

En esta guía sobre el ajuste de Llama 4 con datos web, aprenderás:
- Qué es el ajuste
- Cómo recuperar los conjuntos de datos listos para el ajuste fino utilizando algunas API de scraping
- Cómo configurar la infraestructura en la nube para el proceso de ajuste
- Cómo ajustar Llama 4 con un tutorial paso a paso
¡Empecemos!
¿Qué es el ajuste fino?
El ajuste fino, también conocido como ajuste fino supervisado (SFT), es un proceso que se utiliza para mejorar conocimientos o habilidades específicos en un LLM preentrenado. En el contexto de los LLM, el preentrenamiento se refiere al entrenamiento de un modelo de IA desde cero.
El SFT se utiliza porque un modelo imita sus datos de entrenamiento. Sin embargo, a día de hoy, los LLM son principalmente modelos generalistas. Esto significa que, si se quiere que un modelo aprenda conocimientos específicos, hay que ajustarlo.
Si desea obtener más información sobre el SFT, lea nuestra guía sobre el ajuste supervisado en los LLM.
Rastrear los datos para ajustar LLama 4
Para ajustar un LLM, primero necesita un conjunto de datos de ajuste. En esta sección se explica cómo recuperar datos de un sitio web utilizando las APIde Bright Data Web Scraper, puntos finales dedicados para más de 100 dominios que extraen datos recientes y los recuperan en el formato deseado.
La página web de destino será la página de productos de oficina más vendidos de Amazon:
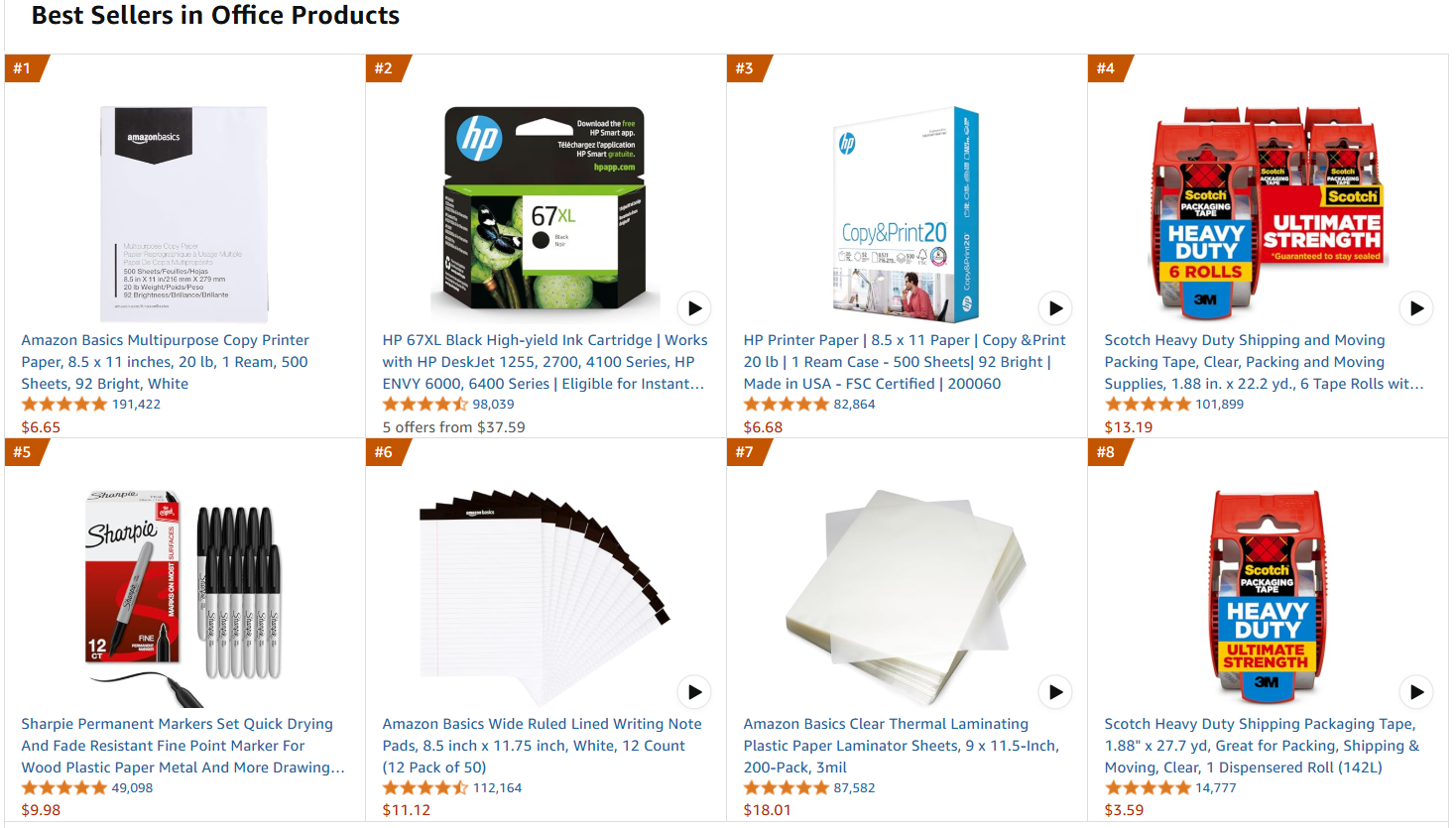
Siga los pasos que se indican a continuación para recuperar los datos de ajuste.
Requisitos
Para utilizar el código para recuperar los datos de Amazon, necesita:
- Python 3.10+ instalado en su equipo.
- Una clave API válida de Bright Data Scraper.
Siga la documentación de Bright Data para recuperar su clave API.
Estructura del proyecto y dependencias
Supongamos que la carpeta principal de su proyecto se llama amazon_scraper/. Al final de este paso, la carpeta tendrá la siguiente estructura:
amazon_scraper/
├── scraper.py
└── venv/Donde:
scraper.pyes el archivo Python que contiene la lógica de codificación.venv/contiene el entorno virtual.
Puedes crear el directorio del entorno virtual venv/ de la siguiente manera:
python -m venv venvPara activarlo, en Windows, ejecute:
venvScriptsactivateDe forma equivalente, en macOS y Linux, ejecute:
source venv/bin/activateEn el entorno virtual activado, instale las dependencias con:
pip install requestsDonde requests es una biblioteca para realizar solicitudes web HTTP.
¡Genial! Ahora ya está listo para obtener los datos que le interesan utilizando las API Scraper de Bright Data.
Paso n.º 1: definir la lógica de scraping
El siguiente fragmento de código define toda la lógica de scraping:
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Punto final para activar la tarea del Scraper de la API
url = "https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
# Convertir los datos de entrada al formato deseado para llamar a la API
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"¡Solicitud realizada correctamente! Respuesta: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"¡Solicitud fallida! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Sondeando instantánea para ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("La instantánea está lista. Descargando...")
snapshot_data = response.json()
# Escribir la instantánea en un archivo json de salida
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantánea guardada en {output_file}")
return
elif response.status_code == 202:
print(F"La instantánea aún no está lista. Reintentando en {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
print(f"¡Solicitud fallida! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<TU clave API>" # Reemplázala por tu clave API de Bright Data's Web Scraper o léela desde los entornos
# URL de los productos más vendidos para recuperar datos
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")Este código:
- Crea la función
trigger_amazon_products_scraping()que inicia la tarea de Scraping web mediante:- Definir el punto final de la API del Scraper que se va a activar.
- Configurando los parámetros para la actividad de scraping.
- Formatear las
URLde entrada en una estructura JSON que la API espera. - Enviar una solicitud
POSTa la API de Bright Data Scraper con el punto final, los encabezados, los parámetros y los datos especificados. - Gestionar el estado de la respuesta.
- Crea una función
poll_and_retrieve_snapshot()que comprueba el estado de la tarea de scraping (identificada porsnapshot_id) y recupera los datos una vez que están listos.
