

En esta entrada del blog, verás:
- Qué es AutoGPT y qué lo hace especial como marco de creación de agentes de IA.
- Por qué los agentes de AutoGPT se benefician del acceso a capacidades de búsqueda web, exploración, interacción y extracción de datos.
- Cómo se puede integrar Bright Data en AutoGPT para proporcionar a los agentes de IA precisamente estas funciones.
¡Empecemos!
¿Qué es AutoGPT?
AutoGPT es una plataforma de código abierto para crear, implementar y ejecutar agentes de IA autónomos.
Lo que la distingue es su interfaz basada en bloques y de bajo código, la ejecución continua de los agentes y la capacidad de conectar herramientas, API y fuentes de datos en flujos de automatización de extremo a extremo.
A diferencia de los simples scripts, los agentes de AutoGPT pueden ejecutarse de forma persistente, reaccionar ante desencadenantes y gestionar tareas de varios pasos. El proyecto cuenta con el respaldo de una gran comunidad de código abierto. Ha logrado una impresionante acogida en GitHub, con más de 183 000 estrellas.
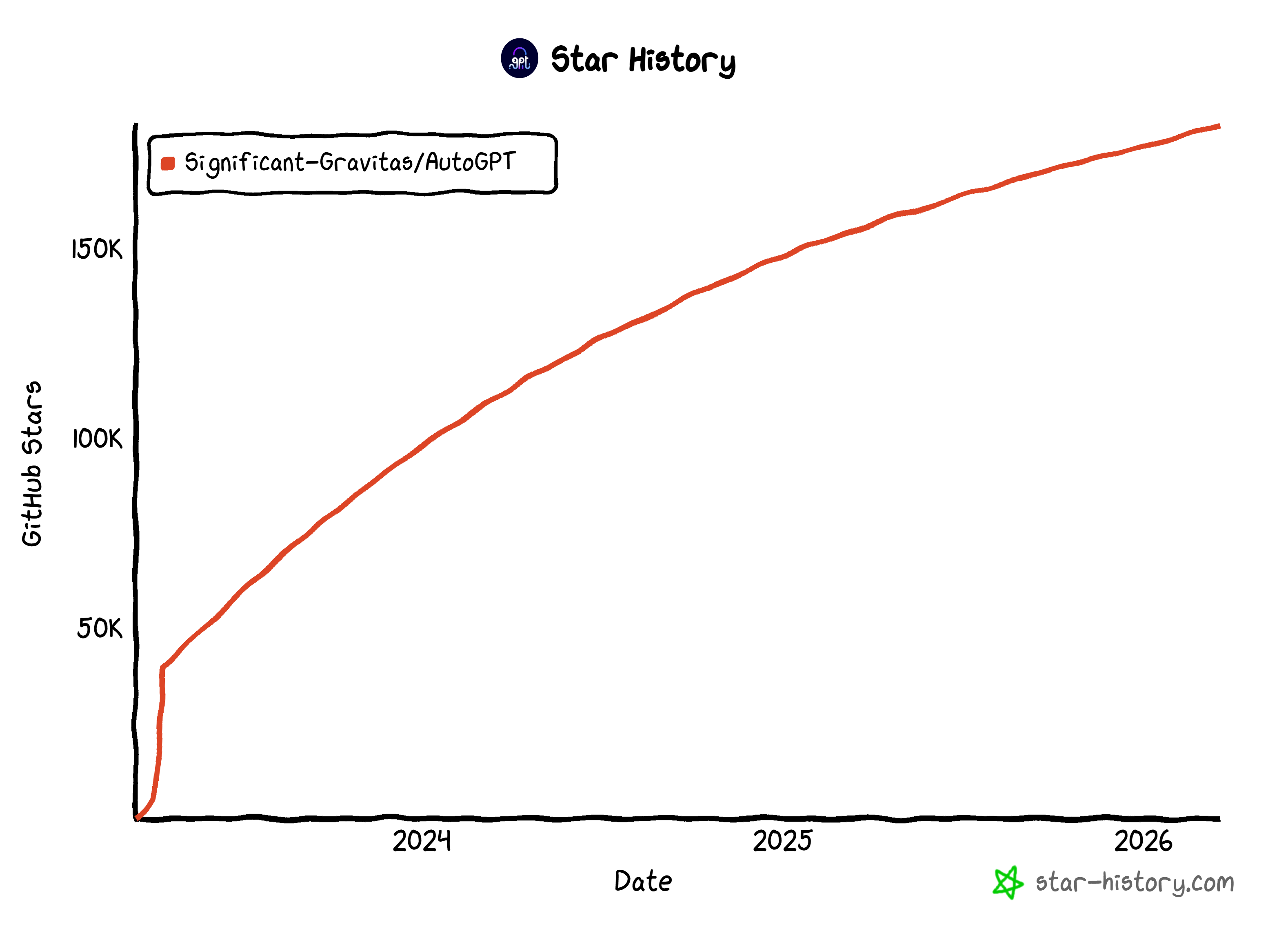
Esas estadísticas lo convierten en uno de los marcos de agentes de IA más populares en la actualidad.
¿Por qué integrar capacidades de exploración web y recuperación de datos en AutoGPT?
No hay duda de que AutoGPT es una solución con numerosas funciones. Sin embargo, todos los agentes de IA basados en LLM se enfrentan a limitaciones inherentes. Los modelos de lenguaje estándar se entrenan con Conjuntos de datos estáticos, lo que significa que su conocimiento queda fijado en un momento específico.
Esto puede dar lugar a información desactualizada, alucinaciones o lagunas cuando los agentes intentan realizar tareas del mundo real que requieren datos actuales. Además, los LLM no pueden interactuar con el mundo real, incluida la web. Por lo tanto, los agentes de IA básicos se ven limitados por esas restricciones nativas.
AutoGPT incluye herramientas nativas para la búsqueda en la web, la exploración y otras interacciones. Sin embargo, estas capacidades integradas pueden tener dificultades en cuanto a escala, fiabilidad y medidas sofisticadas contra los bots en comparación con las soluciones de nivel empresarial.
Aquí es donde entra en juego Bright Data. Basada en una de las redes de proxies más grandes del mundo —con más de 150 millones de direcciones IP en 195 países—, su infraestructura ofrece un tiempo de actividad del 99,99 % y concurrencia ilimitada.
La integración de Bright Data en AutoGPT permite a los agentes acceder a contenido web en tiempo real, resultados de búsqueda y datos estructurados de cualquier sitio web. En concreto, los productos clave de Bright Data que pueden mejorar los flujos de trabajo de AutoGPT incluyen:
- API Web Unlocker: Accede al contenido de cualquier sitio web en HTML sin formato o Markdown, eludiendo los CAPTCHAs y las protecciones antibots.
- API SERP: recopila resultados de motores de búsqueda de Google, Bing, Yandex y muchos otros motores de búsqueda.
- API de Scraper: extrae datos estructurados de plataformas como Amazon, LinkedIn, Instagram y Yahoo Finance.
- API Crawl: Convierte sitios web completos en conjuntos de datos estructurados para su posterior procesamiento mediante IA.
Al combinar las capacidades de agente de AutoGPT con las soluciones de Bright Data, los agentes de IA pueden recuperar información en tiempo real de forma autónoma y ejecutar flujos de trabajo complejos que superan con creces las limitaciones de los LLM estándar.
Cómo integrar Bright Data en AutoGPT: una guía paso a paso
En esta sección guiada, aprenderás a crear un agente de IA en AutoGPT que se integre con Bright Data para la recuperación de datos web.
En concreto, este agente actuará como asistente de marcadores, ayudándote a decidir si merece la pena guardar un artículo online para leerlo más tarde. Este es solo un ejemplo sencillo para mostrar la integración, pero hay muchos otros casos de uso posibles.
¡Sigue las instrucciones que aparecen a continuación!
Requisitos previos
Para alojar AutoGPT en tu propio servidor, asegúrate de que tu sistema cumple los siguientes requisitos de hardware:
- Sistema operativo: Linux (se recomienda Ubuntu 20.04 o posterior), macOS (10.15 o posterior) o Windows 10/11 con WSL2.
- CPU: se recomiendan 4 o más núcleos.
- RAM: Mínimo 8 GB (se recomiendan 16 GB).
- Almacenamiento: al menos 10 GB de espacio libre.
También debes tener estas herramientas instaladas localmente en tu equipo:
- Docker Engine 20.10.0+
- Docker Compose 2.0.0+
- Git 2.30+
- Node.js 16.x+ (con npm 8.x+)
- Visual Studio Code 1.60+ o cualquier editor de código moderno
Además, asegúrate de que se cumplan los siguientes requisitos de red:
- Una conexión a Internet estable.
- Acceso a los puertos necesarios (que se configurarán a través de Docker).
- Capacidad para establecer conexiones HTTPS salientes.
Para implementar el agente de IA en AutoGPT, también necesitarás:
- Una cuenta de Bright Data con una zona de API de Web Unlocker configurada y una clave de API establecida.
- Una clave API de uno de los proveedores de LLM compatibles con AutoGPT (en este ejemplo, utilizaremos OpenAI).
No te preocupes por configurar tu cuenta de Bright Data todavía, ya que se te guiará a través del proceso en un capítulo específico.
Paso n.º 1: Instalar AutoGPT localmente
Asegúrate de que tu sistema cumple los requisitos previos de hardware, software y red. Además, comprueba que Docker esté en funcionamiento.
Para simplificar el proceso de configuración del autoalojamiento de AutoGPT, lo más recomendable es utilizar el script de instalación oficial de una sola línea. Este instala todas las dependencias necesarias, descarga el código más reciente y ejecuta la aplicación por ti.
En macOS o Linux, ejecuta el script de instalación de una sola línea con:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.shDe forma equivalente, en Windows, ejecuta el siguiente comando en PowerShell:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"El proceso de instalación puede tardar unos minutos, así que ten paciencia. Una vez completado, deberías ver un resultado similar al siguiente: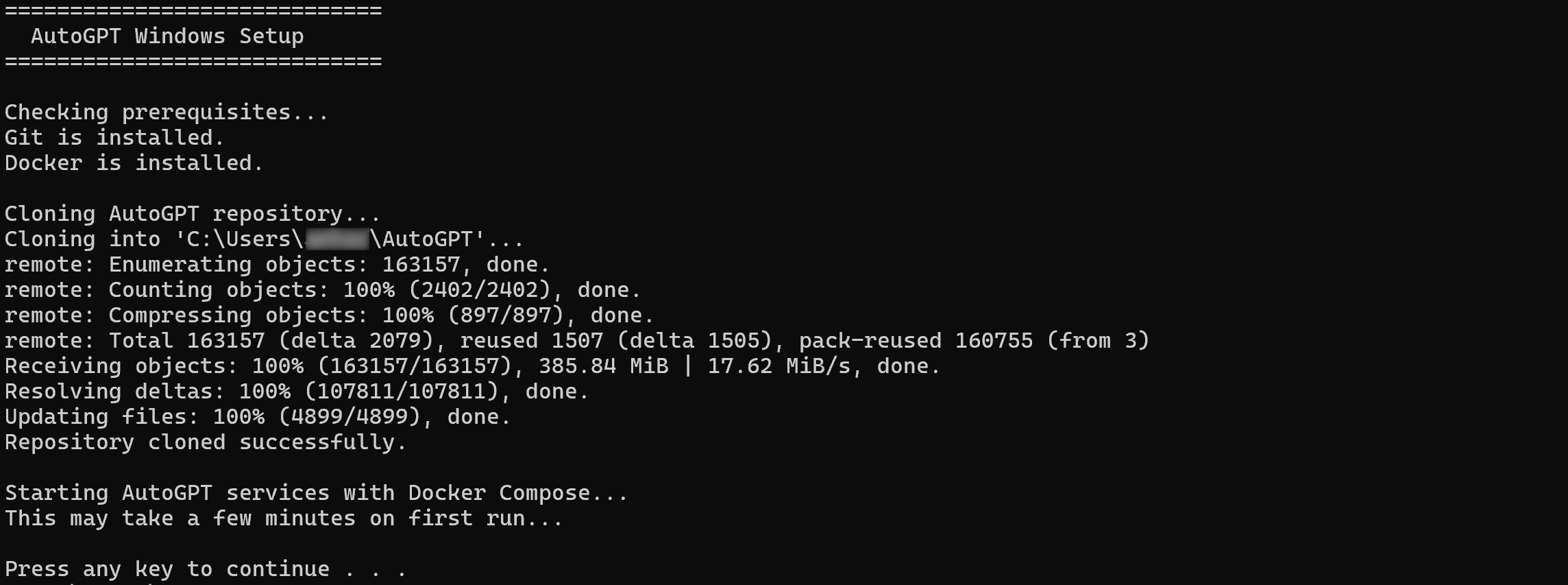
¡Genial! En este punto, AutoGPT debería estar correctamente configurado localmente y listo para ejecutarse.
Paso n.º 2: Iniciar la plataforma
Ve a la carpeta de instalación:
cd AutoGPT/autogpt_platformA continuación, copia el archivo .env.default que viene con el repositorio clonado a .env:
cp .env.default .envEste comando crea un archivo .env en el directorio autogpt_platform utilizando la configuración predeterminada. Modifica este archivo para definir tus propias variables de entorno solo si necesitas una configuración personalizada. De lo contrario, mantén los valores predeterminados.
A continuación, inicia la plataforma AutoGPT con:
docker compose up -d --buildEste comando compila y ejecuta todos los servicios de backend necesarios definidos en el archivo docker-compose.yml en modo independiente.
Una vez que los servicios estén en funcionamiento, comprueba que todo funciona correctamente visitando http://localhost en el navegador.
De forma predeterminada, los diferentes servicios de AutoGPT están disponibles en:
- Servidor de interfaz de usuario (frontend):
http://localhost. - Servidor WebSocket de backend:
http://localhost:8001. - Servidor REST de la API de ejecución:
http://localhost:8006.
A continuación se muestra lo que deberías ver:
Regístrate creando tu cuenta. Tras iniciar sesión, se te redirigirá al Agent Builder en la interfaz de AutoGPT:
¡Genial! Ya estás listo para crear tu primer agente y conectarlo a Bright Data.
