

La generación aumentada por recuperación (RAG) y el ajuste fino son dos conceptos muy diferentes en la IA y tienen dos propósitos muy distintos. La RAG permite a un LLM acceder a información externa durante el tiempo de ejecución. El ajuste fino permite al LLM ajustar su conocimiento interno para un aprendizaje más profundo y permanente.
Al final de esta guía, podrás responder a las siguientes preguntas.
- ¿Qué es el ajuste fino?
- ¿Qué es RAG?
- ¿Cuándo se debe utilizar el ajuste fino?
- ¿Cuándo se debe utilizar RAG?
- ¿Cómo se complementan el RAG y el ajuste fino?
¿Qué es el ajuste fino?
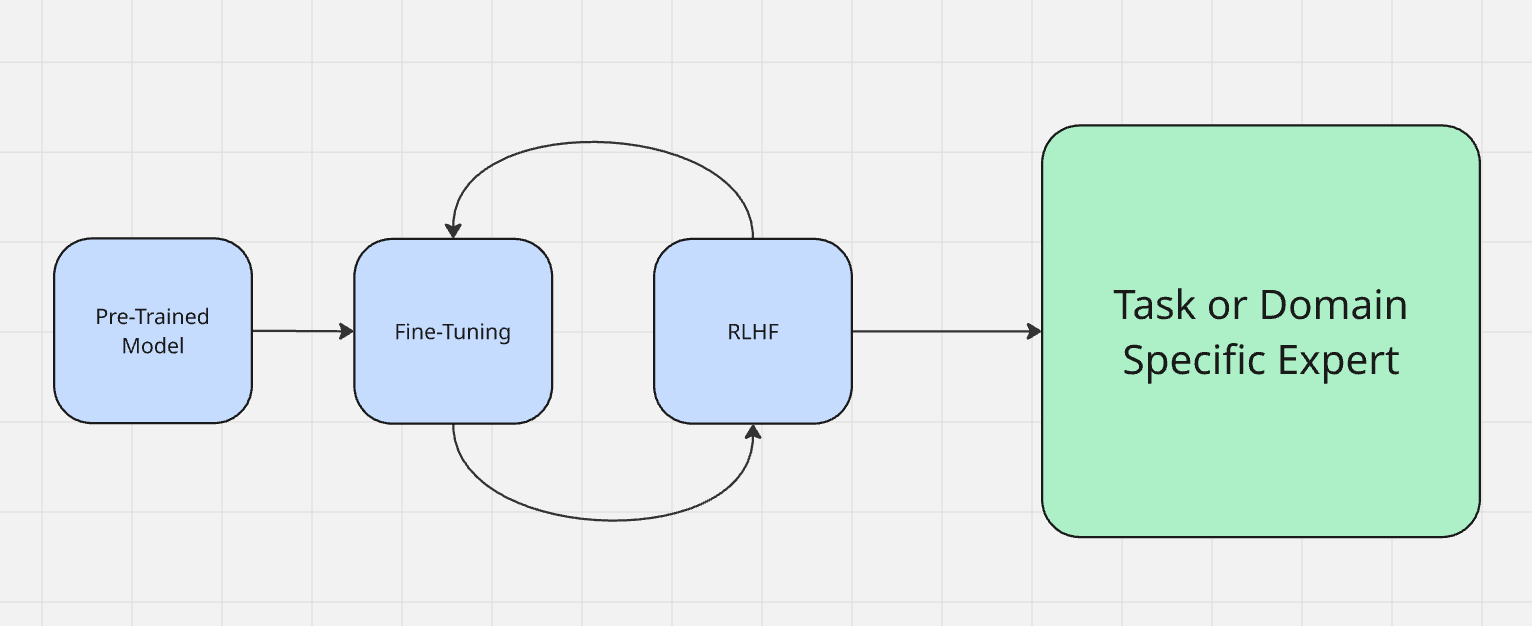
El ajuste fino se considera a menudo parte del proceso real de entrenamiento del modelo. Puede obtener más información sobre cómo se entrenan los modelos aquí. Los modelos pasan primero por un periodo denominado «preentrenamiento». En términos sencillos, es cuando aprenden a ingestar entradas y generar salidas. Una vez finalizado el preentrenamiento, el modelo contiene una gran cantidad de conocimientos, pero aún no está optimizado para aplicarlos.
