

En este tutorial, aprenderá:
- Por qué necesita una solución de monitorización de marca personalizada en primer lugar.
- Cómo crear una utilizando el SDK de Bright Data, OpenAI y SendGrid.
- Cómo implementar un flujo de trabajo de IA de monitorización de reputación de marca en Python.
Puedes ver el repositorio de GitHub para todos los archivos del proyecto. Ahora, ¡vamos a sumergirnos!
¿Por qué construir una solución de monitorización de marca personalizada?
Lamonitorización de marca es una de las tareas más importantes en marketing, y hay varios servicios online disponibles para ayudar con ella. El problema con estas soluciones es que tienden a ser caras y pueden no estar adaptadas a sus necesidades específicas.
Por eso tiene sentido crear una solución personalizada de control de la reputación de la marca. Al principio, esto puede sonar intimidante, ya que puede parecer un objetivo complejo. Sin embargo, con las herramientas adecuadas (como está a punto de ver), es completamente alcanzable.
Explicación del flujo de trabajo de IA de reputación de marca
En primer lugar, no se puede crear una herramienta de monitorización de marca eficaz sin información externa fiable sobre la marca. Una gran fuente para ello es Google News. Al comprender lo que se dice de su marca en los artículos de noticias diarios y el sentimiento que hay detrás de ellos, puede tomar decisiones informadas. El objetivo final es responder, proteger o promocionar tu marca.
El problema es que el scraping de artículos de noticias es complicado. Google News, en particular, está protegido con múltiples medidas anti-bot. Además, cada fuente de noticias tiene su propio sitio web con protecciones únicas, lo que dificulta la recopilación programática de datos de noticias de forma coherente.
Aquí es donde Bright Data entra en juego. Gracias a sus capacidades de búsqueda y raspado web, pone a su disposición numerosos productos e integraciones para acceder de forma programática a datos web públicos listos para IA desde cualquier sitio web.
En concreto, con el nuevo SDK de Bright Data, puede aprovechar las soluciones más útiles de Bright Data de forma simplificada mediante unas pocas líneas de código Python.
Una vez que disponga de los datos de las noticias, puede confiar en la IA para seleccionar los artículos más relevantes y analizarlos en busca de opiniones e información sobre las marcas. A continuación, puede utilizar un servicio como Twilio SendGrid para enviar el informe resultante a todo su equipo de marketing. A un alto nivel, esto es exactamente lo que hace un flujo de trabajo personalizado de IA de reputación de marca.
Ahora, echemos un vistazo más de cerca a cómo implementarlo desde una perspectiva técnica.
Pasos técnicos
Los pasos para implementar el flujo de trabajo de IA de monitorización de reputación de marca son:
- Cargar variables de entorno: Cargue las claves API de Bright Data, OpenAI y SendGrid desde las variables de entorno. Estas claves son necesarias para conectarse a los servicios de terceros que alimentan este flujo de trabajo.
- Cargar el archivo de configuración: Lea un archivo de configuración JSON (por ejemplo,
config.json) que contenga las consultas de búsqueda iniciales, el número de artículos de noticias que se incluirán en el informe, junto con la dirección de correo electrónico del remitente y las direcciones de correo electrónico de los destinatarios. - Recupere las URL de las páginas de Google News: Utilice el SDK de Bright Data para raspar las páginas de resultados del motor de búsqueda (SERPs ) para el término de búsqueda configurado. Desde cada una de ellas, acceda a las URL de las páginas de Google Noticias.
- Recopilación de páginas de Google News: Utilice el SDK de Bright Data para extraer las páginas completas de Google News en formato Markdown. Cada una de estas páginas contiene varias URL de artículos de noticias.
- Deje que la IA identifique las noticias principales: Introduzca las páginas de Google News extraídas en un modelo de OpenAI y deje que seleccione los artículos de noticias más relevantes para la supervisión de la marca.
- Raspe artículos de noticias individuales: Utilice el SDK de Bright Data para recuperar el contenido de cada artículo devuelto por la IA.
- Analizar los artículos de noticias para conocer la reputación de la marca: Introduzca cada artículo de noticias en la IA y pídale que proporcione un resumen, una indicación del análisis del sentimiento y datos clave para la reputación de la marca.
- Generar un informe HTML final: Pasa los resultados del análisis de noticias a la IA y pídele que genere un informe HTML bien estructurado.
- Envíe el informe por correo electrónico: Utiliza el SDK de SendGrid para enviar el informe HTML generado por la IA a los destinatarios especificados, proporcionando una visión global de la reputación de la marca.

Vea cómo implementar este flujo de trabajo de IA en Python.
