

En esta entrada del blog, descubrirás:
- Qué es Cartesia y qué ofrece para el desarrollo de agentes de voz con IA.
- Por qué los agentes de voz (como cualquier otro agente) necesitan acceso a la web para ser eficaces y verdaderamente fiables.
- Cómo dotar a un agente de voz con IA de Cartesia de la capacidad de buscar y extraer información de la web mediante la integración con Bright Data.
¡Empecemos!
¿Qué es Cartesia?
Cartesia es una plataforma centrada en los desarrolladores para crear agentes de voz con IA en tiempo real. Combina modelos de voz de baja latencia con una pila completa de desarrollo de agentes, proporcionando todo lo necesario para pasar de la idea a un agente de voz listo para la producción.
La plataforma está diseñada para una iteración rápida, lo que permite a los desarrolladores crear prototipos, implementar y perfeccionar agentes conversacionales con un mínimo de fricción. Gestiona el habla, el razonamiento, la implementación y las pruebas dentro de un único ecosistema unificado.
La pila de voz de Cartesia se basa en dos modelos internos clave:
- Sonic: un modelo de conversión de texto a voz (TTS) en streaming optimizado para una latencia ultrabaja y una salida altamente expresiva. Es capaz de reír, mostrar emociones y ofrecer un habla natural y similar a la humana en más de 40 idiomas.
- Ink: un modelo de conversión de voz a texto (STT) rápido y preciso, diseñado para conversaciones del mundo real, que gestiona el ruido, los acentos y las disfluencias al tiempo que mantiene una velocidad de transcripción casi en tiempo real.
Para crear agentes, Cartesia ofrece tanto un generador de agentes web integrado como Line, su SDK de código abierto. El SDK de Cartesia admite plantillas, integración de herramientas, orquestación de múltiples agentes y mucho más. Esto le proporciona todo lo que necesita para crear agentes de voz inteligentes y aptos para producción.
Por qué los agentes de voz necesitan acceso a la web
Cartesia es, sin duda, una solución con numerosas funciones para crear agentes de voz con IA, con soporte para más de 100 LLM a través de LiteLLM. Sin embargo, incluso con esta amplia selección, todos los LLM comparten la misma limitación inherente: su conocimiento está congelado en un momento específico en el tiempo. Esto puede dar lugar a respuestas desactualizadas, alucinaciones o lagunas cuando los agentes deben gestionar tareas del mundo real y actualizadas.
Además, los LLM no pueden acceder de forma nativa a la web ni interactuar con sistemas externos. Como resultado, los flujos de trabajo estándar de los agentes siguen estando limitados por las restricciones de los modelos. Para superar esto, es esencial la integración con servicios externos a través de herramientas personalizadas.
Aquí es donde entra en juego Bright Data. Al conectar Cartesia con Bright Data, sus agentes pueden acceder a información en tiempo real, resultados de búsqueda y datos estructurados de cualquier sitio web.
La infraestructura de nivel empresarial de Bright Data cuenta con una de las redes de Proxies más grandes del mundo, con más de 400 millones de direcciones IP en 195 países, lo que permite un acceso seguro, fiable y escalable a contenido web en directo.
Los principales productos de Bright Data con los que puede equipar a los agentes de voz de Cartesia incluyen:
- API SERP: recopila resultados de motores de búsqueda de Google, Bing y otros para generar respuestas bien fundamentadas.
- API Web Unlocker: Accede a contenido de cualquier sitio en HTML sin formato o Markdown, eludiendo los CAPTCHAs y las protecciones antibots.
- API de Scraper: extrae datos estructurados de plataformas como Amazon, LinkedIn e Instagram.
- API Crawl: convierte sitios web completos en Conjuntos de datos estructurados para flujos de trabajo de IA posteriores.
Con Bright Data, los agentes de Cartesia ya no se limitan a conocimientos preentrenados. Pueden explorar, recuperar y razonar con datos web en tiempo real y de confianza. Esto les permite ofrecer respuestas más precisas, sensibles al contexto y prácticas.
Cómo crear un agente de voz con IA de Cartesia impulsado por la recuperación de datos web de Bright Data
En esta sección paso a paso, aprenderás a crear un agente de voz con IA con Cartesia. El agente se mejorará con capacidades de búsqueda web y Scraping web utilizando Bright Data.
En concreto, el agente de voz con IA simulará la generación de un breve informe al estilo de las noticias que podrá escuchar sobre un tema determinado. También podrá chatear con el agente para hacerle preguntas de seguimiento y profundizar en el tema.
Nota: Esta es solo una posible implementación de un agente de voz con IA. La integración de Bright Data admite muchos otros casos de uso.
Concretamente, integrarás dos de los productos de Bright Data preparados para IA:
- La API Web Unlocker para dotar al agente de la capacidad de extraer datos de cualquier URL.
- API SERP para permitir que el agente realice búsquedas en la web.
Juntas, estas herramientas dotan al agente de IA de la capacidad de aplicar el patrón de búsqueda y extracción. Esto resulta ideal para la validación de datos y el descubrimiento web.
Para tener un mayor control programático al crear el agente, utilizaremos Line (es decir, el SDK de Cartesia). Esto se debe a que el Agent Builder es excelente para la creación de prototipos, pero algo limitado.
¡Sigue las instrucciones que aparecen a continuación!
