

En esta guía sobre el ajuste fino de GPT-OSS con datos web, aprenderás:
- Qué es Unsloth y por qué acelera el ajuste fino
- Cómo recopilar datos de formación de calidad utilizando las API de scraping de Bright Data
- Cómo configurar su entorno para un ajuste fino eficiente
- Cómo ajustar GPT-OSS con un completo tutorial paso a paso
¡Empecemos!
¿Qué es Unsloth y por qué utilizarlo para el ajuste fino?
Unsloth es una librería ligera que agiliza considerablemente el ajuste fino de LLM y es totalmente compatible con el ecosistema Hugging Face (Hub, transformadores, PEFT, TRL). La librería es compatible con la mayoría de las GPU NVIDIA, desde la GTX 1070 hasta la H100, y funciona a la perfección con todo el conjunto de entrenadores de la librería TRL.

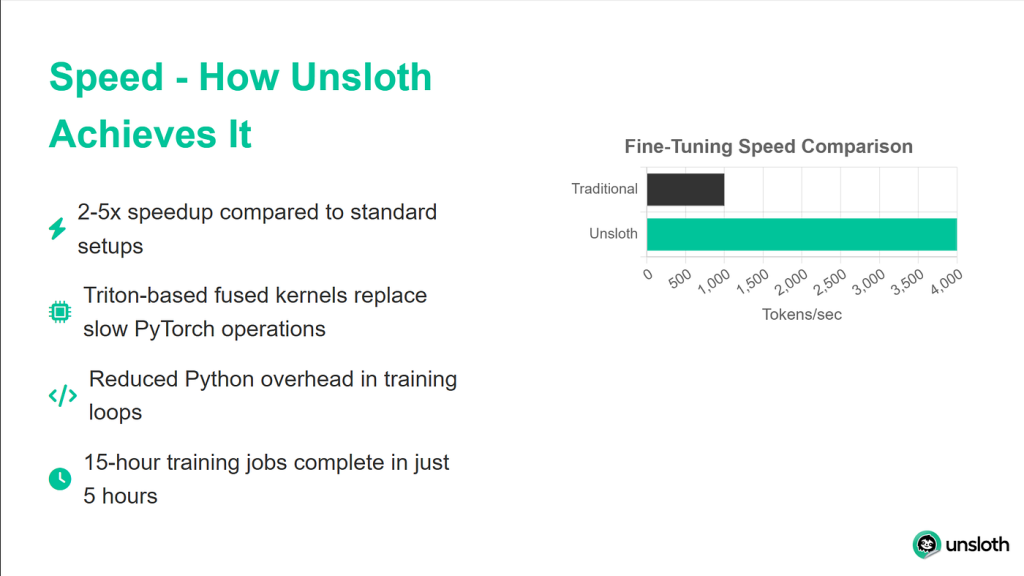
Las mejoras de rendimiento que proporciona Unsloth son impresionantes. En las pruebas comparativas, alcanza velocidades de entrenamiento dos veces más rápidas en comparación con las implementaciones de transformadores estándar, a la vez que utiliza un 40% menos de memoria. Esto significa que puede entrenar modelos más grandes o utilizar lotes de mayor tamaño con el mismo hardware. Y lo que es más importante, su precisión se degrada un 0%, por lo que se obtienen todas estas ventajas sin sacrificar la calidad del modelo.
Comprensión de los modelos GPT-OSS
El lanzamiento de GPT-OSS por parte de OpenAI marca un cambio significativo en su enfoque del desarrollo de IA. Por primera vez, tenemos acceso a auténticos modelos GPT sin limitaciones de API, facturación basada en el uso o límites de tarifa.
GPT-OSS se presenta en dos variantes principales:
- GPT-OSS-120B: este modelo de mayor tamaño iguala la calidad de GPT-4, pero requiere al menos 80 GB de memoria GPU.
- GPT-OSS-20B: comparable al rendimiento de GPT-3.5, este modelo funciona eficazmente en GPU de 16 GB (perfecto para nuestro tutorial).
Una característica única que diferencia a GPT-OSS de otros modelos abiertos es su control del esfuerzo de razonamiento. Puedes ajustar la profundidad con la que el modelo analiza los problemas estableciendo el nivel de razonamiento en “bajo”, “medio” o “alto”. Esto le permite equilibrar la velocidad y la precisión en función de su caso de uso específico.
Por qué los datos de calidad son importantes para el ajuste fino
Elajuste fino es tan bueno como los datos con los que se alimenta. Podemos tener la configuración de entrenamiento más sofisticada, pero si nuestros datos tienen ruido, son incoherentes o están mal formateados, el modelo aprenderá esos mismos problemas. Por eso utilizaremos las API de Raspador Web de Bright Data para obtener datos limpios, bien formateados y precisos.
Bright Data se encarga de las partes complejas del Scraping web que a menudo hacen fracasar las soluciones personalizadas. Gestiona la rotación de IP para evitar la limitación de velocidad, resuelve CAPTCHAs automáticamente, maneja contenido dinámico renderizado en JavaScript y mantiene una calidad de datos consistente a través de millones de solicitudes.
Para nuestro tutorial, utilizaremos la API de Bright Data para recopilar documentación de Python, que luego transformaremos en datos de entrenamiento para nuestro modelo.
Requisitos previos y configuración del entorno
Antes de empezar, vamos a asegurarnos de que dispone de todo lo necesario para realizar con éxito el ajuste fino. Utilizaremos Google Colab porque proporciona acceso gratuito a la GPU, pero el mismo proceso funciona en cualquier máquina con al menos 16 GB de VRAM.
Requisitos de hardware
Para este tutorial, necesitarás
- Una GPU con al menos 16 GB de VRAM (T4, V100 o superior)
- 25GB de espacio libre en disco para los pesos de los modelos y los puntos de control
- Conexión a Internet estable para descargar modelos y dependencias
En Google Colab, puedes acceder a una GPU T4 de forma gratuita:
- Abriendo un nuevo bloc de notas
- Ir a Tiempo de ejecución → Cambiar tipo de tiempo de ejecución
- Seleccionando la GPU como acelerador de hardware
- Haciendo clic en Guardar para aplicar los cambios
Instalación de Unsloth y sus dependencias
Una vez que tu GPU runtime esté listo, instalaremos Unsloth y todas las dependencias necesarias. El proceso de instalación está optimizado para evitar conflictos entre las distintas versiones de los paquetes:
%%captura
# Instalar Unsloth y las dependencias del núcleo
pip install --upgrade -qqq uv
try: import numpy; get_numpy = f "numpy=={numpy.__version__}"
except: get_numpy = "numpy"
!uv pip install -qqq
"torch>=2.8.0" "triton>=3.4.0" {get_numpy} torchvision bitsandbytes "transformers>=4.55.3"
"unsloth_zoo[base] @ git+https://github.com/unslothai/unsloth-zoo"
"unsloth[base] @ git+https://github.com/unslothai/unsloth"
git+https://github.com/triton-lang/triton.git@05b2c186c1b6c9a08375389d5efe9cb4c401c075#subdirectory=python/triton_kernels
!uv pip install --upgrade --no-deps transformers==4.56.2 tokenizers
pip install --no-deps trl==0.22.2
!pip install -q brightdata-sdkEste script de instalación se encarga de varios detalles importantes. En primer lugar, utiliza uv para una resolución de paquetes más rápida. También fija versiones específicas para evitar problemas de compatibilidad, instala los kernels Triton personalizados de Unsloth para un rendimiento óptimo e incluye el SDK de Bright Data para nuestro paso de recopilación de datos.
