
Esta guía le muestra cómo conectar Bright Data Web MCP con LangGraph para crear un agente de investigación de IA que pueda buscar, extraer y razonar sobre datos web en tiempo real.
En esta guía, aprenderá a:
- Crear un agente LangGraph que controle su propio bucle de razonamiento
- Dar a ese agente acceso web en tiempo real utilizando el nivel gratuito de Bright Data Web MCP
- Conectar herramientas de búsqueda y extracción a un agente operativo
- Actualizar el mismo agente con automatización del navegador utilizando las herramientas premium de Web MCP
Introducción a LangGraph
LangGraph le permite crear aplicaciones LLM en las que el flujo de control es explícito y fácilmente inspeccionable, sin quedar oculto dentro de indicaciones o reintentos. Cada paso se convierte en un nodo. Cada transición es definida por usted.
El agente se ejecuta como un bucle. El modelo LLM lee el estado actual y responde o solicita una herramienta. Si llama a una herramienta (como la búsqueda web), el resultado se añade de nuevo al estado y el modelo vuelve a decidir. Cuando tiene suficiente información, el bucle finaliza.
Esta es la diferencia clave entre los flujos de trabajo y los agentes. Un flujo de trabajo sigue pasos fijos. Un agente realiza un bucle: decide, actúa, observa y vuelve a decidir. Este bucle es la misma base que se utiliza en los sistemas RAG agenticos, donde la recuperación se produce de forma dinámica en lugar de en puntos fijos.
LangGraph le ofrece una forma estructurada de crear ese bucle, con memoria, llamada de herramientas y condiciones de parada explícitas. Puede ver todas las decisiones que toma el agente y controlar cuándo se detiene.
¿Por qué utilizar Bright Data Web MCP con LangGraph?
Los LLM razonan bien, pero no pueden ver lo que está sucediendo en la web en este momento. Su conocimiento se detiene en el momento del entrenamiento. Por lo tanto, cuando un agente necesita datos actuales, el modelo tiende a llenar el vacío con conjeturas.
Bright Data Web MCP le da a su agente acceso directo a datos web en vivo a través de herramientas de búsqueda y extracción. En lugar de adivinar, el modelo basa sus respuestas en fuentes reales y actualizadas.
LangGraph es lo que hace que ese acceso sea utilizable en un entorno de agente. Un agente tiene que decidir cuándo sabe lo suficiente y cuándo debe buscar más datos.
Con Web MCP, cuando el agente responde a una pregunta, puede señalar las fuentes que realmente ha utilizado en lugar de basarse en su memoria. Esto hace que el resultado sea más fácil de confiar y depurar.
Cómo conectar Bright Data Web MCP a un agente LangGraph
LangGraph controla el bucle del agente. Bright Data Web MCP proporciona al agente acceso a datos web en tiempo real. Lo que queda es conectarlos sin añadir complejidad.
En esta sección, configurará un proyecto mínimo en Python, se conectará al servidor Web MCP y expondrá sus herramientas a un agente LangGraph.
Requisitos
Para seguir este tutorial, necesita:
- Python versión 3.11+
- Cuenta de Bright Data
- Cuenta de OpenAI Platform
Paso n.º 1: generar una clave API de OpenAI
El agente necesita una clave API LLM para razonar y decidir cuándo utilizar las herramientas. En esta configuración, esa clave proviene de OpenAI.
Cree una clave API desde el panel de control de la plataforma OpenAI. Abra la página «Claves API» y haga clic en «Crear nueva clave secreta».
