

En esta guía, verá lo siguiente:
- Qué es Pica y por qué es una excelente opción para construir agentes de IA que se integren con herramientas externas.
- Por qué los agentes de IA requieren la integración con soluciones de terceros para la recuperación de datos.
- Cómo utilizar el conector Bright Data integrado en un agente Pica para obtener datos web y obtener respuestas más precisas.
Sumerjámonos.
¿Qué es la pica?
Pica es una plataforma de código abierto diseñada para crear rápidamente agentes de IA e integraciones SaaS. Proporciona acceso simplificado a más de 125 API de terceros sin necesidad de gestionar claves ni configuraciones complejas.
El objetivo de Pica es facilitar la conexión de los modelos de IA con herramientas y servicios externos. Con Pica, puede configurar integraciones en unos pocos clics y luego utilizarlas fácilmente en su código. Esto permite que los flujos de trabajo de IA gestionen la recuperación de datos en tiempo real, se ocupen de automatizaciones complejas y mucho más.
El proyecto ha ganado popularidad rápidamente en GitHub, acumulando más de 1.300 estrellas en pocos meses. Esto demuestra su fuerte crecimiento y adopción por parte de la comunidad.
Por qué los agentes de IA necesitan integraciones de datos web
Todos los marcos de agentes de IA heredan limitaciones básicas de los LLM en los que se basan. Dado que los LLM están preentrenados en conjuntos de datos estáticos, carecen de conciencia de tiempo real y no pueden acceder de forma fiable a contenidos web en directo.
Esto suele dar lugar a respuestas desfasadas o incluso alucinaciones. Para superar estas limitaciones, los agentes (y los LLM de los que dependen) necesitan acceder a datos web fiables y actualizados. ¿Por qué datos de Internet? Porque la web sigue siendo la fuente de información más completa y actualizada que existe.
Por eso, un agente de IA eficaz debe poder integrarse rápida y fácilmente con proveedores de datos web de IA de terceros. Y aquí es exactamente donde entra en juego Pica.
En la plataforma Pica, encontrará más de 125 integraciones disponibles, incluida una para Bright Data:
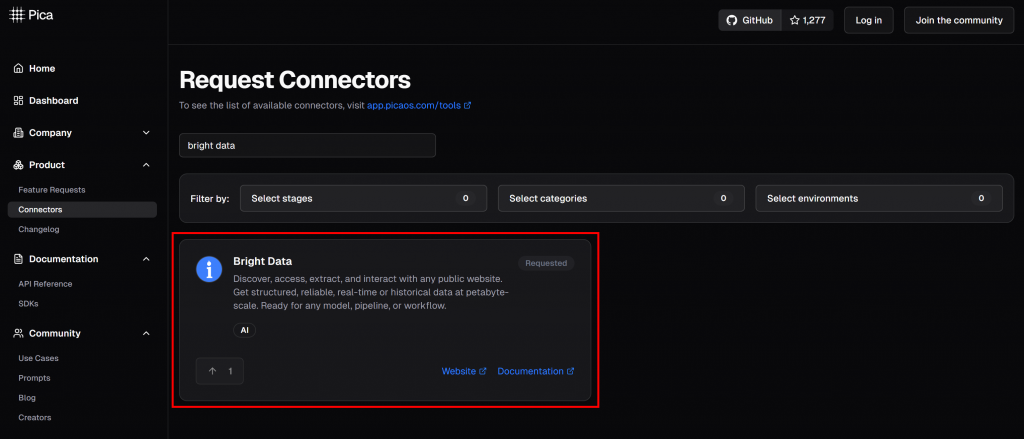
La integración de Bright Data permite a sus agentes y flujos de trabajo de IA conectarse sin problemas con:
- API de Web Unlocker: Una API de scraping avanzada que elude las protecciones contra bots y entrega el contenido de cualquier página web en formato Markdown.
- API de raspado web: Soluciones especializadas para extraer de forma ética datos frescos y estructurados de sitios populares como Amazon, LinkedIn, Instagram y otros 40.
Estas herramientas proporcionan a sus agentes de IA, flujos de trabajo o canalizaciones la capacidad de respaldar sus respuestas con datos web fiables, extraídos sobre la marcha de páginas relevantes. Vea esta integración en acción en el próximo capítulo.
Cómo construir un agente de IA que pueda recuperar datos de la web con Pica y Bright Data
En esta sección guiada, aprenderá a utilizar Pica para construir un agente Python AI que se conecte a la integración de Bright Data. De esta forma, tu agente podrá recuperar datos web estructurados de sitios como Amazon.