Verificación de la configuración de la GPU
Después de la instalación, vamos a verificar que su GPU se detecta correctamente y tiene suficiente memoria:
importar torch
# Obtener información de la GPU
gpu_stats = torch.cuda.get_device_properties(0)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f "GPU = {gpu_stats.name}")
print(f "Memoria máxima = {max_memory} GB")
print(f "Versión CUDA = {torch.version.cuda}")
print(f "Versión de PyTorch = {torch.__version__}")
# Verificar los requisitos mínimos
if max_memory < 15:
print("⚠️ Advertencia: Su GPU podría no tener suficiente memoria para GPT-OSS-20B")
si no:
print("✅ Tu GPU tiene memoria suficiente para el ajuste fino")Deberías ver al menos 15 GB de memoria disponible en la GPU. La GPU T4 del Colab libre proporciona 16GB, lo que es perfecto para nuestras necesidades con las optimizaciones de Unsloth.
Cargando GPT-OSS con Unsloth
Ahora cargaremos el modelo GPT-OSS utilizando el cargador optimizado de Unsloth. El proceso es notablemente sencillo en comparación con los transformadores estándar, ya que Unsloth maneja todos los detalles de optimización automáticamente.
Carga del modelo base
from unsloth import FastLanguageModel
importar torch
# Configuración
max_seq_length = 1024 # Ajuste basado en sus datos
dtype = None # Auto-detecta el mejor dtype para tu GPU
# Unsloth proporciona modelos pre-cuantizados para una carga más rápida
fourbit_models = [
"unsloth/gpt-oss-20b-unsloth-bnb-4bit", # BitsAndBytes 4bit
"unsloth/gpt-oss-120b-unsloth-bnb-4bit",
"unsloth/gpt-oss-20b", # Formato MXFP4
"unsloth/gpt-oss-120b",
]
# Cargar el modelo
model, tokenizer = FastLanguageModel.from_pretrained(
nombre_modelo = "unsloth/gpt-oss-20b",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True, # Esencial para ajustar en 16GB
full_finetuning = False, # Utilizar LoRA por eficiencia
)
print(f"✅ ¡Modelo cargado con éxito!")
print(f "Tamaño del modelo: {model.num_parameters():,} parámetros")
print(f "Usando dispositivo: {model.dispositivo}")El método FastLanguageModel.from_pretrained( ) hace varias cosas entre bastidores. Detecta automáticamente las capacidades de tu GPU y las optimiza en consecuencia, aplica cuantificación de 4 bits para reducir el uso de memoria en un 75%, configura el modelo para entrenamiento LoRA en lugar de un ajuste fino completo y configura mecanismos de atención eficientes en memoria.
Configuración de los adaptadores LoRA
LoRA (Low-Rank Adaptation) es lo que hace posible el ajuste fino en el hardware de consumo. En lugar de actualizar todos los parámetros del modelo, sólo entrenamos pequeñas matrices adaptadoras que se insertan en las capas clave:
model = FastLanguageModel.get_peft_model(
model,
r = 8, # rango LoRA - más alto = más capacidad pero más lento
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16, # Factor de escala LoRA
lora_dropout = 0, # Dropout desactivado para un entrenamiento más rápido
bias = "none", # No entrenar términos de sesgo
use_gradient_checkpointing = "unsloth", # Crítico para ahorrar memoria
random_state = 3407,
use_rslora = False, # LoRA estándar funciona mejor en la mayoría de los casos
loftq_config = None,
)
# Mostrar estadísticas de entrenamiento
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
porcentaje_entrenable = 100 * parámetros_entrenables / todos_los_parámetros
print(f "Entrenando {parámetros_entrenables:,} parámetros de {todos_los_parámetros:,}")
print(f "¡Sólo es el {porcentaje_entrenable:.2f}% de todos los parámetros!")
print(f "Memoria ahorrada: ~{(1 - porcentaje_entrenable/100) * 40:.1f}GB")Esta configuración consigue un equilibrio entre la eficiencia del entrenamiento y la capacidad del modelo. Con r=8, estamos entrenando menos del 1% de los parámetros totales y, al mismo tiempo, obtenemos excelentes resultados de ajuste. La comprobación del gradiente por sí sola ahorra alrededor de un 30% de memoria, lo que puede suponer la diferencia entre ajustar el modelo en memoria u obtener errores OOM (Out of Memory).
Prueba del control del esfuerzo de razonamiento GPT-OSS
Antes de empezar con el ajuste fino, vamos a explorar la característica única de esfuerzo de razonamiento de GPT-OSS. Esto le permite controlar cuánto “piensa” el modelo antes de responder:
from transformers import TextStreamer
# Problema de prueba que requiere razonamiento matemático
mensajes = [
{"rol": "usuario", "contenido": "Resuelve x^5 + 3x^4 - 10 = 3. Explica tu planteamiento"},
]
# Prueba con BAJO esfuerzo de razonamiento
print("="*60)
print("RAZONAMIENTO BAJO (Rápido pero menos minucioso)")
print("="*60)
inputs = tokenizer.apply_chat_template(
mensajes,
add_generation_prompt = True,
return_tensores = "pt",
return_dict = True
reasoning_effort = "low",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, max_new_tokens = 128, streamer = text_streamer)
# Prueba con esfuerzo de razonamiento ALTO
print("n" + "="*60)
print("ALTO RAZONAMIENTO (Más lento pero más preciso)")
print("="*60)
inputs = tokenizer.apply_chat_template(
mensajes,
add_generation_prompt = True,
return_tensores = "pt",
return_dict = True
reasoning_effort = "high",
).to("cuda")
_ = model.generate(**inputs, max_new_tokens = 512, streamer = text_streamer)Cuando ejecutemos este código, veremos que con el razonamiento “bajo”, el modelo da una respuesta rápida aproximada, mientras que el razonamiento “alto” produce una solución más detallada con un trabajo paso a paso. Esta característica es muy valiosa para equilibrar la velocidad y la precisión en los despliegues de producción.
Recopilación de datos de entrenamiento con Bright Data
Ahora recopilaremos datos de entrenamiento de alta calidad utilizando la API Raspador Web de Bright Data. Este enfoque es mucho más fiable que crear su propio raspador, ya que Bright Data gestiona toda la compleja infraestructura necesaria para el Scraping web a gran escala.
Configuración del recolector de datos
from brightdata import bdclient
de typing import List, Dict
import re
importar json
clase DataCollector:
def __init__(self, api_token: str):
"""
Inicializar cliente de Bright Data para Scraping web.