Tenga en cuenta que la API de rastreo se llamó utilizando una sola URL. Por lo tanto, el código anterior recupera los datos solo de una página de Amazon de destino. Esto es suficiente para el alcance de este tutorial, pero puede añadir tantas URL de Amazon como desee a la lista.
Tenga en cuenta que cuantas más URL añada, más aumentará el tamaño del conjunto de datos. Un conjunto de datos más grande, si se cura bien, significa un mejor ajuste. Por otro lado, cuanto más grande sea el conjunto de datos, más tiempo de cálculo se necesitará.
¡Perfecto! Su lógica de scraping está bien definida y ya está listo para ejecutar el script.
Paso n.º 2: Ejecutar el script
Para extraer la página web de destino, ejecute el script con:
python Scraper.pyObtendrá el siguiente resultado:
¡Solicitud exitosa! Respuesta: s_m9in0ojm4tu1v8h78
Captura de pantalla de sondeo para ID: s_m9in0ojm4tu1v8h78...
La instantánea aún no está lista. Volviendo a intentarlo en 20 segundos...
# ...
La instantánea aún no está lista. Volviendo a intentarlo en 20 segundos...
La instantánea está lista. Descargando...
Instantánea guardada en amazon-data.jsonAl final del proceso, la carpeta del proyecto contendrá:
amazon_scraper/
├── scraper.py
├── amazon-data.json # <-- Tenga en cuenta el conjunto de datos de ajuste fino.
└── venv/El proceso ha creado automáticamente el archivo amazon-data.json que contiene los datos extraídos. A continuación se muestra la estructura prevista del archivo JSON:
[
{
"title": "Papel para impresora y copiadora multiuso Amazon Basics, 8,5 x 11 pulgadas, 20 lb, 1 resma, 500 hojas, 92 brillante, blanco",
"seller_name": "Amazon.com",
"brand": "Amazon Basics",
"description": "Descripción del producto Papel para impresora y copiadora multiuso Amazon Basics, 8,5 x 11 pulgadas, 20 lb - 1 resma (500 hojas), 92 GE blanco brillante Del fabricante AmazonBasics",
"initial_price": 6,65,
"currency": "USD",
"availability": «En stock»,
«reviews_count»: 190989,
«categories»: [
«Productos de oficina»,
«Material de oficina y escolar»,
«Papel»,
«Papel para copias e impresiones»,
«Papel para copias y multiuso»
],
...
// omitido por brevedad...
}¡Muy bien! Ha extraído correctamente los datos de Amazon y los ha guardado en un archivo JSON. Este archivo JSON es el conjunto de datos de ajuste fino que utilizará más adelante en el proceso de ajuste fino.
Configuración de Hugging Face para utilizar Llama 4
El modelo que utilizará es Llama-4-Scout-17B-16E-Instruct de Hugging Face.
Si nunca ha utilizado Hugging Face, cuando haga clic en el enlace por primera vez se le pedirá que cree una cuenta:
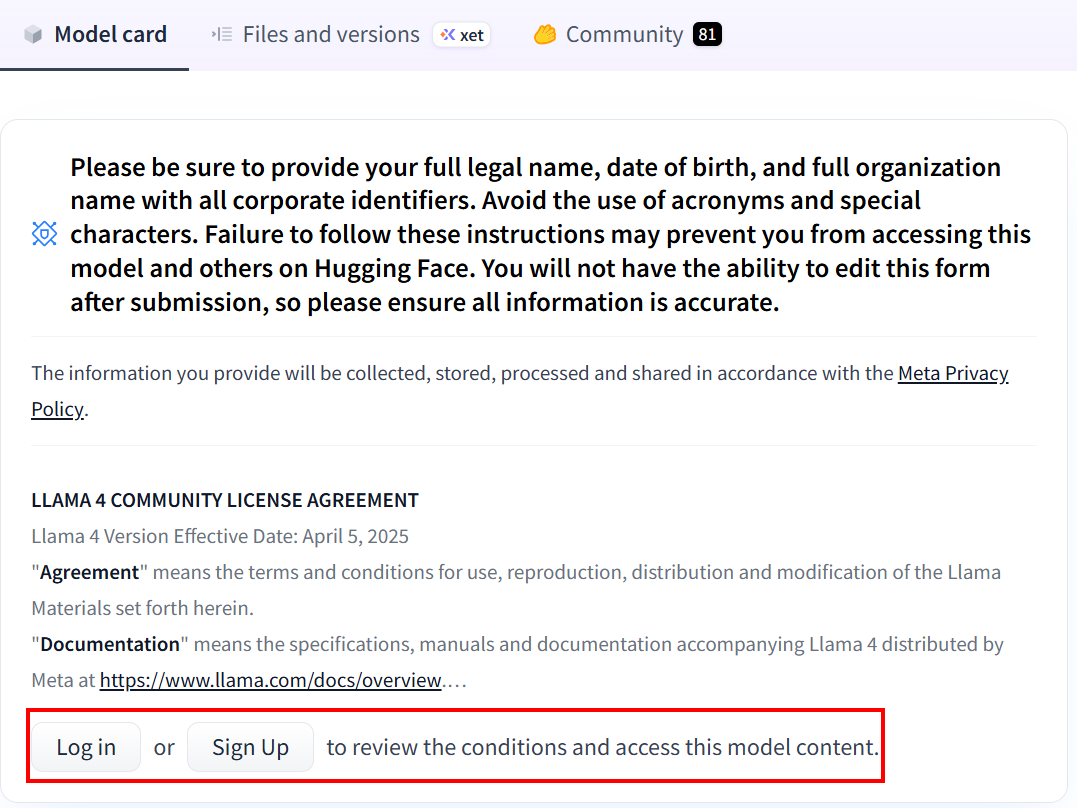
Después de crear la cuenta, si nunca ha utilizado ningún modelo Llama 4, deberá rellenar el formulario de acuerdo. Haga clic en «Expand to review and access» (Expandir para revisar y acceder) para leer y rellenar el formulario:
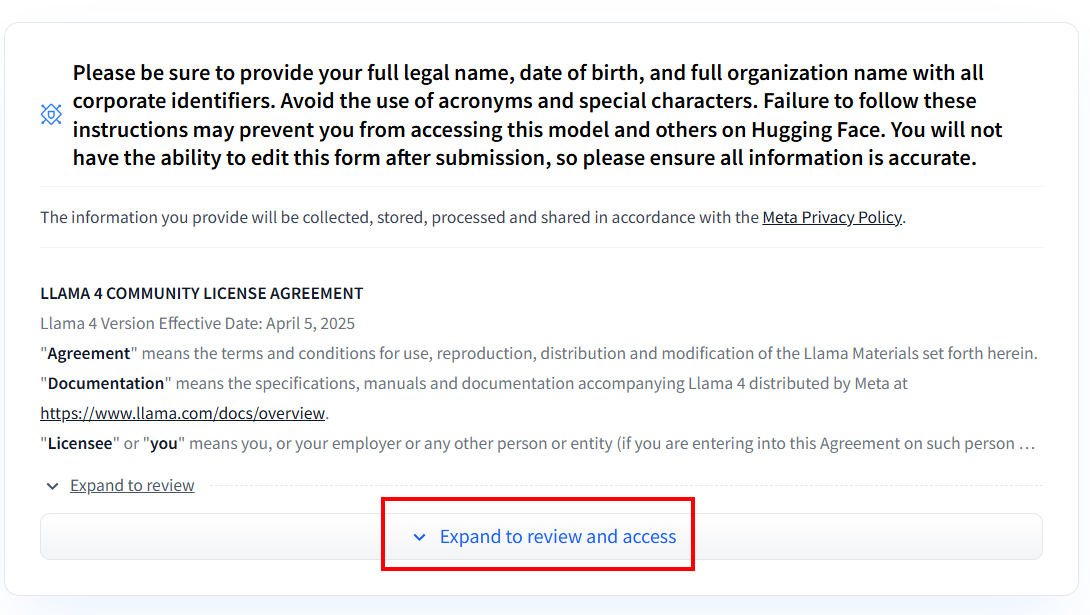
Después de rellenar el formulario, se revisará tu solicitud:
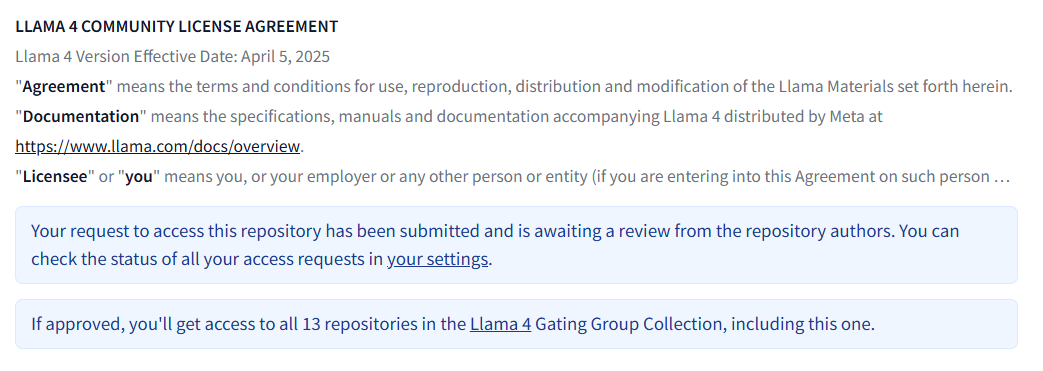
Comprueba el estado de tu solicitud en la sección«Gated Repositories»:
Una vez que tu solicitud sea aceptada, podrás crear un nuevo token. Ve a«Access Tokens» y crea un token con permisos de escritura. A continuación, cópialo y guárdalo en un lugar seguro para utilizarlo más adelante:
¡Hurra! Ha completado todos los pasos necesarios para utilizar un modelo Llama 4 con Hugging Face.
