

En esta guía aprenderás:
- Por qué el Scraping web es un método excelente para enriquecer los LLM con datos del mundo real
- Las ventajas y los retos de utilizar datos extraídos en los flujos de trabajo de LangChain
- Una biblioteca para simplificar la integración del scraping en LangChain
- Cómo crear una integración completa de Scraping web LangChain en un tutorial paso a paso
¡Empecemos!
Uso del Scraping web para potenciar sus aplicaciones LLM
El scraping web consiste en recuperar datos de las páginas web. Esos datos se pueden utilizar para alimentar aplicaciones RAG (Retrieval-Augmented Generation) integrándolos con LLM (Large Language Models).
Los sistemas RAG requieren acceso a datos ricos, actualizados, en tiempo real, específicos de un dominio o expansivos que no están fácilmente disponibles en los Conjuntos de datos estáticos que se pueden comprar o descargar en línea. El Scraping web cubre esa laguna al proporcionar información estructurada extraída de diversas fuentes, como artículos de noticias, listados de productos y redes sociales.
Obtenga más información en nuestro artículo sobre la recopilación de datos de entrenamiento LLM.
Ventajas y retos del uso de datos extraídos en LangChain
LangChain es un potente marco para crear flujos de trabajo impulsados por la IA, que permite una integración simplificada de los LLM con diversas fuentes de datos. Destaca en el análisis de datos, la síntesis y la respuesta a preguntas, ya que combina los LLM con conocimientos específicos de un dominio en tiempo real. Sin embargo, la adquisición de datos de alta calidad siempre es un problema.
El scraping web puede resolver ese problema, pero conlleva varios retos, como las medidas antibots, los CAPTCHA y los sitios web dinámicos. Mantener Scrapers eficientes y que cumplan con la normativa también puede llevar mucho tiempo y ser técnicamente complejo. Para obtener más detalles, consulte nuestra guía sobre medidas antirrastreo.
Estos obstáculos pueden ralentizar el desarrollo de aplicaciones basadas en IA que dependen de datos en tiempo real. ¿La solución? La API Web Scraper de Bright Data, una herramienta lista para usar que ofrece puntos finales de scraping para cientos de sitios web.
Con funciones avanzadas como la rotación de IP, la Resolución de CAPTCHA y la representación de JavaScript, Bright Data automatiza la extracción de datos por usted. Esto garantiza una recopilación de datos fiable, eficiente y sin complicaciones, todo ello accesible a través de simples llamadas a la API.
LangChain Herramientas de Bright Data
Ahora bien, aunque podría integrar la API Web Scraper de Bright Data y otras herramientas de scraping directamente en su flujo de trabajo de LangChain, hacerlo requeriría una lógica personalizada y código repetitivo. Para ahorrar tiempo y esfuerzo, es preferible utilizar el paquete oficial de integración de LangChain Bright Data, langchain-brightdata.
Este paquete le permite conectarse a los servicios de Bright Data dentro de los flujos de trabajo de LangChain. En concreto, expone las siguientes clases:
BrightDataSERP: se integra con la API SERP de Bright Data para realizar consultas en motores de búsqueda con geolocalización.BrightDataUnblocker: funciona con el Web Unlocker de Bright Data para acceder a sitios web que pueden estar restringidos geográficamente o protegidos por sistemas antibots.BrightDataWebScraperAPI: interactúa con la API Web Scraper de Bright Data para extraer datos estructurados de varios dominios.
En este tutorial, nos centraremos en el uso de la clase BrightDataWebScraperAPI. ¡Es hora de ver cómo!
LangChain Scraping web con tecnología de Bright Data: guía paso a paso
En esta sección, aprenderás a crear un flujo de trabajo de Scraping web con LangChain. El objetivo es utilizar LangChain para recuperar contenido de un perfil de LinkedIn utilizando la API Web Scraper de Bright Data y, a continuación, utilizar OpenAI para evaluar si el candidato es adecuado para un puesto de trabajo específico.
Utilizaremos mi página de perfil público de LinkedIn como referencia, pero cualquier otro perfil de LinkedIn también servirá:
Nota: Lo que estamos creando aquí es solo un ejemplo. El código que está a punto de escribir se adapta fácilmente a diferentes escenarios. Eso significa que también se puede ampliar con funciones adicionales de LangChain. Por ejemplo, incluso podría crear un chatbot RAG basado en datos SERP.