Paso n.º 3: Diseña el flujo de trabajo del agente de IA
AutoGPT ofrece varios bloques, cada uno de los cuales gestiona una acción o tarea específica. En este ejemplo, quieres crear un flujo de trabajo de agente que:
- Acepte la URL de un artículo (de cualquier sitio web) como entrada.
- Recupere el contenido del artículo en Markdown utilizando la API Web Unlocker de Bright Data.
- Pase el contenido a un modelo de lenguaje grande (LLM) para generar una puntuación del 1 al 10 que indique el valor del artículo para añadirlo a los marcadores, así como un comentario de estilo humano que explique la puntuación.
- Devuelva el resultado estructurado.

En AutoGPT, este flujo de trabajo se puede implementar utilizando los siguientes bloques:
- Entrada del agente: Acepta la URL del artículo del usuario.
- Crear diccionario: Crea el cuerpo de la solicitud para la API de Bright Data Web Unlocker utilizando la URL proporcionada.
- Enviar solicitud web autenticada: envía la solicitud a la API de Bright Data Web Unlocker y recupera el contenido del artículo.
- Generador de respuesta estructurada de IA: Pasa el contenido del artículo al LLM y genera una evaluación estructurada del marcador (puntuación + comentario).
- Salida del agente: Devuelve el resultado estructurado final.
¡Perfecto! Ahora que los pasos del flujo de trabajo del agente están claros, el siguiente paso es implementarlo. Pero primero, empecemos con Bright Data.
Paso n.º 4: Configura tu cuenta de Bright Data
Como se ha indicado anteriormente, el flujo de trabajo del agente de IA que desea implementar se basa en el producto Web Unlocker de Bright Data. Para conectarse a él en AutoGPT, necesita una cuenta de Bright Data con una zona de la API de Web Unlocker configurada, junto con una clave de API.
Para obtener una guía rápida, consulta el artículo«Guía de inicio rápido para la API de Web Unlocker de Bright Data».También puedes seguir los pasos que se indican a continuación.
Si no tienes una cuenta de Bright Data, crea una nueva. De lo contrario, simplemente inicia sesión. Accede al panel de control y ve a la página «Proxies & Scraping». Echa un vistazo a la tabla «My Zones»: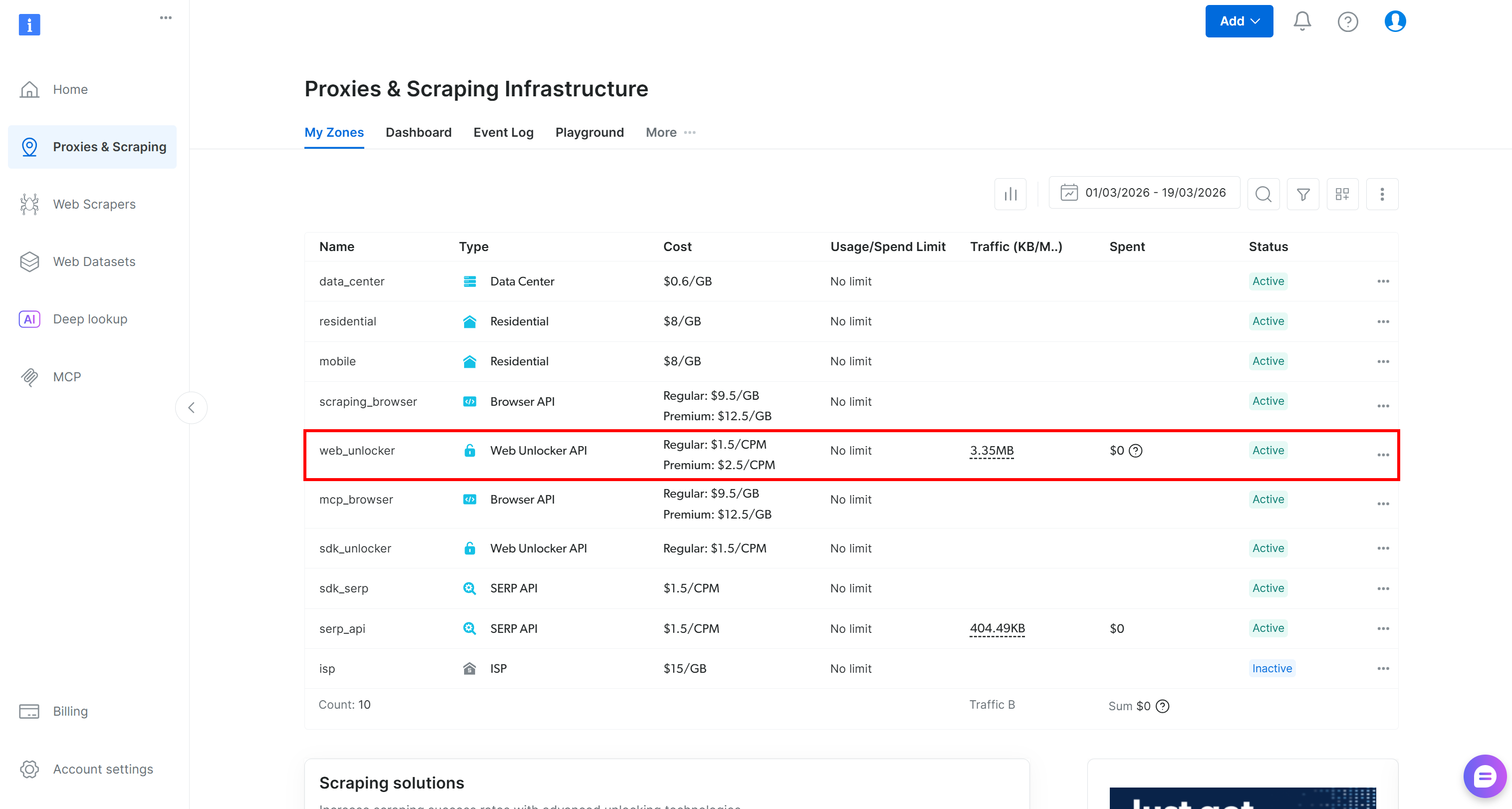
Si ya existe una zona de la API de Web Unlocker (por ejemplo, web_unlocker) en la tabla, ya está todo listo.
Si no está, debes crear una. Desplázate hasta la tarjeta «API de desbloqueo», haz clic en el botón «Crear zona» y sigue las instrucciones del asistente.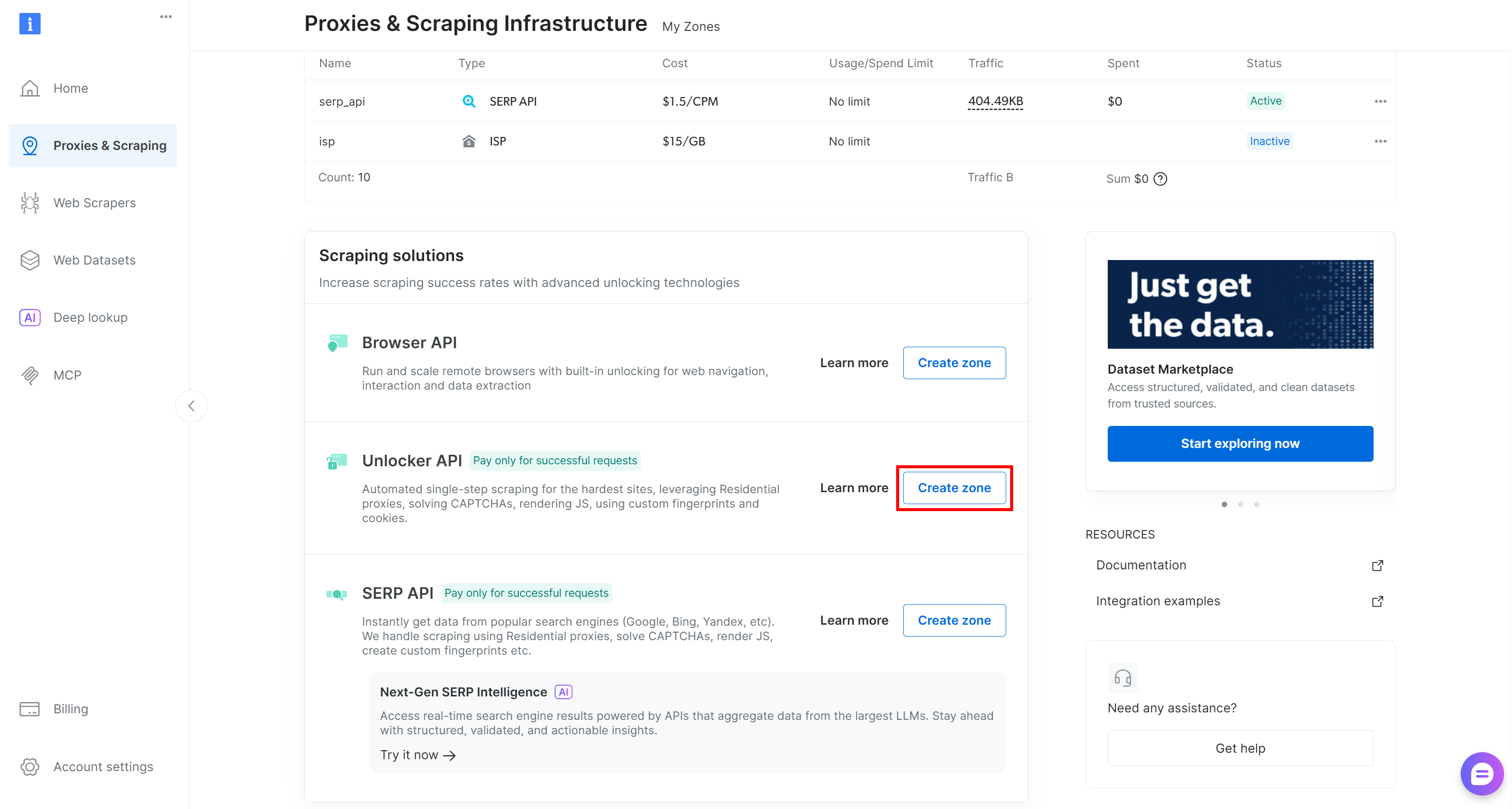
Elige bien el nombre de tu zona, ya que lo necesitarás más adelante. En esta guía, daremos por hecho que la zona se llama web_unlocker.
Por último, genera tu clave API de Bright Data y guárdala en un lugar seguro. La necesitarás para autenticar las solicitudes HTTP que AutoGPT envíe a Bright Data.
¡Ya está! Se han cumplido los requisitos previos de Bright Data.
