

Durante 30 años, Craigslist ha sido un mercado de referencia para todo tipo de ofertas. A pesar de su diseño muy sencillo, propio de los años 90, Craigslist podría ser el mejor lugar del mundo para comprar ofertas «en venta por el propietario».
Hoy vamos a extraer datos de coches de Craigslist utilizandoun Scraper de Python. Siga estos pasos y estará rastreando Craigslist como un profesional en poco tiempo. ¿Busca escala? Eche un vistazo a nuestra comparación de las mejores herramientas de rastreo.
Qué extraer de Craigslist
Excavando en HTML: la forma difícil
La habilidad más importante en el Scraping web es saber dónde buscar. Podríamos escribir un analizador sintáctico demasiado complicado que extraiga elementos individuales del código HTML.
Si observas el camión de la imagen siguiente, sus datos están anidados dentro de un elemento div de la clase cl-gallery. Si queremos hacerlo de la manera difícil, podemos encontrar esta etiqueta y luego realizar el parseo de más elementos a partir de ahí.
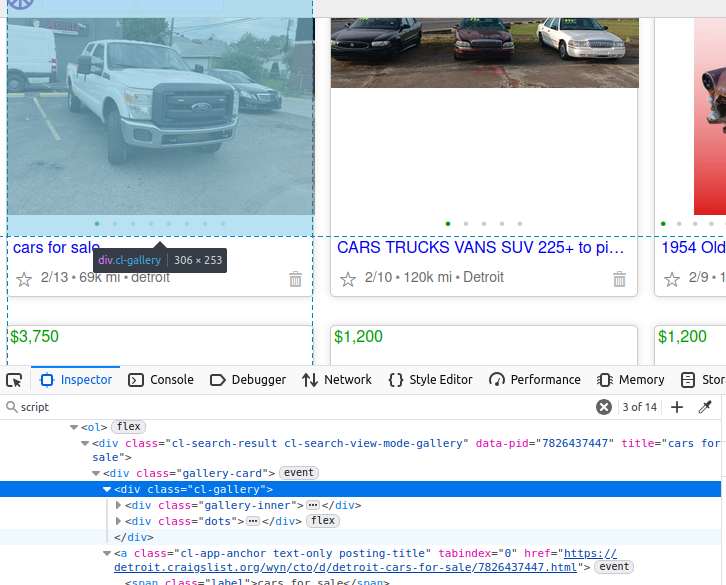
Encontrar el JSON: ahorrar un tiempo precioso
Sin embargo, hay una forma mejor. Muchos sitios, incluido Craigslist, utilizan datos JSON incrustados para construir toda la página. Si puedes encontrar este JSON, tu trabajo de parseo se reduce casi a cero.
En una página de Craigslist, hay un objeto de script que contiene todos los datos que queremos. Si extraemos este elemento, obtenemos los datos de toda la página. Si te fijas, su id es ld_searchpage_results. Podemos localizar este elemento con el selector CSS: script[id='ld_searchpage_results'].
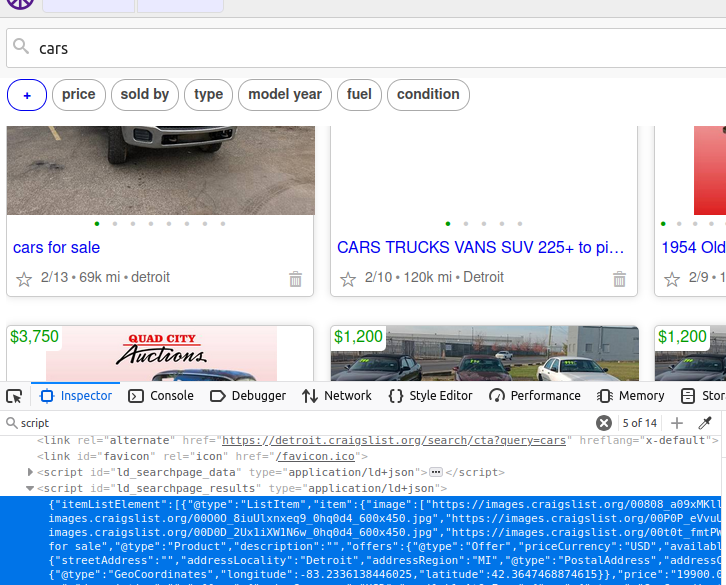
Rastreando Craigslist con Python
Ahora que sabemos lo que estamos tratando de encontrar, extraer datos de Craigslist será mucho más fácil. En las siguientes secciones, repasaremos el código individual y luego lo reuniremos todo en un Scraper funcional.