Configuración de la infraestructura en la nube para ajustar Llama 4
Los modelos Llama 4 son muy grandes, y su nombre te ayuda a comprender lo grandes que son. Por ejemplo, Llama-4-Scout-17B-16E-Instruct significa que tiene 17 000 millones de parámetros con 128 expertos.
El proceso de ajuste fino requiere que entrene el modelo utilizando el conjunto de datos de ajuste fino que ha recuperado anteriormente. Dado que el modelo tiene 17 000 millones de parámetros, necesita mucho hardware para hacerlo. En concreto, necesita más de una GPU. Por este motivo, utilizará un servicio en la nube para llevar a cabo el proceso de ajuste fino.
Para este tutorial, utilizará RunPod como servicio en la nube. Vaya a«RunPod»y cree una cuenta. A continuación, vaya al menú «Facturación» y añada 25 $ utilizando la tarjeta de crédito:
Nota: Pagará inmediatamente 25 $ y RunPod añadirá el equivalente a 25 $ en créditos a su cuenta. Consumirá créditos por hora, dependiendo de cuántas horas esté activo su pod cuando se implemente. Por lo tanto, impleméntelo solo cuando esté seguro de que puede utilizarlo. De lo contrario, consumirá créditos sin utilizarlos realmente. El consumo real por hora depende del tipo y número de GPU que elija en los siguientes pasos.
Vaya al menú «Pods» para comenzar a configurar su pod. El pod funciona como un servidor virtual que le proporciona las CPU, GPU, memoria y almacenamiento necesarios para sus tareas. Haga clic en el botón «Implementar»:
Puede elegir entre diferentes configuraciones:
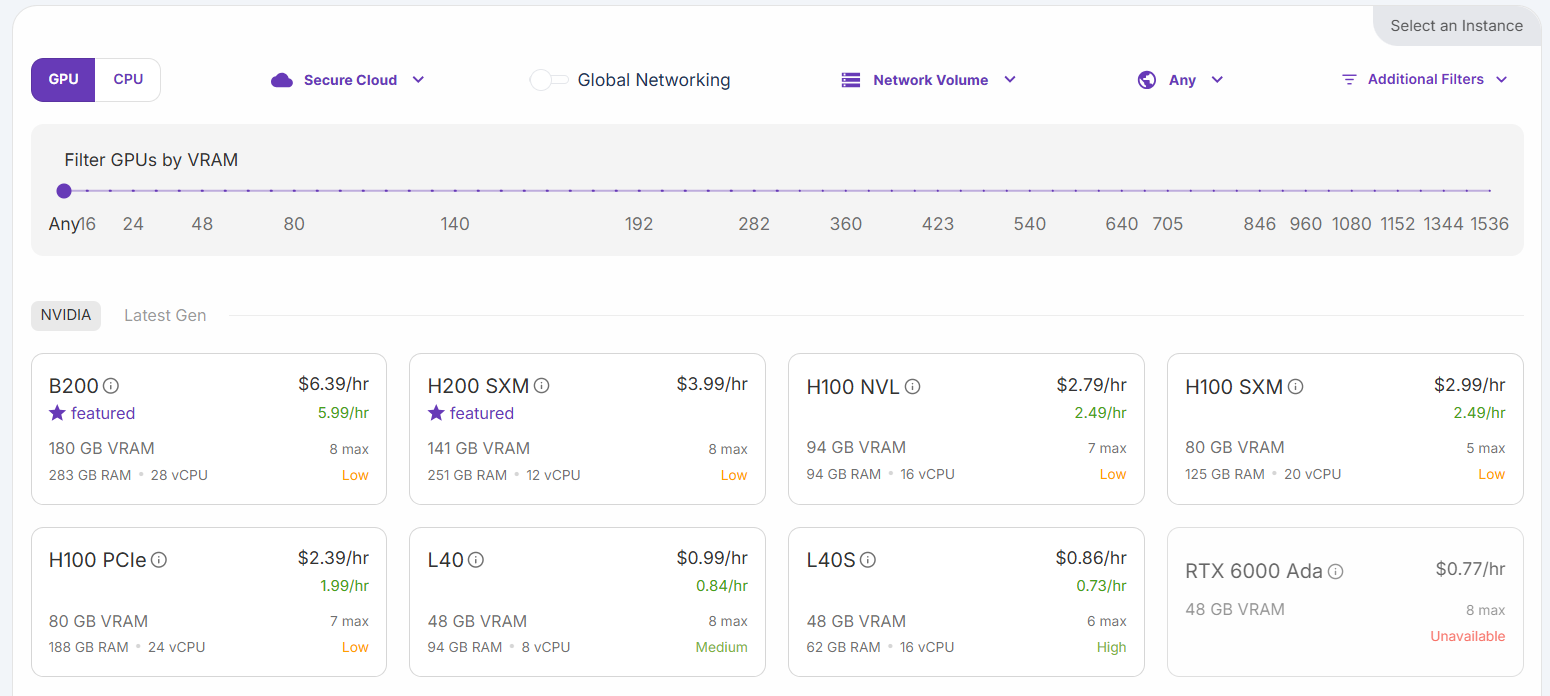
Seleccione la opción «H200 SXM GPU». Asigne un nombre al pod y seleccione el número de GPU. Para este tutorial, bastará con 3 GPU:
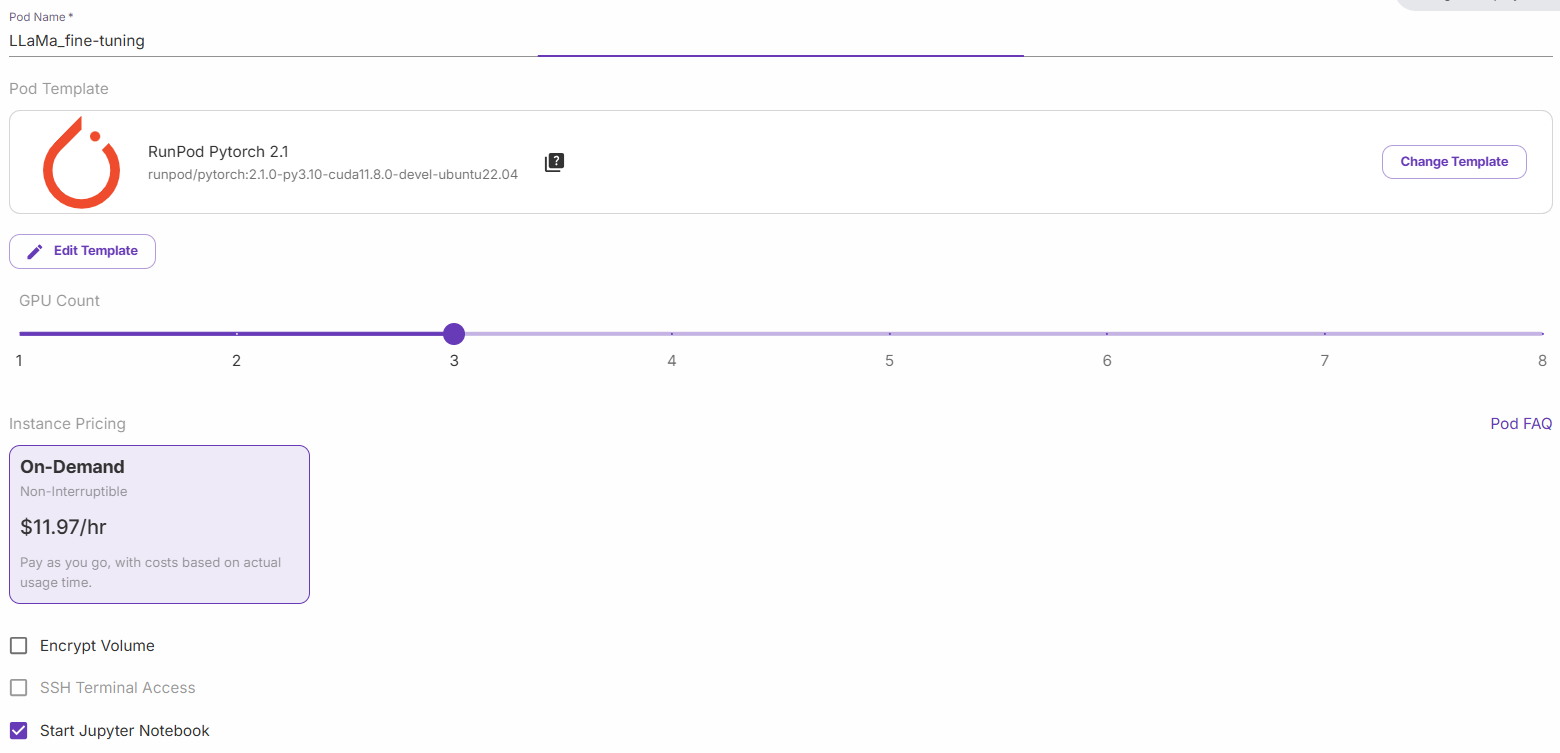
Seleccione «Iniciar un cuaderno Jupyter» y haga clic en «Implementar bajo demanda». Ahora, vaya a la sección «Pods» y edite su pod:
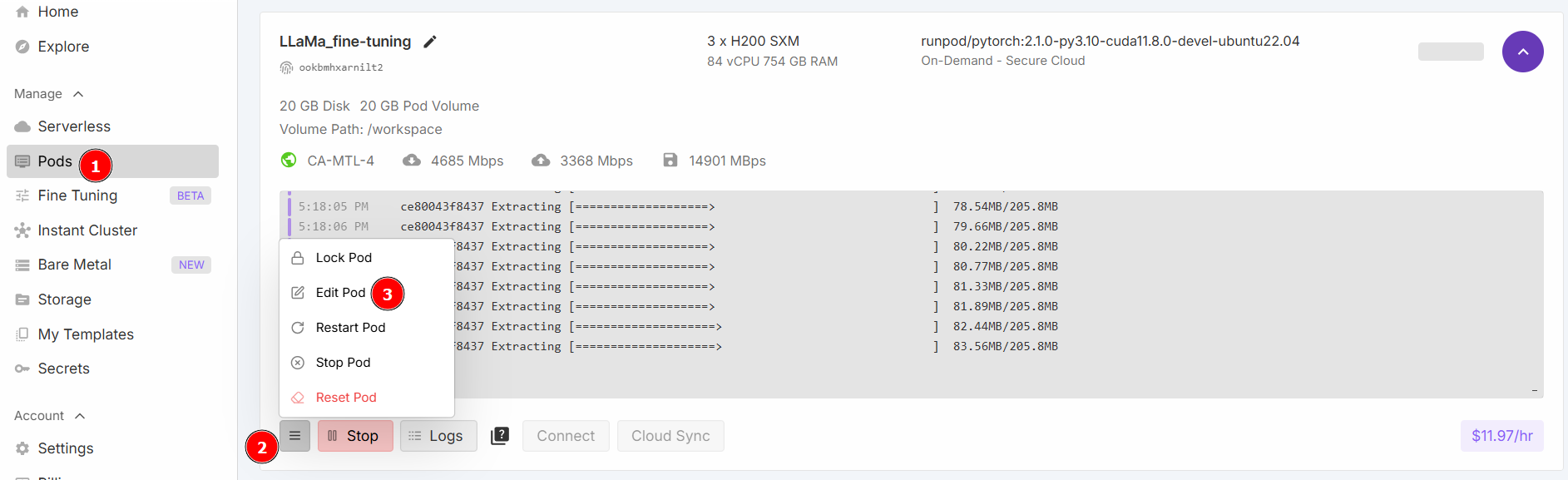
Cambie los valores de «Disco contenido» y «Disco de volumen» como se indica a continuación y, a continuación, guarde los cambios:
Cuando haya completado la configuración, haga clic en el botón «Conectar»:
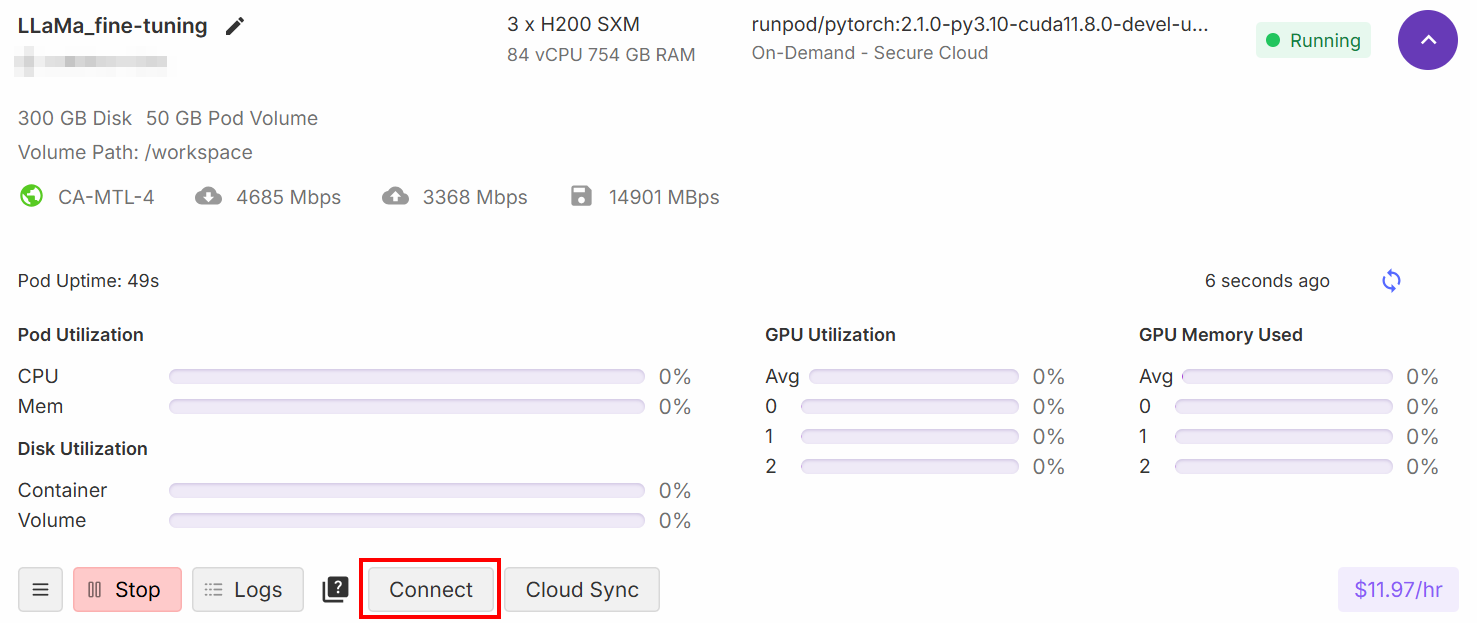
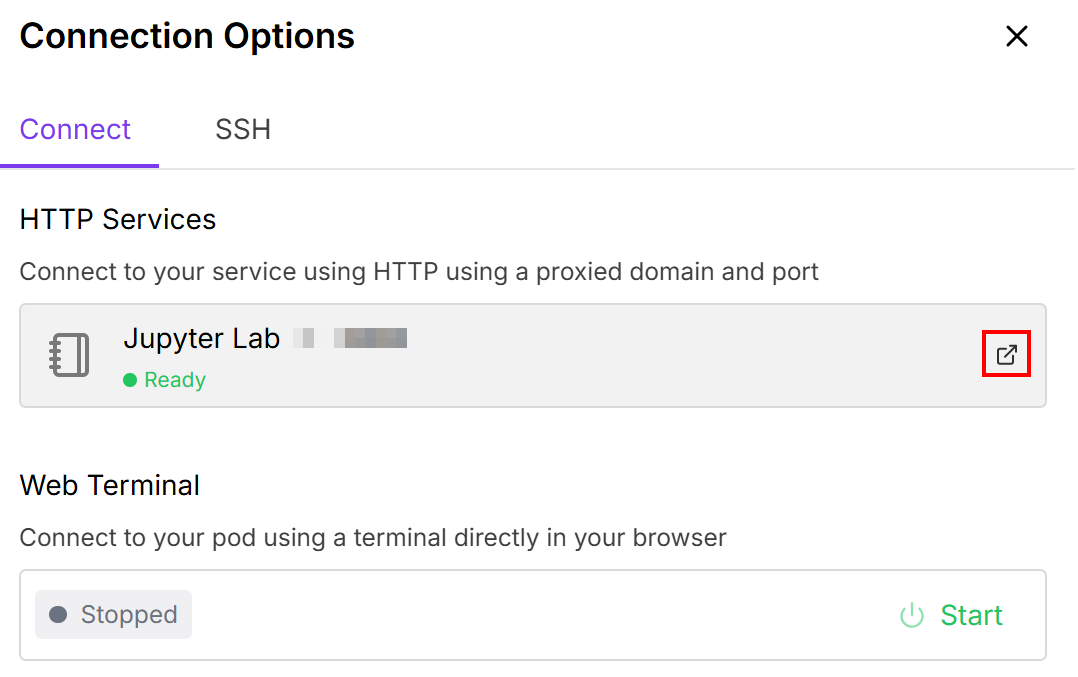
Esto le permite conectar el pod a un cuaderno de Jupiter Lab:
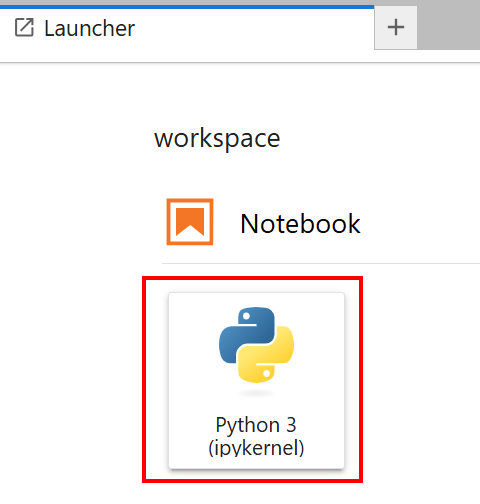
Seleccione el cuaderno con la tarjeta «Python 3 (ipykernel)»:
¡Muy bien! Ahora ya tiene la infraestructura adecuada para entrenar el modelo Llama 4.
Ajuste fino de Llama 4 con los datos recopilados
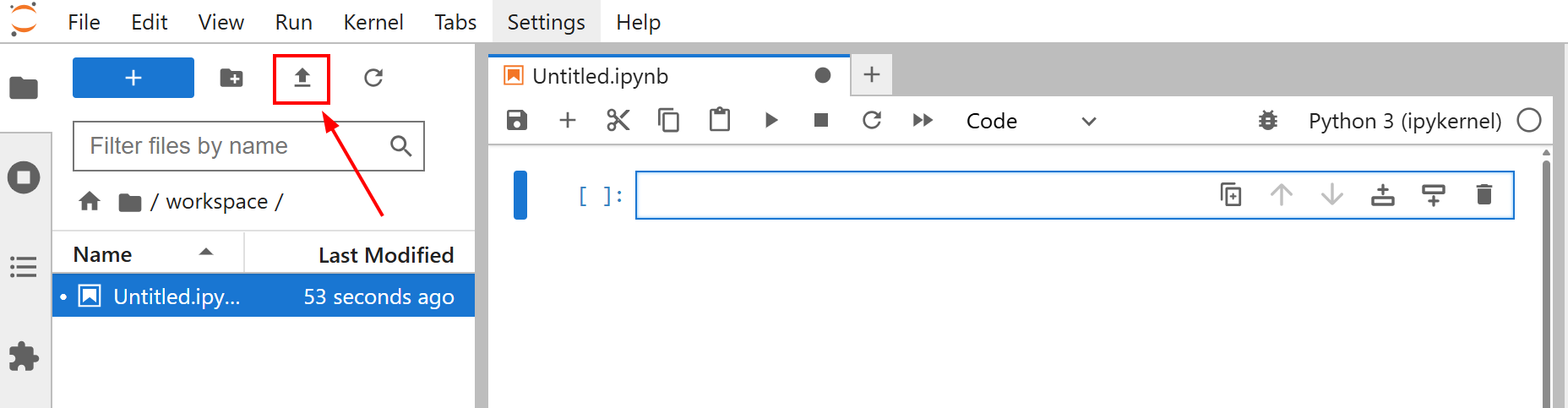
Antes de comenzar a ajustar su modelo, cargue el archivo amazon-data.json en su cuaderno Jupyter Lab. Para ello, haga clic en el botón «Cargar archivos»:
El objetivo del ajuste para este tutorial es entrenar Llama 4 utilizando el conjunto de datos amazon-data.json. De esta manera, le enseñas a Llama 4 cómo crear descripciones para objetos de oficina dadas algunas características como el nombre del objeto y algunas características.