Paso n.º 5: Inicializar el agente
Todo flujo de trabajo de agente de AutoGPT necesita una entrada y una salida. Empieza por ir a la sección «Build» para acceder a la página del generador de agentes:
Pulsa el botón «Save», asigna un nombre a tu agente, como «Bookmark Likelihood Evaluator», y luego haz clic en «Save Agent»: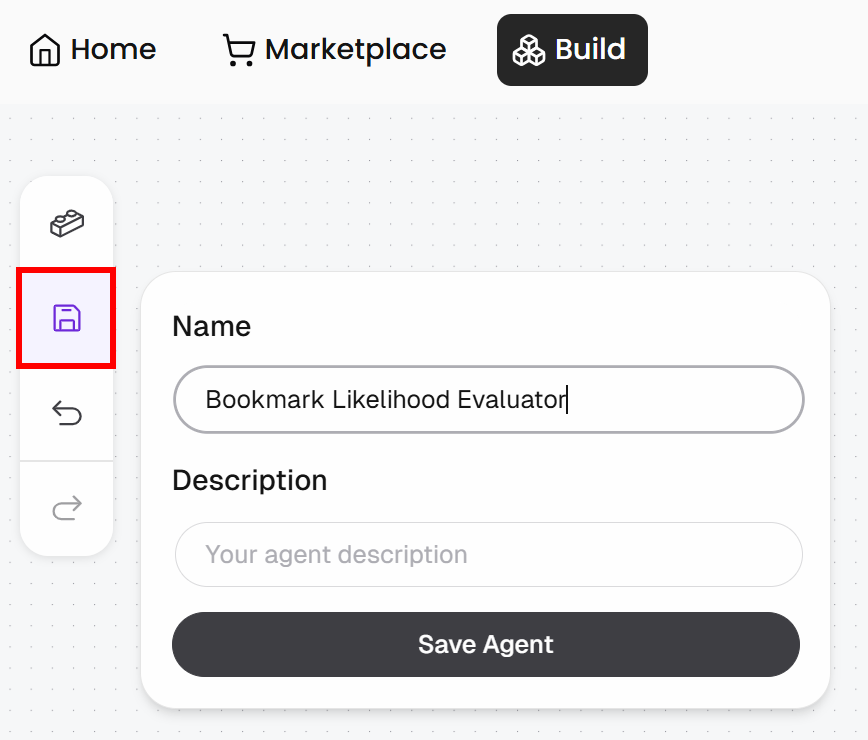
En la página del generador de agentes, pulsa el botón «Blocks» (Bloques) a la izquierda y añade un bloque «Agent Input» (Entrada del agente):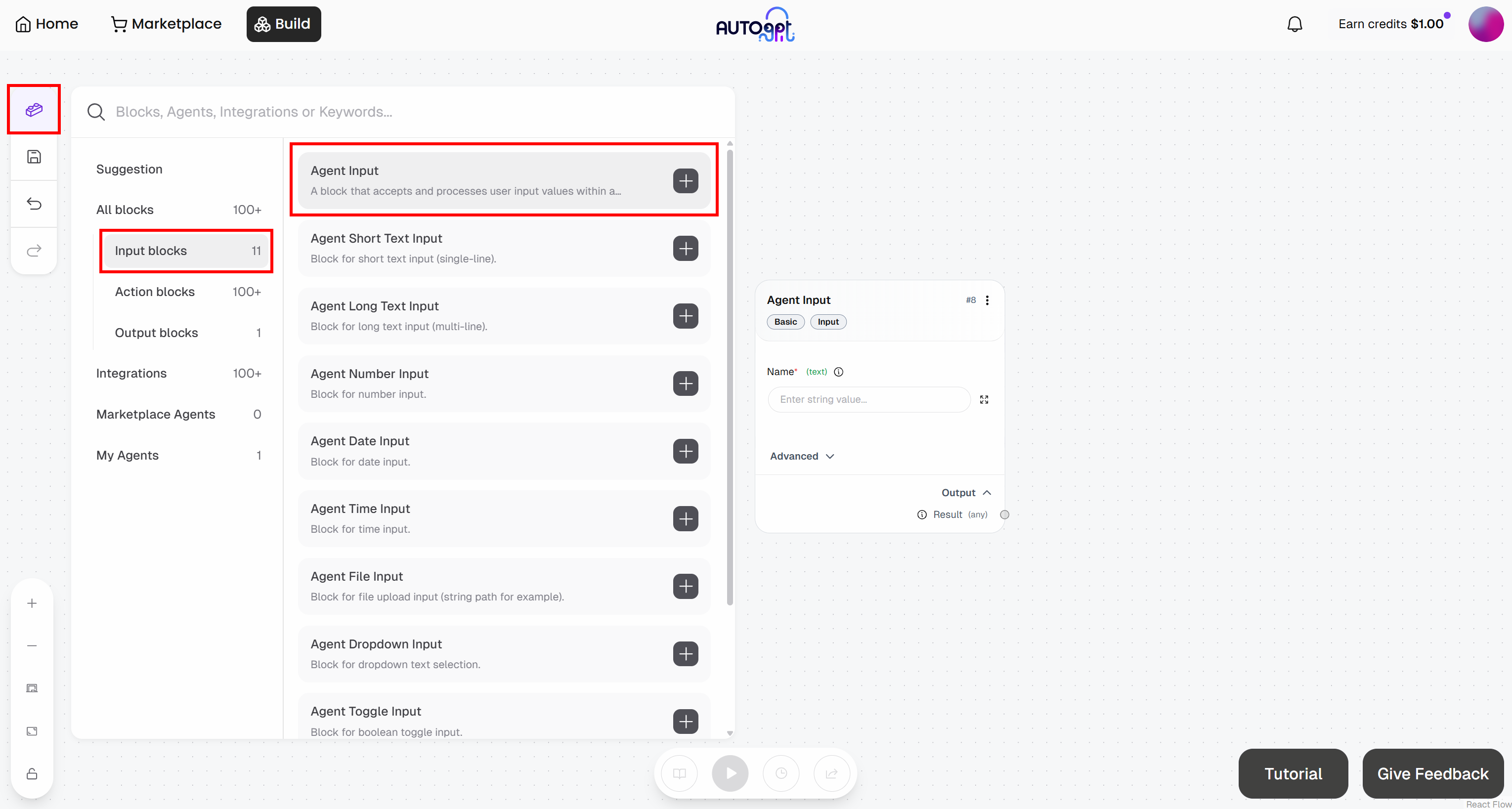
De forma similar, añade un bloque «Agent Output»: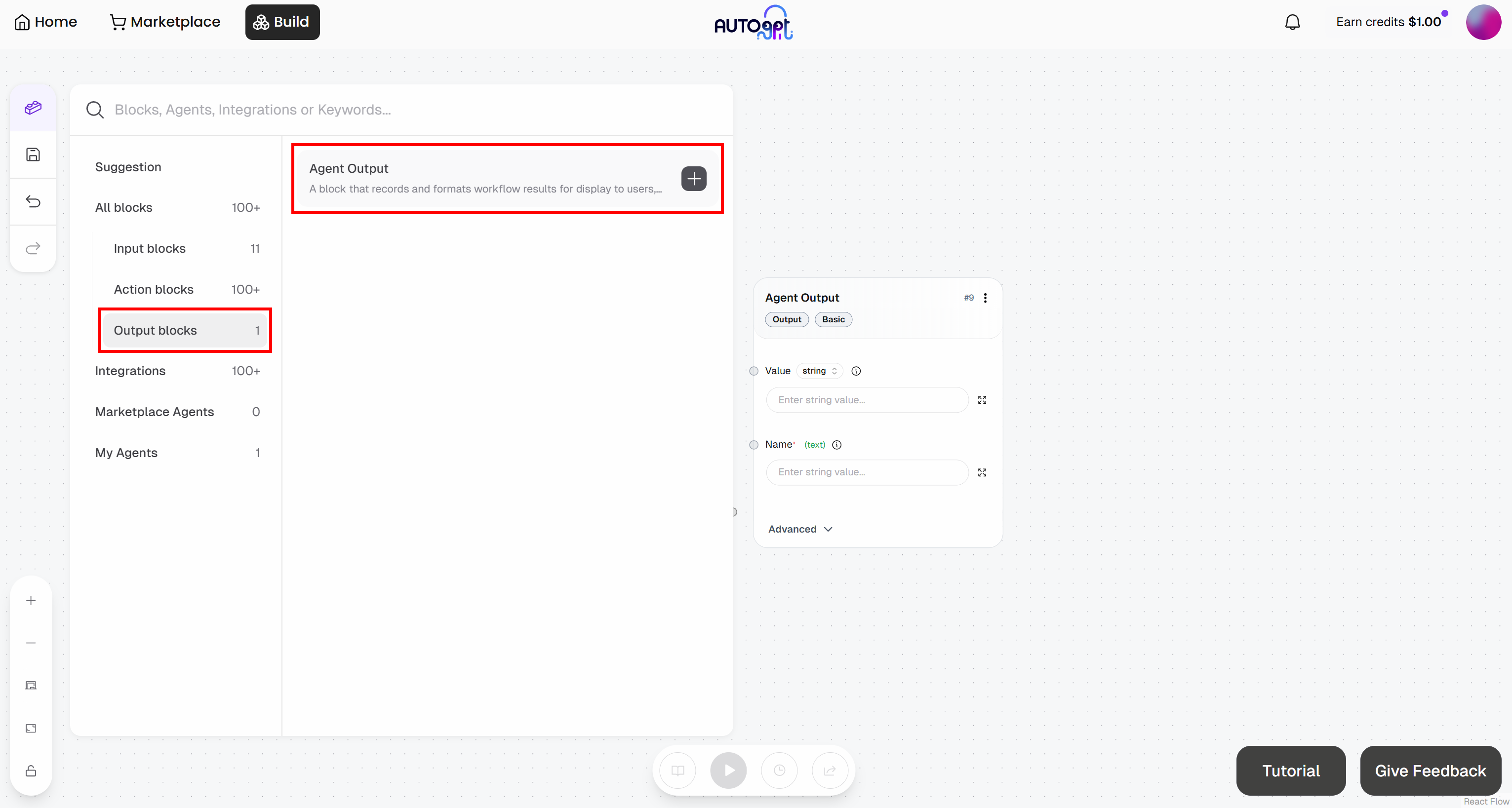
Configura los bloques de la siguiente manera:
- Entrada del agente: asígnale el nombre «URL del artículo»
- Bloque de salida del agente: asígnale el nombre «Probabilidad de marcar como favorito»
En este punto, tu flujo de trabajo de agente inicial debería tener este aspecto: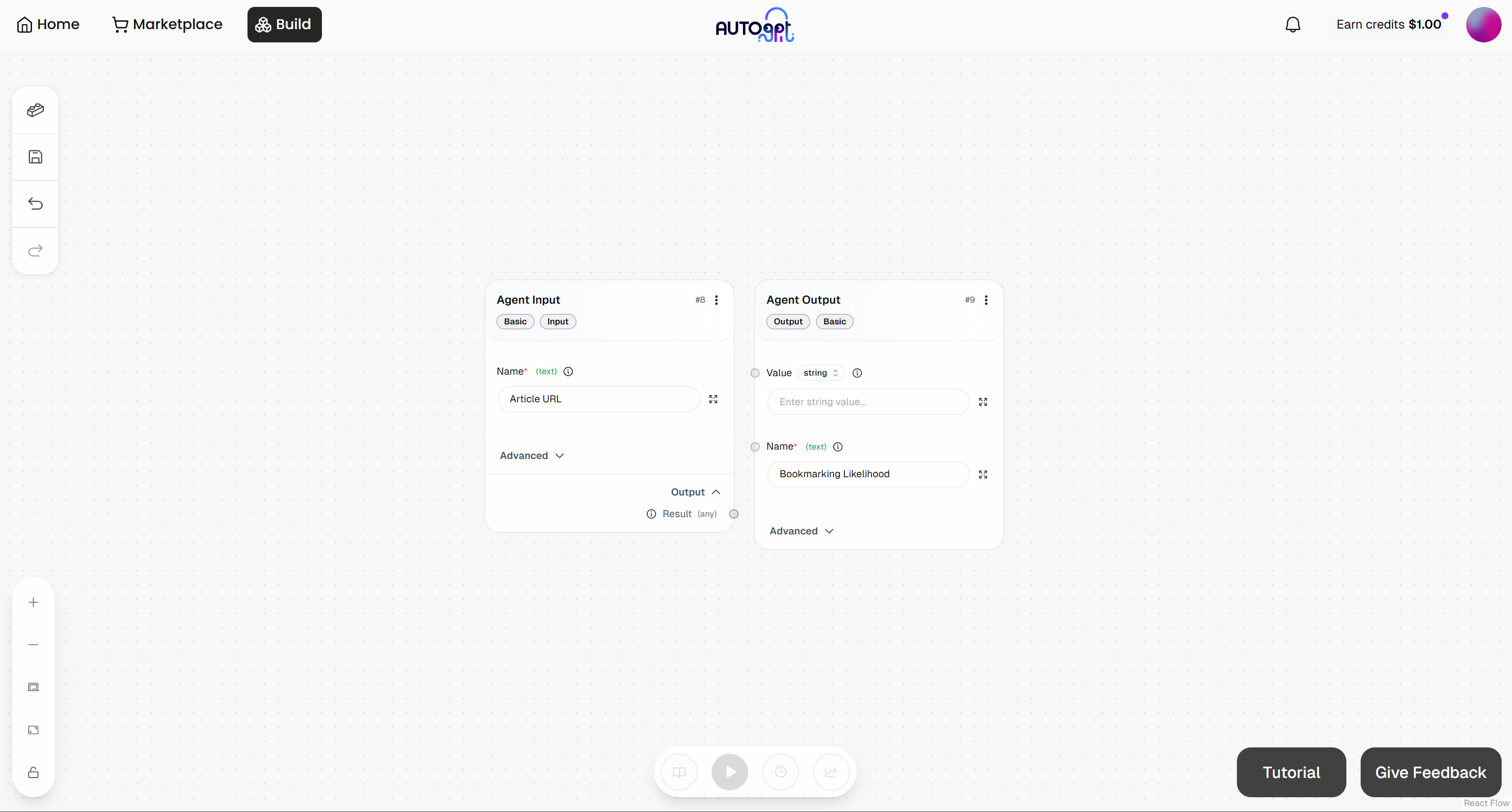
¡Genial! Es hora de seguir definiendo el resto de tu flujo de trabajo de agente.
Paso n.º 6: Realizar la solicitud de scraping
Para realizar la solicitud HTTP a la API de Bright Data Web Unlocker, necesitas dos bloques:
- Crear diccionario: Define el cuerpo de la solicitud.
- Enviar solicitud web autenticada: envía la solicitud autenticada al punto final de Web Unlocker en las API de Bright Data.
