

En esta guía aprenderás:
- Qué es CloudScraper y para qué sirve
- Por qué debe integrar Proxies en Cloudscraper
- Cómo hacerlo en una guía paso a paso
- Cómo implementar la rotación de proxies en Cloudscraper
- Cómo gestionar proxies autenticados
- Cómo utilizar un proveedor de proxies premium como Bright Data
¡Empecemos!
¿Qué es CloudScraper?
CloudScraper es un módulo de Python diseñado para eludir la página antibots de Cloudflare (comúnmente conocida como«I’m Under Attack Mode» o IUAM). En realidad, se implementa utilizando Requests, uno de los clientes HTTP de Python más populares.
Esta biblioteca es especialmente útil para extraer o rastrear sitios web protegidos por Cloudflare. La página antibots verifica actualmente si el cliente es compatible con JavaScript, pero Cloudflare podría introducir técnicas adicionales en el futuro.
Dado que Cloudflare actualiza periódicamente sus soluciones antibots, la biblioteca se actualiza periódicamente para seguir siendo funcional.
¿Por qué utilizar Proxies con CloudScraper?
Cloudflare puede bloquear tu IP si realizas demasiadas solicitudes. Del mismo modo, podría activar defensas más sofisticadas que son difíciles de eludir incluso con herramientas como CloudScraper. Para mitigar esto, necesitas un método fiable para rotar tu dirección IP.
Aquí es donde entra en juego un servidor Proxy. Los proxies actúan como intermediarios entre su Scraper y el sitio web de destino, enmascarando su dirección IP real con la IP del servidor Proxy. Si se bloquea una IP, puede cambiar rápidamente a un nuevo Proxy, lo que garantiza un acceso ininterrumpido.
Los proxies ofrecen dos ventajas clave para el Scraping web con CloudScraper:
- Mayor seguridad y anonimato: al enrutar las solicitudes a través de un Proxy, su verdadera identidad permanece oculta, lo que reduce el riesgo de detección.
- Evitar bloqueos e interrupciones: los Proxy le permiten rotar las direcciones IP de forma dinámica, lo que le ayuda a eludir los bloqueos y los limitadores de velocidad.
Al combinar Proxies con herramientas como CloudScraper, puede crear una configuración de Scraping web robusta que minimiza los riesgos y maximiza la eficiencia. Este enfoque de doble capa garantiza una extracción de datos segura y fluida, incluso desde sitios con medidas avanzadas contra el scraping.
Configurar un Proxy con CloudScraper: guía paso a paso
¡Aprenda a utilizar Proxies con CloudScraper en esta sección guiada!
Paso n.º 1: Instalar CloudScraper
Puede instalar CloudScraper a través del paquete pip de CloudScraper utilizando este comando:
pip install -U cloudscraper
Tenga en cuenta que Cloudflare actualiza constantemente su motor antibots. Por lo tanto, incluya la opción -U al instalar el paquete para asegurarse de que obtiene la última versión.
Paso n.º 2: Inicializar Cloudscraper
Para empezar, primero importe CloudScraper:
import cloudscraper
A continuación, cree una instancia de CloudScraper utilizando el método create_scraper():
Scraper = cloudscraper.create_scraper()
El objeto Scraper funciona de manera similar al objeto Session de la biblioteca requests. En concreto, le permite realizar solicitudes HTTP sin pasar por las medidas antibots de Cloudflare.
Paso n.º 3: integrar un Proxy
Dado que CloudScraper se basa en Requests, la integración de Proxy funciona de la misma manera queen Requests. Si no está familiarizado con ese procedimiento, lea nuestro tutorial para configurar un Proxy en Requests.
Para utilizar un Proxy con CloudScraper, debe definir un diccionario de Proxies y pasarlo al método get() como se muestra a continuación:
proxies = {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
# Realizar una solicitud a través del Proxy especificado
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)
El parámetro proxies del método get() se pasa a Requests. Esto permite al cliente HTTP enrutar su solicitud a través del servidor Proxy HTTP o HTTPS especificado, dependiendo del protocolo de su URL de destino.