Requisitos previos
Para seguir este tutorial, asegúrate de que dispones de lo siguiente:
- Un sistema operativo basado en Unix (Linux, macOS o WSL en Windows).
- Python 3.9+ instalado localmente.
uvinstalado localmente.- Una clave API de uno de los proveedores de LLM compatibles con Cartesia (en este caso, utilizaremos una clave API de Gemini).
- Una cuenta de Bright Data con las API Web Unlocker y API SERP configuradas, junto con una clave API.
- Una cuenta de Cartesia con una clave API configurada.
No te preocupes todavía por configurar las cuentas de Bright Data y Cartesia, ya que se te guiará a través de los subcapítulos dedicados.
Paso n.º 1: Inicializar un proyecto de Cartesia
Empieza creando una carpeta para tu proyecto utilizando uv (este es el método recomendado en la guía de inicio rápido de Cartesia):
uv init cartesia-bright-data-voice-agentEntra en la carpeta del proyecto:
cd cartesia-bright-data-voice-agentDeberías ver una estructura de carpetas como esta:
cartesia-bright-data-voice-agent/
├── .git/
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.tomlEste es el resultado del comando uv init.
Céntrate en el archivo main.py. Ahí es donde añadirás tu lógica Cartesia para diseñar un agente de voz con IA ampliado con capacidades de recuperación de datos web y búsqueda utilizando Bright Data.
A continuación, instala las dependencias del proyecto con:
uv add cartesia-line requestsLas dos bibliotecas necesarias son:
cartesia-line: el SDK de Cartesia Line para crear agentes de voz inteligentes y de baja latencia.requests: el popular cliente HTTP de Python, que se utilizará para llamar a las API de Bright Data en herramientas Cartesia personalizadas.
uv instalará automáticamente estas bibliotecas en un entorno virtual.venv. Ahora puedes abrir el proyecto directamente en tu IDE de Python favorito.
¡Bien hecho! Tu proyecto Cartesia en blanco está listo para empezar.
Paso n.º 2: Empieza a usar la CLI de Cartesia
Para probar un agente de Cartesia localmente, debes instalar e iniciar sesión en la CLI de Cartesia. Para la autenticación, necesitas una clave API de Cartesia, ¡así que preparémosla primero!
Si aún no tienes una cuenta, crea una nueva cuenta de Cartesia. De lo contrario, inicia sesión. Una vez que hayas iniciado sesión, llegarás al panel de control:
Ahora, ve a la página «Claves API» y haz clic en el botón «Nuevo»:
Asigna un nombre a tu clave API (por ejemplo, «Agente de voz con tecnología Bright Data»), haz clic en «Crear» y verás la clave API en una ventana modal.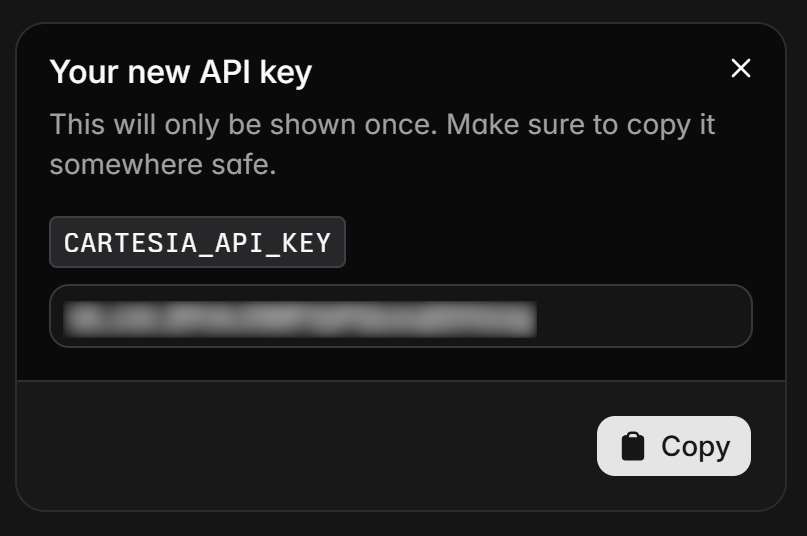
Copia el token de API y guárdalo en un lugar seguro, ya que lo necesitarás pronto.
En tu terminal basada en Unix, instala la CLI de Cartesia con:
curl -fsSL https://cartesia.sh | shTras la instalación, reinicia tu shell para poder utilizar el comando cartesia desde cualquier lugar.
Para autenticarte en la CLI, ejecuta:
cartesia auth loginSe te pedirá que introduzcas tu clave API de Cartesia. Pégala y pulsa Intro. Si se realiza correctamente, deberías ver un mensaje como este:
Nota: En este ejemplo, «Writech» es el nombre de la organización de Cartesia. En tu caso, verás un mensaje personalizado para tu organización.
¡Perfecto! Es hora de configurar tu cuenta de Bright Data para completar los requisitos previos iniciales.
Paso n.º 3: Configurar una cuenta de Bright Data
Para conectar la API SERP y Web Unlocker en Cartesia, primero necesitas una cuenta de Bright Data con una zona de API SERP y una zona de API Web Unlocker configuradas, además de una clave API.