Ahora ya está listo para empezar a entrenar el modelo. Siga los pasos que se indican a continuación para ajustar Llama 4 con datos web nuevos.
Paso n.º 1: Instalar las bibliotecas
En la primera celda de su cuaderno, instale las bibliotecas necesarias:
%%capture
!pip install transformers==4.51.0
%pip install -U Conjuntos de datos
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Estas bibliotecas son:
transformers: proporciona miles de modelos preentrenados.Conjuntos de datos: Ofrece acceso a una amplia colección de conjuntos de datos y herramientas eficientes de procesamiento de datos.accelerate: simplifica la ejecución de scripts de entrenamiento de PyTorch en diversas configuraciones distribuidas con cambios mínimos en el código.peft: permite ajustar modelos preentrenados de gran tamaño de forma más eficiente, actualizando solo un pequeño subconjunto de parámetros.trl: Diseñada para entrenar modelos de lenguaje transformador utilizando técnicas de aprendizaje por refuerzo.scipy: Una biblioteca para la computación científica y técnica en Python.huggingface_hub: proporciona una interfaz Python para interactuar con Hugging Face Hub. Esto le permite descargar y cargar modelos, Conjuntos de datos y espacios.bitsandbytes: Ofrece optimizadores de 8 bits y funciones de cuantificación fáciles de usar, lo que reduce el consumo de memoria para el entrenamiento y la inferencia de grandes modelos de aprendizaje profundo.
