

Siga este tutorial paso a paso y aprenda a crear un script de Python para Indeed que realice el Scraping web para extraer automáticamente datos sobre ofertas de empleo.
Esta guía tratará los siguientes temas:
- ¿Por qué extraer datos de empleo de la web?
- Bibliotecas y herramientas para extraer datos de Indeed
- Rastrear datos de empleo de Indeed con Selenium
¿Por qué extraer datos de empleo mediante Scraping web?
Scraping web para recopilar datos sobre empleos es útil por varias razones, entre ellas:
- Estudio de mercado: permite a las empresas y a los analistas del mercado laboral recopilar información sobre las tendencias del sector. Por ejemplo, esto incluye qué habilidades tienen una gran demanda o las regiones geográficas que experimentan un crecimiento del empleo. También permite supervisar las actividades de contratación de la competencia.
- Optimización de la búsqueda y la selección de empleo: ayuda a los solicitantes de empleo a buscar ofertas de trabajo en múltiples fuentes para encontrar puestos que se ajusten a sus cualificaciones y preferencias.
- Optimización de la contratación y los recursos humanos: apoya el proceso de contratación facilitando la contratación y ayudando a comprender las tendencias salariales del mercado y los beneficios que buscan los candidatos.
Por lo tanto, los datos sobre empleo son útiles tanto para los empleadores como para los solicitantes de empleo.
En lo que respecta a los Scrapers de ofertas de empleo, hay un aspecto esencial que hay que destacar. La plataforma objetivo debe ser pública. En otras palabras, debe permitir que incluso los usuarios que no hayan iniciado sesión puedan realizar búsquedas de empleo. Esto se debe a que rastrear datos bajo un muro de inicio de sesión puede acarrear problemas legales.
Eso significa descartar LinkedIn. ¿Qué otras plataformas de empleo quedan? ¡Indeed, una de las principales plataformas de empleo online!
Bibliotecas y herramientas para extraer datos de Indeed
Python se considera uno de los mejores lenguajes para el Scraping web gracias a su sintaxis, su facilidad de uso y su rico ecosistema de bibliotecas. Así que, vamos a por ello. Echa un vistazo a nuestra guía sobre Scraping web con Python.
Ahora tienes que elegir las bibliotecas de scraping adecuadas entre las muchas disponibles. Para tomar una decisión informada, explora Indeed en tu navegador. Verás que la mayoría de los datos del sitio se recuperan tras la interacción. Esto significa que el sitio utiliza mucho AJAX para cargar y actualizar el contenido de forma dinámica sin necesidad de recargar la página. Para hacer Scraping web en un sitio así, necesitas una herramienta que sea capaz de ejecutar JavaScript. ¡Esa herramienta es Selenium!
Selenium permite extraer datos de sitios web dinámicos en Python. Representa los sitios en un navegador web controlable, realizando las operaciones que usted le indique. Gracias a Selenium, puede extraer datos incluso si el sitio de destino utiliza JavaScript para la representación o la recuperación de datos.
¡Aprenda a extraer ofertas de empleo de sitios web como Indeed!
Rastrear datos de empleo de Indeed con Selenium
Sigue este tutorial paso a paso y descubre cómo crear un script de Python para realizar Scraping web de Indeed.
Paso 1: Configuración del proyecto
Antes de realizar tareas de scraping web, asegúrate de que cumples estos requisitos previos:
- Python 3+ instalado en su equipo: descargue el instalador, haga doble clic en él y siga las instrucciones del asistente de instalación.
- Un IDE de Python de su elección: PyCharm Community Edition o Visual Studio Code con la extensión Python son dos excelentes opciones.
¡Ahora ya tiene todo lo necesario para configurar un proyecto Python!
Abra el terminal y ejecute los siguientes comandos para:
- Crear una carpeta indeed-scraper
- Entrar en ella
- Inicializarla con un entorno virtual Python
mkdir indeed-Scraper
cd indeed-Scraper
python -m venv envEn Linux o macOS, ejecute el siguiente comando para activar el entorno:
./env/bin/activate
En Windows, ejecute:
envScriptsactivate.ps1
A continuación, inicialice un archivo scraper.py que contenga la siguiente línea en la carpeta del proyecto:
print("¡Hola, mundo!")
Por ahora, solo imprime «¡Hola, mundo!», pero pronto contendrá la lógica de scraping de Indeed.
Ejecútelo para verificar que funciona con:
python Scraper.py
Si todo ha salido según lo previsto, debería imprimir este mensaje en la terminal:
¡Hola, mundo!
Ahora que sabes que el script funciona, abre la carpeta del proyecto en tu IDE de Python.
¡Bien hecho! ¡Prepárate para escribir código Python!
Paso 2: Instalar las bibliotecas de scraping
Como se mencionó anteriormente, Selenium es una gran herramienta cuando se trata de Scraping web de ofertas de empleo de Indeed. Ejecuta el siguiente comando en el entorno virtual Python activado para añadirlo a las dependencias del proyecto:
pip install selenium
Esto puede tardar un poco, así que ten paciencia.
Ten en cuenta que este tutorial hace referencia a Selenium 4.11.2, que incluye funciones de detección automática de controladores. Si tienes una versión anterior de Selenium instalada en tu PC, actualízala con:
pip install selenium -U
Ahora, borre scraper.py. A continuación, importe el paquete e inicialice un Scraper de Selenium con:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configurar una instancia de Chrome controlable
# en modo sin interfaz gráfica
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# lógica de rastreo...
# cerrar el navegador y liberar los recursos
driver.quit()
Este script instancia una instancia de WebDriver para controlar mediante programación una instancia de Chrome. El navegador se abrirá en segundo plano en modo sin interfaz gráfica, lo que significa que no habrá GUI. Esa es una configuración habitual para la producción. Si, por el contrario, prefieres seguir las operaciones que ejecuta el script de trabajos de Scraping web en la página, comenta esa opción. Esto resulta útil en el desarrollo.
Asegúrate de que tu IDE de Python no informe de ningún error. Ignora las advertencias que puedas recibir debido a las importaciones no utilizadas. ¡Estás a punto de utilizar las bibliotecas para extraer datos del repositorio de GitHub!
¡Perfecto! Es hora de crear su Scraper web Indeed Python.
Paso 3: Conéctese a la página web de destino
Abre Indded y busca los trabajos que te interesan. En esta guía, verás cómo extraer ofertas de trabajo remotas para ingenieros de software en Nueva York. Ten en cuenta que cualquier otra búsqueda de trabajo en Indeed servirá. La lógica de extracción será la misma.
Así es como se ve la página de destino en el navegador en el momento de escribir este artículo:
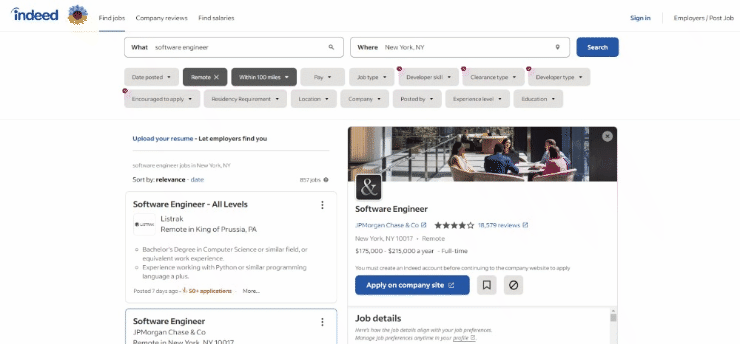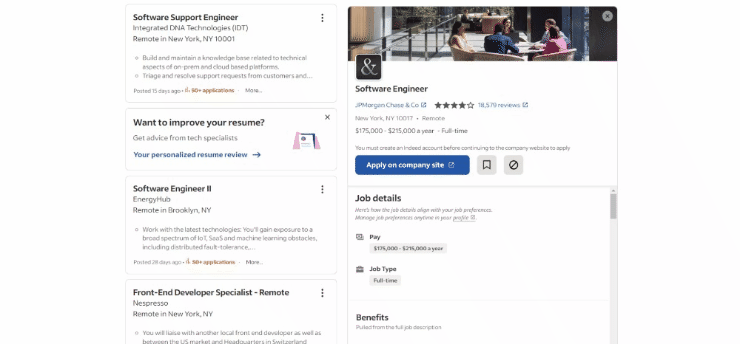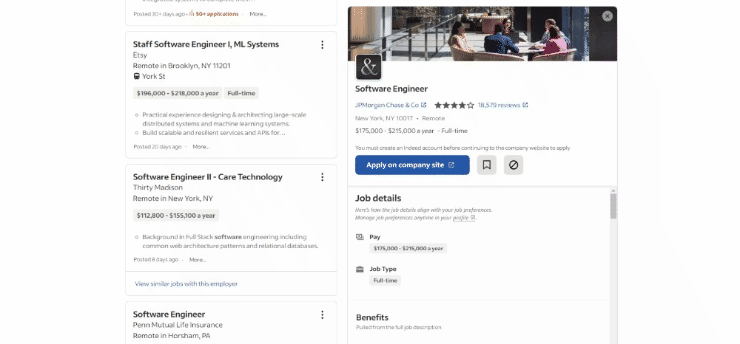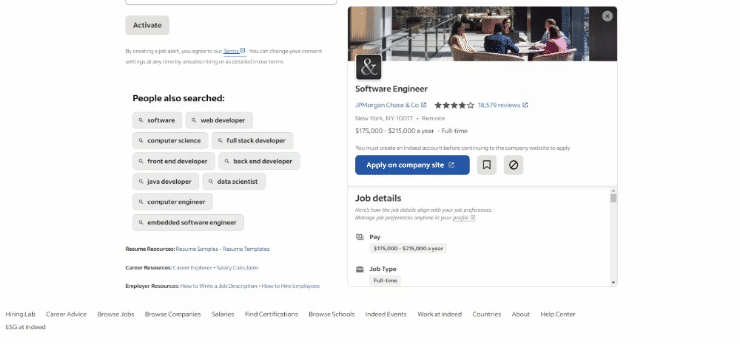
En concreto, así es como se ve la URL de la página de destino:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
Como puede ver, se trata de una URL dinámica que cambia en función de algunos parámetros de consulta.
A continuación, puede utilizar Selenium para conectarse a la página de destino con:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
La función get() indica al navegador que visite la página especificada por la URL pasada como parámetro.
Después de abrir la página, debe establecer el tamaño de la ventana para asegurarse de que todos los elementos sean visibles:
driver.set_window_size(1920, 1080)
Así es como se ve tu script de scraping de Indeed hasta ahora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configurar una instancia de Chrome controlable
# en modo sin interfaz gráfica
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# establecer el tamaño de la ventana para asegurarse de que las páginas
# no se rendericen en modo responsivo
driver.set_window_size(1920, 1080)
# abrir la página de destino en el navegador
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# lógica de scraping...