Paso n.º 4: Prueba la configuración de la integración del Proxy de CloudScraper
A modo de demostración, nos centraremos en el punto final /ip del proyecto HTTPBin. Este punto final devuelve la dirección IP de la persona que realiza la llamada. Si todo funciona como se espera, la respuesta debería mostrar la dirección IP del Proxy.
Para probar la configuración, puede obtener una IP de Proxy de una lista de Proxies gratuitos.
Advertencia: los proxies gratuitos suelen ser poco fiables, recopilan datos y pueden ser inseguros, especialmente si no proceden de uno de los mejores proveedores de Proxy del mercado. Intente utilizarlos solo con fines educativos.
Supongamos que esta es la URL de su servidor Proxy:
http://202.159.35.121:443
Así es como puede integrarla con CloudScraper:
import cloudscraper
# Crear una instancia de CloudScraper
scraper = cloudscraper.create_scraper()
# Especificar su Proxy
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# Realizar una solicitud a través del Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Imprimir la respuesta del punto final "/ip"
print(response.text)
Si la configuración es correcta, debería ver una respuesta como esta:
{
"origin": "202.159.35.121:1819"
}
Observe cómo la IP de la respuesta coincide con la IP del Proxy, tal y como se esperaba.
Nota: Los servidores Proxy gratuitos suelen tener una vida útil corta. Por lo tanto, es posible que el Proxy utilizado en el ejemplo siguiente ya no funcione cuando lea este artículo.
¡Bien hecho! Ha completado una sencilla integración de Proxy en CloudScraper.
Cómo implementar la rotación de proxies
El uso de un Proxy con Cloudscraper ayuda a ocultar su dirección IP. Sin embargo, los sitios de destino aún pueden bloquear las IP. Eso ocurre si se reciben demasiadas solicitudes desde la misma dirección, ya sea su propia IP o la del Proxy.
Para evitar las prohibiciones de IP, es esencial utilizar un Proxy rotativo con regularidad. Al distribuir sus solicitudes entre varias direcciones IP, puede hacer que su tráfico parezca provenir de diferentes usuarios. Eso reduce la probabilidad de detección.
Para implementar la rotación de proxies, comience por obtener una lista de proxies de un proveedor fiable. Guárdelos en una matriz:
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<TU_URL_PROXY_n>", "https": "<TU_URL_PROXY_n>"},
]
A continuación, utiliza el método random.choice() para seleccionar aleatoriamente un Proxy de la lista:
random_proxy = random.choice(proxy_list)
No olvide importar random desde la biblioteca estándar de Python:
import random
Después, simplemente configura el Proxy seleccionado aleatoriamente en la solicitud get():
response = Scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)
Si todo está configurado correctamente, la solicitud utilizará un Proxy diferente de la lista en cada ejecución. Aquí está el código completo:
import cloudscraper
import random
# Crear una instancia de Cloudscraper
scraper = cloudscraper.create_scraper()
# Lista de URL de Proxy (reemplazar con las URL de Proxy reales)
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<TU_URL_PROXY_n>", "https": "<TU_URL_PROXY_n>"},
]
# Selecciona aleatoriamente un Proxy de la lista
random_proxy = random.choice(proxy_list)
# Realiza una solicitud utilizando el Proxy seleccionado aleatoriamente
# (sustituye por la URL de destino real)
response = Scraper.get("<TU_URL_DE_DESTINO>", proxies=random_proxy)
¡Enhorabuena! Ya ha integrado la rotación de proxies con Cloudscraper.
Utiliza Autenticar proxies en CloudScraper
La mayoría de los proveedores ofrecen servidores Proxy autenticados, de modo que solo los usuarios de pago pueden acceder a ellos. Por lo general, es necesario especificar un nombre de usuario y una contraseña para acceder a esos servidores Proxy.
