

En este tutorial aprenderás:
- Cómo se puede utilizar un enfoque basado en el fan-out de consultas y la comparación de Google AI Overview para mejorar GEO y SEO.
- Cómo construir este flujo de trabajo a alto nivel utilizando seis agentes de IA.
- Cómo implementar este flujo de trabajo de optimización de contenido de IA con CrewAI, integrado con Gemini y Bright Data.
- Algunas ideas y consejos para mejorar aún más el flujo de trabajo.
Sumerjámonos.
TL;DR
¿Quieres pasar directamente a los archivos del proyecto listos para usar? Consulta el proyecto en GitHub.
Explicación de la comparación de consultas en Fan-Out y AI Overview para mejorar GEO y SEO
Todos sabemos que el SEO(Search Engine Optimization) es el arte de mejorar la visibilidad de un sitio web en los resultados de búsqueda orgánicos. Pero ahora el mundo está en transición hacia la GEO (Optimización Generativa deMotores).
Si no está familiarizado con GEO, se trata de una estrategia de marketing digital centrada en hacer que el contenido sea más visible dentro de los motores de búsqueda impulsados por IA, como Google AI Overviews, ChatGPT y otros.
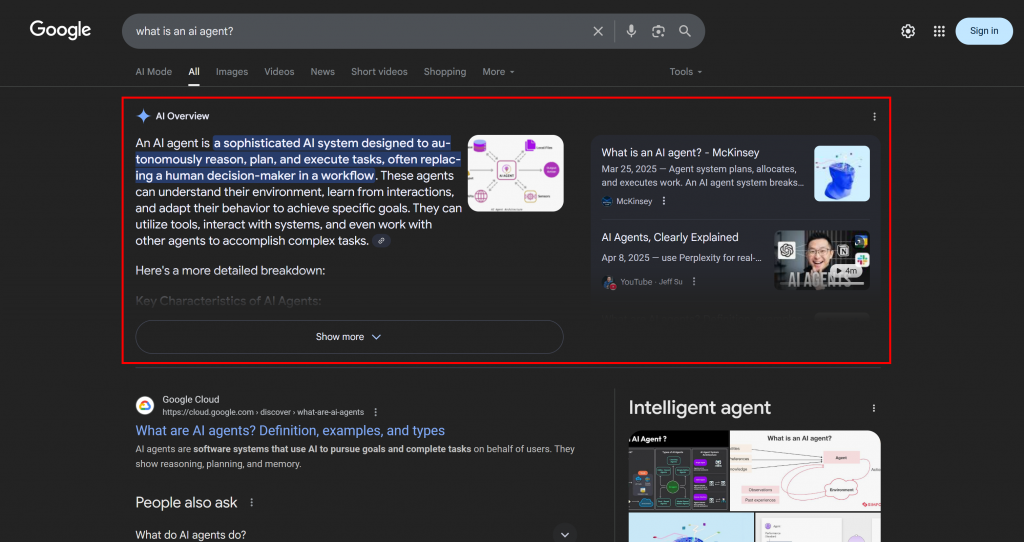
Dado que los LLM son esencialmente cajas negras, no existe una forma directa de “optimizar” una página web para GEO (de forma muy parecida a lo que era el SEO antes de que existieran las herramientas de búsqueda por volumen de palabras clave).
Lo que puede hacer es seguir un planteamiento empírico: observe los resúmenes generados por la IA en el mundo real y los resultados de las consultas para sus palabras clave objetivo. A partir de un término de búsqueda específico, si ciertos temas siguen apareciendo en los resultados de la IA, deberías optimizar el contenido de tu página en torno a esos temas.
En el contexto de la búsqueda asistida por IA de Google, un abanico de consultas es una técnica que convierte una única consulta del usuario en una red de subconsultas relacionadas. En lugar de limitarse a hacer coincidir la consulta original con la mejor respuesta, Google AI Mode va más allá generando y buscando varias preguntas relacionadas a la vez.
