
En este tutorial, aprenderá:
- Qué es Flyte y qué lo hace especial para flujos de trabajo de IA, datos y aprendizaje automático.
- Por qué los flujos de trabajo de Flyte son aún más potentes cuando se incorporan datos web.
- Cómo integrar Flyte con el SDK de Bright Data para construir un flujo de trabajo potenciado por IA para el análisis SEO.
¡Entremos en materia!
¿Qué es Flyte?
Flyte es una plataforma de orquestación de flujos de trabajo moderna y de código abierto que le ayuda a crear canalizaciones de IA, datos y aprendizaje automático de nivel de producción. Su principal fortaleza radica en unificar equipos y pilas tecnológicas, fomentando la colaboración entre científicos de datos, ingenieros de ML y desarrolladores.
Construido sobre Kubernetes, Flyte está diseñado para la escalabilidad, la reproducibilidad y el procesamiento distribuido. Puede utilizarlo para definir flujos de trabajo a través de su SDK de Python. A continuación, despliéguelos en la nube o en entornos locales, abriendo la puerta a una utilización eficiente de los recursos y una gestión simplificada del flujo de trabajo.
En el momento de escribir estas líneas, el repositorio GitHub de Flyte cuenta con más de 6.5k estrellas.
Características principales
Las principales características soportadas por Flyte son:
- Interfaces fuertemente tipadas: Definir los tipos de datos en cada paso para garantizar la corrección y hacer cumplir los guardarraíles de datos.
- Inmutabilidad: Las ejecuciones inmutables garantizan la reproducibilidad evitando cambios en el estado de un flujo de trabajo.
- Linaje dedatos: Realice un seguimiento del movimiento y la transformación de los datos a lo largo de todo el ciclo de vida del flujo de trabajo.
- Asignación de tareas y paralelismo: Ejecute tareas en paralelo de forma eficiente con una configuración mínima.
- Reejecución granular y recuperación de fallos: Reintente sólo las tareas fallidas o vuelva a ejecutar tareas específicas sin alterar los estados anteriores del flujo de trabajo.
- Almacenamiento en caché: almacene en caché los resultados de las tareas para optimizar las ejecuciones repetidas.
- Flujos de trabajo dinámicos y bifurcación: cree flujos de trabajo adaptables que evolucionen en función de las necesidades y ejecute bifurcaciones de forma selectiva.
- Flexibilidad de lenguaje: Desarrolle flujos de trabajo utilizando Python, Java, Scala, SDK de JavaScript o contenedores sin procesar en cualquier lenguaje.
- Despliegue nativo en la nube: Despliegue Flyte en AWS, GCP, Azure u otros proveedores de nube.
- Simplicidad de desarrollo a producción: Mueve flujos de trabajo de desarrollo o staging a producción sin esfuerzo.
- Gestión de entradas externas: Ponga en pausa la ejecución hasta que las entradas necesarias estén disponibles.
Para explorar todas las capacidades, consulte la documentación oficial de Flyte.
Por qué los flujos de trabajo de IA necesitan datos web frescos
Los flujos de trabajo de IA son tan potentes como los datos que procesan. Por supuesto, los datos abiertos son valiosos, pero el acceso a los datos en tiempo real es lo que marca la diferencia desde una perspectiva empresarial. ¿Y cuál es la mayor y más rica fuente de datos? La web.
Al incorporar datos web en tiempo real a sus flujos de trabajo de IA, puede obtener información más profunda, mejorar la precisión de las predicciones y tomar decisiones más informadas. Por ejemplo, tareas como el análisis SEO, la investigación de mercado o el seguimiento del sentimiento de marca dependen de información actualizada, que cambia constantemente en Internet.
El problema es que obtener datos web actualizados es todo un reto. Los sitios web tienen estructuras diferentes, requieren distintos enfoques de raspado y están sujetos a actualizaciones frecuentes. Aquí es donde entra en juego una solución como Bright Data Python SDK.
El SDK le permite buscar, raspar e interactuar con contenido web en vivo mediante programación. Más concretamente, proporciona acceso a los productos más útiles de la infraestructura de Bright Data a través de unas sencillas llamadas a métodos. Esto hace que el acceso a los datos web sea fiable y escalable.
Al combinar las capacidades web de Flyte y Bright Data, puede crear flujos de trabajo de IA automatizados que se mantengan actualizados con la web en constante cambio. Vea cómo en el siguiente capítulo.