Normalmente ajustamos un modelo utilizando el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). Al realizar el ajuste fino, se habla con el modelo para comprobar su salida. Por ejemplo, si un modelo dice «el cielo es verde», hay que corregirlo para que diga «el cielo es azul». Al ajustar, se evalúa la salida de la máquina y se refuerza el comportamiento deseado, de forma similar a cuando se le dice a un perro «¡buen chico!» por su buen comportamiento o se le da un golpe con el periódico por su mal comportamiento.
Al ajustar un LLM, lo estás preparando para su tarea real en el mundo real. Hay dos tipos principales de ajuste.
- Adaptación de dominio: imagina que quieres crear un experto en programación con un modelo base como DeepSeek. Tienes un modelo sólido con una base decente, pero aún no es un verdadero experto en nada. Claro, entiende los comandos de shell y la mayor parte del código Python, pero necesita experiencia. Aquí es donde le enseñarías los puntos más delicados de la informática y la codificación con cosas como StackOverflow y LeetCode. Una vez finalizado el ajuste, tendrás un modelo que puede escribir código más rápido y mejor que cualquier humano.
- Adaptación a la tarea: La adaptación a la tarea consiste en adaptarse a la tarea que se está realizando. En los LLM actuales, esto se ve más comúnmente en los chats reales. A principios de 2026, ChatGPT-4o recibió un ajuste muy intenso para adaptarse al sentimiento de la persona que hablaba con él. En este caso, se utilizó RLHF para incentivar al bot a reflejar el sentimiento del usuario. Si el usuario habla de forma técnica, GPT también lo hace. Si el usuario habla de derecho, GPT habla en lenguaje jurídico. Si el usuario suena religioso, GPT se vuelve religioso (sí, de verdad).
El ajuste se utiliza para influir en la toma de decisiones y las inferencias reales del modelo.
¿Qué es RAG?
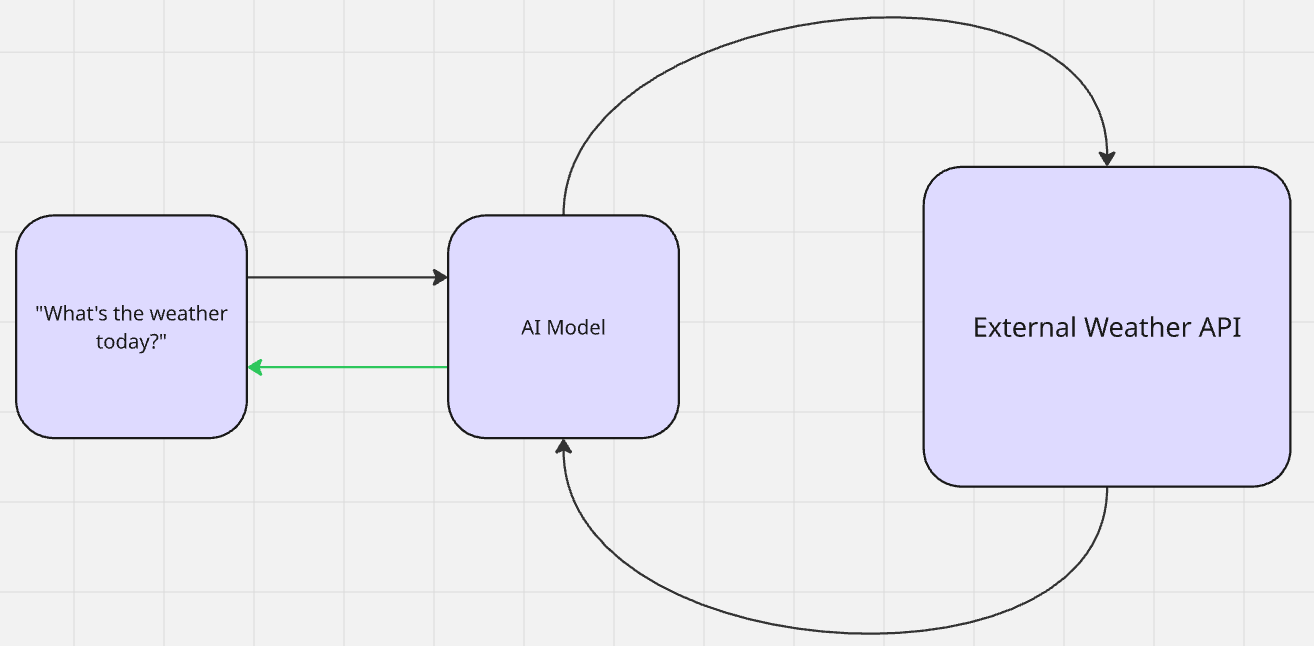
Con RAG, no se produce un aprendizaje real. Una IA recupera datos adicionales para la relevancia contextual y genera resultados. Una vez creados los resultados, el modelo vuelve a su estado anterior a la recuperación. Se trata de una forma de aprendizaje sin disparo. El modelo hace referencia a la información sin contexto previo. A continuación, utiliza su preentrenamiento para hacer inferencias y generar resultados.
Cuando le preguntas a Gemini «¿Qué tiempo hace hoy?», busca (recupera) el tiempo (aumenta su conocimiento) y luego te da (genera) la salida.
Hay dos tipos principales de RAG: pasivo y activo. Esto se demuestra mejor en la generación más reciente de modelos de chat con memorias almacenadas.
- RAG pasivo: los «recuerdos» se almacenan en una base de datos vectorial y se consultan más adelante para contextualizar. Cuando un LLM conoce tu nombre o tus preferencias, se trata de un RAG pasivo. La información consultada está pensada para ser estática y permanente. La única forma de eliminar los «recuerdos» es mediante la eliminación manual.
- RAG activo: Piensa en nuestro ejemplo anterior sobre el tiempo. El tiempo cambia todos los días. El modelo realiza una búsqueda activa (probablemente a través de una API) sobre el tiempo. Una vez que está seguro de que entiende el tiempo, te lo devuelve con su propia «personalidad» personalizada.
Las canalizaciones RAG siguen exactamente este flujo de trabajo: recuperar los datos -> aumentar la inferencia -> generar el resultado.
¿Cuándo se debe realizar un ajuste fino?
El ajuste fino se utiliza mejor cuando se quiere definir cómo piensa realmente el modelo. Cuando se quiere que el conocimiento y la inferencia sean permanentes, se debe realizar un ajuste fino. Si el LLM necesita comprender realmente los datos, se debe realizar un ajuste fino.
Si el resultado producido por su modelo no es del todo correcto, si su proceso de pensamiento parece incluso ligeramente erróneo, debe realizar un ajuste fino.
- Tono y personalidad: si tiene en mente una actitud o entonación específica para su modelo, realice un ajuste fino. Esto es especialmente útil en los chatbots personalizados. Cuando Grok 3 sorprendió al mundo con personalidades definidas por el usuario, esto se debió en gran parte al ajuste fino.
- Casos extremos y precisión: cuando tu modelo tiene problemas con casos extremos o no representa correctamente sus datos de entrenamiento, es necesario realizar un ajuste fino. Esto es especialmente cierto en el caso de los modelos utilizados en el diagnóstico médico. Un modelo que alucina con la ley podría dar lugar a procedimientos judiciales. Un modelo que alucina con una afección médica es peligroso para el paciente.
- Tamaño del modelo y reducción de costes: el ajuste fino puede reducir significativamente el tamaño y el coste operativo de su modelo. Por ejemplo, el equipo de Llama fue capaz de destilar los resultados de GPT-4 en GPT-3.5. Puede leer más sobre esto en su documentación sobre ajuste fino aquí.
- Nuevas tareas y capacidades: si desea añadir una capacidad real que aún no existe en un modelo preentrenado, debe ajustarlo. Imagine que tiene un modelo entrenado para utilizar solo inglés, pero necesita resultados en español: ni la ingeniería de prompts ni el RAG resolverán este problema, necesita un ajuste.
¿Cuándo se debe utilizar RAG?
RAG se utiliza mejor para modelos que ya piensan correctamente. Si su modelo produce el resultado correcto después del ajuste fino, es probable que sea el momento de añadir RAG para el acceso a datos externos. Sin el contexto adecuado, los modelos suelen resultar inútiles para muchas tareas, por muy inteligentes que sean.
Recuerde nuestro ejemplo anterior sobre el tiempo. Podría tener el modelo más inteligente del planeta, pero sin acceso a datos en tiempo real, su modelo no puede proporcionarle el tiempo, ni ninguna otra información en tiempo real. RAG tiene sentido para las siguientes necesidades de datos.
- Datos en tiempo real: ya lo hemos visto con el tiempo. Esto incluye noticias, proyecciones financieras, supervisión de sistemas y otros flujos de datos que cambian rápidamente.
- Asistentes de investigación o bibliotecarios: a veces, las personas solo necesitan que se les indique el recurso correcto. Cuando haces una pregunta con Gemini o Brave Search, obtienes una respuesta directa. El modelo revisa la documentación y te indica los recursos relevantes.
- Atención al cliente: cuando necesitas un LLM para atender el servicio de asistencia y responder a preguntas generales, RAG es rápido y eficaz. Los modelos de IA ya saben cómo responder a preguntas y leer documentación, solo necesitan acceder al contenido adecuado.
- Resultados personalizados: ¿Recuerdas que antes mencionamos el tono reflejado por el usuario de GPT? No se trata de brujería medieval. El modelo hace referencia a datos almacenados en una base de datos. Si OpenAI tuviera que volver a entrenar los modelos para cada usuario, no existiría.
Cómo decidir entre ellos
Si tu modelo necesita pensar mejor, debes ajustarlo. Si tu modelo necesita información externa, utiliza RAG. En realidad, nos estamos moviendo hacia sistemas híbridos. Una vez que lo lances al mercado, tu modelo necesita pensar con claridad y acceder a los datos adecuados. La siguiente tabla te ayudará a decidir cuándo utilizar cada uno de ellos para tu proyecto.
| Situación | Mejor opción | ¿Por qué? |
|---|---|---|
| El resultado suena incorrecto o desalineado | Ajustar | Estás corrigiendo el razonamiento, el tono o el comportamiento |
| La salida es precisa, pero carece de detalles | RAG | Te faltan datos externos o específicos del ámbito |
| Necesitas datos actualizados o datos en tiempo real | RAG | Los modelos estáticos no pueden aprender después del entrenamiento. |
| Desea un rendimiento sólido en un nuevo dominio | Ajustar | Está añadiendo conocimientos profundos e internalizados |
| Necesita tanto precisión como actualidad | Ambos | Ajuste fino para la lógica, RAG para el conocimiento externo |
Herramientas de Bright Data para RAG y ajuste fino
En Bright Data, ofrecemos un sólido conjunto de herramientas para satisfacer tus necesidades de ajuste y RAG. Tanto si necesitas Conjuntos de datos de entrenamiento como canalizaciones en tiempo real, nuestros sistemas te lo proporcionan.
Ajuste
- Conjuntos de datos: obtenga datos históricos de todo Internet, actualizados diariamente. Tanto si busca redes sociales, listados de productos o incluso Wikipedia, lo tenemos todo listo para el entrenamiento.
- API de archivo: entrene con fuentes multimodales y de otro tipo con petabytes de datos añadidos a diario.
- Anotación: acelere su entrenamiento utilizando un servicio de anotación flexible con su elección de etiquetado asistido por IA y supervisado por humanos.
RAG
- API de búsqueda: Realice búsquedas web en tiempo real utilizando cualquier motor de búsqueda importante con parámetros personalizados, como imágenes o compras.
- API Unlocker: utilice nuestros servicios de Proxy gestionados para extraer datos de casi cualquier sitio web.
- Navegador de agentes: Automatización completa del navegador para su agente de IA.
- Servidor MCP: conecte su agente de IA a nuestras herramientas con una integración perfecta.
Conclusión
El ajuste fino enseña a su modelo a pensar. RAG le da a su modelo acceso a datos externos sin necesidad de volver a entrenarlo ni sobrecargarlo. En realidad, debería utilizar ambos, pero en diferentes etapas del desarrollo.
Al comprender cuándo y por qué utilizar el ajuste fino y RAG, puede tomar decisiones informadas con sus propios modelos de IA. Tanto si está creando un experto en un dominio específico como si le está dando acceso a datos en tiempo real, nuestras herramientas están a su disposición, al igual que nosotros.
¡Regístrese para obtener una prueba gratuita y comience hoy mismo!