Si no tienes una cuenta de Bright Data, crea una nueva. Si ya tienes una cuenta, inicia sesión. Ve a tu panel de control, navega hasta la página «Proxies & Scraping» y comprueba la tabla «My Zones»: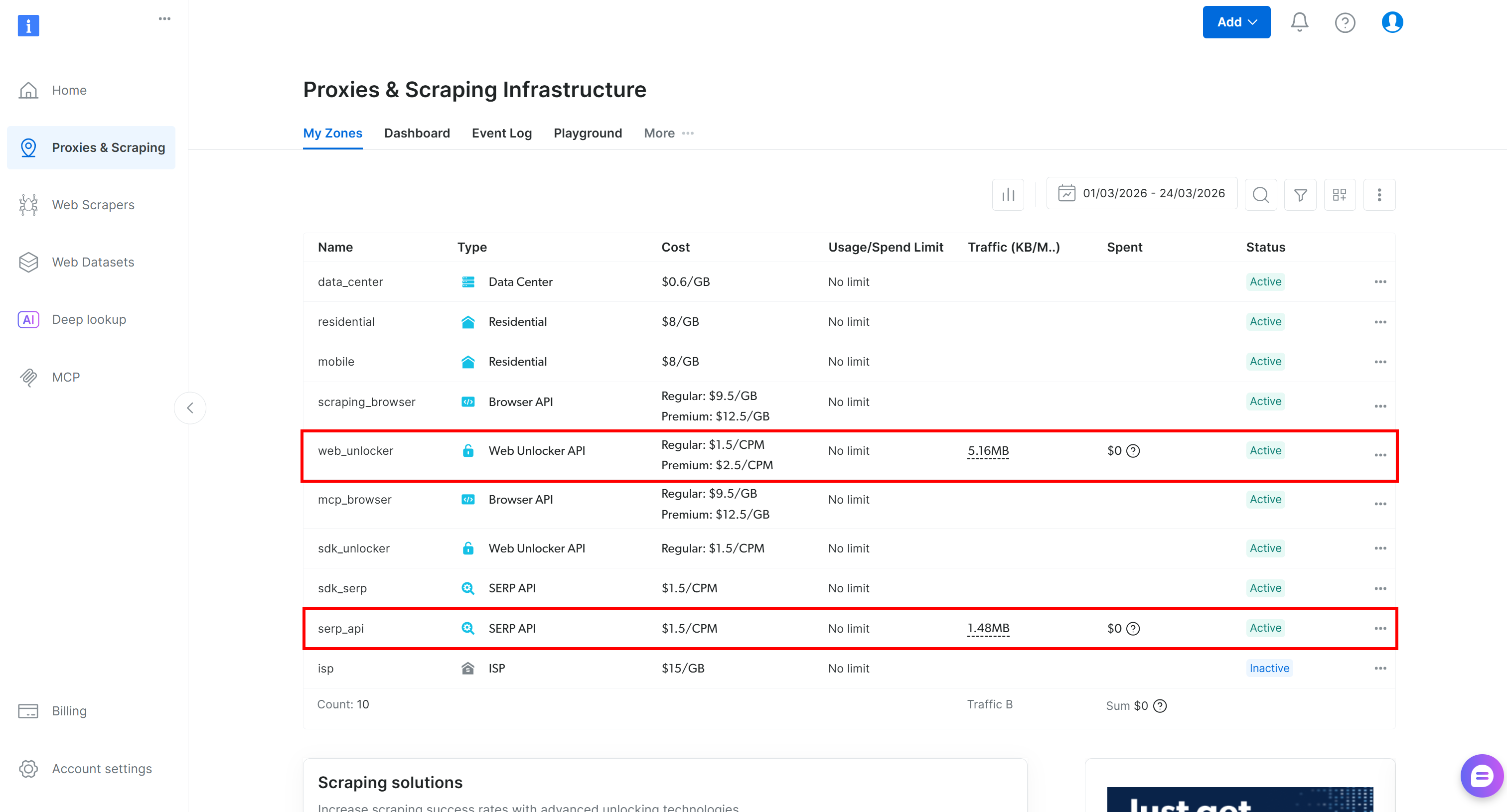
Si la tabla ya incluye una zona de API de Web Unlocker (por ejemplo, web_unlocker) y una zona de API SERP (por ejemplo, serp_api), ya está todo listo. Estas dos zonas se utilizarán para llamar a los servicios de API Web Unlocker y SERP a través de herramientas personalizadas.