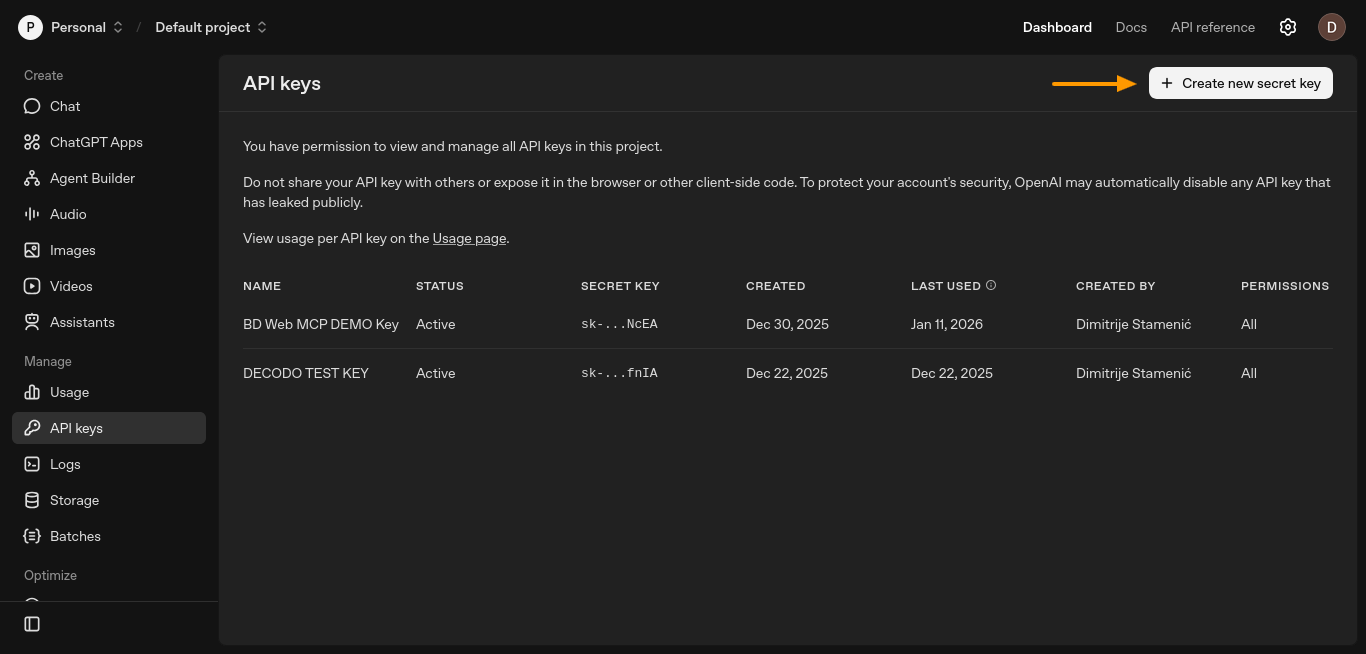
Se abrirá una nueva ventana en la que podrá configurar su clave.
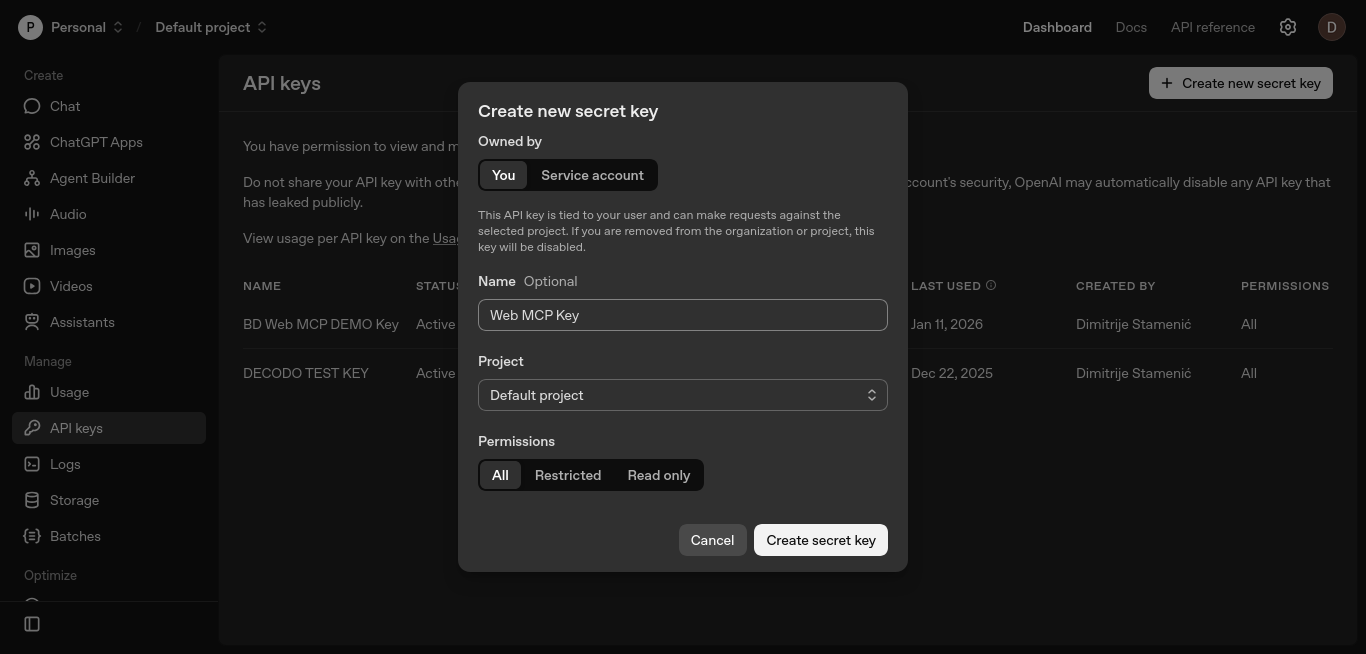
Mantenga los valores predeterminados, opcionalmente asigne un nombre a la clave y haga clic en «Crear clave secreta».
Copie la clave y guárdela de forma segura. La añadirá a la variable de entorno OPENAI_API_KEY en los siguientes pasos.
Esta clave permite a LangGraph llamar al modelo LLM, que puede decidir cuándo invocar las herramientas Web MCP.
Paso n.º 2: Generar el token API de Bright Data
A continuación, necesitará un token API de Bright Data. Este token autentica su agente con el servidor Web MCP y le permite llamar a las herramientas de búsqueda y scraping.
Genere el token en el panel de control de Bright Data. Abra «Configuración de la cuenta», vaya a «Usuarios y claves API» y haga clic en «+ Añadir clave».
Para esta guía, mantenga los valores predeterminados y haga clic en «Guardar»:
Copie la clave y guárdela en un lugar seguro. La añadirá a la variable de entorno BRIGHTDATA_TOKEN en los siguientes pasos.
Este token es lo que le da a su agente permiso para acceder a datos web en tiempo real a través de Web MCP.
Paso n.º 3: Configurar un proyecto sencillo en Python