Siga los pasos que se indican a continuación para crear su agente de IA basado en Bright Data con Pica.
Requisitos previos
Para seguir este tutorial, necesitas
- Python 3.9 o superior instalado en su máquina (recomendamos la última versión).
- Una cuenta Pica.
- Una clave API de Bright Data.
- Una clave API de OpenAI.
No se preocupe si todavía no tiene una clave API de Bright Data o una cuenta Pica. Le mostraremos cómo configurarlas en los próximos pasos.
Paso 1: Inicializar el proyecto Python
Abre un terminal y crea un nuevo directorio para tu proyecto de agente Pica AI:
mkdir pica-bright-data-agentLa carpeta pica-bright-data-agent contendrá el código Python para su agente Pica. Este utilizará la integración de Bright Data para la recuperación de datos web.
A continuación, navega hasta el directorio del proyecto y crea un entorno virtual dentro de él:
cd pica-bright-data-agent
python -m venv venvAhora, abre el proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Dentro de la carpeta del proyecto, crea un nuevo archivo llamado agent.py. Su estructura de directorios debe tener este aspecto:
pica-bright-data-agent/
├── venv/
└── agent.pyActive el entorno virtual en su terminal. En Linux o macOS, ejecute:
source venv/bin/activateEquivalentemente, en Windows, dispara este comando:
venv/Scripts/activateEn los siguientes pasos, instalarás los paquetes de Python necesarios. Si prefieres instalarlo todo ahora mismo, con tu entorno virtual activado, simplemente ejecuta:
pip install langchain langchain-openai pica-langchain python-dotenv¡Ya está todo listo! Ya tienes un entorno de desarrollo Python listo para construir un agente de IA con integración de Bright Data en Pica.
Paso nº 2: Configurar las variables de entorno Lectura
Su agente se conectará a servicios de terceros como Pica, Bright Data y OpenAI. Para mantener la seguridad de estas integraciones, evita codificar las claves API directamente en el código Python. En su lugar, almacénalas como variables de entorno.
Para facilitar la carga de variables de entorno, utilice la biblioteca python-dotenv. En su entorno virtual activado, instálela con:
pip install python-dotenvA continuación, importe la biblioteca y llame a load_dotenv() en la parte superior de su archivo agent.py para cargar sus variables de entorno:
import os
from dotenv import load_dotenv
load_dotenv()Esta función permite a su script leer variables desde un archivo local .env. Cree este archivo .env en la raíz del directorio de su proyecto. Su estructura de carpetas se verá así:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.py¡Genial! Ya está preparado para gestionar de forma segura sus claves API y otros secretos utilizando variables de entorno.
Paso nº 3: Configurar Pica
Si aún no lo ha hecho, cree una cuenta gratuita en Pica. Por defecto, Pica generará una clave API para usted. Puedes usar esa clave API con LangChain o cualquier otra integración compatible.
Visita la página “Inicio rápido” y selecciona la pestaña “LangChain”:
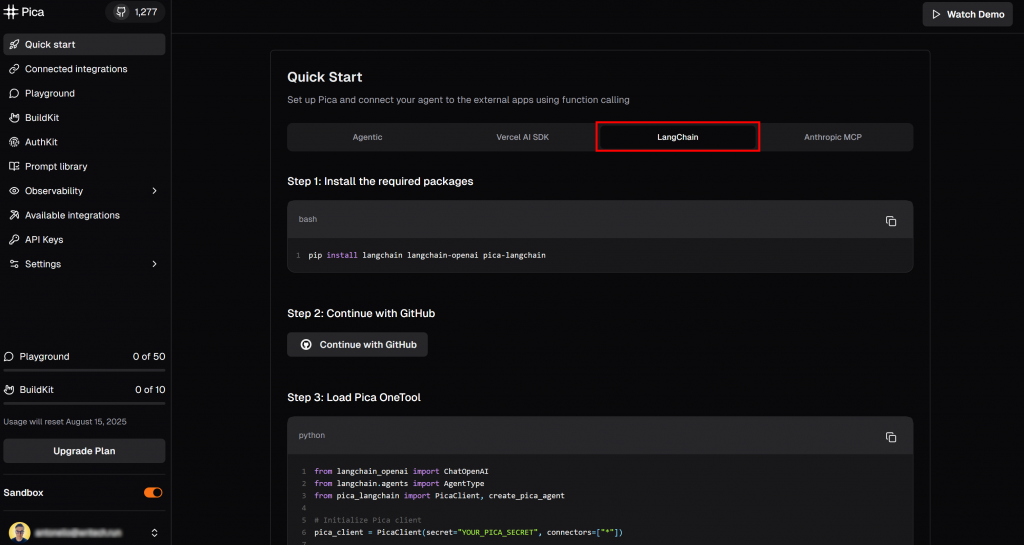
Aquí encontrarás las instrucciones para empezar a utilizar Pica en LangChain. Específicamente, siga el comando de instalación que allí se muestra. En su entorno virtual activado, ejecute:
pip install langchain langchain-openai pica-langchainAhora, desplácese hacia abajo hasta llegar a la sección “Clave API”:

Haz clic en el botón “copiar al portapapeles” para copiar tu clave API de Pica. A continuación, pégala en tu archivo .env definiendo una variable de entorno como esta:
PICA_API_KEY="<YOUR_PICA_KEY>"Sustituya el por la clave API que acaba de copiar.