¡Sigue los pasos que se indican a continuación para empezar!
Requisitos previos
Para completar este tutorial, necesitarás lo siguiente:
- Python 3+ instalado en tu equipo
- Una clave API de OpenAI
- Una cuenta de Bright Data
No te preocupes si te falta alguno de estos elementos. Te guiaremos a lo largo de todo el proceso, desde la instalación de Python hasta la obtención de tus credenciales de OpenAI y Bright Data.
Paso n.º 1: Configuración del proyecto
En primer lugar, comprueba si Python 3 está instalado en tu equipo. Si no es así, descárgalo e instálalo.
Ejecute este comando en la terminal para crear una carpeta para su proyecto:
mkdir langchain-scrapinglangchain-scraping contendrá tu proyecto de scraping de Python LangChain.
A continuación, navega hasta la carpeta del proyecto e inicializa un entorno virtual Python dentro de ella:
cd langchain-scraping
python3 -m venv venvNota: En Windows, usa python en lugar de python3.
Ahora, abra el directorio del proyecto en su IDE de Python favorito. PyCharm Community Edition o Visual Studio Code con la extensión Python serán suficientes.
Dentro de langchain-scraping, añada un archivo script.py. Se trata de un script Python vacío, pero pronto contendrá su lógica de Scraping web LangChain.
En la terminal del IDE, en Linux o macOS, activa el entorno virtual con el siguiente comando:
source venv/bin/activateO, en Windows, ejecuta:
venv/Scripts/activate¡Genial! Ya lo tienes todo configurado.
Paso n.º 2: Instalar las bibliotecas necesarias
El proyecto de scraping Python LangChain se basa en las siguientes bibliotecas:
python-dotenv: para cargar variables de entorno desde un archivo.env. Se utilizará para gestionar las claves API de Bright Data y OpenAI.langchain-openai: integraciones de LangChain para OpenAI a través de su SDKopenai.langchain-brightdata: integración de LangChain con los servicios de scraping de Bright Data.
En un entorno virtual activado, instale todas las dependencias con este comando:
pip install python-dotenv langchain-openai langchain-brightdata¡Genial! Ya está listo para escribir la lógica de scraping.
Paso n.º 3: Prepare su proyecto
En script.py, añade la siguiente importación:
from dotenv import load_dotenvA continuación, crea un archivo .env en la carpeta de tu proyecto para almacenar todas tus credenciales. Así es como debería ser la estructura actual de los archivos de tu proyecto:

Indique a python-dotenv que cargue las variables de entorno desde .env con esta línea en script.py:
load_dotenv()¡Genial! Es hora de configurar la solución API Web Scraper de Bright Data.
Paso n.º 4: Configurar la API Web Scraper
Como se mencionó al principio de este artículo, el Scraping web presenta varios retos. Afortunadamente, resulta mucho más fácil con una solución integral como las API Web Scraper de Bright Data. Estas API te permiten recuperar contenido analizado de más de 120 sitios web sin esfuerzo.
Para configurar la API Web Scraper en LangChain utilizando langchain_brightdata, siga las instrucciones que se indican a continuación. Para obtener una introducción general a la solución de Scraping web de Bright Data, consulte la documentación oficial.
