

En esta guía aprenderás:
- Qué es LlamaIndex y por qué se utiliza tanto.
- Lo que lo hace único para el desarrollo de agentes de IA, especialmente su soporte incorporado para integraciones de datos.
- Cómo utilizar LlamaIndex para construir un agente de IA con capacidades de recuperación de datos tanto de sitios generales como de motores de búsqueda específicos.
Sumerjámonos.
¿Qué es LlamaIndex?
LlamaIndex es un marco de datos Python de código abierto para crear aplicaciones basadas en LLM.
Le ayuda a crear flujos de trabajo y agentes de IA listos para la producción, capaces de encontrar y recuperar información relevante, sintetizar perspectivas, generar informes detallados, tomar acciones automatizadas y mucho más.
LlamaIndex es una de las bibliotecas de más rápido crecimiento para la construcción de agentes de IA, con más de 42k estrellas GitHub:
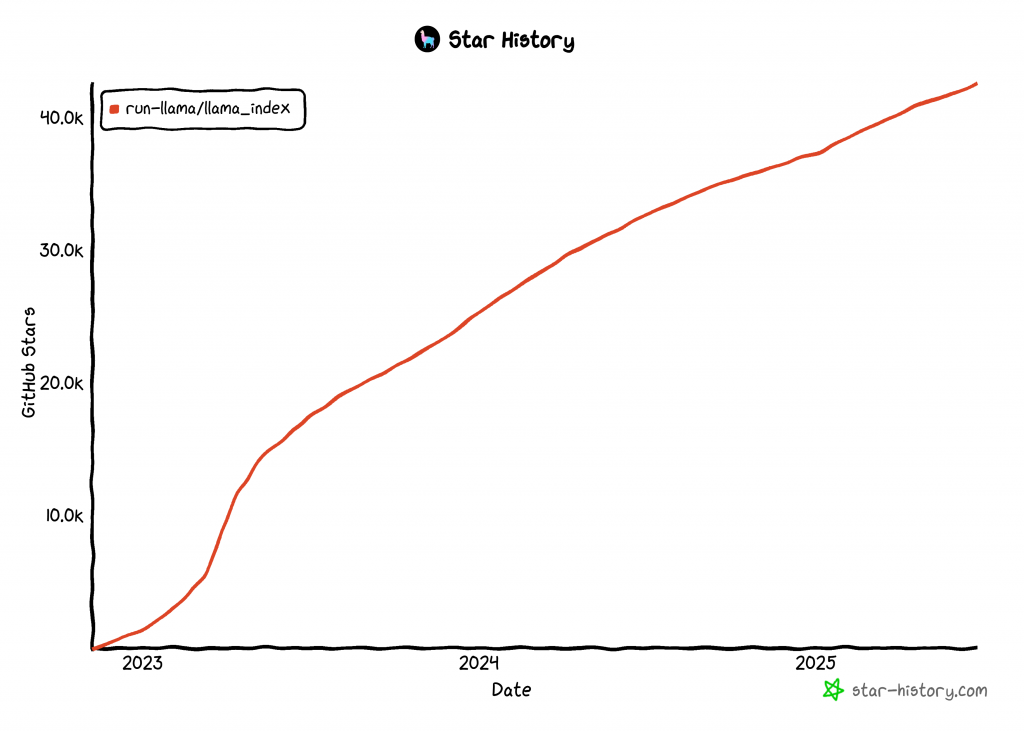
Integre datos en su agente de IA LlamaIndex
En comparación con otras tecnologías de creación de agentes de IA, LlamaIndex se centra en los datos. Por eso el repositorio GitHub del proyecto define LlamaIndex como un “marco de datos”.
En concreto, LlamaIndex aborda una de las mayores limitaciones de los LLM. Se trata de su desconocimiento de los acontecimientos actuales o en tiempo real. Esta limitación se debe a que los LLM se entrenan con conjuntos de datos estáticos y no tienen acceso integrado a información actualizada.
Para resolver ese problema, LlamaIndex introduce soporte para herramientas que:
- Proporcione conectores de datos para ingerir datos de API, PDF, documentos de Word, bases de datos SQL, páginas web, etc.
- Estructure sus datos mediante índices, gráficos y otros formatos optimizados para el consumo de LLM.
- Habilite la recuperación avanzada para que pueda introducir un mensaje LLM y recibir una respuesta enriquecida con conocimientos, basada en el contexto pertinente.