# cerrar el navegador y liberar los recursos
driver.quit()
Comenta la opción para habilitar el modo sin interfaz gráfica y ejecuta el script. Se abrirá la ventana siguiente durante una fracción de segundo antes de cerrarse:
Tenga en cuenta el aviso «Chrome está siendo controlado por software automatizado». Eso garantiza que Selenium funciona como se espera.
Paso 4: Familiarícese con la estructura de la página
Antes de sumergirse en el scraping, hay otro paso crucial que debe llevar a cabo. El scraping de datos de un sitio implica seleccionar elementos HTML y extraer datos de ellos. Encontrar una forma de obtener los nodos deseados del DOM no siempre es fácil. Por eso debe dedicar algo de tiempo a analizar la estructura de la página para comprender cómo definir una estrategia de selección eficaz.
Abra su navegador y visite la página de búsqueda de empleo de Indeed. Haga clic con el botón derecho del ratón en cualquier elemento y seleccione la opción «Inspeccionar» para abrir las herramientas de desarrollo de su navegador:
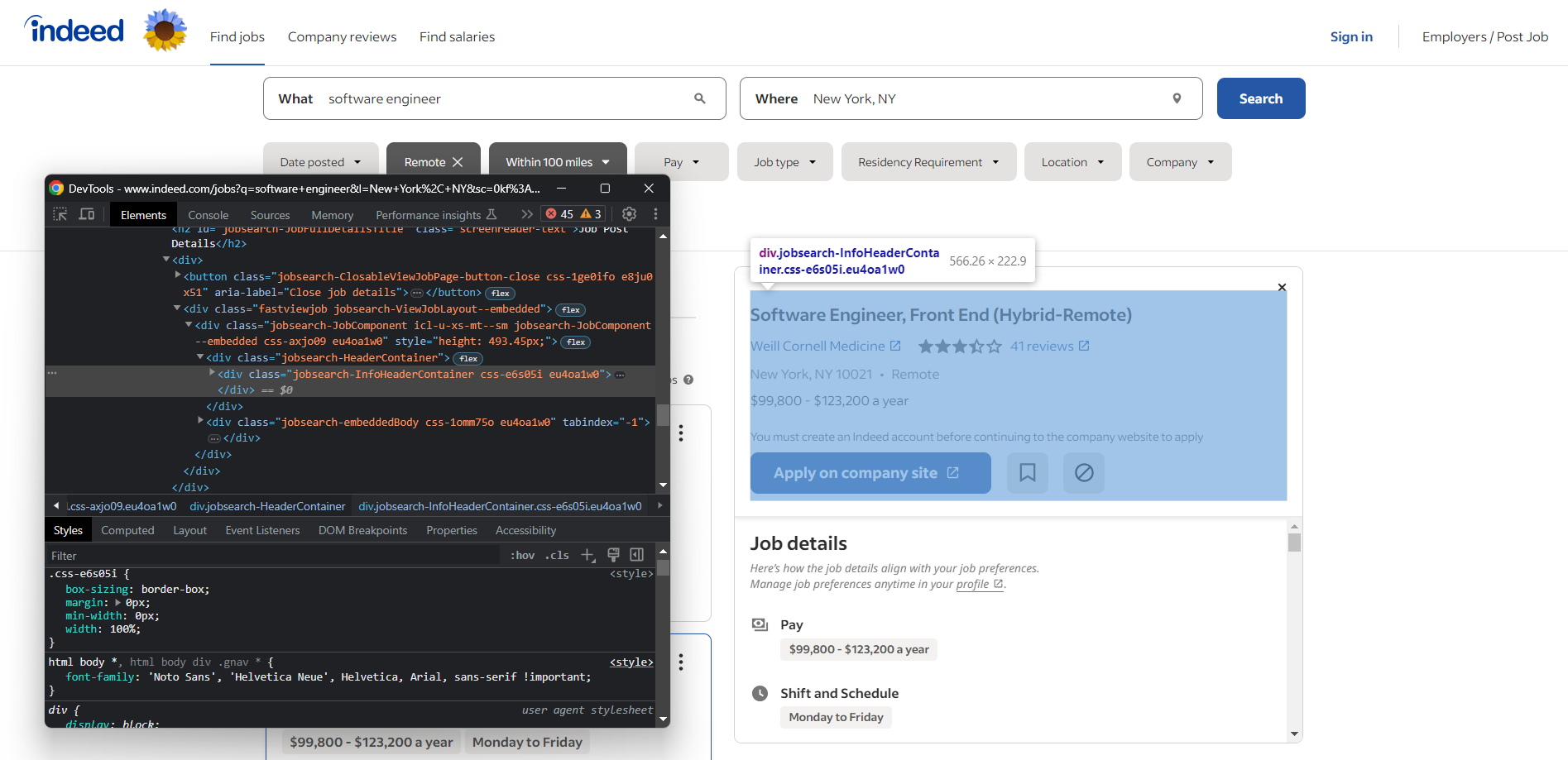
Aquí verás que la mayoría de los elementos que contienen datos interesantes tienen clases CSS como las siguientes:
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
Dado que parecen generarse aleatoriamente en el momento de la compilación, no debes basarte en ellas para el scraping. En su lugar, debes basar la lógica de selección en clases como:
jobsearch-JobInfoHeader-titledatecardOutline
O ID como:
companyRatingsapplyButtonLinkContainerjobDetailsSection
Además, tenga en cuenta que algunos nodos tienen atributos HTML únicos:
data-company-namedata-testid
Es información útil que hay que tener en cuenta para los trabajos de Scraping web de Indeed. Interactúa con la página para estudiar cómo reacciona y qué datos muestra. Te darás cuenta de que las diferentes ofertas de empleo tienen diferentes atributos de información.
Siga inspeccionando el sitio de destino y familiarícese con su estructura DOM hasta que se sienta preparado para continuar.
Paso 5: Comience a extraer los datos de los puestos de trabajo
Una sola página de búsqueda de Indeed incluye varias ofertas de empleo. Por lo tanto, necesitas una matriz para realizar un seguimiento de los empleos extraídos de la página:
jobs = []Como habrás observado en el paso anterior, las ofertas de empleo se muestran en tarjetas .cardOutline:
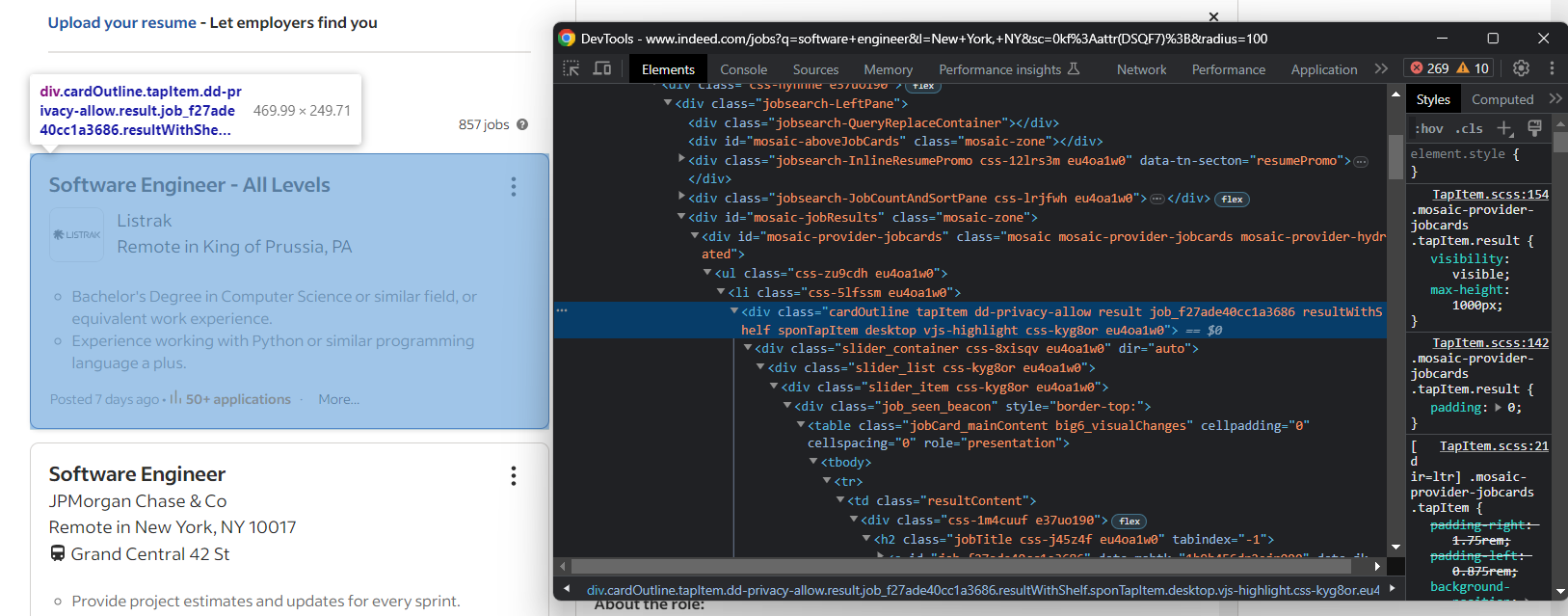
Selecciónalas todas con:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
El método find_elements() de Selenium te permite localizar elementos web en una página web. Del mismo modo, también existe el método find_element() para obtener el primer nodo que coincida con la consulta de selección.
By.CSS_SELECTOR indica al controlador que utilice una estrategia de selector CSS. Selenium también admite:
By.ID: para buscar un elemento por el atributo HTMLidBy.TAG_NAME: para buscar elementos basándose en su etiqueta HTMLBy.XPATH: para buscar elementos mediante una expresión XPath
Importar By con:
from selenium.webdriver.common.by import By
Iterar sobre la lista de tarjetas de trabajo e inicializar un diccionario Python donde almacenar los detalles del trabajo:
for job_card in job_cards:
# inicializar un diccionario para almacenar los datos de trabajo extraídos
job = {}
# lógica de extracción de datos de trabajo...
Una oferta de trabajo puede tener varios atributos. Dado que solo una pequeña parte de ellos son obligatorios, inicializa inmediatamente una lista de variables con valores predeterminados:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
Ahora que ya estás familiarizado con la página, sabes que algunos detalles se encuentran en la ficha de trabajo general. Otros, en cambio, se encuentran en la pestaña de detalles que aparece al interactuar.