Cómo construir un flujo de trabajo SEO AI en Flyte y Bright Data Python SDK
En esta sección guiada, aprenderá a construir un agente de IA en Flyte que:
- Toma una palabra clave (o frase clave) como entrada y utiliza el SDK de Bright Data para buscar resultados relevantes en la web.
- Utiliza el SDK de Bright Data para extraer las 3 primeras páginas para la palabra clave dada.
- Pasa el contenido de las páginas resultantes a OpenAI para generar un informe Markdown con información SEO.
En otras palabras, gracias a la integración Flyte + Bright Data, podrás crear un flujo de trabajo de IA real para el análisis SEO. Esto proporciona información procesable, relacionada con el contenido, basada en lo que las páginas con mejor rendimiento están haciendo para posicionarse bien.
¡Empecemos!
Requisitos previos
Para seguir este tutorial, asegúrate de tener
- Python instalado localmente
- Una clave de API de Bright Data (con permisos de administrador )
- Una clave API de OpenAI
Se le guiará a través de la configuración de su cuenta Bright Data para su uso con el SDK Python de Bright Data, así que no necesita preocuparse por eso ahora. Para más información, eche un vistazo a la documentación.
La guía oficial de instalación de Flyte recomienda la instalación a través de uv. Por lo tanto, instale/actualice uv globalmente con:
pip install -U uvPaso #1: Configuración del Proyecto
Abre un terminal y crea un nuevo directorio para tu proyecto de análisis SEO AI:
mkdir flyte-seo-workflowLa carpeta flyte-seo-workflow/ contendrá el código Python para su flujo de trabajo Flyte.
A continuación, navega al directorio del proyecto:
cd flyte-seo-workflowEn el momento de escribir esto, Flyte sólo soporta versiones de Python >=3.9 y <3.13 (se recomienda la versión 3.12 ).
Configure un entorno virtual para Python 3.12 con:
uv venv --python 3.12Active el entorno virtual. En Linux o macOS, ejecute
source .venv/bin/activateEquivalentemente, en Windows, ejecute
.venv/Scripts/activateAñade un nuevo archivo llamado workflow.py. Tu proyecto debería contener ahora
flyte-seo-workflow/
├── .venv/
└── workflow.pyworkflow.py representa tu archivo Python principal.
Con el entorno virtual activado, instala las dependencias necesarias:
uv pip install flytekit brightdata-sdk openaiLas librerías que acabas de instalar son:
flytekit: Para crear flujos de trabajo y tareas Flyte.brightdata-sdk: Para ayudarle a acceder a las soluciones de Bright Data en Python.openai: Para interactuar con los LLM de OpenAI.
Nota: Flyte proporciona un conector oficial ChatGPT(ChatGPTTask), pero se basa en una versión antigua de las API de OpenAI. También viene con algunas limitaciones, como tiempos de espera estrictos. Por estas razones, generalmente es mejor proceder con una integración personalizada.
Carga el proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Listo. Ahora tiene un entorno Python listo para el desarrollo del flujo de trabajo de IA en Flyte.
Paso #2: Diseñe su flujo de trabajo de IA
Antes de saltar directamente a la codificación, es útil dar un paso atrás y pensar en lo que su flujo de trabajo AI necesita hacer.
En primer lugar, recuerde que un flujo de trabajo Flyte consiste en:
- Tareas: Funciones marcadas con la anotación
@task. Estas son las unidades fundamentales de computación en Flyte. Las tareas son bloques de construcción ejecutables independientemente, fuertemente tipados y contenedorizados que forman flujos de trabajo. - Flujos de trabajo: Marcados con
@workflow, los flujos de trabajo se construyen encadenando tareas, con la salida de una tarea alimentando la entrada de la siguiente para formar un grafo acíclico dirigido (DAG).
En este caso, puede lograr su objetivo con las siguientes tres tareas simples:
get_seo_urls: Dada una palabra o frase clave de entrada, utilice el SDK de Bright Data para recuperar las 3 URL principales de la SERP (página de resultados del motor de búsqueda) de Google resultante.get_content_pages: Recibe las URL como entrada y utiliza el SDK de Bright Data para raspar las páginas, devolviendo su contenido en formato Markdown(que es ideal para el procesamiento de IA).generate_seo_report: Obtiene la lista de contenido de la página y la pasa a una solicitud, pidiéndole que produzca un informe Markdown que contenga información sobre SEO, como enfoques comunes, estadísticas clave (número de palabras, párrafos, H1, H2, etc.) y otras métricas relevantes.