Args:
api_token: Su token de API de Bright Data
"""
self.client = bdclient(api_token=api_token)
self.datos_recogidos = []
print("✅ Cliente de Bright Data inicializado")
def recoger_documentacion(self, urls: List[str]) -> List[Dict]:
"""
Recoge las páginas de documentación y las convierte en datos de entrenamiento.
Este método maneja tanto el raspado por lotes como el raspado individual de URLs,
volviendo automáticamente a las peticiones individuales si el lote falla.
"""
print(f "Comenzando a raspar {len(urls)} URLs...")
try:
# Intentar el scraping por lotes para mayor eficiencia
results = self.client.scrape(urls, data_format="markdown")
if isinstance(results, str):
# Se devuelve un único resultado
print("Procesando un único resultado...")
training_data = self.process_single_result(results)
elif isinstance(resultados, lista):
# Se devuelven varios resultados
print(f "Procesando {len(resultados)} resultados...")
datos_entrenamiento = []
para i, contenido en enumerar(resultados, 1):
if contenido:
print(f" Procesando resultado {i}/{len(resultados)}")
ejemplos = self.proces_single_result(contenido)
training_data.extend(ejemplos)
si no
print(f "Tipo de resultado inesperado: {tipo(resultados)}")
datos_entrenamiento = []
except Exception as e:
print(f "Error en la búsqueda por lotes: {e}")
print("Volviendo a la búsqueda de URL individuales...")
# Fallback: raspado de URLs una a una
datos_entrenamiento = []
for url in urls:
try:
print(f" Scraping: {url}")
content = self.client.scrape(url, data_format="markdown")
si contenido:
ejemplos = self.process_single_result(contenido)
training_data.extend(ejemplos)
print(f" ✓ Ejemplos extraídos {len(ejemplos)}")
except Excepción como url_error:
print(f" ✗ Falló: {url_error}")
self.datos_recogidos = datos_entrenamiento
print(f"✗ Recopilación completa: {len(self.datos_recogidos)} ejemplos de entrenamiento")
return datos_recogidosQué hace este código:
- Estrategia de recuperación inteligente: El recopilador intenta primero la recopilación por lotes por eficiencia. Si esto falla (debido a problemas de red o a límites de la API), automáticamente vuelve al raspado de URL individuales.
- Seguimiento del progreso: Las actualizaciones en tiempo real nos muestran exactamente lo que está sucediendo durante el proceso de raspado, lo que facilita la depuración.
- Resistencia a errores: Cada URL está envuelta en su propio bloque try-catch, por lo que una URL fallida no detendrá todo el proceso de recopilación.
- Formato Markdown: Solicitamos los datos en formato Markdown porque es más limpio que el HTML y más fácil de procesar en datos de formación.
El cliente de Bright Data gestiona varias tareas complejas por nosotros:
- Rotación de direcciones IP para evitar la limitación de velocidad
- Resolución de CAPTCHA automáticamente
- Procesamiento de páginas con mucho JavaScript
- Reintento de solicitudes fallidas con backoff exponencial
Procesamiento de contenido raspado para convertirlo en datos de entrenamiento
La clave de un buen ajuste son unos datos limpios y bien formateados. Así es como procesamos el contenido extraído en pares pregunta-respuesta:
def process_single_result(self, content: str) -> List[Dict]:
"""
Procesa el contenido raspado en pares de preguntas y respuestas limpios.
Este método realiza una limpieza agresiva para
artefactos de formato y crear ejemplos que suenen naturales.
"""
ejemplos = []
# Paso 1: Eliminar todo el formato HTML y Markdown
content = re.sub(r'<[^>]+>', '', content) # Etiquetas HTML
content = re.sub(r'', '', content) # Imágenes
content = re.sub(r'[([^]]+)]([^)]+)', r'1', content) # Enlaces
content = re.sub(r'```[^`]*```', '', content) # Bloques de código
content = re.sub(r'`[^`]+`', '', content) # Código inline
content = re.sub(r'[#*_~>`|-]+', ' ', content) # Símbolos Markdown
content = re.sub(r'(.)', r'1', content) # Secuencias de escape
content = re.sub(r'https?://[^s]+', '', content) # URLs
content = re.sub(r'S+.w+', '', content) # Rutas de archivos
content = re.sub(r's+', ' ', content) # Normalizar los espacios en blanco
# Paso 2: Dividir en frases
frases = re.split(r'(?<=[.!?])s+', contenido)
# Paso 3: Filtrar la navegación y el contenido repetitivo
frases_limpias = []
skip_patterns = ['navegación', 'copyright', 'índice',
'índice', 'anterior', 'siguiente',
haga clic aquí", "descargar", "compartir"].
for sent in sent:
sent = sent.strip()
# Mantener sólo las frases sustanciales
if (len(sent) > 30 and
not any(skip in sent.lower() for skip in skip_patterns)):
clean_sentences.append(sent)
# Paso 4: Crear pares de preguntas y respuestas a partir de frases consecutivas
for i in range(0, len(frases_limpias) - 1):
instrucción = frases_limpias[i][:200].strip()
response = frases_limpias[i + 1][:300].strip()
# Asegúrese de que ambas partes son sustanciales
si len(instrucción) > 20 y len(respuesta) > 30:
examples.append({
"instrucción": instrucción
"respuesta": respuesta
})
devolver ejemplosCómo funciona el procesamiento:
El método process_single_result transforma el contenido web sin procesar en datos de entrenamiento limpios a través de cuatro pasos críticos:
- Paso 1 – Limpieza agresiva: Eliminamos todos los artefactos de formato que podrían confundir al modelo:
- Etiquetas HTML que podrían haber sobrevivido a la conversión a Markdown
- Referencias a imágenes y enlaces que no añaden valor a la comprensión del texto.
- Bloques de código y código en línea (queremos prosa, no muestras de código).
- Caracteres especiales y secuencias de escape que crean ruido
- Paso 2 – Segmentación de frases: Dividimos el contenido en frases individuales utilizando marcadores de puntuación. Así obtenemos unidades lógicas de texto con las que trabajar.
- Paso 3 – Filtrado de calidad: Eliminamos:
- Las frases cortas (menos de 30 caracteres) que carecen de sustancia.
- Elementos de navegación como “haga clic aquí” o “página siguiente”.
- Contenido repetitivo como avisos de copyright
- Cualquier frase que contenga patrones comunes de navegación web
- Paso 4 – Creación de pares: Creamos pares de entrenamiento tratando frases consecutivas como pares de pregunta-respuesta. Esto funciona porque la documentación suele seguir el patrón de enunciar un concepto y luego explicarlo.
El resultado son datos de entrenamiento limpios y contextuales que enseñan al modelo patrones naturales de flujo y respuesta.