Por ejemplo, la fecha de creación y el número de solicitudes se encuentran en la pestaña de resumen:
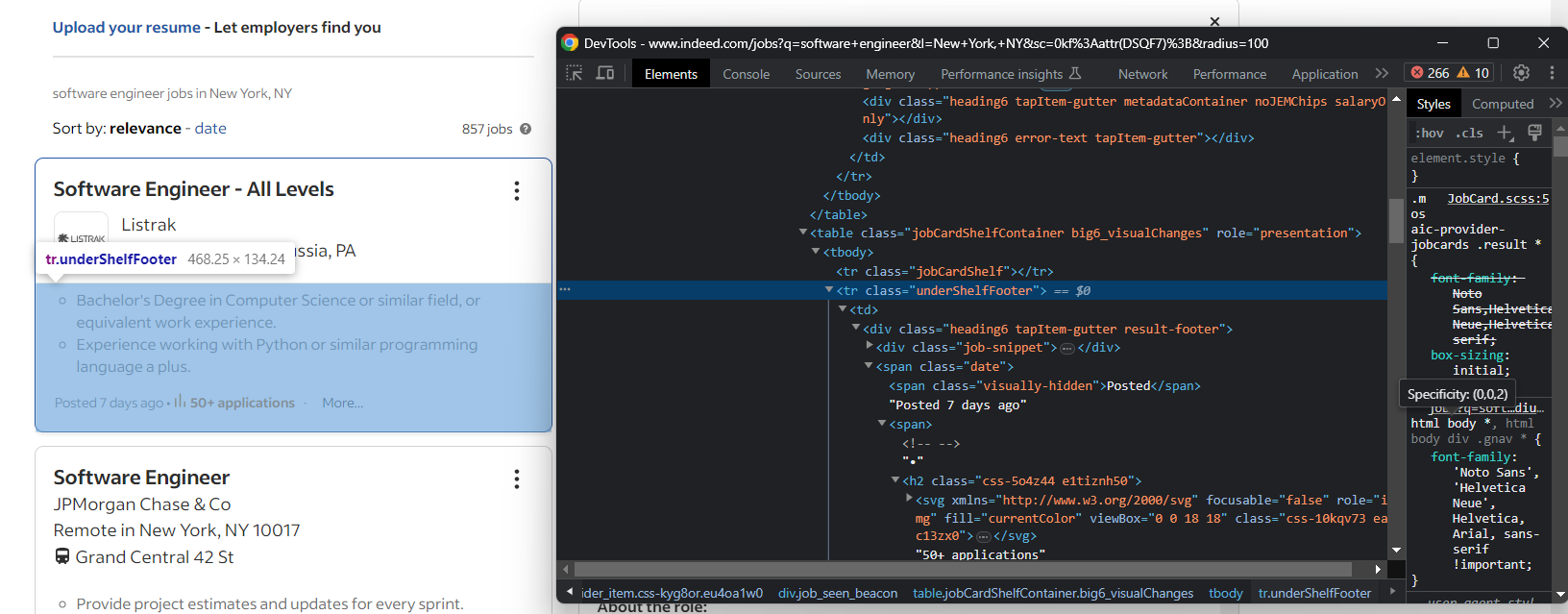
Extraiga ambos con:
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
Este fragmento destaca algunos patrones que son clave para el Scraping web de ofertas de empleo de Indeed. Como la mayoría de los elementos de información son opcionales, debes protegerte contra el siguiente error:
selenium.common.exceptions.NoSuchElementException: Mensaje: no existe tal elemento
Selenium lo lanza cuando intenta seleccionar un elemento HTML que no se encuentra actualmente en la página.
Importa la excepción con:
from selenium.common import NoSuchElementException
La instrucción try ... catch garantiza que, si el elemento de destino no se encuentra en el DOM, el script continuará sin fallos.
Además, parte de la información del trabajo se encuentra en cadenas como:
<info_1> • <info_2>
Si falta <info_2>, el formato de la cadena es, en su lugar:
<info_1>
Por lo tanto, es necesario cambiar la lógica de extracción de datos en función de la presencia del carácter «``•``».
Dado un elemento HTML, puede acceder a su contenido de texto con el atributo text. Utilice las cadenas replace() de Python para limpiar las cadenas recopiladas.
Paso 6: Lidiar con las medidas antiscraping de Indeed
Indeed adopta algunas técnicas y tecnologías para evitar que los bots accedan a sus datos. Por ejemplo, al interactuar con las tarjetas de empleo, tiende a abrir este modal de vez en cuando:
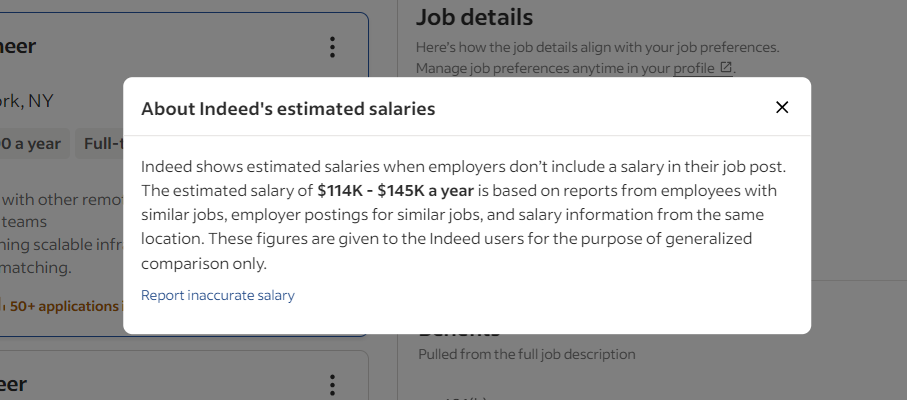
Esta ventana emergente bloquea la interacción. Si no se aborda adecuadamente, detendrá su script Selenium Indeed. Inspecciónelo en DevTools y preste atención al botón de cierre:
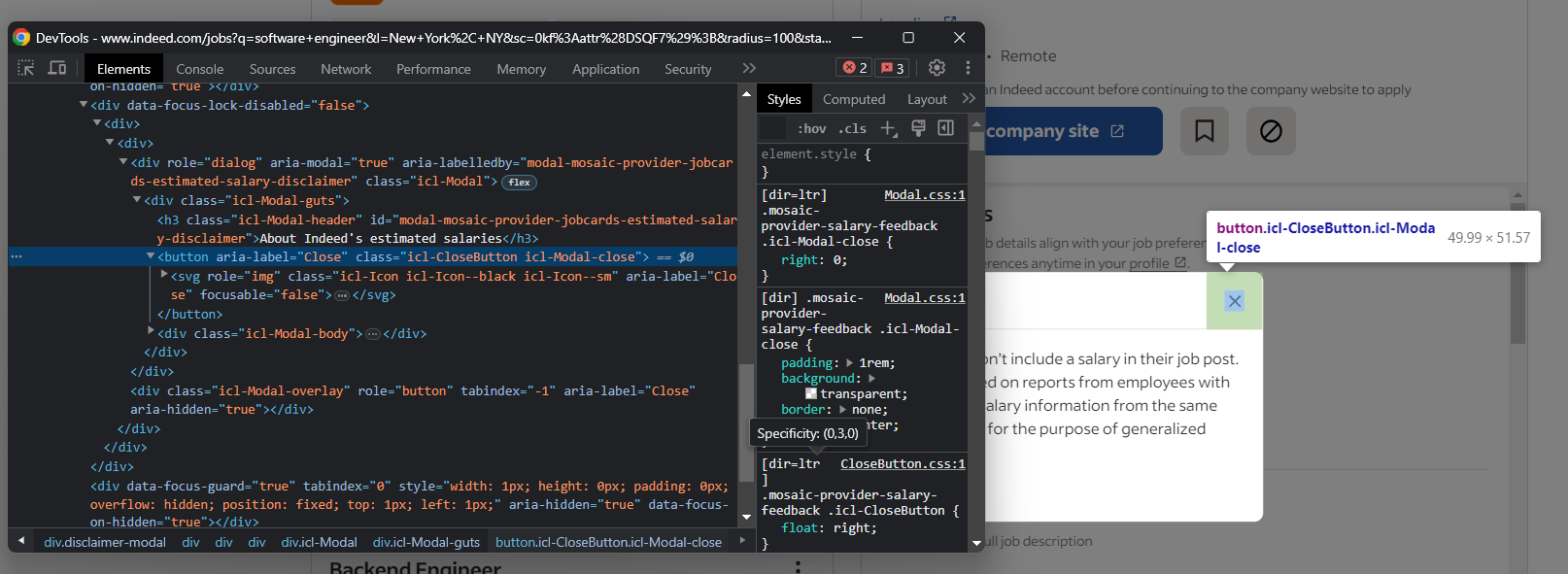
Cierre este modal en Selenium con:
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
El método click() de Selenium te permite hacer clic en el elemento seleccionado en el navegador controlado.
¡Genial! Esto cerrará la ventana emergente y le permitirá continuar con la interacción.
Otra técnica de protección de datos que hay que tener muy en cuenta es Cloudflare. Cuando se interactúa demasiado con la página y se producen demasiadas solicitudes, Indeed muestra esta pantalla antibots:
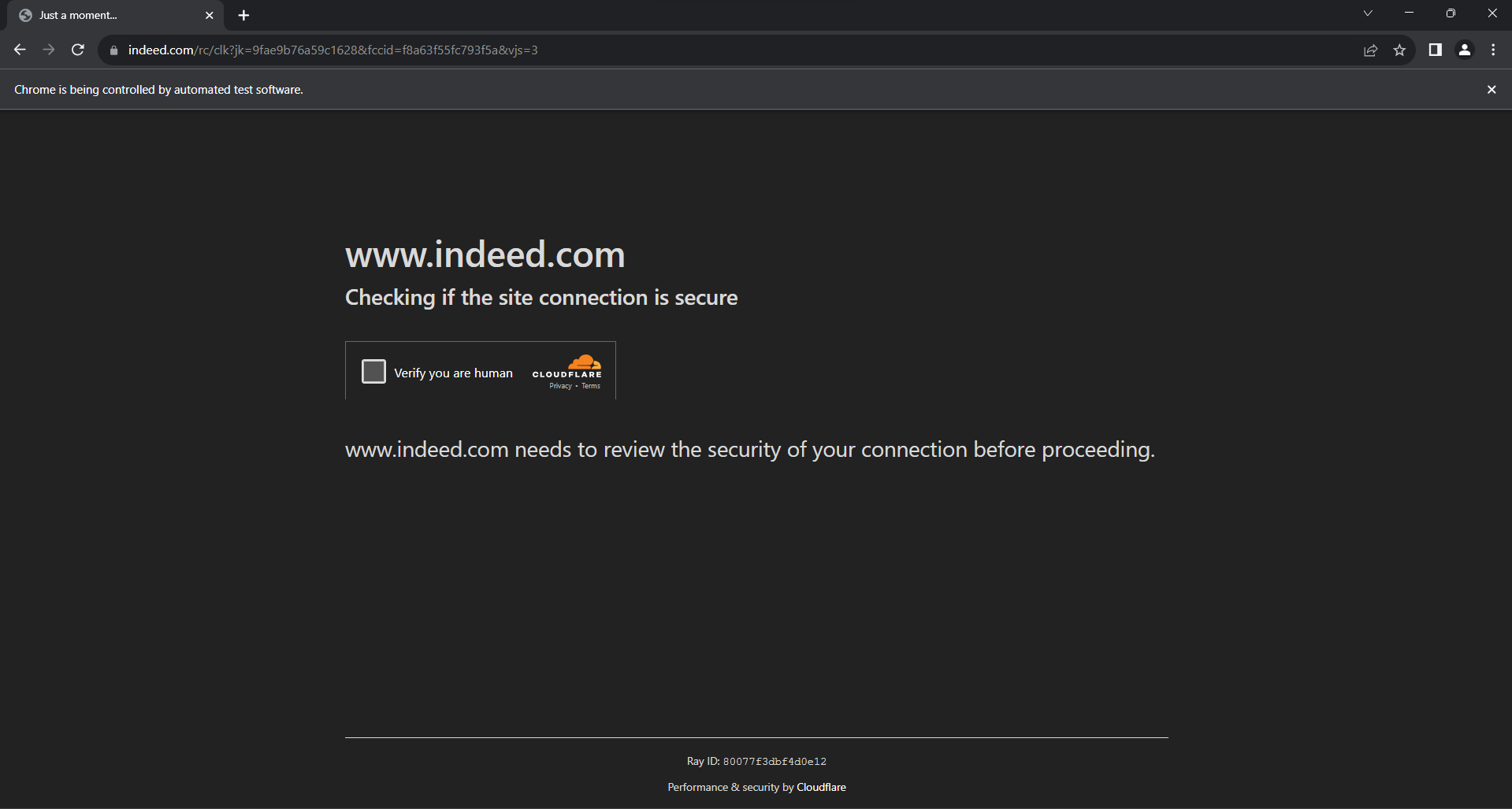
La resolución de CAPTCHA de Cloudflare desde Selenium es una tarea muy difícil que requiere un producto premium. Al fin y al cabo, extraer datos de Indeed no es tan fácil. Afortunadamente, puedes evitarlos introduciendo algunos retrasos aleatorios en tu script.