Empieza añadiendo el bloque «Crear diccionario»: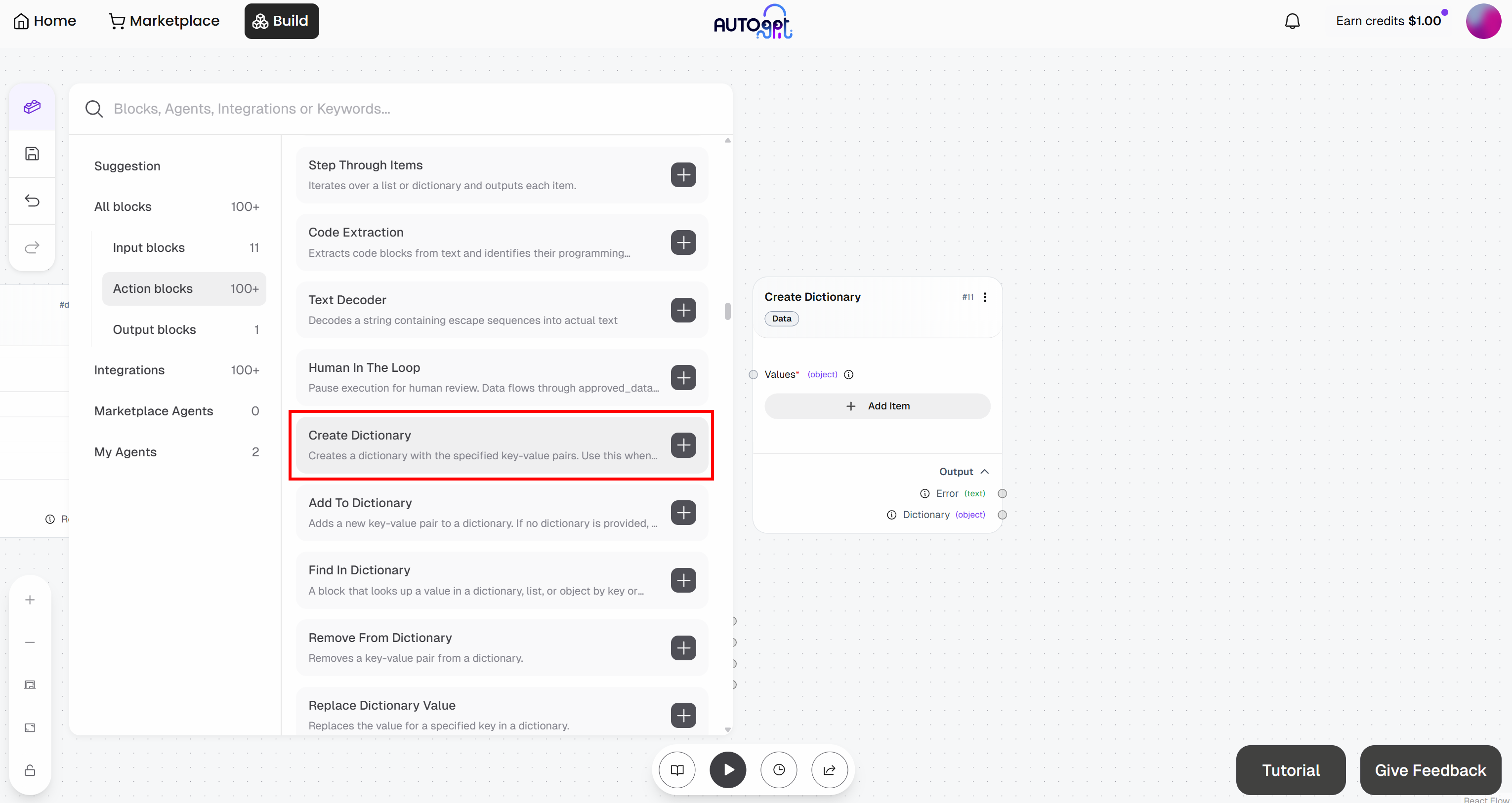
A continuación, añade el bloque «Enviar solicitud web autenticada»: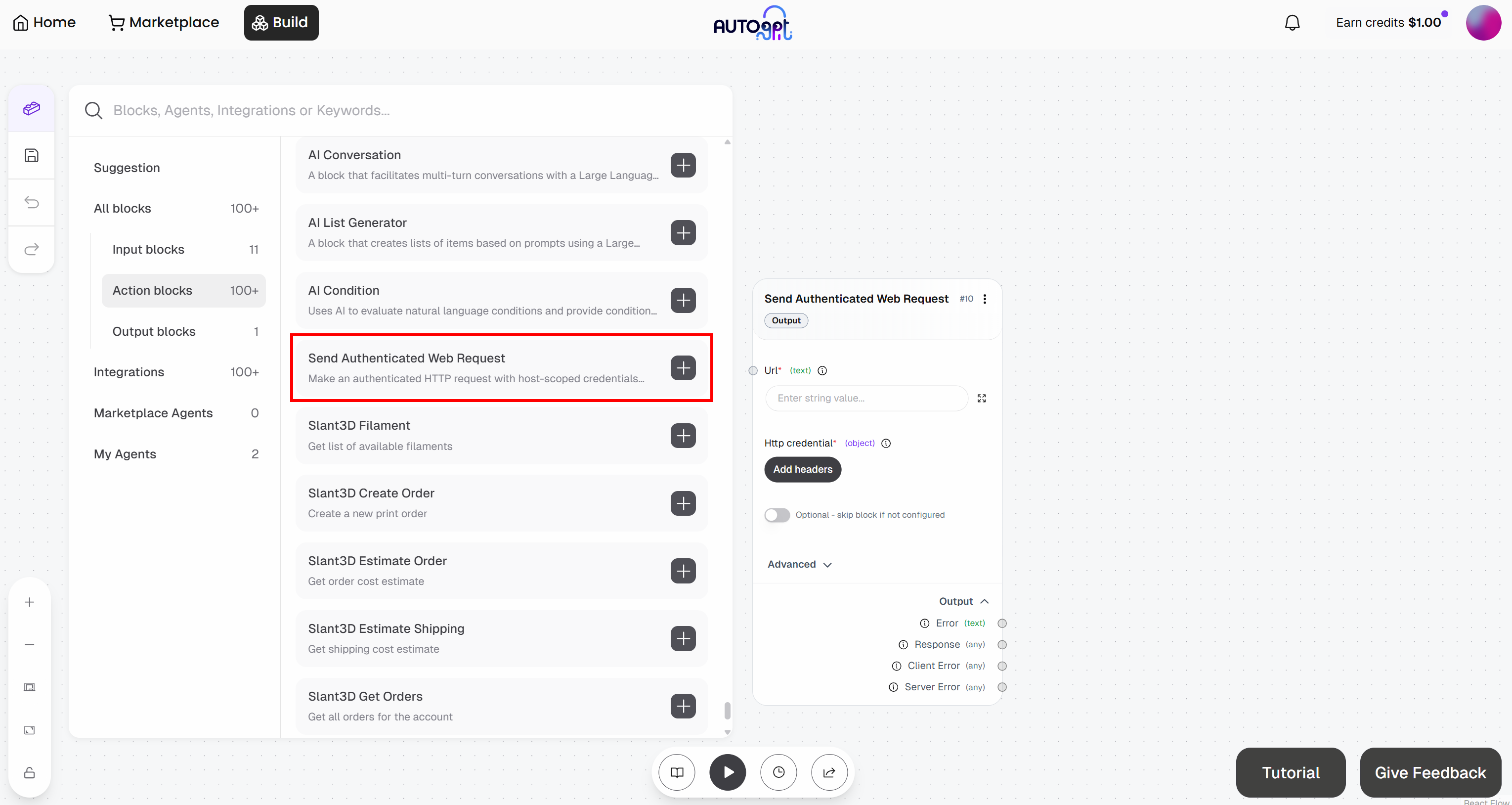
Prepárate para configurar el bloque «Enviar solicitud web autenticada». Esto enviará una solicitud a la API de Web Unlocker. Para obtener más detalles sobre cómo funciona este punto final y cómo llamarlo, consulta la documentación oficial.
Despliega el menú desplegable «Avanzado» y rellena todo el bloque de la siguiente manera:
- URL:
https://api.brightdata.com/request. - Método HTTP:
POST
A continuación, haz clic en el botón «Añadir encabezados» debajo de «Credenciales HTTP»: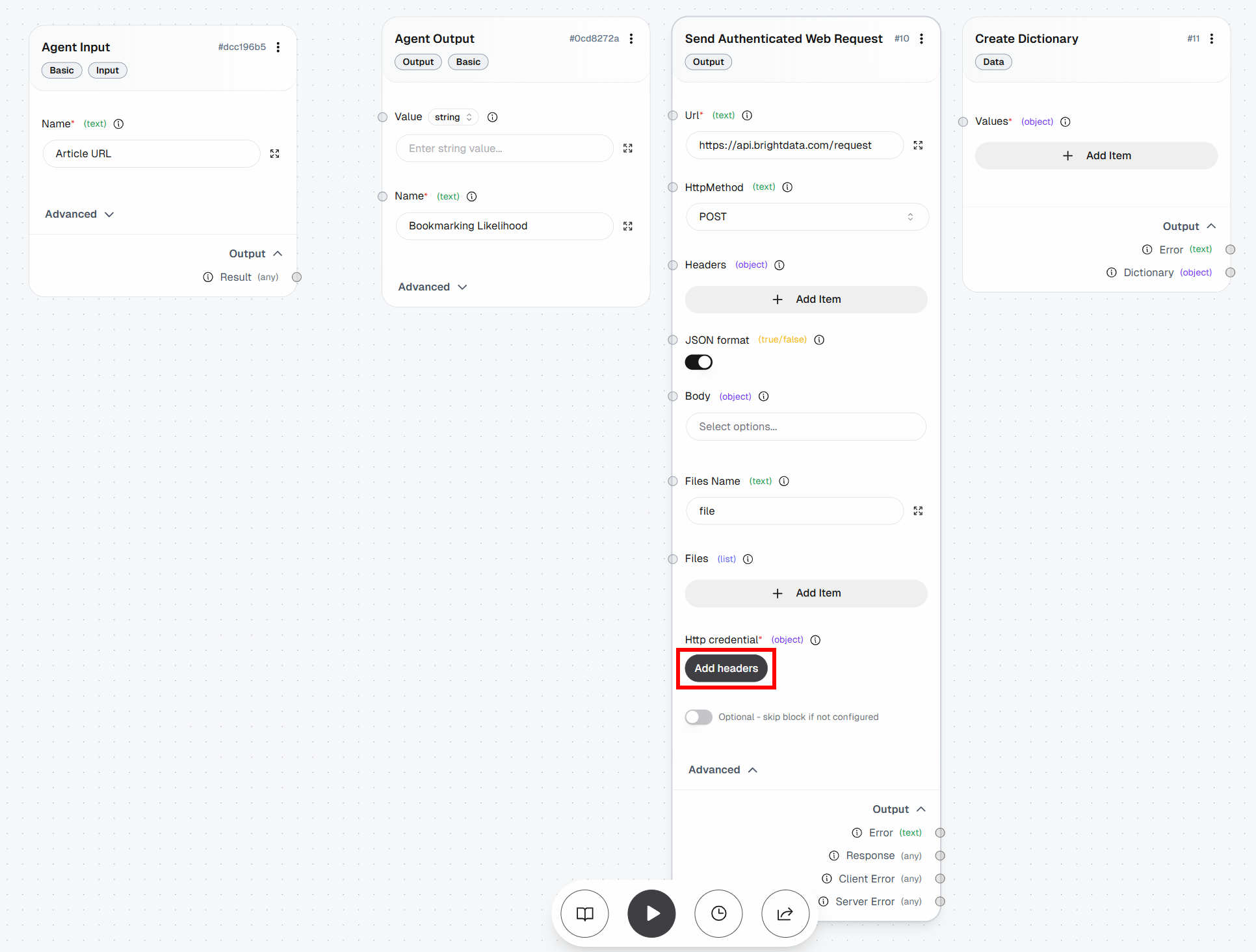
Configura la autenticación basada en encabezados de la siguiente manera:
- Nombre del encabezado:
Authorization - Valor del encabezado:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
Recuerda sustituir el marcador de posición <YOUR_BRIGHT_DATA_API_KEY> por tu clave API de Bright Data real.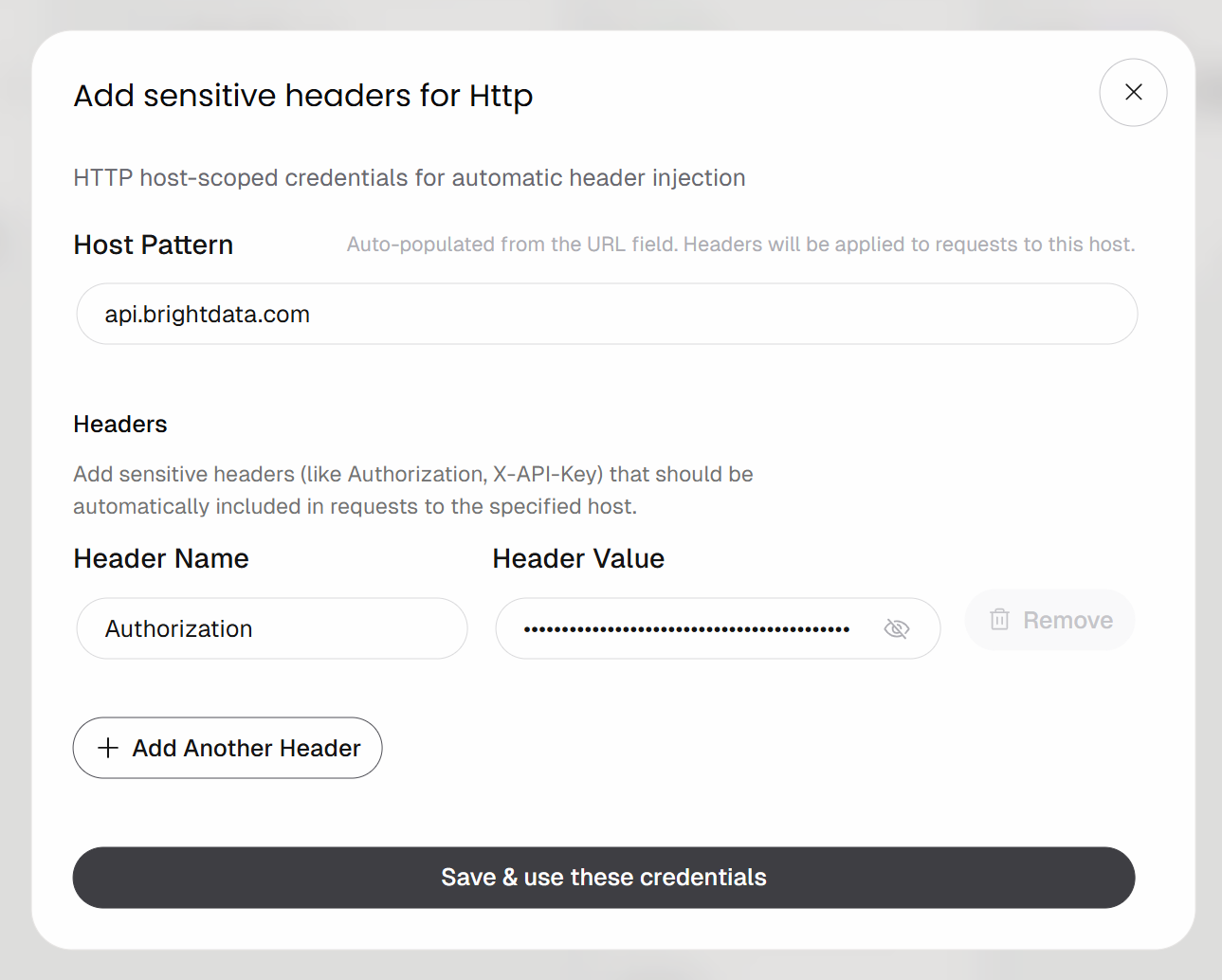
Haz clic en el botón «Guardar y usar estas credenciales» para confirmar.
La solicitud POST se autenticará utilizando el encabezado Authorization. Ese es el método de autenticación recomendado para llamar a las API de Bright Data.
Ahora, debe definir el cuerpo de la solicitud. En este caso, necesita una carga JSON como la siguiente:
{
"zone": "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}Esto indica a la API de Bright Data que utilice su zona de la API de Web Unlocker (por ejemplo, web_unlocker) en una URL de destino, que será proporcionada por el bloque «Entrada del agente». El parámetro format: "raw" garantiza que la API devuelva el resultado directamente en el cuerpo de la respuesta, en lugar de como una estructura JSON. El parámetro data_format: "markdown" configura la API para extraer el contenido del artículo en Markdown, que es un formato ideal para la ingesta por parte de agentes de IA.