Recopilación y validación de los datos
Ahora pongamos todo junto y recopilemos nuestros datos de entrenamiento:
# Inicializa el recopilador con tu token de API.
# Obtenga su token de /cp/api_tokens
BRIGHTDATA_API_TOKEN = "tu_brightdata_api_token_aquí"
collector = DataCollector(api_token=BRIGHTDATA_API_TOKEN)
# URLs to scrape - Python documentation makes excellent training data
urls = [
"https://docs.python.org/3/tutorial/introduction.html",
"https://docs.python.org/3/tutorial/controlflow.html",
"https://docs.python.org/3/tutorial/datastructures.html",
"https://docs.python.org/3/tutorial/modules.html",
"https://docs.python.org/3/tutorial/classes.html",
]
print("="*60)
print("COMENZANDO RECOGIDA DE DATOS")
print("="*60)
training_data = collector.collect_documentation(urls)
# Validar que tenemos datos
if len(datos_entrenamiento) == 0:
print("⚠️ ERROR: ¡No se han recopilado datos de entrenamiento!")
print("Solución de problemas:")
print("1. Compruebe que su token de la API de Bright Data es correcto")
print("2. Compruebe que su cuenta tiene créditos suficientes")
print("3. Pruebe primero con una única URL para comprobar la conectividad")
raise ValueError("No se han recopilado datos de entrenamiento")Comprendiendo la configuración de la recogida de datos:
- API Token: Tendrá que registrarse en una cuenta de Bright Data para obtener su token de API. Ofrece una prueba gratuita con créditos para empezar.
- Selección de URL: Estamos utilizando la documentación de Python porque:
- Está bien estructurada y es coherente
- Contiene contenido técnico perfecto para la formación de un asistente de codificación
- El estilo explicativo se traduce bien al formato de preguntas y respuestas.
- Está disponible públicamente y su origen es ético.
- Gestión de errores: La comprobación de validación garantiza que no se proceda con un conjunto de datos vacío, lo que provocaría que el entrenamiento fallara posteriormente. Los pasos de resolución de problemas ayudan a diagnosticar los problemas más comunes.
Validación y limpieza final de los datos
Antes de utilizar los datos para el entrenamiento, realizamos una limpieza final:
# Validación y limpieza final
def validacion_final(ejemplos: Lista[Dict]) -> Lista[Dict]:
"""
Realizar la validación final y la deduplicación de los ejemplos de entrenamiento.
"""
datos_limpios = []
instrucciones_vistas = set()
para ex en ejemplos:
instrucción = ex.get('instrucción', '').strip()
respuesta = ex.get('respuesta', '').strip()
# Última pasada de limpieza
instrucción = re.sub(r'[^a-zA-Z0-9s.,?!]', '', instrucción)
respuesta = re.sub(r'[^a-zA-Z0-9s.,?!]', '', respuesta)
# Eliminar duplicados y garantizar la calidad
if (len(instruction) > 10 and
len(response) > 20 and
instruction not in seen_instructions):
instrucciones_visto.add(instrucción)
datos_limpios.append({
"instrucción": instrucción
"respuesta": respuesta
})
devolver datos_limpios
datos_entrenamiento = validación_final(datos_entrenamiento)
print(f"n✅ Conjunto final de datos: {len(datos_entrenamiento)} ejemplos únicos")
print("nMuestra ejemplos de entrenamiento:")
print("="*60)
for i, example in enumerate(datos_entrenamiento[:3], 1):
print(f "Ejemplo {i}:")
print(f "Q: {ejemplo['instrucción']}")
print(f "A: {ejemplo['respuesta']}")Qué consigue la validación:
- Deduplicación: El conjunto de
instrucciones vistasgarantiza que no haya preguntas duplicadas, lo que podría dar lugar a un ajuste excesivo durante el entrenamiento. - Limpieza final de caracteres: Eliminamos todos los caracteres especiales restantes, excepto los signos de puntuación básicos, para garantizar la limpieza y coherencia del texto.
- Validación de la longitud: Aplicamos longitudes mínimas para garantizar que los ejemplos tengan sustancia:
- Las instrucciones deben tener al menos 10 caracteres.
- Las respuestas deben tener al menos 20 caracteres.
- Garantía de calidad: Al imprimir ejemplos de muestra, puede verificar visualmente la calidad de los datos antes de proceder a la formación.
El resultado final debe mostrar pares de preguntas y respuestas limpios y legibles que tengan sentido como datos de entrenamiento. Si los ejemplos no tienen sentido o están mal formateados, es posible que tenga que ajustar los parámetros de procesamiento o elegir diferentes URL de origen.
Consejo profesional: Para casos de uso en producción, considere la posibilidad de utilizar el mercado de Bright Data para Conjuntos de datos previamente recopilados. Ofrece Conjuntos de datos curados para varios dominios que pueden ahorrarle mucho tiempo y garantizar una calidad consistente.
Formateo de datos para la formación de GPT-OSS
GPT-OSS espera datos en un formato de chat específico. Utilizaremos las utilidades de Unsloth para asegurarnos de que nuestros datos están formateados correctamente para obtener unos resultados de entrenamiento óptimos:
from unsloth.chat_templates import standardize_sharegpt
from Conjuntos de datos import Conjunto de datos
def preparar_conjunto_datos(datos_brutos: Lista[Dict]):
"""
Convierte los pares de preguntas y respuestas sin procesar en un conjunto de datos de entrenamiento con el formato adecuado.
Esta función maneja:
1. 1. Conversión al formato de mensaje
2. Aplicación de la plantilla de chat GPT-OSS
3. Corregir cualquier problema de formato
"""
print("Preparando conjunto de datos para entrenamiento...")
# Paso 1: Convertir a formato de mensaje de chat
datos_formateados = []
for item in datos_brutos:
formatted_data.append({
"mensajes": [
{"rol": "usuario", "contenido": item["instrucción"]},
{"rol": "asistente", "contenido": item["respuesta"]}
]
})
# Paso 2: Creación del conjunto de datos HuggingFace
dataset = Dataset.from_list(datos_formateados)
print(f "Conjunto de datos creado con {len(conjunto_datos)} ejemplos")
# Paso 3: Normalizar al formato ShareGPT
dataset = standardize_sharegpt(dataset)Lo que ocurre en esta primera parte
- Conversión del formato de los mensajes: Transformamos nuestros sencillos pares de preguntas y respuestas en un formato de conversación que esperan los modelos GPT. Cada ejemplo de entrenamiento se convierte en una conversación de dos turnos con una pregunta del usuario y una respuesta del asistente.
- Creación de Conjuntos de datos: La clase Dataset de HuggingFace proporciona un manejo eficiente de los datos, incluyendo:
- Acceso a mapas de memoria para Conjuntos de datos de gran tamaño.
- Batching y shuffling integrados
- Compatibilidad con todo el ecosistema HuggingFace.
- Estandarización de ShareGPT: La función
standardize_sharegptgarantiza que nuestros datos coincidan con el formato ShareGPT, que se ha convertido en el estándar de facto para la formación de modelos de chat. De este modo se gestionan los casos extremos y se garantiza la coherencia.
