

La creación de modelos especializados que comprendan su dominio a menudo necesita algo más que ingeniería de consulta o generación aumentada por recuperación (RAG). Los modelos disponibles públicamente son potentes, pero carecen de los conocimientos más recientes o del gusto específico que exige su caso de uso. Dado que disponemos de datos web, que van desde artículos, documentaciones, listados de productos y transcripciones de vídeos, esta brecha puede salvarse mediante un ajuste fino.
En esta entrada de blog aprenderá
- Cómo recopilar y preparar datos web específicos de un dominio utilizando los scrapers y conjuntos de datos de Bright Data.
- Cómo ajustar un modelo GPT de código abierto con los datos recopilados.
- Cómo evaluar y desplegar su modelo perfeccionado para tareas del mundo real.
Entremos en materia
Qué es el ajuste fino
En palabras sencillas, el ajuste fino es el proceso de tomar un modelo que ya ha sido preentrenado en un gran conjunto de datos generales y adaptarlo para que funcione bien en un nuevo conjunto de datos o tarea, a menudo más específicos. Cuando se realiza un ajuste fino, lo que se hace es cambiar los pesos del modelo en lugar de construirlo desde cero. Cambiar las ponderaciones es lo que hace que se comporte de forma diferente o de la manera que usted desee.
Los datos de la web son útiles para el ajuste fino porque te ofrecen:
- Frescura: Se actualizan continuamente para captar las últimas tendencias, acontecimientos y tecnologías.
- Diversidad: Acceso a diferentes estilos de redacción, fuentes y pensamientos, lo que reduce el sesgo de los conjuntos de datos limitados.
El proceso de ajuste fino funciona como se muestra a continuación:
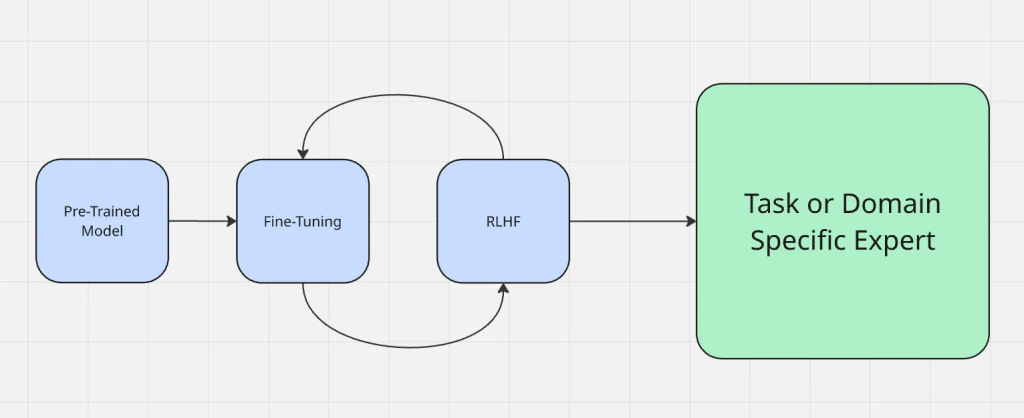
El ajuste fino es distinto de otros métodos de adaptación habituales, como la ingeniería de instrucciones y la generación aumentada por recuperación. La ingeniería de estímulos cambia la forma de formular preguntas a un modelo, pero no cambia el modelo en sí. La RAG añade una fuente de conocimiento externa en tiempo de ejecución, como dar contexto a algo nuevo. El ajuste fino, por otro lado, actualiza directamente los parámetros del modelo, lo que lo hace más fiable para producir resultados precisos del dominio sin contexto adicional cada vez.
A diferencia de la generación aumentada por recuperación (RAG), que enriquece un modelo con contexto externo en tiempo de ejecución, el ajuste fino adapta el propio modelo. Si desea profundizar en las ventajas y desventajas, consulte RAG vs. Fine-Tuning.
¿Por qué utilizar datos web para el ajuste fino?