¡Perfecto! Ha instalado las bibliotecas necesarias para el proceso de ajuste fino.
Paso n.º 2: Conéctese a Hugging Face
En la segunda celda de su cuaderno, escriba:
from huggingface_hub import notebook_login, login
# Inicio de sesión interactivo
notebook_login()
print("Celda de inicio de sesión ejecutada. Si tiene éxito, puede continuar.")Cuando lo ejecute, se mostrará lo siguiente:
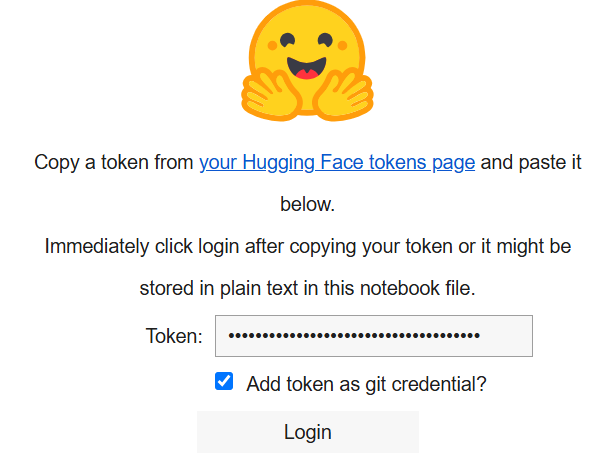
En el cuadro «Token», pegue el token que ha creado en su cuenta de Hugging Face.
¡Genial! Ahora puedes recuperar el modelo Llama 4 de Hugging Face.
Paso n.º 3: Cargar el modelo Llama 4
En la tercera celda de su cuaderno, escriba el siguiente código:
import os
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, Llama4ForConditionalGeneration, BitsAndBytesConfig
from trl import SFTTrainer
# Cargar modelo
base_model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
# Configuración para la cuantificación de BitsAndBytes
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
# Cargar el modelo Llama4 con las configuraciones especificadas
model = Llama4ForConditionalGeneration.from_pre-trained(
base_model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
# Desactivar el almacenamiento en caché para el modelo
model.config.use_cache = False
# Establecer el paralelismo del tensor de preentrenamiento en 1
model.config.pre-training_tp = 1
# Ruta al archivo de datos JSON de ajuste fino.
fine_tuning_data_file_path = "amazon-data.json"
# Ruta a los resultados
output_model_dir = "results_llama_office_items_finetuned/"
final_model_adapter_path = os.path.join(output_model_dir, "final_adapter")
max_seq_length_for_tokenization = 1024
# Crear directorio de salida
os.makedirs(output_model_dir)El fragmento anterior:
- Define el nombre del modelo que se va a cargar con
base_model_name. - Configura los pesos del modelo con
bnb_configutilizando el métodoBitsAndBytesConfig(). - Carga el modelo con el método
from_pre-trained()para entrenarlo. - Carga el conjunto de datos de ajuste fino con
fine_tuning_data_file_path. - Define la ruta del directorio de salida para los resultados y lo crea con el método
makedirs().
Cuando la celda termine de ejecutarse, debería ver un resultado como este:

¡Fantástico! Su modelo Llama 4 está configurado y cargado en el cuaderno.
Paso n.º 4: preparar el conjunto de datos de ajuste fino para el proceso de entrenamiento
Escriba el siguiente código en la cuarta celda de su cuaderno para preparar el conjunto de datos de ajuste fino para el proceso de entrenamiento:
from Conjuntos de datos import Dataset
# Abrir el conjunto de datos de ajuste fino
with open(fine_tuning_data_file_path, "r") as f:
data_list = json.load(f)
# Convertir la lista de elementos de datos en un objeto Hugging Face Dataset
raw_fine_tuning_dataset = Dataset.from_list(data_list)
print(f"Datos JSON convertidos a Conjunto de datos Hugging Face. Número de ejemplos: {len(raw_fine_tuning_dataset)}")
def format_fine_tuning_entry(data_item):
system_message = "Eres un redactor publicitario experto. Genera una descripción del producto concisa y atractiva basándote en los detalles proporcionados."
# AJUSTA LAS SIGUIENTES LÍNEAS a tu archivo de ajuste fino
item_title = data_item.get("title")
item_brand = data_item.get("brand")
item_category = data_item.get("categories")
item_name = data_item.get("name")
item_features_list = data_item.get("features")
item_features_str = ", ".join(item_features_list) if isinstance(item_features_list, list) else str(item_features_list)
target_description = data_item.get("description")
# Indicación de entrenamiento
user_prompt = (
f"Genera una descripción del producto para el siguiente artículo:n"
f"Título: {item_title}nMarca: {item_brand}nCategoría: {item_category}n"
f"Nombre: {item_name}nCaracterísticas: {item_features_str}nDescripción:"
)
# Formato de chat Llama
formatted_string = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt}<|eot_id|>"
f"<|start_header_id|>asistente<|end_header_id|>nn{target_description}<|eot_id|>"
)
return {"text": formatted_string}
# Aplicar la función de formato a cada entrada del conjunto de datos sin procesar para estructurarlo para el ajuste fino.
text_formatted_dataset = raw_fine_tuning_dataset.map(format_fine_tuning_entry)
# Configuración del tokenizador
tokenizer = AutoTokenizer.from_pre-trained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# Pretokenizar el conjunto de datos
def tokenize_function_for_sft(examples):
# Tokenizar el campo «texto» que contiene la cadena completa con formato de chat
tokenized_output = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=max_seq_length_for_tokenization,
)
return tokenized_output
# Aplicar la función de tokenización al conjunto de datos formateado
conjunto_de_datos_tokenizado = conjunto_de_datos_formateado_texto.map(
función_tokenizar_para_sft,
por_lotes=True,
eliminar_columnas=["texto"]
)Esta celda del cuaderno:
- Abre el conjunto de datos de ajuste fino y lo convierte en un objeto Hugging Face
Datasetutilizando el métodoDataset.from_list(). - Define una función
format_fine_tuning_entry(). Su propósito es tomar un único elemento de datos (los detalles de un producto) y transformarlo en un formato de texto estructurado adecuado para el ajuste de instrucciones de un modelo de chat como Llama. Tenga en cuenta que esto debe adaptarse a la estructura de su conjunto de datos de ajuste. - Tokeniza los conjuntos de datos y aplica la tokenización con el método
map(). Esto se hace porque los modelos de lenguaje no entienden el texto sin procesar. Funcionan con representaciones numéricas llamadas tokens.
Cuando la celda termina de ejecutarse, el resultado esperado es el siguiente:

Tenga en cuenta que el valor de «Num examples» depende de su conjunto de datos de ajuste.
¡Increíble! Su conjunto de datos de ajuste fino está listo para el proceso de ajuste fino.
Paso n.º 5: Configurar el entorno y los parámetros para el ajuste fino eficiente en parámetros (PEFT)
En una nueva celda de su cuaderno, escriba el siguiente código para configurar el entorno y los parámetros para PEFT:
from transformers import BitsAndBytesConfig
from peft import LoraConfig
# Configuración de QLoRA
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,)
# Configuración de LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)Este código:
- Define la configuración QLoRA para la cuantificación con el método
BitsAndBytesConfig()para especificar cómo se debe cuantificar un modelo de lenguaje preentrenado cuando se carga. La cuantificación es una técnica para reducir los costes computacionales y de memoria. - Define la configuración LoRA para configurar el modelo para un ajuste fino eficiente en términos de parámetros con el método LoraConfig().