Aplicación del modelo de chat
Ahora aplicaremos los requisitos de formato específicos de GPT-OSS:
# Paso 4: Aplicar la plantilla de chat específica de GPT-OSS
def formatting_prompts_func(ejemplos):
"""Aplicar la plantilla de chat de GPT-OSS a cada ejemplo."""
convos = ejemplos["mensajes"]
textos = []
for convo in convos:
# Aplicar plantilla sin aviso de generación (estamos entrenando)
text = tokenizer.apply_chat_template(
convo,
tokenize = False,
add_generation_prompt = False
)
texts.append(texto)
return {"texto": textos}
Conjuntos de datos = dataset.map(
formatting_prompts_func,
batched = True,
desc = "Aplicar plantilla de chat"
)Comprender la aplicación de la plantilla
- Plantilla de chat Propósito: Cada familia de modelos tiene sus propios tokens y formatos especiales. GPT-OSS utiliza etiquetas como
<|start|>,<|message|>, y<|channel|>para delinear las diferentes partes de la conversación. - No hay aviso de generación: Establecemos
add_generation_prompt = Falseporque estamos entrenando, no generando. Durante el entrenamiento, queremos que el modelo vea conversaciones completas, no avisos esperando a ser completados. - Procesamiento por lotes: El parámetro
batched = Trueprocesa varios ejemplos a la vez, lo que acelera significativamente el proceso de formateo para Conjuntos de datos de gran tamaño. - Salida de texto: Mantenemos la salida como texto (sin tokenizar) en esta fase, ya que el formador se encargará de la tokenización con su propia configuración.
Verificación y corrección de problemas de formato
GPT-OSS tiene un requisito específico para la etiqueta de canal que debemos verificar:
# Paso 5: Verificar y corregir la etiqueta de canal si es necesario
sample_text = dataset[0]['text']
print("comprobando formato...")
print(f "Muestra (primeros 200 caracteres): {sample_text[:200]}")
if "<|canal|>" not in texto_de_muestra:
print("⚠️ Falta etiqueta de canal, corrigiendo formato...")
def arreglar_formato(ejemplos):
"""Añade la etiqueta channel para compatibilidad con GPT-OSS."""
textos_fijados = []
for text in ejemplos["texto"]:
# GPT-OSS espera la etiqueta channel entre rol y mensaje
text = text.replace(
"<|inicio|>asistente<|mensaje|>",
"<|inicio|>asistente<|canal|>final<|mensaje|>"
)
fixed_texts.append(texto)
return {"texto": textos_fijados}
Conjuntos de datos = dataset.map(
formato_fijo,
batched = True,
desc = "Añadir etiquetas de canal"
)
print("✅ Formato corregido")
print(f"n✅ Conjunto de datos listo: {len(dataset)} ejemplos formateados")
return Conjuntos de datos
# Preparar el conjunto de datos
dataset = prepare_dataset(training_data)Por qué es importante la etiqueta de canal
- Función de la etiqueta de canal: La etiqueta
<|canal|>finalle dice a GPT-OSS que esta es la respuesta final, no un paso de razonamiento intermedio. Esto es parte del sistema único de control de esfuerzo de razonamiento de GPT-OSS. - Verificación del formato: Comprobamos si la etiqueta existe y la añadimos si falta. De este modo se evitan los fallos de formación debidos a desajustes de formato.
- Corrección automática: La operación de sustitución garantiza la compatibilidad sin necesidad de intervención manual. Esto es especialmente importante cuando se utilizan diferentes versiones de tokenizadores que pueden tener diferentes comportamientos por defecto.
Estadísticas y validación de los conjuntos de datos
Por último, verifiquemos nuestro conjunto de datos preparado:
# Mostrar estadísticas
print("Estadísticas del conjunto de datos:")
print(f "Número de ejemplos: {len(conjuntodatos)}")
print(f "Longitud media del texto: {sum(len(x['texto']) for x in dataset) / len(dataset):.0f} chars")
# Mostrar un ejemplo completo formateado
print("nEjemplo formateado:")
print("="*60)
print(conjunto de datos[0]['texto'][:500])
print("="*60)
# Verificar que todos los ejemplos tienen el formato correcto
format_checks = {
"has_user_tag": all("<|start|>user" in ex['text'] for ex in dataset),
"has_assistant_tag": all("<|start|>assistant" in ex['text'] for ex in dataset),
"has_channel_tag": all("<|channel|>" in ex['text'] for ex in dataset),
"has_message_tags": all("<|message|>" in ex['text'] for ex in dataset),
}
print("nValidación de formato:")
para comprobación, pasada en format_checks.items():
status = "✅" if passed else "❌"
print(f"{estado} {comprobación}: {pasado}")Qué buscar en la validación:
- Estadísticas de longitud: La longitud media del texto te ayuda a establecer longitudes de secuencia adecuadas para el entrenamiento. Si es demasiado larga, puede que tenga que truncarla o utilizar una longitud máxima mayor.
- Formato completo: Las cuatro comprobaciones deben superarse:
- Las etiquetas de usuario indican dónde comienza la entrada del usuario
- Las etiquetas de asistente marcan las respuestas del modelo
- Las etiquetas de canal especifican el tipo de respuesta
- Las etiquetas de mensaje contienen el contenido real
- Inspección visual: El ejemplo impreso le permite ver exactamente en qué se entrenará el modelo. Debería parecerse a:
<|inicio|>usuario<|mensaje|>Su pregunta aquí<|fin|>
<|start|>assistant<|channel|>final<|message|>La respuesta aquí<|end|>Si falla alguna validación, es posible que el entrenamiento no funcione correctamente o que el modelo aprenda patrones incorrectos. La corrección automática debería resolver la mayoría de los problemas, pero la inspección manual ayuda a detectar casos extremos.
Configuración del entrenamiento con Unsloth y TRL
Ahora estableceremos la configuración del entrenamiento. Unsloth se integra perfectamente con la librería TRL de Hugging Face, dándonos lo mejor de ambos mundos: las optimizaciones de velocidad de Unsloth y los probados algoritmos de entrenamiento de TRL.
from trl import SFTConfig, SFTTrainer
from unsloth.chat_templates import train_on_responses_only
# Crear la configuración de entrenamiento
training_config = SFTConfig(
# Configuración básica
per_device_train_batch_size = 2, # Ajuste basado en la memoria de su GPU
gradient_accumulation_steps = 4, # Tamaño efectivo del lote = 2 * 4 = 8
warmup_steps = 5,
max_steps = 60, # Para pruebas rápidas; aumentar para producción
# Configuración de la tasa de aprendizaje
learning_rate = 2e-4,
lr_scheduler_type = "linear",
# Ajustes de optimización
optim = "adamw_8bit", # El optimizador de 8 bits ahorra memoria
weight_decay = 0.01,
# Registro y guardado
logging_steps = 1,
save_steps = 20,
output_dir = "salidas",
# Configuración avanzada
seed = 3407, # Para reproducibilidad
fp16 = True, # Entrenamiento de precisión mixta
report_to = "none", # Establecer en "wandb" para el seguimiento del experimento
)
print("Configuración de entrenamiento:")
print(f" Tamaño efectivo del lote: {training_config.per_device_train_batch_size * training_config.gradient_accumulation_steps}")
print(f" Pasos totales de entrenamiento: {training_config.max_steps}")
print(f" Tasa de aprendizaje: {training_config.learning_rate}")Configuración del entrenador
El SFTTrainer (Supervised Fine-Tuning Trainer) se encarga de toda la complejidad del entrenamiento:
# Inicializar el entrenador
entrenador = SFTTrainer(
modelo = modelo,
tokenizer = tokenizer,
train_dataset = dataset,
args = configuración_entrenamiento,
)
print("✅ Entrenador inicializado")