Cree un nuevo directorio de proyecto y un entorno virtual:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv Active el entorno virtual:
source webmcp-langgraph-venv/bin/activateEsto mantiene las dependencias aisladas y evita conflictos con otros proyectos. Con el entorno activo, instale solo las dependencias necesarias. Se trata de los mismos adaptadores MCP que se utilizan en las integraciones LangChain y LangGraph de Bright Data, por lo que la configuración se mantiene coherente a medida que su agente crece:
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvCree un archivo .env para almacenar sus claves API:
touch .envPega la clave API de OpenAI y la clave de Bright Data en el archivo .env:
OPENAI_API_KEY="su-clave-API-openai"
BRIGHTDATA_TOKEN="su-clave-API-brightdata"Mantén el nombre OPENAI_API_KEY sin cambios. LangChain lo lee automáticamente, por lo que no es necesario pasar la clave en el código.
Por último, crea un único archivo Python y define el mensaje del sistema que define la función del agente, los límites y las reglas de uso de las herramientas:
# archivo webmcp-langgraph-demo.py
SYSTEM_PROMPT = """Eres un asistente de investigación web.
Tarea:
- Investiga el tema del usuario utilizando los resultados de búsqueda de Google y algunas fuentes.
- Devuelve entre 6 y 10 puntos clave sencillos.