Para ello, vaya al bloque «Create Dictionary» y haga clic en «Add Item». Defina los siguientes campos:
Zona:<YOUR_WEB_UNLOCKER_API_ZONE_NAME>(por ejemplo,«web_unlocker»)url: (déjelo en blanco por ahora, ya que se rellenará dinámicamente)formato:«raw»formato_de_datos:«markdown»
A continuación, conecta la salida «Diccionario» del bloque «Crear diccionario» a la entrada «Cuerpo» del bloque «Enviar solicitud web autenticada»: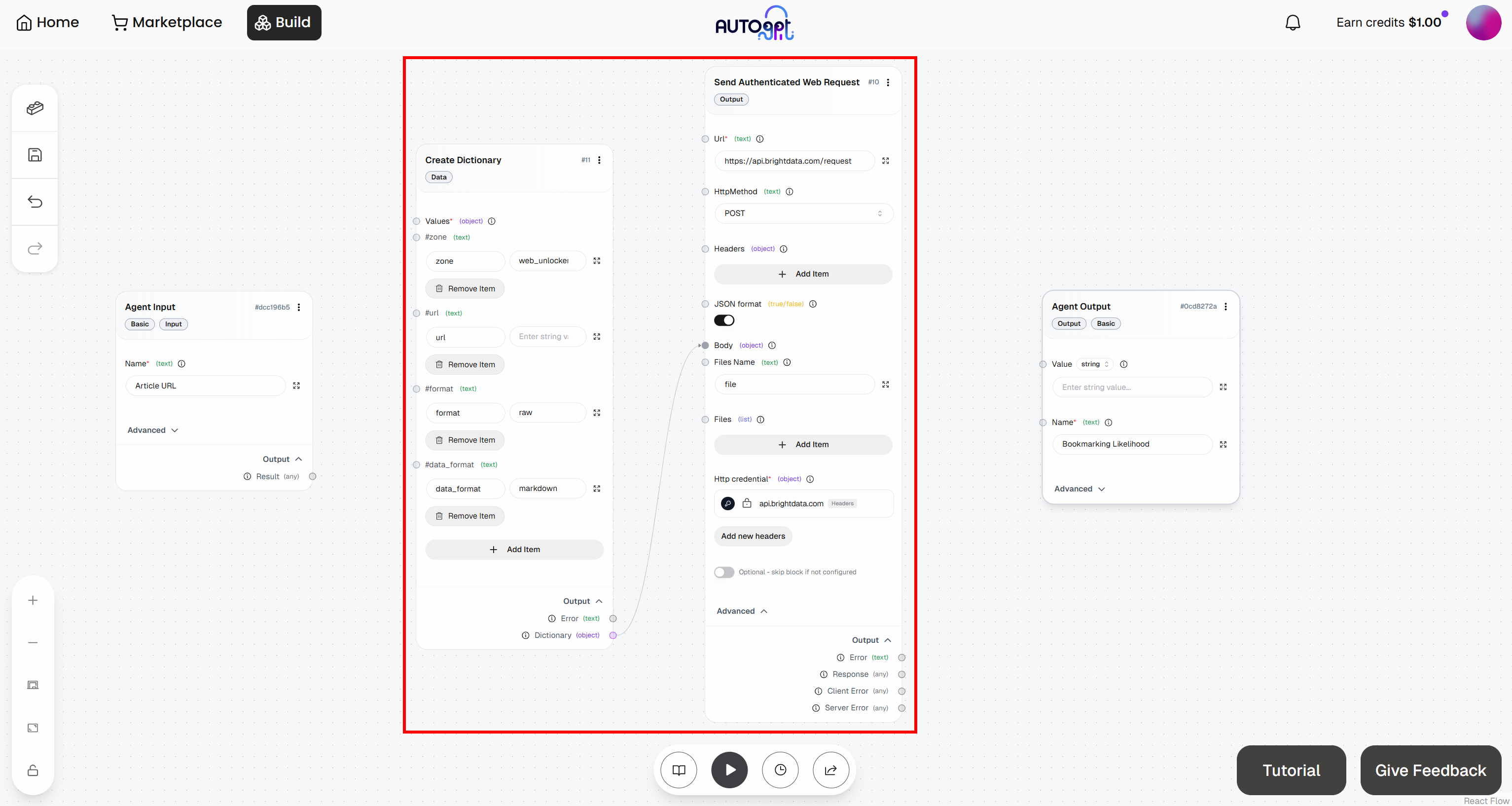
¡Genial! La integración de Bright Data en tu flujo de trabajo de AutoGPT ya está completa.
Paso n.º 7: Añadir el motor LLM
El último bloque que falta es el motor LLM, responsable de analizar el contenido Markdown obtenido mediante Scraping web a través de la API de Web Unlocker y asignarle una puntuación de marcador.
Dado que quieres que este flujo de trabajo evalúe diferentes artículos a lo largo del tiempo, debe producir un resultado coherente y estructurado.
Para lograrlo, utiliza el bloque «Generador de respuestas estructuradas con IA». Esto te permite indicar a un LLM que realice una tarea y devuelva los resultados en un formato predefinido.
Empieza añadiendo este bloque a tu flujo de trabajo: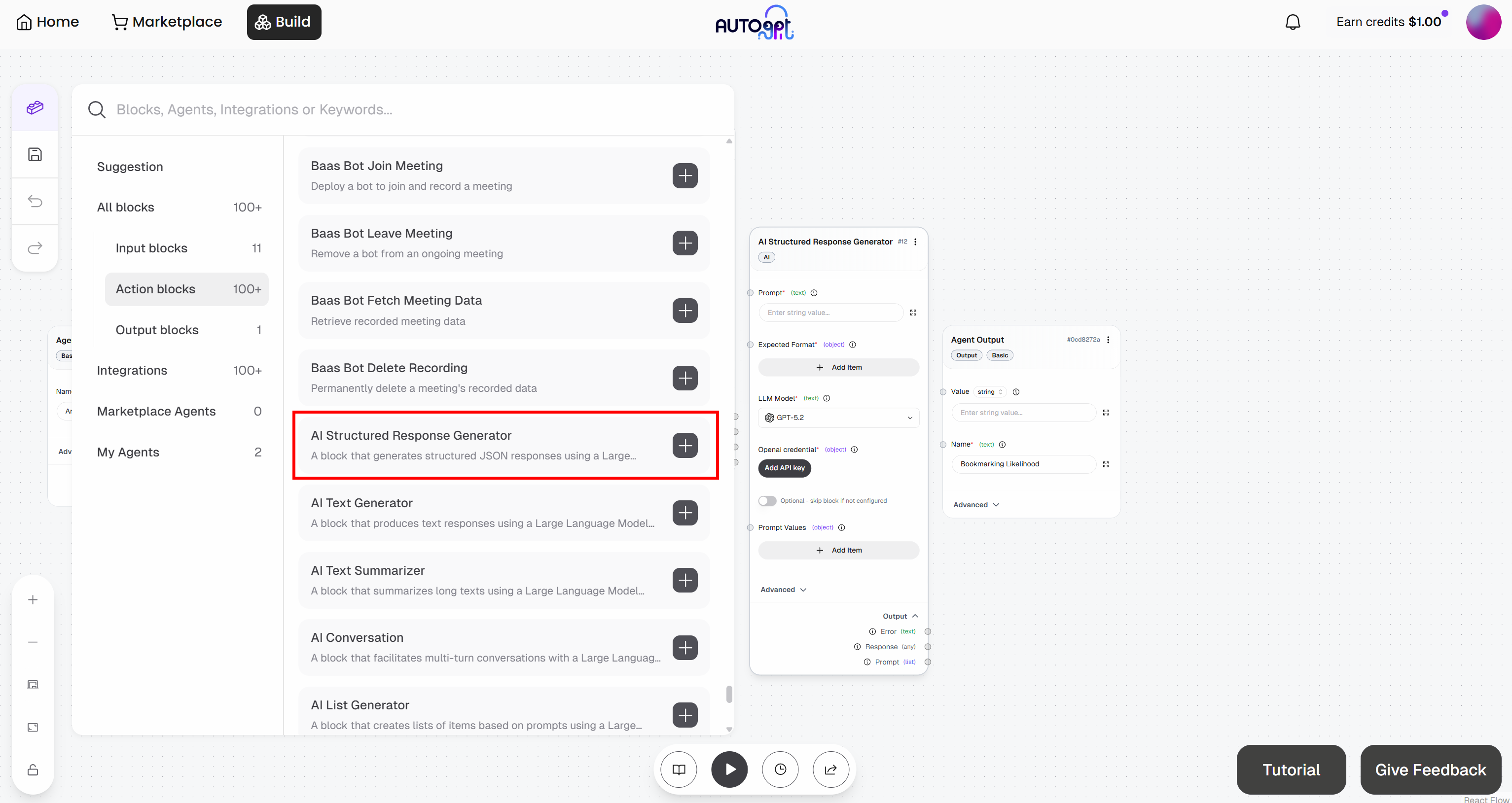
Conecta el bloque a tu cuenta de OpenAI haciendo clic en el botón «Añadir clave API». Introduce un nombre para tu clave, pega tu clave API de OpenAI y haz clic en «Añadir clave API»: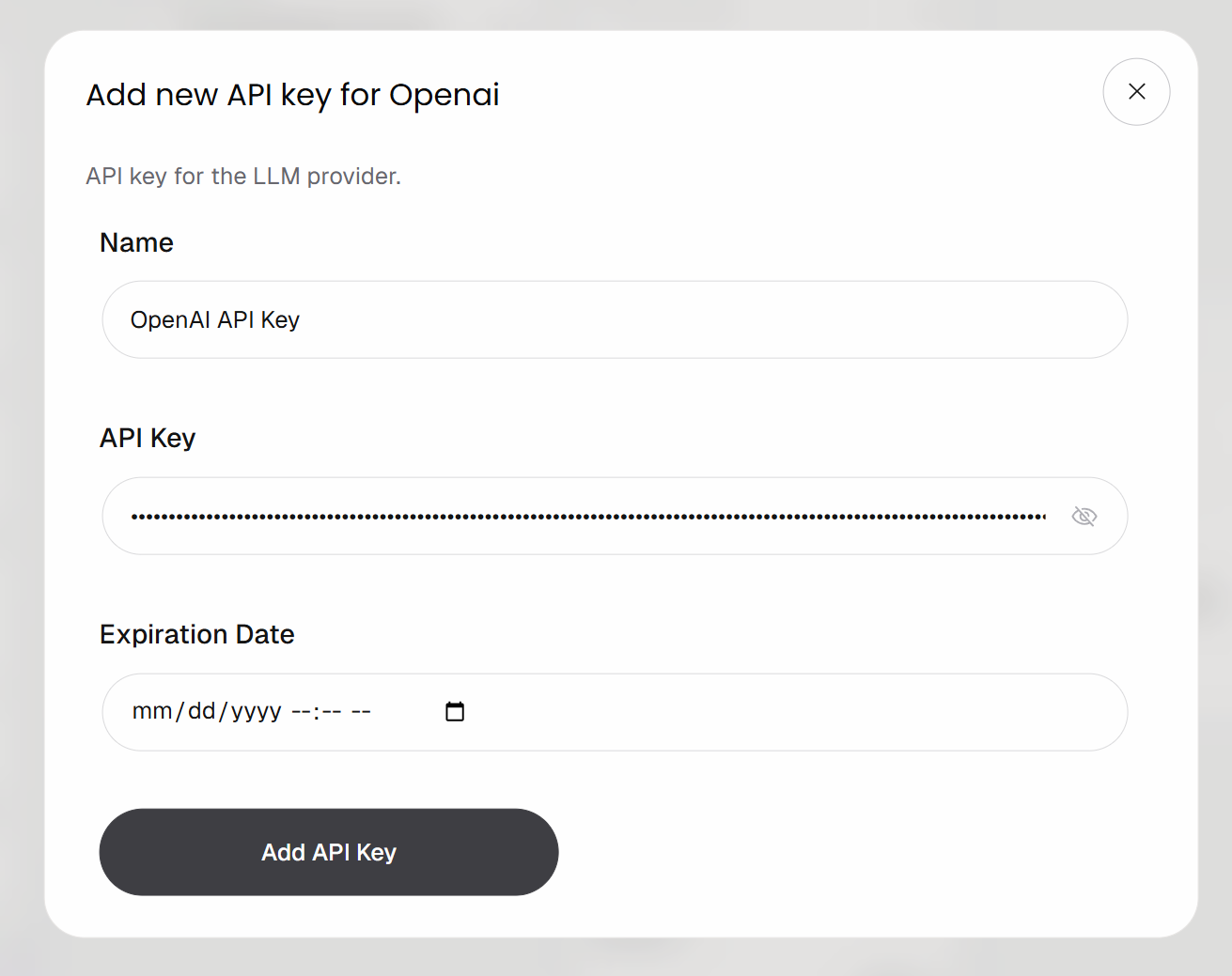
Tu bloque «Generador de respuestas estructuradas con IA» ya está autenticado y listo para llamar al modelo de OpenAI configurado.
Ahora, rellena el bloque con lo siguiente:
- Indicación:
Eres un evaluador de contenido experto.
Tu tarea consiste en analizar el siguiente artículo y determinar si merece la pena guardarlo en marcadores para consultarlo en el futuro.
Artículo:
"{{article}}"
Evalúa el artículo basándote en:
- Utilidad práctica (¿ofrece información útil?)
- Profundidad (¿es superficial o exhaustivo?)
- Relación señal-ruido (¿es conciso o está lleno de relleno?)
- Reutilización (¿merece la pena volver a consultarlo más adelante?)
Devuelve un objeto JSON con:
- «score»: un número entero del 1 al 10 (1 = no merece la pena guardarlo en favoritos, 10 = hay que guardarlo en favoritos)
- «comment»: una explicación concisa y en lenguaje natural (1-2 frases como máximo)
Pautas:
- Sé crítico y evita sobrevalorar
- Da puntuaciones más altas solo a contenidos con valor a largo plazo
- Evita comentarios genéricos
- *Modelo*: GPT-5.1 Mini (o cualquier otro modelo de OpenAI de uso general)En la indicación, fíjate en el marcador de posición {{article}}. Se trata de una variable que se sustituirá dinámicamente por un «valor de indicación». Concretamente, se sustituirá por el contenido Markdown devuelto por el bloque «Enviar solicitud web autenticada».