- Soporta una integración perfecta con marcos externos como LangChain, Flask, Docker y ChatGPT.
En otros términos, la construcción con LlamaIndex normalmente significa combinar la biblioteca central con un conjunto de plugins / integraciones adaptadas a su caso de uso. Por ejemplo, explore un escenario de raspado web LlamaIndex.
Actualmente, la Web es la mayor y más completa fuente de datos del planeta. Por lo tanto, lo ideal sería que un agente de IA tuviera acceso a ella para fundamentar sus respuestas y realizar tareas con mayor eficacia. Aquí es donde entran en juego las herramientas de LlamaIndex Bright Data.
Con las herramientas de Bright Data, su agente de IA LlamaIndex gana:
- Funcionalidad de web scraping en tiempo real desde cualquier página web.
- Datos estructurados de productos y plataformas de sitios como Amazon, LinkedIn, Zillow, Facebook y muchos otros.
- La capacidad de recuperar los resultados de los motores de búsqueda para cualquier consulta.
- Captura visual de datos mediante capturas de pantalla a toda página, útiles para resumir o realizar análisis visuales.
Vea cómo funciona esta integración en el próximo capítulo.
Construya un agente LlamaIndex que pueda consultar la Web utilizando herramientas de Bright Data
En esta sección paso a paso, aprenderá a utilizar LlamaIndex para crear un agente de IA en Python que se conecte a las herramientas de Bright Data.
Esta integración dotará a su agente de potentes funciones de acceso a datos web. En concreto, el agente de IA obtendrá la capacidad de extraer contenido de cualquier página web, obtener resultados de motores de búsqueda en tiempo real y mucho más. Para más información, consulte nuestra documentación oficial.
Siga los pasos que se indican a continuación para crear su agente de IA basado en Bright Data utilizando LlamaIndex.
Requisitos previos
Para seguir este tutorial, necesitarás lo siguiente:
- Python 3.9 o superior instalado en su máquina (se recomienda la última versión).
- Una clave API de Bright Data para la integración con
BrightDataToolSpec. - Una clave API de un proveedor LLM soportado (en esta guía, utilizaremos Gemini, que es de uso gratuito a través de API. Siéntete libre de usar cualquier proveedor soportado por LlamaIndex).
No se preocupe si todavía no tiene una clave API de Gemini o Bright Data. Le explicaremos cómo crear ambas en los pasos siguientes.
Paso 1: Cree su proyecto Python
Comienza abriendo un terminal y creando una nueva carpeta para tu proyecto de agente de IA LlamaIndex:
mkdir llamaindex-bright-data-agentllamaindex-bright-data-agent/ contendrá el código para su agente de IA con capacidades de recuperación de datos web impulsadas por Bright Data.
A continuación, entra en el directorio del proyecto y crea un entorno virtual dentro de él:
cd llamaindex-bright-data-agent
python -m venv venvAhora, abre la carpeta del proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code (con la extensión Python) o PyCharm Community Edition.
Crea un nuevo archivo llamado agent.py en la raíz de la carpeta. La estructura de tu proyecto ahora debería verse así:
llamaindex-bright-data-agent/
├── venv/
└── agent.pyEn tu terminal, activa el entorno virtual. En Linux o macOS, ejecuta este comando:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activateEn los próximos pasos, le guiaremos a través de la instalación de los paquetes necesarios. Aún así, si prefieres instalarlos todos ahora, ejecuta:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-gemini llama-indexNota: Estamos instalando llama-index-llms-gemini porque este tutorial utiliza Gemini como proveedor LLM. Si está planeando utilizar un proveedor diferente, asegúrese de instalar la integración LlamaIndex correspondiente.
¡Ya está todo listo! Ahora tiene un entorno de desarrollo Python listo para construir un agente de IA utilizando LlamaIndex y las herramientas de Bright Data.
Paso 2: Configurar las variables de entorno Lectura
Su agente LlamaIndex se conectará a servicios externos como Gemini y Bright Data a través de claves API. Por razones de seguridad, nunca codifique las claves API directamente en su código Python. En su lugar, utilice variables de entorno para mantenerlas privadas.