Creación de un flujo de trabajo de reputación de marca potenciado por IA con el SDK de Bright Data
En esta sección del tutorial, aprenderá a crear un flujo de trabajo de IA para supervisar la reputación de su marca. Los datos de noticias de marca necesarios se obtendrán de Bright Data, a través del SDK de Bright Data para Python. OpenAI proporcionará las capacidades de IA y SendGrid se encargará del envío de correos electrónicos.
Al final de este tutorial, dispondrá de un flujo de trabajo completo de IA en Python que le entregará los resultados directamente en su bandeja de entrada. El informe de salida identificará las noticias clave que su marca debe conocer, dándole todo lo que necesita para responder rápidamente y mantener una fuerte presencia de marca.
¡Construyamos un flujo de trabajo de IA de reputación de marca!
Requisitos previos
Para seguir este tutorial, asegúrate de tener lo siguiente:
- Python 3.8+ instalado localmente.
- Una clave API de Bright Data.
- Una clave de API de OpenAI.
- Una clave de API Twilio SendGrid.
Si aún no dispone de un token de API de Bright Data, regístrese en Bright Data y siga la guía de configuración. Del mismo modo, siga las instrucciones oficiales de OpenAI para obtener su clave de API de OpenAI.
En cuanto a SendGrid, cree una cuenta, verifíquela, conecte una dirección de correo electrónico y verifique su dominio. Cree una clave API y compruebe que puede enviar correos electrónicos mediante programación a través de ella.
Paso #1: Crea tu Proyecto Python
Abre un terminal y crea un nuevo directorio para tu flujo de trabajo de IA de monitorización de reputación de marca:
mkdir brand-reputation-monitoring-workflowLa carpeta brand-reputation-monitoring-workflow/ contendrá el código Python para tu flujo de trabajo de IA.
A continuación, vaya al directorio del proyecto y cree un entorno virtual:
cd brand-reputation-monitoring-workflow
python -m venv .venvAhora, carga el proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Dentro de la carpeta del proyecto, añade un nuevo archivo llamado workflow.py. Su proyecto debería contener ahora
brand-reputation-monitoring-workflow/
├── .venv/
└── workflow.pyworkflow.py será tu archivo Python principal.
Activa el entorno virtual. En Linux o macOS, ejecuta:
source .venv/bin/activateDe forma equivalente, en Windows, ejecuta:
.venv/Scripts/activateCon el entorno activado, instala las dependencias necesarias con:
pip install python-dotenv brightdata-sdk openai sendgrid pydanticLas librerías que acabas de instalar son
python-dotenv: Para cargar variables de entorno desde un archivo.env, facilitando la gestión de claves API de forma segura.brightdata-sdk: Para ayudarle a acceder a las herramientas y soluciones de scraping de Bright Data en Python.openai: Para interactuar con los modelos lingüísticos de OpenAI.sendgrid: Para enviar rápidamente correos electrónicos utilizando la API Web Twilio SendGrid v3.pydantic: Para definir modelos para salidas de IA y su configuración.
Listo. Su entorno de desarrollo Python está listo para construir un flujo de trabajo de IA de monitorización de reputación de marca con OpenAI, Bright Data SDK y SendGrid.
Paso #2: Configurar la lectura de variables de entorno
Configure su script para leer secretos de las variables de entorno. En su archivo workflow.py, importe python-dotenv y llame a load_dotenv() para cargar automáticamente las variables de entorno:
from dotenv import load_dotenv
cargar_dotenv()Ahora tu script puede leer variables de un archivo .env local. Por lo tanto, cree un archivo .env en la raíz del directorio de su proyecto:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env # <-----------
└── workflow.pyAbra el archivo .env y añada los envs OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN y SENDGRID_API_KEY:
OPENAI_API_KEY="<SU_CLAVE_OPENAI_API_KEY>"
BRIGHT_DATA_API_TOKEN="<SU_BRIGHT_DATA_API_TOKEN>"
SENDGRID_API_KEY="<SU_CLAVE_SENDGRID_API_TOKEN>"Sustituye los marcadores de posición por tus credenciales reales:
<YOUR_OPENAI_API_KEY>→ Su clave de API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Su token de la API de Bright Data.<YOUR_SENDGRID_API_KEY>→ Su clave de API de SendGrid.
¡¡¡Genial!!! Ahora ha configurado de forma segura los secretos de terceros utilizando variables de entorno.
Paso #3: Inicializar los SDKs
Comience añadiendo las importaciones necesarias:
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClientA continuación, inicialice los clientes SDK:
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()Las tres líneas anteriores inicializan lo siguiente:
- SDK de Bright Data para Python
- OpenAI Python SDK
- SendGrid Python SDK
Tenga en cuenta que no necesita cargar manualmente las variables de entorno de la clave de API en su código y pasarlas a los constructores. Esto se debe a que OpenAI SDK, Bright Data SDK y SendGrid SDK buscan automáticamente OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN y SENDGRID_API_KEY en su entorno, respectivamente. En otras palabras, una vez que estos entornos están configurados en .env, los SDK se encargan de cargarlos por ti.