¡Muy bien! El entorno está listo para un ajuste eficiente.
Paso n.º 6: Inicializar el proceso de entrenamiento
En una nueva celda, escriba el siguiente código para inicializar el proceso de entrenamiento:
from peft import get_peft_model, prepare_model_for_kbit_training
from transformers import TrainingArguments
# Preparar el modelo para el entrenamiento k-bit.
model = prepare_model_for_kbit_training(
model,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# Aplicar la configuración PEFT (LoRA) al modelo.
model = get_peft_model(model, lora_config)
# Desactivar el almacenamiento en caché en la configuración del modelo.
model.config.use_cache = False
# Imprimir el número de parámetros entrenables en el modelo.
model.print_trainable_parameters()
# Definir argumentos de entrenamiento.
training_args = TrainingArguments(
output_dir=output_model_dir,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=25,
save_steps=50,
fp16=True,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
max_grad_norm=0.3,
save_total_limit=2,)
# Inicializar SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
peft_config=lora_config,
)El código de esta celda:
- El método
prepare_model_for_kbit_training()prepara elmodeloprecargado para el entrenamiento con cuantificación. - El método
get_peft_model()toma elmodelobase cuantificado y preparado y aplicalora_config. - Define los argumentos de entrenamiento llamando a la clase
TrainingArguments(). - Inicializa el entrenador con
SFTTrainer().
A continuación se muestra el resultado esperado:

Paso n.º 7: Entrenar el modelo
El proceso finalmente está listo para entrenar el modelo Llama 4 utilizando el método train():
# Entrenar el modelo
trainer.train()
# Guardar el modelo ajustado
trainer.save_model(final_model_adapter_path) # Guarda el adaptador LoRA
tokenizer.save_pre-trained(final_model_adapter_path) # Guarda el tokenizador con el adaptadorEl resultado es el siguiente:

Tenga en cuenta que puede obtener números diferentes debido a la naturaleza estocástica de la IA.
Paso n.º 8: preparar el modelo para la inferencia
Para preparar el modelo para la inferencia, escriba el siguiente código en una nueva celda:
# Cargar el modelo con cuantificación para la inferencia
base_model_for_inference = AutoModelForCausalLM.from_pre-trained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# Cargar el adaptador LoRA ajustado y adjuntarlo al modelo
fine_tuned_model_for_testing = PeftModel.from_pre-trained(
base_model_for_inference,
final_model_adapter_path
)
# Fusionar el adaptador LoRA en el modelo base
fine_tuned_model_for_testing = fine_tuned_model_for_testing.merge_and_unload()
# Cargar el tokenizador
fine_tuned_tokenizer_for_testing = AutoTokenizer.from_pre-trained(
final_model_adapter_path,
trust_remote_code=True)
# Configurar el tokenizador para la inferencia
fine_tuned_tokenizer_for_testing.pad_token = fine_tuned_tokenizer_for_testing.eos_token
fine_tuned_tokenizer_for_testing.padding_side = "left"
# Establecer el modelo ajustado en modo de evaluación
fine_tuned_model_for_testing.eval()El código de esta celda:
- Carga el modelo con el método
from_pre-trained()para realizar la inferencia. - Carga, aplica y fusiona el adaptador LoRA al modelo base para la inferencia.
- Carga el tokenizador ajustado y lo configura para la inferencia.
- Establece el modelo en modo de evaluación con el método
eval(). Esto deshabilita los comportamientos específicos del entrenamiento, lo que garantiza resultados consistentes y deterministas durante la inferencia.
¡Ya está! Todo está configurado para la inferencia.
Paso n.º 9: Inferir el modelo
En este último paso, realizarás la inferencia. Anteriormente, has entrenado Llama 4 con productos extraídos de Amazon. Ahora, dada una serie de datos que incluyen el nombre y las características de artículos de oficina, quieres ver si el modelo es capaz de generar su descripción.
El siguiente código le permite gestionar el proceso de inferencia:
# Define una lista de elementos de datos de productos sintéticos para probar el modelo ajustado
synthetic_test_items = [
{
"title": "Silla de oficina ergonómica ejecutiva", "brand": "ComfortLuxe", "category": "Sillas de oficina", "name": "ErgoPro-EL100",
"features": ["Diseño con respaldo alto", "Soporte lumbar ajustable", "Tejido de malla transpirable", "Mecanismo de inclinación sincronizado", "Reposabrazos acolchados", "Base de nailon resistente"]
},
{
"title": "Convertidor de escritorio ajustable", "brand": "FlexiDesk", "category": "Escritorios y estaciones de trabajo", "name": "HeightRise-FD20",
«características»: [«Amplia superficie de dos niveles», «Elevación suave con resorte de gas», «Rango de altura ajustable de 6 a 17 pulgadas», «Soporta hasta 35 libras», «Bandeja para teclado incluida», «Pies de goma antideslizantes»]
},
{
«título»: «Combinación de teclado y ratón inalámbricos», «marca»: «TechGear», «categoría»: «Periféricos informáticos», «nombre»: «SilentType-KM850»,
"características": ["Teclado de tamaño completo con teclado numérico", "Teclas silenciosas", "Ratón ergonómico con DPI ajustable", "Conectividad inalámbrica de 2,4 GHz", "Batería de larga duración", "Receptor USB plug-and-play"]
},
{
«título»: «Organizador de escritorio con cajones», «marca»: «NeatOffice», «categoría»: «Accesorios de escritorio», «nombre»: «SpaceSaver-DO3»,
«características»: [«Diseño con múltiples compartimentos», «Dos cajones extraíbles», «Estructura de madera resistente», «Tamaño compacto», «Ideal para bolígrafos, notas y pequeños suministros»]
},
{
"title": "Lámpara de escritorio LED con puerto de carga USB", "brand": "BrightSpark", "category": "Iluminación de oficina", "name": "LumiCharge-LS50",
"características": ["Niveles de brillo ajustables (5)", "Modos de temperatura de color (3)", "Diseño flexible con cuello de cisne", "Puerto de carga USB integrado", "Luz que cuida la vista y no parpadea", "LED de bajo consumo"]
},
]
# Mensaje del sistema y estructura de solicitud para la inferencia
system_message_inference = «Eres un redactor publicitario experto. Genera una descripción del producto concisa y atractiva basándote en los detalles proporcionados».
print("n--- Generación de descripciones con un modelo ajustado utilizando datos de prueba sintéticos ---")
# Iterar a través de cada elemento de la lista synthetic_test_items
for item_data in synthetic_test_items:
# Construir la parte de solicitud al usuario basándose en la estructura del elemento sintético
user_prompt_inference = (
f"Generar una descripción del producto para el siguiente artículo de oficina:n"
f"Título: {item_data["title"]}n"
f"Marca: {item_data["brand"]}n"
f"Categoría: {item_data["category"]}n"
f"Nombre: {item_data["name"]}n"
f"Características: {", ".join(item_data["features"])}n"
f"Descripción:" # El modelo generará texto después de esto.