Como puede ver en el ejemplo siguiente, el Modo IA de Google suele devolver unos 10 enlaces relacionados con breves resúmenes que le ayudarán a profundizar en el tema:
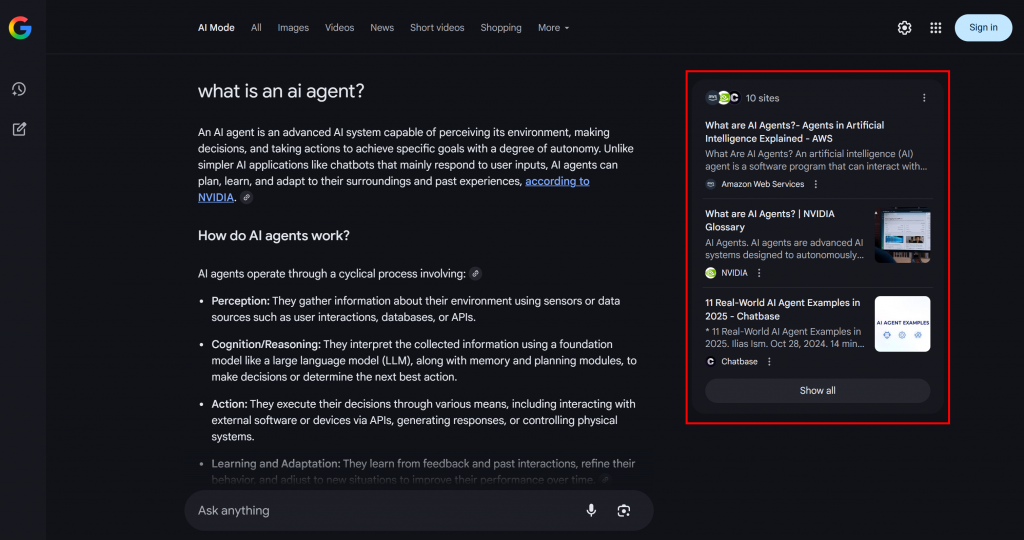
Eso es lo que es un fan-out de consultas de Google, que puede definirse en términos más sencillos como una colección de subconsultas relacionadas generadas a partir de una única búsqueda de IA.
Si ciertos temas se repiten en los fan-outs de consulta y en los resúmenes de IA, tiene sentido estructurar una página de contenido en torno a ellos. Como efecto secundario positivo, este enfoque también puede mejorar el SEO tradicional, ya que es probable que motores como Google impulsen las páginas en las SERP que ya funcionan bien en sus resultados de búsqueda impulsados por IA.
Ahora que ya conoces los conceptos básicos, puedes profundizar en los detalles técnicos de este enfoque de GEO.
Cómo construir un sistema de optimización GEO multiagente
Como puede imaginarse, la implementación de un agente de IA para apoyar su flujo de trabajo de optimización de contenidos GEO no es sencilla. Un enfoque eficaz es confiar en un sistema multiagente basado en seis agentes especializados:
- Raspador de títulos: Extrae el encabezado o título principal de una página web, dada su URL.
- Buscador de consultas de Google: Utiliza el título extraído para llamar a la herramienta de búsqueda de Google disponible en Gemini y generar un abanico de consultas.
- Extractor de consultas principales de Google: Analiza el abanico de consultas para identificar y extraer la consulta de búsqueda principal tipo Google.
- Recuperador de información general sobre IA de Google: Utiliza la consulta principal para realizar una búsqueda en la SERP de Google y recupera de ella la sección AI Overview.
- Resumidor deconsultas: Condensa el contenido de la consulta (que suele ser bastante largo) en un resumen optimizado de Markdown, destacando los temas clave.
- Optimizador de contenido de IA: Compara el resumen de la consulta con la descripción general de Google AI para identificar patrones y temas recurrentes. Genera un documento Markdown de salida con información práctica para la optimización del contenido GEO.
Ahora bien, algunos de los agentes descritos anteriormente son bastante genéricos y pueden implementarse con la mayoría de los LLM (por ejemplo, Google Main Query Extractor, Query Fan-Out Summarizer y AI Content Optimizer). Sin embargo, otros agentes requieren capacidades más especializadas y acceso a modelos o herramientas específicos.
Por ejemplo, el extractor de consultas principales de Google necesita acceder a la herramienta google_search, que sólo está disponible en los modelos Gemini. Del mismo modo, el agente Title Scraper debe acceder al contenido de la página web para extraer el título. Esta tarea puede suponer un reto, ya que muchos sitios web cuentan con medidas anti-AI. Para evitar problemas, puede integrar Title Scraper con Web Unlocker. Esta API de raspado de Bright Data recupera el contenido en HTML sin procesar o en formato Markdown optimizado para IA, evitando todos los bloqueos por usted.
Del mismo modo, el Recuperador de información general sobre la IA de Google requiere una herramienta como Bright Data SERP API para realizar la consulta de búsqueda y extraer la información general sobre la IA en tiempo real.