¡Fantástico! Su cuenta Pica está ahora totalmente configurada y lista para usar en su código.
Paso nº 4: Integrar los datos de Bright en Pica
Antes de empezar, asegúrese de seguir la guía oficial para configurar una clave API de Bright Data. Necesitará esta clave para conectar su agente a Bright Data mediante la integración incorporada disponible en la plataforma Pica.
Ahora que ya tiene su clave API, puede añadir la integración de Bright Data en Pica.
En la pestaña “LangChain” de su panel de control de Pica, desplácese hasta la sección “Integraciones recientes” y pulse el botón “Examinar integraciones”:
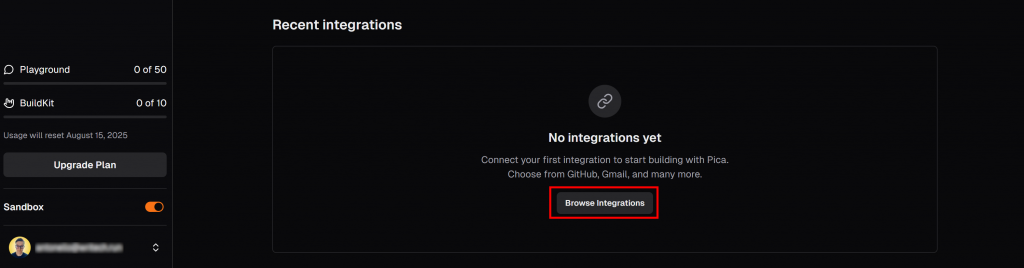
Se abrirá un modal. En la barra de búsqueda, escriba “brightdata” y seleccione la integración “BrightData”:
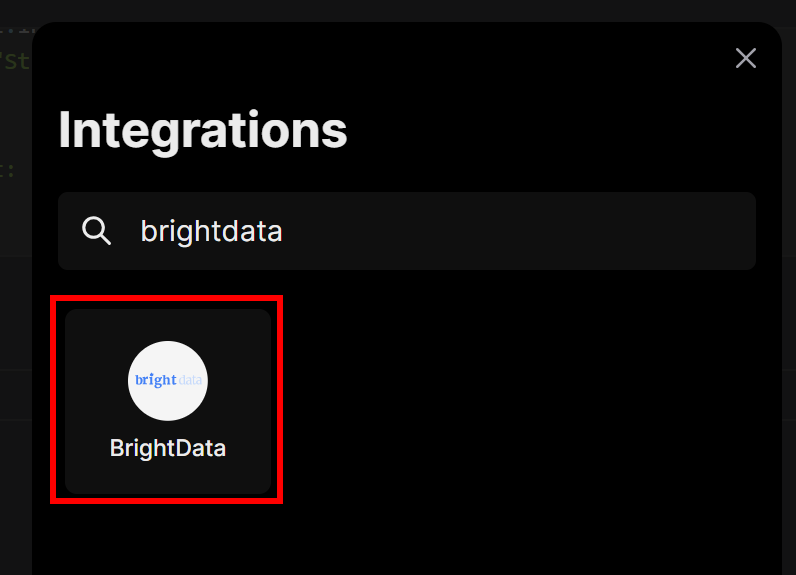
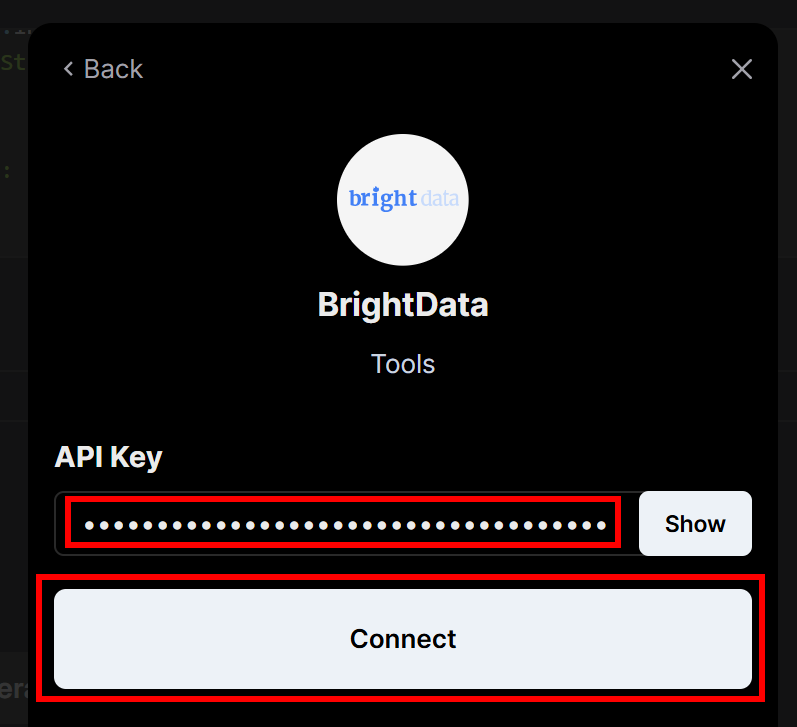
Se le pedirá que introduzca la clave API de Bright Data que creó anteriormente. Péguela y, a continuación, haga clic en el botón “Conectar”:
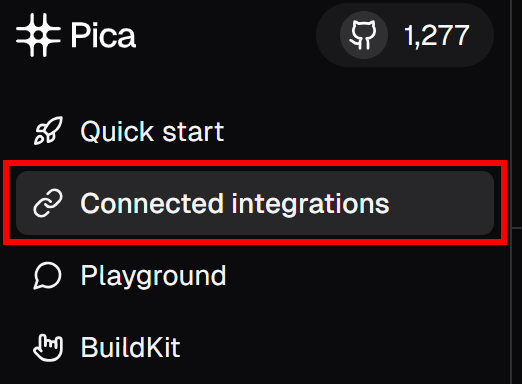