Si falta alguna de las zonas, créala. Desplácese hasta las tarjetas «API de desbloqueo» y «API SERP» y, a continuación, haga clic en «Crear zona». Siga el asistente para añadir ambas zonas: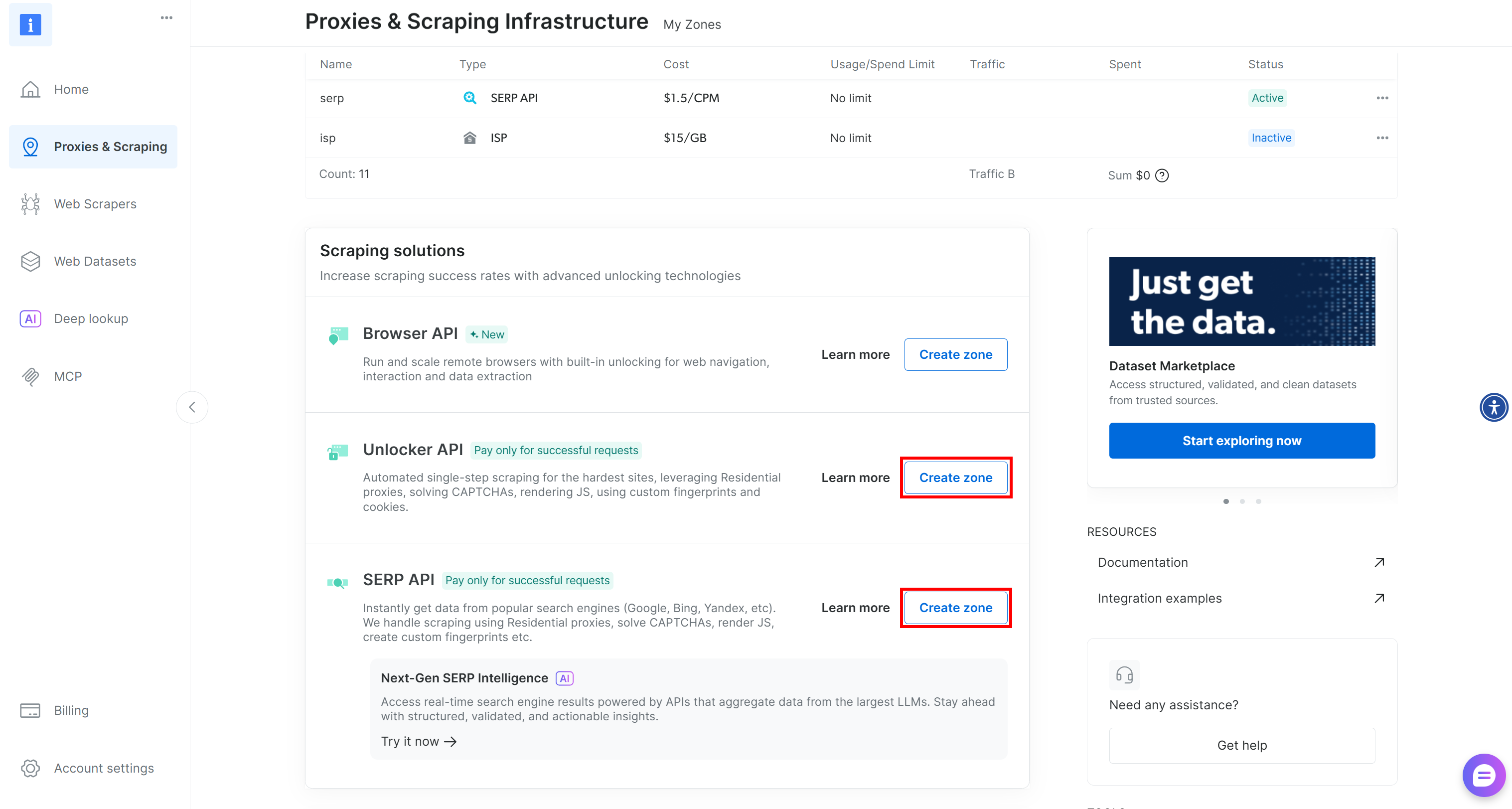
Para obtener instrucciones detalladas, consulta estas páginas de documentación:
Recuerda los nombres que asignes a ambas zonas, ya que los necesitarás en el siguiente paso. Por último, genera tu clave API de Bright Data y guárdala en un lugar seguro.
¡Genial! Bright Data ya está listo para integrarse en Cartesia.
Paso n.º 4: Configurar la lectura de variables de entorno
Este flujo de trabajo del agente de voz con IA depende de algunos secretos: un proveedor de LLM (Gemini, en este caso) y Bright Data (clave API + nombres de zona). Codificar estos secretos en tu código supone un riesgo de seguridad, por lo que es mejor guardarlos en variables de entorno.
La CLI de Cartesia lee automáticamente un archivo .env en segundo plano utilizando python-dotenv, por lo que puedes almacenar todos tus secretos allí. Empieza añadiendo un archivo .env al directorio de tu proyecto:
cartesia-bright-data-voice-agent/
├── .git/
├── .env # <-----------
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.tomlA continuación, rellénalo con tus claves secretas:
GEMINI_API_KEY="<TU_CLAVE_API_GEMINI>"
BRIGHT_DATA_API_KEY="<TU_CLAVE_API_BRIGHT_DATA>"
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<TU_ZONA_DE_WEB_UNLOCKER_DE_BRIGHT_DATA>" # p. ej., "web_unlocker"
BRIGHT_DATA_SERP_API_ZONE="<TU_ZONA_DE_SERP_API_DE_BRIGHT_DATA>" # p. ej., "serp_api"Sustituya todos los marcadores de posición por sus valores reales. Dado que el flujo de trabajo no debe iniciarse a menos que se hayan configurado todos estos secretos, añada la siguiente lógica a main.py:
import os
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Falta la variable de entorno: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_WEB_UNLOCKER_ZONE")Ten en cuenta que no es obligatorio utilizar un archivo .env. También puedes establecer las variables de entorno directamente en tu terminal con:
export GEMINI_API_KEY="<TU_CLAVE_API_GEMINI>" BRIGHT_DATA_API_KEY="<SU_CLAVE_API_DE_BRIGHT_DATA>" BRIGHT_DATA_WEB_UNLOCKER_ZONE="<SU_ZONA_DE_DESBLOQUEO_WEB_DE_BRIGHT_DATA>" BRIGHT_DATA_SERP_API_ZONE="<SU_ZONA_API_SERP_DE_BRIGHT_DATA>"¡Excelente! Tus variables de entorno ya están configuradas de forma segura. A continuación: implementación de las herramientas de Bright Data para el Scraping web y la búsqueda.