En otras palabras, gracias a Gemini y a la infraestructura de IA de Bright Data, puede implementar este caso de uso GEO/SEO. Lo que ahora necesita es un sistema de construcción de agentes de IA para orquestar estos agentes, como se indica en este gráfico resumen:
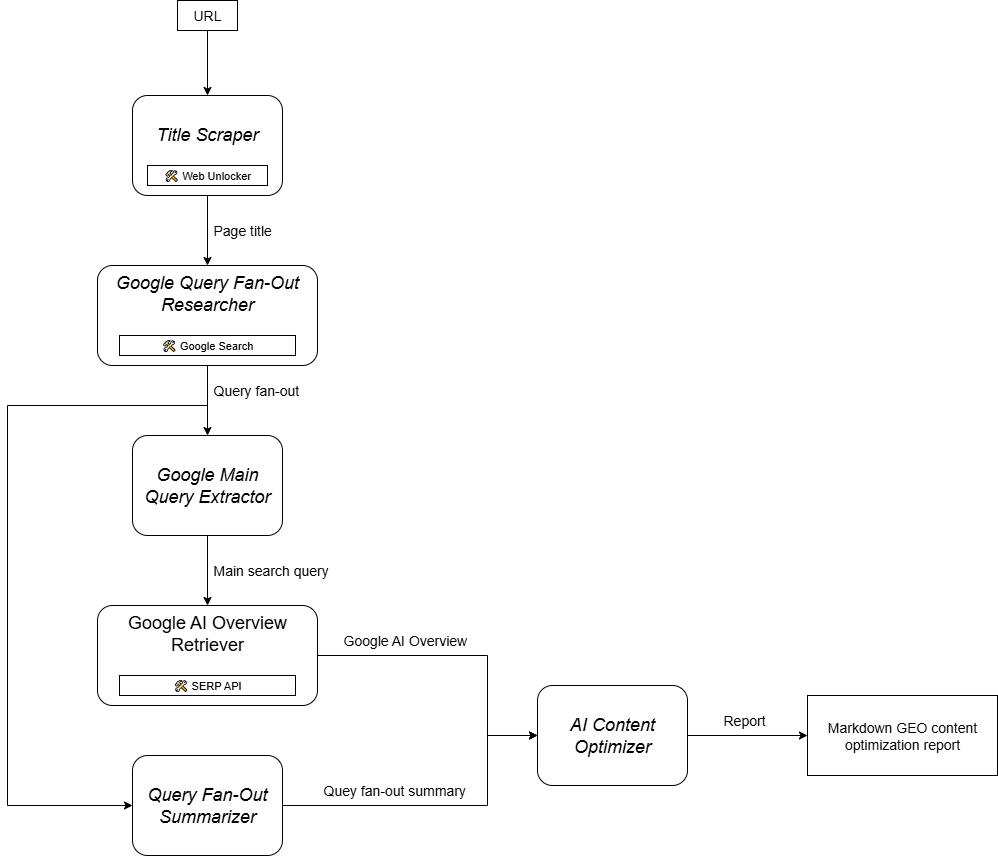
Dado que CrewAI está diseñado específicamente para orquestar sistemas multiagente, es el marco ideal para construir y gestionar este flujo de trabajo.
Implementación de un sistema de optimización de contenidos GEO multiagente en CrewAI mediante Gemini y Bright Data
Siga los pasos que se indican a continuación para aprender a crear un sistema multiagente que proporcione un flujo de trabajo repetible para optimizar páginas web para motores de búsqueda impulsados por IA. Mediante el análisis sistemático de los fan-outs de las consultas y los resúmenes de IA, este enfoque le ayuda a descubrir temas de alta prioridad y a estructurar el contenido para lograr clasificaciones más altas basadas en IA.
El código que se muestra a continuación está escrito en Python utilizando CrewAI, con integración de Bright Data y Gemini para proporcionar a los agentes las herramientas y capacidades necesarias.
Requisitos previos
Para seguir este tutorial, asegúrate de tener:
- Python 3.10+ instalado localmente.
- Una clave API Gemini (no se requieren créditos).
- Una cuenta de Bright Data.
No se preocupe si no tiene una cuenta de Bright Data. Se le guiará a través del proceso de creación de una.
Además, es muy importante entender cómo funciona CrewAI. Antes de empezar, recomendamos revisar la documentación oficial.
Paso 1: Configure su aplicación CrewAI
CrewAI requiere uv para su instalación. Puede instalarlo globalmente con el siguiente comando:
pip install uvTambién puede seguir la guía de instalación oficial de su sistema operativo.