Los datos web se presentan en formatos ricos y recientes (artículos, listados de productos, mensajes en foros, transcripciones de vídeos e incluso texto derivado de vídeos), lo que supone una ventaja que ni los conjuntos de datos estáticos ni los sintéticos pueden igualar. Esta variedad ayuda a un modelo a manejar diferentes tipos de entrada con mayor eficacia.
He aquí algunos ejemplos de diferentes contextos en los que brillan los datos web:
- Datos de redes sociales: Los tokens de las plataformas sociales ayudan a los modelos a comprender el lenguaje informal, la jerga y las tendencias en tiempo real, que son esenciales para aplicaciones como el análisis de sentimientos o los bots de chat.
- Conjuntos de datos estructurados: Los tokens de fuentes estructuradas, como catálogos de productos o informes financieros, permiten una comprensión precisa y específica del dominio, fundamental para los sistemas de recomendación o las previsiones financieras.
- Contexto de nicho: Las startups y las aplicaciones especializadas se benefician de los tokens procedentes de conjuntos de datos relevantes adaptados a sus casos de uso, como documentos legales para la tecnología legal o revistas médicas para la IA médica.
Los datos web introducen una variedad y un contexto naturales, mejorando el realismo y la solidez de un modelo ajustado.
Estrategias de recopilación de datos
Los scrapers a gran escala y los proveedores de conjuntos de datos como Bright Data permiten recopilar volúmenes masivos de contenido web de forma rápida y fiable. Esto permite crear conjuntos de datos específicos de un dominio sin tener que dedicar meses a la recopilación manual.
Bright Data ha creado la infraestructura de recopilación de datos web más diversificada y fiable del sector, compuesta por varias fuentes y puntos de acceso a la red. Los datos web no se limitan a texto sin formato. Bright Data puede capturar entradas multimodales como metadatos, atributos de productos y transcripciones de vídeo, que ayudan a un modelo a aprender un contexto más rico.
Debe evitarse la recopilación de datos mediante scrapes sin procesar, ya que casi siempre contienen ruido, contenido irrelevante o artefactos de formato. El filtrado, la eliminación de duplicados y la limpieza estructurada son pasos importantes para garantizar que el conjunto de datos de entrenamiento mejore el rendimiento en lugar de introducir confusión.
Preparación de los datos web para su ajuste
- Conversión de datos sin procesar en pares estructurados de entrada/salida. Los datos sin procesar rara vez están listos para el entrenamiento tal cual. El primer paso consiste en convertir los datos en pares estructurados de entrada/salida. Por ejemplo, una documentación sobre el ajuste fino puede formatearse en una pregunta del tipo “¿Qué es el ajuste fino?” con la respuesta original como salida de destino. Este tipo de estructura garantiza que el modelo aprenda a partir de ejemplos bien definidos en lugar de texto desorganizado.
- Manejo de diversos formatos: JSON, CSV, transcripciones, páginas web. Los datos web suelen presentarse en distintos formatos, como JSON de API, exportaciones CSV, HTML sin procesar o transcripciones de vídeos. La estandarización de los datos web en un formato coherente como JSONL simplifica su gestión y su introducción en los canales de formación.
- Empaquetar conjuntos de datos para un entrenamiento eficiente. Para mejorar los resultados y el proceso de entrenamiento, los conjuntos de datos a menudo se “ordenan”, lo que significa que varios ejemplos más cortos se combinan en una única secuencia para reducir los tokens desperdiciados y optimizar el uso de la memoria de la GPU durante el ajuste fino.
- Equilibrio entre datos web específicos de un dominio y datos web generales. Encontrar un equilibrio es importante. Un exceso de datos de un único dominio puede hacer que el modelo sea estrecho y poco profundo, mientras que un exceso de datos generales puede diluir el conocimiento especializado al que se dirige. Los mejores resultados suelen obtenerse combinando una base sólida de datos web generales con ejemplos específicos del dominio.
Elegir un modelo base
La elección del modelo de base adecuado influye directamente en el rendimiento del sistema. No existe una solución única, sobre todo teniendo en cuenta la variedad de ofertas dentro de cada familia de modelos. En función del tipo de datos, los resultados deseados y el presupuesto, puede que un modelo se adapte mejor a sus necesidades que otro.