Para configurar un «valor de prompt», haz clic en «Añadir elemento» y define una variable llamada article. A continuación, conecta la salida «Respuesta» del bloque «Enviar solicitud web autenticada» al valor de prompt article: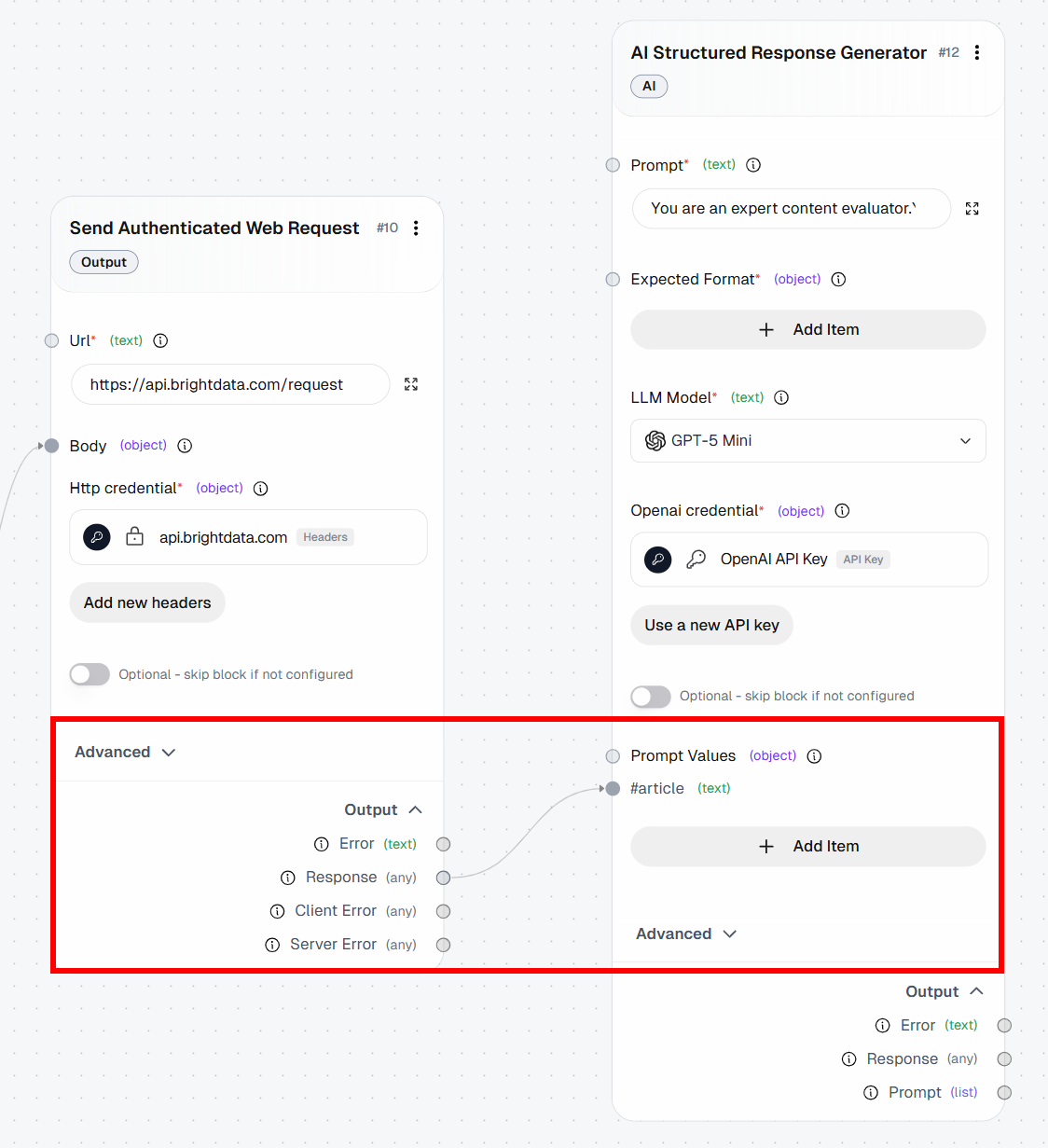
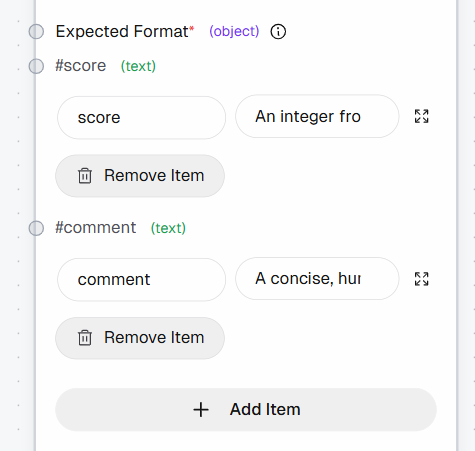
A continuación, define la salida estructurada añadiendo los siguientes campos a la sección «Formato esperado»:
puntuación: «Un número entero del 1 al 10 (1 = no merece la pena marcarlo como favorito, 10 = hay que marcarlo como favorito)»comentario: «Una explicación concisa y de estilo humano (1-2 frases como máximo)»
¡Genial! Tu flujo de trabajo de agente AutoGPT impulsado por Bright Data ya incluye todos los componentes básicos. Solo queda conectarlos todos.
Paso n.º 8: Conecta todos los bloques
Para finalizar el flujo de trabajo, conecta todos los bloques para crear un proceso completo.
Empieza conectando la salida «Resultado» del bloque «Entrada del agente» al campo url del bloque «Crear diccionario». Esto garantiza que la URL de entrada fluya desde la entrada del flujo de trabajo hacia la solicitud de la API de Web Unlocker, que extraerá la página y pasará el resultado al LLM para su análisis.
Por último, conecta la salida «Respuesta» del bloque «Generador de respuestas estructuradas de IA» al bloque «Salida del agente». Esto cierra el flujo de trabajo y completa el flujo de datos.