Asegúrate de que la última operación de tu bucle «for» sea:
time.sleep(random.uniform(1, 5))
Esto detendrá el script durante un número aleatorio de segundos, de 1 a 5.
Importa los paquetes necesarios de la biblioteca estándar de Python con:
import random
import time
¡Muy bien! Nada impedirá que tu script automatizado extraiga datos de Indeed.
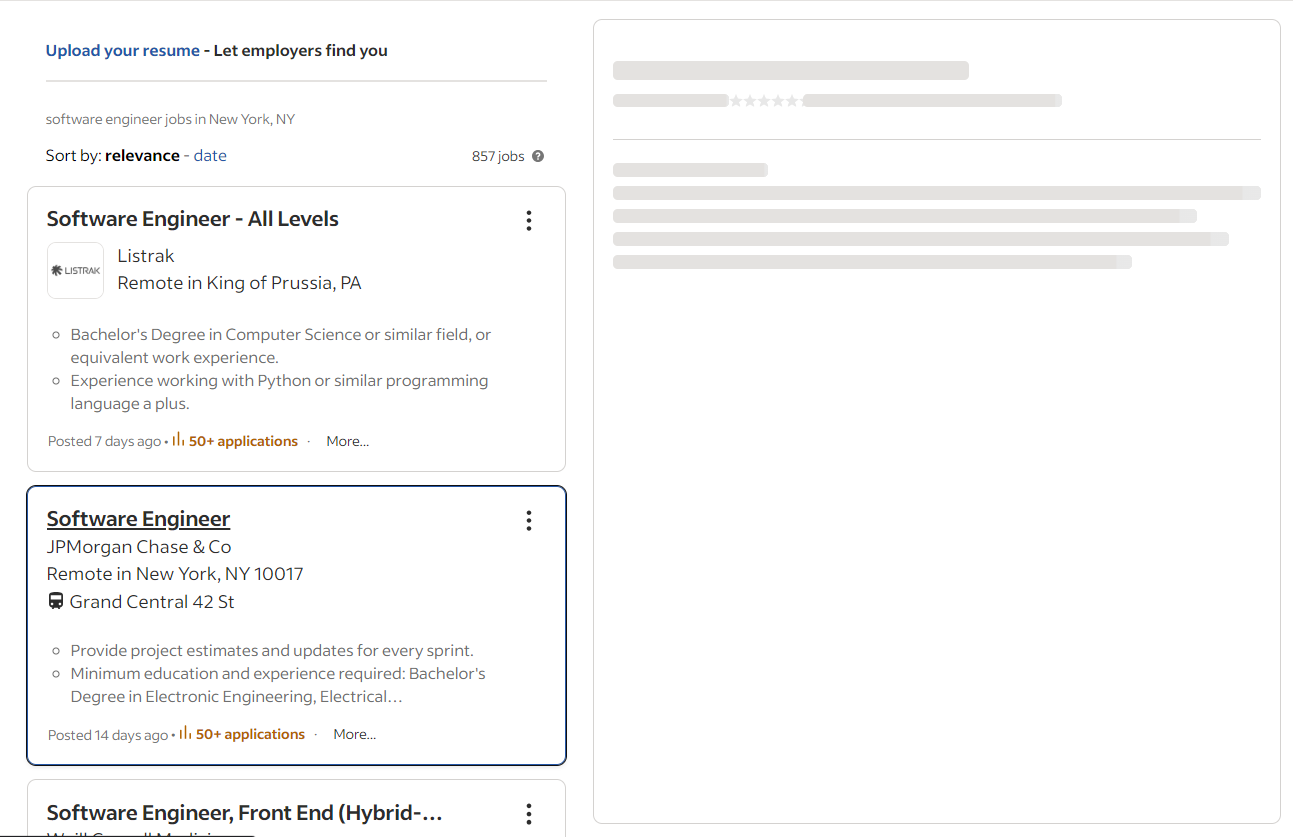
Paso 7: Abre la ficha de detalles del puesto
Cuando haces clic en una tarjeta de resumen de trabajo, Indeed realiza una llamada AJAX para recuperar los detalles sobre la marcha. Mientras se esperan estos datos, la página muestra un marcador de posición animado:
Puedes verificar que las secciones de detalles se han cargado cuando el elemento siguiente aparece en la página:
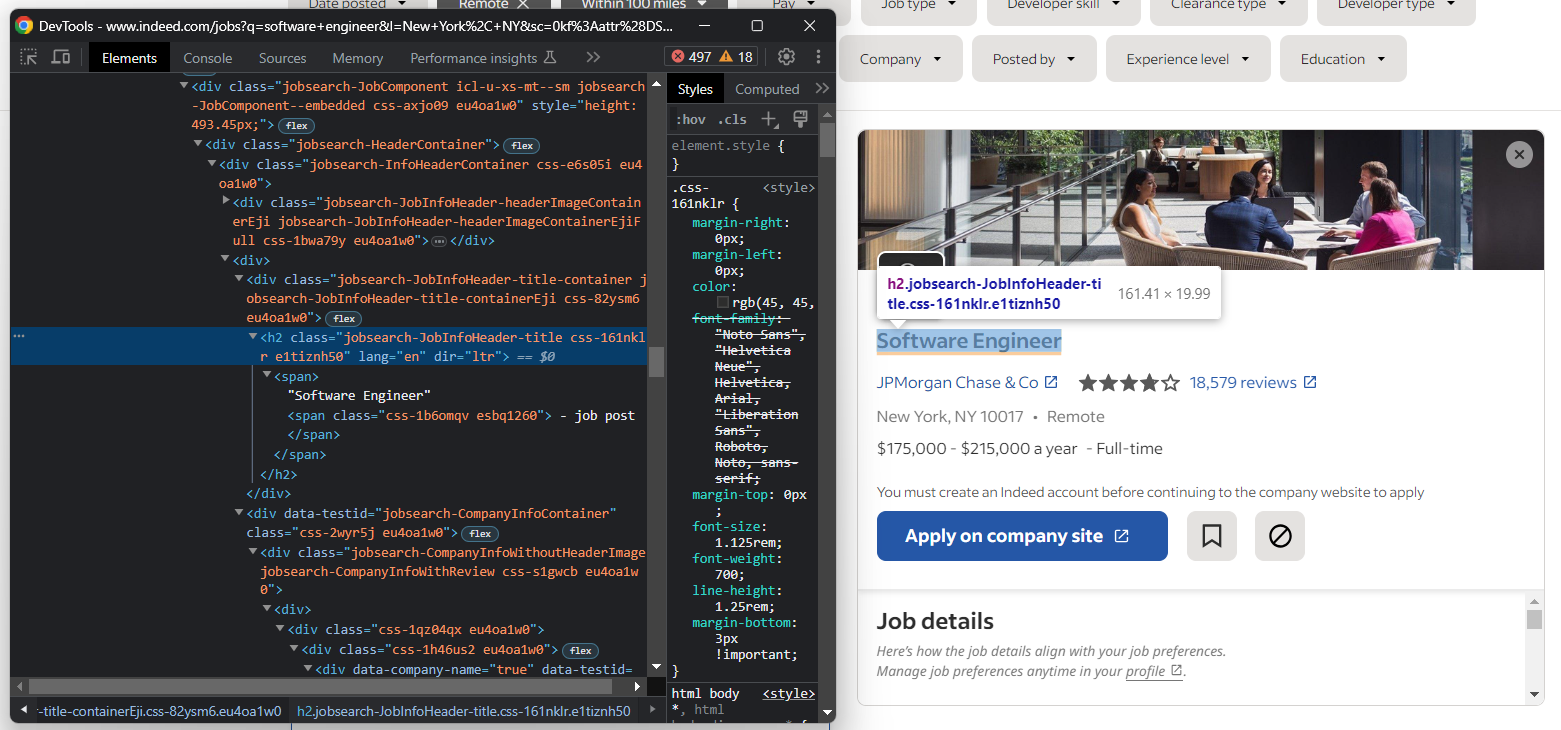
Por lo tanto, para acceder a los datos de los detalles del puesto de trabajo en Selenium, debes:
- Realizar la operación de clic
- Esperar a que la página contenga los datos de interés
Consíguelo con:
job_card.click()
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
El objeto WebDriverWait de Selenium te permite esperar a que se produzca una condición específica. En este caso, el script espera hasta 5 segundos a que .jobsearch-JobInfoHeader-title aparezca en la página. Después de eso, lanzará una excepción TimeoutException.
Tenga en cuenta que el fragmento anterior también recupera el título de la oferta de empleo.