)
full_prompt_for_inference = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>usuario<|end_header_id|>nn{user_prompt_inference}<|eot_id|>"
f"<|start_header_id|>asistente<|end_header_id|>nn"
)
print(f"nPROMPT para el elemento: {item_data["name"]}")
# Tokenizar la cadena completa de la indicación utilizando el tokenizador ajustado.
inputs = fine_tuned_tokenizer_for_testing(
full_prompt_for_inference,
return_tensors="pt",
padding=False,
truncation=True,
max_length=max_seq_length_for_tokenization - 150
).to(fine_tuned_model_for_testing.device)
# Realizar inferencia
with torch.no_grad():
outputs = fine_tuned_model_for_testing.generate(
**inputs,
max_new_tokens=150,
num_return_sequences=1,
do_sample=True,
temperature=0.6,
top_k=50,
top_p=0.9,
pad_token_id=fine_tuned_tokenizer_for_testing.eos_token_id,
eos_token_id=[
fine_tuned_tokenizer_for_testing.eos_token_id,
fine_tuned_tokenizer_for_testing.convert_tokens_to_ids("<|eot_id|>")
]
)
# Decodificar los ID de tokens generados de nuevo en una cadena de texto legible para los humanos
generated_text_full = fine_tuned_tokenizer_for_testing.decode(outputs[0], skip_special_tokens=False)
# Definir el marcador que indica el comienzo de la respuesta del asistente en el formato de chat Llama.
assistant_marker = "<|start_header_id|>assistant<|end_header_id|>nn"
# Busca la última aparición del marcador del asistente en el texto generado.
assistant_response_start_index = generated_text_full.rfind(assistant_marker)
# Extrae la descripción real generada de la salida completa del modelo.
if assistant_response_start_index != -1:
# Si se encuentra el marcador del asistente, extrae el texto que viene después de él.
generated_description = generated_text_full[assistant_response_start_index + len(assistant_marker):]
# Define el token de fin de turno para Llama
eot_token = "<|eot_id|>"
# Comprueba si la descripción extraída termina con el token de fin de turno de Llama y elimínalo.
if generated_description.endswith(eot_token):
generated_description = generated_description[:-len(eot_token)]
# Comprueba también si termina con el token estándar de fin de secuencia del tokenizador y elimínalo.
if generated_description.endswith(fine_tuned_tokenizer_for_testing.eos_token):
descripción_generada = descripción_generada[:-len(fine_tuned_tokenizer_for_testing.eos_token)]
# Elimina cualquier espacio en blanco al principio o al final de la descripción limpia.
descripción_generada = descripción_generada.strip()
else:
# Recurso alternativo: Si no se encuentra el marcador del asistente, intenta extraer la parte generada asumiendo que es todo lo que hay después de la solicitud de entrada original.
input_prompt_decoded_len = len(fine_tuned_tokenizer_for_testing.decode(inputs["input_ids"][0], skip_special_tokens=False))
# Decodifica los tokens de la solicitud de entrada para obtener su longitud como una cadena.
descripción_generada = texto_generado_completo[input_prompt_decoded_len:].strip()
# Limpiar cualquier token de fin de turno de Llama de esta extracción alternativa.
if descripción_generada.endswith("<|eot_id|>"):
descripción_generada = descripción_generada[:-len("<|eot_id|>")]
descripción_generada = descripción_generada.strip()
# Imprimir la descripción generada extraída y limpia.
print(f"GENERATED (Fine-tuned):n{descripción_generada}")
# Imprimir una línea separadora para facilitar la lectura entre elementos.
print("-" * 50)Esta última celda de Jupyter Notebook gestiona el proceso de inferencia. Ese proceso es útil para ver lo bueno que fue el entrenamiento durante el proceso de ajuste fino.
En concreto, el código anterior:
- Define los datos de prueba como una lista llamada
synthetic_test_items. Cada elemento de esta lista es un diccionario que representa un producto y contiene detalles como su título, marca, categoría, nombre y una lista de características. Estos datos sirven como entrada para el modelo y su estructura debe coincidir con la del conjunto de datos de ajuste fino. - Configura su estructura de solicitud de referencia con
system_message_inference. Esta debe coincidir con la solicitud utilizada durante el proceso de entrenamiento. - El bucle
for item_data in synthetic_test_itemscrea un mensaje de usuario para cadaitem_data. La estructura de cadaitem_datadebe coincidir con la utilizada en el proceso de entrenamiento. - Tokeniza y controla cómo el modelo produce el texto de salida. La inferencia real se realiza bajo la instrucción
with. En particular, gracias al métodogenerate(), que es el paso de inferencia central. - Decodifica la salida sin procesar del modelo (que es una secuencia de ID de tokens) en una cadena legible para los humanos (
generated_text_full) utilizando el tokenizador. - Utiliza un bloque
if-elsepara limpiar la salida sin procesar del modelo de lenguaje y extraer solo la descripción del producto generada por el asistente. La salida sin procesar (generated_text_full) suele incluir toda la entrada seguida de la respuesta del modelo, todo ello formateado con los tokens de chat especiales de Llama. - Imprime los resultados.
El resultado esperado es el siguiente:
--- Generación de descripciones con un modelo ajustado utilizando datos de prueba sintéticos ---
PROMPT para el artículo: ErgoPro-EL100
GENERADO (ajustado):
**Presentamos la ErgoPro-EL100: la silla de oficina ergonómica ejecutiva definitiva**
Experimente lo último en comodidad y soporte con la ComfortLuxe ErgoPro-EL100, diseñada para mejorar su experiencia laboral. Esta silla de oficina de primera calidad cuenta con un diseño de respaldo alto que envuelve la parte superior del cuerpo, proporcionando un soporte lumbar sin igual y promoviendo una postura saludable.
El tejido de malla transpirable garantiza una experiencia de asiento fresca y cómoda, mientras que el mecanismo de inclinación sincronizado permite ajustes perfectos a su posición de trabajo preferida. Los reposabrazos acolchados proporcionan un apoyo y una comodidad adicionales, reduciendo la tensión en los hombros y las muñecas.
Fabricada para durar, la ErgoPro-EL100 cuenta con una base de nailon resistente que garantiza estabilidad y durabilidad. Tanto si trabaja muchas horas como si simplemente
--------------------------------------------------
PROMPT para el artículo: HeightRise-FD20
GENERADO (ajustado):
**Aumente su productividad con el convertidor de escritorio ajustable HeightRise-FD20 de FlexiDesk**
Lleve su trabajo a nuevas alturas con el HeightRise-FD20 de FlexiDesk, el convertidor de escritorio ajustable definitivo. Diseñado para revolucionar su espacio de trabajo, este innovador convertidor transforma cualquier escritorio en una estación de pie cómoda y ergonómica.
**Experimente los beneficios de estar de pie**
El HeightRise-FD20 cuenta con una amplia superficie de dos niveles, perfecta para colocar su ordenador portátil, monitor y otras herramientas de trabajo esenciales. El suave elevador de gas permite ajustar la altura sin esfuerzo, desde 15 hasta 43 cm, lo que garantiza una posición de pie cómoda que se adapta a sus necesidades.
**Duradero y fiable**
Con una construcción robusta y patas de goma antideslizantes.
--------------------------------------------------¡Et voilà! Ha ajustado Llama 4 con un nuevo conjunto de datos recuperado mediante las API de Bright Data Scraper.
Conclusión
En este artículo, has aprendido a ajustar Llama 4 con un conjunto de datos extraídos de Amazon utilizando las API de Bright Data Scraper. Has seguido todo el proceso, que consiste en:
- Recuperar los datos de la web.
- Configurar una cuenta de Hugging Face con un token.
- Configurar la infraestructura en la nube necesaria.
- Entrenar y probar (inferir) Llama 4.
El núcleo del proceso de ajuste fino se basa en disponer de Conjuntos de datos de alta calidad. Afortunadamente, Bright Data te ofrece numerosos servicios preparados para la IA para la adquisición o creación de Conjuntos de datos:
- Navegador de scraping: un navegador compatible con Playwright, Selenium y Puppeter con capacidades de desbloqueo integradas.
- API de Scraper: API preconfiguradas para extraer datos estructurados de más de 100 dominios importantes.
- Web Unlocker: una API todo en uno que se encarga de desbloquear sitios con protecciones antibots.
- API SERP: una API especializada que desbloquea los resultados de los motores de búsqueda y extrae datos SERP completos.
- Modelos básicos: acceda a conjuntos de datos compatibles a escala web para impulsar el preentrenamiento, la evaluación y el ajuste.
- Proveedores de datos: conéctese con proveedores de confianza para obtener conjuntos de datos de alta calidad y preparados para la IA a gran escala.
- Paquetes de datos: obtenga conjuntos de datos seleccionados y listos para usar, estructurados, enriquecidos y anotados.
¡Cree una cuenta Bright Data gratuita para probar nuestra infraestructura de datos preparada para la IA!