Paso n.º 5: Definir la herramienta Web Unlocker para el Scraping web
Por defecto, un agente de voz de Cartesia IA no puede acceder a la web externa. Para habilitarlo, debes equiparlo con herramientas personalizadas a las que el agente pueda llamar. Aquí definirás una herramienta para conectarte a la API Web Unlocker de Bright Data para el Scraping web.
En Cartesia, una herramienta no es más que una función anotada con uno de los decoradores de herramientas disponibles. A continuación se muestra cómo crear una herramienta de Scraping web de Cartesia que se conecte a la API de Web Unlocker:
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "La URL de la página que se va a extraer"]
) -> str:
"""
Recupera el contenido de la página web utilizando la API Web Unlocker de Bright Data
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_ZONA,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Realizar una solicitud a la API de Bright Data Web Unlocker
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textTen en cuenta que el SDK de Cartesia utiliza la cadena de documentación de la función como descripción de la herramienta y las anotaciones de tipo para sus parámetros. Además, el primer parámetro de cada herramienta debe ser ctx, que representa el contexto de la herramienta. Esto proporciona acceso al estado de la conversación y garantiza la compatibilidad con versiones futuras.
La función bright_data_web_unlocker() utiliza el cliente HTTP Requests para realizar una solicitud POST a su zona de la API de Bright Data Web Unlocker. Esto devuelve la versión Markdown de la página web especificada en el argumento page_url. Para obtener más detalles sobre los parámetros y opciones disponibles, consulte la documentación de Bright Data.
Tenga en cuenta que el argumento data_format está establecido en «markdown». Esto habilita la función«Scrape as Markdown»para obtener el contenido extraído en un formato Markdown optimizado para IA,ideal para la ingesta de LLM. El argumento format está establecido en «raw» para que la API responda con el contenido Markdown extraído sin formato, en lugar de envolverlo en JSON.
¡Genial! Su aplicación Cartesia IA ahora incluye una herramienta para realizar Scraping web con éxito utilizando Bright Data.
Paso n.º 6: Definir la herramienta de la API SERP para la búsqueda web
Del mismo modo, define una herramienta de función personalizada para llamar a la API SERP:
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "La consulta de búsqueda de Google"]
) -> str:
"""
Realiza una consulta en la web para un término específico utilizando la API SERP de Bright Data.
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Realiza una solicitud a la API SERP de Bright Data
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.textEsta función realiza una solicitud POST a tu zona de la API SERP. Envía una consulta a Google y recupera los resultados de búsqueda analizados a través de Bright Data. Para obtener más detalles, consulta la documentación de la API SERP de Bright Data.
¡Genial! Tu aplicación Cartesia ya incluye las herramientas necesarias basadas en Bright Data.
Paso n.º 7: Definir el agente de voz de Cartesia
En este punto, ya tienes todos los componentes necesarios para definir tu agente Cartesia. El enfoque recomendado es utilizar la clase LlmAgent integrada, que admite más de 100 proveedores de LLM a través de LiteLLM.
Para definir el agente de voz, proporcione a la clase:
- El modelo LLM y la clave API.
- Las herramientas que puede utilizar.
- Un mensaje del sistema que describa lo que debe hacer el agente.
- Un mensaje inicial.
A continuación se explica cómo combinarlo todo:
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
async def get_agent(env, call_request):
# Define el agente de voz con IA
SYSTEM_PROMPT = """
Eres un asistente útil capaz de buscar en la web para recuperar información actualizada.
Responde con un tono claro, informativo y al estilo de las noticias.
"""
return LlmAgent(
model="gemini/gemini-3-flash-preview",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="¡Hola! ¿En qué puedo ayudarte hoy?",
),
)Algunas cosas a tener en cuenta:
- La matriz
de herramientasincluye las dos herramientas personalizadas de Bright Data definidas anteriormente (bright_data_web_unlockerybright_data_serp_api). - La herramienta
end_callintegrada es necesaria para que el agente pueda finalizar una conversación de forma adecuada. - El modelo LLM configurado es Gemini 3 Flash, pero cualquier otro modelo Gemini servirá.
Por último, registra el agente en la clase VoiceAgentApp y ejecútalo:
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()¡Misión cumplida! Has creado un agente de voz con IA para respuestas de tipo noticioso. Este agente es capaz de buscar y recuperar información en tiempo real de la web para ofrecer respuestas más precisas y actualizadas.
Paso n.º 8: Código final
Esto es lo que debería contener ahora el archivo main.py:
# uv add cartesia-line requests
import os
from line.llm_agent import loopback_tool
from typing import Annotated
import requests
import urllib
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
# Leer las claves necesarias del entorno
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Falta la variable de entorno: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Falta la variable de entorno: BRIGHT_DATA_WEB_UNLOCKER_ZONE")
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "La URL de la página que se va a rastrear"]
) -> str:
"""
Recupera el contenido de la página web utilizando la API de Bright Data Web Unlocker
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_ZONA,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Realizar una solicitud a la API de Bright Data Web Unlocker
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "La consulta de búsqueda de Google"]
) -> str:
"""
Realiza una consulta en la web para un término específico utilizando la API SERP de Bright Data.