En concreto, los SDK utilizarán las claves de API configuradas para autenticar las llamadas de API subyacentes a sus servidores utilizando tu cuenta.
Importante: Para obtener más detalles sobre cómo funciona el SDK de Bright Data y cómo conectarlo a las zonas necesarias en su cuenta de Bright Data, consulte la página oficial de GitHub o la documentación.
¡Perfecto! Los bloques de construcción para elaborar su flujo de trabajo de IA de monitorización de reputación de marca ya están listos.
Paso 4: Recuperar las URL de Google News
El primer paso en la lógica del flujo de trabajo es extraer las SERP de las consultas de búsqueda relacionadas con la marca que desea supervisar. Para ello, utilice el método search() del SDK de Bright Data, que llama a la API de SERP entre bastidores.
A continuación, analice la respuesta de texto JSON que obtenga de search() para acceder a las URL de las páginas de noticias de Google, que tendrán el siguiente aspecto:
https://www.google.com/search?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQJegQIPhABConsigue todo eso con esta función
def get_google_news_page_urls(search_queries):
# Recuperar SERPs para las consultas de búsqueda dadas
serp_results = brightdata_client.search(
consultas_búsqueda,
search_engine="google",
parse=True # Para obtener el resultado SERP como una cadena JSON analizada
)
news_page_urls = []
for serp_result in serp_results:
# Cargar la cadena JSON en un diccionario
serp_data = json.loads(serp_result)
# Extraer la URL de Google News de cada SERP analizada
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "Noticias":
news_url = item["href"]
news_page_urls.append(news_url)
return página_noticias_urlsCuando se pasa una matriz de consultas a search() (como en este caso), el método devuelve una matriz de SERPs, una para cada consulta, respectivamente. Dado que parse está configurado como True, cada resultado se devuelve como una cadena JSON, que tendrá que analizar con el módulo json incorporado en Python.
Recuerde importar json de la biblioteca estándar de Python:
import json¡Fantástico! Ya puedes recuperar mediante programación una lista de URL de páginas de Google News relacionadas con tu marca.
Paso 5: Raspe las páginas de Google Noticias y obtenga las mejores URL de noticias
Tenga en cuenta que una sola página de Google Noticias contiene varios artículos de noticias:
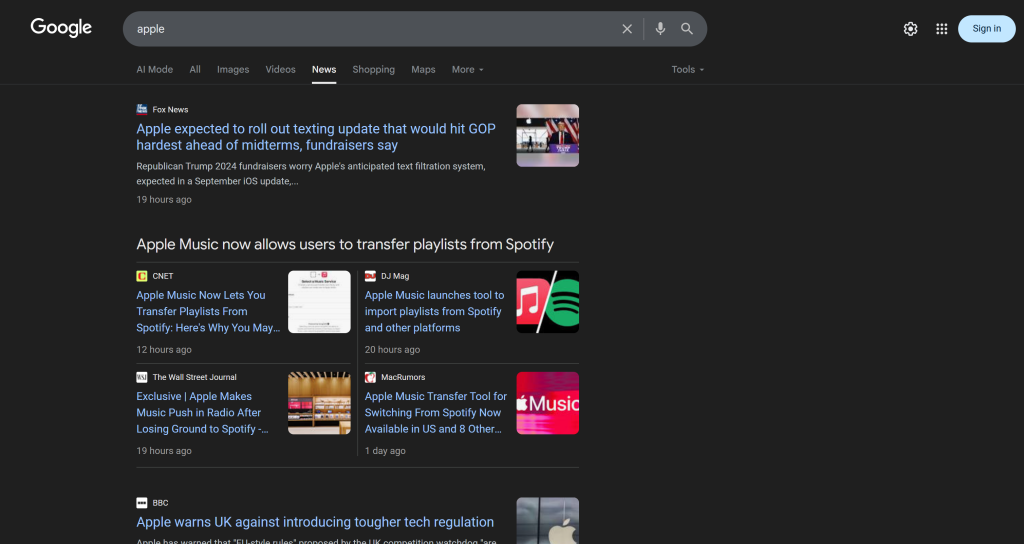
Por lo tanto, la idea es
- Scrapear el contenido de las páginas de Google News y obtener los resultados en formato Markdown.
- Alimentar el contenido Markdown a una IA (un modelo OpenAI, en este caso), pidiéndole que seleccione los 5 mejores artículos de noticias para la monitorización de la reputación de marca.