Importa WebDriverWait y EC:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
A partir de ahora, el elemento en el que hay que centrarse es esta columna de detalles:
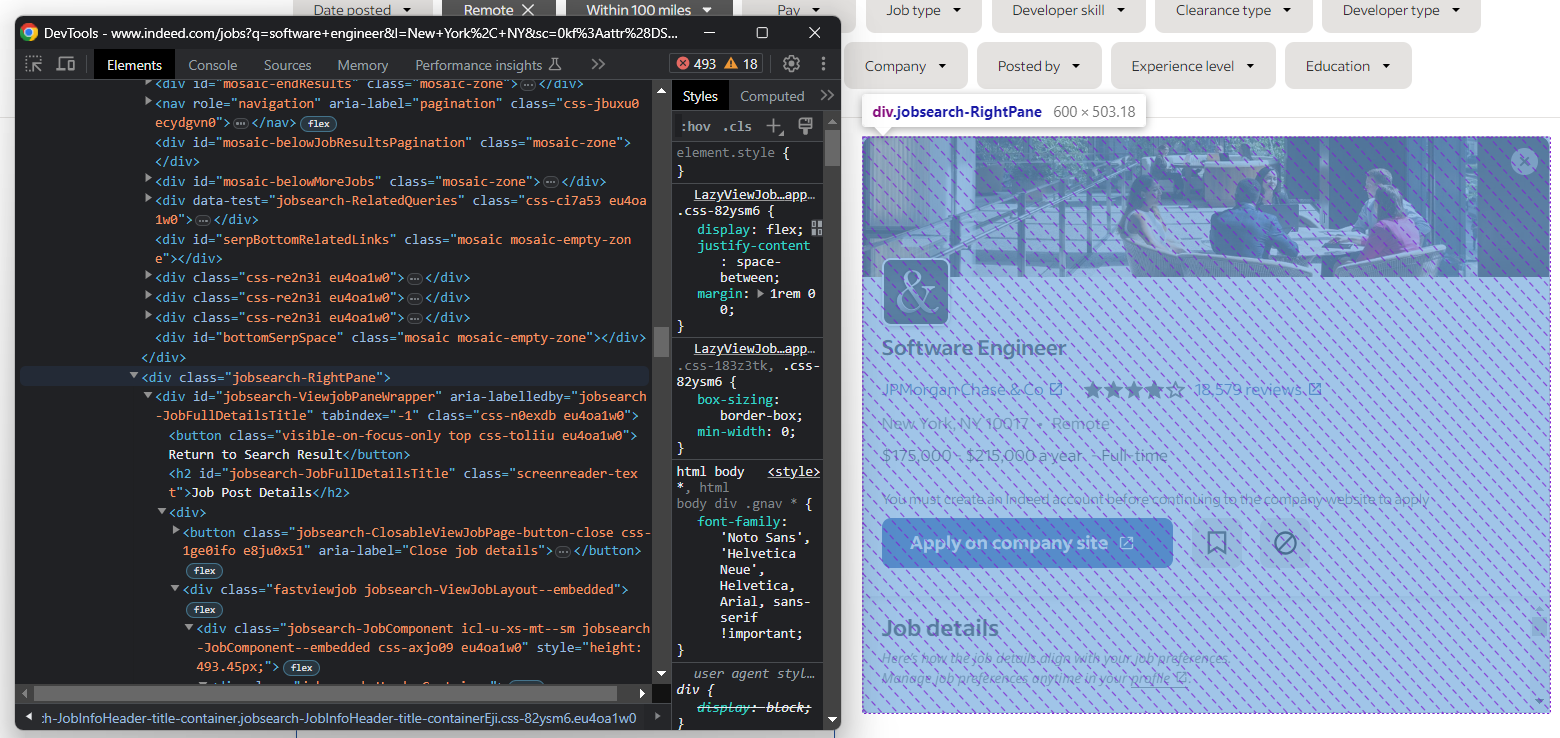
Selecciónelo con:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
¡Fantástico! ¡Ya está todo listo para extraer algunos datos de empleo!
Paso 8: Extraer los detalles del trabajo
Es hora de rellenar las variables que definimos en el paso 4 con algunos datos de empleo.
Obtenga el nombre de la empresa que ofrece la vacante:
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
A continuación, extrae la información sobre las valoraciones de los usuarios y el número de reseñas de la empresa:
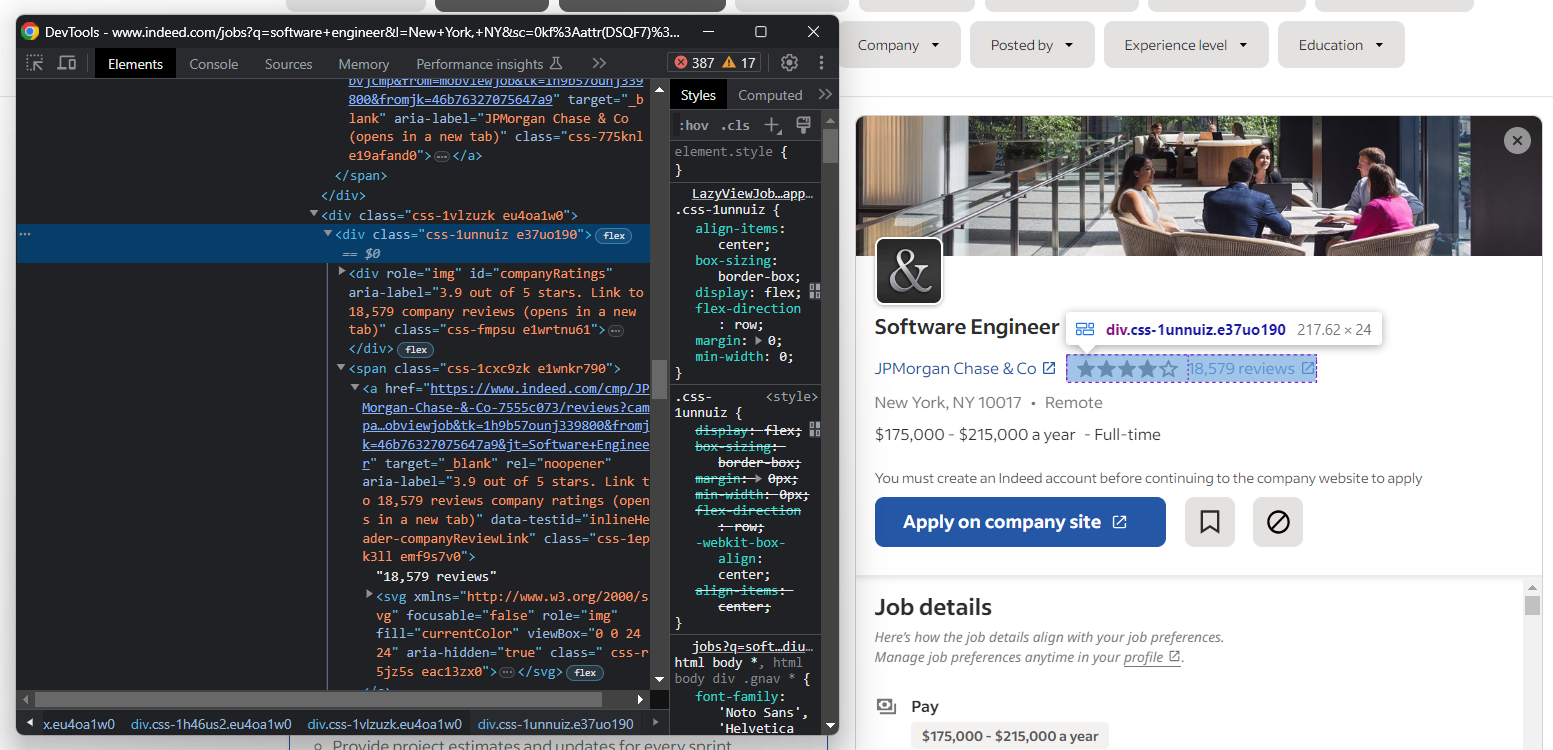
Como puede ver, no hay una forma fácil de acceder al elemento que almacena el número de reseñas.