- Añade una breve lista de «Fuentes:» con solo las URL que has utilizado.
Cómo utilizar las herramientas:
- Primero, utilice la herramienta de búsqueda para obtener los resultados de Google.
- Seleccione entre 3 y 5 resultados fiables y recopílelos.
- Si la recopilación falla, pruebe con otro resultado.
Restricciones:
- Utilice como máximo 5 fuentes.
- Dé preferencia a los documentos oficiales o las fuentes primarias.
- Sea rápido: no realice rastreos profundos.
"""Paso n.º 4: Configurar los nodos de LangGraph
Esta es la parte fundamental del agente. Una vez que comprenda este bucle, todo lo demás son detalles de implementación.
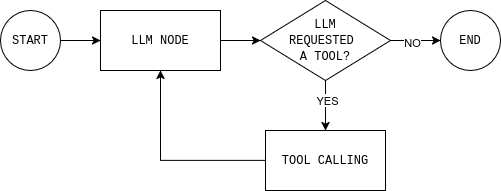
Antes de escribir el código, es útil comprender el bucle del agente que vas a crear. El diagrama muestra un bucle simple del agente LangGraph: el modelo lee el estado actual, decide si necesita datos externos, llama a una herramienta si es necesario, observa el resultado y repite hasta que puede responder.
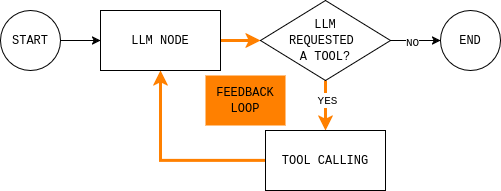
Para implementar este bucle, necesitas dos nodos (un nodo LLM y un nodo de ejecución de herramientas) y una función de enrutamiento que decida si continuar o terminar y dar una respuesta final.
El nodo LLM envía el estado actual de la conversación y las reglas del sistema al modelo y devuelve una respuesta o llamadas a herramientas. El detalle clave es que cada respuesta del modelo se añade a MessagesState, de modo que en pasos posteriores se puede ver qué decidió el modelo y por qué.
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_callEl nodo de ejecución de herramientas ejecuta las herramientas que el modelo ha solicitado y registra los resultados como observaciones. Esta separación mantiene el razonamiento en el modelo y la ejecución en el código.
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# Las herramientas MCP suelen ser asíncronas.
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_nodePor último, la regla de enrutamiento decide si el gráfico debe continuar en bucle o detenerse. En la práctica, responde a una sola pregunta: ¿el modelo solicitó herramientas?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return ENDPaso n.º 5: conectar todo
Todo lo que se hace en este paso se encuentra dentro de la función main(). Aquí es donde se configuran las credenciales, se conecta a Web MCP, se vinculan las herramientas, se crea el gráfico y se ejecuta una consulta.
Comience cargando las variables de entorno y leyendo BRIGHTDATA_TOKEN. Esto mantiene las credenciales fuera del código fuente y falla rápidamente si falta el token.
# Cargar variables de entorno desde .env
load_dotenv()
# Leer token de Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")A continuación, crea un MultiServerMCPClient y dirígete al punto final Web MCP. Este cliente conecta el agente a los datos web en tiempo real.
# Conectarse al servidor Bright Data Web MCP
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})Nota: Web MCP utiliza Streamable HTTP como transporte predeterminado, lo que simplifica la transmisión de herramientas y los reintentos en comparación con las configuraciones antiguas basadas en SSE. Por eso, la mayoría de las integraciones MCP más recientes se estandarizan en este transporte.
A continuación, recupere las herramientas MCP disponibles e indexe por nombre. El nodo de ejecución de la herramienta utiliza este mapa para enrutar las llamadas.
# Obtener todas las herramientas MCP disponibles (búsqueda, raspado, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}Inicialice el LLM y vincule las herramientas MCP a él. Esto permite llamar a las herramientas.