Prepárese para implementar las tareas y el flujo de trabajo de Flyte importándolos desde flytekit:
from flytekit import task, workflow¡Maravilloso! Ahora, todo lo que queda es implementar el flujo de trabajo real.
Paso #3: Gestionar las claves API
Antes de implementar las tareas, necesitas ocuparte de la gestión de las claves API para las integraciones de OpenAI y Bright Data.
Flyte viene con un sistema de gestión de secretos dedicado, que le permite manejar de forma segura secretos en sus scripts, como claves de API y credenciales. En producción, confiar en el sistema de gestión de secretos de Flyte es la mejor práctica y altamente recomendada.
Para este tutorial, ya que estamos trabajando con un simple script, podemos simplificar las cosas mediante el establecimiento de las claves de la API directamente en el código:
importar os
os.environ["OPENAI_API_KEY"] = "<TU_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<TU_BRIGHTDATA_API_TOKEN>"Sustituye los marcadores de posición por los valores reales de tu clave API:
<YOUR_OPENAI_API_KEY>→ Su clave de API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Su token de API de Bright Data (recupérelo como se explica en la guía oficial de Bright Data).
Tenga en cuenta que se recomienda utilizar una clave de API de Bright Data con permisos de administrador. Esto permite que el SDK Python de Bright Data se conecte automáticamente a su cuenta y configure los productos requeridos al inicializar el cliente.
En otras palabras, el SDK Python de Bright Data con una clave API de administrador configurará automáticamente su cuenta con todo lo que necesita para funcionar.
Recuerde: Nunca codifique secretos en los scripts de producción. Utilice siempre un gestor de secretos en Flyte.
Paso #4: Implementar la tarea get_seo_urls
Defina una función get_seo_urls() que acepte una palabra clave como cadena, y anótela con @task para que se convierta en una tarea Flyte válida. Dentro de la función, utilice el método search() del SDK Python de Bright Data para realizar una búsqueda web.
Entre bastidores, search() llama a la API SERP de Bright Data, que devuelve los resultados de la búsqueda como una cadena JSON con este formato:
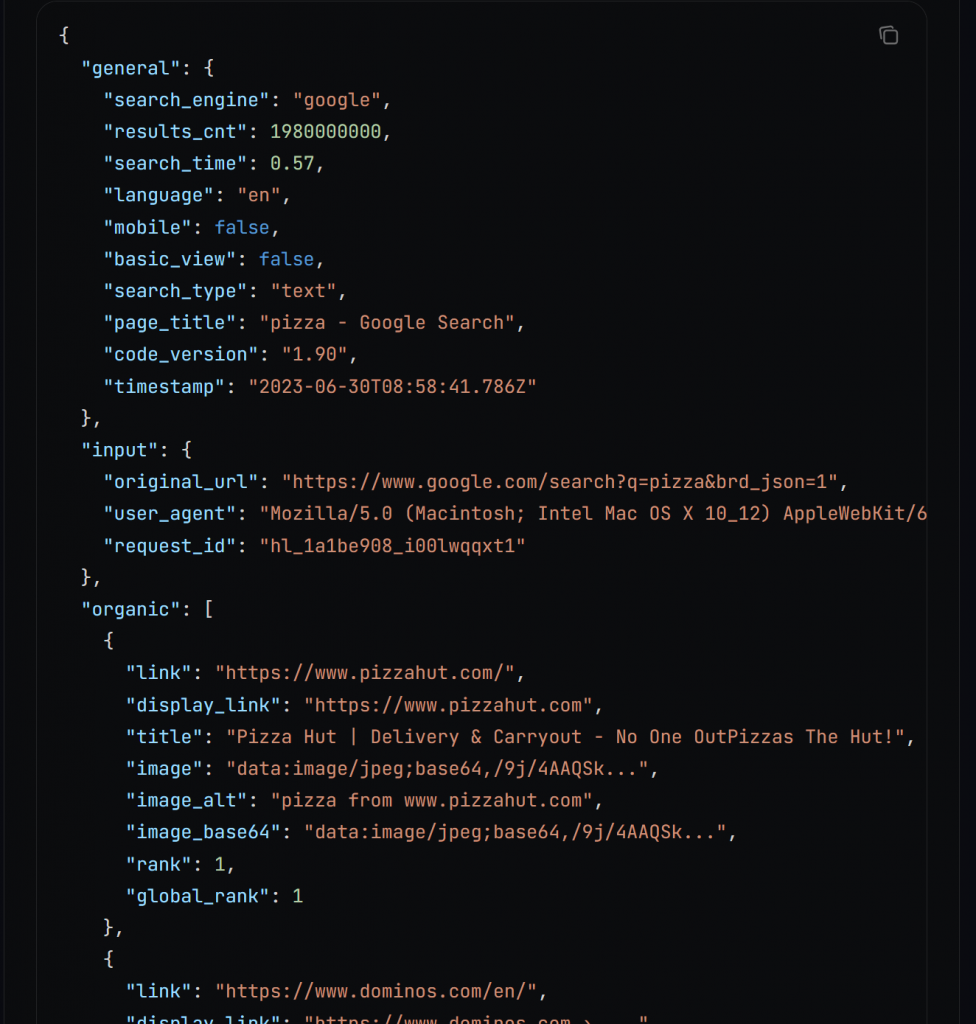
Más información sobre la función de salida JSON en la documentación.
Analice la cadena JSON en un diccionario y extraiga un número determinado de URL de SEO. Estas URL corresponden a los X primeros resultados que obtendría normalmente de Google al buscar la palabra clave introducida.
Implementa la tarea con:
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> Lista[str]:
import json
# Inicializar el cliente del SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtener la SERP de Google para la palabra clave dada como una cadena JSON analizada
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["cuerpo"].
data = json.loads(json_response)
# Extraer las URLs de las páginas SEO con mayor "num_links" de la SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urlsRecuerda la importación requerida para typing
from typing import ListaNota: Puede que se pregunte por qué el cliente Bright Data Python SDK se importa dentro de la tarea en lugar de globalmente. Esto es intencionado, ya que las tareas Flyte deben ser ejecutables independientemente. En otros términos, cada tarea debe incluir todo lo que necesita para ejecutarse por sí misma, sin depender de dependencias globales.
Paso 5: Implementar la tarea get_content_pages
Ahora que ha recuperado las URLs SEO, puede pasarlas al métodoscrape() del SDK Python de Bright Data. Este método raspa todas las páginas en paralelo y devuelve su contenido. Para recibir la salida en formato Markdown, simplemente establezca el argumento data_format="markdown":
@tarea()
def get_content_pages(page_urls:List[str]) -> List[str]:
# Inicializar el cliente del SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtener el contenido Markdown de cada página
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list será una lista de cadenas, donde cada cadena es la representación Markdown de la página de entrada correspondiente.
Bajo el capó, scrape() llama a la API Bright Data Web Unlocker. Se trata de una API de raspado de propósito general capaz de acceder a cualquier página web, independientemente de sus protecciones anti-bot.
Independientemente de las URL que haya obtenido en la tarea anterior, get_content_pages() obtendrá con éxito su contenido y lo convertirá de HTML sin procesar a Markdown optimizado y listo para la IA.
Paso 6: Implementar la tarea generate_seo_report
Llama a la API de OpenAI con el prompt apropiado para generar un informe SEO basado en el contenido de la página obtenida:
def generate_seo_report(page_content_list: List[str]) -> str:
# Inicializar el cliente OpenAI para llamar a las APIs OpenAI
from openai import OpenAI
openai_client = OpenAI()
# El prompt para generar el informe SEO deseado
prompt = f""
# Dado el contenido de abajo para algunas páginas web,
# producir un informe estructurado en formato Markdown que contenga los conocimientos SEO obtenidos analizando el contenido de cada página.
# El informe debe incluir:
# - Temas y elementos comunes entre todas las páginas
# - Diferencias clave entre las páginas
# - Una tabla resumen que incluya estadísticas como el número de palabras, número de párrafos, recuento de encabezados H2 y H3, etc.
# CONTENIDO:
# {"{nnPAGE:".join(page_content_list)}
# """
# Ejecutar la consulta en el modelo de IA seleccionado
response = openai_client.responses.create(
model="gpt-5-mini",
input=pregunta,
)
return response.output_textEl resultado de esta tarea será el informe SEO Markdown deseado.
Nota: El modelo OpenAI utilizado anteriormente era GPT-5-mini, pero puedes sustituirlo por cualquier otro modelo OpenAI. Del mismo modo, puedes sustituir la integración OpenAI por completo y utilizar cualquier otro proveedor de LLM.
Fantástico. Las tareas están listas, y ahora es el momento de combinarlas en un flujo de trabajo Flyte AI.
Paso 7: Definir el flujo de trabajo de IA
Crea una función @workflow que orqueste las tareas en secuencia:
@workflow
def seo_ai_workflow() -> str:
input_kw = "mejor llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
devolver informeEn este flujo de trabajo:
- La tarea
get_seo_urlsrecupera las 3 mejores URLs SEO para la frase clave “best llms”. - La tarea
get_content_pagesraspa y convierte el contenido de esas URLs en Markdown. - La tarea
generate_seo_reporttoma el contenido Markdown y produce un informe final de SEO en formato Markdown.
¡Misión completada!
Paso #8: Poner todo junto
Su archivo final workflow.py debe contener:
from flytekit import tarea, flujo de trabajo
importar os
from typing import Lista
# Establece los secretos requeridos (sustitúyelos por tus claves API)
os.environ["OPENAI_API_KEY"] = "<TU_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<TU_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> Lista[str]:
import json
# Inicializar el cliente del SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtener la SERP de Google para la palabra clave dada como una cadena JSON analizada
res = bright_data_client.search(kw, response_format="json", parse=True)
# Analizar la cadena JSON para convertirla en un diccionario
json_response = res["cuerpo"]
data = json.loads(json_response)
# Extraer las URLs de las páginas SEO con mayor "num_links" de la SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@tarea()
def get_content_pages(page_urls: List[str]) -> List[str]:
# Inicializar el cliente del SDK de Bright Data
from brightdata import bdclient
bright_data_client = bdclient()
# Obtener el contenido Markdown de cada página
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@tarea
def generar_seo_informe(lista_pagina_contenido: Lista[str]) -> str:
# Inicializar el cliente OpenAI para llamar a las APIs OpenAI
from openai import OpenAI
openai_client = OpenAI()
# El prompt para generar el informe SEO deseado
prompt = f""
# Dado el contenido de abajo para algunas páginas web,
# producir un informe estructurado en formato Markdown que contenga los conocimientos SEO obtenidos analizando el contenido de cada página.
# El informe debe incluir:
# - Temas y elementos comunes entre todas las páginas
# - Diferencias clave entre las páginas
# - Una tabla resumen que incluya estadísticas como el número de palabras, número de párrafos, recuento de encabezados H2 y H3, etc.
# CONTENIDO:
# {"{nnPAGE:".join(page_content_list)}
# """
# Ejecutar la consulta en el modelo de IA seleccionado
response = openai_client.responses.create(
model="gpt-5-mini",
input=pregunta,
)
return respuesta.texto_salida
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms" # Cámbialo para que coincida con tus objetivos de análisis SEO
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
devolver informe
if __name__ == "__main__":
seo_ai_workflow()¡Vaya! En menos de 80 líneas de código Python, acabas de construir un flujo de trabajo SEO AI completo. Esto no habría sido posible sin Flyte y el SDK de Bright Data.
Puede ejecutar su flujo de trabajo desde la CLI con:
pyflyte run workflow.py seo_ai_workflowEste comando lanzará la función seo_ai_workflow @workflow desde el archivo workflow.py.
Nota: Los resultados pueden tardar un poco en aparecer, ya que la búsqueda en la web, el scraping y el procesamiento de la IA llevan algún tiempo.
Cuando el flujo de trabajo se complete, deberías obtener un resultado Markdown similar a este:
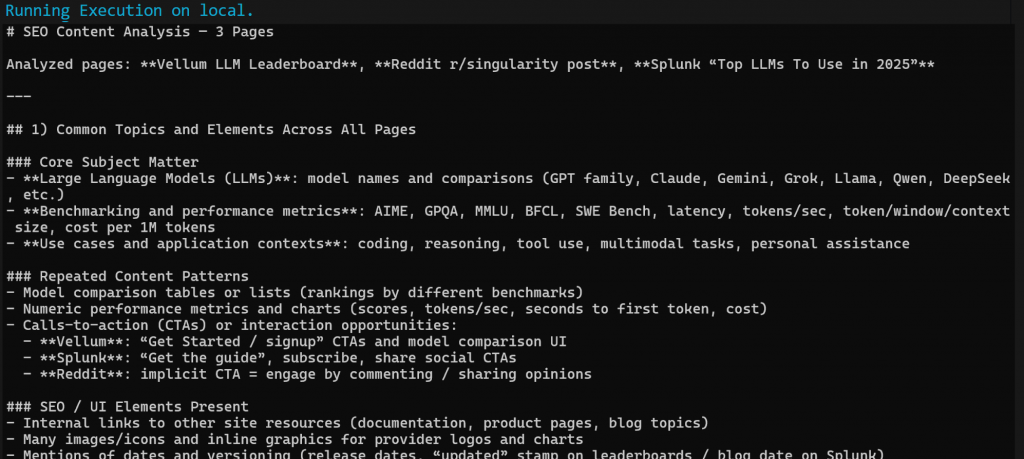
Pega la salida Markdown en cualquier visor Markdown para desplazarte por ella y explorarla. Debería tener un aspecto similar al siguiente:
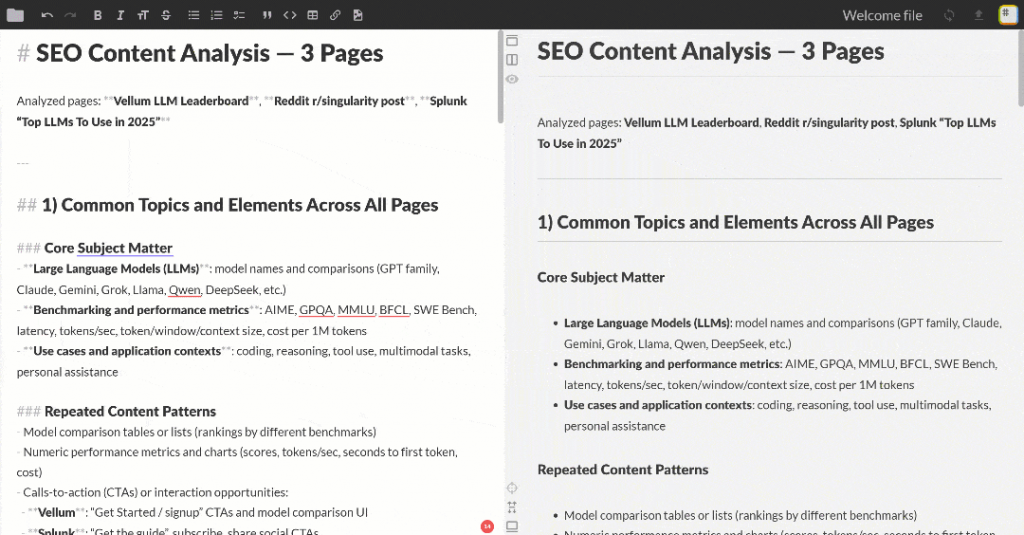
La salida contiene varias perspectivas SEO y una tabla resumen, exactamente como se solicitó a OpenAI. Este ha sido un simple ejemplo del poder de la integración de Flyte + Bright Data.
¡Et voilà! Siéntete libre de definir otras tareas y probar diferentes LLMs para implementar otros casos de uso útiles de flujos de trabajo agénticos y de IA.
Siguientes pasos
La implementación del flujo de trabajo Flyte AI que se proporciona aquí es sólo un ejemplo. Para que esté lista para producción, o para proceder con una implementación adecuada, los siguientes pasos son:
- Integrar un sistema de gestión de secretos compatible con Flyte: Evitar la codificación de claves API en el código. Utiliza Flyte task secrets u otros sistemas soportados para manejar las credenciales de forma segura y elegante.
- Gestión de avisos: Generar prompts dentro de una tarea es aceptable, pero para la reproducibilidad, considere versionar sus prompts o almacenarlos externamente.
- Despliegue del flujo de trabajo: Siga las instrucciones oficiales para dockerizar su flujo de trabajo y prepararlo para el despliegue utilizando las capacidades de Flyte.
Conclusión
En esta entrada de blog, aprendió a utilizar las capacidades de búsqueda y raspado web de Bright Data dentro de Flyte para crear un flujo de trabajo de análisis SEO impulsado por IA. El proceso de implementación se simplificó gracias al SDK de Bright Data, que proporciona un fácil acceso a los productos de Bright Data a través de llamadas a métodos sencillos.
Para crear flujos de trabajo más sofisticados, explore el conjunto completo de soluciones de la infraestructura de IA de Bright Data para obtener, validar y transformar datos web en tiempo real.
Regístrese gratuitamente en Bright Data y empiece a experimentar con nuestras soluciones de datos web preparadas para la IA.