Para facilitar el trabajo con variables de entorno, instale la biblioteca python-dotenv. En tu entorno virtual activado, ejecuta
pip install python-dotenvA continuación, abra su archivo agent.py y añada las siguientes líneas en la parte superior para cargar variables desde un archivo .env:
from dotenv import load_dotenv
load_dotenv()La función load_dotenv() busca un archivo .env en el directorio raíz del proyecto y carga automáticamente sus valores en el entorno.
Ahora, crea un archivo .env junto a tu archivo agent.py, así:
llamaindex-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.pyPerfecto. Ya has configurado una forma segura de gestionar las credenciales sensibles de la API para servicios de terceros. Tim para continuar la configuración inicial rellenando el archivo .env con los envs requeridos.
Paso 3: Empezar con Bright Data
En el momento de redactar este documento, BrightDataToolSpec expone las siguientes herramientas dentro de LlamaIndex:
scrape_as_markdown: Extrae el contenido en bruto de cualquier página web y lo devuelve en formato Markdown.get_screenshot: Captura una pantalla completa de una página web y la guarda localmente.motor_buscador: Realiza una consulta de búsqueda en motores de búsqueda como Google, Bing, Yandex, etc. Devuelve la SERP completa o una versión estructurada en JSON de esos datos.web_data_feed: Recupera datos JSON estructurados de plataformas conocidas.