# Inicializar el LLM y permitirle llamar a las herramientas MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)Ahora construye el agente LangGraph mostrado anteriormente. Crea un StateGraph(MessagesState), añade los nodos LLM y tool, y conecta los bordes para que coincidan con el bucle.
# Construye el agente LangGraph.
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Flujo del gráfico:
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()Por último, ejecuta el agente con una indicación real. Establece un recursion_limit para evitar bucles infinitos.
# Ejemplo de consulta de investigación
topic = "¿Qué es Bright Data Web MCP?"
# Ejecuta el agente
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Investiga este tema:n{topic}")
]
},
# Evitar bucles infinitos
config={"recursion_limit": 12})
# Imprimir la respuesta final
print(result["messages"][-1].content)Así es como se ve en main():
async def main():
# Cargar variables de entorno desde .env
load_dotenv()
# Leer token de Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")
# Conectarse al servidor MCP web de Bright Data
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# Obtener todas las herramientas MCP disponibles (búsqueda, extracción, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# Inicializar el LLM y permitirle llamar a las herramientas MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# Construir el agente LangGraph.
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Flujo del gráfico:
# INICIO → LLM → (herramientas?) → LLM → FINAL
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# Ejemplo de consulta de investigación
topic = "¿Qué es el Protocolo de Contexto de Modelo (MCP) y cómo se utiliza con LangGraph?"
# Ejecutar el agente
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Investiga este tema:n{topic}")
]
},
# Evitar bucles infinitos
config={"recursion_limit": 12}
)
# Imprimir la respuesta final
print(result["messages"][-1].content)Nota: Puede encontrar una versión completa y ejecutable de este agente en este repositorio de GitHub. Clone el repositorio, añada sus claves API a un archivo
.envy ejecute el script para ver el bucle completo de LangGraph + Web MCP en acción.
Uso de herramientas de pago de Web MCP para superar los retos del scraping web con la automatización del navegador
El scraping estático dejará de funcionar una vez que se salga de las páginas renderizadas por el servidor y se entre en sitios con mucho JavaScript o impulsados por la interacción. Se trata de la misma división entre estático y dinámico que determina cuándo se necesita un navegador real en lugar de HTML sin procesar.
También falla en páginas que requieren una interacción real del usuario (desplazamiento infinito, paginación basada en botones), donde la automatización del navegador se convierte en la única opción fiable.