intentar:
elemento_calificación_empresa = elemento_detalles_empleo.find_element(By.ID, "companyRatings")
calificación_empresa = elemento_calificación_empresa.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
A continuación, céntrate en la ubicación de la empresa:
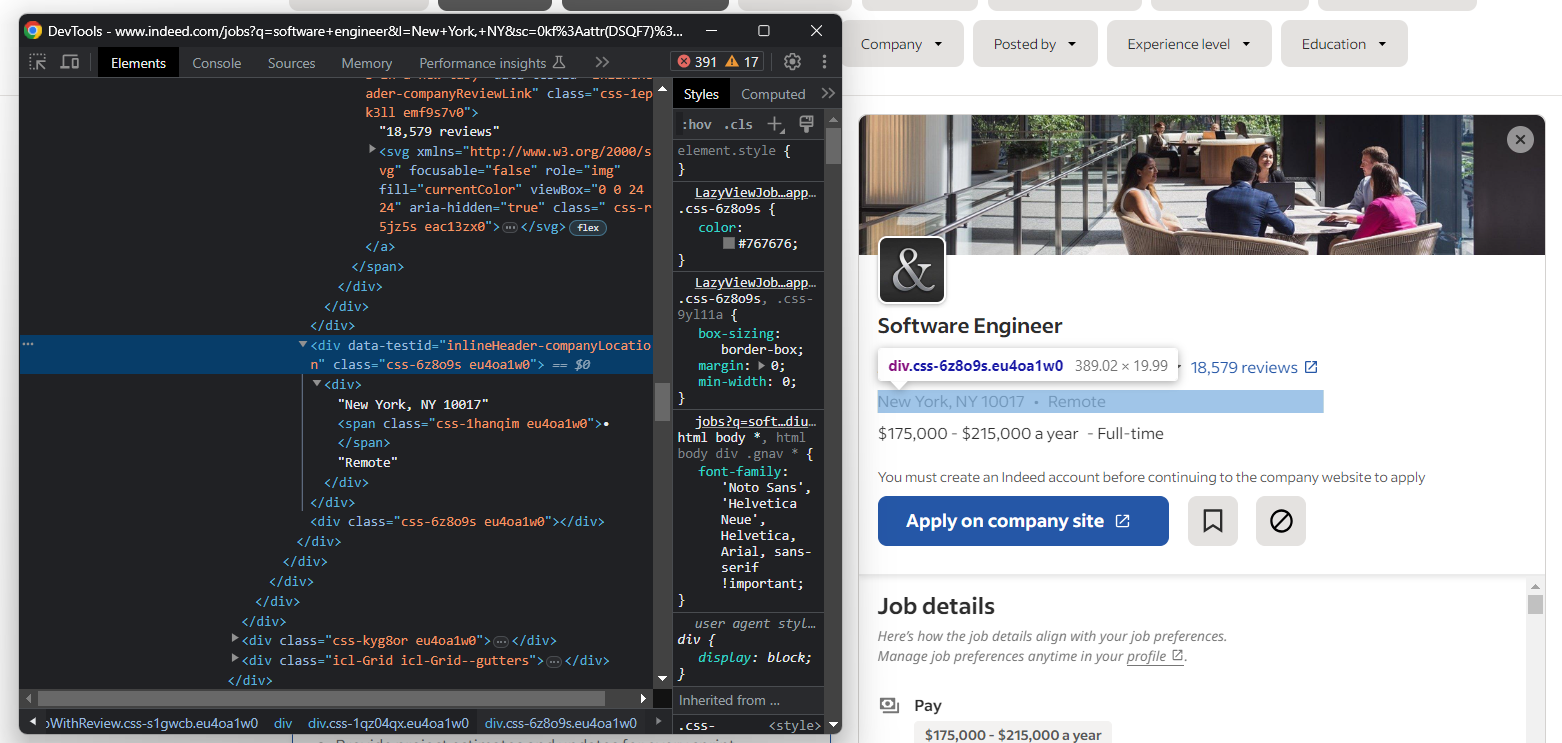
De nuevo, debes aplicar el patrón «``•``» mencionado en el paso 4:
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
Como es posible que desee solicitar rápidamente el puesto de trabajo, eche un vistazo también al botón «Solicitar en el sitio web de la empresa» de Indeed:
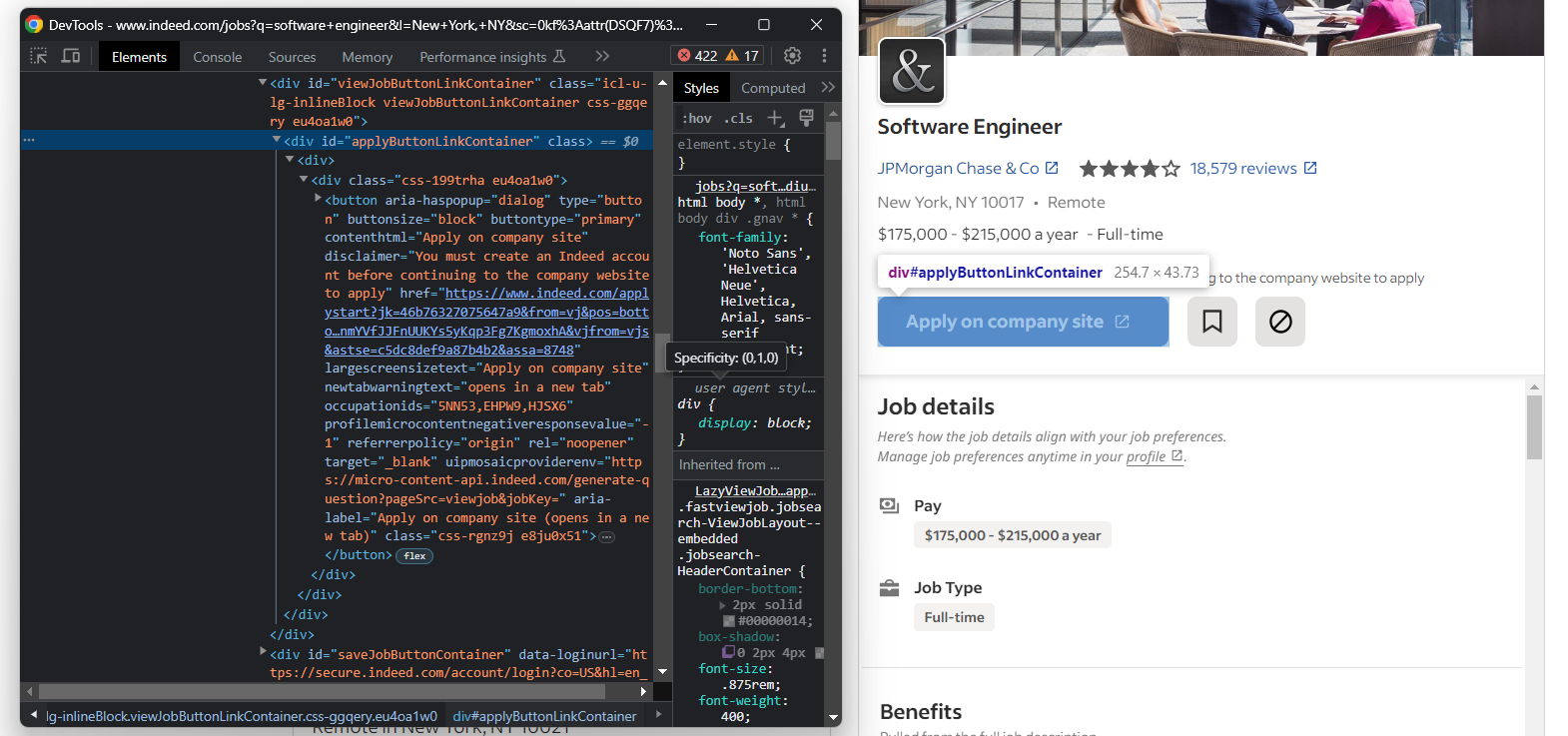
Recupera la URL de destino del botón con:
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
La función get_attribute() de Selenium devuelve el valor del atributo HTML especificado.
Ahora comienza la parte complicada.
Si inspeccionas la sección «Detalles del trabajo», notarás que no hay una forma fácil de seleccionar los elementos de salario y tipo de trabajo:
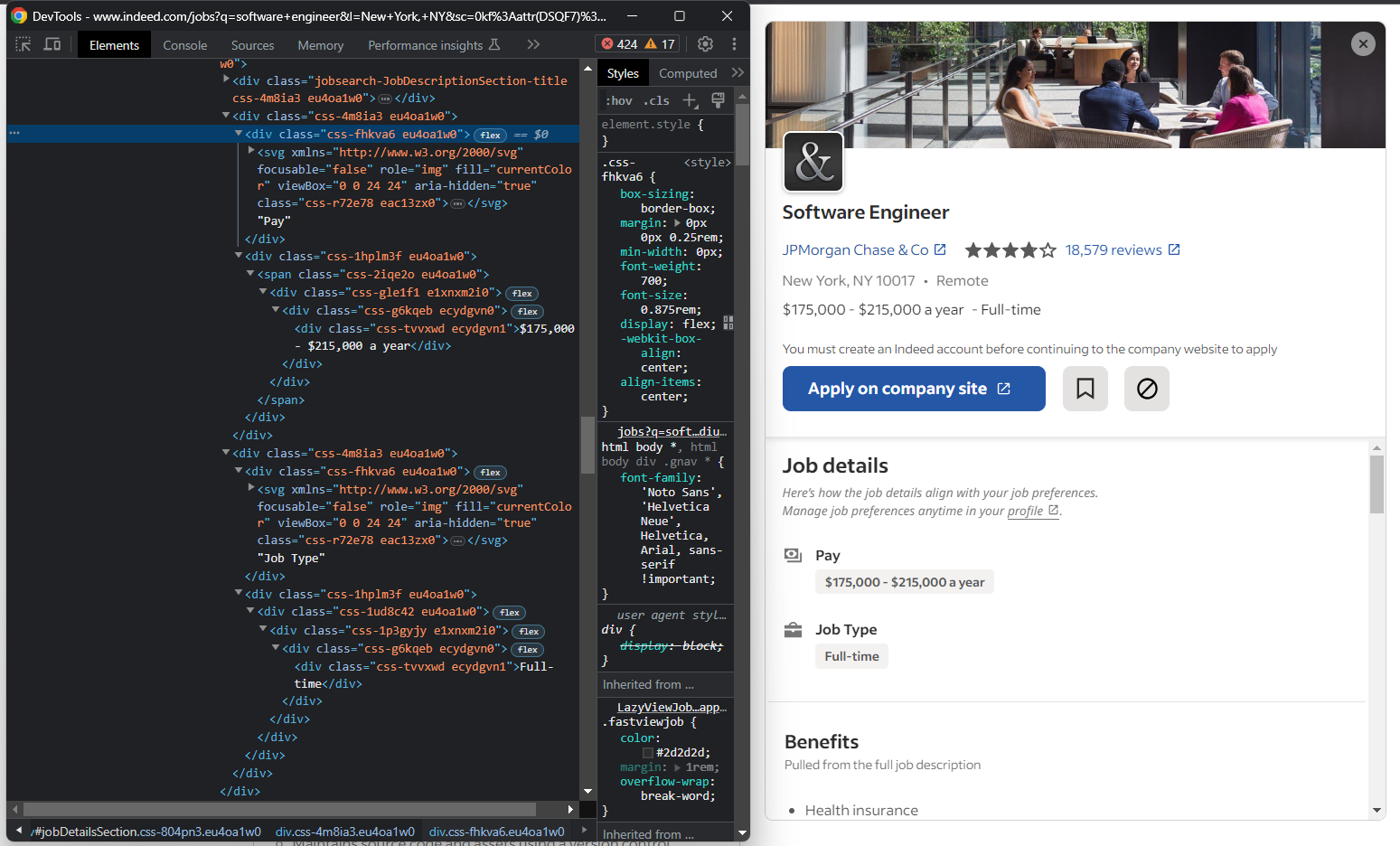
Lo que puedes hacer es:
- Obtener todos los
<div>dentro del<div>«Detalles del trabajo» - Iterar sobre ellos
- Si el texto del
<div>actual contiene «Salario» o «Tipo de trabajo», obtener el siguiente elemento hermano - Extraer los datos de interés
En otras palabras, tienes que implementar la siguiente lógica:
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
Selenium no proporciona un método de utilidad para acceder a los hermanos de un nodo. Lo que puedes hacer en su lugar es utilizar la expresión Xpath following-sibling::*.