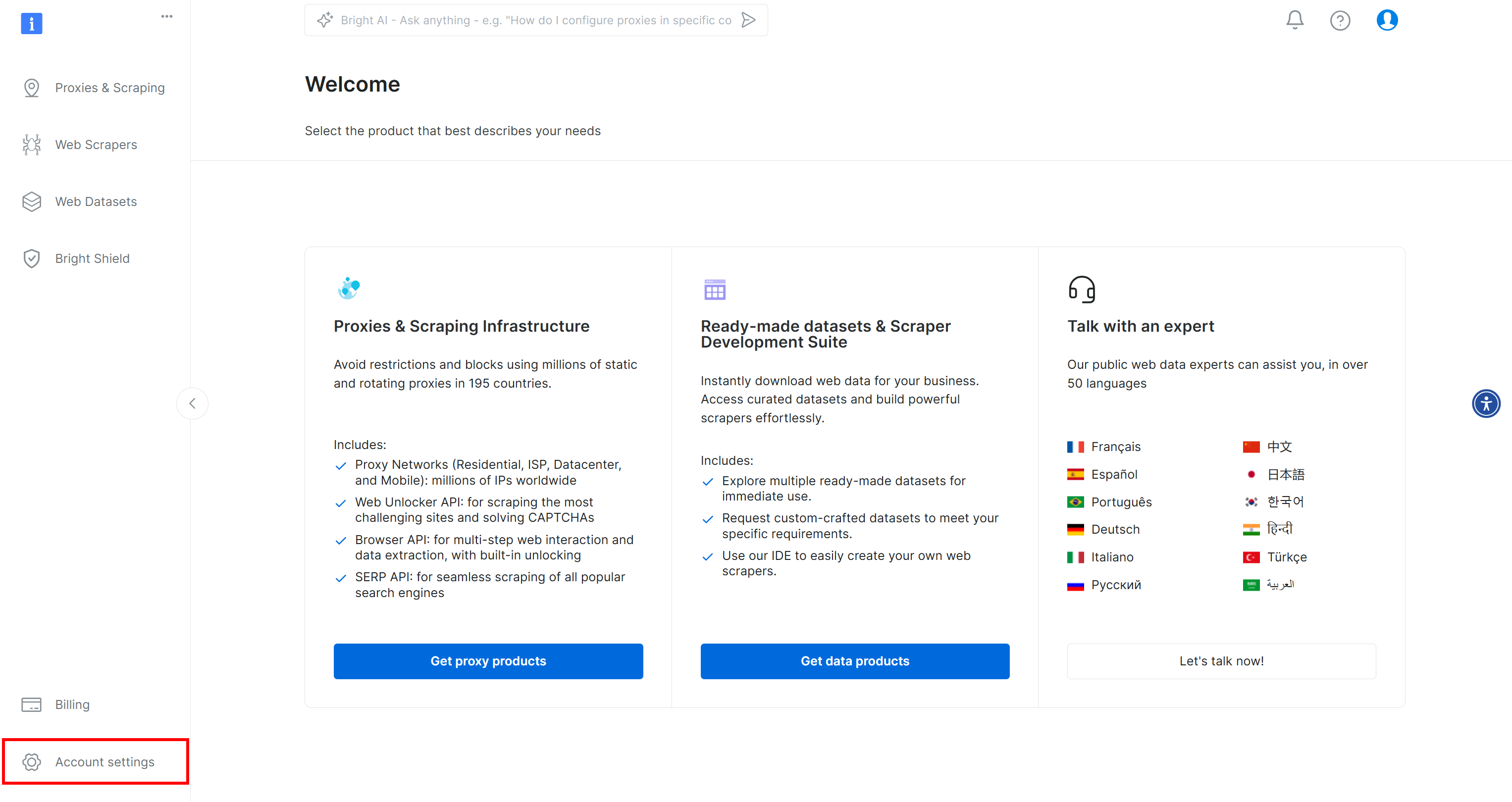
Si aún no lo ha hecho, cree una cuenta de Bright Data. Después de iniciar sesión, se le dirigirá al panel de control de su cuenta. Desde aquí, haga clic en el botón «Configuración de la cuenta» situado en la parte inferior izquierda:
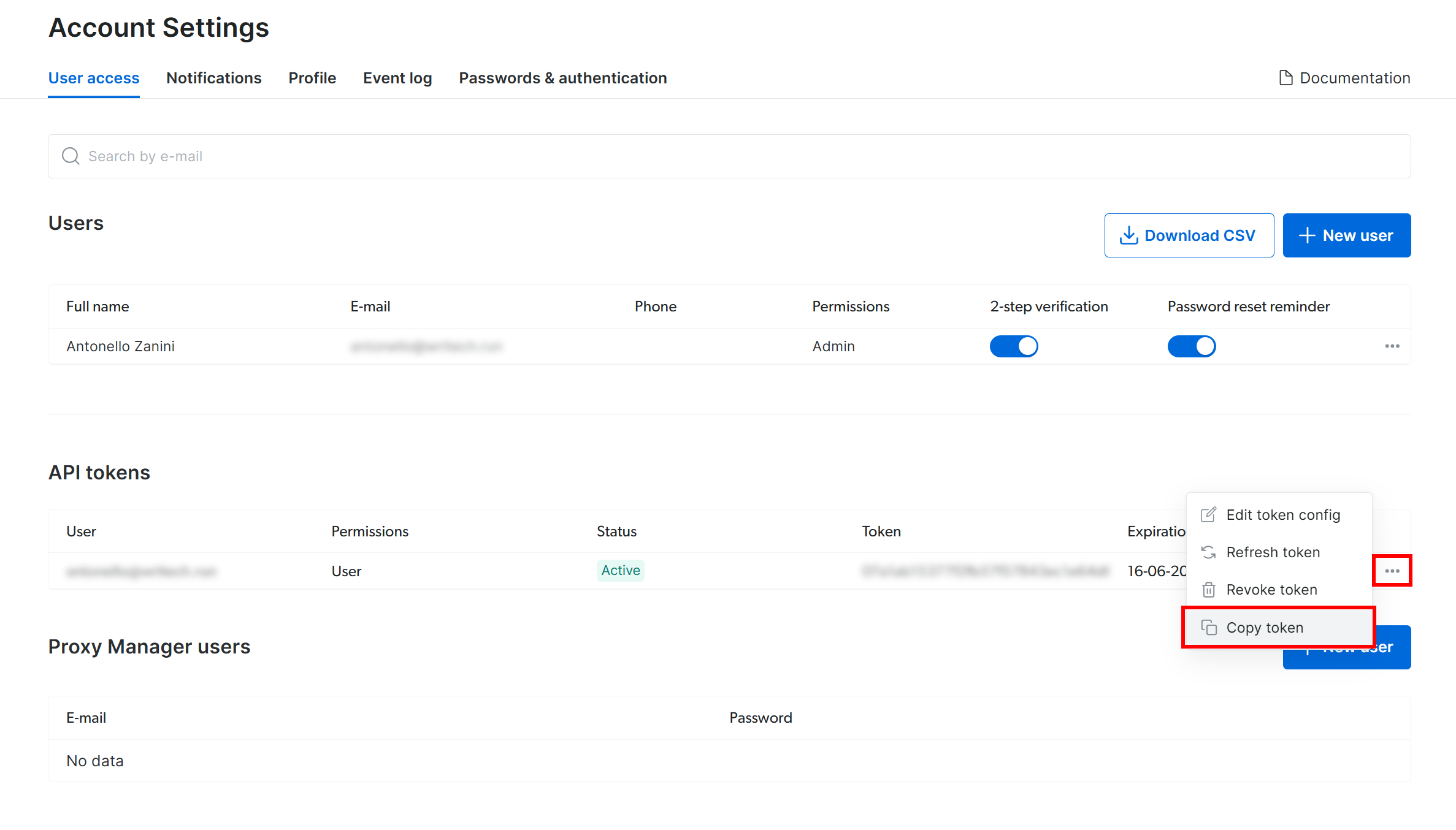
En la página «Configuración de la cuenta», si ya ha creado un token de