# Configurar para entrenar sólo con las respuestas del asistente.
# Esto es crucial - no queremos que el aprendizaje del modelo genere preguntas del usuario
gpt_oss_kwargs = dict(
instruction_part = "<|start|>user<|message|>",
response_part = "<|start|>assistant<|channel|>final<|message|>"
)
entrenador = entrenar_sobre_respuestas_solo(
trainer,
**gpt_oss_kwargs,
)
print("✅ Configurado para entrenamiento de sólo respuesta")Comprender la configuración del entrenador:
- Integración de SFTTrainer: El entrenador combina varios componentes:
- Su modelo configurado con LoRA
- El tokenizador para procesar texto
- Su conjunto de datos preparado
- Los parámetros de configuración del entrenamiento
- Entrenamiento de sólo respuesta: Esto es fundamental para los modelos de chat. Al utilizar
train_on_responses_only, nos aseguramos:- El modelo sólo calcula la pérdida en las respuestas del asistente
- No aprende a generar preguntas del usuario
- El entrenamiento es más eficiente (hay que optimizar menos tokens).
- El modelo mantiene su capacidad para comprender diversas entradas del usuario.
- Etiquetas específicas de GPT-OSS: Las partes de instrucción y respuesta deben coincidir exactamente con lo que contienen los datos formateados. Estas etiquetas indican al entrenador dónde dividir entre lo que debe ignorar (entrada del usuario) y lo que debe entrenar (respuesta del asistente).
Verificación de la máscara de entrenamiento
Es importante verificar que sólo estamos entrenando las respuestas del asistente, no las preguntas del usuario:
# Verificar que la máscara de entrenamiento es correcta
print("Verificando la máscara de entrenamiento...")
muestra = trainer.train_dataset[0]
# Decodificar las etiquetas para ver con qué estamos entrenando
-100 indica que no estamos entrenando (enmascarado)
fichas_visibles = []
for token_id, label_id in zip(sample["input_ids"], sample["labels"]):
if label_id != -100:
visible_tokens.append(token_id)
si visible_tokens:
decoded = tokenizer.decode(visible_tokens)
print(f "Entrenamiento en: {decoded[:200]}...")
print("✅ Máscara verificada - sólo entrenamiento en respuestas")
si no:
print("⚠️ Advertencia: No se han detectado tokens de entrenamiento visibles")Lo que te dice la verificación de la máscara:
- La etiqueta -100: En PyTorch, -100 es un valor especial que le dice a la función de pérdida que ignore estos tokens. Así es como implementamos el entrenamiento de sólo respuesta:
- Los tokens de entrada del usuario se etiquetan como -100 (ignorados)
- Los tokens de respuesta del asistente mantienen sus IDs de token reales (entrenados)
- Comprobación de tokens visibles: Al extraer sólo los tokens no enmascarados, podemos ver exactamente de qué aprenderá el modelo. Sólo deberías ver el texto de respuesta del asistente, no la pregunta del usuario.
- Por qué es importante: Sin el enmascaramiento adecuado:
- El modelo podría aprender a generar preguntas del usuario en lugar de respuestas.
- El entrenamiento sería menos eficiente (optimizando tokens innecesarios)
- El modelo podría desarrollar comportamientos no deseados, como hacerse eco de las entradas del usuario.
- Consejos de depuración: Si ve texto introducido por el usuario en el texto descodificado, compruébelo:
- Las cadenas
instruction_partyresponse_partcoinciden exactamente - El formato del conjunto de datos incluye todas las etiquetas necesarias.
- El tokenizador aplica correctamente la plantilla de chat.
- Las cadenas
Inicio del proceso de entrenamiento
Con todo configurado, estamos listos para comenzar el entrenamiento. Vamos a monitorizar el uso de memoria de la GPU y a seguir el progreso del entrenamiento:
import time
importar torch
# Borra la caché de la GPU antes del entrenamiento
torch.cuda.empty_cache()
# Registra el estado inicial de la GPU
start_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
start_time = time.time()
print("="*60)
print("COMENZANDO ENTRENAMIENTO")
print("="*60)
print(f "Memoria GPU inicial reservada: {start_gpu_memory:.2f} GB")
print(f "Entrenamiento para {training_config.max_steps} pasos...")
print("Progreso del entrenamiento:")
# Comienza el entrenamiento
trainer_stats = trainer.train()
# Calcular las estadísticas de entrenamiento
training_time = time.time() - start_time
memoria_gpu_final = torch.cuda.max_memory_reserved() / 1024**3
memoria_utilizada = memoria_gpu_final - memoria_gpu_inicial
print("n" + "="*60)
print("ENTRENAMIENTO COMPLETO")
print("="*60)
print(f "Tiempo empleado: {tiempo_entrenamiento/60:.1f} minutos")
print(f "Pérdida final: {trainer_stats.metrics['train_loss']:.4f}")
print(f "Memoria de GPU utilizada para el entrenamiento: {memory_used:.2f} GB")
print(f "Memoria máxima de la GPU: {final_gpu_memory:.2f} GB")
print(f "Velocidad de entrenamiento: {trainer_stats.metrics.get('train_steps_per_second', 0):.2f} pasos/segundo")Comprensión de las métricas de entrenamiento:
- Gestión de la memoria de la GPU:
- Borrar la caché antes del entrenamiento libera la memoria no utilizada
- La monitorización del uso de memoria ayuda a optimizar el tamaño de los lotes para futuras ejecuciones.
- La diferencia entre el inicio y el final muestra la sobrecarga real del entrenamiento.
- Los picos de memoria indican lo cerca que se está de los errores de OOM.
- Indicadores de progreso del entrenamiento:
- Pérdida: debe disminuir con el tiempo. Si se estabiliza pronto, es posible que su ritmo de aprendizaje sea demasiado bajo.
- Pasos/segundo: Ayuda a estimar el tiempo de entrenamiento para Conjuntos de datos más grandes.
- Tiempo empleado: En una GPU T4, unos 10-15 minutos para 60 pasos.
- Qué hay que tener en cuenta durante el entrenamiento:
- Pérdida en constante disminución (bueno)
- Pérdida que salta erráticamente (tasa de aprendizaje demasiado alta)
- La pérdida no cambia (tasa de aprendizaje demasiado baja o problemas con los datos)
- Errores de memoria (reduzca el tamaño del lote o la longitud de la secuencia)
- Expectativas de rendimiento:
- GPU T4: 0,5-1,0 pasos/segundo
- V100: 1,5-2,5 pasos/segundo
- A100: 3-5 pasos/segundo
El entrenamiento debería completarse sin errores, y debería ver que la pérdida disminuye de alrededor de 2-3 inicialmente a menos de 1,0 al final.