Ahora, céntrate en las prestaciones del trabajo. Normalmente, hay más de una:
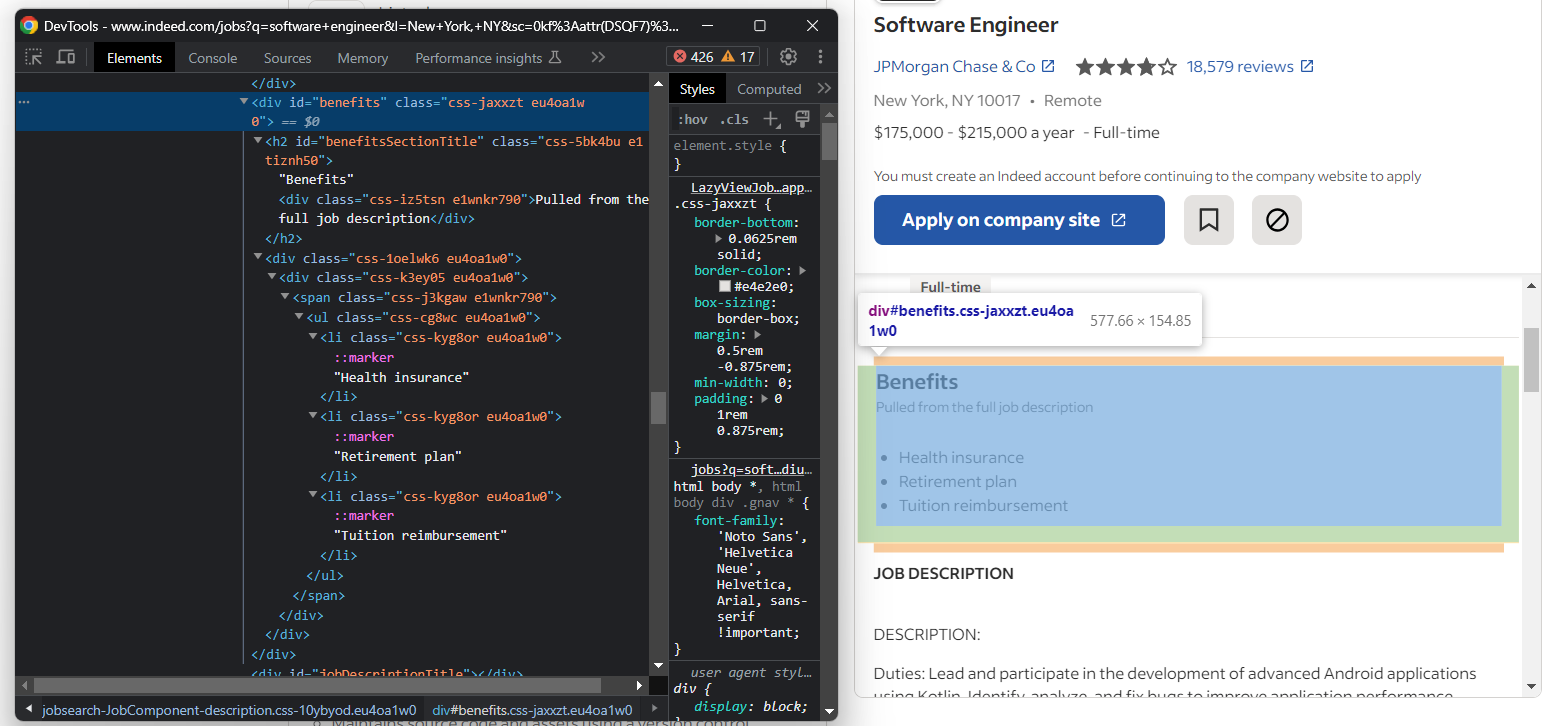
Para recuperarlos todos, debes inicializar una lista y rellenarla con:
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
Por último, obtenga la descripción del puesto sin formato:
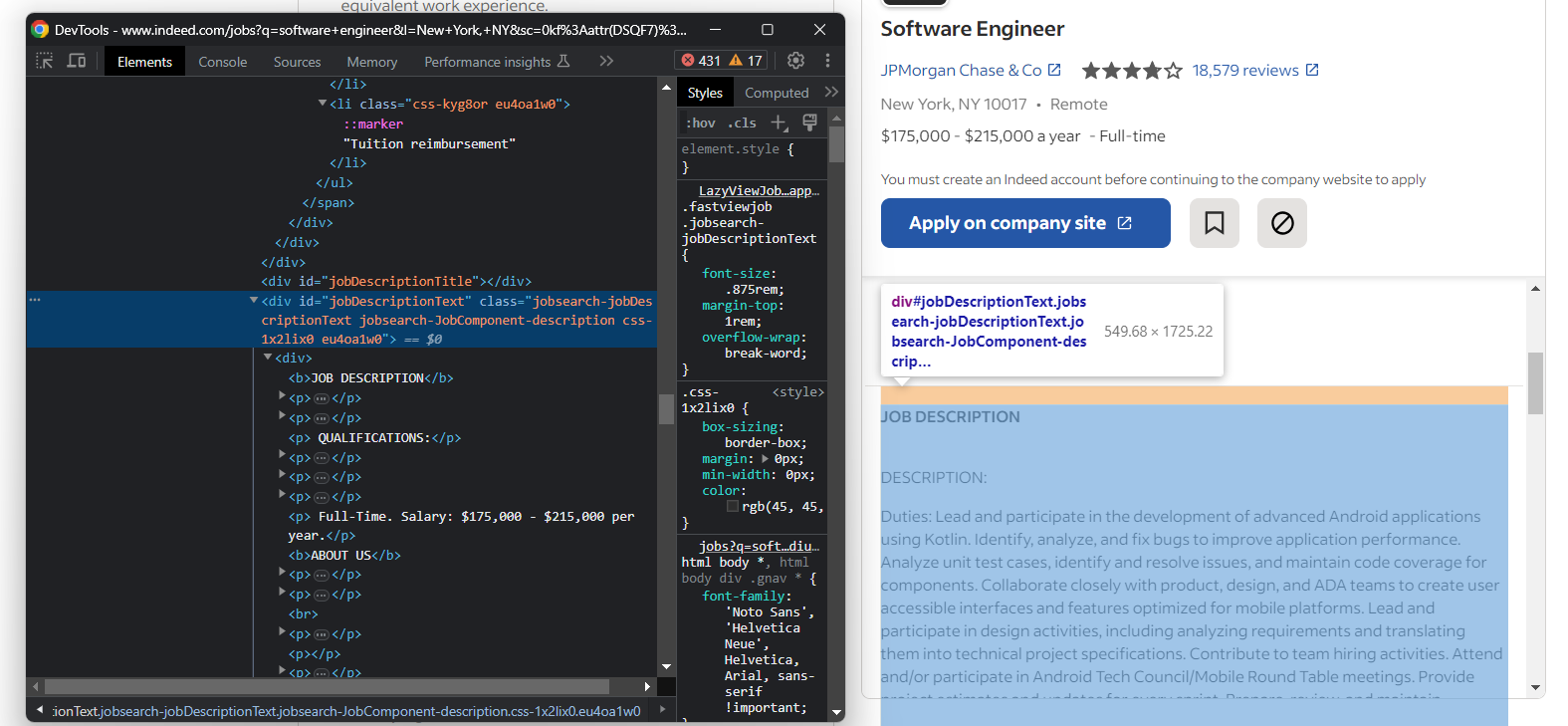
Extraiga el texto de la descripción con:
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
Rellene el diccionario de empleos y añádalo a la lista de empleos:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
También puede añadir una instrucción de registro para verificar que el script funciona según lo esperado:
print(job)
Ejecute el script:
python Scraper.py
Esto producirá un resultado similar al siguiente:
{'posted_at': '17 days ago', 'applications': '50+', 'title': 'Software Support Engineer', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3.5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'tipo_ubicación': 'Remoto', 'enlace_solicitud': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '80 000-100 000 $ al año', 'job_type': 'A tiempo completo', 'benefits': ['401(k)', '401(k) matching', 'Seguro dental', 'Seguro médico', 'Permiso parental remunerado', 'Permiso remunerado', 'Permiso parental', 'Seguro oftalmológico'], 'description': «Integrated DNA Technologies (IDT) es el fabricante líder de oligonucleótidos personalizados y tecnologías patentadas para (omitido por brevedad...)»}
¡Et voilà! Acabas de aprender a extraer ofertas de empleo de sitios web.
Paso 9: Extrae varias páginas de ofertas de empleo
Una búsqueda de empleo típica en Indeed produce una lista paginada con docenas de resultados. ¡Vimos cómo extraer cada página!
En primer lugar, inspecciona una página y toma nota de cómo se comporta Indeed. En concreto, muestra el siguiente elemento cuando hay una página siguiente disponible.