Web MCP ofrece la automatización del navegador de scraping y el scraping avanzado como herramientas MCP. Para el agente, son solo opciones adicionales cuando las herramientas más simples no son suficientes.
Habilitar las herramientas de automatización del navegador en Web MCP
Dado que las herramientas de automatización del navegador de Web MCP no están incluidas en el nivel gratuito, primero debe añadir fondos a su cuenta de Bright Data en el menú «Facturación» de la barra lateral izquierda.
A continuación, habilite el grupo de herramientas de automatización del navegador para su configuración de MCP. Abra la sección «MCP» y haga clic en «Editar»:
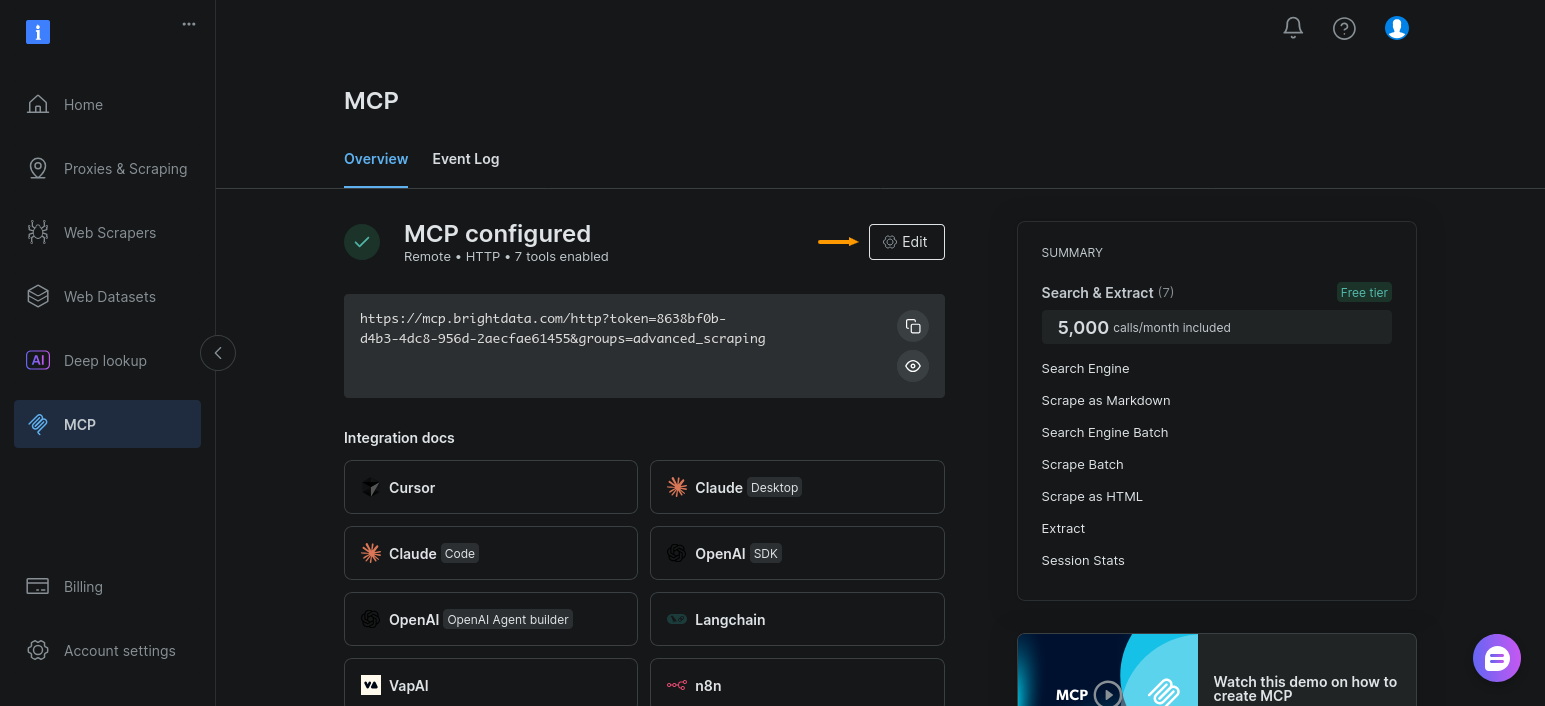
Ahora solo tiene que habilitar «Automatización del navegador» y hacer clic en «Continuar con la configuración»:
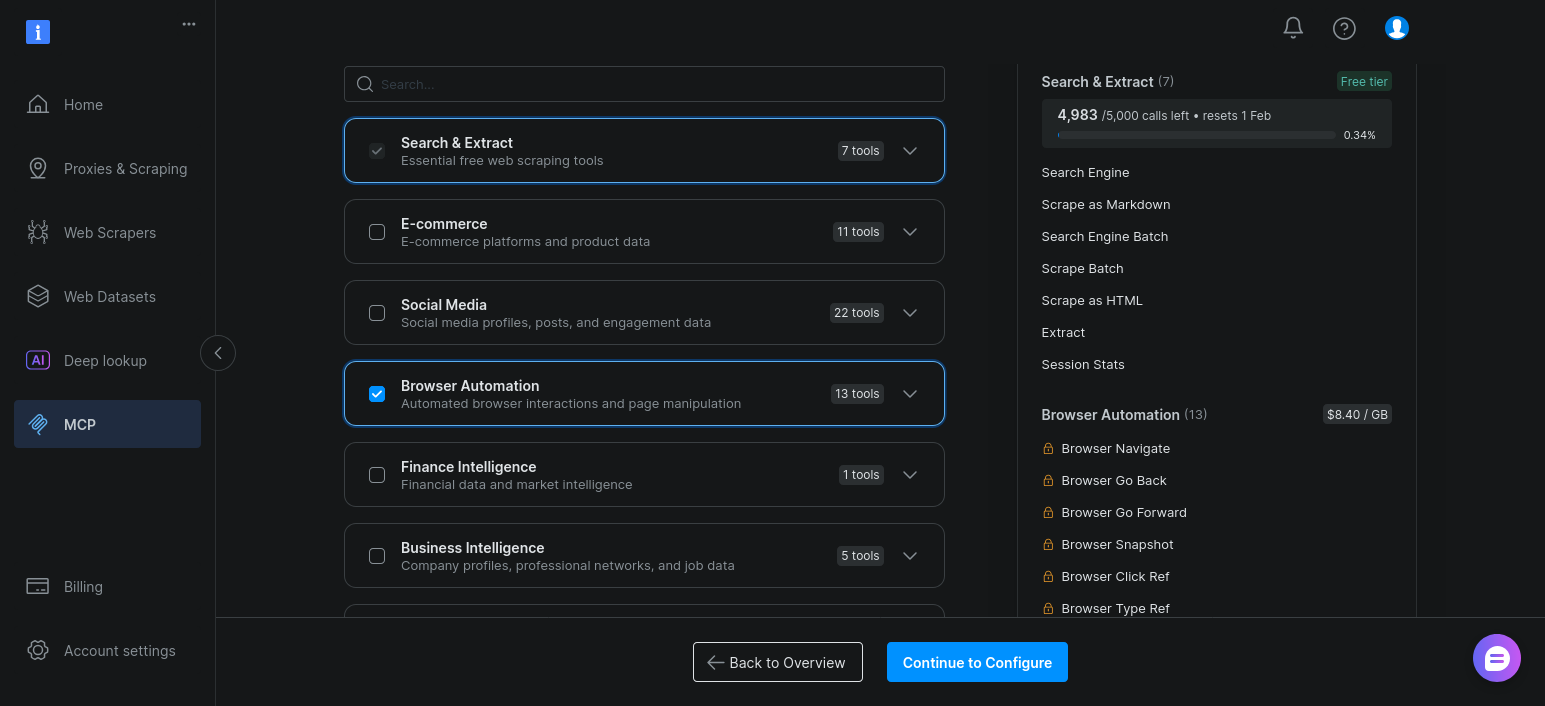
Mantenga la configuración predeterminada y haga clic en «Copiar y cerrar»:
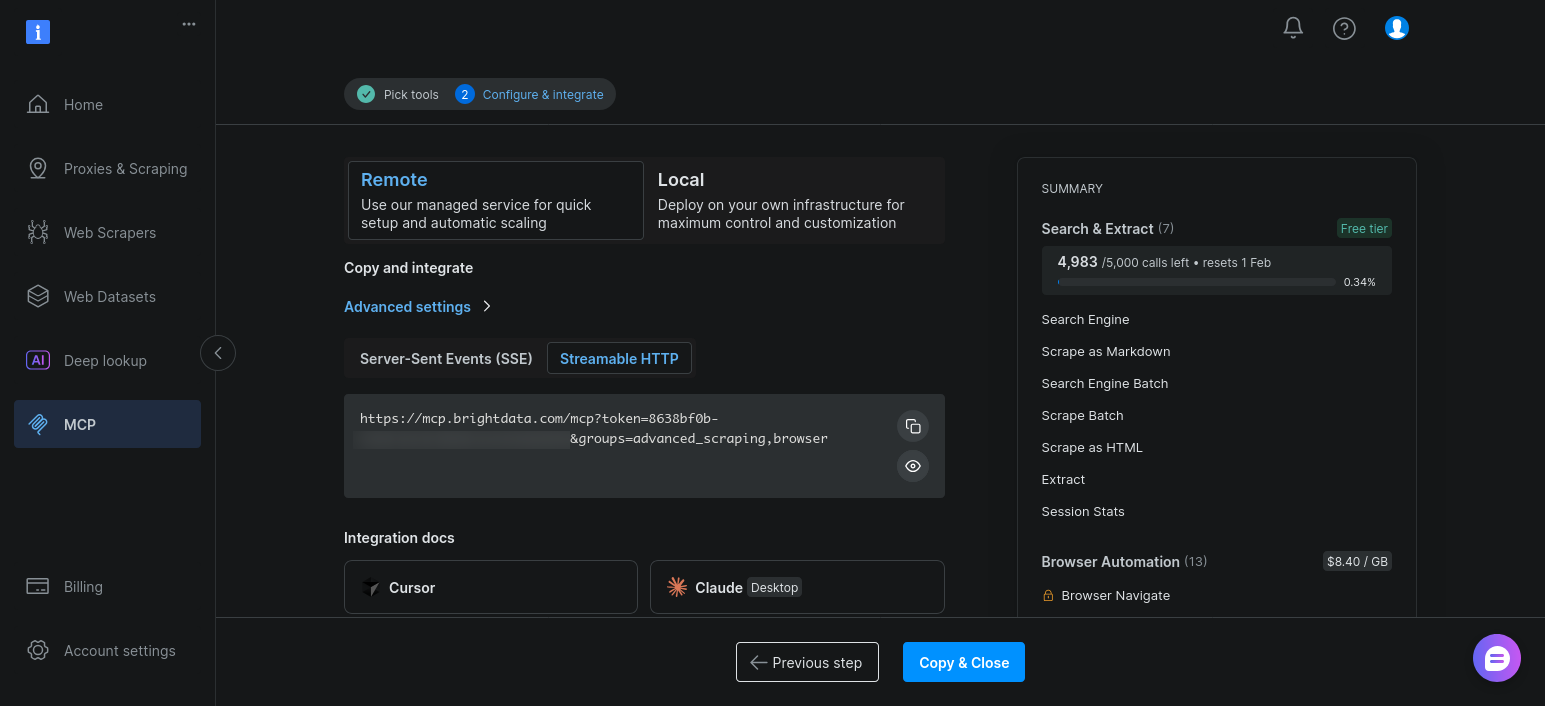
Una vez habilitadas, estas herramientas aparecerán junto a las herramientas de búsqueda y extracción cuando el agente llame a client.get_tools().
Amplíe el agente LangGraph existente para las herramientas de automatización del navegador
La clave aquí es sencilla: no cambie su arquitectura LangGraph.
Su agente ya:
- Descubre herramientas de forma dinámica
- Las vincula al modelo
- Dirige la ejecución a través del mismo bucle
LLM -> herramienta -> observación
Añadir herramientas de automatización del navegador solo cambia las herramientas que están disponibles.