Parseo de la página
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#si recibimos un código de estado incorrecto, lanzamos un error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
imagen = imágenes[0]
elemento_limpio = {
"nombre": elemento.get("name"),
"imagen": imagen,
"precio": elemento.get("offers").get("price"),
"moneda": elemento.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#hemos revisado todos los anuncios, establecemos success = True y rompemos el bucle
success = True
except Exception as e:
print(f"Error al extraer los anuncios, {e} en {url}")
return scraped_data
- En primer lugar, creamos nuestras variables
url,scraped_dataysuccess.url: La URL exacta de la búsqueda que queremos realizar.scraped_data: Aquí es donde colocamos todos los resultados de la búsqueda.success: Queremos que este Scraper sea persistente. En combinación con un buclewhile, nuestro Scraper no se cerrará hasta que el trabajo haya finalizado y hayamos establecido success enTrue.
- A continuación, obtenemos la página y lanzamos un error en caso de una respuesta incorrecta.
soup = BeautifulSoup(response.text, "html.parser")crea un objetoBeautifulSoupque podemos utilizar para analizar la página.- Encontramos nuestro JSON incrustado con
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']"). - A continuación, lo convertimos en un
diccionarioconjson.loads(). - A continuación, iteramos a través de todos los elementos y limpiamos sus datos. El
clean_itemse añade a nuestroscraped_data. - Por último, establecemos
successenTruey devolvemos la matriz de listados extraídos.
Almacenamiento de nuestros datos
Los dos métodos de almacenamiento más comunes en el Scraping web son CSV y JSON. Veremos cómo almacenar nuestros listados en ambos formatos.
Guardar en un archivo JSON
Este fragmento básico contiene nuestra lógica de almacenamiento JSON. Abrimos un archivo y lo pasamos a json.dump() junto con nuestros datos. Usamos indent=4 para que el archivo JSON sea legible.
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save the results: {e}")
Guardar en un archivo CSV
Guardar en un CSV requiere un poco más de trabajo. CSV no maneja muy bien las matrices. Por eso solo extrajimos una imagen al limpiar los datos.
Si no hay listados, la función se cierra. Si hay listados, escribimos los encabezados CSV utilizando las claves () del primer elemento de la matriz. A continuación, utilizamos csv.DictWriter() para escribir los encabezados y los listados.
def write_listings_to_csv(listings, filename):
if not listings:
print("No listings found. Skipping CSV writing.")
return
# Define CSV column headers
fieldnames = listings[0].keys()
# Escribir datos en CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
Poniendo todo junto
Ahora podemos juntar todas estas piezas. Este código contiene nuestro Scraper totalmente funcional.
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("No listings found. Skipping CSV writing.")
return
# Define CSV column headers
fieldnames = listings[0].keys()
# Escribir datos en CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#si recibimos un código de estado incorrecto, lanzamos un error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
imagen = imágenes[0]
elemento_limpio = {
"nombre": elemento.get("name"),
"imagen": imagen,
"precio": elemento.get("offers").get("price"),
"moneda": elemento.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#hemos revisado todos los anuncios, establecemos success = True y rompemos el bucle
success = True
except Exception as e:
print(f"Error al recopilar los anuncios, {e} en {url}")
return scraped_data
if __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save the results: {e}")
elif OUTPUT == "csv":
try:
write_listings_to_csv(listings, f"{QUERY}-{LOCATION}.csv")
print(f"Se han guardado {len(listings)} listados en {QUERY}-{LOCATION}.csv")
except Exception as e:
print(f"Error al escribir la salida CSV: {e}")
else:
print("Método de salida no compatible")
Dentro del bloque principal, puede gestionar los métodos de almacenamiento con la variable OUTPUT. Si desea almacenar en un archivo JSON, configúrelo en json. Si desea un CSV, configure esta variable en csv. En la recopilación de datos, utilizará ambos métodos de almacenamiento todo el tiempo.
Salida JSON
Como puede ver en la imagen siguiente, cada coche se representa mediante un objeto JSON legible con una estructura clara y limpia.