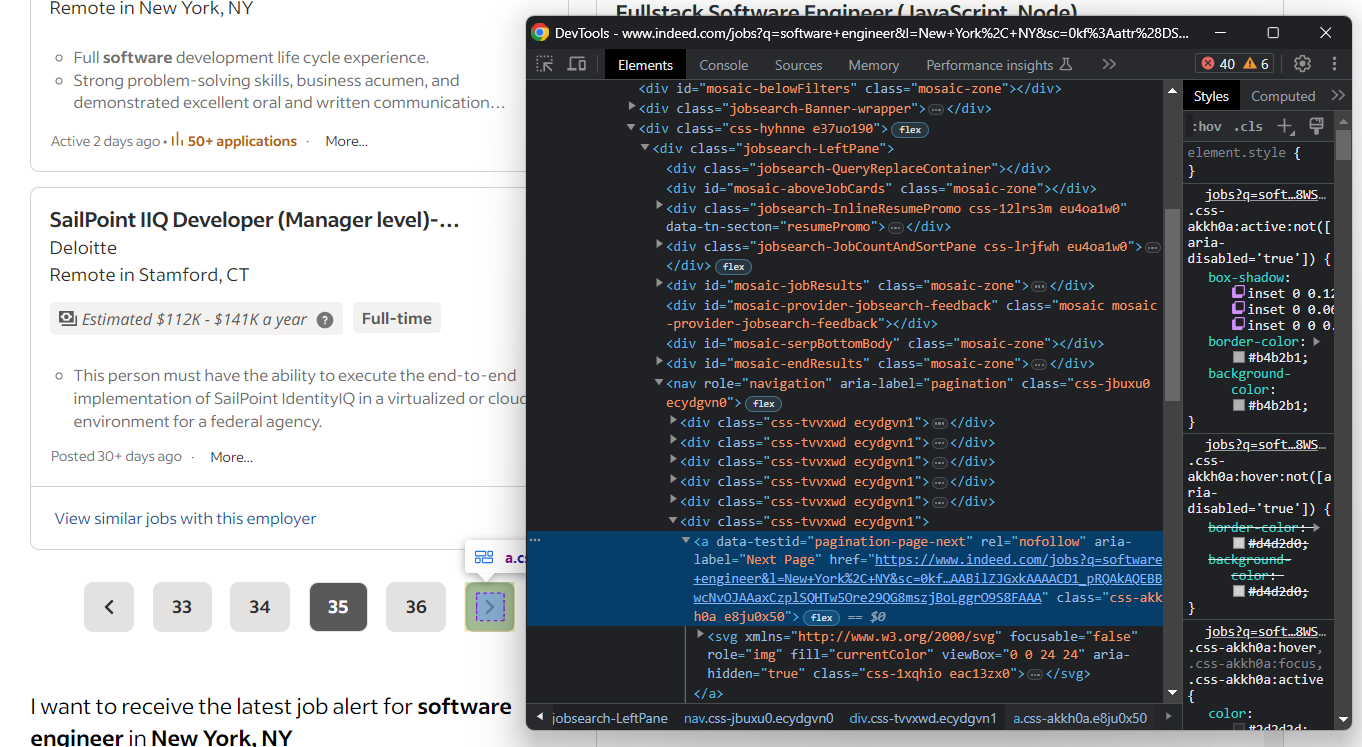
De lo contrario, falta el elemento de la página siguiente:
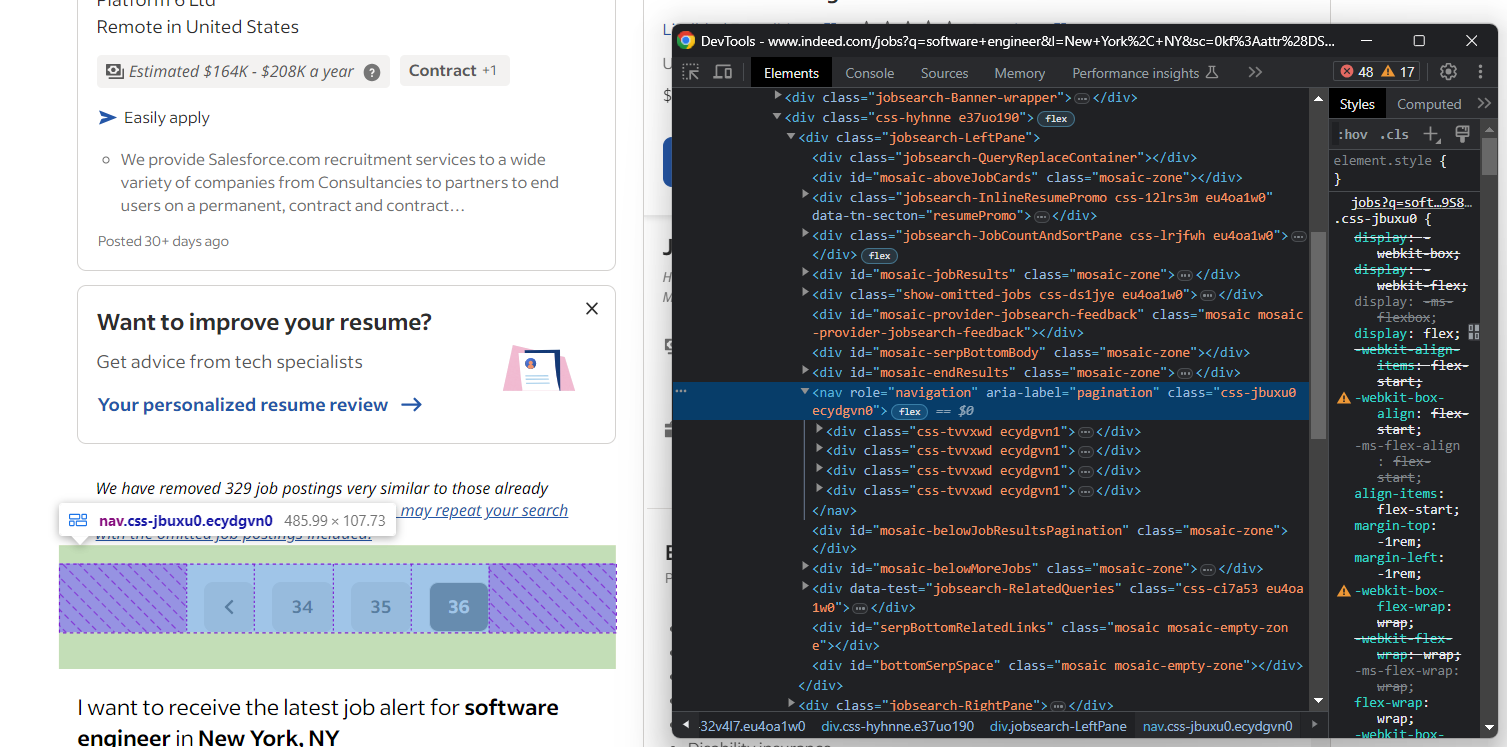
Ten en cuenta que Indeed puede devolver una lista con cientos de ofertas de empleo. Como no quieres que tu script se ejecute indefinidamente, considera la posibilidad de añadir un límite al número de páginas extraídas.
Implementa el rastreo web en Indeed en Selenium con:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# scraping logic...
pages_scraped += 1
# si esta no es la última página, pasa a la siguiente página
# de lo contrario, rompe el bucle while
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
El Scraper de Indeed seguirá repitiendo el bucle hasta llegar a la última página o recorrer 5 páginas.
Paso 10: Exportar los datos extraídos a JSON
En este momento, los datos extraídos se almacenan en una lista de diccionarios Python. Exportarlos a JSON para facilitar su intercambio y lectura.
En primer lugar, crea un objeto de salida:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
El atributo de fecha es necesario porque las fechas de publicación de las ofertas de empleo están en el formato «hace <X> días». Sin algún contexto sobre el día en que se extrajeron los datos de los empleos, sería difícil entenderlos.
Recuerde importar datetime:
from datetime import datetime
A continuación, expórtalo con:
import json
# lógica de recopilación...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
El fragmento anterior inicializa un archivo de salida jobs.json con open() y lo rellena con datos JSON a través de json.dump(). Consulte nuestro artículo para obtener más información sobre cómo realizar el parseo y la serialización de datos a JSON en Python.
El paquete json proviene de la biblioteca estándar de Python, por lo que ni siquiera necesitas instalar una dependencia adicional para lograr el objetivo.
¡Vaya! Has partido de datos de empleo sin procesar contenidos en una página web y ahora tienes datos JSON semiestructurados. Ya estás listo para echar un vistazo al script completo de Indeed Python para el Scraping web.
Paso 11: Ponlo todo junto
Aquí está el archivo scraper.py completo:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# configurar una instancia controlable de Chrome
# en modo sin interfaz gráfica
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# abrir la página de destino en el navegador
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# establecer el tamaño de la ventana para asegurarse de que las páginas
# no se rendericen en modo responsivo
driver.set_window_size(1920, 1080)
# una estructura de datos donde almacenar las ofertas de empleo
# extraídas de la página
jobs = []
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# selecciona las tarjetas de ofertas de empleo de la página
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# inicializa un diccionario para almacenar los datos de empleo extraídos
job = {}
# inicializar los atributos del trabajo para recopilar
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# obtener los datos generales del empleo de la tarjeta de resumen
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("en curso", "")
.strip()
posted_at = posted_at_text
.replace("Publicado", "")
.replace("Empleador", "")
.replace("Activo", "")
.strip()
excepto NoSuchElementException:
pasar
# cerrar el modal anti-scraping
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# cargar la tarjeta de detalles del trabajo
job_card.click()
# esperar a que se cargue la sección de detalles del trabajo después del clic
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
# extraer los detalles del trabajo
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
elemento_enlace_empresa = elemento_detalles_empleo.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
nombre_empresa = elemento_enlace_empresa.text
excepto NoSuchElementException:
pasar
intentar:
elemento_calificación_empresa = elemento_detalles_empleo.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
excepto NoSuchElementException:
pasar
intentar:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
tipo_ubicación = empresa_ubicación_elemento_texto_matriz[1]
excepto NoSuchElementException:
pasar
intentar:
aplicar_enlace_elemento = detalles_trabajo_elemento.encontrar_elemento(By.CSS_SELECTOR, "#applyButtonLinkContainer botón")
aplicar_enlace = aplicar_enlace_elemento.obtener_atributo("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
descripción = description_element.text
except NoSuchElementException:
pass
# almacenar los datos extraídos
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# esperar un número aleatorio de segundos entre 1 y 5
# para evitar bloqueos por limitación de velocidad
time.sleep(random.uniform(1, 5))
# incrementar el contador de scraping
pages_scraped += 1
# si no es la última página, ir a la siguiente
# de lo contrario, romper el bucle while
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# cerrar el navegador y liberar los recursos
driver.quit()
# produce el objeto de salida
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# expórtalo a JSON
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
En menos de 200 líneas de código, acabas de crear un Scraper web con todas las funciones para extraer datos de empleos de Indeed.
Ejecútalo con:
python Scraper.py
Espera unos minutos a que el script se complete
Al final del proceso de rastreo, aparecerá un archivo jobs.json en la carpeta raíz de tu proyecto. Ábrelo y verás:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 days ago",
"applications": "50+",
"title": "Ingeniero de software - Todos los niveles",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remoto",
"apply_link": "https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"Gym membership",
"Paid time off"
],
"description": "Acerca de Listrak: Somos una empresa de SaaS que ofrece una plataforma integrada de marketing digital en la que confían más de 1000 minoristas y marcas líderes para el marketing por correo electrónico y mensajes de texto, la resolución de identidades, los desencadenantes de comportamiento y la coordinación entre canales. Nuestra sede se encuentra en (omitido por brevedad...)"
},
// omitido por brevedad...
{
«posted_at»: «Hace 9 días»,
«applications»: null,
«title»: «Ingeniero de software, Front End (híbrido-remoto)»,
«company_name»: «Weill Cornell Medicine»,
«company_rating»: «3,4»,
"company_reviews": "41",
"location": "Nueva York, NY 10021",
"location_type": "Remoto",
"apply_link": "https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
«salario»: «99 800 $ - 123 200 $ al año»,
«tipo de empleo»: nulo,
«beneficios»: nulo,
«descripción»: «Título: Ingeniero de software, Front End (híbrido-remoto)nTítulo: Ingeniero de software, Front End (híbrido-remoto)nUbicación: Upper East SidenUnidad organizativa: Olivier Elemento LabnDías laborables: de lunes a viernesnEstatus de exención: exentonRango salarial: 99 800,00 $ - 123 200,00 $nAs (omitido por brevedad...)"
}
}
¡Enhorabuena! ¡Acabas de aprender a extraer datos de Indeed con Python!
Conclusión
En este tutorial, has comprendido por qué Indeed es uno de los mejores portales de empleo de la web y cómo extraer datos de él. En concreto, has visto cómo crear un Scraper en Python que puede recuperar datos de ofertas de empleo de este portal.
Como se muestra aquí, extraer datos de Indeed no es una tarea fácil. El sitio cuenta con una protección anti-scraping que podría bloquear tu script. Cuando se trata de sitios de este tipo, necesitas un navegador controlable que sea capaz de gestionar automáticamente CAPTCHAs, huellas digitales, reintentos automáticos y mucho más. ¡Esto es exactamente lo que ofrece nuestro nuevo Navegador de scraping!
¿No quieres lidiar con el Scraping web, pero te interesan los datos sobre empleos? Explora nuestros conjuntos de datos de Indeed y nuestro conjunto de datos de ofertas de empleo. Regístrate ahora y comienza tu prueba gratuita.
Nota: esta guía ha sido probada exhaustivamente por nuestro equipo en el momento de su redacción, pero dado que los sitios web actualizan con frecuencia su código y estructura, es posible que algunos pasos ya no funcionen como se esperaba.