Consigue el primer micro-paso con esta función:
def scrape_news_pages(news_page_urls):
# Scrapea cada página de noticias en paralelo y devuelve su contenido en Markdown
return brightdata_client.scrape(
url=página_noticias_urls,
data_format="markdown"
) Bajo el capó, el método scrape() del SDK de Bright Data llama a la API Web Unlocker. Cuando se pasa una matriz de URL, scrape( ) realiza la tarea de raspado en paralelo, obteniendo todas las páginas simultáneamente. En este caso, la API está configurada para devolver datos en Markdown, que es ideal para la ingestión de LLM (como se demostró en nuestro benchmark de formato de datos en Kaggle).
A continuación, completa el segundo micro-paso con:
def get_best_news_urls(news_pages, num_news):
# Utiliza GPT para extraer las URLs de noticias más relevantes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"rol": "system",
"content": f "Extraer del texto las {num_news} noticias más relevantes para la monitorización de la reputación de marca y devolverlas como una lista de cadenas URL."
},
{
"role": "user",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLLista,
)
return response.output_parsed.urlsEsto simplemente concatena las salidas de texto Markdown de la función anterior y las pasa al modelo GPT-5-mini OpenAI, pidiéndole que extraiga las URL más relevantes.
Se espera que la salida siga el modelo URLList, que es un modelo Pydantic definido como:
class URLList(BaseModel):
urls: Lista[str]Gracias a la opcióntext_format del método parse(), estás indicando a la API de OpenAI que devuelva el resultado como una instancia de URLList. Básicamente, estás obteniendo una lista de cadenas, donde cada cadena representa una URL.
Importa las clases necesarias de pydantic:
from pydantic import BaseModel
from typing import Lista¡Impresionante! Ahora tiene una lista estructurada de URLs de noticias, lista para ser raspada y analizada en busca de reputación de marca.
Paso 6: Extraer las páginas de noticias y analizarlas para monitorizar la reputación de la marca
Ahora que tienes una lista de las mejores URL de noticias, utiliza scrape() de nuevo para obtener su contenido en Markdown:
def scrape_news_articles(news_urls):
# Raspa cada URL de noticias y devuelve una lista de dicts con URL y contenido
news_content_list = brightdata_client.scrape(
url=urls_noticias,
data_format="markdown"
)
lista_noticias = []
para url, contenido en zip(urls_noticias, lista_contenido_noticias):
news_list.append({
"url": url
"contenido": contenido
})
return lista_noticiasIndependientemente del dominio en el que estén alojados estos artículos de noticias o de las medidas anti-scraping que existan, la API de Web Unlocker se encargará de ello y devolverá el contenido de cada artículo en Markdown. En detalle, los artículos de noticias se rasparán en paralelo. Para realizar un seguimiento de qué URL de noticias corresponde a qué salida Markdown, utilice zip().
A continuación, introduce el contenido Markdown de cada noticia en OpenAI para analizar su reputación de marca. Para cada artículo, extraiga
- El título
- La URL
- Un breve resumen
- Una etiqueta rápida de sentimiento (por ejemplo, “positivo”, “negativo” o “neutral”)
- De 3 a 5 puntos de vista procesables, breves y fáciles de entender
Consíguelo con la siguiente función
def procesar_lista_noticias(lista_noticias):
# Dónde almacenar los artículos de noticias analizados
lista_análisis_noticias = []
# Analizar cada noticia con GPT para monitorizar la reputación de la marca
for news in lista_noticias:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"rol": "system",
"content": f""
Dado el contenido de la noticia:
1. Extraer el título.
2. 2. Extraer la URL.
3. Escribe un resumen en no más de 30 palabras.
4. Extraiga el sentimiento de la noticia como uno de los siguientes: "positivo", "negativo" o "neutro".
5. 5. Extrae de la noticia las 3 o 5 principales ideas breves y útiles (no más de 10/12 palabras) sobre la reputación de la marca, presentándolas en un lenguaje claro, conciso y directo.
"""
},
{
"rol": "user",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=AnálisisNoticias,
)
# Obtener el objeto de noticias analizado de salida y añadirlo a la lista
análisis_noticias = response.output_parsed
news_analysis_list.append(news_analysis)
return lista_análisis_noticiasEsta vez, el modelo Pydantic establecido en text_format es:
class AnálisisNoticias(ModeloBase):
título: str
url: str
resumen: str
análisis_sentimiento: cadena
percepciones: lista[str]Así, el resultado de la función process_news_list() será una lista de objetos NewsAnalysis.
¡Genial! El procesamiento de noticias basado en IA para la monitorización de la reputación de marca está completo.
Paso #7: Generar el Reporte de Email y Enviarlo
¿Alguna vez se ha preguntado cómo se estructuran los correos electrónicos y cómo aparecen en la bandeja de entrada de su cliente? Esto se debe a que la mayoría de los cuerpos de correo electrónico son en realidad sólo páginas HTML estructuradas. Al fin y al cabo, el protocolo de correo electrónico permite enviar documentos HTML.