Probar el modelo ajustado
Ahora viene la parte emocionante, ¡comprobar si nuestro ajuste ha funcionado! Crearemos una función de prueba completa y evaluaremos el modelo en varias preguntas relacionadas con Python:
from transformers import TextStreamer
def prueba_modelo(pregunta: cadena, razonamiento_esfuerzo: cadena = "medio", max_longitud: int = 256):
"""
Prueba el modelo ajustado con una pregunta dada.
Args:
Pregunta: La pregunta o instrucción
esfuerzo_razonamiento: "bajo", "medio" o "alto".
max_length: Máximo de tokens a generar
Devuelve:
La respuesta generada
"""
# Crear el formato del mensaje
mensajes = [
{"rol": "sistema", "contenido": "Eres un asistente experto en Python"},
{"rol": "usuario", "contenido": prompt}
]
# Aplicar plantilla de chat
inputs = tokenizer.apply_chat_template(
mensajes,
add_generation_prompt = True,
return_tensores = "pt",
return_dict = True,
esfuerzo_razonamiento = esfuerzo_razonamiento,
).to("cuda")
# Configurar el streaming para la salida en tiempo real
streamer = TextStreamer(
tokenizer,
skip_prompt=Verdadero,
skip_special_tokens=True
)
# Generar respuesta
salidas = model.generate(
**entradas,
max_new_tokens = max_length,
streamer = streamer,
temperatura = 0.7
top_p = 0.9,
do_sample = True,
)
# Decodificar y devolver la respuesta
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
devolver respuesta
# Prueba sobre varios temas de Python
preguntas_prueba = [
"¿Qué es un generador de Python y cuándo debo utilizarlo?
"¿Cómo leo un archivo CSV en Python?",
"Explica async/await en Python con un ejemplo sencillo",
"¿Cuál es la diferencia entre una lista y una tupla en Python?",
"¿Cómo manejo correctamente las excepciones en Python?",
]
print("="*60)
print("PRUEBA DEL MODELO AFINADO")
print("="*60)
for i, question in enumerate(preguntas_prueba, 1):
print(f"n{'='*60}")
print(f "Pregunta {i}: {pregunta}")
print(f"{'='*60}")
print("Respuesta:")
_ = modelo_prueba(pregunta, esfuerzo_razonamiento="medio")
print()
Debería notar que el modelo proporciona ahora respuestas más detalladas y específicas de Python en comparación con antes del ajuste. Las respuestas deberían reflejar el estilo de documentación y la profundidad técnica de tus datos de entrenamiento.
Probar distintos niveles de razonamiento
Probemos también cómo afecta el esfuerzo de razonamiento a las respuestas:
complex_question = "Escribe una función Python que encuentre todos los números primos hasta n usando el Tamiz de Eratóstenes"
print("="*60)
print("PRUEBA DE LOS NIVELES DE ESFUERZO DE RAZONAMIENTO")
print("="*60)
for esfuerzo in ["bajo", "medio", "alto"]:
print(f"n{'='*40}")
print(f "Esfuerzo de razonamiento: {esfuerzo.superior()}")
print(f"{'='*40}")
_ = modelo_prueba(pregunta_compleja, esfuerzo_razonamiento=esfuerzo, longitud_máxima=300)
print()Cuando ejecutes el código, verás que “bajo” ofrece una implementación básica, “medio” proporciona un buen equilibrio entre explicación y código, mientras que “alto” incluye explicaciones detalladas y optimizaciones.
Guardar e implantar el modelo
Una vez realizado el ajuste con éxito, querrá guardar su modelo para utilizarlo en el futuro. Tenemos varias opciones dependiendo de sus necesidades de despliegue:
Guardar localmente
importar os
# Crear directorio para guardar
save_dir = "gpt-oss-python-expert"
os.makedirs(save_dir, exist_ok=True)
print("Guardando el modelo localmente...")
# Opción 1: Guardar sólo los adaptadores LoRA (pequeño, ~200MB)
lora_save_dir = f"{save_dir}-lora"
model.save_pretrained(lora_save_dir)
tokenizer.save_pretrained(lora_save_dir)
print(f"✅ Adaptadores LoRA guardados en {lora_save_dir}")
# Comprueba el tamaño
lora_size = sum(
os.path.getsize(os.path.join(lora_save_dir, f))
for f in os.listdir(lora_save_dir)
) / (1024**2)
print(f" Tamaño: {lora_size:.1f} MB")
# Opción 2: Guardar modelo fusionado (tamaño completo, ~20GB)
merged_save_dir = f"{save_dir}-merged"
model.save_pretrained_merged(
merged_save_dir,
tokenizer,
save_method = "merged_16bit" # Opciones: "merged_16bit", "mxfp4"
)
print(f"✅ Modelo fusionado guardado en {merged_save_dir}")Envío a Hugging Face Hub
Para compartir y desplegar fácilmente tu modelo, envíalo a Hugging Face:
from huggingface_hub import login
# Accede a Hugging Face (necesitarás tu token)
# Obtén el token de: https://huggingface.co/settings/tokens
login(token="hf_...") # Sustitúyelo por tu token
# Empujar adaptadores LoRA (recomendado para compartir)
model_name = "tu-nombre-deusuario/gpt-oss-python-expert-lora"
print(f "Empujando adaptadores LoRA a {nombre_modelo}...")
model.push_to_hub(
nombre_modelo,
use_auth_token=True,
commit_message="Ajustado GPT-OSS en la documentación de Python"
)
tokenizer.push_to_hub(
nombre_modelo,
use_auth_token=True
)
print(f"✅ Modelo disponible en: https://huggingface.co/{nombre_modelo}")
# Opcionalmente empujar el modelo fusionado (lleva más tiempo)
if False: # Establecer en True si desea empujar el modelo completo
nombre_modelo_fusionado = "tu-nombre_de_usuario/gpt-oss-python-experto"
model.push_to_hub_merged(
nombre_modelo_fusionado,
tokenizer,
save_method = "mxfp4", # 4 bits para un tamaño más pequeño
use_auth_token=True
)Carga del modelo ajustado
A continuación se explica cómo cargar el modelo para su posterior inferencia:
from unsloth import FastLanguageModel
# Cargar desde el directorio local
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
# O cargar desde Hugging Face Hub
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "tu-nombre-de-usuario/gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
print("✅ ¡Modelo cargado y listo para la inferencia!")Estrategias de optimización para obtener mejores resultados
Estas son algunas de las estrategias que he encontrado útiles para optimizar el ajuste fino del modelo:
Técnicas de optimización de la memoria
Cuando se trabaja con memoria limitada en la GPU, estas técnicas pueden marcar la diferencia entre el éxito y los errores OOM:
# 1. Gradient checkpointing - cambia computación por memoria
model.gradient_checkpointing_enable()
# 2. Reduzca la longitud de la secuencia si sus datos lo permiten
max_seq_length = 512 # En lugar de 1024
# 3. Utilice tamaños de lote más pequeños con más acumulación
per_device_train_batch_size = 1
gradient_accumulation_steps = 16 # Aún efectivo tamaño de lote de 16
# 4. Habilitar la atención eficiente de la memoria (si es compatible)
model.config.use_flash_attention_2 = True
# 5. Limpiar la caché regularmente durante el entrenamiento
importar gc
gc.collect()
torch.cuda.empty_cache()Buenas prácticas de entrenamiento
Por experiencia, estas prácticas conducen a mejores resultados de ajuste:
- Empiece con poco: pruebe primero con 100 ejemplos. Si funciona, aumente gradualmente.