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Realizar una solicitud a la API SERP de Bright Data
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
async def get_agent(env, call_request):
# Define el agente de voz con IA
SYSTEM_PROMPT = """
Eres un asistente útil capaz de buscar en la web para recuperar contexto actualizado.
Responde con un tono claro, informativo y al estilo de las noticias.
"""
return LlmAgent(
model="gemini/gemini-2.5-flash",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="¡Hola! ¿En qué puedo ayudarte hoy?",
),
)
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()¡Genial! En unas 100 líneas de código Python, has conseguido crear un potente agente de IA de voz con capacidades de descubrimiento de datos web.
Paso n.º 9: Probar el agente de voz
Asegúrate de haber definido todas las variables de entorno necesarias (ya sea en un archivo .env o mediante un comando export ). A continuación, inicia el agente con:
PORT=8000 uv run python main.pyEsto inicia la aplicación Cartesia localmente en http://localhost:8000, tal y como se muestra en los registros:
En un terminal independiente, interactúa con tu agente ejecutando:
cartesia chat 8000La experiencia de Cartesia Chat se iniciará directamente en tu terminal: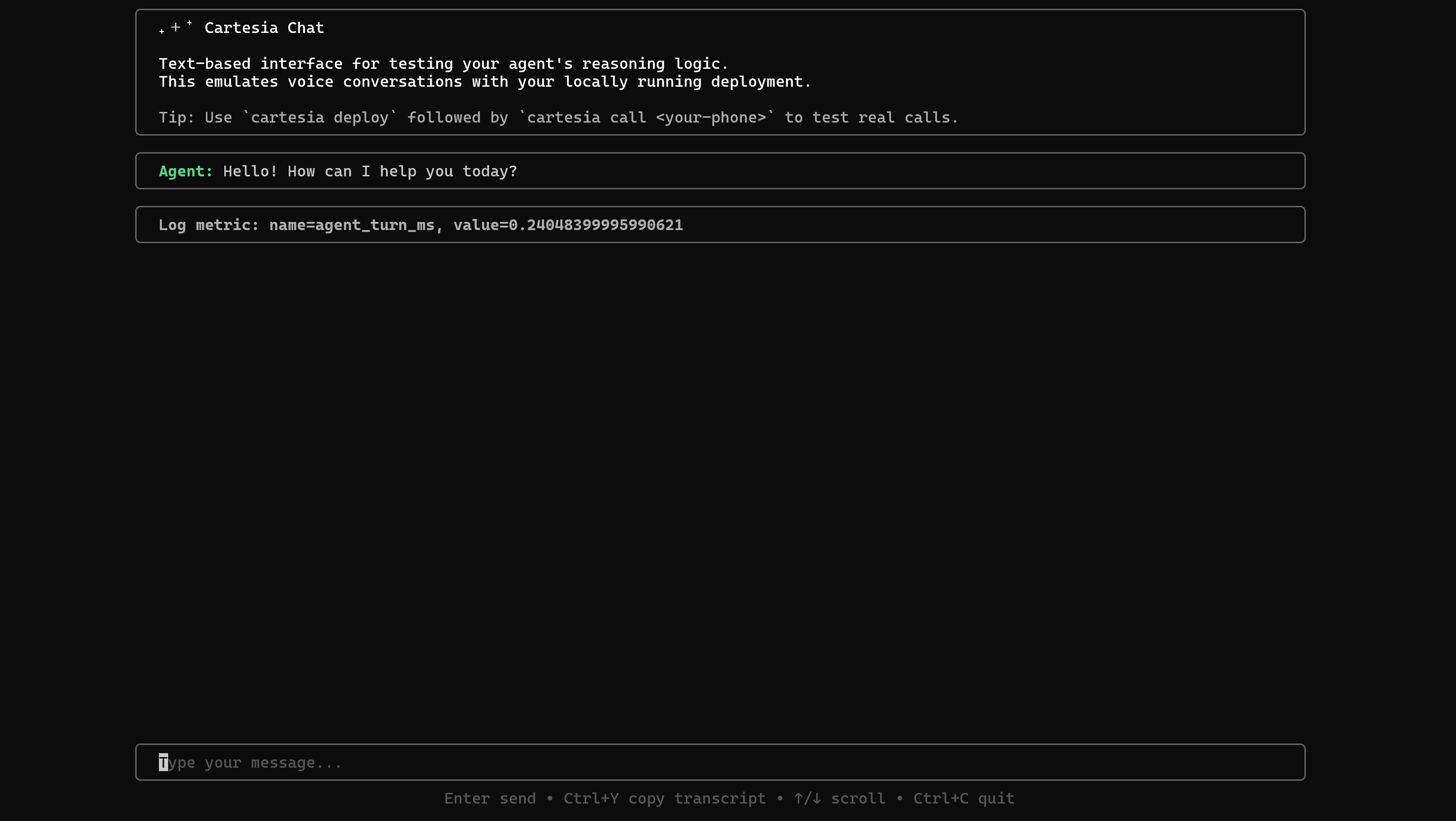
Esta configuración te permite simular conversaciones a través del chat en lugar de por voz, lo que simplifica mucho las pruebas.