Las tres primeras herramientas (scrape_as_markdown, get_screenshot y search_engine) utilizan la API Web Unlocker de Bright Data. Esta solución abre la puerta al web scraping y a las capturas de pantalla de cualquier sitio, incluso de aquellos con una estricta protección anti-bot. Además, admite el acceso a datos web SERP de los principales motores de búsqueda.
En cambio, web_data_feed aprovecha la API Web Scraper de Bright Data. Este punto final devuelve datos preestructurados de una lista predefinida de plataformas compatibles, como Amazon, Instagram, LinkedIn y ZoomInfo, entre otras.
Para integrar estas herramientas, necesitarás:
- Active la solución Web Unlocker en su panel de Bright Data.
- Recupere su token de Bright Data API, que le permite acceder tanto a la API de Web Unlocker como a la de Web Scraper.
Siga los pasos que se indican a continuación para completar la configuración.
En primer lugar, si aún no tiene una cuenta de Bright Data, siga adelante y [cree una](). Si ya tiene una cuenta, inicie sesión y abra su panel de control. Haga clic en el botón “Obtener productos proxy”:
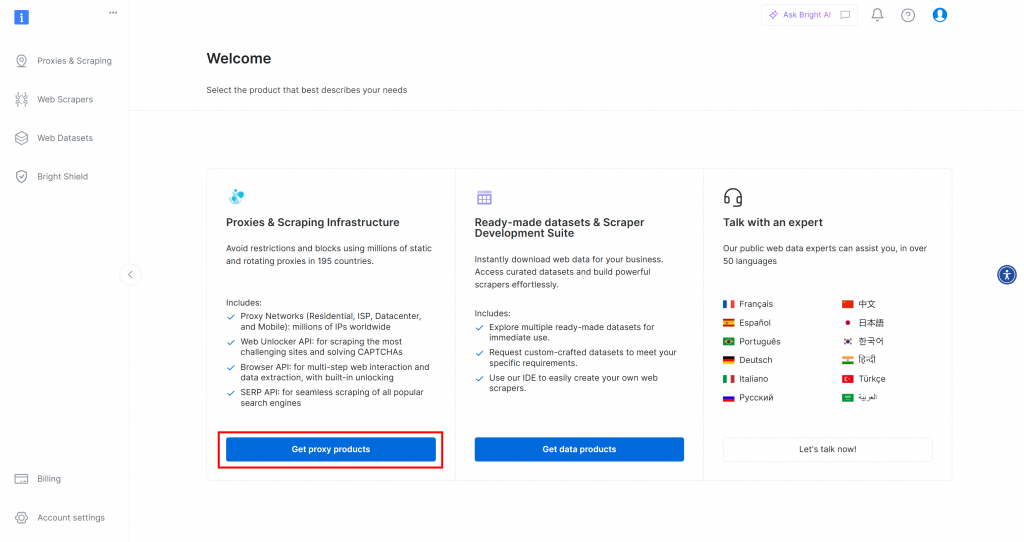
Será redirigido a la página “Proxies & Scraping Infrastructure”:
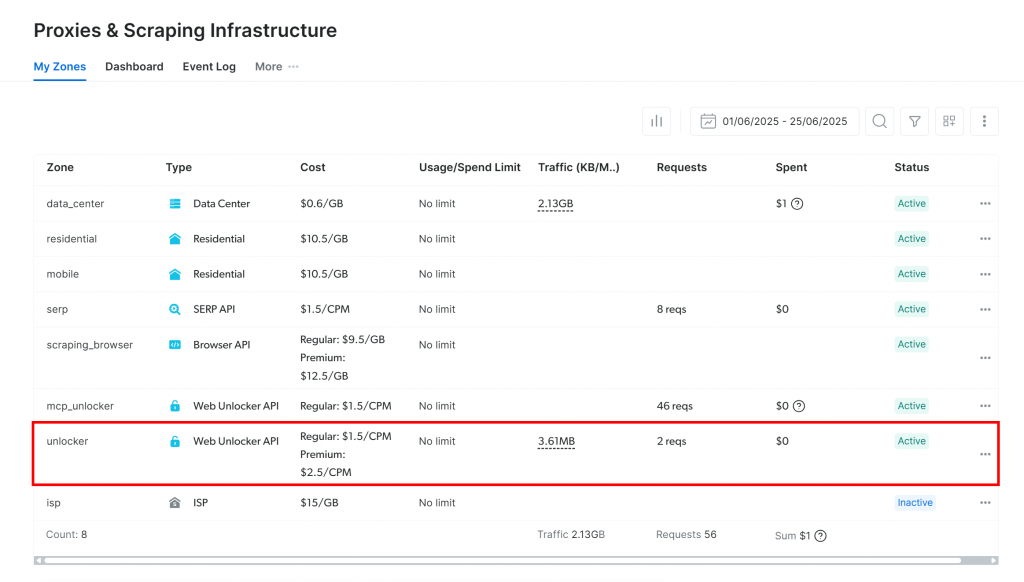
Si ya ves una zona API de Web Unlocker activa (como arriba), estás listo. El nombre de la zona(unlocker, en este caso) es importante, ya que lo necesitará más adelante en su código.
Si aún no dispone de una, desplácese hasta la sección “Web Unlocker API” y haga clic en “Crear zona”:
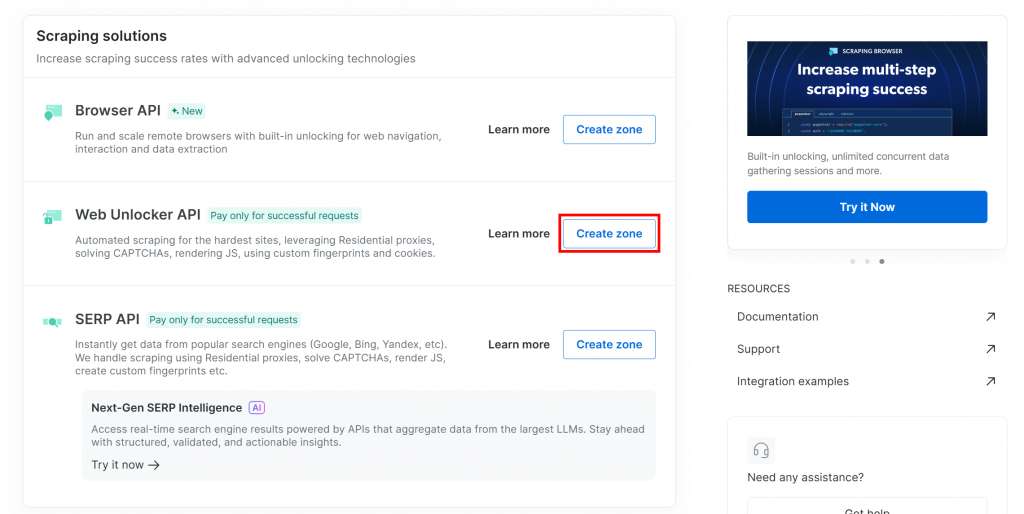
Dale a tu nueva zona un nombre, como desbloqueador, activa las funciones avanzadas para un mejor rendimiento, y haz clic en “Añadir”:
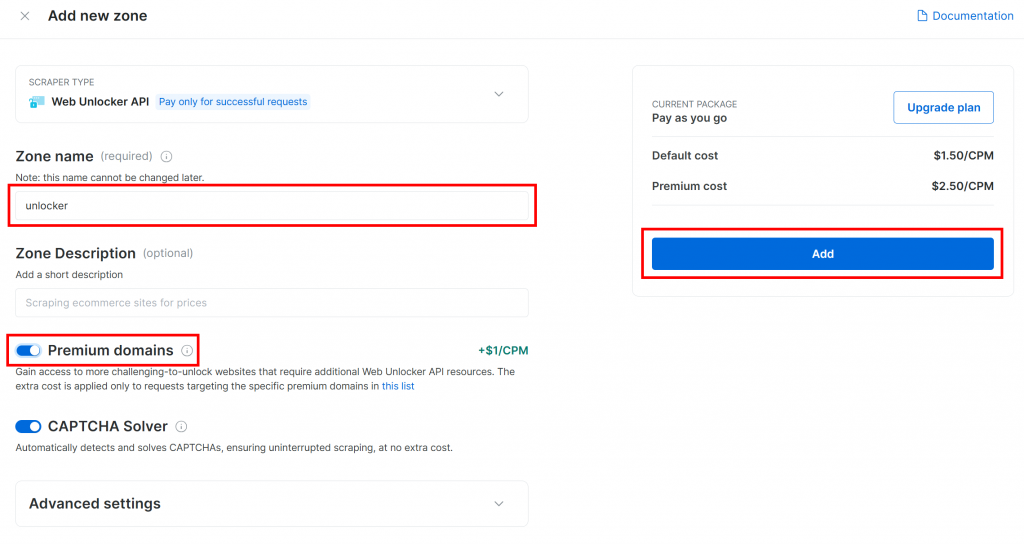
Una vez creada la zona, se le redirigirá a la página de configuración de la zona:
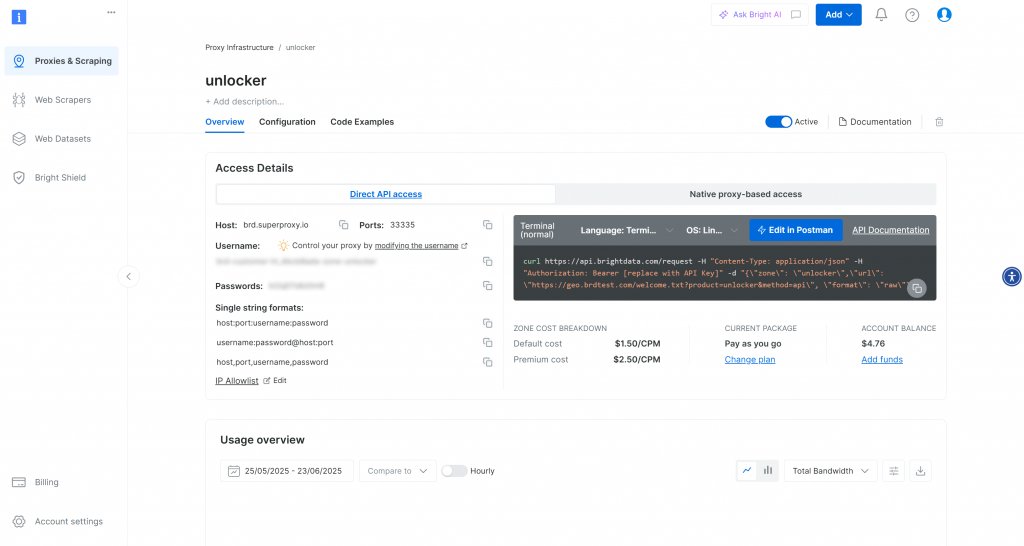
Asegúrese de que el conmutador de activación está en “Activo”. Esto confirma que la zona está correctamente configurada y lista para su uso.
A continuación, siga la guía oficial de Bright Data para generar su clave API. Una vez que la tenga, guárdela de forma segura en su archivo .env de la siguiente forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Sustituya el por el valor real de su clave API.
¡Sorprendente! Es hora de integrar las herramientas de Bright Data en su script de agente LlamaIndex.