API de Bright Data, haga clic en «…» y seleccione la opción «Copiar token»:
De lo contrario, haga clic en el botón «Añadir token»:
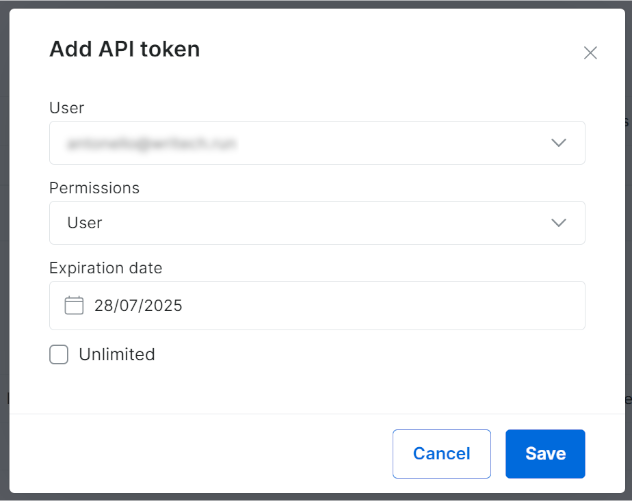
Aparecerá el siguiente modal. Configure su token API de Bright Data y pulse el botón «Guardar»:
Recibirá su nuevo token API:
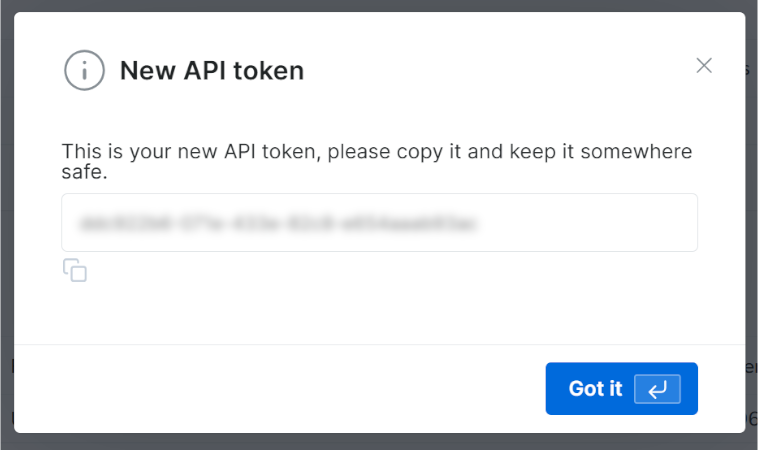
Copie el valor de su clave API de Bright Data.