Dada la lista de objetos de análisis de noticias generada anteriormente, conviértela en JSON, pásasela a AI y pídele que produzca un documento HTML listo para ser enviado por correo electrónico:
def create_html_email_body(lista_análisis_noticias):
# Generar un cuerpo de correo electrónico HTML estructurado a partir de las noticias analizadas
response = openai_client.responses.create(
model="gpt-5-mini",
input=f""
Dado el contenido que aparece a continuación, genere un cuerpo de correo electrónico HTML estructurado que esté bien formateado, responda y esté listo para enviar.
Asegúrese de utilizar correctamente encabezados, párrafos, etiquetas de color y enlaces cuando proceda.
No incluya encabezados ni pies de página y limítese a incluir esta información, nada más.
CONTENIDO:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_textPor último, utilice Twilio SendGrid SDK para enviar el correo electrónico mediante programación:
def send_email(sender, recipients, html_body):
# Enviar el correo electrónico HTML utilizando SendGrid
mensaje = Mail(
from_email=remitente,
to_emails=receptores,
subject="Informe semanal de seguimiento de la marca",
html_content=html_body
)
sendgrid_client.send(mensaje)Esto requiere la siguiente importación:
from sendgrid.helpers.mail import CorreoYa está. Todas las funciones para implementar este flujo de trabajo AI de monitoreo de reputación de marca ya han sido implementadas.
Paso 8: Cargue sus preferencias y configuraciones
Algunas de las funciones definidas en los pasos anteriores aceptan argumentos específicos (por ejemplo, search_queries, num_news, sender, recipients). Estos valores pueden cambiar de una ejecución a otra, por lo que no debes codificarlos en tu script Python.
En su lugar, léalos de un archivo config.json que contenga los siguientes campos:
search_queries: La lista de consultas de reputación de marca para las que recuperar noticias.num_news: El número de noticias que se incluirán en el informe final.remitente: Una dirección de correo electrónico aprobada por SendGrid desde la que se enviará el informe.destinatarios: La lista de direcciones de correo electrónico a las que se enviará el informe HTML.
Modele el objeto de configuración utilizando la siguiente clase Pydantic:
class Config(BaseModel):
consultas_busqueda: List[str] = Field(..., min_items=1)
num_news: int = Campo(..., gt=0)
remitente: str = Campo(..., min_longitud=1)
destinatarios: Lista[str] = Campo(..., min_elementos=1)Las definiciones de campo especifican reglas de validación para garantizar que las configuraciones cumplen el formato esperado. Se importa con
from pydantic import CampoA continuación, lea las configuraciones de flujo de trabajo de un archivo config.json local y analícelo en un objeto Config:
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config) Añade un archivo config.json al directorio de tu proyecto:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env
├── config.json # <-----------
└── workflow.pyY rellenarlo con algo como esto:
{
"search_queries": ["apple", "iphone", "ipad"],
"sender": "[email protected]",
"destinatarios": ["[email protected]", "[email protected]", "[email protected]"],
"num_news": 5
}Adapte los valores a sus objetivos específicos. Además, recuerde que el campo remitente debe ser una dirección de correo electrónico verificada en su cuenta SendGrid. De lo contrario, la función send_email( ) fallará con un error 403 Forbidden.
¡Así se hace! Otro paso y el flujo de trabajo está completo.
Paso #9: Definir la Función Principal
Es hora de componer todo. Llame a cada función predefinida en el orden correcto, dando las entradas correctas de la configuración:
consultas_busqueda = config.consultas_busqueda
print(f "Recuperando las URL de las páginas de Google Noticias para las siguientes consultas de búsqueda: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(consultas_busqueda)
¡print(f"{len(google_news_page_urls)} URL(s) de páginas de noticias de Google recuperadas!)
print("Extracción de contenido de cada página de Google Noticias...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("¡Páginas de Google News extraídas!)
print("Extracción de las URL de noticias más relevantes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(noticias_urls)} noticias encontradas:n" + "n".join(f"- {noticias}" for noticias in noticias_urls) + "n")
print("Escaneando los artículos de noticias seleccionados...")
news_list = scrape_news_articles(news_urls)
print(f"{len(noticias_urls)} ¡artículos de noticias raspados!")
print("Analizando cada noticia para monitorizar la reputación de marca...")
lista_análisis_noticias = lista_análisis_noticias(lista_noticias)
print("¡Análisis de noticias completo!)
print("Generando cuerpo de correo HTML...")
html = crear_cuerpo_email_html(lista_análisis_noticias)
print("¡Cuerpo de correo HTML generado!)
print("Enviando el email con el informe HTML de monitorización de reputación de marca...")
send_email(config.remitente, config.destinatarios, html)
print("¡E-mail enviado!")Nota: El flujo de trabajo puede tardar un poco en completarse, por lo que es útil añadir registros para realizar un seguimiento del progreso en el terminal. ¡Misión completada!