A continuación, instala CrewAI globalmente en tu sistema:
uv tool install crewai Ahora, crea un nuevo proyecto CrewAI llamado ai_content_optimization_agent:
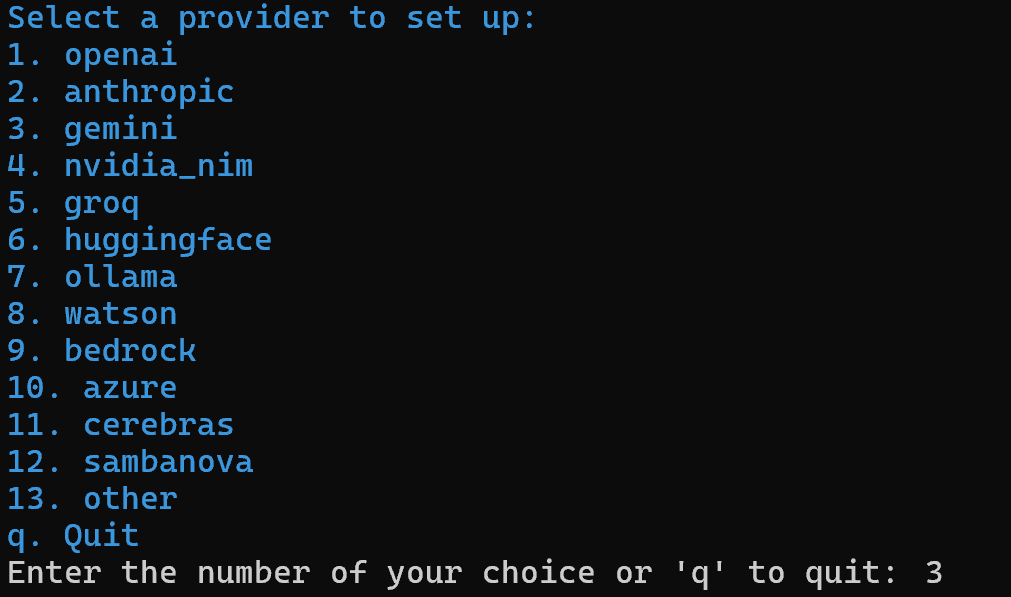
crewai create crew ai_content_optimization_agentSe le pedirá que seleccione un proveedor de IA. Dado que el flujo de trabajo actual funciona con Gemini, elija la opción 3:
A continuación, seleccione un modelo Gemini:
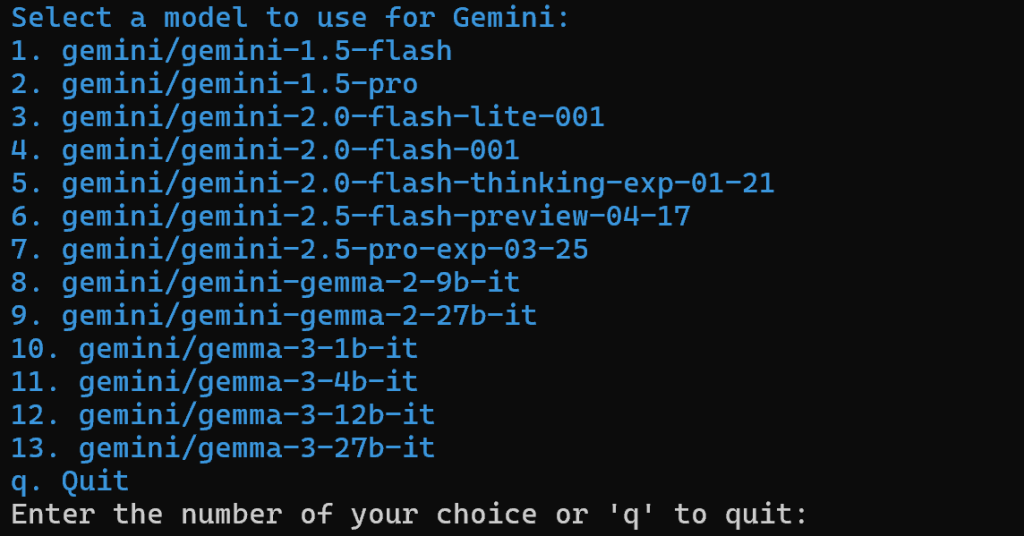
Puede elegir cualquiera de los modelos disponibles, ya que lo sustituirá más adelante en el artículo. Por lo tanto, no es importante.
Continúe introduciendo su clave API Gemini:

Después de este paso, su proyecto en la estructura de carpetas ai_content_optimization_agent/ tendrá el siguiente aspecto:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlCarga el proyecto en tu IDE de Python favorito y familiarízate con él. Explora los archivos actuales y observa que .env ya contiene el modelo Gemini seleccionado y tu clave API Gemini:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Si no estás familiarizado con los archivos de CrewAI o tienes algún problema, consulta la guía de instalación oficial.
Navega hasta la carpeta de tu proyecto en tu terminal:
cd ai_content_optimization_agentA continuación, inicializa un entorno virtual Python en su interior:
python -m venv .venv Nota: El entorno virtual debe llamarse .venv. De lo contrario, el comando crewai run para iniciar el flujo de trabajo de CrewAI fallará.