A continuación se muestra cómo debería quedar tu flujo de trabajo final de AutoGPT, mejorado con capacidades de Scraping web gracias a Bright Data: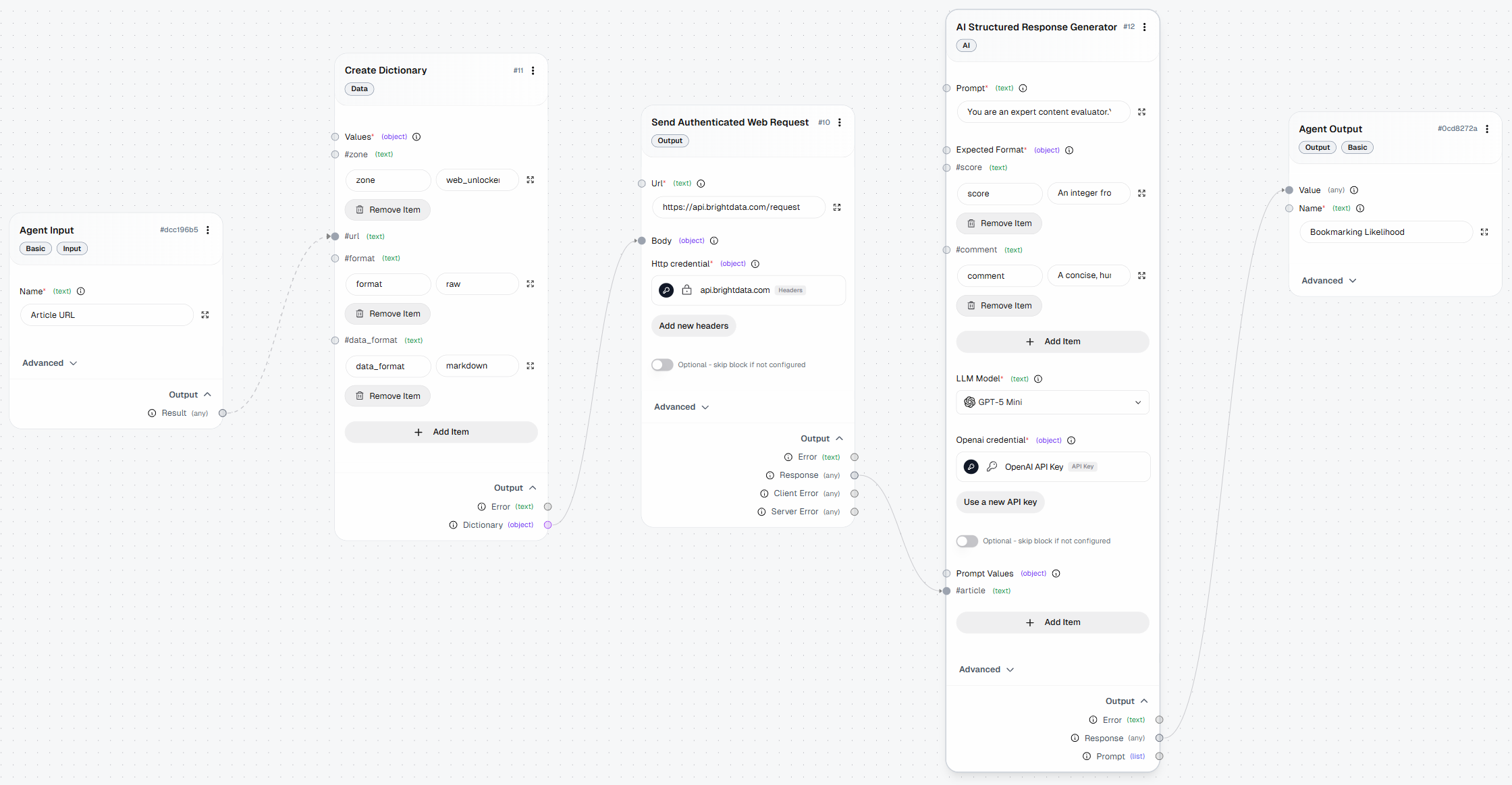
Paso n.º 9: Probar el agente
Haz clic en el botón «Run agent» para iniciar tu flujo de trabajo de agente y probarlo: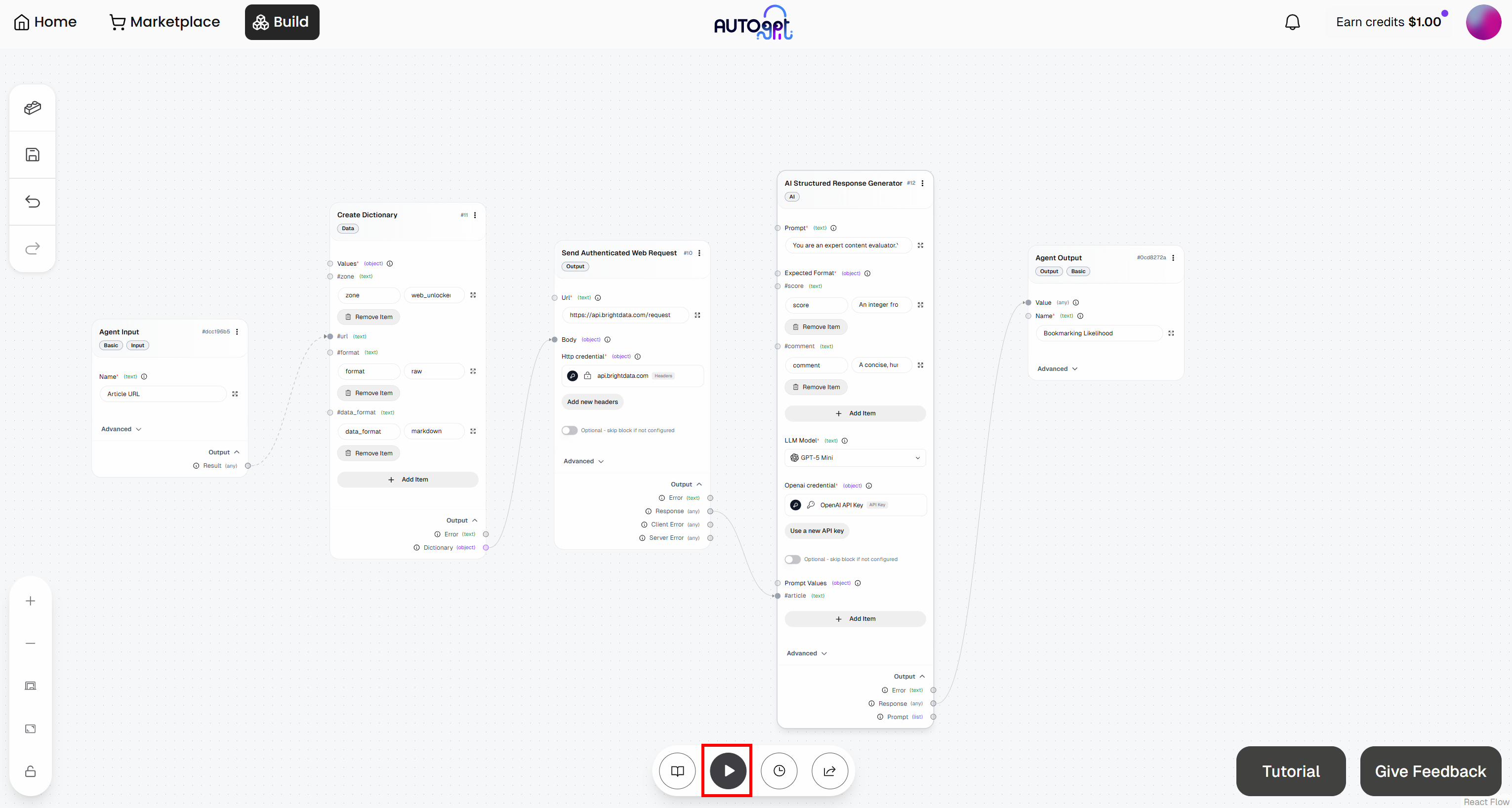
Se le pedirá que introduzca la URL de entrada del flujo de trabajo (es decir, la URL del artículo). Pegue una entrada de blog como esta:
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/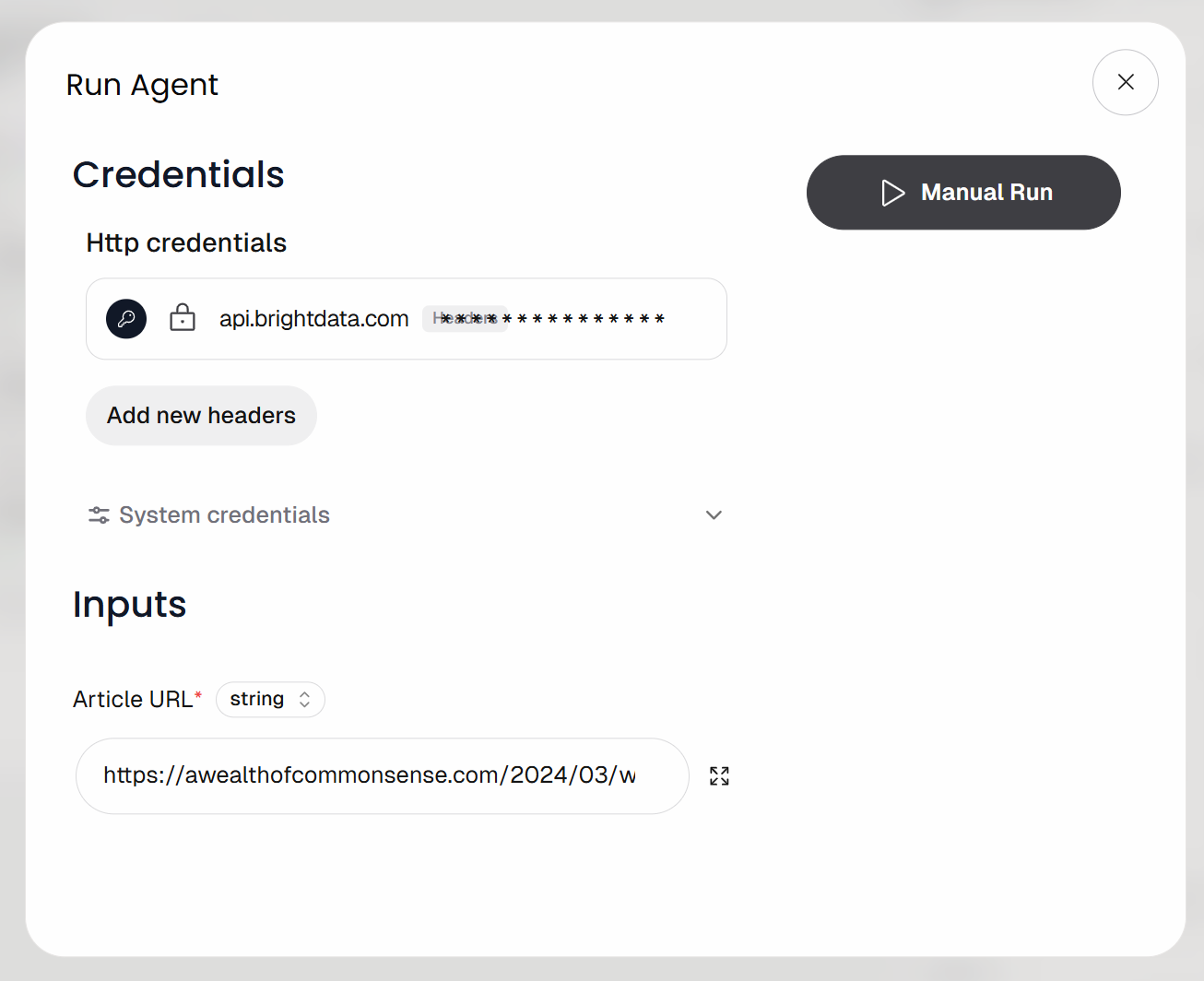
A continuación, inicia el flujo de trabajo haciendo clic en el botón «Ejecución manual». Esto es lo que deberías ver: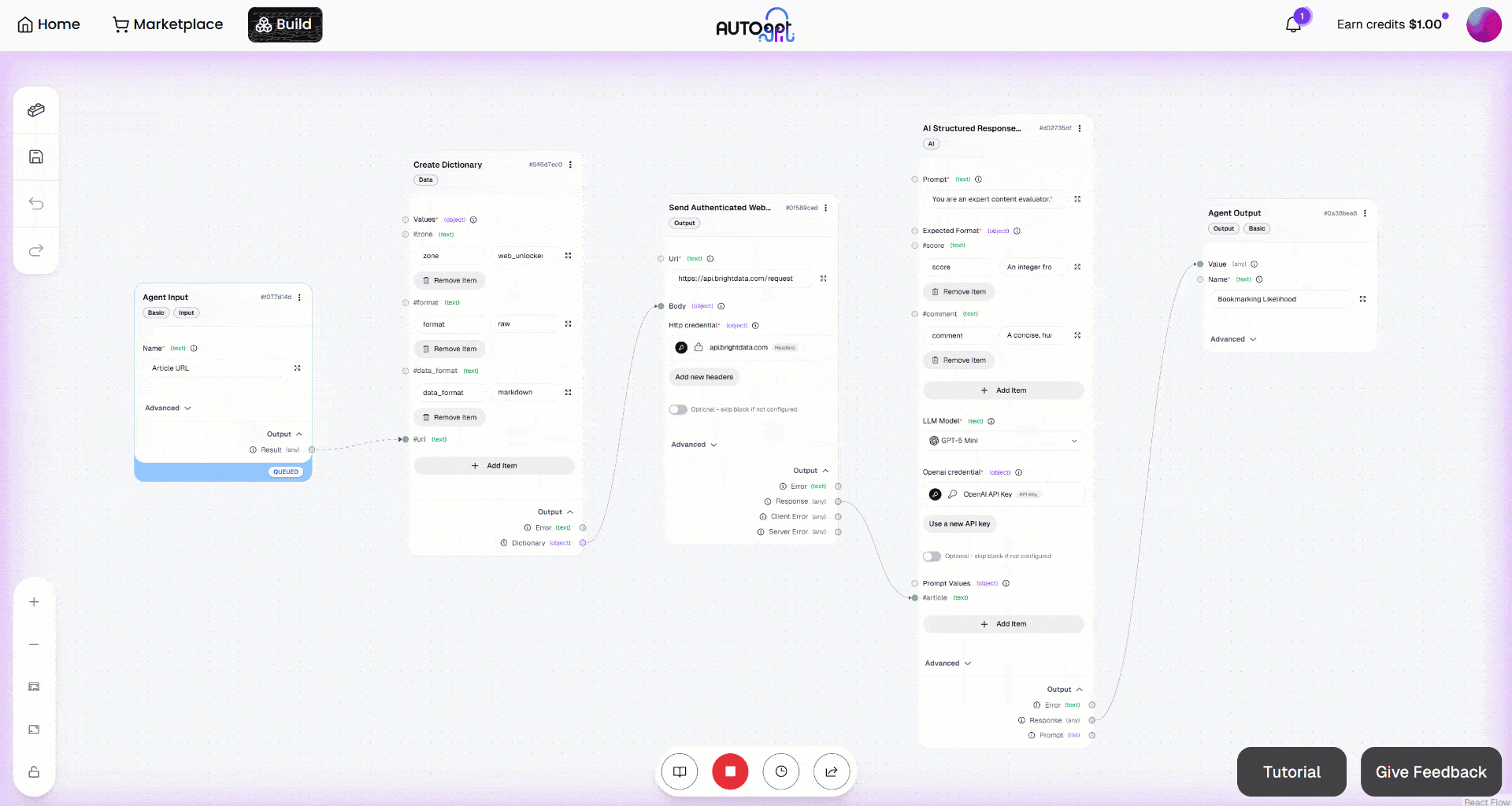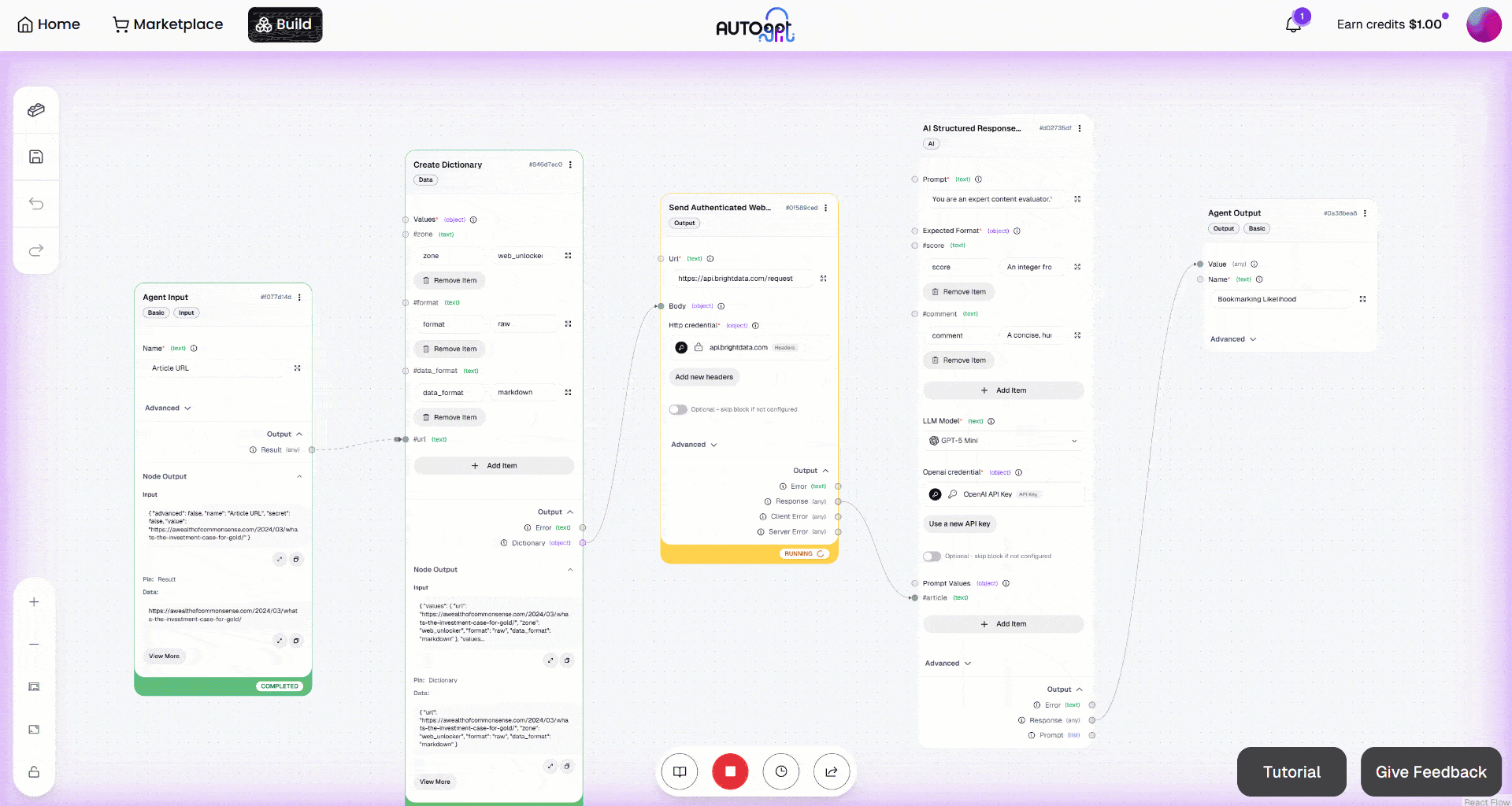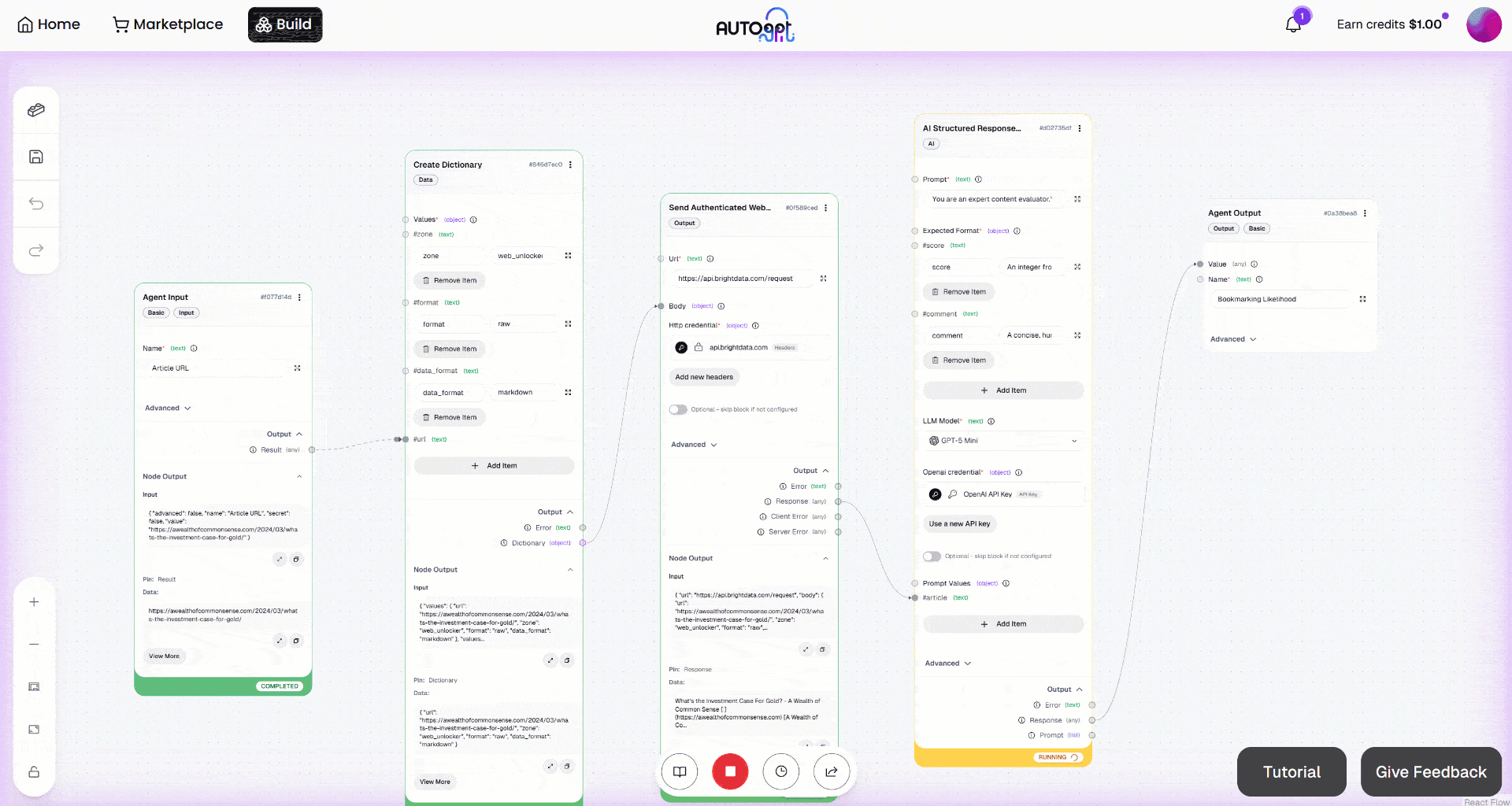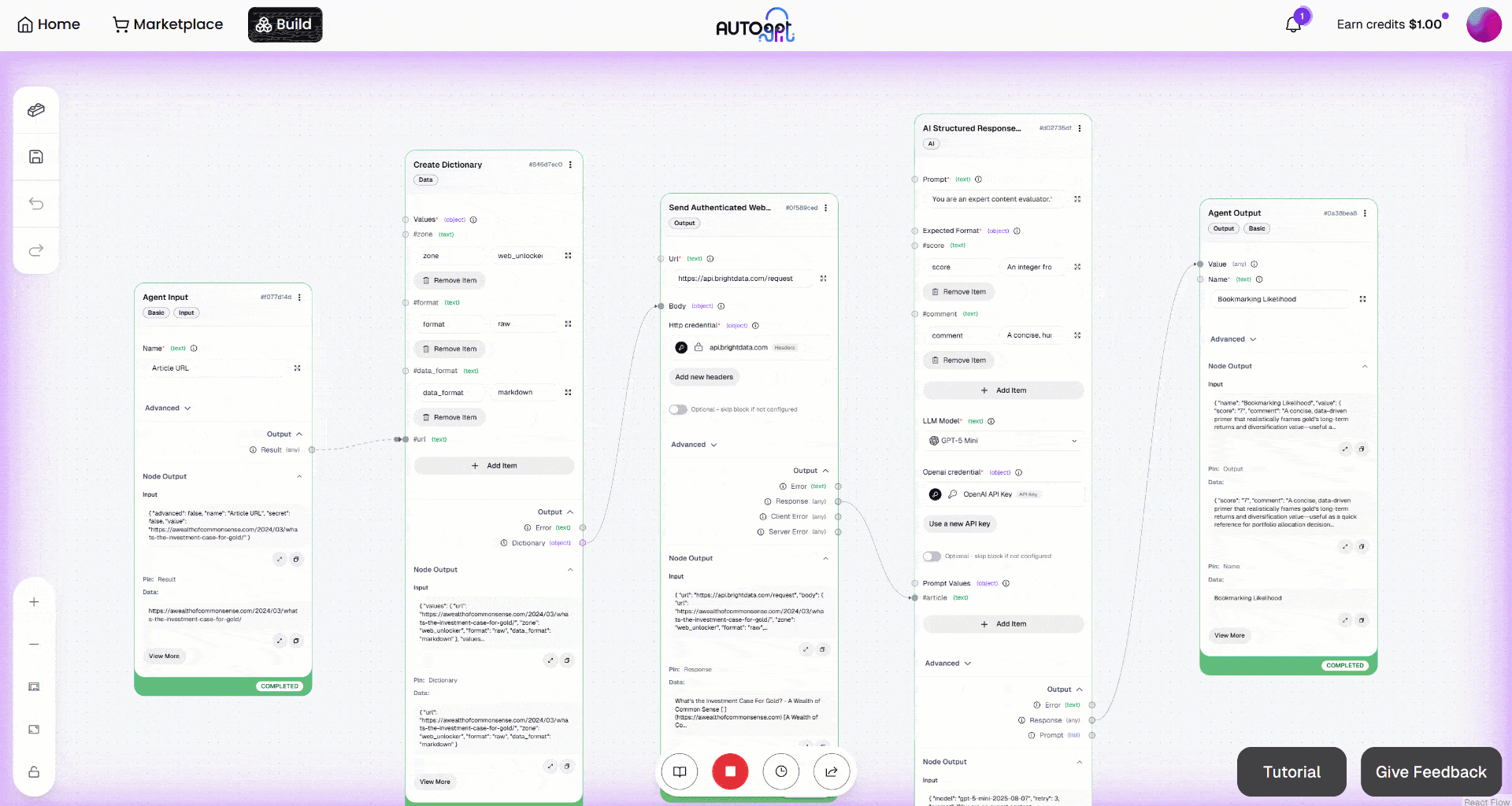
Despliega el resultado en el bloque «Resultado del agente». Verás que el agente IA ha generado un resultado como este: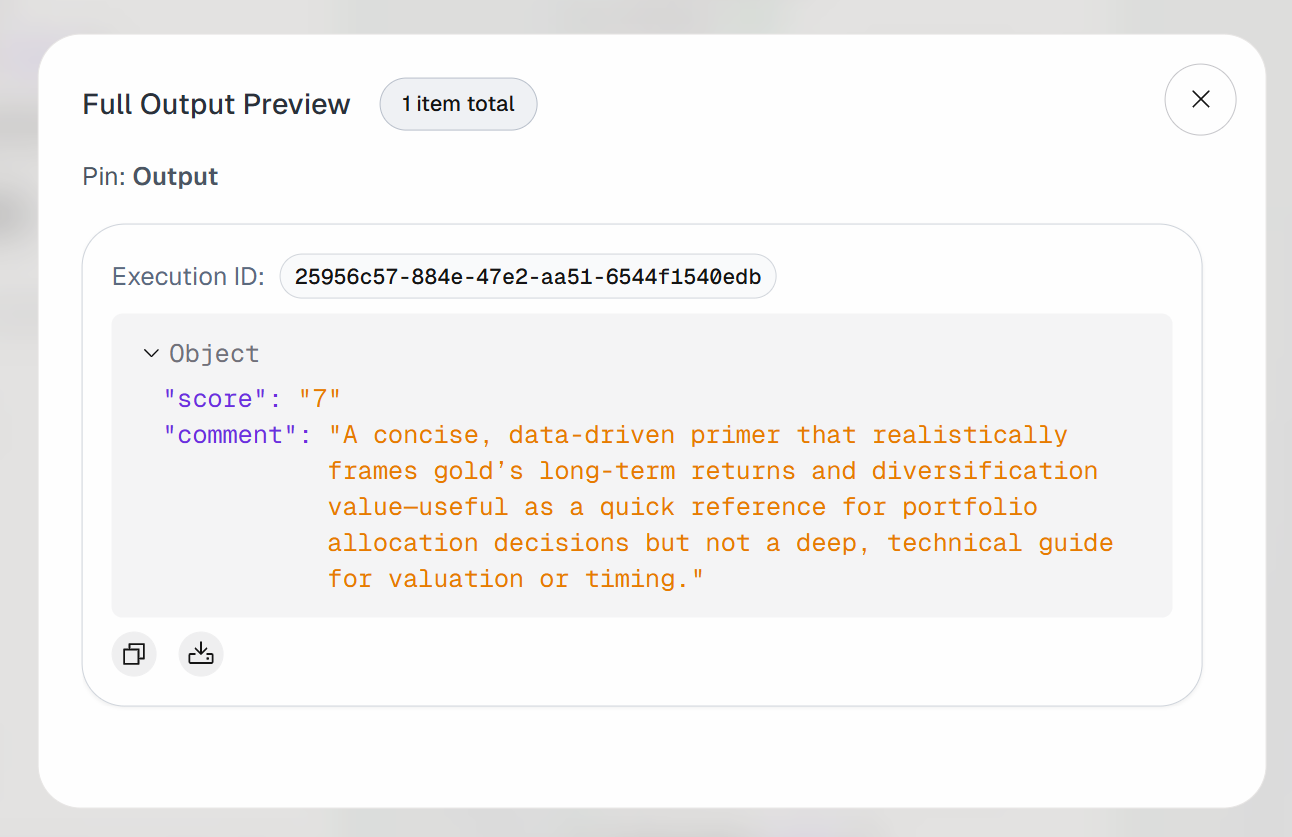
Por lo tanto, el artículo de entrada se considera lo suficientemente valioso como para guardarlo en los marcadores y leerlo más adelante.
Si examinas la salida del bloque «Send Authenticated Web Request», observarás:
Esto corresponde a la versión Markdown del artículo de entrada de destino: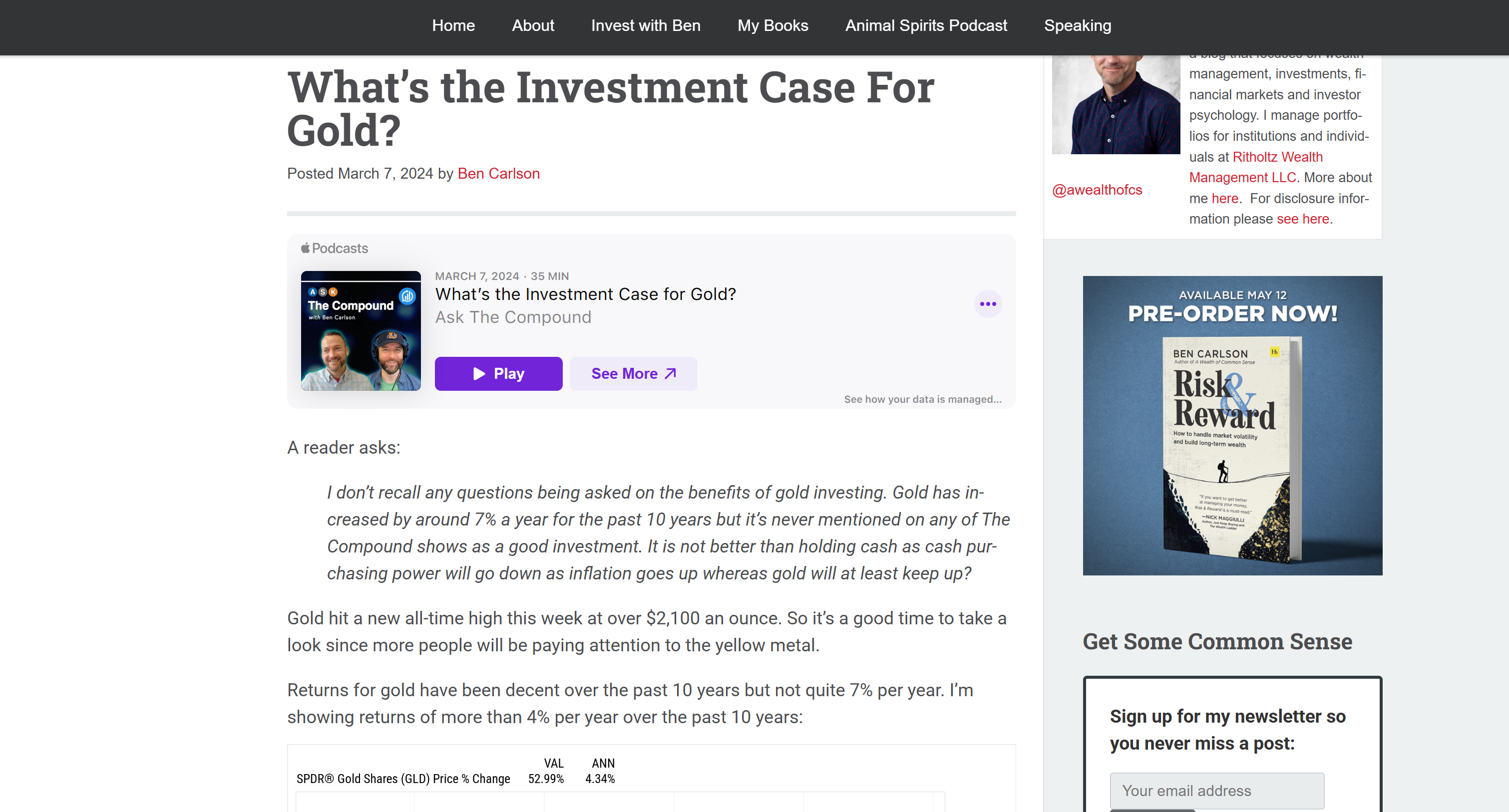
Esto confirma que la API de Bright Data Web Unlocker ha recuperado con éxito el contenido de la página rápidamente y en un formato que hace que el procesamiento de LLM sea más eficiente y eficaz.