Paso #10: Poner todo junto
El código final del archivo workflow.py es:
from dotenv import load_dotenv
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Field
from typing import List
import json
from sendgrid.helpers.mail import Correo
# Cargar variables de entorno desde el archivo .env
load_dotenv()
# Inicializar el cliente del SDK de Bright Data
brightdata_client = bdclient()
# Inicializar el cliente OpenAI SDK
openai_client = OpenAI()
# Inicializar el cliente SDK SendGrid
sendgrid_client = SendGridAPIClient()
# Modelos Pydantic
clase Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Campo(..., gt=0)
remitente: str = Campo(..., min_longitud=1)
destinatarios: Lista[str] = Campo(..., min_elementos=1)
clase URLList(BaseModel):
urls: Lista[str]
clase NewsAnalysis(BaseModel):
title: str
url: str
resumen: str
análisis_sentimiento: cadena
percepciones: Lista[str]
def get_google_news_page_urls(consultas_busqueda):
# Recuperar SERPs para las consultas de búsqueda dadas
serp_results = brightdata_client.search(
consultas_búsqueda,
search_engine="google",
parse=True # Para obtener el resultado SERP como una cadena JSON analizada
)
news_page_urls = []
for serp_result in serp_results:
# Cargar la cadena JSON en un diccionario
serp_data = json.loads(serp_result)
# Extraer la URL de Google News de cada SERP analizada
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "Noticias":
news_url = item["href"]
news_page_urls.append(news_url)
return noticias_página_urls
def scrape_news_pages(news_page_urls):
# Escanea cada página de noticias en paralelo y devuelve su contenido en Markdown
return brightdata_client.scrape(
url=páginas_noticias_urls,
data_format="markdown"
)
def obtener_mejores_urls_noticias(paginas_noticias, numero_noticias):
# Utiliza GPT para extraer las URLs de noticias más relevantes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"rol": "system",
"content": f "Extraer del texto las {num_news} noticias más relevantes para la monitorización de la reputación de marca y devolverlas como una lista de cadenas URL."
},
{
"role": "user",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLLista,
)
return response.output_parsed.urls
def scrape_news_articles(news_urls):
# Raspa cada URL de noticia y devuelve una lista de dicts con URL y contenido
news_content_list = brightdata_client.scrape(
url=urls_noticias,
data_format="markdown"
)
lista_noticias = []
para url, contenido en zip(urls_noticias, lista_contenido_noticias):
news_list.append({
"url": url
"contenido": contenido
})
devolver lista_noticias
def procesar_lista_noticias(lista_noticias):
# Dónde almacenar los artículos de noticias analizados
lista_análisis_noticias = []
# Analizar cada noticia con GPT para monitorizar la reputación de la marca
for news in lista_noticias:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"rol": "system",
"content": f""
Dado el contenido de la noticia:
1. Extraer el título.
2. 2. Extraer la URL.
3. Escribe un resumen en no más de 30 palabras.
4. Extraiga el sentimiento de la noticia como uno de los siguientes: "positivo", "negativo" o "neutro".
5. 5. Extrae de la noticia las 3 o 5 principales ideas breves y útiles (no más de 10/12 palabras) sobre la reputación de la marca, presentándolas en un lenguaje claro, conciso y directo.
"""
},
{
"rol": "user",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=AnálisisNoticias,
)
# Obtener el objeto de noticias analizado de salida y añadirlo a la lista
análisis_noticias = response.output_parsed
news_analysis_list.append(news_analysis)
return lista_análisis_noticias
def crear_cuerpo_correo_html(lista_análisis_noticias):
# Generar un cuerpo de correo electrónico HTML estructurado a partir de las noticias analizadas
response = openai_client.responses.create(
model="gpt-5-mini",
input=f""
Dado el contenido que aparece a continuación, genere un cuerpo de correo electrónico HTML estructurado que esté bien formateado, responda y esté listo para enviar.
Asegúrese de utilizar correctamente encabezados, párrafos, etiquetas de color y enlaces cuando proceda.
No incluya encabezados ni pies de página y limítese a incluir esta información, nada más.