- Controle las métricas: Vigile el sobreajuste: si la pérdida de entrenamiento disminuye pero la pérdida de validación aumenta, deténgase antes.
- Mezcle los datos: Combine datos específicos del dominio con datos generales de instrucción para evitar olvidos catastróficos.
- Programación de la tasa de aprendizaje: Comience con el valor por defecto 2e-4, pero no tenga miedo de experimentar. He visto buenos resultados con 5e-5 para Conjuntos de datos más pequeños.
- Estrategia de comprobación: Guardar cada N pasos para que pueda recuperarse desde el mejor punto de control:
training_config = SFTConfig(
save_steps = 50,
save_total_limit = 3, # Guardar sólo 3 mejores puntos de control
load_best_model_at_end = True,
metric_for_best_model = "loss",
)Optimizaciones de velocidad
Para maximizar la velocidad de entrenamiento:
# Usar PyTorch 2.0 compile para un entrenamiento más rápido
if hasattr(torch, 'compile'):
model = torch.compile(model)
print("✅ Modelo compilado para un entrenamiento más rápido")
# Habilitar TF32 en las GPU Ampere (A100, RTX 30xx)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# Usar lotes más grandes si la memoria lo permite
# Los lotes más grandes suelen entrenar más rápido
tamaño_lote_óptimo = find_optimal_batch_size(model, max_memory=0.9)Opciones de despliegue para producción
Una vez ajustado el modelo, tiene varias opciones de despliegue:
API local rápida con FastAPI
Para la creación rápida de prototipos, cree una API sencilla:
# guardar como: api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
from unsloth import FastLanguageModel
app = FastAPI()
# Cargar el modelo una vez al inicio
model, tokenizer = Ninguno, Ninguno
@app.on_event("inicio")
async def load_model():
global model, tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
"gpt-oss-python-expert-lora",
max_seq_length = 1024,
load_in_4bit = True,
)
clase GenerateRequest(BaseModel):
prompt: str
esfuerzo_razonamiento: str = "medio
max_tokens: int = 256
@app.post("/generar")
async def generate(request: GenerateRequest):
if not model:
raise HTTPException(status_code=503, detail="Modelo no cargado")
messages = [{"rol": "user", "content": request.prompt}]
inputs = tokenizer.apply_chat_template(
mensajes,
add_generation_prompt = True,
return_tensors = "pt",
esfuerzo_razonamiento = request.esfuerzo_razonamiento,
).to("cuda")
salidas = model.generate(
**entradas,
max_new_tokens = request.max_tokens,
temperatura = 0.7,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"respuesta": respuesta}
# Ejecutar con: uvicorn api:app --host 0.0.0.0 --port 8000Despliegue de producción con vLLM
Para servicios de producción de alto rendimiento, vLLM ofrece un rendimiento excelente:
# Instalación de vLLM
pip install vLLm
# Sirva su modelo
python -m vllm.entrypoints.openai.api_server
--model gpt-oss-python-expert-merged
--tensor-parallel-size 1 --max-model-len 1024
--max-model-len 1024
--dtype float16Opciones de despliegue en la nube
Cada plataforma en la nube tiene sus ventajas:
Puntos finales de inferencia facial
- La configuración más sencilla: sólo tiene que pulsar y desplegar
- Ideal para pruebas y producción a pequeña escala
- Escalado automático disponible
- Perfecto para el despliegue sin servidor
- Pague sólo por el uso real
- Ideal para cargas de trabajo en ráfagas
- Más rentable para un servicio 24/7
- Control total del entorno
- Bueno para aplicaciones de alto rendimiento
- Calidad empresarial con integración total en AWS
- Monitorización y registro avanzados
- Ideal para implementaciones de producción a gran escala
Resolución de problemas comunes
Incluso con las optimizaciones de Unsloth, puede encontrarse con algunos problemas. He aquí cómo resolver los más comunes:
Errores de memoria insuficiente CUDA
Este es el problema más común al ajustar modelos grandes:
# Solución 1: Reducir el tamaño del lote
training_config = SFTConfig(
per_device_train_batch_size = 1, # Tamaño mínimo del lote
gradient_accumulation_steps = 8, # Compensar con acumulación
)
# Solución 2: Reducir la longitud de la secuencia
max_seq_length = 512 # En lugar de 1024
# Solución 3: Usar una cuantización más agresiva
model = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
load_in_4bit = True,
use_double_quant = True, # Aún más ahorro de memoria
)
# Solución 4: Activar todas las optimizaciones de memoria
use_gradient_checkpointing = "unsloth"
use_flash_attention = TrueReducir la velocidad de entrenamiento
Si el entrenamiento está tardando demasiado:
# Usar el conjunto completo de optimizaciones de Unsloth
model = FastLanguageModel.get_peft_model(
model,
use_gradient_checkpointing = "unsloth", # Crítico
lora_dropout = 0, # 0 es más rápido que dropout
bias = "none", # "none" es más rápido que los sesgos de entrenamiento
use_rslora = False, # LoRA estándar es más rápido
)
# Comprueba que estás usando el dtype correcto
torch.set_float32_matmul_precision('medium') # O 'high'El modelo no está aprendiendo
Si su pérdida no está disminuyendo
- Compruebe el formato de los datos: Asegúrese de que sus datos coinciden exactamente con el formato GPT-OSS
- Verifique el enmascaramiento de respuestas: Confirme que sólo está entrenando las respuestas
- Ajuste la tasa de aprendizaje: Pruebe 5e-4 o 1e-4 en lugar de 2e-4
- Aumente la calidad de los datos: Elimine los ejemplos de baja calidad
- Añada más datos: Más de 500 ejemplos suelen funcionar mejor que 100
Resultados incoherentes
Si el modelo genera resultados incoherentes o de baja calidad:
# Utilice una temperatura más baja para obtener resultados más coherentes
resultados = model.generate(
temperatura = 0.3, # Menor = más consistente
top_p = 0.9
repetition_penalty = 1.1, # Reduce la repetición
)
# Ajuste fino para más pasos
max_steps = 200 # En lugar de 60
# Utilizar un filtrado de datos de mayor calidad
min_response_length = 50 # En lugar de 30Conclusión
Conclusión
El ajuste fino de GPT-OSS es más rápido y sencillo cuando se combina la velocidad de Unsloth con datos de entrenamiento estructurados y de alta calidad proporcionados por una de las principales empresas de datos de entrenamiento de IA. El uso de las soluciones de Bright Data para IA le garantiza el acceso a los datos fiables necesarios para un ajuste fino eficaz, de modo que pueda crear modelos de IA a medida para cualquier caso de uso.
Si desea profundizar en las estrategias de extracción de datos basadas en IA, consulte estos recursos adicionales:





