejemplos de arquitectura de canalización de datos
Las arquitecturas de canalización de datos deben tener en cuenta aspectos como el volumen de recopilación previsto, el origen y el destino de los datos, así como el tipo de procesamiento que podría ser necesario.
A continuación se presentan tres ejemplos arquetípicos de arquitectura de canalización de datos:
- Un canal de datos en streaming: este canal de datos está destinado a aplicaciones más en tiempo real. Por ejemplo, una agencia de viajes online (OTA) que recopila datos sobre los precios, los paquetes y las campañas publicitarias de la competencia. Esta información se procesa/formatea y, a continuación, se envía a los equipos/sistemas pertinentes para su posterior análisis y toma de decisiones (por ejemplo, un algoritmo encargado de reajustar el precio de los billetes en función de las bajadas de precios de la competencia).
- Un canal de datos por lotes: se trata de una arquitectura más sencilla y directa. Normalmente consiste en un sistema o fuente que genera una gran cantidad de puntos de datos, que luego se envían a un destino (es decir, una «instalación» de almacenamiento y análisis de datos). Un buen ejemplo de ello sería una institución financiera que recopila grandes cantidades de datos sobre las compras, ventas y el volumen de los inversores en el Nasdaq. Esa información se envía para su análisis y, a continuación, se utiliza para informar a la gestión de la cartera.
- Un canal de datos híbrido: este tipo de enfoque es muy popular entre las grandes empresas y entornos, ya que permite obtener información en tiempo real, así como procesar y analizar datos por lotes. Muchas empresas que optan por este enfoque prefieren conservar los datos en formato sin procesar para poder aumentar su versatilidad en el futuro en lo que respecta a nuevas consultas y cambios estructurales en el canal.
Canalización de datos frente a canalización ETL
Los flujos de trabajo ETL, o de extracción, transformación y carga, suelen servir para el almacenamiento y la integración. Normalmente funcionan como una forma de tomar los datos recopilados de fuentes dispares, transferirlos a un formato más universal y accesible, y cargarlos en un sistema de destino. Los flujos de trabajo ETL suelen permitirnos recopilar, guardar y preparar datos para un acceso y análisis rápidos.
Un canal de datos se centra más en la creación de un proceso sistémico en el que los datos se pueden recopilar, formatear y transferir o cargar a los sistemas de destino. Los canales de datos son más bien un protocolo que garantiza que todas las partes de la «máquina» funcionen según lo previsto.
Conclusión
Encontrar e implementar la arquitectura de canalización de datos adecuada para su negocio es extremadamente importante para su éxito como empresa. Tanto si opta por un enfoque de streaming, por lotes o híbrido, le interesará aprovechar la tecnología que le ayude a automatizar y adaptar las soluciones a sus necesidades específicas.