CONTENIDO:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_text
def send_email(remitente, destinatarios, html_body):
# Enviar el correo HTML usando SendGrid
mensaje = Mail(
from_email=remitente,
to_emails=receptores,
subject="Informe semanal de seguimiento de la marca",
html_content=html_body
)
sendgrid_client.send(mensaje)
def main():
# Leer el fichero config y validarlo
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config)
consultas_busqueda = config.consultas_busqueda
print(f "Recuperación de las URL de las páginas de Google Noticias para las siguientes consultas de búsqueda: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(consultas_busqueda)
¡print(f"{len(google_news_page_urls)} URL(s) de páginas de noticias de Google recuperadas!)
print("Extracción de contenido de cada página de Google Noticias...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("¡Páginas de Google News extraídas!)
print("Extracción de las URL de noticias más relevantes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(noticias_urls)} noticias encontradas:n" + "n".join(f"- {noticias}" for noticias in noticias_urls) + "n")
print("Escaneando los artículos de noticias seleccionados...")
news_list = scrape_news_articles(news_urls)
print(f"{len(noticias_urls)} ¡artículos de noticias raspados!")
print("Analizando cada noticia para monitorizar la reputación de marca...")
lista_análisis_noticias = lista_análisis_noticias(lista_noticias)
print("¡Análisis de noticias completo!)
print("Generando cuerpo de correo HTML...")
html = crear_cuerpo_correo_html(lista_análisis_noticias)
print("¡Cuerpo de correo HTML generado!)
print("Enviando el email con el informe HTML de monitorización de reputación de marca...")
send_email(config.remitente, config.destinatarios, html)
print("¡E-mail enviado!")
# Ejecuta la función principal
if __name__ == "__main__":
main()¡Et voilà! Gracias al SDK de Bright Data, la API de OpenAI y el SDK de Twilio SendGrid, has podido crear un flujo de trabajo de monitorización de la reputación de marca impulsado por IA en menos de 200 líneas de código.
Paso 11: Probar el flujo de trabajo
Asuma que sus search_queries son "nike" y "nike shoes". num_news está establecido en 5, y el informe está configurado para ser enviado a su correo electrónico personal (tenga en cuenta que puede utilizar la misma dirección de correo electrónico tanto para el remitente como para el primer elemento de los destinatarios).
En su entorno virtual activado, lance su flujo de trabajo con
python workflow.pyEl resultado en el terminal será algo parecido a
Recuperación de URL de páginas de Google News para las siguientes consultas de búsqueda: nike, zapatillas nike
2 URL de páginas de Google Noticias recuperadas.
Extracción del contenido de cada página de Google Noticias...
Páginas de Google Noticias extraídas
Extracción de las URL de noticias más relevantes...
5 noticias encontradas:
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
Raspado de los artículos de noticias seleccionados...
5 artículos extraídos
Análisis de cada noticia para monitorizar la reputación de la marca...
Análisis de noticias completo.
Generación del cuerpo HTML del correo electrónico...
¡Cuerpo de correo electrónico HTML generado!
Enviando el email con el informe HTML de monitorización de reputación de marca...
¡Email enviado!Nota: Los resultados cambiarán en función de las noticias disponibles. Por lo tanto, nunca serán los mismos que los anteriores para cuando leas este tutorial.
Después del mensaje “¡Email enviado!”, debería ver un “Informe semanal de monitorización de marca” en su bandeja de entrada:

Ábrelo, y contendrá algo como:
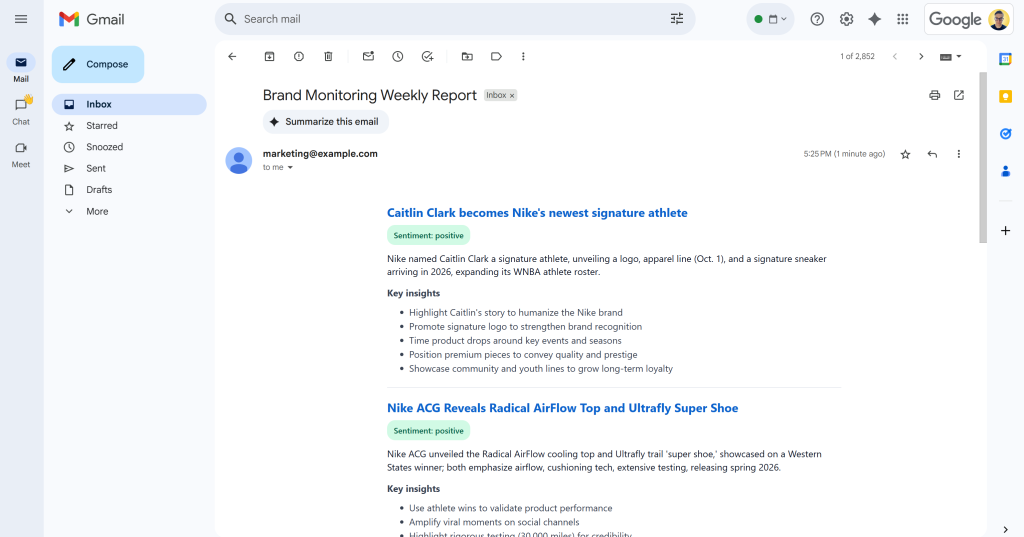
Como puede ver, la IA fue capaz de producir un informe de seguimiento de marca visualmente atractivo con todos los datos solicitados.