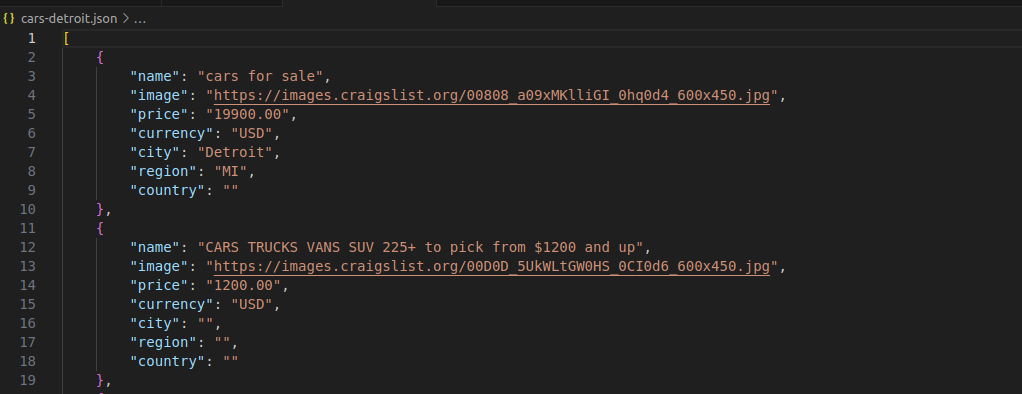
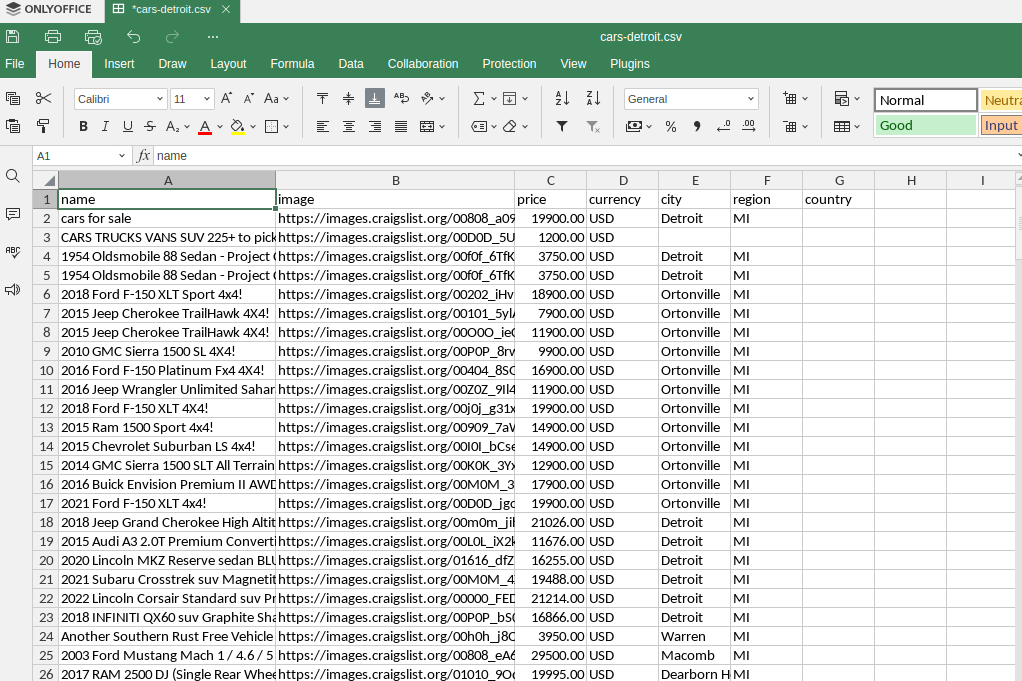
Salida CSV
Nuestra salida CSV es muy similar. Obtenemos una hoja de cálculo limpia con todos nuestros listados.
Eluda las protecciones de Craigslist con Web Unlocker
A medida que amplíe sus operaciones de scraping en Craigslist, inevitablemente se encontrará con obstáculos: CAPTCHAs, bloqueos de IP y sistemas de detección de bots que pueden detener sus Scrapers.
Web Unlocker de Bright Dataresuelve estos retos automáticamente con una infraestructura de nivel empresarial diseñada específicamente para la recopilación de datos a gran escala.