¡Et voilà! Acabas de crear un agente de IA en AutoGPT que se integra con Bright Data para la recuperación dinámica de datos web.
Próximos pasos
Este ha sido un ejemplo sencillo, pero ten en cuenta que la integración de AutoGPT + Bright Data se puede ampliar para admitir flujos de trabajo de agentes mucho más avanzados.
Por ejemplo, con un enfoque similar, puedes conectar tu agente a otros productos basados en la API de Bright Data para añadir capacidades de búsqueda y rastreo web. Del mismo modo, puedes integrarlo con API de scraping que proporcionan fuentes de datos directas desde múltiples dominios.
Para potenciar tu agente, explora la amplia gama de capacidades que ofrece AutoGPT consultando la documentación oficial.
Conclusión
En esta entrada del blog, has aprendido a añadir las capacidades de exploración web, interacción, búsqueda y scraping de datos de Bright Data a AutoGPT. Esto permite a los agentes de IA superar las principales limitaciones de conocimiento e interacción típicas de los LLM estándar.
Has visto cómo crear un agente de IA sencillo que actúe como asesor de marcadores. Para crear flujos de trabajo de agentes más complejos —que requieran acceso a fuentes web en tiempo real, búsqueda web o interacciones web—, integra AutoGPT con el conjunto completo de servicios de Bright Data para IA.
¡Crea hoy mismo una cuenta gratuita de Bright Data y empieza a experimentar con nuestras soluciones de datos web preparadas para la IA!