En Linux y macOS, active el entorno virtual con:
source .venv/bin/activateAlternativamente, en Windows, ejecute:
.venvScriptsactivateListo. Ahora tienes un proyecto CrewAI en blanco.
Paso nº 2: Integrar Gemini
Como se mencionó anteriormente, por defecto, CrewAI añade el modelo Gemini seleccionado al archivo .env. Para configurar el último modelo, sobrescriba la variable de entorno MODEL en el archivo .env de la siguiente manera:
MODEL=gemini/gemini-2.5-flashDe este modo, sus agentes de IA orquestados con CrewAI podrán conectarse a gemini-2.5-flash. En el momento de escribir este artículo, este es el último modelo de Gemini Flash. Además, tiene unos límites de velocidad muy generosos cuando se consulta a través de la API (como en esta integración de CrewAI).
En crew.py, carga el nombre MODEL desde el entorno usando:
MODEL = os.getenv("MODEL")Esta variable se utilizará más adelante para establecer el LLM en los agentes.
No olvide importar os de la biblioteca estándar de Python:
import os¡Genial! Se acabó el montaje de Géminis.
Paso 3: Instalar y configurar CrewAI Bright Data Tools
Extraer el título de una página web mediante IA no es sencillo. La mayoría de los LLM no pueden acceder directamente al contenido de las páginas web. E incluso cuando disponen de herramientas integradas para hacerlo, a menudo fallan debido a las avanzadas medidas anti-scraping, como la huella digital del navegador y los CAPTCHA. Las mismas dificultades se plantean en el caso del scraping de SERP en directo, ya que Google impide activamente el scraping automatizado.
Aquí es donde Bright Data se vuelve fundamental. Por suerte, las herramientas de Bright Data de CrewAI lo soportan oficialmente.
Para empezar, regístrese para obtener una cuenta de Bright Data (o inicie sesión si ya tiene una). A continuación, acceda al panel de control de su perfil y siga las instrucciones oficiales para configurar una zona Web Unlocker:

Asegúrese de que la zona está configurada como “Activa”:
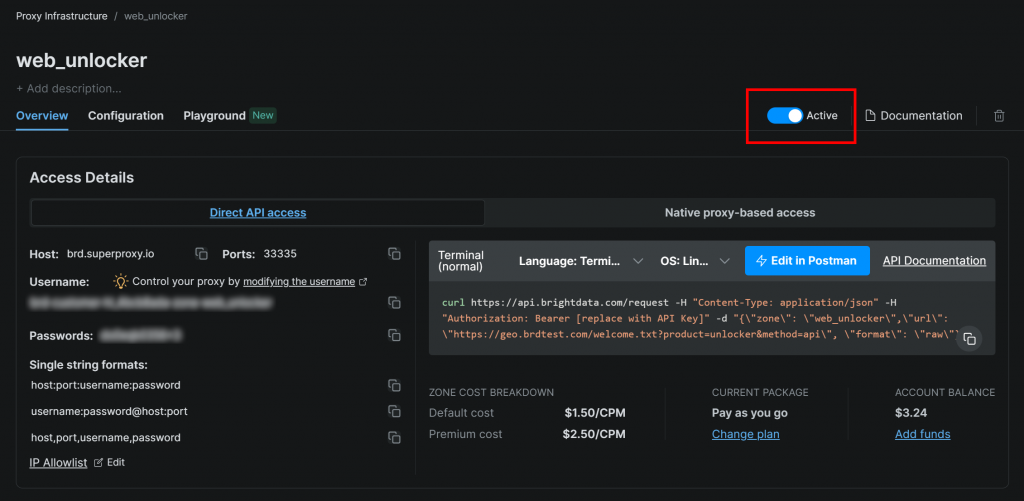
En este caso, el nombre de la zona Web Unlocker es "web_unlocker", pero puede darle el nombre que desee. Tenga este nombre en mente, ya que lo necesitará pronto.
Una vez completada la configuración, siga la guía oficial para generar su clave API de Bright Data. Guárdela de forma segura, ya que la necesitará en breve.
Ahora, en su entorno virtual activado, instale los requisitos de la herramienta CrewAI Bright Data:
pip install crewai[tools] aiohttp requestsPara que la integración funcione, añada sus credenciales de Bright Data al archivo .env mediante los dos envs siguientes:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"Sustituya el y por su clave de API de Bright Data y su nombre de zona de Web Unlocker reales, respectivamente.
A continuación, en crew.py, importe las herramientas de Bright Data:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchToolInicialícelos como se indica a continuación:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()Ahora puede proporcionar capacidades de desbloqueo web y recuperación de SERP a sus agentes simplemente pasándoles estas herramientas. Fantástico.
Paso nº 4: Construir el Agente Rascador de Títulos
Ahora tienes todo en su lugar para construir tu primer agente. Comience con el agente Title Scraper, que se encarga de extraer el título de una página web.
Para obtener el título de la página, hay dos formas principales:
- Recupera el contenido de texto del elemento HTML
<h1>. - Si falta
<h1>, pide a la IA que infiera el título de la página a partir del resto del contenido de la página.
No olvides que esto requiere la integración de la herramienta Web Unlocker. En crew.py, define el agente CrewAI y la tarea como sigue:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)Dado que esta tarea implica llamar a una herramienta de terceros, tiene sentido habilitar la lógica de reintentos (hasta 3 veces) a través de la opción max_retries. Esto evita que todo el flujo de trabajo falle debido a problemas temporales de red o errores de la herramienta. La misma lógica debería aplicarse a todas las demás tareas que dependen de servicios de terceros (a través de herramientas) o que implican operaciones complejas de IA que pueden fallar debido a errores de procesamiento de LLM.
A continuación, en su archivo de configuración agents.yaml, defina el agente Title Scraper de la siguiente manera:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."A continuación, en tasks.yaml, describa su tarea principal como sigue:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."Observa cómo esta tarea lee la URL de una entrada de CrewAI gracias a la sintaxis {url}. Verás cómo rellenar ese argumento de entrada en uno de los siguientes pasos.
Genial. El agente Title Scraper está completo. Ahora aplicará una lógica similar para definir todos los agentes restantes.
Paso nº 5: Implementar el agente investigador de Google Query Fan-Out
CrewAI no proporciona una forma integrada de acceder a la herramienta de búsqueda de Google disponible en los modelos Gemini. En su lugar, es necesario definir una integración personalizada Gemini LLM como se muestra en el repositorio oficial de integración Gemini CrewAI.
Esencialmente, tienes que crear una clase que extienda la clase CrewAI LLM. Esto se conectará a Gemini y habilitará la herramienta google_search. Puedes colocar esta clase en un archivo llamado gemini_google_search_llm.py dentro de una subcarpeta personalizada llms/ (o puedes poner la clase directamente en la parte superior de crew.py).
Defina su clase de integración Gemini LLM personalizada de la siguiente manera:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)Esto le permite acceder a la herramienta de búsqueda de Google en su modelo Gemini configurado.
Nota: La herramienta de búsqueda de Google incluye cierta cuota en el nivel gratuito de la API, por lo que puedes utilizarla en tu aplicación sin necesidad de un plan premium.
A continuación, en crew.py, importa la clase GeminiWithGoogleSearch:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchSe utiliza para especificar el agente Query Fan-Out Researcher de la siguiente manera:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)Tenga en cuenta que el LLM utilizado en la clase Agente es una instancia de la clase personalizada GeminiWithGoogleSearch. Dado que la tarea de generación de consultas en forma de abanico produce una salida valiosa para la depuración y el análisis posterior, debes exportarla a un archivo de salida personalizado. En este caso, la salida producida se almacenará en el archivo output/query_fanout.md.
Además, observe cómo el contexto de la tarea principal del agente es exactamente la salida de la tarea principal del agente anterior en el flujo de trabajo. De esta forma, el agente actual tendrá acceso a la salida producida por el agente Title Scraper. En concreto, lo utilizará como entrada cuando realice la recuperación en abanico a través de la herramienta de búsqueda de Google.