En su archivo .env, almacene esta información como una variable de entorno BRIGHT_DATA_API_KEY:
BRIGHT_DATA_API_KEY="<SU_CLAVE_DE_API_DE_BRIGHT_DATA>"Reemplaza <TU_CLAVE_API_BRIGHT_DATA> con el valor que copiaste del modal/tabla.
Ahora, en script.py, importe langchain_brightdata:
from langchain_brightdata import BrightDataWebScraperAPINo es necesario realizar ninguna otra acción, ya que langchain_brightdata intenta automáticamente leer la clave API de Bright Data desde la variable de entorno BRIGHT_DATA_API_KEY.
¡Ya está! Ahora puede utilizar la API Web Scraper en LangChain.
Paso n.º 5: Utilizar Bright Data para el Scraping web
langchain_brightdata admite la integración con la API Web Scraper de Bright Data a través de la clase BrightDataWebScraperAPI.
A continuación se ofrece una descripción general del funcionamiento de esa clase:
- Realiza una solicitud sincrónica a la API Web Scraper configurada, aceptando la URL de la página que se va a extraer.
- Se inicia una tarea de scraping basada en la nube para recuperar y realizar el parseo de los datos de la URL especificada.
- La biblioteca espera a que finalice la tarea de scraping y, a continuación, devuelve los datos extraídos en formato JSON.
Para integrar el Scraping web en su flujo de trabajo de LangChain, defina una función reutilizable con el siguiente código:
def get_scraped_data(url, dataset_type):
# Inicializa la clase de integración de la API LangChain Bright Data Scraper.
web_scraper_api = BrightDataWebScraperAPI()
# Recuperar los datos de interés conectándose a la API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return resultsLa función acepta los siguientes argumentos:
url: la URL de la página de la que se van a recuperar los datos.dataset_type: especifica el tipo de API de Web Scraper que se utilizará para extraer datos de la página. Por ejemplo,«linkedin_person_profile»indica a la API de Web Scraper que extraiga datos de la URL del perfil público de LinkedIn proporcionada.
En este ejemplo, llámela de la siguiente manera:
url = "https://linkedin.com/in/antonello-zanini"
scraped_data = get_scraped_data(url, "linkedin_person_profile")scraped_data contendrá datos como estos:
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# Omitido por brevedad...
"about": "Soy ingeniero de software autónomo, editor técnico y redactor técnico con cientos...",
"current_company": {
"name": "Freelance"
},
"current_company_name": "Freelance",
# Omitido por brevedad...
«languages»: [
{
«title»: «Italiano»,
«subtitle»: «Competencia nativa o bilingüe»
},
{
«title»: «Inglés»,
«subtitle»: «Competencia profesional completa»
},
{
"title": "Español",
"subtitle": "Competencia profesional completa"
}
],
"recommendations_count": 32,
"recommendations": [
# Omitido por brevedad...
],
"posts": [
# Omitido por brevedad...
],
"activity": [
# Omitido por brevedad...
],
# Omitido por brevedad...
}En detalle, almacena toda la información disponible en la versión pública de la página de perfil de LinkedIn de destino, pero estructurada en formato JSON. Para obtener esos datos, la API Web Scraper ha eludido cualquier mecanismo antibots o antiescraping por ti.
¡Increíble! Acabas de aprender a utilizar la API Scraper de Bright Data Web para el Scraping web en LangChain.