Para autenticar un Proxy en CloudScraper, debe incluir las credenciales necesarias directamente en la URL del Proxy. El formato para la autenticación con nombre de usuario y contraseña es el siguiente:
<PROTOCOLO_PROXY>://<SU_NOMBRE_DE_USUARIO>:<SU_CONTRASEÑA>@<DIRECCIÓN_IP_PROXY>:<PUERTO_PROXY>
Con ese formato, la configuración del Proxy de CloudScraper tendría el siguiente aspecto:
import cloudscraper
# Crear una instancia de Cloudscraper
scraper = cloudscraper.create_scraper()
# Defina su Proxy autenticado
proxies = {
"http": "<PROTOCOLO_PROXY>://<SU_NOMBRE_DE_USUARIO>:<SU_CONTRASEÑA>@<DIRECCIÓN_IP_PROXY>:<PUERTO_PROXY>",
"https": "<PROTOCOLO_PROXY>://<TU_NOMBRE_DE_USUARIO>:<TU_CONTRASEÑA>@<DIRECCIÓN_IP_PROXY>:<PUERTO_PROXY>"
}
# Realiza una solicitud a través del Proxy autenticado especificado.
response = Scraper.get("<TU_URL_DESTINO>", proxies=proxies)
¡Genial! Ya estás listo para ver cómo usar proxies premium en Cloudflare.
Integra proxies premium en Cloudscraper
Para obtener resultados fiables en entornos de scraping de producción, debes utilizar Proxies de proveedores de primer nivel como Bright Data. Bright Data cuenta con una red de alta calidad de más de 150 millones de IP en 195 países, con soporte para los cuatro tipos principales de Proxies:
- Proxies de centros de datos
- Proxies residenciales
- Proxy móvil
- Proxy ISP
Con características como la rotación automática de IP, un tiempo de actividad del 100 % y sesiones de IP fijas, Bright Data se posiciona como el proveedor de proxies líder del mercado.
Para integrar los proxies de Bright Data en CloudScraper, cree una cuenta o inicie sesión. Acceda al panel de control y haga clic en la zona «Residencial» de la tabla:
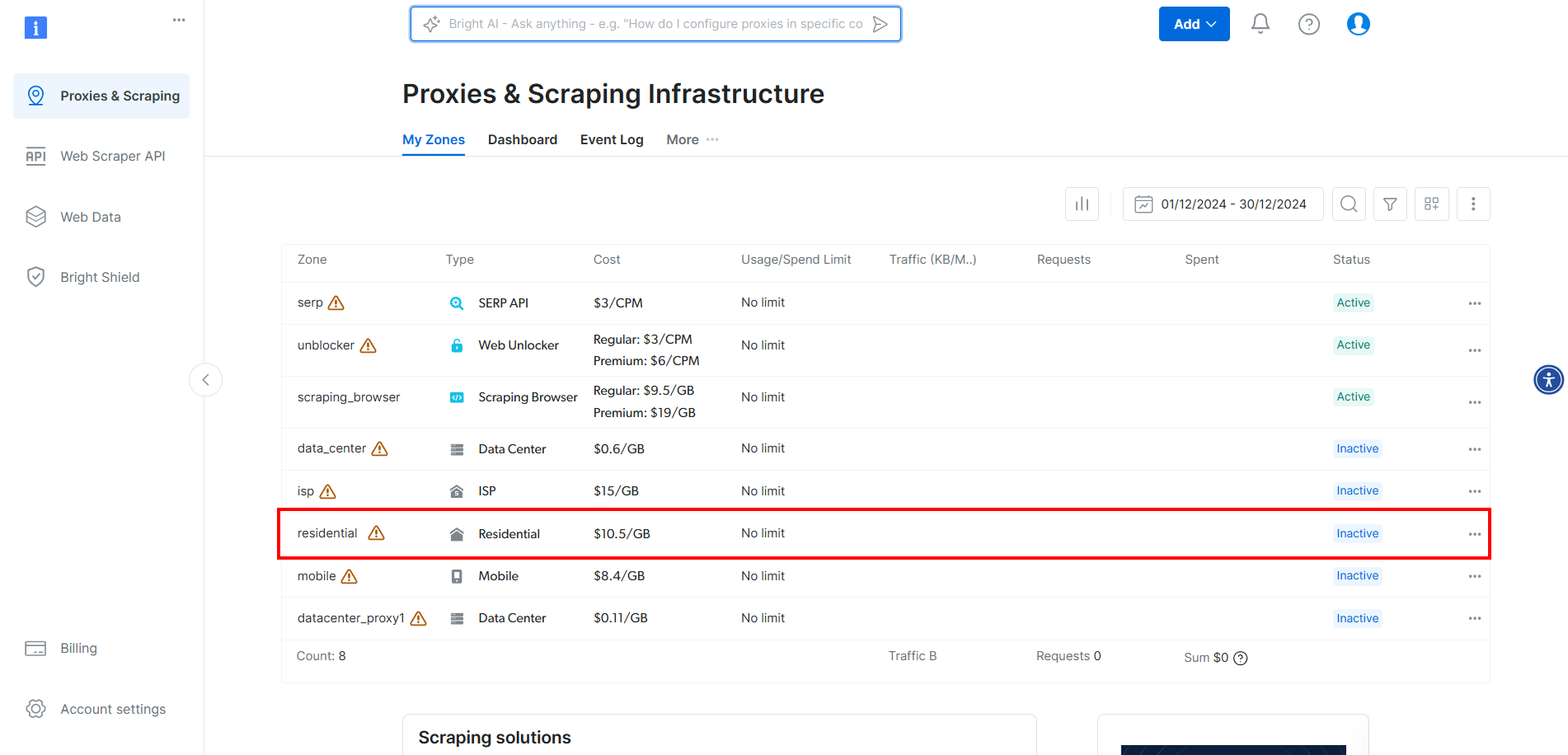
Aquí, active los Proxies haciendo clic en el botón:
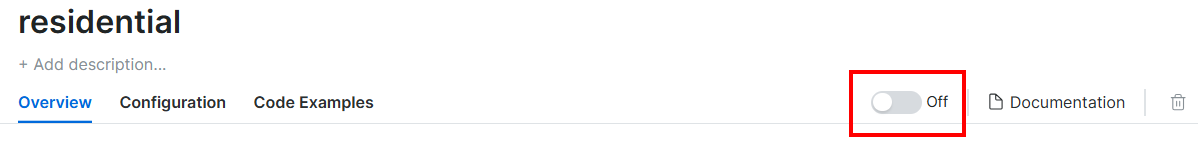
Esto es lo que debería ver ahora:

En la sección «Detalles de acceso», copie el host del Proxy, el nombre de usuario y la contraseña:
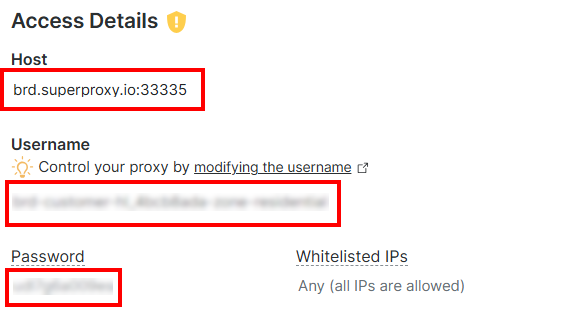
Tu URL de Proxy de Bright Data tendrá este aspecto:
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335
Ahora, integra el Proxy en Cloudscraper de la siguiente manera:
import cloudscraper
# Crear instancia de CloudScraper
scraper = cloudscraper.create_scraper()
# Definir el Proxy de Bright Data
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# Realizar una solicitud utilizando el Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Imprimir la respuesta
print(response.text)
Ten en cuenta que los Proxies residenciales de Bright Data rotan automáticamente. Por lo tanto, recibirás una IP diferente cada vez que ejecutes el script.
¡Et voilà! Integración del Proxy CloudScraper completada.
Conclusión
En este tutorial, ha visto cómo utilizar Cloudscraper con proxies para obtener la máxima eficacia. Ha aprendido los conceptos básicos de la integración de proxies con la herramienta Python Cloudflare-bypass y también ha explorado técnicas más avanzadas, como la rotación de proxies.
Conseguir mejores resultados es mucho más fácil cuando se utilizan servidores Proxy IP de alta calidad de un proveedor de primer nivel como Bright Data.
Bright Data controla los mejores servidores Proxy del mundo y presta servicio a empresas de la lista Fortune 500 y a más de 20 000 clientes. Su red mundial de Proxy incluye:
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxies residenciales: más de 150 millones de IPs residenciales en más de 195 países.
- Proxy ISP: más de 700 000 IP de ISP.
- Proxy móvil: más de 7 millones de IP móviles.
En general, se trata de una de las redes de proxies más grandes y fiables que existen.
Cree hoy mismo una cuenta gratuita en Bright Data para probar nuestros servidores Proxy.