Resolución automática de CAPTCHA
En lugar de resolver manualmente los CAPTCHAs o perder datos valiosos por solicitudes bloqueadas, Web Unlocker se encarga de ello por usted:
- ✅Resolución automática de CAPTCHAspara reCAPTCHA, hCaptcha y más
- ✅Aleatorización de huellas digitales en tiempo realpara evitar la detección
- ✅Lógica de reintento inteligenteque se adapta a los mecanismos de protección de cada sitio
- ✅Tasa de éxito del 99,9 %incluso en páginas muy protegidas
Más información sobre nuestrascapacidades de resolución de CAPTCHA.
Integración sencilla
import requests
# Punto final de Web Unlocker
WEB_UNLOCKER_URL = 'https://brd.superproxy.io:33335'
AUTH = 'brd-customer-<CUSTOMER_ID>-zona-web_unlocker:<ZONA_PASSWORD>'
def scrape_with_unlocker(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
response = requests.get(
url,
Proxies={
'http': f'http://{AUTH}@{WEB_UNLOCKER_URL}',
'https': f'http://{AUTH}@{WEB_UNLOCKER_URL}'
},
verify=False
)
return response.text
# Scrape sin preocuparte por bloqueos o CAPTCHAs
listings = scrape_with_unlocker("detroit", "cars")Con Web Unlocker, obtienes:
- Sin necesidad de realizar la resolución de CAPTCHA manualmente
- Sin dolores de cabeza por la gestión de Proxies
- Sin configuración de rotación de IP
- Solo una recopilación de datos limpia y fiable a gran escala
Uso del Navegador de scraping
El Navegador de scraping nos permite ejecutar una instancia de Playwright con integración de Proxy. Esto puede llevar tu scraping al siguiente nivel al operar un navegador completo desde tu script de Python. Si estás interesado en integrar Proxy con Playwright
En el código siguiente, nuestro método de parseo sigue siendo prácticamente el mismo, pero utilizamos asyncio con async_playwright para abrir un navegador sin interfaz gráfica y obtener la página utilizando este navegador. En lugar de BeautifulSoup, pasamos nuestro selector CSS al método query_selector() de Playwright.
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<TU-NOMBRE-DE-USUARIO>-zone-<TU-NOMBRE-DE-ZONA>:<TU-CONTRASEÑA>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(keyword, location):
print('Conectando con el Navegador de scraping...')
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(SBR_WS_CDP)
context = await browser.new_context()
page = await context.new_page()
try:
print('¡Conectado! Navegando a la página web...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
except Exception as e:
print(f"Failed to scrape data: {e}")
finally:
await browser.close()
return scraped_data
async def main():
QUERY = "cars"
LOCATION = "detroit"
listings = await scrape_listings(QUERY, LOCATION)
try:
with open(f"{QUERY}-scraping-browser.json", "w") as file:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save results {e}")
if __name__ == '__main__':
asyncio.run(main())
Uso de un Scraper personalizado sin código
En Bright Data también ofrecemos un Scraper de Craigslist sin código. Con el Scraper sin código, usted especifica los datos y las páginas que desea rascar. A continuación, nosotros creamos y desplegamos un Scraper para usted.
En la sección «Mis scrapers», haz clic en «Nuevo» y selecciona «Solicitar un Scraper personalizado».
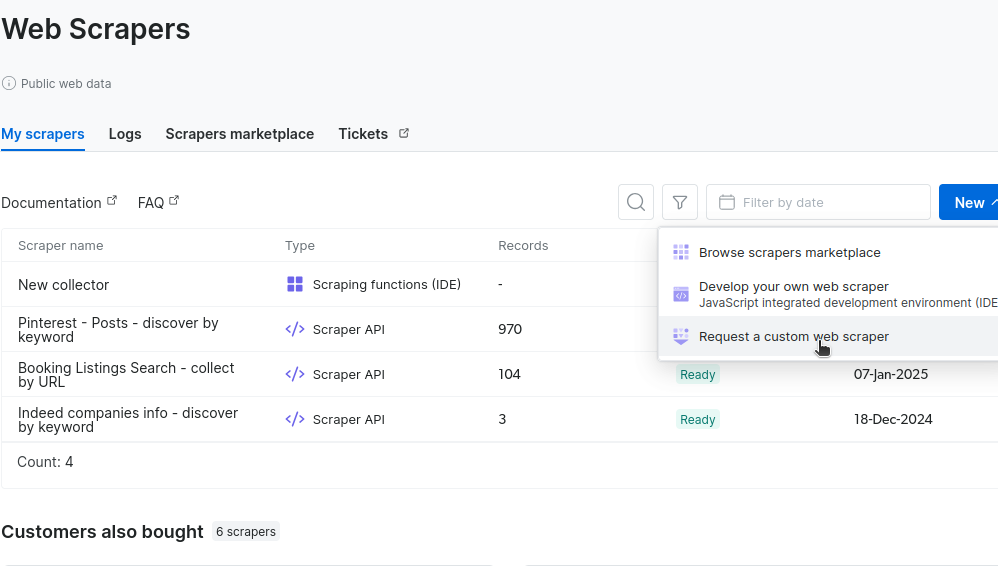
A continuación, se le pedirá que introduzca algunas URL que contengan el diseño de su sitio. En la imagen siguiente, pasamos la URL de nuestra búsqueda de coches en Detroit. Puede añadir una segunda URL para su ciudad.