A continuación, en el menú de la izquierda, haga clic en la opción “Integraciones conectadas”:
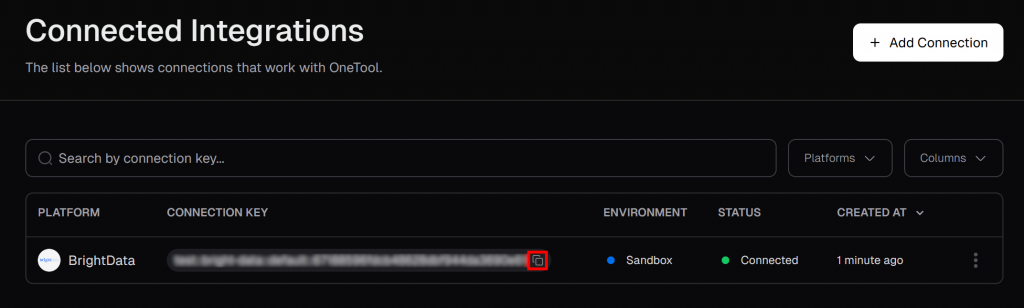
En la página “Integraciones conectadas”, debería ver Bright Data como una integración conectada. En la tabla, haga clic en el botón “Copiar al portapapeles” para copiar su clave de conexión:
Luego, pégalo en tu archivo .env añadiendo:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"Asegúrese de sustituir el por la clave de conexión real que ha copiado.
Necesitará ese valor para inicializar su agente Pica en código, para que sepa que debe cargar la conexión Bright Data configurada. Vea cómo hacerlo en el siguiente paso.
Paso nº 5: Inicialice su Agente Pica
En agent.py, inicializa tu agente Pica con:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()El fragmento anterior inicializa un cliente Pica, conectándose a su cuenta Pica utilizando el secreto PICA_API_KEY cargado desde su entorno. Además, selecciona la integración de Bright Data que configuró anteriormente de entre todos los conectores disponibles.