Para elegir el modelo adecuado con el que empezar, siga esta lista de comprobación:
- ¿Qué modalidad o modalidades necesitará su modelo?
- ¿Qué tamaño tienen los datos de entrada y salida?
- ¿Qué complejidad tienen las tareas que intenta realizar?
- ¿Qué importancia tiene el rendimiento frente al presupuesto?
- ¿Qué importancia tiene la seguridad del asistente de IA para su caso de uso?
- ¿Tiene su empresa un acuerdo existente con Azure o GCP?
Por ejemplo, si se trata de vídeos o textos extremadamente largos (de horas de duración o cientos de miles de palabras), Gemini 1.5 pro podría ser una opción óptima, ya que proporciona una ventana de contexto de hasta 1 millón de tokens.
Varios modelos de código abierto son buenos candidatos para el ajuste fino de datos web, como los modelos Gemma 3, Llama 3.1, Mistral 7B o Falcon. Las versiones más pequeñas son prácticas para la mayoría de los proyectos de ajuste fino, mientras que las más grandes destacan cuando su dominio necesita una gran cobertura y precisión. También puede consultar esta guía sobre la adaptación de Gemma 3 para el ajuste fino.
Ajuste con Bright Data
Para demostrar cómo los datos web contribuyen al ajuste fino, veamos un ejemplo utilizando Bright Data como fuente. En este ejemplo, utilizaremos la API Scraper de Bright Data para recopilar información de productos de Amazon y ajustar un modelo Llama 4 en Hugging Face.
Paso 1: Recopilación del conjunto de datos
Utilizando la API web scraper de Bright Data, puede recuperar datos estructurados de productos (título, productos, descripciones, reseñas, etc.) con sólo unas pocas líneas de Python.
El objetivo en este paso es crear un pequeño proyecto que:
- Active un entorno virtual Python
- Llame a la API Web Scraper de Bright Data
- Guarde los resultados en amazon-data.json
Requisitos previos
- Python 3.10+
- Un token de API de Bright Data
- Un ID de recopilador de Bright Data (del panel de Bright Data) /cp/scrapers
- Una OPENAI_API_KEY ya que estaremos ajustando un modelo GPT-4.
Cree una carpeta de proyecto
mkdir web-scraper u0026u0026 cd web-scrapper
Crear y activar un entorno virtual
Active un entorno virtual, y debería ver (venv) al principio de su intérprete de comandos.
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
Instalar dependencias
Esta es una librería para hacer peticiones web HTTP
pip install requests
Una vez completado esto, ya está listo para obtener los datos de interés utilizando las APIs de raspado de Bright Data.
Definir la lógica de raspado
El siguiente fragmento activará su recolector de Bright Data (p. ej., productos de Amazon), sondeará hasta que finalice el scrape y guardará los resultados en un archivo JSON local.
Reemplace su clave api en la cadena de clave api aquí
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
Ejecute el código
python3 web_scraper.py
Debería ver
- Un ID de instantánea impreso
- Scrape completado.
- Guardado en amazon-data.json (…items)
El proceso crea automáticamente los datos que contienen nuestros datos raspados. Esta es la estructura esperada de los datos:
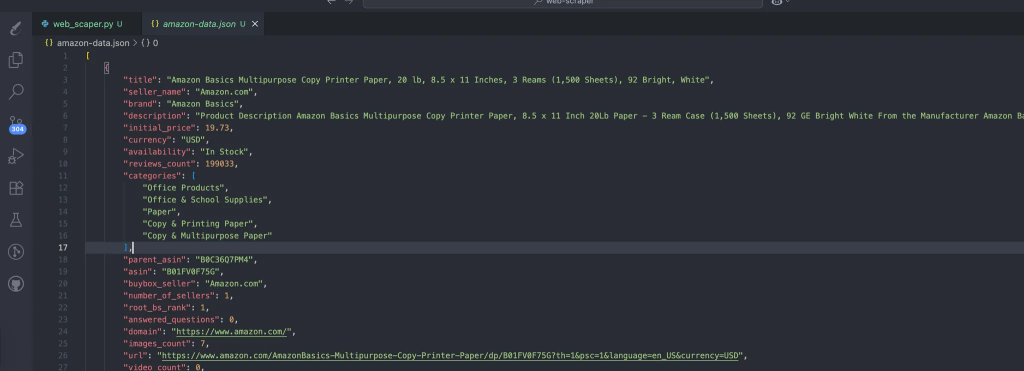
Paso #2: Convertir JSON en pares de entrenamiento
Cree prepare_pair.py en la raíz del proyecto, con el siguiente fragmento para estructurar nuestros datos en formato JSONL y dejarlos listos para el paso de ajuste.