Prueba una consulta como esta:
Busca en la web la consulta «noticias sobre la inflación en EE. UU.», selecciona 3 o 5 artículos específicos (no páginas de centros de noticias), extrae su contenido y utiliza esa información para producir un podcast de unos 3 minutos que resuma las ideas clave, citando las fuentes.A continuación se muestra lo que debería suceder:
Fíjate en cómo el agente primero llama a la herramienta bright_data_serp_api con la consulta «noticias sobre la inflación en EE. UU.». En el otro terminal, verás registros con los resultados JSON devueltos por la API SERP de Bright Data. A partir de esos resultados, el agente selecciona 3 URL de artículos relevantes: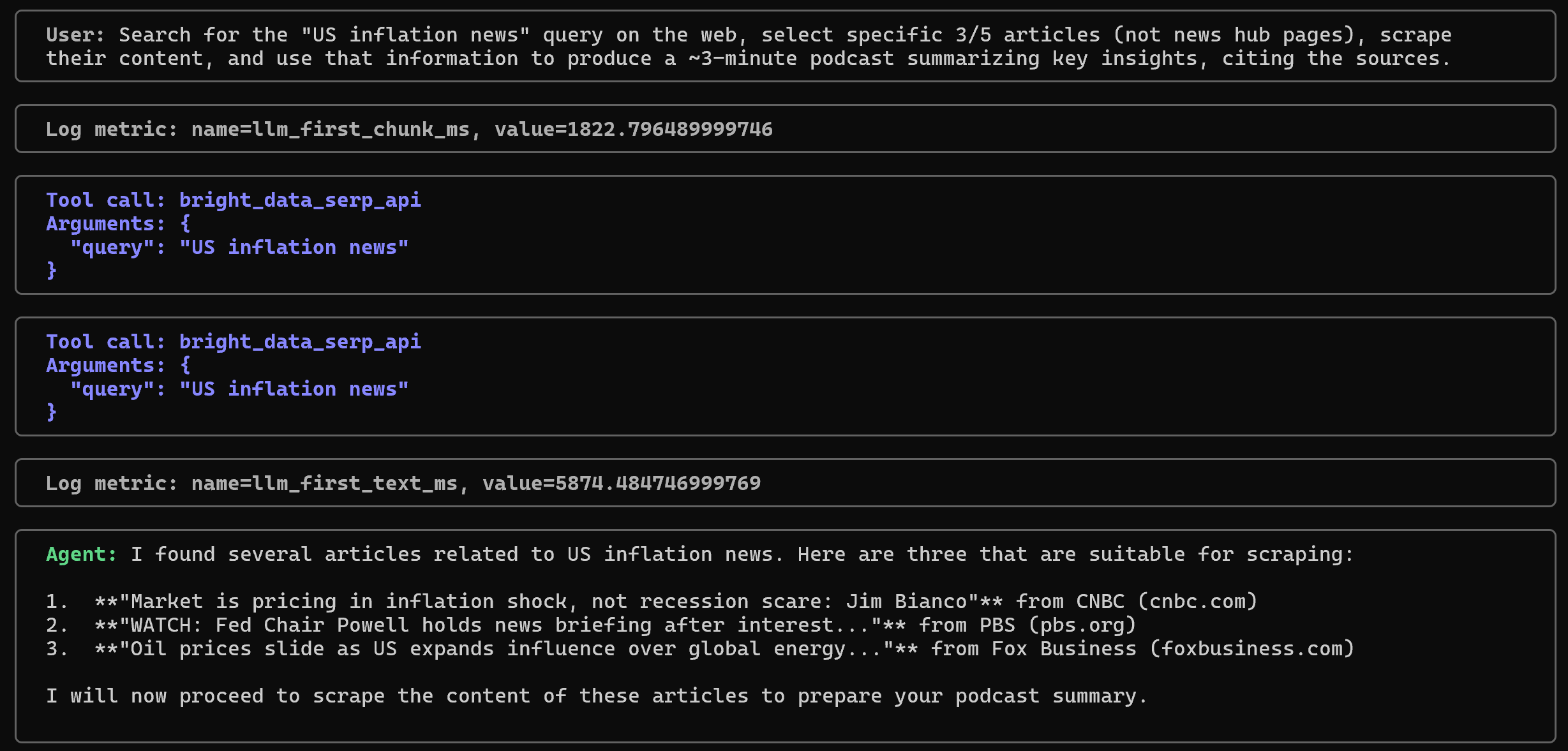
A continuación, extrae el contenido de cada página utilizando la herramienta bright_data_web_unlocker y elabora un resumen respaldado por las fuentes: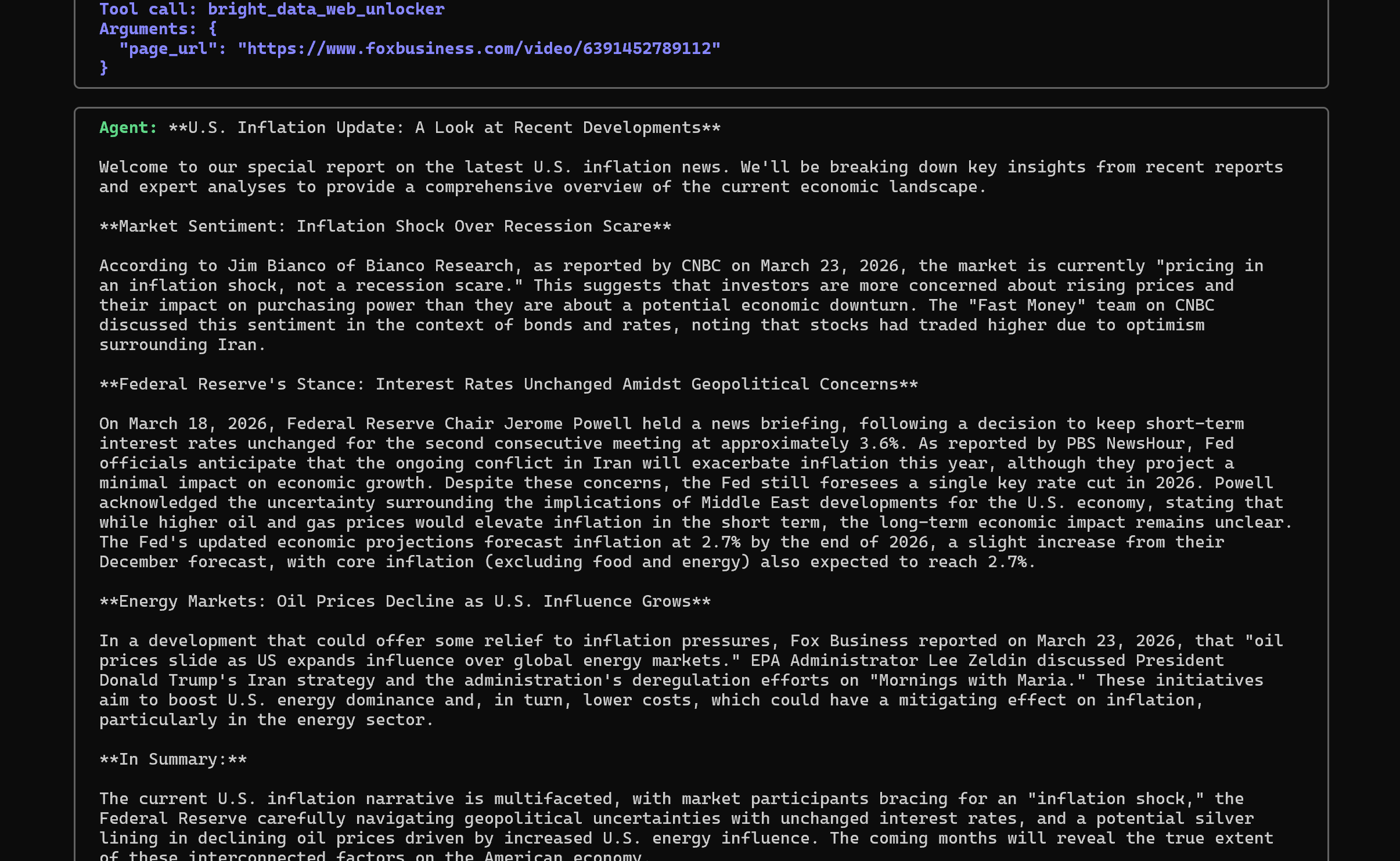
Fíjate en cómo el tono de la respuesta se asemeja al de un periodista, coincidiendo con el mensaje del sistema que definiste anteriormente.
¡Et voilà! Ha creado con éxito un agente de voz capaz de buscar y recuperar información de la web de forma activa, lo que da lugar a respuestas más precisas y sensibles al contexto. Esto no sería posible sin la integración de las herramientas de búsqueda y Scraping web de Bright Data.
Próximos pasos
Ahora que tienes un agente de voz con IA que funciona, el siguiente paso es implementarlo en Cartesia y llamarlo desde tu teléfono. Para perfeccionar y personalizar aún más tu agente según tus necesidades, consulta la documentación.
Por último, ten en cuenta que, tal y como hemos mostrado en este tutorial, puedes integrar otros productos de Bright Data basados en API. Esto ampliará las capacidades de tu agente.
Recuerda que Cartesia admite muchas integraciones, incluido LiveKit (otra tecnología para crear agentes de voz con IA). Para obtener más información, consulta cómo integrar Bright Data con LiveKit.
Conclusión
En esta entrada del blog, has aprendido qué es Cartesia y qué aporta al desarrollo de agentes de voz con IA. También has visto cuáles son sus limitaciones y cómo abordarlas utilizando las integraciones de Bright Data.
Al añadir dos herramientas especializadas a tus agentes de voz, les has dotado de la capacidad de buscar en la web y extraer datos de páginas web. Esto ha sido posible gracias a la conexión de tus agentes con herramientas personalizadas impulsadas por la API SERP y la API Web Unlocker de Bright Data.
Para ampliar aún más la funcionalidad —como acceder a feeds web en directo o automatizar interacciones web—, integra los agentes de voz de Cartesia con el conjunto completo de servicios de Bright Data para IA.
¡Regístrate hoy mismo para obtener una cuenta gratuita de Bright Data y empieza a integrar soluciones de datos web preparadas para la IA en tus agentes!