Esto significa que cualquier agente de IA que cree con este cliente podrá aprovechar las capacidades de recuperación de datos web en tiempo real de Bright Data.
No olvide importar las clases necesarias:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptions¡Estupendo! Estás listo para proceder con la integración del LLM.
Paso 6: Integrar OpenAI
Su agente de Pica necesitará un motor LLM para comprender las solicitudes de entrada y realizar las tareas deseadas utilizando las capacidades de Bright Data.
Este tutorial usa la integración OpenAI, así que definirás el LLM para tu agente en tu fichero agent. py de la siguiente manera:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Tenga en cuenta que todos los ejemplos de Pica LangChain en la documentación utilizan temperatura=0. Esto asegura que el modelo es determinista, produciendo siempre la misma salida para la misma entrada.
Recuerda que la clase ChatOpenAI proviene de esta importación:
from langchain_openai import ChatOpenAIEn particular, ChatOpenAI espera que tu clave de la API OpenAI esté definida en una variable de entorno llamada OPENAI_API_KEY. Por lo tanto, en su archivo .env, agregue:
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>Reemplaza el por tu clave de API de OpenAI real.
¡Sorprendente! Ahora tienes todos los bloques de construcción para definir tu agente Pica AI.
Paso nº 7: Defina su agente de pica
En Pica, un agente de IA consta de tres partes principales:
- Una instancia de cliente Pica
- Un motor LLM
- Un tipo de agente Pica
En este caso, desea crear un agente de IA que pueda llamar a funciones de OpenAI (que a su vez se conectan a las capacidades de recuperación web de Bright Data a través de la integración de Pica). Por lo tanto, cree su agente Pica así:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) No olvide añadir las importaciones necesarias:
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeMaravilloso. Ahora todo lo que queda es probar su agente en una tarea de recuperación de datos.
Paso 8: Interrogar al agente de IA
Para verificar que la integración de Bright Data funciona en su agente Pica, dele una tarea que normalmente no podría realizar por sí mismo. Por ejemplo, pídale que recupere datos actualizados de una página de producto reciente de Amazon, como la Nintendo Switch 2 (disponible en https://www.amazon.com/dp/B0F3GWXLTS/).
Para ello, invoque a su agente con esta entrada:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})Nota: El mensaje es intencionadamente explícito. Indica al agente exactamente lo que debe hacer, qué página debe raspar y qué integración debe utilizar. Esto asegura que el LLM aprovechará las herramientas de Bright Data configuradas a través de Pica, produciendo los resultados esperados.
Por último, imprima la salida del agente:
print(f"nAgent Result:n{result}")Y con esta última línea, tu agente Pica AI está completo. Es hora de verlo todo en acción.
Paso 9: Póngalo todo junto
Tu archivo agent.py debería contener ahora:
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")Como puede ver, en menos de 50 líneas de código, ha construido un agente de Pica con potentes capacidades de recuperación de datos. Esto es posible gracias a la integración de Bright Data disponible directamente en la plataforma Pica.
Ejecute su agente con:
python agent.pyEn su terminal, debería ver registros similares a los siguientes:
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataEn términos más sencillos, esto es lo que hizo su agente de la Pica:
- Se ha conectado a Pica y ha obtenido la integración de Bright Data configurada.
- Descubrió que había 54 herramientas disponibles en la plataforma Bright Data.
- Obtención de una lista de todos los conjuntos de datos de Bright Data.
- Basándose en su solicitud, seleccionó la herramienta “Trigger Synchronous Web Scraping and Retrieve Results” y la utilizó para extraer datos frescos de la página de productos de Amazon especificada. Entre bastidores, esto desencadena una llamada a Bright Data Amazon Scraper, pasando la URL del producto de Amazon. El scraper recuperará y devolverá los datos del producto.
- Ejecutada con éxito la acción de scraping y devueltos los datos.