A continuación, en agents.yaml, añade:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."Y en tasks.yaml:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."Si te estás preguntando qué aspecto tiene una consulta en abanico, a continuación te mostramos un breve fragmento de un resultado real de la herramienta google_search:
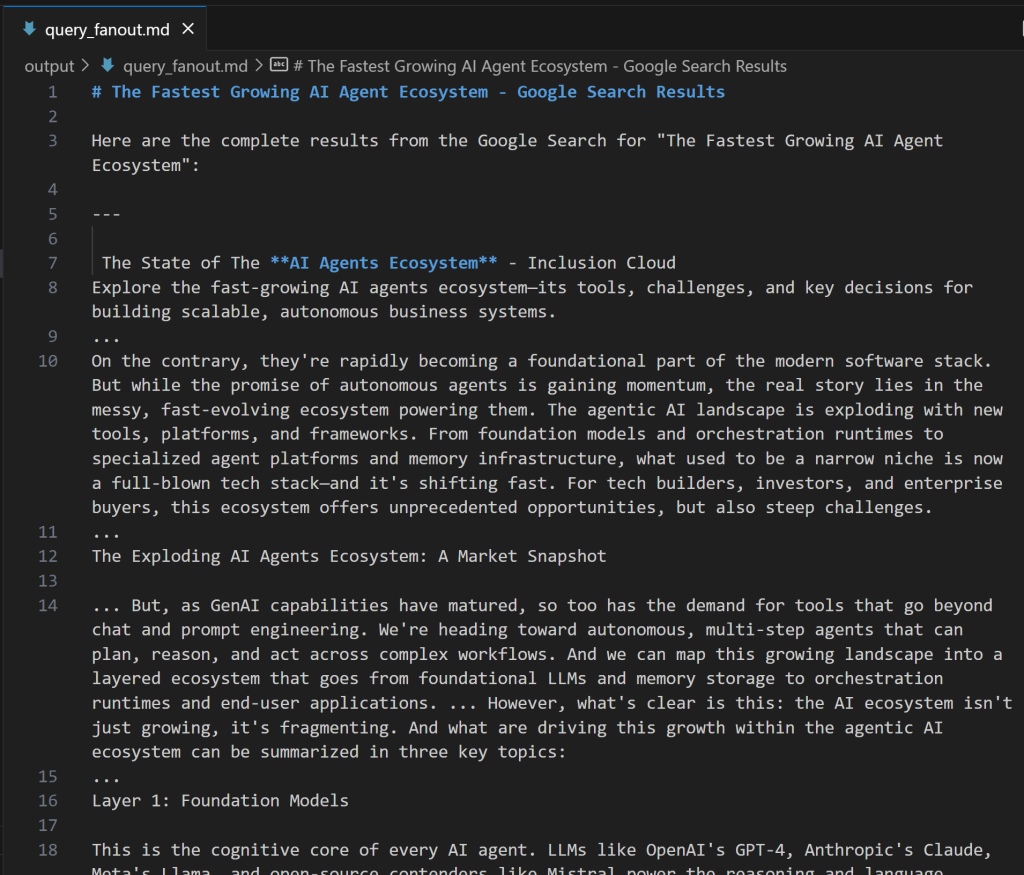
Perfecto. El agente Google Query Fan-Out Researcher está listo.
Paso nº 6: Definir los agentes restantes
Al igual que antes, procede a definir el resto de agentes en crew.py:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)Respectivamente, el código anterior especifica:
- El agente Google Main Query Extractor y su tarea principal.
- El agente Google AI Overview Retriever y su tarea principal.
- El agente Query Fan-Out Summarizer y su tarea principal.
- El agente AI Content Optimizer y su tarea principal.
Completa las definiciones de agente añadiendo estas líneas a agents.yaml:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."Y estas líneas a tasks.yaml:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.Vea cómo la tarea ai_overview_extraction_task incluye especificaciones técnicas para recuperar la AI Overview en la respuesta de la API SERP. Más información en la documentación oficial.
¡Maravilloso! Ya se han creado todos sus agentes de IA en el flujo de trabajo de optimización de contenidos GEO. A continuación, es el momento de añadir un Crew para orquestarlos.
Paso nº 7: Agregar todos los agentes de una tripulación
Dentro de crew.py, define una nueva función Crew para ejecutar los agentes secuencialmente:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)¡Asombroso! La clase AiContentOptimizationAgent en el archivo crew.py está completa. Sólo tienes que ejecutar su método crew() en el archivo main.py para iniciar el flujo de trabajo.
Paso nº 8: Definir el flujo de ejecución
Anula el archivo main.py para:
- Lee la URL de entrada desde el terminal utilizando la función
input()de Python. - Utilice la URL proporcionada para construir la entrada de agente requerida.
- Inicializa una instancia de
AiContentOptimizationAgenty llama a su métodocrew(), pasando un objeto de entrada con el campo{url}requerido rellenado. - Ejecute el flujo de trabajo de IA.
Implementa toda la lógica anterior en main.py de la siguiente manera:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")Paso 9: Ponga a prueba a su agente
En su entorno virtual activado, antes de iniciar su agente, instale las dependencias necesarias con:
crewai installA continuación, ponga en marcha su sistema de optimización GEO multiagente:
crewai runSe le pedirá que introduzca la URL de entrada:

En este ejemplo, utilizaremos como entrada una página del propio sitio CrewAI:
https://www.crewai.com/ecosystem
Esta página presenta a los principales actores del ecosistema de agentes de IA.