Paso 4: Instalar y configurar las herramientas de datos de LlamaIndex Bright
En agent.py, comience cargando su clave API de Bright Data desde el entorno:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")No olvides importar os de la biblioteca estándar de Python:
import osCon su entorno virtual activado, instale el paquete de herramientas LlamaIndex Bright Data:
pip install llama-index-tools-brightdataEn su archivo agent.py, importe la clase BrightDataToolSpec:
from llama_index.tools.brightdata import BrightDataToolSpecA continuación, cree una instancia de BrightDataToolSpec utilizando su clave API y el nombre de la zona:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="<BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>", # Replace with the actual value
verbose=True, # Useful while developing
)Sustituya el por el nombre de la zona API de Web Unlocker que configuró anteriormente. En este caso, es unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True,
)Tenga en cuenta que la opción verbose se ha establecido en True. Esto es útil durante el desarrollo, ya que imprime información útil sobre lo que está sucediendo cuando el agente LlamaIndex realiza solicitudes a través de Bright Data.
A continuación, convierta la especificación de herramientas en una lista de herramientas utilizables en su agente:
brightdata_tools = brightdata_tool_spec.to_tool_list()¡Fantástico! Las herramientas de Bright Data ya están integradas y listas para alimentar su agente LlamaIndex. El siguiente paso es conectar su LLM.
Paso nº 5: Preparar el modelo LLM
Para utilizar Gemini (el proveedor de LLM elegido) comience por instalar el paquete de integración necesario:
pip install llama-index-llms-google-genaiA continuación, importa la clase GoogleGenAI del paquete instalado:
from llama_index.llms.google_genai import GoogleGenAIAhora, inicializa el LLM Gemini así:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)En este ejemplo, estamos utilizando el modelo gemini-2.5-flash. Puede cambiarlo por cualquier otro modelo Gemini compatible según sea necesario.
Entre bastidores, GoogleGenAI busca automáticamente una variable de entorno llamada GEMINI_API_KEY. Para establecerla, abre tu archivo .env y añade la siguiente línea:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Sustituya el con su clave Gemini API real. Si no dispone de una, recupérela gratuitamente siguiendo la guía oficial.
Nota: Si prefiere utilizar un proveedor LLM diferente, LlamaIndex admite muchas opciones. Consulte la documentación oficial de LlamaIndex para obtener instrucciones de configuración.
¡Buen trabajo! Ahora tiene todos los componentes básicos conectados para construir un agente LlamaIndex con capacidades de recuperación de datos web.
Paso nº 6: Crear el agente LlamaIndex
En primer lugar, instale el paquete principal de LlamaIndex:
pip install llama-indexLuego, en tu archivo agent.py, importa la clase FunctionCallingAgent:
from llama_index.core.agent import FunctionCallingAgentFunctionCallingAgent es un tipo especial de agente de IA de LlamaIndex que puede interactuar con herramientas externas, como las herramientas de Bright Data que configuró anteriormente.
Inicialice el agente con sus herramientas LLM y Bright Data de la siguiente manera:
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)Esto configura un agente de IA que procesa las entradas del usuario utilizando su LLM y puede llamar a las herramientas de Bright Data para recuperar información según sea necesario. El indicador verbose=True es útil durante el desarrollo porque muestra qué herramientas utiliza el agente para cada solicitud.
¡Bien hecho! La integración de LlamaIndex + Bright Data está completa. El siguiente paso es construir el REPL para uso interactivo.
Paso 7: Implementar el REPL
REPL significa “Read-Eval-Print Loop” (bucle de lectura, evaluación e impresión) y es un patrón de programación interactivo en el que puede introducir comandos, hacer que se evalúen y ver los resultados inmediatamente. En este contexto, usted:
- Introduzca un comando o tarea.
- Deja que el agente de IA lo evalúe y lo gestione.
- Véase la respuesta.
Este bucle continúa indefinidamente, hasta que escribas "exit".
Cuando se trata de agentes de IA, el REPL tiende a ser más práctico que enviar prompts aislados. La razón es que permite a tu agente LlamaIndex mantener el contexto de la sesión, mejorando sus respuestas al aprender de interacciones anteriores.
Ahora, implementa la lógica REPL en agent.py como se muestra a continuación:
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Este REPL:
- Lee la entrada del usuario desde la línea de comandos con
input(). - Evalúalo utilizando el agente LlamaIndex impulsado por Gemini y Bright Data con
agent.chat(). - Imprime la respuesta en la consola.
¡Fantástico! El agente de IA LlamaIndex está listo.