El resultado debería ser algo parecido a esto:

Pegue esta salida en un editor Markdown y verá un informe de producto bien formateado como éste:
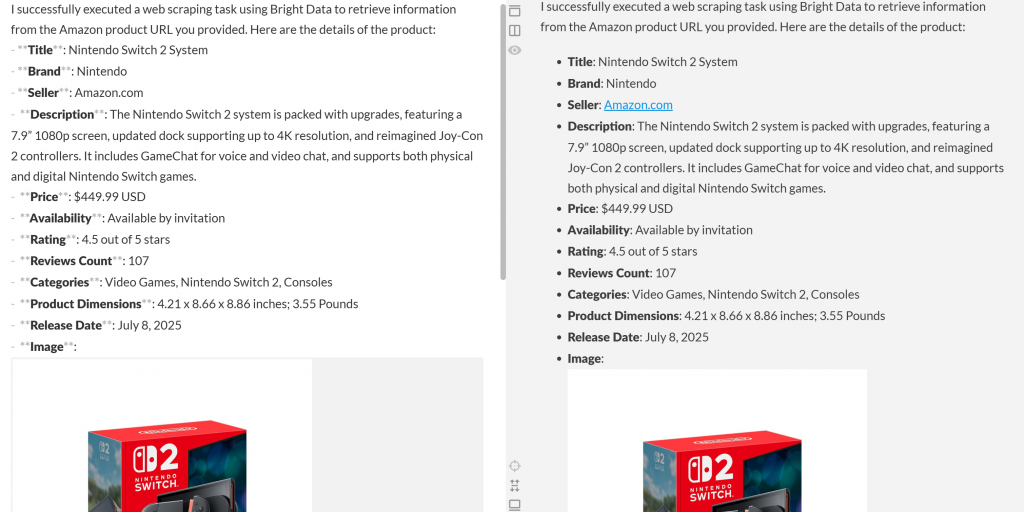
Como puede ver, el agente fue capaz de producir un informe Markdown con datos significativos y actualizados de la página de producto de Amazon. Puede comprobar la exactitud visitando la página del producto de destino en su navegador:
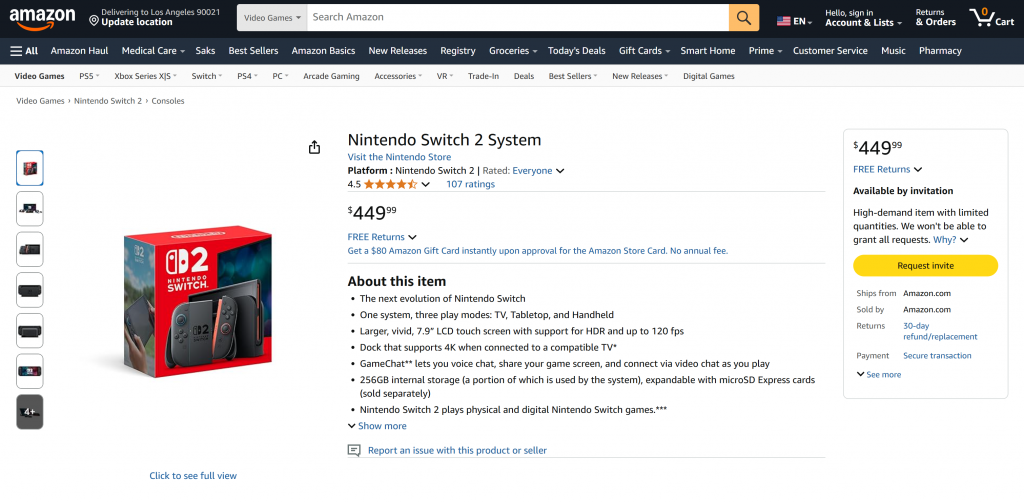
Observe cómo los datos producidos son datos reales de la página de Amazon, no alucinados por el LLM. Este es un testimonio del scraping realizado a través de las herramientas de Bright Data. Y esto es sólo el principio.
Con la amplia gama de acciones de Bright Data disponibles en Pica, su agente puede ahora recuperar datos de prácticamente cualquier sitio web. Esto incluye objetivos complejos como Amazon, conocido por sus estrictas medidas anti-scraping (como el famoso CAPTCHA de Amazon).
¡Et voilà! Acaba de experimentar un scraping web sin fisuras, impulsado por la integración de Bright Data en su agente Pica AI.
Conclusión
En este artículo, has visto cómo utilizar Pica para construir un agente de IA que puede respaldar sus respuestas con datos web frescos. Esto ha sido posible gracias a la integración de Pica con Bright Data. El conector Bright Data de Pica permite a la IA obtener datos de cualquier página web.
Ten en cuenta que esto es sólo un ejemplo sencillo. Si desea crear agentes más avanzados, necesitará soluciones sólidas para obtener, validar y transformar datos web en tiempo real. Eso es precisamente lo que puede encontrar en la infraestructura de Bright Data AI.
Cree una cuenta gratuita en Bright Data y empiece a explorar nuestras herramientas de extracción de datos web preparadas para la IA.