A través de nuestro proceso automatizado, extraemos los sitios y creamos un esquema para que lo revise.
Una vez creado el esquema, debe revisarlo.
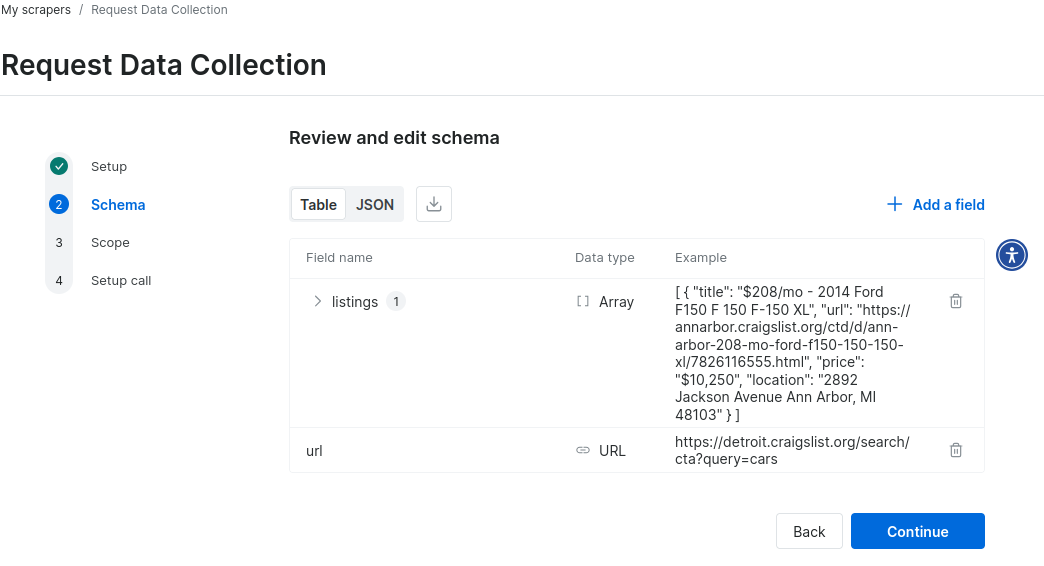
Aquí tiene un ejemplo de datos JSON del esquema para un Scraper personalizado de Craigslist. En cuestión de minutos, tendrá un prototipo funcional.
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
"url": {
"type": "url",
"active": true,
"sample_value": "https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html"
},
"price": {
"type": "price",
"active": true,
"sample_value": "$10,250"
},
"location": {
"type": "text",
"active": true,
"sample_value": "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
"url": {
"type": "url",
"required": true,
"active": true,
"sample_value": "https://detroit.craigslist.org/search/cta?query=cars"
}
}
}
A continuación, establezca el alcance de la recopilación. No necesitamos rastrear todo Craigslist, ni solo una sección específica, por lo que le proporcionaremos las URL para iniciar el rastreo.