Paso nº 8: Póngalo todo junto y ejecute el agente
Esto es lo que tu archivo agent.py debería contener ahora:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent import FunctionCallingAgent
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True, # Useful while developing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Ejecute el script del agente utilizando el siguiente comando:
python agent.pyCuando se inicie el script, verás algo como esto:

Introduzca el siguiente mensaje en el terminal:
Generate a report summarizing the most important information about the product "Death Stranding 2" using data from its Amazon page: "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"El resultado será:
Eso fue bastante rápido, así que vamos a desglosar lo que pasó:
- El agente identifica que la tarea requiere datos de productos de Amazon, por lo que llama a la herramienta
web_data_feedcon esta entrada:{"source_type": "amazon_product", "url": "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"} - Esta herramienta consulta de forma asíncrona la API Amazon Web Scraper de Bright Data para obtener datos estructurados de productos.
- Una vez devuelta la respuesta JSON, el agente la alimenta al LLM Gemini.
- Gemini procesa los datos frescos y genera un resumen claro y preciso.
En otras palabras, dada la petición, el agente selecciona inteligentemente la mejor herramienta. En este caso, es web_data_feed. Recupera datos de productos en tiempo real de la página de Amazon con un enfoque asíncrono. A continuación, el LLM los utiliza para generar un resumen significativo.
En este caso, el agente de IA regresó:
Here's a summary report for "Death Stranding 2: On The Beach - PS5" based on its Amazon product page:
**Product Report: Death Stranding 2: On The Beach - PS5**
* **Title:** Death Stranding 2: On The Beach - PS5
* **Brand/Manufacturer:** Sony Interactive Entertainment
* **Price:** $69.99 USD
* **Release Date:** June 26, 2026
* **Availability:** Available for pre-order.
**Description:**
"Death Stranding 2: On The Beach" is an upcoming PlayStation 5 title from legendary game creator Hideo Kojima. Players will embark on a new journey with Sam and his companions to save humanity from extinction, traversing a world filled with otherworldly enemies and obstacles. The game explores the question of human connection and promises to once again change the world through its unique narrative and gameplay.
**Key Features:**
* **Pre-order Bonus:** Includes Quokka Hologram, Battle Skeleton Silver (LV1,LV2,LV3), Boost Skeleton Silver (LV1,LV2,LV3), and Bokka Silver (LV1,LV2,LV3).
* **Open World:** Features large, varied open-world environments with unique challenges.
* **Gameplay Choices:** Offers multiple approaches to combat and stealth, allowing players to choose between aggressive tactics, sneaking, or avoiding danger.
* **New Story:** Continues the narrative from the original Death Stranding, following Sam on a fresh journey with unexpected twists.
* **Player Interaction:** Player actions can influence how other players interact with the game's world.
**Category & Ranking:**
* **Categories:** Video Games, PlayStation 5, Games
* **Best Sellers Rank:** #10 in Video Games, #1 in PlayStation 5 Games
**Sales Performance:**
* **Bought in past month:** 7,000 unitsFíjese en que el agente de la IA no podría lograr ese resultado sin las herramientas de Bright Data. Esto se debe a que
- El producto Amazon elegido es un producto nuevo y los LLM no se entrenan con datos tan recientes.
- Es posible que los LLM no puedan raspar o acceder por sí mismos a páginas web en tiempo real.
- El scraping de productos de Amazon es notoriamente difícil debido a los estrictos sistemas anti-bot como el famoso CAPTCHA de Amazon.
Importante: Si prueba otras solicitudes, verá que el agente selecciona y utiliza automáticamente las herramientas configuradas adecuadas para recuperar los datos que necesita para generar respuestas fundamentadas.
¡Et voilà! Ahora dispone de un agente de IA LlamaIndex con funciones de acceso a datos web de primera categoría, impulsado por la integración con Bright Data.
Conclusión
En este artículo, has aprendido a utilizar LlamaIndex para construir un agente de IA con acceso en tiempo real a datos web, gracias a las herramientas de Bright Data.
Esa integración proporciona a su agente la capacidad de recuperar contenido web público en formato Markdown, formatos JSON estructurados e incluso como capturas de pantalla. Esto es válido tanto para sitios web como para motores de búsqueda.
Ten en cuenta que la integración vista aquí era sólo un ejemplo básico. Si su objetivo es crear agentes más avanzados, necesitará herramientas fiables para recuperar, validar y transformar datos web en tiempo real. Eso es exactamente para lo que está construida la infraestructura de IA de Bright Data.
Cree una cuenta gratuita en Bright Data y empiece hoy mismo a explorar nuestras herramientas de datos preparadas para la IA.