Ejecute el agente en esta página, y verá una salida como esta:
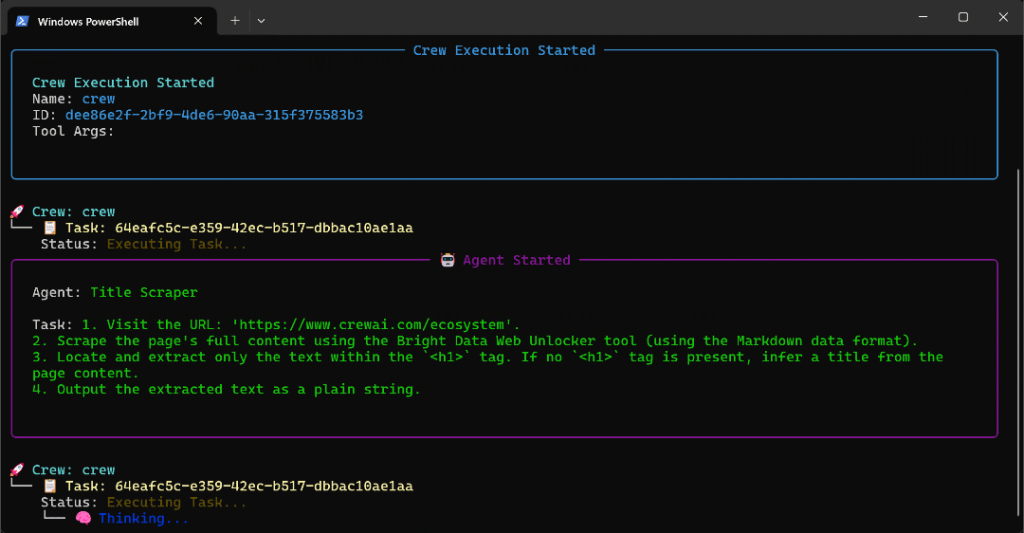
El GIF anterior se ha acelerado, pero esto es lo que ocurre paso a paso:
- El agente Title Scraper recoge el título de la página a través de la herramienta Bright Data Web Unlocker. El resultado es
"The Fastest Growing AI Agent Ecosystem"(exactamente como se muestra en la captura de pantalla de la página). - Google Query Fan-Out Researcher genera la salida query fan-out de la herramienta
google_search. Esto produce el archivoquery_fanout.mden la carpetaoutput/. - El extractor de consultas principales de Google identifica la consulta de búsqueda principal similar a Google a partir del abanico de consultas. El resultado es
"AI agent ecosystem growth". - Google AI Overview Retriever obtiene la AI Overview para la consulta de búsqueda a través de la SERP API de Bright Data. El resultado se almacena en
ai_overview.md. - El agente Query Fan-Out Summarizer condensa el contenido de la consulta fan-out en un resumen Markdown detallado en
query_fanout_summary.md. - AI Content Optimizer compara el resumen de consultas con la descripción general de Google AI para generar el archivo
report.mdfinal.
Al final de la ejecución, la carpeta output/ debe contener los cuatro archivos siguientes:
Abra report.md en modo de vista previa en Visual Studio Code y desplácese por él:

Como puede ver, contiene un informe Markdown detallado para ayudarle a optimizar el contenido de la página de entrada dada para GEO (y SEO).
Ahora, utiliza este agente en las URLs de las páginas web que quieras mejorar para el ranking AI, y mejorarás tu posicionamiento GEO y SEO.
¡Et voilà! Misión cumplida.
Próximos pasos
El agente de optimización de contenidos AI construido anteriormente ya es bastante potente, pero siempre se puede mejorar. Una idea es añadir otro agente al principio del flujo de trabajo que tome un mapa del sitio como entrada (opcionalmente usando una regex para filtrar URLs, por ejemplo, para seleccionar sólo entradas de blog). Este agente podría entonces pasar las URLs al flujo de trabajo existente, potencialmente en paralelo, permitiéndole analizar múltiples páginas para la optimización del contenido AI al mismo tiempo.
En general, ten en cuenta que puedes experimentar con las instrucciones de agents.yaml y tasks.yaml para adaptar el comportamiento de cada uno de los seis agentes a tu caso de uso específico. No se requieren conocimientos técnicos avanzados para realizar estos ajustes.
Conclusión
En este artículo, usted aprendió cómo aprovechar las capacidades de integración de IA de Bright Data para construir un flujo de trabajo multiagente complejo para la optimización GEO/SEO en CrewAI.
El flujo de trabajo de IA presentado aquí es ideal para cualquiera que busque una forma programática de mejorar el contenido de las páginas web tanto para los motores de búsqueda tradicionales como para las búsquedas impulsadas por IA.
Para crear flujos de trabajo avanzados similares, explore toda la gama de soluciones para recuperar, validar y transformar datos web en directo en la infraestructura de Bright Data AI.
Cree hoy mismo una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas web preparadas para la IA.