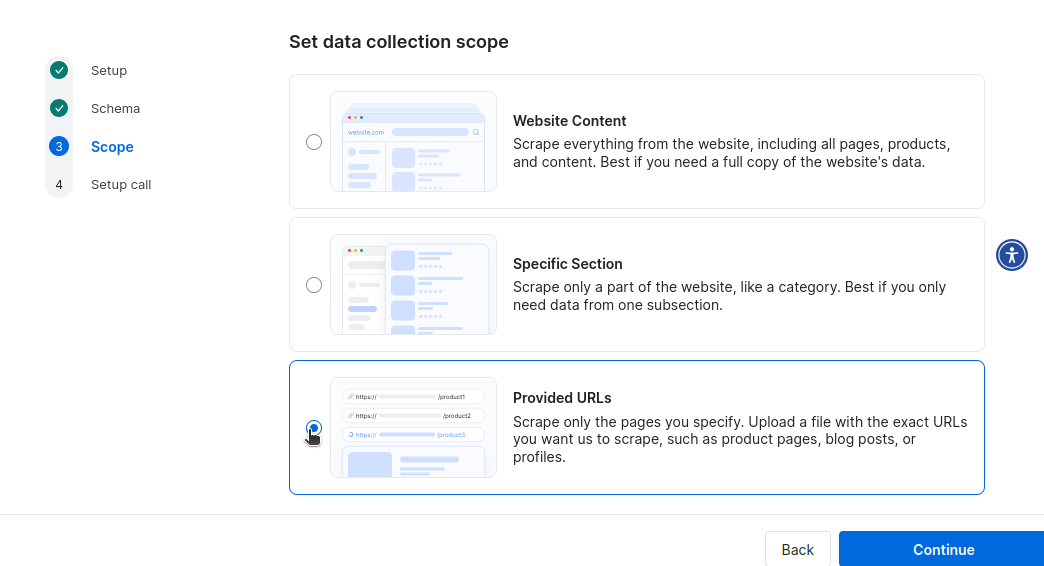
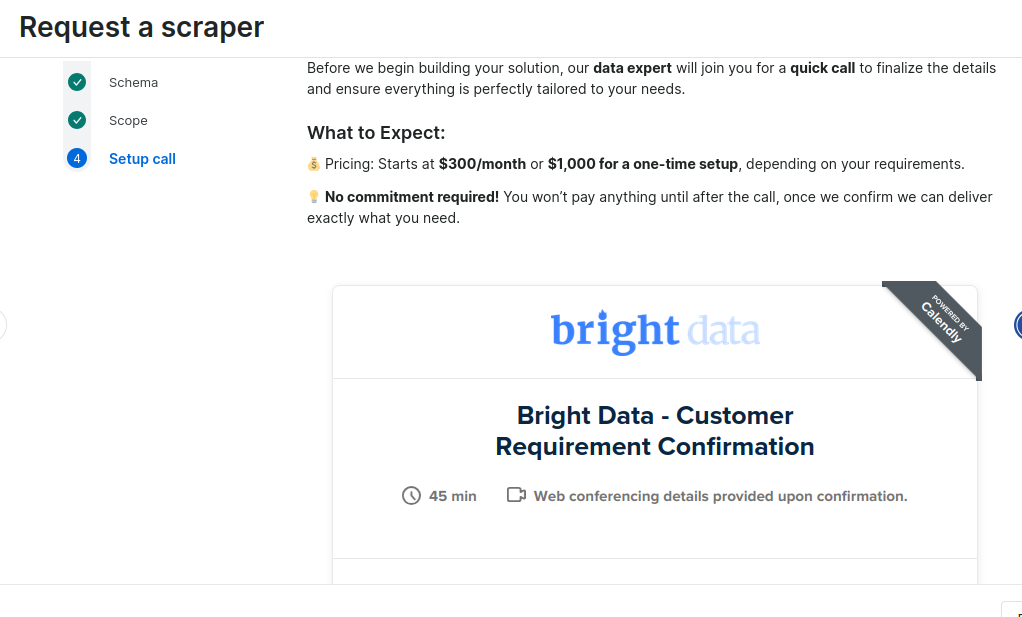
Por último, se le pedirá que programe una llamada con uno de nuestros expertos para la implementación. Puede pagar 300 $ al mes por el mantenimiento o una cuota única de implementación de 1000 $.
Conclusión
Cuando extraiga datos de Craigslist, ahora puede aprovechar Python para un procesamiento de datos rápido y eficiente. Ya sabe cómo realizar el Parseo y limpiar los datos. También ha aprendido a almacenarlos utilizando CSV y JSON. Si necesita la funcionalidad completa del navegador, puede utilizar el Navegador de scraping para satisfacer estas necesidades con una integración completa del Proxy. Si desea automatizar completamente su proceso de extracción, ahora también sabe cómo manejar nuestro No-Code Scraper.
Además, si quieres saltarte por completo el proceso de scraping, Bright Data ofrece conjuntos de datos de Craigslist listos para usar. ¡Regístrate ahora y empieza tu prueba gratuita hoy mismo!