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
Ejecuta el siguiente comando:
python3 prepare_pairs.py
Y debería dar la siguiente salida en el archivo:
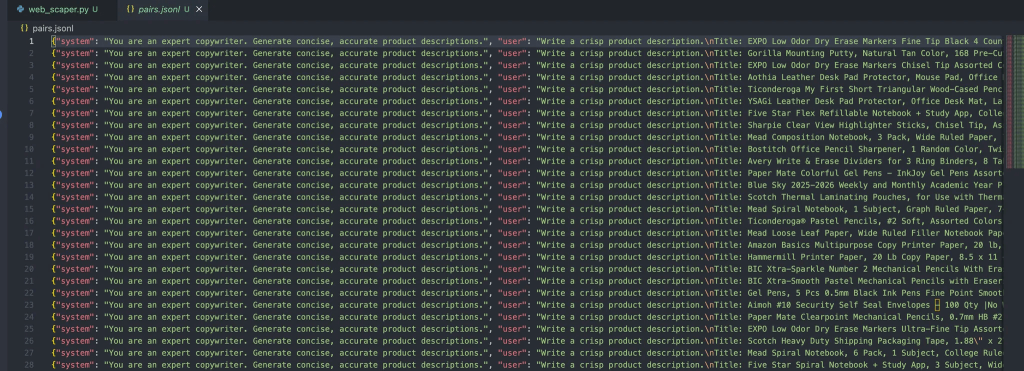
Cada mensaje en este objeto contiene tres roles:
- Sistema: Proporciona el contexto inicial para el asistente.
- Usuario: La entrada del usuario.
- Asistente: La respuesta del asistente.
Paso 3: Cargar el archivo para su ajuste fino
Una vez que el archivo está listo, los siguientes pasos son simplemente conectarlo a las tuberías de ajuste fino de OpenAI con los siguientes pasos:
Instalar las dependencias OpenAI
pip install openai
Crear un upload.py para cargar el conjunto de datos
Este script leerá del archivo pairs.jsonl que ya tenemos
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
Ejecuta el siguiente comando:
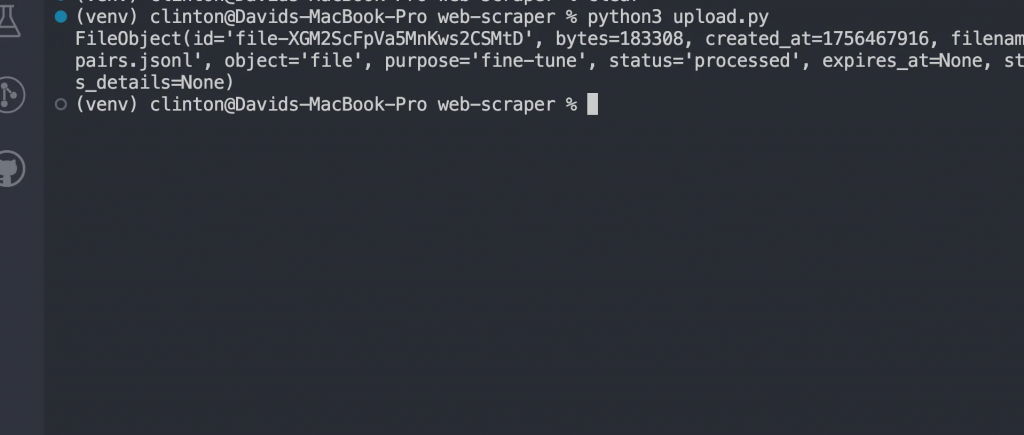
python3 upload.py
Ahora deberías ver una respuesta como:
Ajuste fino del modelo
Crea un archivo fine-tune.py y reemplaza el FILE_ID con el id del archivo subido que obtuvimos de nuestra respuesta anterior, y ejecuta el archivo:
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
Esto debería darnos esta respuesta:
Monitorizar hasta que finalice el entrenamiento
Una vez iniciado el trabajo de ajuste, el modelo necesita tiempo para entrenarse en el conjunto de datos. Dependiendo del tamaño del conjunto de datos, esto puede llevar desde unos minutos hasta horas.