Paso n.º 6: Prepárate para usar los modelos de OpenAI
Este ejemplo se basa en los modelos OpenAI para la integración de LLM en LangChain. Para utilizar esos modelos, debes configurar una clave API de OpenAI en tus variables de entorno.
Por lo tanto, añade la siguiente línea a tu archivo .env:
OPENAI_API_KEY="<TU_CLAVE_API_OPEN>"Reemplaza <TU_CLAVE_API_OPENAI> por el valor de tu clave API de OpenAI. Si no sabes cómo obtenerla, sigue la guía oficial.
Ahora, en script.py, importe langchain_openai de esta manera:
from langchain_openai import ChatOpenAINo es necesario hacer nada más. langchain_openai buscará automáticamente tu clave API de OpenAI en la variable de entorno OPENAI_API_KEY.
¡Genial! Es hora de utilizar los modelos OpenAI en su script de scraping de LangChain.
Paso n.º 7: Generar la solicitud LLM
Define una variable f-string que tome los datos extraídos y genere un prompt para el LLM. En este caso, el prompt incluye tu solicitud de RR. HH. e incorpora los datos extraídos del candidato:
prompt = f"""
«¿Crees que este candidato es adecuado para un puesto de ingeniero de software remoto? ¿Por qué?
Responde en no más de 150 palabras.
CANDIDATO:
'{scraped_data}'
"""En este ejemplo, estás creando un flujo de trabajo de IA para asesores de RR. HH. utilizando LangChain. Gracias a la flexibilidad de la API Web Scraper (que admite más de 120 dominios) combinada con los LLM, puedes adaptar fácilmente este enfoque para impulsar una amplia gama de otros flujos de trabajo de LangChain.
💡 Idea: para una mayor flexibilidad, considera leer la indicación del archivo .env.
En el ejemplo actual, la indicación completa será:
¿Cree que este candidato es adecuado para un puesto de ingeniero de software remoto? ¿Por qué?
Responda en no más de 150 palabras.
CANDIDATO:
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// omitido por brevedad...
"about": "Soy ingeniero de software autónomo, editor técnico y redactor técnico con cientos...",
},
[omitido por brevedad...]'Si lo pasas a ChatGPT, deberías obtener el resultado deseado:
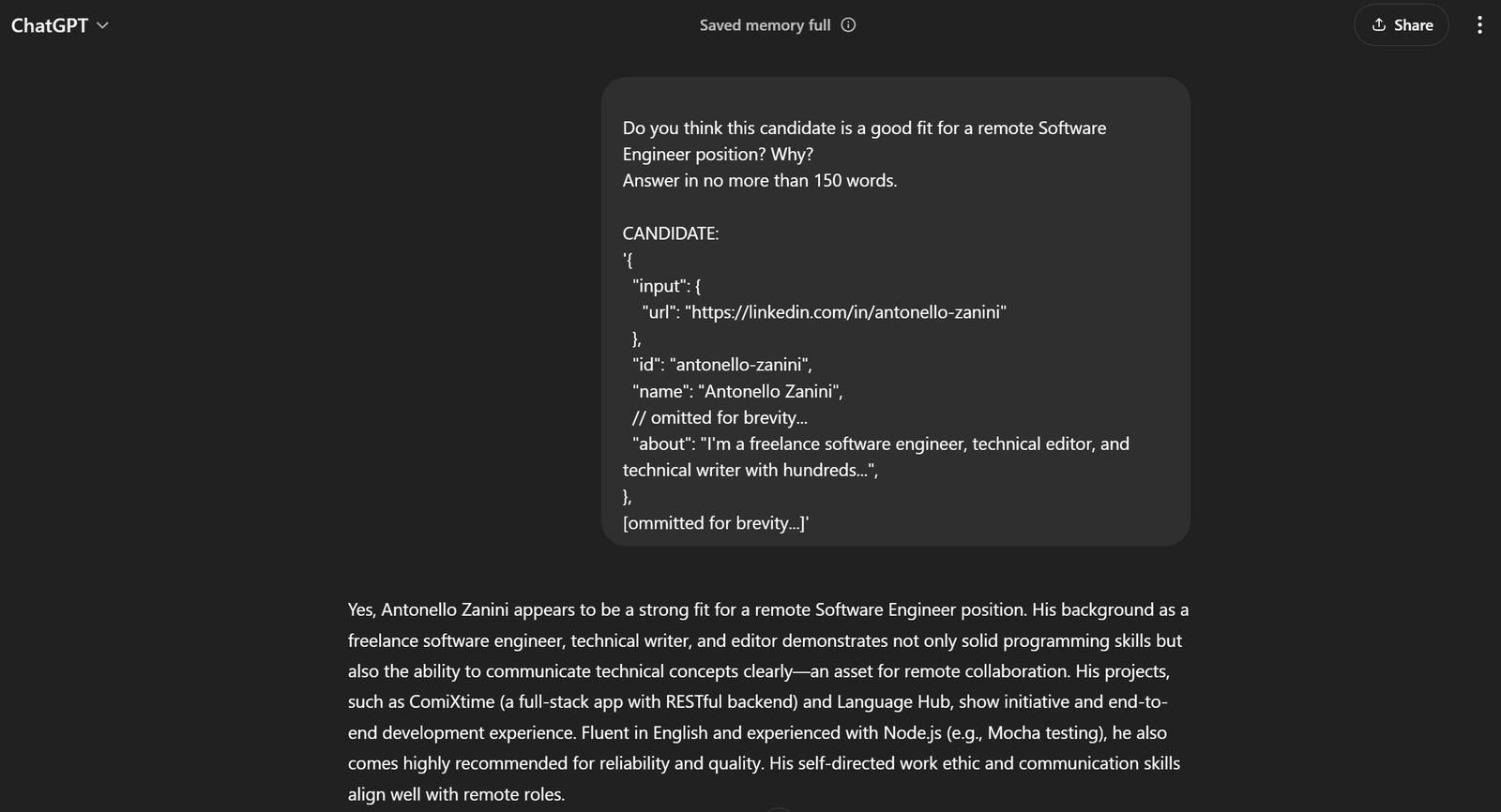
¡Esto es suficiente para saber que la indicación funciona a la perfección!
Paso n.º 8: Integrar OpenAI
Pasa la indicación que generaste anteriormente a un objeto ChatOpenAI LangChain configurado en el modelo de IA GPT-4o mini:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)Al final del procesamiento de IA, response.content debería contener un resultado similar a la evaluación generada por ChatGPT en el paso anterior. Accede a esa respuesta de texto con:
evaluación = respuesta.contenido¡Vaya! La lógica de Scraping web de LangChain está completa.
Paso n.º 9: Exportar los datos procesados por IA
Ahora solo tienes que exportar los datos generados por el modelo de IA seleccionado a través de LangChain a un formato legible para los humanos, como un archivo JSON.
En primer lugar, inicialice un diccionario con los datos que desee. A continuación, expórtelo y guárdelo como un archivo JSON, tal y como se muestra a continuación:
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)Importe json desde la biblioteca estándar de Python:
import json¡Enhorabuena! Tu script está listo.
Paso n.º 10: añadir algunos registros
El proceso de scraping web con Web Scraping IA y el análisis de ChatGPT puede llevar algún tiempo. Esto es normal debido a la sobrecarga que supone el scraping y el procesamiento de datos de servicios de terceros. Por lo tanto, es una buena práctica incluir registros para realizar un seguimiento del progreso del script.
Para ello, añade sentencias de impresión en los pasos clave del script, como se muestra a continuación:
url = "https://linkedin.com/in/antonello-zanini"
print(f"Rastreadando datos con la API Web Scraper desde {url}...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Datos rastreados con éxito")
print("Creando la solicitud de IA...")
prompt = f"""
"¿Cree que este candidato es adecuado para un puesto de ingeniero de software remoto? ¿Por qué?
Responda en no más de 150 palabras.
CANDIDATO:
'{scraped_data}'
"""
print("Solicitud creadana")
print("Enviando prompt a ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("Respuesta recibida de ChatGPTn")
print("Exportando datos a JSON"...)
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Datos exportados a '{file_name}'")Tenga en cuenta que cada paso del flujo de trabajo de Scraping web de LangChain se registra claramente. Ahora será mucho más fácil seguir la ejecución en la terminal.
Paso n.º 11: Ponlo todo junto
Tu archivo script.py final debe contener:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# Cargar las variables de entorno del archivo .env
load_dotenv()
def get_scraped_data(url, dataset_type):
# Inicializar la clase de integración de la API LangChain Bright Data Scraper
web_scraper_api = BrightDataWebScraperAPI()
# Recuperar los datos de interés conectándose a la API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# Recuperar el contenido de la página web dada
url = "https://linkedin.com/in/antonello-zanini"
print(f"Retirado datos con la API Web Scraper de {url}...")