Desplácese por el informe y verá:
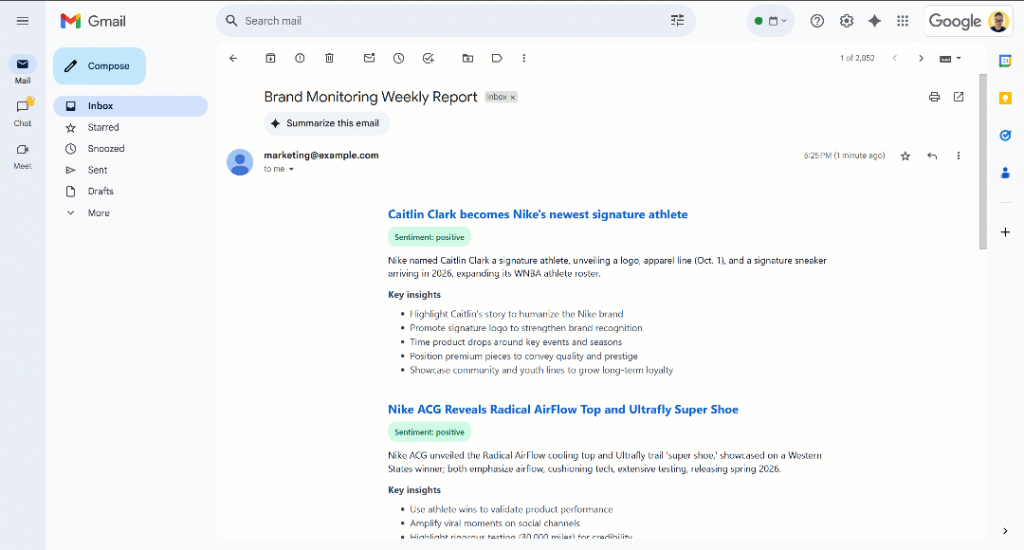
Observe que las etiquetas de sentimiento están codificadas por colores para ayudarle a comprender rápidamente el sentimiento. Además, los títulos de las noticias están en azul, ya que son enlaces a los artículos originales.
¡Et voilà! Empezó con unas cuantas consultas de búsqueda y terminó con un correo electrónico que contiene un informe de seguimiento de marca bien estructurado.
Todo ello ha sido posible gracias a la potencia de las soluciones de raspado de datos web disponibles en el SDK de Bright Data. Recuerde que las páginas raspadas se devuelven en formatos Markdown optimizados para LLM, de modo que cualquier modelo de IA pueda analizarlas según sus necesidades. Explore otros casos de uso de flujos de trabajo agénticos y de IA compatibles.
Próximos pasos
El actual flujo de trabajo de IA de monitorización de la reputación de marca ya es bastante sofisticado, pero podría mejorarlo aún más con estas ideas:
- Añada una capa de memoria para las noticias cubiertas anteriormente: Para evitar analizar los mismos artículos varias veces, mejorando la precisión de los informes y reduciendo la duplicación.
- Introducir plantillas SendGrid para la estandarización: La IA puede producir informes HTML ligeramente diferentes con estructuras distintas en cada ejecución. Para que el diseño sea coherente, defina una plantilla SendGrid, rellénela con los datos de análisis de noticias generados y envíela a través del SDK SendGrid. Más información en la documentación oficial.
- Almacene el informe HTML generado en la nube: Guarde el informe en S3 para asegurarse de que se archiva y está disponible para el análisis histórico de supervisión de marcas.
Conclusión
En este artículo, aprendió a aprovechar las capacidades de búsqueda y raspado web de Bright Data para crear un flujo de trabajo de reputación de marca impulsado por IA. Este proceso fue aún más fácil gracias al nuevo SDK de Bright Data, que permite acceder a los productos de Bright Data con simples llamadas a métodos.
El flujo de trabajo de IA presentado aquí es ideal para los equipos de marketing interesados en monitorizar su marca y recibir información procesable a bajo coste. Ayuda a ahorrar tiempo y esfuerzo proporcionando instrucciones contextuales para apoyar la protección de la marca y la toma de decisiones.
Para crear flujos de trabajo más avanzados, explore toda la gama de soluciones de la infraestructura de IA de Bright Data para obtener, validar y transformar datos web en tiempo real.
Cree una cuenta gratuita de Bright Data y empiece a experimentar con nuestras soluciones de datos web preparadas para la IA.