En la práctica, el único cambio es la URL de conexión MCP. En lugar de conectarse al punto final básico, solicite los grupos de herramientas avanzadas de scraping y automatización del navegador:
# Habilitar el rastreo avanzado y la automatización del navegador de scraping
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"Cuando vuelva a ejecutar el script, client.get_tools() devolverá herramientas adicionales basadas en el navegador. El modelo puede elegirlas cuando el rastreo estático devuelva resultados escasos o incompletos.
Conclusión
LangGraph le ofrece un bucle de agente claro e inspeccionable con condiciones de estado, enrutamiento y detención que usted controla. Web MCP proporciona a ese bucle un acceso fiable a datos web reales sin introducir la lógica de scraping en las indicaciones o el código.
El resultado es una separación clara de responsabilidades. El modelo decide qué hacer. LangGraph decide cómo se ejecuta el bucle. Bright Data se encarga de la búsqueda, la extracción y los problemas de bloqueo. Cuando algo falla, puedes ver dónde ha fallado y por qué.
Igualmente importante es que esta configuración no le deja en un callejón sin salida. Puede empezar con las herramientas básicas de Web MCP para una investigación rápida y pasar a las herramientas de pago de Web MCP cuando el Scraping web falle. La arquitectura del agente sigue siendo la misma. Solo se amplía el alcance del agente.