# Utilizar la API Web Scraper para obtener los datos retirados
scraped_data = get_scraped_data(url, "linkedin_person_profile")
imprimir("Datos extraídos correctamenten")
imprimir("Creando la indicación de IA...")
# Definir la indicación utilizando los datos extraídos como contexto
indicación = f"""
"¿Crees que este candidato es adecuado para un puesto de ingeniero de software remoto? ¿Por qué?
Responde en no más de 150 palabras.
CANDIDATO:
'{scraped_data}'
"""
print("Prompt creado")
# Pide a ChatGPT que realice la tarea especificada en el prompt
print("Enviando prompt a ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# Obtener el resultado de la IA
evaluación = respuesta.contenido
imprimir("Respuesta recibida de ChatGPTn")
imprimir("Exportando datos a JSON...")
# Exportar los datos producidos a JSON
exportar_datos = {
"url": url,
"evaluación": evaluación
}
# Escribir el diccionario de salida en un archivo JSON
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Datos exportados a '{file_name}'")¿Te lo puedes creer? Con unas 50 líneas de código, acabas de crear un script de LangChain basado en IA para el Scraping web.
Comprueba que funciona con este comando:
python3 script.pyO, en Windows:
python script.pyEl resultado en la terminal debería ser:
Recopilación de datos con la API Web Scraper de https://linkedin.com/in/antonello-zanini...
Datos recopilados correctamente.
Creando la solicitud de IA...
Solicitud creada.
Enviando la solicitud a ChatGPT...
Respuesta recibida de ChatGPT.
Exportando datos a JSON...
Datos exportados a «analysis.json».Abra el archivo analysis.json que apareció en el directorio del proyecto y debería ver algo como esto:
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zanini parece ser un candidato sólido para un puesto de ingeniero de software remoto. Su experiencia como ingeniero de software autónomo indica adaptabilidad y automotivación, cualidades cruciales para el trabajo remoto. Su experiencia en redacción técnica y editorial sugiere unas sólidas habilidades de comunicación, esenciales para colaborar con equipos remotos. Además, sus diversos conocimientos de programación, evidenciados en publicaciones sobre pruebas unitarias y paquetes JavaScript, refuerzan su experiencia técnica. Ha obtenido importantes comentarios positivos de los clientes, que destacan su fiabilidad y claridad en los resultados, rasgos fundamentales para una colaboración remota eficaz. Además, sus habilidades multilingües en italiano, inglés y español pueden mejorar la comunicación en equipos internacionales diversos. En general, la combinación de competencia técnica, habilidades de comunicación y recomendaciones positivas de Antonello lo convierten en un candidato ideal para un puesto remoto.
}¡Et voilà! El flujo de trabajo de HR LangChain, enriquecido con datos en tiempo real, ya está completo.
Conclusión
En este tutorial, has descubierto por qué el Scraping web es un método eficaz para recopilar datos para tus flujos de trabajo de IA y cómo analizar esos datos utilizando LangChain.
En concreto, ha creado un script de Scraping web de LangChain basado en Python para extraer datos de una página de perfil de LinkedIn y procesarlos utilizando las API de OpenAI. Aunque este flujo de trabajo de LangChain es ideal para apoyar las tareas de RR. HH., el código mostrado se puede ampliar fácilmente a otros flujos de trabajo y escenarios.
Los principales retos del Scraping web en LangChain son:
- Los sitios web suelen cambiar la estructura de sus páginas.
- Muchos sitios implementan medidas avanzadas contra los bots.
- Recuperar grandes volúmenes de datos simultáneamente puede ser complejo y costoso.
La API Web Scraper de Bright Data representa una solución eficaz para extraer datos de los principales sitios web, superando fácilmente estos retos. Gracias a su fluida integración con LangChain, es una herramienta invaluable para dar soporte a aplicaciones RAG y otras soluciones basadas en LangChain.
No deje de explorar nuestras ofertas adicionales para IA y LLM.
Regístrese ahora para descubrir cuál de los servicios de Proxy o productos de scraping de Bright Data se adapta mejor a sus necesidades. ¡Comience con una prueba gratuita!