Pero no querrás adivinar cuándo estará listo; en su lugar, escribe y ejecuta este código en monitor.py
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
A continuación, ejecute el archivo con python3 [manage.py](http://manage.py) en el terminal, y debería mostrar detalles como:
- Si el entrenamiento tuvo éxito o fracasó.
- Cuántos tokens fueron entrenados
- El ID del nuevo modelo afinado.
En esta sección, sólo debe avanzar cuando el campo de estado diga
u0022succeededu0022
Chatee con su modelo perfeccionado
Una vez finalizado el trabajo, ya tienes tu propio modelo GPT personalizado. Para usarlo, abra chat.py, actualice el MODEL_ID con el que le devolvió su trabajo de ajuste fino y ejecute el archivo:
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
Este paso prueba que el ajuste fino funcionó. En lugar de utilizar el modelo base de propósito general, ahora estás hablando con un modelo entrenado específicamente en tus datos.
Aquí es donde verá que sus resultados cobran vida.
Puedes esperar resultados como:
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
Conclusión
Cuando se trabaja con el ajuste fino a escala web, es importante ser realista sobre las limitaciones y los flujos de trabajo:
- Recursos necesarios: El entrenamiento en conjuntos de datos grandes y diversos requiere computación y almacenamiento. Si está experimentando, empiece con porciones más pequeñas de sus datos antes de escalar.
- Itere gradualmente: En lugar de volcar millones de registros en su primer intento, perfeccione con un conjunto de datos más pequeño. Utilice los resultados para detectar lagunas o errores en su proceso de preprocesamiento.
- Flujos de trabajo de despliegue: Trate los modelos perfeccionados como cualquier otro artefacto de software. Actualícelos, intégrelos en CI/CD cuando sea posible y mantenga opciones de reversión en caso de que un nuevo modelo no funcione correctamente.
Por suerte, Bright Data le ofrece numerosos servicios preparados para la IA para la adquisición o creación de conjuntos de datos:
- Scraping Browser: Un navegador compatible con Playwright, Selenium-, Puppeter con capacidades de desbloqueo integradas.
- API deraspado web: API preconfiguradas para extraer datos estructurados de más de 100 dominios principales.
- Desbloqueador web: Una API todo en uno que gestiona el desbloqueo de sitios con protecciones anti-bot.
- API SERP: Una API especializada que desbloquea los resultados de los motores de búsqueda y extrae datos SERP completos.
- Datos para modelos de cimentación: Acceda a conjuntos de datos compatibles a escala web para potenciar el preentrenamiento, la evaluación y el ajuste.
- Proveedores de datos: Conéctese con proveedores de confianza para obtener conjuntos de datos de alta calidad preparados para la IA a escala.
- Paquetes de datos: Obtenga conjuntos de datos curados y listos para usar: estructurados, enriquecidos y anotados.
El perfeccionamiento de grandes modelos lingüísticos con datos web permite una especialización de dominio muy potente. La web proporciona contenidos frescos, diversos y multimodales, desde artículos y reseñas hasta transcripciones y metadatos estructurados, que los conjuntos de datos curados por sí solos no pueden igualar.
Cree una cuenta de Bright Data de forma gratuita para probar nuestra infraestructura de datos preparada para la IA.




